
Kami telah menulis banyak artikel tentang scraping dengan Python, tapi itu bukan satu-satunya bahasa yang cocok untuk ekstraksi data. Jadi hari ini kita akan berbicara tentang scraping NodeJS.
Pertama, mari kita lihat informasi umum tentang apa itu dan bagaimana mempersiapkan komputer Anda untuk bekerja dengan NodeJS dan membuat scraper dengan Axios dan Cheerio.
Daftar Isi
Pengantar NodeJS
NodeJS bukanlah bahasa pemrograman lain, tetapi sejenis lingkungan yang memungkinkan Anda bekerja dengan JavaScript di luar browser. Ini memiliki mesin dasar yang sama dengan Chrome – V8.
Siapa pun yang pernah berurusan dengan JavaScript di front end akan merasa mudah untuk memulai.
Secara sederhana, Node.js adalah aplikasi C++ yang mengambil kode JavaScript sebagai masukan dan menjalankannya.
Keuntungan utama NodeJS adalah memungkinkan Anda mengimplementasikan arsitektur asinkron dalam satu thread. Selain itu, berkat komunitas yang aktif, NodeJS memiliki solusi siap pakai untuk semua kesempatan, namun kita akan membicarakannya nanti.
Jadi, mari bersiap untuk menggores:
- Instal NodeJS.
- Mari perbarui NPM.
Untuk menginstal NodeJS, kunjungi situs resminya dan unduh file instalasi. Saat ini ada dua versi yang tersedia:
Versi 16.17.1 LTS stabil dan 18.9.1 adalah yang terbaru. Pilihan versi terserah pengguna dan tidak mempengaruhi contoh di artikel ini.
Setelah mengunduh dan menginstal paket, periksa apakah semuanya berfungsi dengan baik. Anda dapat melakukan ini dari baris perintah dengan perintah berikut:
node -v
npm -vUntuk memperbarui NPM Anda dapat menjalankan perintah berikut:
npm install -g npmSetelah itu, Anda bisa mulai bekerja dengan paket NPM.
Paket atau solusi NPM untuk semua situasi
NPM (Node Package Manager) adalah manajer paket standar yang memungkinkan setiap pengguna mengunduh paket dari server cloud npm atau mengunggah paket ke server ini. Ini berarti bahwa setiap pengguna yang telah menulis pustaka JavaScript atau alat untuk melakukan tugasnya dapat mengunggahnya ke server, setelah itu siapa pun dapat mengunggahnya.
Dengan pendekatan ini, ada banyak paket NPM siap pakai saat ini dan jika diinginkan, Anda dapat menemukan solusi siap pakai untuk hampir semua masalah atau tugas.
Untuk menulis scraper sederhana kita memerlukan dua alat berikut:
- Alat yang memungkinkan Anda menjalankan permintaan dan mendapatkan kode halaman.
- Alat yang memproses kode sumber dan mengambil data tertentu.
Mari kita coba memutuskan perpustakaan mana yang lebih baik bagi kita.
Bekerja dengan permintaan
Ada dua perpustakaan populer untuk mendapatkan kode halaman dan mengirim permintaan POST dan GET di NodeJS: Axios dan Fetch. Meskipun Axios memiliki banyak kekurangan dan Fetch adalah perpustakaan yang relatif baru yang tidak memiliki kekurangan tersebut, Axios masih lebih populer. Dan semua itu karena:
- Kode dengan Axios lebih ringkas.
- Pustaka Axios melaporkan kesalahan jaringan, namun Fetch API tidak.
- Axios dapat memantau kemajuan pembongkaran data, tetapi Fetch tidak bisa.
Selain kedua perpustakaan ini, Ky (klien HTTP kecil dan canggih berdasarkan window.fetch) dan Superagent (perpustakaan klien HTTP kecil berdasarkan XMLHttpRequest) juga patut disebutkan.
Jika proyeknya kecil dan dua perpustakaan terakhir dapat diimplementasikan, lebih baik menggunakannya.
Parsing perpustakaan
Saat ini, Cheerio adalah parser terpopuler yang membuat pohon DOM halaman dan memungkinkan Anda bekerja dengannya dengan nyaman. Cheerio menganalisis markup dan menyediakan fungsi untuk memproses data yang diterima.
Sebagai analog dari Cheerio, Anda dapat menggunakan Osmosis, yang memiliki fungsi serupa tetapi ketergantungannya lebih sedikit.
Buat proyek dan tambahkan Axios
Jadi kita akan menggunakan Axios dan Cheerio. Mari tentukan direktori dan mulai NPM di dalamnya. Buka folder tempat scraper Anda berada dan jalankan baris perintah di folder itu. Kemudian masukkan perintah:
npm init -yIni akan membuat file package.json di folder yang menjelaskan proyek kita dan menentukan dependensinya.
Mari kita ke bagian tengah pembuatan scraper. Kita akan melihatnya di situs contoh example.com. Axios memungkinkan Anda membuat permintaan dan menerima data. Untuk proyek ini kita hanya memerlukan permintaan HTTP GET.
Tulis ketergantungan pada baris perintah:
npm install axiosSekarang mari kita coba mendapatkan kode halamannya. Untuk melakukannya, buat file index.js di folder yang sama. Di dalamnya kami menghubungkan Axios, menjalankan permintaan dan menampilkannya di layar:
const axios = require('axios');
const url="https://example.com";
axios.get(url)
.then(response => {
console.log(response.data);
})
Selain itu, kami akan menambahkan penangan kesalahan di bagian akhir agar program tidak rusak saat terjadi kesalahan dan menampilkannya di layar:
.catch(error => {
console.log(error);
})Untuk menjalankan proyek, buka baris perintah dan jalankan perintah berikut:
node index.jsKode sumber halaman example.com ditampilkan di layar:
<!doctype html>
<html>
<head>
<title>Contoh domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Contoh domain</h1>
<p>Domain ini untuk digunakan dalam contoh ilustratif dalam dokumen. Anda dapat menggunakan domain ini dalam literatur tanpa koordinasi sebelumnya atau meminta izin.</p>
<p><a href="https://www.iana.org/domains/example">Informasi lebih lanjut...</a></p>
</div>
</body>
</html>Sekarang mari kita coba judulnya saja
-hari untuk menerima.
Memproses permintaan dengan Cheerio
Cheerio memungkinkan Anda menganalisis materi yang berupa markup HTML dan XML. Jadi kita bisa menggunakannya untuk mendapatkan data spesifik dari kode sumber yang baru saja kita peroleh.
Mari pergi ke baris perintah dan tambahkan dependensi:
npm install cheerioDan letakkan juga di file indeks index.js:
const cheerio = require('cheerio');Mari kita berasumsi bahwa kita dapat memiliki lebih dari satu header dan ingin mempertahankan semuanya:
axios.get(url)
.then(({ data }) => {
const $ = cheerio.load(data);
const title = $('h1')
.map((_, titles) => {
const $titles = $(titles);
return $titles.text()
})
.toArray();
console.log(title)
});
Anda dapat menggunakan pemilih CSS untuk menyiapkan kueri yang lebih kompleks atau memilih data tertentu.
Contoh vs. kenyataan
Kode kami berfungsi pada halaman HTML sederhana, namun untuk sebagian besar situs web, strukturnya bersifat dinamis, bukan statis. Selain itu, jika kita terus-menerus menjelajahi situs tersebut, kita akan diblokir atau ditawari untuk memecahkan captcha. Sayangnya, pengikis sederhana seperti itu tidak akan mampu mengatasi hal ini.
Namun, untuk mengatasi masalah pertama, cukup menggunakan browser tanpa kepala, untuk menyelesaikan masalah kedua - proxy, dan untuk menyelesaikan masalah ketiga - layanan untuk memecahkan captcha. Namun ada solusi yang lebih sederhana - menggunakan web scraping API, yang menyelesaikan semua kesulitan ini.
Mari kita coba menjelajahi beranda medium.com dan mendapatkan judul artikel darinya menggunakan web scraping API dan NodeJS. Untuk menggunakan API, daftar di Scrape-It.Cloud dan salin kunci API dari akun Anda. Kami akan menggunakannya nanti.
Untuk memahami penyeleksi mana yang berisi informasi yang kami perlukan, kunjungi situs web dan Alat Pengembang atau DevTools (F12).
Jika Anda belum pernah bekerja dengan DevTools sebelumnya, kami sarankan membaca artikel kami: “5 Tips & Trik Chrome DevTools untuk Scraping”.
Setelah masuk ke DevTools, tekan Shift+Ctrl+C untuk memilih item di halaman dan melihat kodenya, lalu pilih judul artikel mana pun.
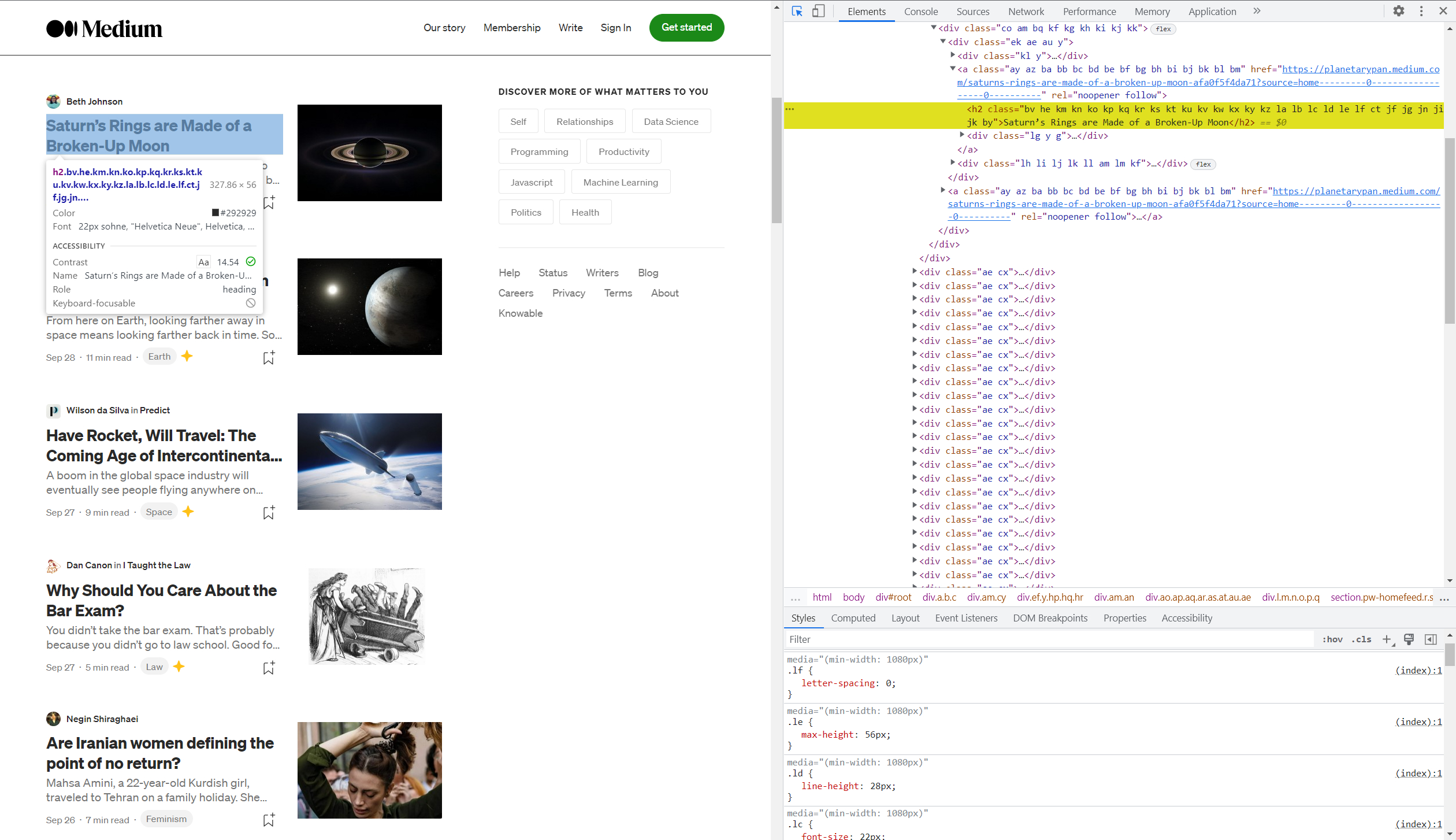
Kode menyorot elemen ini di sisi kanan jendela. Bagus, sekarang mari masuk ke halaman scrape-it.cloud dan buka tab Web Scraping API. Pilih NodeJS di pembuat permintaan dan dapatkan kode siap pakai untuk pengikisan halaman.
Namun, ini tidak cukup. Mari kita siapkan kueri kita untuk mengembalikan judul artikel yang disimpan dalam tag h2 dengan tepat. Untuk melakukan ini kami menggunakan aturan ekstraksi.
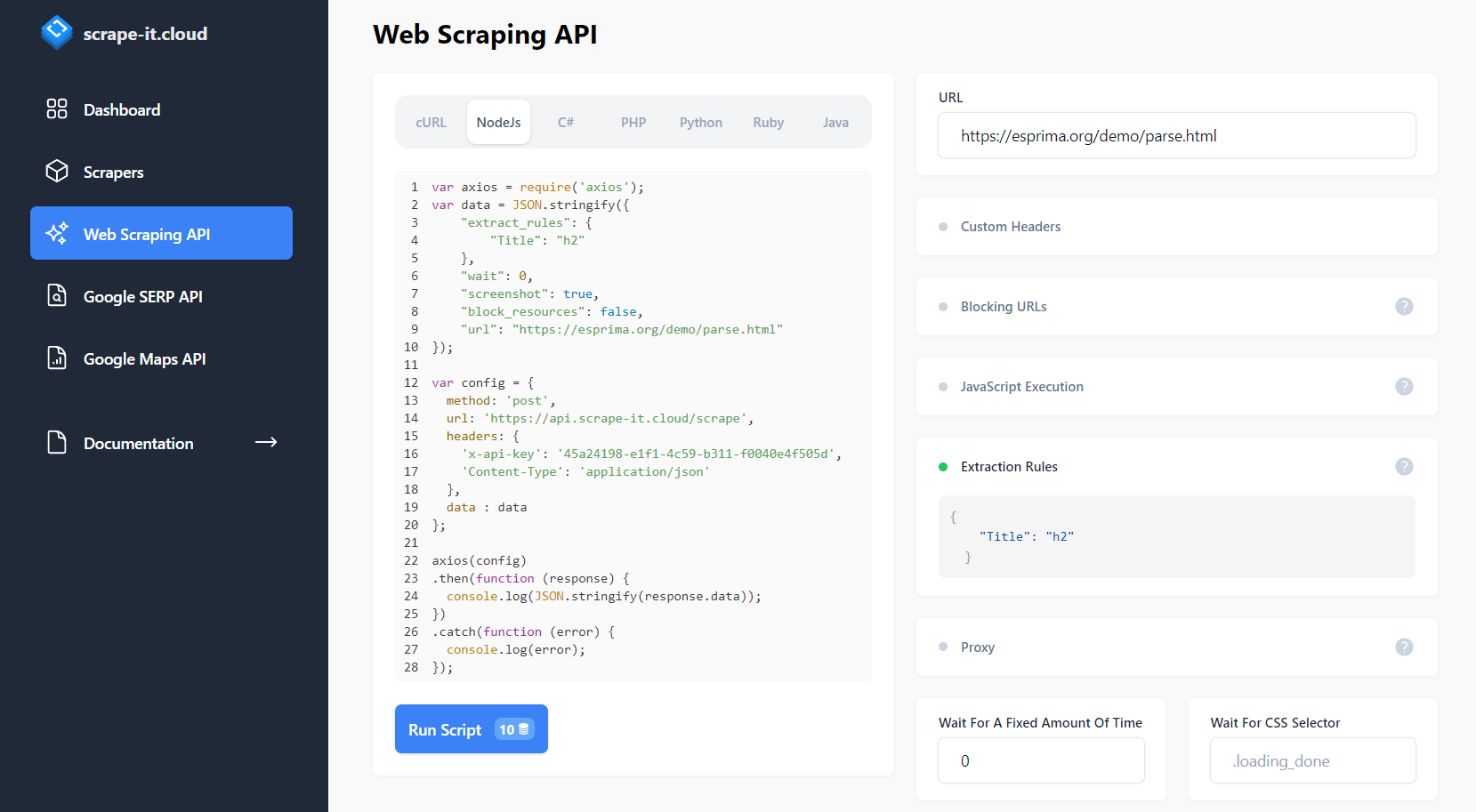
Kita dapat menjalankan skrip yang dihasilkan dari situs atau menyimpannya ke file. Mari simpan ke file dan ubah baris keluaran hasil (baris 24) menjadi kode berikut:
console.log(JSON.stringify(response.data.scrapingResult.extractedData.Title));Ini diperlukan untuk hanya menampilkan judul artikel saja. Jika kita melakukannya, kita mendapatkan daftarnya:
(
"Saturn’s Rings are Made of a Broken-Up Moon",
"What does Earth look like from across the Universe?",
"Have Rocket, Will Travel: The Coming Age of Intercontinental Spaceflight",
"Why Should You Care About the Bar Exam?",
"Are Iranian women defining the point of no return?",
"Corn is in Nearly Everything We Eat. Does It Matter?",
"Health Care Roulette",
"America’s Brief Experiment With Universal Healthcare Is Ending",
"There is More than Meets the Eye in Patagonia’s Bold Activism",
"It’s What You See",
"How Civil Rights Groups are Pushing Back Against Amazon’s New Show",
"Why “Microhistories” Rock",
"How to Be a Tourist",
"You Don’t Feel My Pain",
"The Servitude Of Our Times",
"10 Mental Models for Learning Anything",
"The Joy of Repairing Laptops",
"Why Adnan Syed Is Free"
)Pengikisan seperti itu aman dan mudah serta membantu menghindari penyumbatan dan mengikis data dinamis.
Kesimpulan dan temuan
NodeJS adalah alat pengikis data yang sangat fleksibel dan mudah digunakan yang memungkinkan Anda mengekstrak data dari berbagai situs web dengan cepat dan efisien.
Kode contoh lengkap tanpa API:
const axios = require('axios');
const cheerio = require('cheerio');
const url="https://example.com";
axios.get(url)
.then(({ data }) => {
const $ = cheerio.load(data);
const title = $('h1')
.map((_, titles) => {
const $titles = $(titles);
return $titles.text()
})
.toArray();
console.log(title)
});
Lengkapi kode contoh dengan API:
var axios = require('axios');
var data = JSON.stringify({
"extract_rules": {
"Title": "h2"
},
"wait": 0,
"screenshot": true,
"block_resources": false,
"url": "https://medium.com/"
});
var config = {
method: 'post',
url: 'https://api.scrape-it.cloud/scrape',
headers: {
'x-api-key': 'YOUR-API-KEY',
'Content-Type': 'application/json'
},
data : data
};
axios(config)
.then(function (response) {
console.log(response.data.scrapingResult.extractedData.Title);
})
.catch(function (error) {
console.log(error);
});Jika topik tersebut menarik minat Anda, Anda dapat mempelajari lebih lanjut di artikel “Web Scraping dengan node.js: Cara Memanfaatkan Kekuatan JavaScript” dan “Cara Scrape Yelp dengan NodeJS.”