
Wir haben viele Artikel über Scraping mit Python geschrieben, aber es ist nicht die einzige Sprache, die sich für die Datenextraktion eignet. Deshalb werden wir heute über NodeJS-Scraping sprechen.
Schauen wir uns zunächst allgemeine Informationen darüber an, was es ist und wie Sie Ihren Computer für die Arbeit mit NodeJS vorbereiten und den Scraper mit Axios und Cheerio erstellen.
Einführung in NodeJS
NodeJS ist keine andere Programmiersprache, sondern eine Art Umgebung, die es Ihnen ermöglicht, außerhalb des Browsers mit JavaScript zu arbeiten. Es hat den gleichen Basismotor wie Chrome – V8.
Wer sich bereits mit JavaScript im Frontend beschäftigt hat, wird also einen einfachen Einstieg finden.
Vereinfacht ausgedrückt handelt es sich bei Node.js um eine C++-Anwendung, die JavaScript-Code als Eingabe verwendet und ausführt.
Der Hauptvorteil von NodeJS besteht darin, dass Sie damit eine asynchrone Architektur in einem einzelnen Thread implementieren können. Darüber hinaus verfügt NodeJS dank einer aktiven Community über fertige Lösungen für alle Gelegenheiten, aber darauf gehen wir später noch ein.
Bereiten wir uns also auf das Schaben vor:
- Installieren Sie NodeJS.
- Lassen Sie uns NPM aktualisieren.
Um NodeJS zu installieren, besuchen Sie die offizielle Website und laden Sie die Installationsdatei herunter. Derzeit sind zwei Versionen verfügbar:
Version 16.17.1 LTS ist stabil und 18.9.1 ist die neueste. Die Wahl der Version liegt beim Benutzer und hat keinen Einfluss auf das Beispiel in diesem Artikel.
Überprüfen Sie nach dem Herunterladen und Installieren des Pakets, ob alles ordnungsgemäß funktioniert. Sie können dies über die Befehlszeile mit den folgenden Befehlen tun:
node -v
npm -vUm NPM zu aktualisieren, können Sie den folgenden Befehl ausführen:
npm install -g npmDanach können Sie mit der Arbeit mit NPM-Paketen beginnen.
NPM-Pakete oder Lösungen für alle Situationen
NPM (Node Package Manager) ist ein Standard-Paketmanager, mit dem jeder Benutzer Pakete vom npm-Cloud-Server herunterladen oder Pakete auf diese Server hochladen kann. Das bedeutet, dass jeder Benutzer, der eine JavaScript-Bibliothek oder ein Tool zur Ausführung seiner Aufgaben geschrieben hat, diese auf den Server hochladen kann, woraufhin jeder es hochladen kann.
Mit diesem Ansatz gibt es heute viele fertige NPM-Pakete und wenn Sie möchten, können Sie für fast jedes Problem oder jede Aufgabe eine fertige Lösung finden.
Um einen einfachen Scraper zu schreiben, benötigen wir zwei dieser Werkzeuge:
- Ein Tool, mit dem Sie eine Anfrage ausführen und den Seitencode abrufen können.
- Ein Tool, das den Quellcode verarbeitet und spezifische Daten abruft.
Versuchen wir zu entscheiden, welche Bibliotheken für uns besser sind.
Arbeiten Sie mit Anfragen
Es gibt zwei beliebte Bibliotheken zum Abrufen des Seitencodes und zum Senden von POST- und GET-Anfragen in NodeJS: Axios und Fetch. Obwohl Axios viele Mängel aufweist und Fetch eine relativ neue Bibliothek ist, die solche Fehler nicht aufweist, ist Axios immer noch beliebter. Und das alles, weil:
- Code mit Axios ist prägnanter.
- Die Axios-Bibliothek meldet Netzwerkfehler, die Fetch-API hingegen nicht.
- Axios kann den Fortschritt des Entladens von Daten überwachen, Fetch jedoch nicht.
Neben diesen beiden Bibliotheken sind auch Ky (ein kleiner und durchdachter HTTP-Client auf Basis von window.fetch) und Superagent (eine kleine HTTP-Client-Bibliothek auf Basis von XMLHttpRequest) erwähnenswert.
Wenn das Projekt klein ist und die letzten beiden Bibliotheken implementiert werden können, ist es besser, diese zu verwenden.
Parse-Bibliothek
Bisher ist Cheerio der beliebteste Parser, der den DOM-Baum der Seite erstellt und Ihnen eine bequeme Arbeit damit ermöglicht. Cheerio analysiert das Markup und stellt Funktionen zur Verarbeitung der empfangenen Daten bereit.
Als Analogon zu Cheerio können Sie Osmosis verwenden, das eine ähnliche Funktionalität hat, aber weniger Abhängigkeiten aufweist.
Ein Projekt erstellen und Axios hinzufügen
Wir werden also Axios und Cheerio verwenden. Lassen Sie uns ein Verzeichnis angeben und NPM darin initiieren. Gehen Sie zu dem Ordner, in dem sich Ihr Scraper befindet, und führen Sie die Befehlszeile in diesem Ordner aus. Geben Sie dann den Befehl ein:
npm init -yDadurch wird im Ordner eine package.json-Datei erstellt, die unser Projekt beschreibt und seine Abhängigkeiten angibt.
Kommen wir zum zentralen Teil der Erstellung eines Scrapers. Wir werden es auf der Beispielseite example.com betrachten. Mit Axios können Sie Anfragen stellen und Daten empfangen. Für dieses Projekt benötigen wir nur HTTP-GET-Anfragen.
Schreiben Sie die Abhängigkeit in die Befehlszeile:
npm install axiosVersuchen wir nun, den Seitencode abzurufen. Erstellen Sie dazu im selben Ordner eine index.js-Datei. Darin verbinden wir Axios, führen die Anfrage aus und zeigen sie auf dem Bildschirm an:
const axios = require('axios');
const url="https://example.com";
axios.get(url)
.then(response => {
console.log(response.data);
})
Außerdem werden wir am Ende einen Fehlerhandler hinzufügen, damit das Programm bei Auftreten eines Fehlers nicht unterbrochen wird, und ihn auf dem Bildschirm anzeigen:
.catch(error => {
console.log(error);
})Um das Projekt auszuführen, gehen Sie zur Befehlszeile und führen Sie den folgenden Befehl aus:
node index.jsDer Quellcode der Seite example.com wird auf dem Bildschirm angezeigt:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>Versuchen wir nun, nur den Titel im
-Tag zu erhalten.
Bearbeitung einer Anfrage bei Cheerio
Mit Cheerio können Sie Materialien analysieren, bei denen es sich um HTML- und XML-Markup handelt. Wir können es also verwenden, um spezifische Daten aus dem gerade erhaltenen Quellcode abzurufen.
Gehen wir zur Befehlszeile und fügen Abhängigkeiten hinzu:
npm install cheerioUnd fügen Sie es auch in die Indexdatei index.js ein:
const cheerio = require('cheerio');Nehmen wir an, dass wir mehr als einen Header haben können und alle erhalten möchten:
axios.get(url)
.then(({ data }) => {
const $ = cheerio.load(data);
const title = $('h1')
.map((_, titles) => {
const $titles = $(titles);
return $titles.text()
})
.toArray();
console.log(title)
});
Mithilfe von CSS-Selektoren können Sie komplexere Abfragen einrichten oder bestimmte Daten auswählen.
Beispiel vs. Realität
Unser Code funktionierte auf einer einfachen HTML-Seite, aber bei den meisten Websites ist die Struktur nicht statisch, sondern dynamisch. Wenn wir außerdem ständig die Seite durchsuchen, werden wir gesperrt oder angeboten, ein Captcha zu lösen. Ein so einfacher Schaber wird dem leider nicht gewachsen sein.
Um das erste Problem zu lösen, reicht es jedoch aus, Headless-Browser zu verwenden, um das zweite Problem zu lösen – Proxys, und um das dritte Problem zu lösen – Dienste zum Lösen von Captchas. Aber es gibt eine noch einfachere Lösung – die Verwendung der Web-Scraping-API, die all diese Schwierigkeiten löst.
Versuchen wir, die Homepage von medium.com zu erkunden und mithilfe der Web-Scraping-API und NodeJS die Artikeltitel daraus abzurufen. Um die API zu nutzen, registrieren Sie sich auf der Scrape-It.Cloud und kopieren Sie den API-Schlüssel aus Ihrem Konto. Wir werden es später verwenden.
Um zu verstehen, welche Selektoren die von uns benötigten Informationen enthalten, besuchen Sie die Website und die Entwicklertools oder DevTools (F12).
Wenn Sie noch nie mit DevTools gearbeitet haben, empfehlen wir Ihnen die Lektüre unseres Artikels: „5 Chrome DevTools Tipps & Tricks zum Scraping“.
Nachdem Sie DevTools aufgerufen haben, drücken Sie Umschalt+Strg+C, um ein Element auf der Seite auszuwählen und seinen Code anzuzeigen, und wählen Sie dann den Titel eines beliebigen Artikels aus.
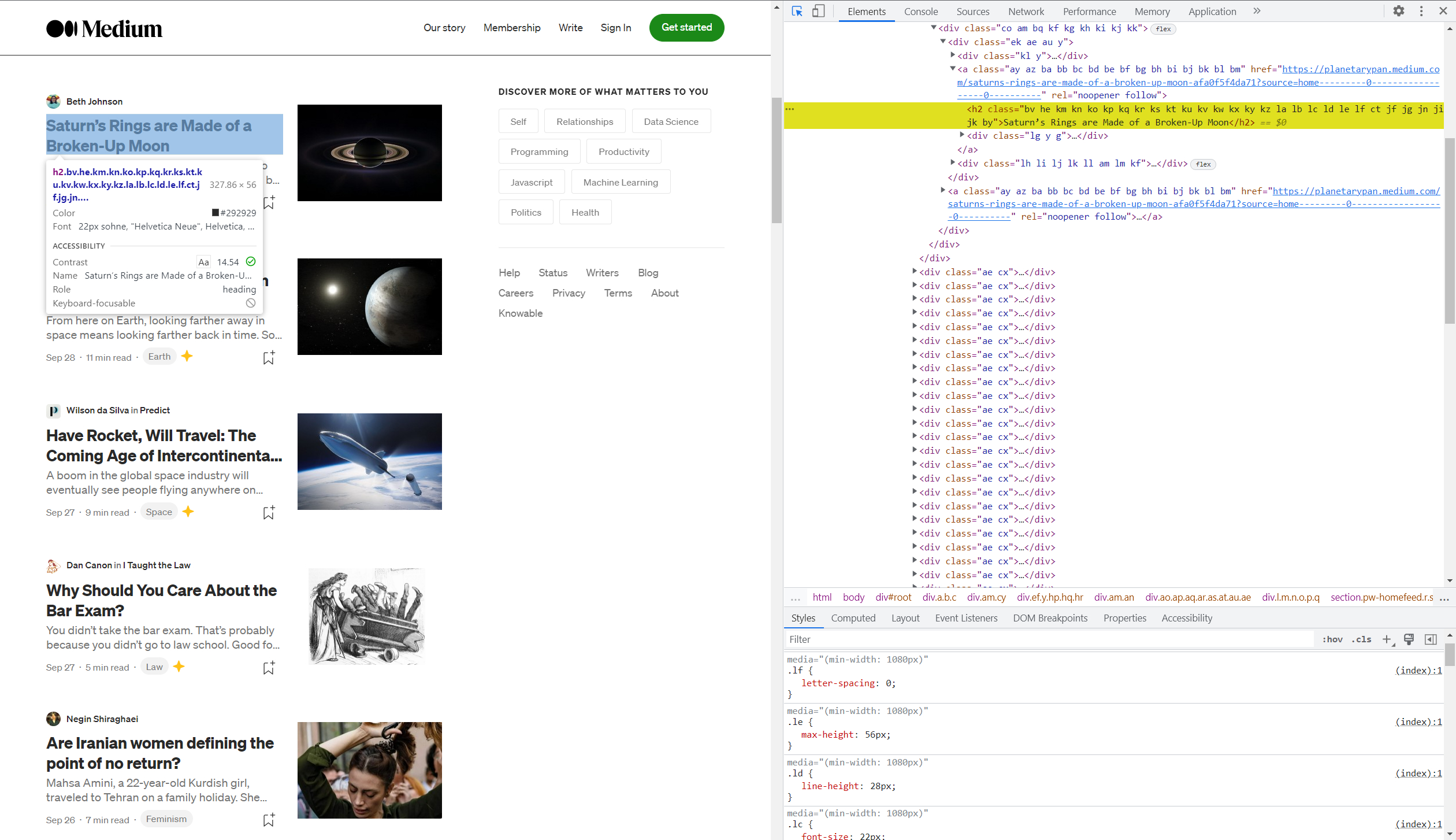
Der Code hebt dieses Element auf der rechten Seite des Fensters hervor. Großartig, jetzt gehen wir zur Seite scrape-it.cloud und gehen zur Registerkarte Web Scraping API. Wählen Sie im Request Builder NodeJS aus und erhalten Sie vorgefertigten Code für das Page Scraping.
Dies reicht jedoch nicht aus. Richten wir unsere Anfrage so ein, dass sie genau die Titel der Artikel zurückgibt, die im h2-Tag gespeichert sind. Dazu verwenden wir Extraktionsregeln.
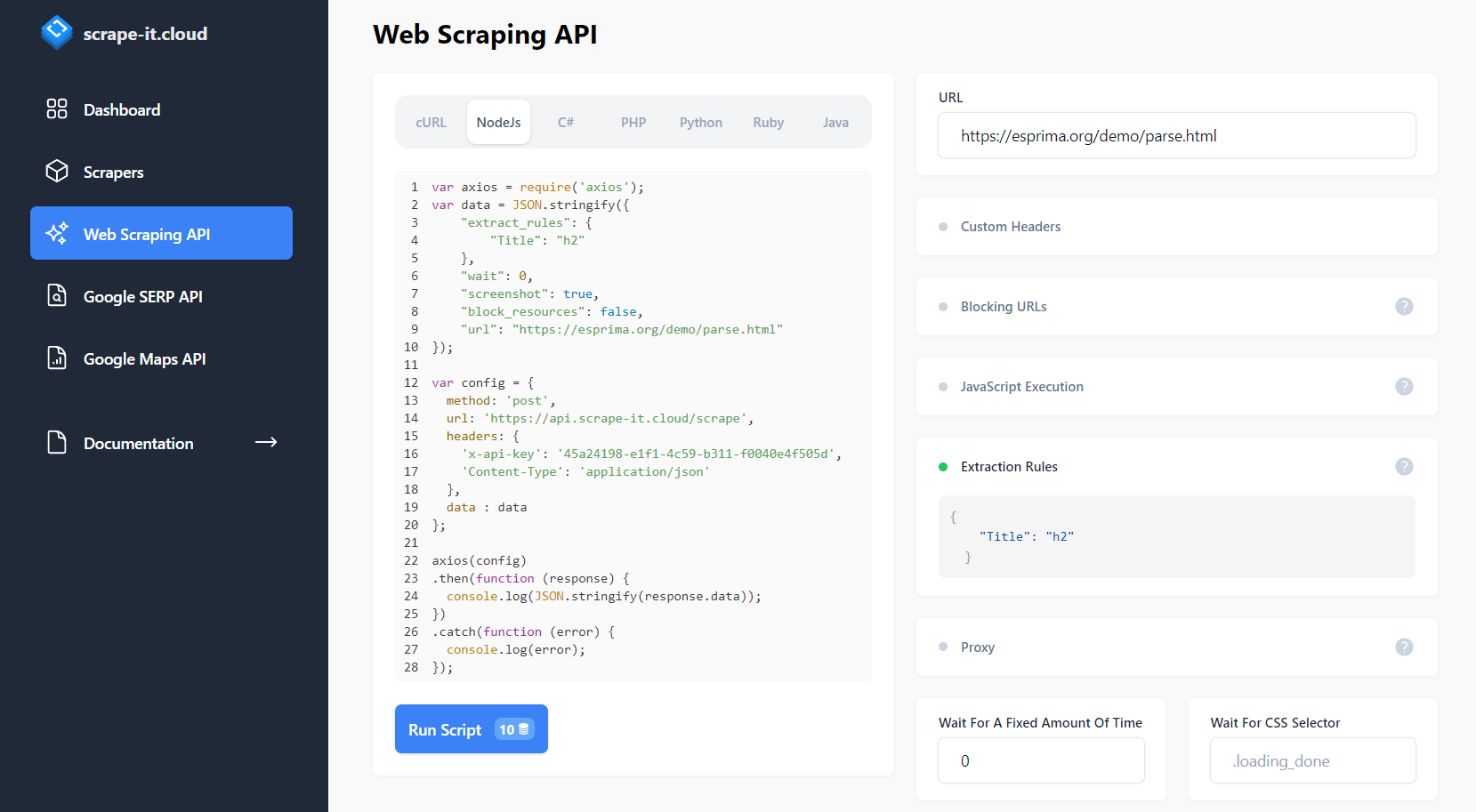
Wir können das resultierende Skript von der Site ausführen oder es in einer Datei speichern. Speichern wir es in einer Datei und ändern Sie die Ergebnisausgabezeile (Zeile 24) in den folgenden Code:
console.log(JSON.stringify(response.data.scrapingResult.extractedData.Title));Dies ist notwendig, um nur die Titel der Artikel anzuzeigen. Wenn wir es tun, erhalten wir die Liste:
(
"Saturn’s Rings are Made of a Broken-Up Moon",
"What does Earth look like from across the Universe?",
"Have Rocket, Will Travel: The Coming Age of Intercontinental Spaceflight",
"Why Should You Care About the Bar Exam?",
"Are Iranian women defining the point of no return?",
"Corn is in Nearly Everything We Eat. Does It Matter?",
"Health Care Roulette",
"America’s Brief Experiment With Universal Healthcare Is Ending",
"There is More than Meets the Eye in Patagonia’s Bold Activism",
"It’s What You See",
"How Civil Rights Groups are Pushing Back Against Amazon’s New Show",
"Why “Microhistories” Rock",
"How to Be a Tourist",
"You Don’t Feel My Pain",
"The Servitude Of Our Times",
"10 Mental Models for Learning Anything",
"The Joy of Repairing Laptops",
"Why Adnan Syed Is Free"
)Ein solches Scraping ist sicher und einfach und hilft, Blockaden zu vermeiden und dynamische Daten zu scrapen.
Fazit und Erkenntnisse
NodeJS ist ein sehr flexibles und benutzerfreundliches Daten-Scraping-Tool, mit dem Sie Daten von verschiedenen Websites schnell und effizient extrahieren können.
Vollständiger Beispielcode ohne API:
const axios = require('axios');
const cheerio = require('cheerio');
const url="https://example.com";
axios.get(url)
.then(({ data }) => {
const $ = cheerio.load(data);
const title = $('h1')
.map((_, titles) => {
const $titles = $(titles);
return $titles.text()
})
.toArray();
console.log(title)
});
Vollständiger Beispielcode mit API:
var axios = require('axios');
var data = JSON.stringify({
"extract_rules": {
"Title": "h2"
},
"wait": 0,
"screenshot": true,
"block_resources": false,
"url": "https://medium.com/"
});
var config = {
method: 'post',
url: 'https://api.scrape-it.cloud/scrape',
headers: {
'x-api-key': 'YOUR-API-KEY',
'Content-Type': 'application/json'
},
data : data
};
axios(config)
.then(function (response) {
console.log(response.data.scrapingResult.extractedData.Title);
})
.catch(function (error) {
console.log(error);
});Wenn Sie das Thema interessiert, können Sie in den Artikeln „Web Scraping mit node.js: So nutzen Sie die Leistungsfähigkeit von JavaScript“ und „So scrapen Sie Yelp mit NodeJS“ mehr erfahren.
