
Dalam tutorial ini, kami akan menunjukkan cara membuat web scraper menggunakan Puppeteer dan API ScraperAPI standar untuk menskalakan scraper kami tanpa diblokir.
Daftar Isi
TL;DR: Scraper Target.com lengkap
Bagi yang sedang terburu-buru, berikut skrip lengkap yang akan kita buat dalam tutorial ini:
<pre class="wp-block-syntaxhighlighter-code">
const puppeteer = require("puppeteer");
const cheerio = require("cheerio");
const Excel = require("exceljs");
const path = require("path");
const TARGET_DOT_COM_PAGE_URL = 'https://www.target.com/s?searchTerm=headphones&tref=typeahead%7Cterm%7Cheadphones%7C%7C%7Chistory';
const EXPORT_FILENAME = 'products.xlsx';
// ScraperAPI proxy configuration
PROXY_USERNAME = 'scraperapi';
PROXY_PASSWORD = '<API_KEY>'; // <-- enter your API_Key here
PROXY_SERVER = 'proxy-server.scraperapi.com';
PROXY_SERVER_PORT = '8001';
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const exportProductsInExcelFile = async (productsList) => {
const workbook = new Excel.Workbook();
const worksheet = workbook.addWorksheet('Headphones');
worksheet.columns = (
{ key: 'title', header: 'Title' },
{ key: 'brand', header: 'Brand' },
{ key: 'currentPrice', header: 'Current Price' },
{ key: 'regularPrice', header: 'Regular Price' },
{ key: 'averageRating', header: 'Average Rating' },
{ key: 'totalReviews', header: 'Total Reviews' },
{ key: 'link', header: 'Link' },
);
worksheet.getRow(1).font = {
bold: true,
size: 13,
};
productsList.forEach((product) => {
worksheet.addRow(product);
});
const exportFilePath = path.resolve(__dirname, EXPORT_FILENAME);
await workbook.xlsx.writeFile(exportFilePath);
};
const parseProductReview = (inputString) => {
const ratingRegex = /(\d+(\.\d+)?)/;
const reviewCountRegex = /(\d+) ratings/;
const ratingMatch = inputString.match(ratingRegex);
const reviewCountMatch = inputString.match(reviewCountRegex);
const rating = ratingMatch?.length > 0 ? parseFloat(ratingMatch(0)) : null;
const reviewCount = reviewCountMatch?.length > 1 ? parseInt(reviewCountMatch(1)) : null;
return { rating, reviewCount };
};
const webScraper = async () => {
const browser = await puppeteer.launch({
ignoreHTTPSErrors: true,
args: (
`--proxy-server=http://${PROXY_SERVER}:${PROXY_SERVER_PORT}`
)
});
const page = await browser.newPage();
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto(TARGET_DOT_COM_PAGE_URL, { timeout: 60000});
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe(aria-label="Reject all")');
await buttonConsentReject?.click();
await waitFor(3000);
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve()
}
}, 100);
});
});
const html = await page.content();
await browser.close();
const $ = cheerio.load(html);
const productList = ();
$(".dOpyUp").each((_, el) => {
const link = $(el).find("a.csOImU").attr('href');
const title = $(el).find('a.csOImU').text();
const brand = $(el).find('a.cnZxgy').text();
const currentPrice = $(el).find("span(data-test='current-price') span").text();
const regularPrice = $(el).find("span(data-test='comparison-price') span").text();
const reviews = $(el).find(".hMtWwx").text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
title,
brand,
currentPrice,
regularPrice,
averageRating: rating,
totalReviews: reviewCount,
link,
});
});
console.log(`Number of items extracted:`, productList.length);
await exportProductsInExcelFile(productList);
console.log('The products has been successfully exported in the Excel file!');
};
void webScraper();
</pre>
Apakah Anda ingin memahami setiap baris kode web scraper ini? Mari kita membangunnya kembali dari awal!
Mengikis data produk Target.com
Sebagai kasus penggunaan untuk menghapus produk Target.com, kami akan menulis web scraper di Node.js yang menemukan headphone dan mengekstrak informasi berikut untuk setiap produk:
- Keterangan
- Harga
- Penilaian rata-rata
- Peringkat Keseluruhan
- Estimasi pengiriman
- Tautan produk
Scraper web mengekspor data yang diekstraksi ke file Excel untuk digunakan atau dianalisis lebih lanjut.
persyaratan
Untuk mengikuti tutorial ini, Anda harus menginstal alat berikut di komputer Anda:
Langkah 1: Siapkan proyek
Mari buat folder dengan kode sumber scraper Target.com
mkdir target-dot-com-scraper
Masuk ke folder dan inisialisasi proyek Node.js baru
cd target-dot-com-scraper
npm init -y
Perintah kedua di atas membuatnya paket.json File dalam folder.
Selanjutnya, buat file indeks.js di mana kita akan menulis scraper kita; Biarkan kosong untuk saat ini.
Langkah 2: Instal dependensi
Untuk membangun web scraper Target.com kita memerlukan tiga paket Node.js berikut:
- Dalang – untuk memuat situs web, melakukan pencarian produk, menggulir halaman untuk memuat lebih banyak hasil, dan mengunduh konten HTML.
- Cheerio – untuk mengekstrak informasi dari HTML yang diunduh dari permintaan Axios.
- ExcelJS – untuk menulis data yang diekstraksi ke dalam buku kerja Excel.
Jalankan perintah berikut untuk menginstal paket-paket ini:
npm install puppeteer cheerio exceljs
Langkah 3: Identifikasi pemilih DOM yang ingin Anda targetkan
Navigasi ke https://www.target.com; Jenis "Headphone" di bilah pencarian dan tekan Enter.
Saat hasil pencarian muncul, periksa halaman untuk melihat struktur HTML dan identifikasi pemilih DOM yang terkait dengan tag HTML yang membungkus informasi yang ingin kita ekstrak.
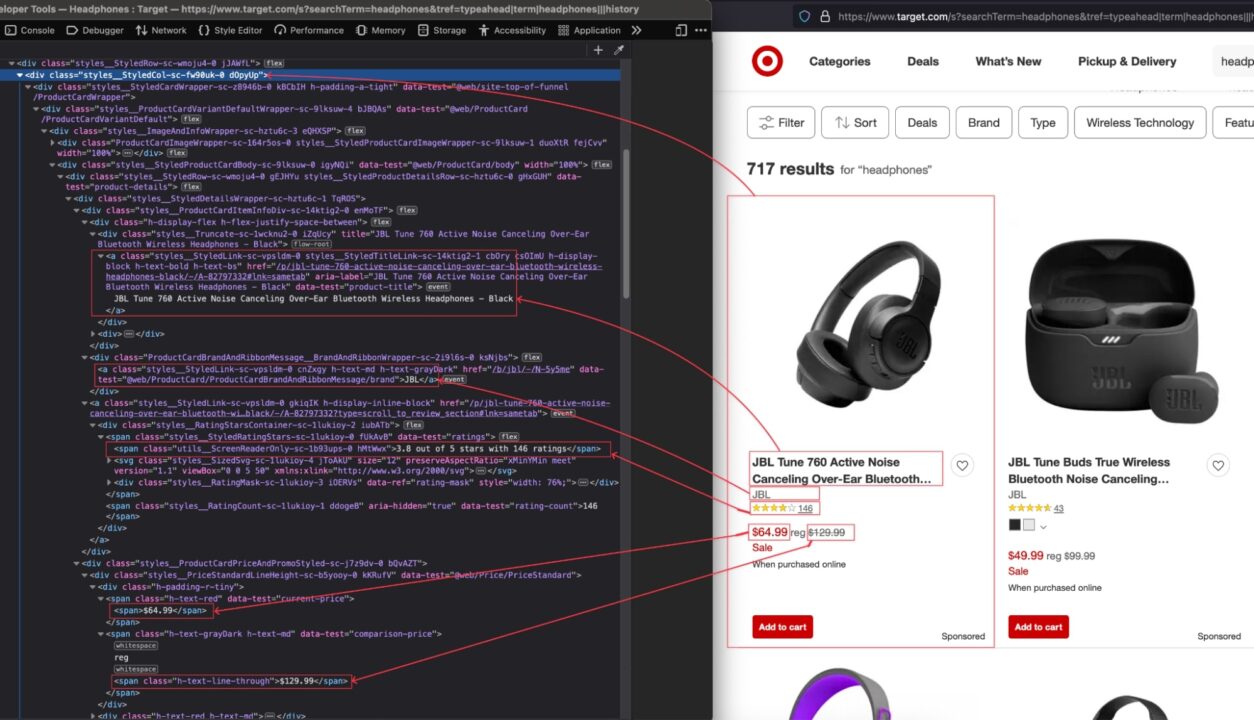
Pada gambar di atas, berikut adalah semua pemilih DOM yang akan ditargetkan oleh web scraper untuk mengekstrak informasi:
| informasi | pemilih DOM |
| Judul produk | .d0pyUp a.csOImU |
| merek | .d0pyUp dan.cnZxgy |
| Harga sekarang | .d0pyUp “span(data-test='harga saat ini') span” |
| Harga normal | .d0pyUp “span(data-test=perbandingan-harga') span” |
| Peringkat dan ulasan | .d0pyUp .hMtWwx |
| Tautan dari Target.com | .d0pyUp a.csOImU |
Berhati-hatilah saat menulis pemilih karena kesalahan ejaan akan mencegah skrip mengambil nilai yang benar.
Langkah 4: Jelajahi halaman produk Target.com
Agar URL dapat dikikis, salin URL tersebut ke bilah alamat bilah browser Anda. Ini adalah URL untuk pencarian “headphone”.
Buka ini indeks.js file dan tambahkan kode berikut:
const puppeteer = require("puppeteer");
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const webScraper = async () => {
const browser = await puppeteer.launch({
headless: false,
args: ("--disabled-setuid-sandbox", "--no-sandbox"),
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto("https://www.google.com/maps/search/bookshop/@36.6092093,-129.3569836,6z/data=!3m1!4b1" , {
waitUntil: 'domcontentloaded',
timeout: 60000
});
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe(aria-label="Reject all")');
await buttonConsentReject?.click();
await waitFor(5000);
};
void webScraper();
Kode di atas melakukan hal berikut:
- Buat instance browser dengan mode tanpa kepala dinonaktifkan. Saat membuat scraper, akan sangat membantu jika Anda melihat interaksi di halaman dan mendapatkan umpan balik. Kami akan menonaktifkannya saat scraper siap diproduksi.
- Tentukan permintaannya
User-AgentOleh karena itu, Target.com memperlakukan kami bukan sebagai bot, tetapi sebagai browser sungguhan. Kemudian navigasikan ke situs web. - Di sebagian besar negara Eropa, halaman persetujuan ditampilkan sebelum dialihkan ke URL; Kami mengklik tombol untuk menolak semuanya dan menunggu tiga detik hingga halaman web dimuat sepenuhnya.
Langkah 5: Gulir ke samping untuk memuat semua produk
Saat halaman dimuat, hanya empat produk yang ditampilkan; Anda harus menggulir ke bagian bawah halaman untuk memuat lebih banyak produk. Kita perlu menerapkan ini di bawah untuk mengambil semua produk di halaman, bukan empat produk pertama.
Dalam indeks.js Di file, tambahkan kode berikut tepat setelah cuplikan yang menunggu halaman dimuat sepenuhnya:
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve()
}
}, 100);
});
});
const html = await page.content();
await browser.close();
Kode di atas bergulir ke halaman bawah; Setelah Anda mencapai halaman bawah, unduh konten HTML halaman tersebut dan tutup browser.
Langkah 6: Ekstrak informasi dari HTML
Sekarang kita memiliki kode HTML halaman tersebut, kita perlu menguraikannya menggunakan Cheerio untuk menavigasi dan mengekstrak semua informasi yang kita inginkan.
Cheerio menyediakan fungsionalitas untuk memuat teks HTML dan kemudian menavigasi struktur untuk mengekstrak informasi menggunakan pemilih DOM.
Kode berikut mengulang setiap elemen, mengekstrak informasi, dan mengembalikan array yang berisi semua produk.
const cheerio = require("cheerio")
// Puppeteer scraping code here
const $ = cheerio.load(html);
const productList = ();
$(".dOpyUp").each((_, el) => {
const link = $(el).find("a.csOImU").attr('href');
const title = $(el).find('a.csOImU').text();
const brand = $(el).find('a.cnZxgy').text();
const currentPrice = $(el).find("span(data-test='current-price') span").text();
const regularPrice = $(el).find("span(data-test='comparison-price') span").text();
const reviews = $(el).find(".hMtWwx").text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
title,
brand,
currentPrice,
regularPrice,
averageRating: rating,
totalReviews: reviewCount,
link,
});
});
console.log(`Number of items extracted:`, productList.length);
console.log(productList);
Langkah 7: Simpan data yang tergores ke file Excel
Menyimpan data yang diekstraksi dalam file Excel sangat bagus untuk menggunakan data untuk tujuan lain, seperti analisis data.
Kami menggunakan paket ExcelJS yang kami instal sebelumnya untuk membuat buku kerja, memetakan properti Produk ke kolom di buku kerja, dan terakhir membuat file di disk.
Mari perbarui ini indeks.js file untuk menambahkan kode berikut:
// Existing imports here…
const path = require("path");
const EXPORT_FILENAME = 'products.xlsx';
const exportProductsInExcelFile = async (productsList) => {
const workbook = new Excel.Workbook();
const worksheet = workbook.addWorksheet('Headphones');
worksheet.columns = (
{ key: 'title', header: 'Title' },
{ key: 'brand', header: 'Brand' },
{ key: 'currentPrice', header: 'Current Price' },
{ key: 'regularPrice', header: 'Regular Price' },
{ key: 'averageRating', header: 'Average Rating' },
{ key: 'totalReviews', header: 'Total Reviews' },
{ key: 'link', header: 'Link' },
);
worksheet.getRow(1).font = {
bold: true,
size: 13,
};
productsList.forEach((product) => {
worksheet.addRow(product);
});
const exportFilePath = path.resolve(__dirname, EXPORT_FILENAME);
await workbook.xlsx.writeFile(exportFilePath);
};
// Existing code here
Langkah 8: Uji implementasinya
Pada langkah ini kami telah menyiapkan segalanya untuk menjalankan web scraper kami. Berikut kode lengkap filenya:
const puppeteer = require("puppeteer");
const cheerio = require("cheerio");
const Excel = require("exceljs");
const path = require("path");
const TARGET_DOT_COM_PAGE_URL = 'https://www.target.com/s?searchTerm=headphones&tref=typeahead%7Cterm%7Cheadphones%7C%7C%7Chistory';
const EXPORT_FILENAME = 'products.xlsx';
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const exportProductsInExcelFile = async (productsList) => {
const workbook = new Excel.Workbook();
const worksheet = workbook.addWorksheet('Headphones');
worksheet.columns = (
{ key: 'title', header: 'Title' },
{ key: 'brand', header: 'Brand' },
{ key: 'currentPrice', header: 'Current Price' },
{ key: 'regularPrice', header: 'Regular Price' },
{ key: 'averageRating', header: 'Average Rating' },
{ key: 'totalReviews', header: 'Total Reviews' },
{ key: 'link', header: 'Link' },
);
worksheet.getRow(1).font = {
bold: true,
size: 13,
};
productsList.forEach((product) => {
worksheet.addRow(product);
});
const exportFilePath = path.resolve(__dirname, EXPORT_FILENAME);
await workbook.xlsx.writeFile(exportFilePath);
};
const webScraper = async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto(TARGET_DOT_COM_PAGE_URL);
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe(aria-label="Reject all")');
await buttonConsentReject?.click();
await waitFor(3000);
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve()
}
}, 100);
});
});
const html = await page.content();
await browser.close();
const $ = cheerio.load(html);
const productList = ();
$(".dOpyUp").each((_, el) => {
const link = $(el).find("a.csOImU").attr('href');
const title = $(el).find('a.csOImU').text();
const brand = $(el).find('a.cnZxgy').text();
const currentPrice = $(el).find("span(data-test='current-price') span").text();
const regularPrice = $(el).find("span(data-test='comparison-price') span").text();
const reviews = $(el).find(".hMtWwx").text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
title,
brand,
currentPrice,
regularPrice,
averageRating: rating,
totalReviews: reviewCount,
link,
});
});
console.log(`Number of items extracted:`, productList.length);
await exportProductsInExcelFile(productList);
console.log('The products has been successfully exported in the Excel file!');
};
void webScraper();
Jalankan kode menggunakan perintah node index.jsdan nikmati hasilnya:
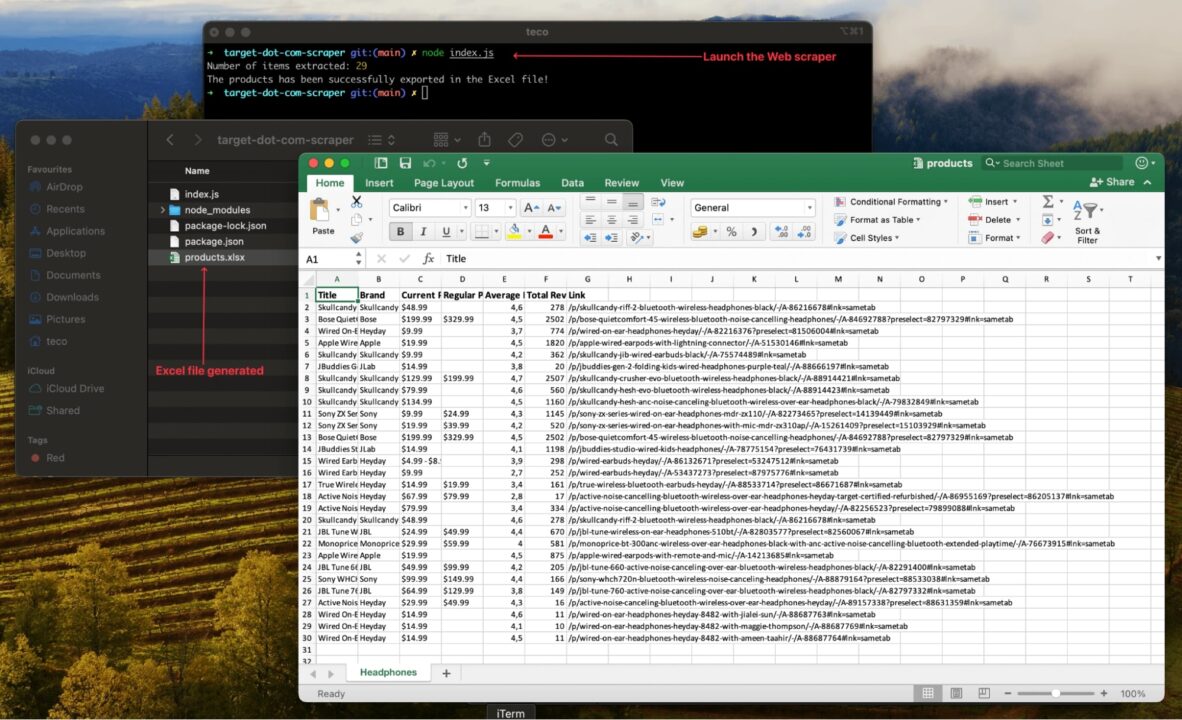
Peningkatan pengikis web
Pengikis web berfungsi untuk satu URL dan satu produk; Untuk membuat catatan yang relevan, Anda harus melakukan hal berikut:
- Kikis lebih banyak produk untuk mendapatkan variasi yang luas
- Kikis data secara teratur agar selalu diperbarui dengan pasar
Anda perlu memperbarui web scraper untuk memproses banyak URL secara bersamaan. Namun, hal ini menimbulkan banyak tantangan karena situs web e-niaga seperti target.com memiliki metode anti-scraping untuk mencegah web scraping yang intensif.
Misalnya, mengirimkan banyak permintaan dalam satu detik menggunakan alamat IP yang sama dapat mengakibatkan Anda diblokir dari server.
Mode Proxy ScraperAPI adalah alat yang tepat untuk mengatasi tantangan ini karena memberi Anda akses ke kumpulan proxy berkualitas tinggi, secara teratur membersihkan proxy yang terbakar, membuat sistem untuk merotasi proxy ini, menangani CAPTCHA, menetapkan header yang sesuai, dan banyak lagi Sistem diciptakan untuk mengatasi segala hambatan.