
In diesem Tutorial zeigen wir Ihnen, wie Sie mit Puppeteer und der Standard-API von ScraperAPI einen Web-Scraper erstellen, um unseren Scraper zu skalieren, ohne blockiert zu werden.
TL;DR: Vollständiger Target.com-Scraper
Für diejenigen, die es eilig haben, ist hier das vollständige Skript, das wir in diesem Tutorial erstellen werden:
<pre class="wp-block-syntaxhighlighter-code">
const puppeteer = require("puppeteer");
const cheerio = require("cheerio");
const Excel = require("exceljs");
const path = require("path");
const TARGET_DOT_COM_PAGE_URL = 'https://www.target.com/s?searchTerm=headphones&tref=typeahead%7Cterm%7Cheadphones%7C%7C%7Chistory';
const EXPORT_FILENAME = 'products.xlsx';
// ScraperAPI proxy configuration
PROXY_USERNAME = 'scraperapi';
PROXY_PASSWORD = '<API_KEY>'; // <-- enter your API_Key here
PROXY_SERVER = 'proxy-server.scraperapi.com';
PROXY_SERVER_PORT = '8001';
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const exportProductsInExcelFile = async (productsList) => {
const workbook = new Excel.Workbook();
const worksheet = workbook.addWorksheet('Headphones');
worksheet.columns = (
{ key: 'title', header: 'Title' },
{ key: 'brand', header: 'Brand' },
{ key: 'currentPrice', header: 'Current Price' },
{ key: 'regularPrice', header: 'Regular Price' },
{ key: 'averageRating', header: 'Average Rating' },
{ key: 'totalReviews', header: 'Total Reviews' },
{ key: 'link', header: 'Link' },
);
worksheet.getRow(1).font = {
bold: true,
size: 13,
};
productsList.forEach((product) => {
worksheet.addRow(product);
});
const exportFilePath = path.resolve(__dirname, EXPORT_FILENAME);
await workbook.xlsx.writeFile(exportFilePath);
};
const parseProductReview = (inputString) => {
const ratingRegex = /(\d+(\.\d+)?)/;
const reviewCountRegex = /(\d+) ratings/;
const ratingMatch = inputString.match(ratingRegex);
const reviewCountMatch = inputString.match(reviewCountRegex);
const rating = ratingMatch?.length > 0 ? parseFloat(ratingMatch(0)) : null;
const reviewCount = reviewCountMatch?.length > 1 ? parseInt(reviewCountMatch(1)) : null;
return { rating, reviewCount };
};
const webScraper = async () => {
const browser = await puppeteer.launch({
ignoreHTTPSErrors: true,
args: (
`--proxy-server=http://${PROXY_SERVER}:${PROXY_SERVER_PORT}`
)
});
const page = await browser.newPage();
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto(TARGET_DOT_COM_PAGE_URL, { timeout: 60000});
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe(aria-label="Reject all")');
await buttonConsentReject?.click();
await waitFor(3000);
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve()
}
}, 100);
});
});
const html = await page.content();
await browser.close();
const $ = cheerio.load(html);
const productList = ();
$(".dOpyUp").each((_, el) => {
const link = $(el).find("a.csOImU").attr('href');
const title = $(el).find('a.csOImU').text();
const brand = $(el).find('a.cnZxgy').text();
const currentPrice = $(el).find("span(data-test='current-price') span").text();
const regularPrice = $(el).find("span(data-test='comparison-price') span").text();
const reviews = $(el).find(".hMtWwx").text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
title,
brand,
currentPrice,
regularPrice,
averageRating: rating,
totalReviews: reviewCount,
link,
});
});
console.log(`Number of items extracted:`, productList.length);
await exportProductsInExcelFile(productList);
console.log('The products has been successfully exported in the Excel file!');
};
void webScraper();
</pre>
Möchten Sie jede Codezeile dieses Web Scrapers verstehen? Lass es uns von Grund auf neu aufbauen!
Scraping von Target.com-Produktdaten
Als Anwendungsfall für das Scraping von Target.com-Produkten schreiben wir einen Web-Scraper in Node.js, der Kopfhörer findet und die folgenden Informationen für jedes Produkt extrahiert:
- Beschreibung
- Preis
- Durchschnittliche Bewertung
- Gesamtbewertungen
- Liefervoranschlag
- Produktlink
Der Web Scraper exportiert die extrahierten Daten in eine Excel-Datei zur weiteren Verwendung oder Analyse.
Voraussetzungen
Um diesem Tutorial folgen zu können, müssen diese Tools auf Ihrem Computer installiert sein:
Schritt 1: Richten Sie das Projekt ein
Erstellen wir einen Ordner mit dem Quellcode des Target.com-Scrapers
mkdir target-dot-com-scraper
Geben Sie den Ordner ein und initialisieren Sie ein neues Node.js-Projekt
cd target-dot-com-scraper
npm init -y
Der zweite Befehl oben erstellt eine package.json Datei im Ordner.
Als nächstes erstellen Sie eine Datei index.js in dem wir unseren Schaber schreiben werden; Lassen Sie es vorerst leer.
Schritt 2: Installieren Sie die Abhängigkeiten
Um den Target.com Web Scraper zu erstellen, benötigen wir diese drei Node.js-Pakete:
- Puppenspieler – zum Laden der Website, zum Durchführen von Produktsuchen, zum Scrollen der Seite, um weitere Ergebnisse zu laden, und zum Herunterladen des HTML-Inhalts.
- Cheerio – um die Informationen aus dem HTML zu extrahieren, das von der Axios-Anfrage heruntergeladen wurde.
- ExcelJS – um die extrahierten Daten in eine Excel-Arbeitsmappe zu schreiben.
Führen Sie den folgenden Befehl aus, um diese Pakete zu installieren:
npm install puppeteer cheerio exceljs
Schritt 3: Identifizieren Sie die DOM-Selektoren, auf die Sie abzielen möchten
Navigieren Sie zu https://www.target.com; Typ „Kopfhörer“ in der Suchleiste ein und drücken Sie die Eingabetaste.
Wenn das Suchergebnis angezeigt wird, überprüfen Sie die Seite, um die HTML-Struktur anzuzeigen und den DOM-Selektor zu identifizieren, der mit dem HTML-Tag verknüpft ist, der die Informationen umschließt, die wir extrahieren möchten.
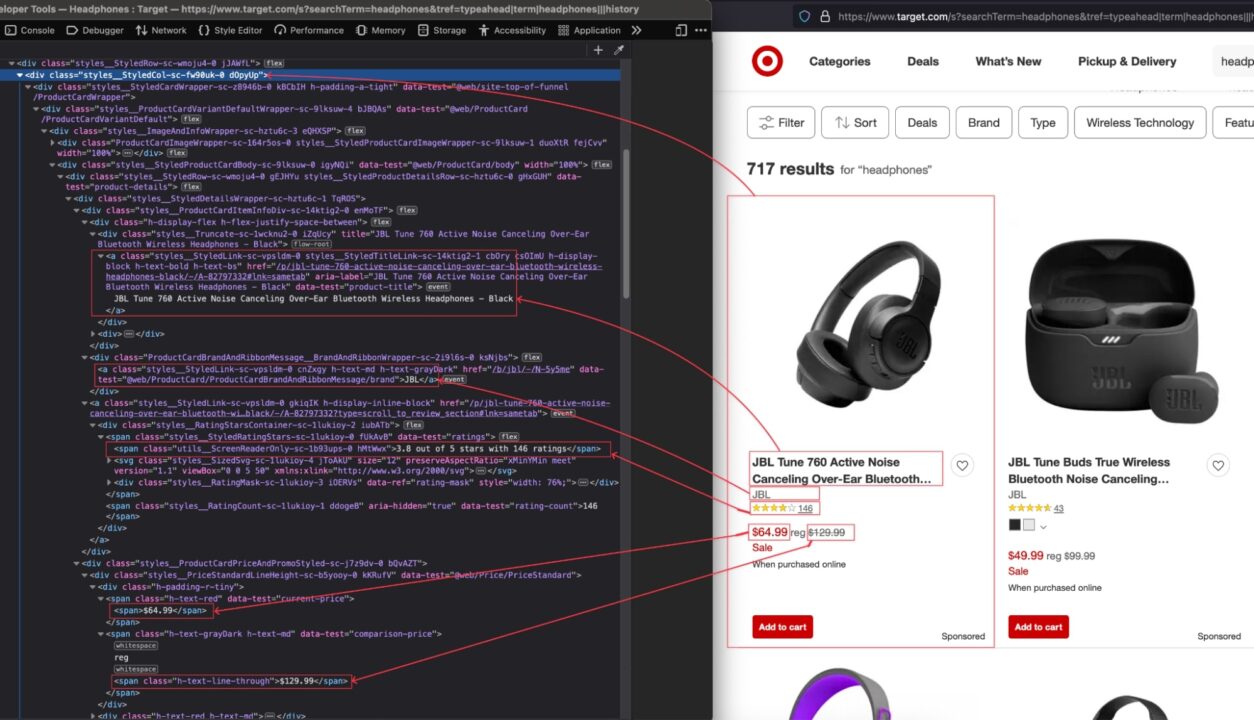
Im obigen Bild sind hier alle DOM-Selektoren aufgeführt, auf die der Web Scraper abzielt, um die Informationen zu extrahieren:
| Information | DOM-Selektor |
| Titel des Produkts | .d0pyUp a.csOImU |
| Marke | .d0pyUp a.cnZxgy |
| Derzeitiger Preis | .d0pyUp „span(data-test='current-price') span“ |
| Regulärer Preis | .d0pyUp „span(data-test=comparison-price') span“ |
| Bewertung und Rezensionen | .d0pyUp .hMtWwx |
| Link von Target.com | .d0pyUp a.csOImU |
Seien Sie beim Schreiben des Selektors vorsichtig, da ein Rechtschreibfehler verhindert, dass das Skript den richtigen Wert abruft.
Schritt 4: Durchsuchen Sie die Produktseite von Target.com
Um die URL zum Scrapen abzurufen, kopieren Sie die URL in die Adressleiste Ihrer Browserzeile. Dies ist die URL für die Suche „Kopfhörer“.
Öffne das index.js Datei und fügen Sie den folgenden Code hinzu:
const puppeteer = require("puppeteer");
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const webScraper = async () => {
const browser = await puppeteer.launch({
headless: false,
args: ("--disabled-setuid-sandbox", "--no-sandbox"),
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto("https://www.google.com/maps/search/bookshop/@36.6092093,-129.3569836,6z/data=!3m1!4b1" , {
waitUntil: 'domcontentloaded',
timeout: 60000
});
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe(aria-label="Reject all")');
await buttonConsentReject?.click();
await waitFor(5000);
};
void webScraper();
Der obige Code bewirkt Folgendes:
- Erstellen Sie eine Browserinstanz mit deaktiviertem Headless-Modus. Beim Erstellen Ihres Scrapers ist es hilfreich, die Interaktion auf der Seite anzuzeigen und eine Feedbackschleife zu haben. Wir werden es deaktivieren, wenn der Scraper produktionsbereit ist.
- Definieren Sie die Anfrage
User-AgentDaher behandelt uns Target.com nicht als Bot, sondern als echten Browser. Navigieren Sie dann zur Webseite. - In den meisten europäischen Ländern wird vor der Weiterleitung zur URL eine Seite mit der Bitte um Einwilligung angezeigt; Wir klicken auf die Schaltfläche, um alles abzulehnen, und warten drei Sekunden, bis die Webseite vollständig geladen ist.
Schritt 5: Führen Sie einen Seitenscroll durch, um alle Produkte zu laden
Beim Laden der Seite werden nur vier Produkte angezeigt; Sie müssen bis zum Ende der Seite scrollen, um weitere Produkte zu laden. Wir müssen dies unten implementieren, um alle Produkte auf der Seite anstelle der ersten vier abzurufen.
Im index.js Fügen Sie in der Datei den folgenden Code direkt nach dem Snippet ein, das darauf wartet, dass die Seite vollständig geladen wird:
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve()
}
}, 100);
});
});
const html = await page.content();
await browser.close();
Der obige Code führt den Bildlauf bis zur unteren Seite durch; Sobald Sie die unterste Seite erreicht haben, laden Sie den HTML-Inhalt der Seite herunter und schließen Sie die Browserinstanz.
Schritt 6: Informationen aus dem HTML extrahieren
Da wir nun den HTML-Code der Seite haben, müssen wir ihn mit Cheerio analysieren, um darin zu navigieren und alle gewünschten Informationen zu extrahieren.
Cheerio bietet Funktionen zum Laden von HTML-Text und zum anschließenden Navigieren durch die Struktur, um mithilfe der DOM-Selektoren Informationen zu extrahieren.
Der folgende Code durchläuft jedes Element, extrahiert die Informationen und gibt ein Array zurück, das alle Produkte enthält.
const cheerio = require("cheerio")
// Puppeteer scraping code here
const $ = cheerio.load(html);
const productList = ();
$(".dOpyUp").each((_, el) => {
const link = $(el).find("a.csOImU").attr('href');
const title = $(el).find('a.csOImU').text();
const brand = $(el).find('a.cnZxgy').text();
const currentPrice = $(el).find("span(data-test='current-price') span").text();
const regularPrice = $(el).find("span(data-test='comparison-price') span").text();
const reviews = $(el).find(".hMtWwx").text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
title,
brand,
currentPrice,
regularPrice,
averageRating: rating,
totalReviews: reviewCount,
link,
});
});
console.log(`Number of items extracted:`, productList.length);
console.log(productList);
Schritt 7: Speichern Sie die Scraped-Daten in einer Excel-Datei
Das Speichern der extrahierten Daten in einer Excel-Datei eignet sich hervorragend für die Verwendung der Daten für andere Zwecke, beispielsweise für die Datenanalyse.
Wir verwenden das Paket ExcelJS, das wir zuvor installiert haben, um eine Arbeitsmappe zu erstellen, die Produkteigenschaft einer Spalte in der Arbeitsmappe zuzuordnen und schließlich die Datei auf der Festplatte zu erstellen.
Lassen Sie uns das aktualisieren index.js Datei, um den folgenden Code hinzuzufügen:
// Existing imports here…
const path = require("path");
const EXPORT_FILENAME = 'products.xlsx';
const exportProductsInExcelFile = async (productsList) => {
const workbook = new Excel.Workbook();
const worksheet = workbook.addWorksheet('Headphones');
worksheet.columns = (
{ key: 'title', header: 'Title' },
{ key: 'brand', header: 'Brand' },
{ key: 'currentPrice', header: 'Current Price' },
{ key: 'regularPrice', header: 'Regular Price' },
{ key: 'averageRating', header: 'Average Rating' },
{ key: 'totalReviews', header: 'Total Reviews' },
{ key: 'link', header: 'Link' },
);
worksheet.getRow(1).font = {
bold: true,
size: 13,
};
productsList.forEach((product) => {
worksheet.addRow(product);
});
const exportFilePath = path.resolve(__dirname, EXPORT_FILENAME);
await workbook.xlsx.writeFile(exportFilePath);
};
// Existing code here
Schritt 8: Testen Sie die Implementierung
In diesem Schritt haben wir alles bereit, um unseren Web Scraper auszuführen. Hier ist der vollständige Code der Datei:
const puppeteer = require("puppeteer");
const cheerio = require("cheerio");
const Excel = require("exceljs");
const path = require("path");
const TARGET_DOT_COM_PAGE_URL = 'https://www.target.com/s?searchTerm=headphones&tref=typeahead%7Cterm%7Cheadphones%7C%7C%7Chistory';
const EXPORT_FILENAME = 'products.xlsx';
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const exportProductsInExcelFile = async (productsList) => {
const workbook = new Excel.Workbook();
const worksheet = workbook.addWorksheet('Headphones');
worksheet.columns = (
{ key: 'title', header: 'Title' },
{ key: 'brand', header: 'Brand' },
{ key: 'currentPrice', header: 'Current Price' },
{ key: 'regularPrice', header: 'Regular Price' },
{ key: 'averageRating', header: 'Average Rating' },
{ key: 'totalReviews', header: 'Total Reviews' },
{ key: 'link', header: 'Link' },
);
worksheet.getRow(1).font = {
bold: true,
size: 13,
};
productsList.forEach((product) => {
worksheet.addRow(product);
});
const exportFilePath = path.resolve(__dirname, EXPORT_FILENAME);
await workbook.xlsx.writeFile(exportFilePath);
};
const webScraper = async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto(TARGET_DOT_COM_PAGE_URL);
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe(aria-label="Reject all")');
await buttonConsentReject?.click();
await waitFor(3000);
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve()
}
}, 100);
});
});
const html = await page.content();
await browser.close();
const $ = cheerio.load(html);
const productList = ();
$(".dOpyUp").each((_, el) => {
const link = $(el).find("a.csOImU").attr('href');
const title = $(el).find('a.csOImU').text();
const brand = $(el).find('a.cnZxgy').text();
const currentPrice = $(el).find("span(data-test='current-price') span").text();
const regularPrice = $(el).find("span(data-test='comparison-price') span").text();
const reviews = $(el).find(".hMtWwx").text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
title,
brand,
currentPrice,
regularPrice,
averageRating: rating,
totalReviews: reviewCount,
link,
});
});
console.log(`Number of items extracted:`, productList.length);
await exportProductsInExcelFile(productList);
console.log('The products has been successfully exported in the Excel file!');
};
void webScraper();
Führen Sie den Code mit dem Befehl aus node index.jsund freuen Sie sich über das Ergebnis:
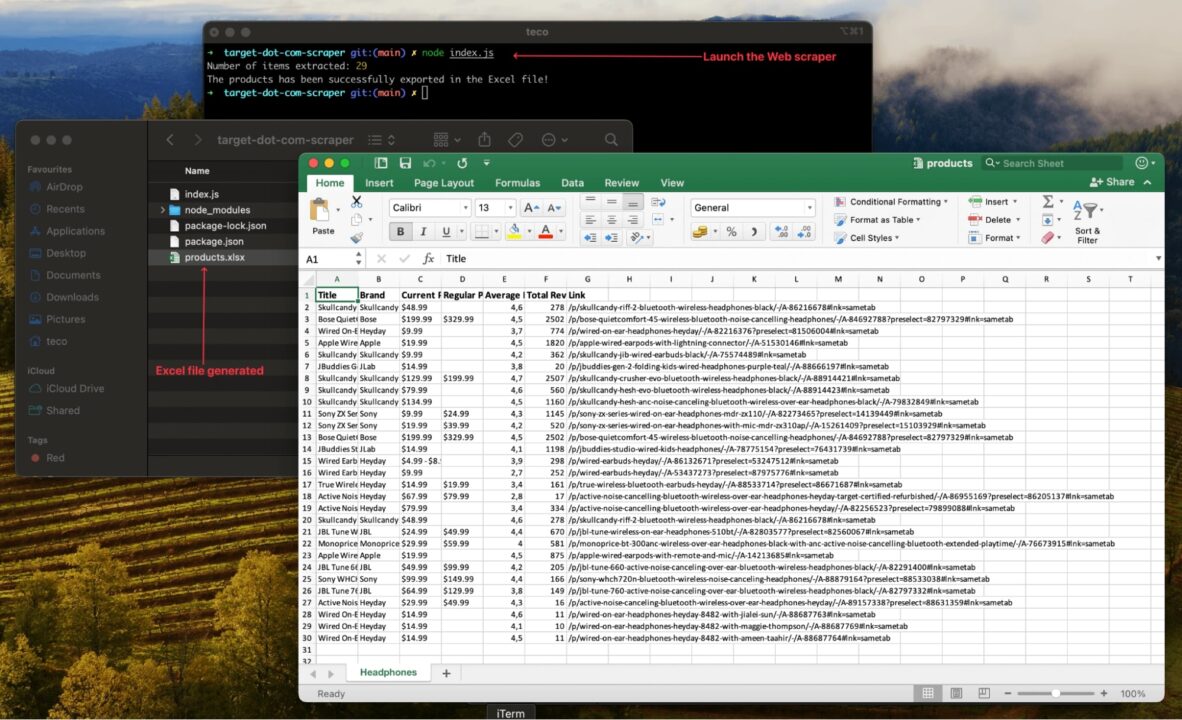
Verbesserung des Web Scrapers
Der Web Scraper funktioniert für eine einzelne URL und ein einzelnes Produkt; Um einen relevanten Datensatz zu erstellen, müssen Sie Folgendes tun:
- Kratzen Sie mehr Produkte ab, um eine große Vielfalt zu erhalten
- Scrapen Sie die Daten regelmäßig, um sie mit dem Markt auf dem Laufenden zu halten
Sie müssen den Web Scraper aktualisieren, um viele URLs gleichzeitig verarbeiten zu können. Dies bringt jedoch viele Herausforderungen mit sich, da E-Commerce-Websites wie target.com über Anti-Scraping-Methoden verfügen, um intensives Web Scraping zu verhindern.
Wenn Sie beispielsweise mehrere Anfragen in einer Sekunde mit derselben IP-Adresse senden, kann dies dazu führen, dass Sie vom Server gesperrt werden.
Der Proxy-Modus von ScraperAPI ist das richtige Tool, um diese Herausforderungen zu meistern, da er Ihnen Zugriff auf einen Pool hochwertiger Proxys bietet, verbrannte Proxys regelmäßig bereinigt, ein System zum Rotieren dieser Proxys erstellt, CAPTCHAs verarbeitet, geeignete Header festlegt und viele weitere Systeme erstellt um etwaige Hindernisse zu überwinden.
