
Dalam tutorial ini, Anda akan mempelajari semua yang perlu Anda ketahui untuk mengekstrak data dari Walmart secara efektif.
Daftar Isi
TL;DR: Pengikis Walmart lengkap
Jika Anda sedang terburu-buru dan hanya ingin membaca kode terakhir, Anda dapat menemukannya di sini:
import json
import requests
from bs4 import BeautifulSoup
url = "https://www.walmart.com/ip/Straight-Talk-Apple-iPhone-SE-2022-3rd-Gen-5G-64GB-Midnight-Prepaid-Smartphone-Locked-to-Straight-Talk/616074177"
payload = {"api_key": "YOUR_API_KEY", "url": url, "render": "true"}
html = requests.get("http://api.scraperapi.com", params=payload)
product_info = {}
soup = BeautifulSoup(html.text)
product_info('product_name') = soup.find("h1", attrs={"itemprop": "name"}).text
product_info('rating') = soup.find("span", class_="rating-number").text
product_info('review_count') = soup.find("a", attrs={"itemprop": "ratingCount"}).text
image_divs = soup.findAll("div", attrs={"data-testid": "media-thumbnail"})
all_image_urls = ()
for div in image_divs:
image = div.find("img", attrs={"loading": "lazy"})
if image:
image_url = image("src")
all_image_urls.append(image_url)
product_info('all_image_urls') = all_image_urls
product_info('price') = soup.find("span", attrs={"itemprop": "price"}).text
next_data = soup.find("script", {"id": "__NEXT_DATA__"})
parsed_json = json.loads(next_data.string)
description_1 = parsed_json("props")("pageProps")("initialData")("data")("product")(
"shortDescription"
)
description_2 = parsed_json("props")("pageProps")("initialData")("data")("idml")(
"longDescription"
)
product_info('description_1_text') = BeautifulSoup(description_1, 'html.parser').text
product_info('description_2_text') = BeautifulSoup(description_2, 'html.parser').text
print(product_info)
Catatan: Jangan lupa untuk menggantinya YOUR_API_KEY dengan kunci API ScraperAPI Anda.
Silakan lanjutkan membaca tutorial untuk memahami cara kerja kode.
Mengikis data produk Walmart
Dalam tutorial ini, Anda akan mempelajari cara mengekstrak data dari satu halaman produk Walmart dan mengekstrak informasi beranotasi berikut (dan deskripsi produk):
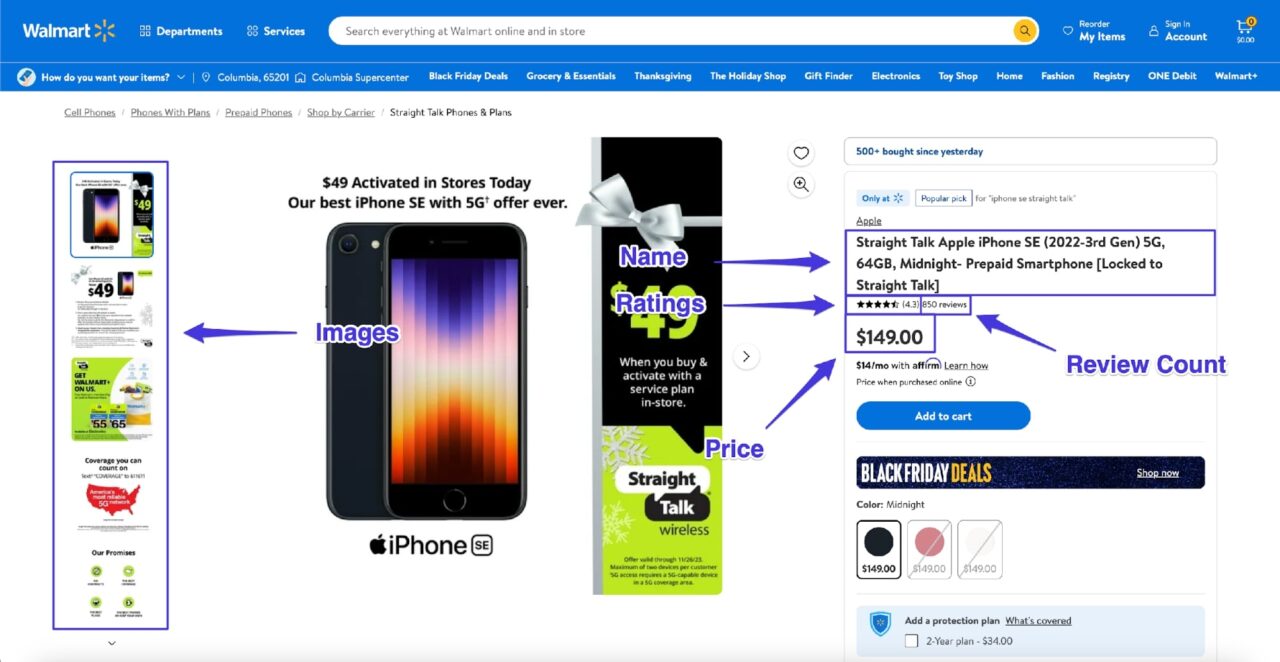
Persyaratan
Tutorial ini didasarkan pada Python versi 3.12. Jika Anda memiliki versi Python lebih besar dari 3.8, semuanya akan baik-baik saja. Namun, jika ada yang tidak berfungsi seperti yang ditunjukkan, coba perbarui versi Python Anda ke 3.12.
Anda dapat memeriksa versi Python Anda dengan menjalankan kode ini di terminal:
Agar semuanya tetap teratur, buat folder baru dengan a app.py File di dalamnya:
$ mkdir walmart_scraper
$ cd walmart_scraper
$ touch app.py
Anda juga dapat menyiapkan lingkungan virtual jika ingin isolasi lebih lanjut:
python -m venv venv
source venv/bin/activate
Selanjutnya Anda perlu menginstal Permintaan dan BeautifulSoup. Anda menggunakan Permintaan untuk mengirim permintaan HTTP dan BeautifulSoup untuk mengurai data respons. Anda dapat dengan mudah menginstal keduanya menggunakan PIP:
$ pip install requests, beautifulsoup4
Langkah 1: Daftar dengan ScraperAPI
Meskipun Anda ingin Walmart gulung tikar, raksasa ritel itu juga tidak ingin datanya dihapus. Karena alasan ini, situs web Walmart menerapkan berbagai tindakan anti-bot yang mengembalikan data yang salah/tidak berguna sebagai respons terhadap permintaan otomatis.
Ada beberapa cara untuk mengatasi masalah ini.
Anda dapat mencoba membuat bot sebisa mungkin meniru perilaku pengguna sebenarnya, atau Anda dapat menggunakan proxy pihak ketiga.
Opsi pertama mungkin berhasil dalam beberapa kasus sederhana, namun terlalu rapuh, dan karena Walmart terus memperbarui tindakan anti-botnya, pertanyaannya adalah “kapan” bot Anda akan rusak, bukan “jika”.
Hal ini membuat opsi proxy menjadi sangat menarik. Opsi ini membebaskan Anda dari tugas sulit untuk memastikan Walmart mengirimkan respons yang benar kembali ke pihak ketiga, sehingga memberi Anda lebih banyak waktu untuk fokus pada logika bisnis Anda.
Dalam tutorial ini, kami akan membahas opsi proxy dan menggunakan ScraperAPI sebagai penyedia proxy kami.
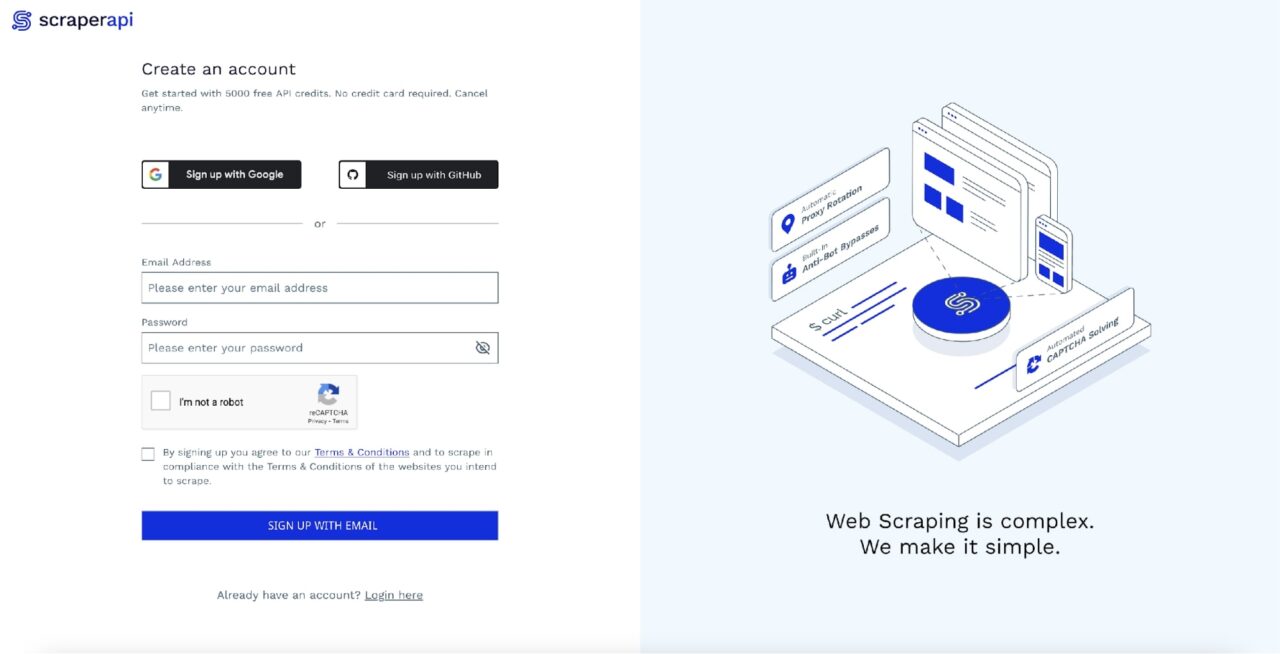
Bagian terbaiknya adalah ScraperAPI menyediakan 5.000 kredit API gratis selama 7 hari sebagai uji coba, dan kemudian memberikan paket gratis yang berlimpah dengan 1.000 kredit API berulang untuk membuat Anda terus maju. Ini cukup untuk mengekstrak data untuk penggunaan umum.
Anda dapat memulai dengan cepat dengan membuka halaman dasbor ScraperAPI dan mendaftar akun baru:
Setelah masuk, Anda akan melihat kunci API Anda:
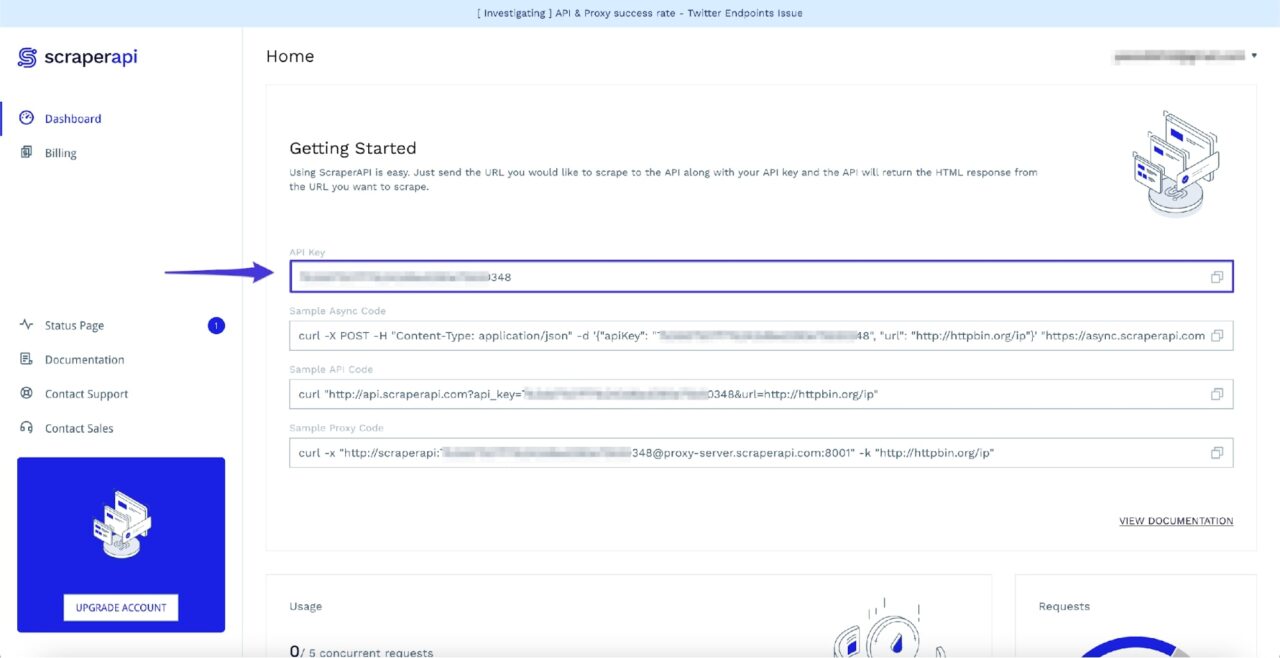
Tuliskan kunci API ini untuk saat ini karena Anda akan membutuhkannya pada langkah berikutnya.
Langkah 2: Dapatkan halaman produk Walmart
Setelah Anda menyiapkan akun ScraperAPI, Anda dapat menggunakan Python untuk membuat permintaan pertama untuk mengunduh halaman produk Walmart. Anda dapat menggunakan halaman produk ini untuk mengikuti.
Anda memiliki opsi berbeda tentang cara merutekan permintaan Anda melalui ScraperAPI.
- Anda dapat mengonfigurasi ScraperAPI sebagai proxy saat menggunakan permintaan atau…
- Anda dapat mengirim permintaan ke titik akhir API ScraperAPI dan meneruskan URL Walmart target sebagai payload.
Untuk informasi selengkapnya tentang opsi ini, lihat dokumentasi resmi.
Dalam kasus kami, kami menggunakan opsi terakhir dan meneruskan URL sebagai payload ke titik akhir API ScraperAPI.
Anda dapat menggunakan kode berikut untuk mendapatkan halaman produk Walmart melalui ScraperAPI:
import requests
url = "https://www.walmart.com/ip/Straight-Talk-Apple-iPhone-SE-2022-3rd-Gen-5G-64GB-Midnight-Prepaid-Smartphone-Locked-to-Straight-Talk/616074177"
payload = {"api_key": "YOUR_API_KEY", "url": url, "render": "true"}
html = requests.get("http://api.scraperapi.com", params=payload)
Catatan: Pastikan Anda menggantinya YOUR_API_KEY dengan kunci API ScraperAPI Anda
Setelah Anda mendapatkan respon HTML, Anda dapat menggunakannya untuk membuat objek BeautifulSoup dan kemudian menggunakannya untuk mengikis data yang diperlukan:
from bs4 import BeautifulSoup
# ...
soup = BeautifulSoup(html.text, 'html.parser')
Ini adalah waktu yang tepat untuk mulai mengumpulkan data dengan BeautifulSoup.
Langkah 3: Ekstrak nama produk
BeautifulSoup menawarkannya find() Metode yang menggunakan berbagai jenis filter dan kemudian menggunakannya untuk memindai dan memfilter pohon HTML.
Filter terpenting yang perlu Anda ketahui adalah filter string dan atribut.
- Itu penyaring tali mengambil string yang digunakan BeautifulSoup untuk mencocokkan nama tag HTML.
- Itu Filter atribut Juga membantu memfilter semua tag HTML yang cocok berdasarkan nilai atribut tertentu.
Tapi bagaimana Anda tahu tag HTML mana yang berisi data yang Anda inginkan? Di sinilah alat pengembang berperan.
Alat pengembang disertakan dengan sebagian besar browser populer dan memungkinkan Anda dengan mudah mengetahui tag HTML mana yang berisi data yang ingin Anda ekstrak.
Anda dapat dengan mudah mengakses alat pengembang Klik kanan pada nama produk dan Klik Pada memeriksa.
Ini adalah tampilannya ketika alat pengembang terbuka di Firefox (Chrome juga akan terlihat serupa):
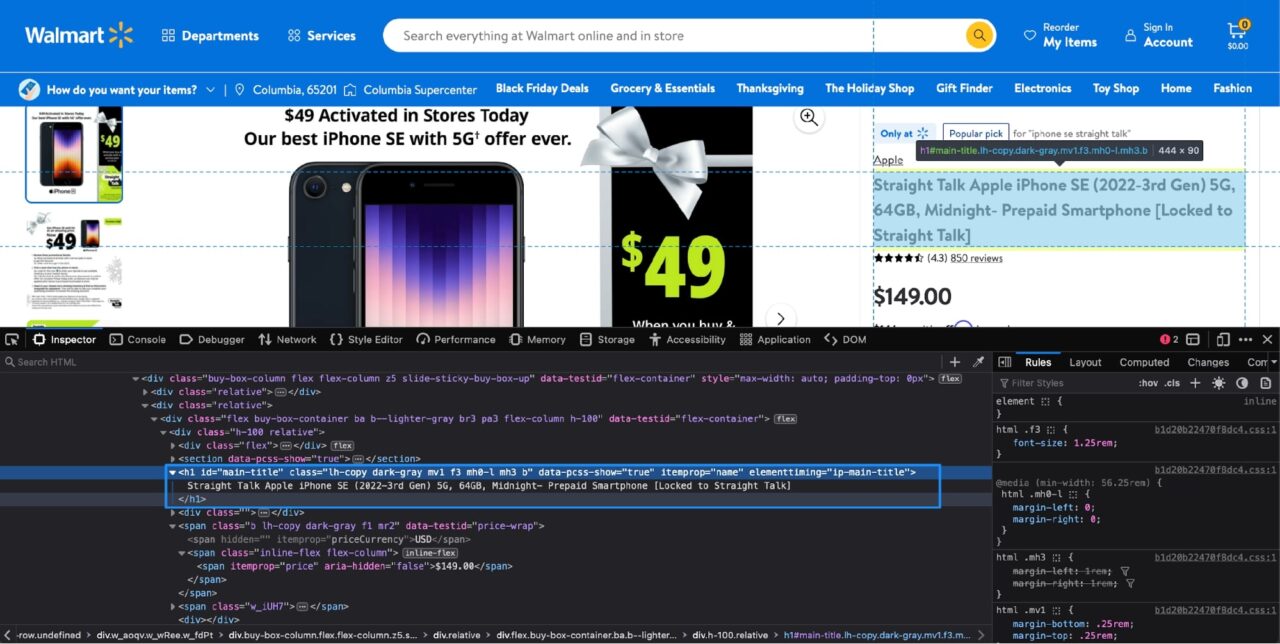
Bagian yang disorot di inspektur Tab tersebut memberi tahu Anda bahwa nama produk disimpan di a h1 hari dengan itu itemprop Atribut disetel ke name.
Catatan: Beberapa atribut dapat ditetapkan ke sebuah tag. Tugas Anda adalah mencari tahu kombinasi atribut apa yang cukup untuk mengidentifikasi tag tertentu secara unik. Untungnya, dalam hal ini, hanya itu yang Anda butuhkan itemprop Atribut karena tidak ada yang lain h1 Tandai di situs ini siapa yang memiliki ini itemprop Atribut disetel ke name.
Anda dapat menggunakan pengetahuan ini untuk membuat pemanggilan metode ini guna mengekstrak nama produk menggunakan BeautifulSoup:
product_name = soup.find("h1", attrs={"itemprop": "name"}).text
Itu text atribut di akhir pemanggilan metode cukup mengekstrak teks dari elemen HTML yang sesuai.
Jika Anda mencoba mencetak nilai product_name variabel, Anda akan melihat output ini:
>>> print(product_name)
Straight Talk Apple iPhone SE (2022-3rd Gen) 5G, 64GB, Midnight- Prepaid Smartphone (Locked to Straight Talk)
Manis! Itu berhasil! Sekarang Anda dapat mencoba menghapus sisa data dari halaman tersebut.
Langkah 4: Ekstrak harga produk
Ini adalah proses serupa untuk menentukan harga produk. Jika kamu Memeriksa harga dengan alat pengembang, ini yang akan Anda lihat:
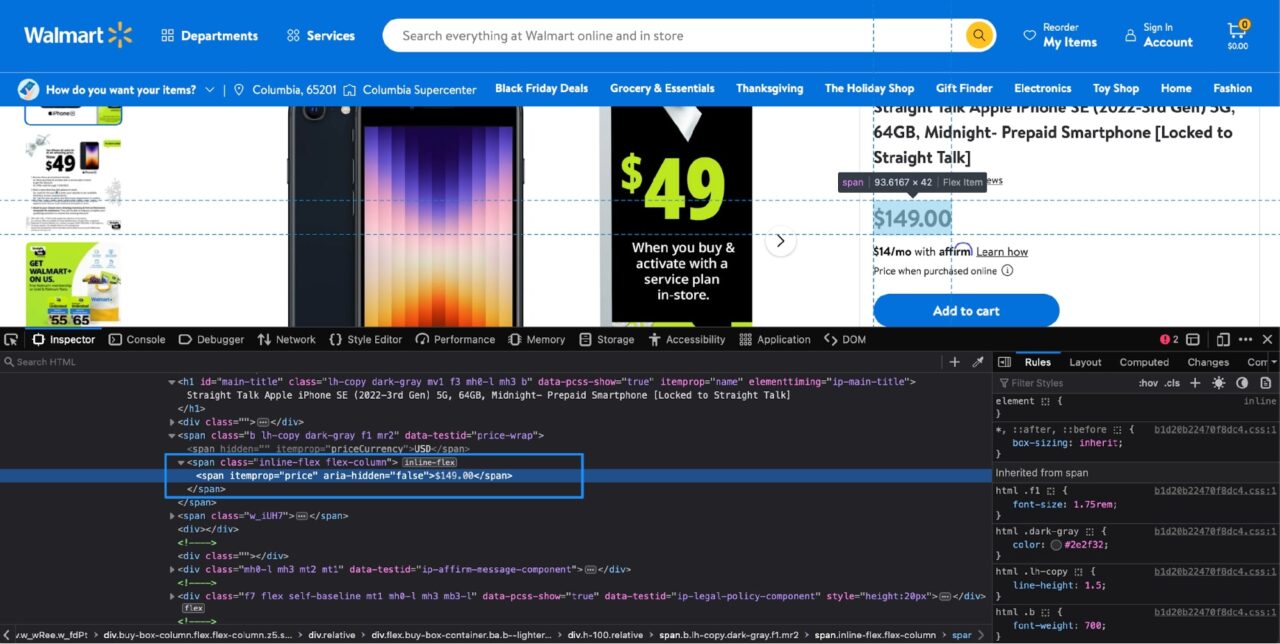
Informasi harga disertakan dalam satu span hari dengan itu itemprop Atribut disetel ke price. Ini menghasilkan kode Python berikut:
price = soup.find("span", attrs={"itemprop": "price"}).text
Langkah 5: Ekstrak jumlah peringkat dan ulasan produk
Kira-kira langkah yang sama diperlukan untuk mengekstrak semua informasi dari halaman produk. Jika kamu Memeriksa Menurut ulasan, Anda akan melihat struktur DOM berikut:
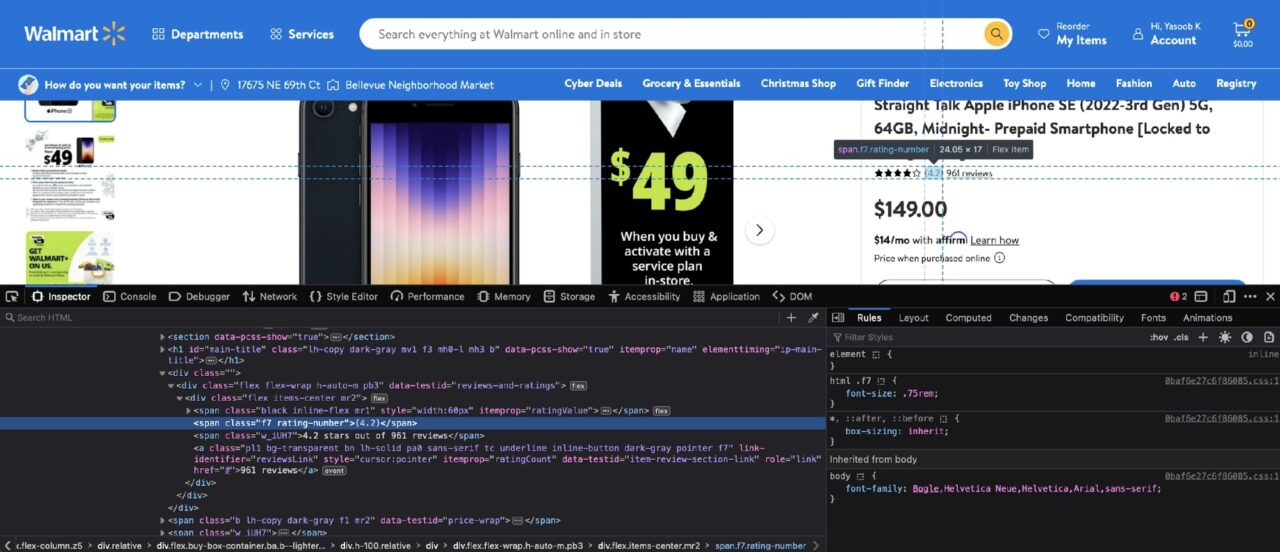
Nomor rating disertakan dalam satu span dengan kelas rating-numberdan jumlah ulasan disertakan dalam satu a hari dengan itu atribut itemprop disetel ke ratingCount.
Berikut adalah kode Python yang dihasilkan:
rating = soup.find("span", class_="rating-number").text
review_count = soup.find("a", attrs={"itemprop": "ratingCount"}).text
Satu-satunya perbedaan antara kode ini dan kode ekstraksi sebelumnya adalah Anda menggunakan class_ Argumen untuk meneruskan nama kelas ke BeautifulSoup. Ini hanyalah cara lain untuk memfilter berdasarkan nama kelas. Untuk informasi lebih lanjut tentang berbagai filter, lihat dokumentasi resmi.
Langkah 6: Ekstrak gambar produk
Sekarang saatnya melihat gambar produk. Seperti inilah struktur DOM untuk gambar produk:
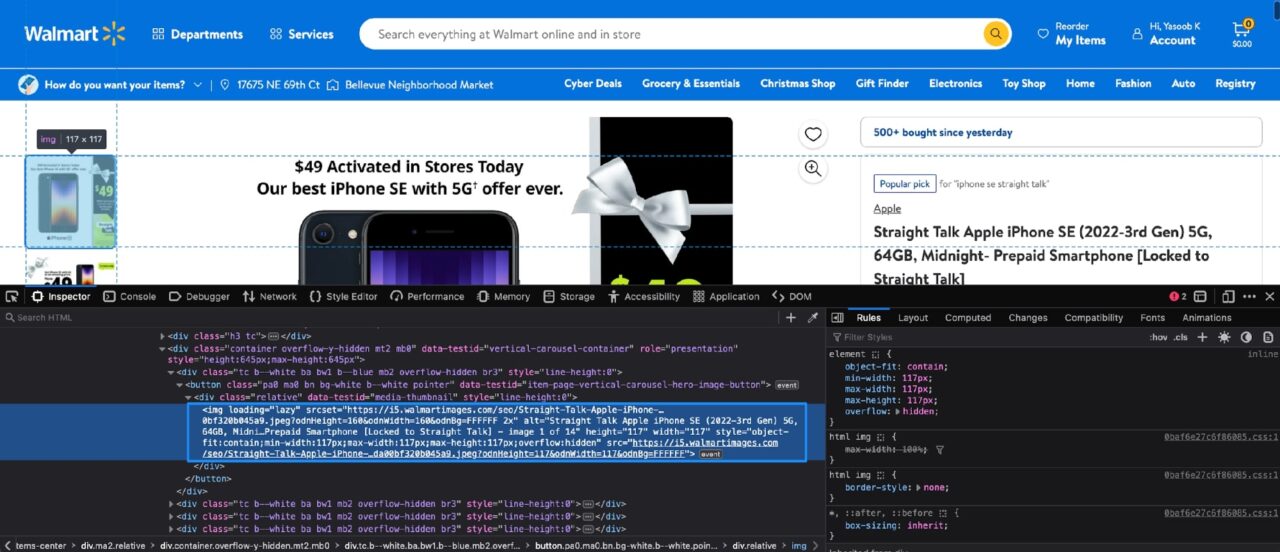
Setiap gambar produk disertakan dalam ilustrasi serupa img hari dengan itu loading Atribut disetel ke malas.
Anda dapat menggunakan BeautifulSoup dan menerapkan filter untuk mendapatkannya img Tag lalu ekstrak src Atribut yang berisi URL gambar sebenarnya.
Hanya ada satu masalah kecil. Ada yang lain img Tag di halaman ini yang memiliki ini loading Atribut disetel ke lazy. Jika kami tidak menambahkan pemfilteran tambahan, BeautifulSoup akan mengembalikan lebih banyak tag dari yang diharapkan.
Salah satu solusinya adalah memfilter tag lain terlebih dahulu untuk mempersempit cakupan pencarian, lalu menjalankan filter tambahan pada tag yang dikembalikan tersebut untuk mendapatkan semua tag bertingkat yang diperlukan. img Kata kunci.
Jika Anda melihat lebih dekat, Anda dapat mengamati orang tuanya div Tag berisi a data-testid Atribut disetel ke media-thumbnail. Dengan pengetahuan ini, Anda dapat menulis kode Python berikut:
image_divs = soup.find_all("div", attrs={"data-testid": "media-thumbnail"})
all_image_urls = ()
for div in image_divs:
image = div.find("img", attrs={"loading": "lazy"})
if image:
image_url = image("src")
all_image_urls.append(image_url)
Kode ini awalnya menemukan semua orang divs yang berisi gambar produk, dan kemudian untuk masing-masing div Pemfilteran tambahan diterapkan untuk memperoleh informasi yang relevan img Atribut sumber dari tag.
Langkah 7: Ekstrak deskripsi produk
Anda sekarang hampir mencapai garis finis. Informasi terakhir yang perlu Anda ekstrak adalah deskripsi produk.
Namun, seperti yang akan segera Anda lihat, ini juga yang paling membingungkan. Jika kamu Memeriksa Dalam deskripsi produk Anda akan menemukan struktur DOM berikut:
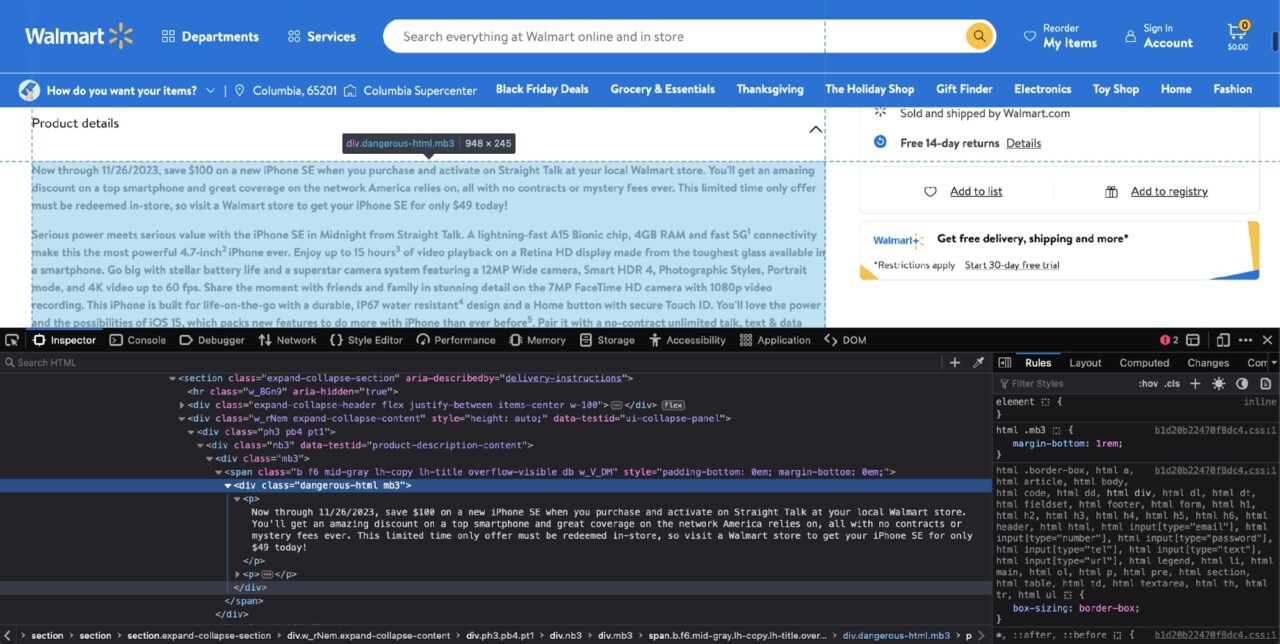
Sekilas kasus ini tampak sederhana div Saring dengan ini dangerous-html Filter kelas:
soup.find("div", class_="dangerous-html")
Namun, ini tidak mengembalikan tag yang cocok! Sihir macam apa ini?
Ternyata, Walmart menggunakan kerangka NextJS untuk situs web mereka dan tag ini diisi oleh NextJS di sisi klien.
Biasanya, ada dua kemungkinan skenario ketika BeautifulSoup tidak mengembalikan tag yang cocok:
- Salah satu skenarionya adalah setelah pemuatan halaman awal, informasi dimuat melalui permintaan AJAX
- Skenario kedua adalah informasi tersebut sudah ada di suatu tempat dalam dokumen HTML, namun diisi dengan beberapa JavaScript di tujuan akhirnya
Skenario kedua adalah informasi tersebut sudah ada di suatu tempat dalam dokumen HTML, namun diisi dengan beberapa JavaScript di tujuan akhirnya.
Jika Anda mencari deskripsi produk di Memeriksa Di tab, Anda akan segera melihat bahwa deskripsi produk disimpan dalam satu script tandai juga:
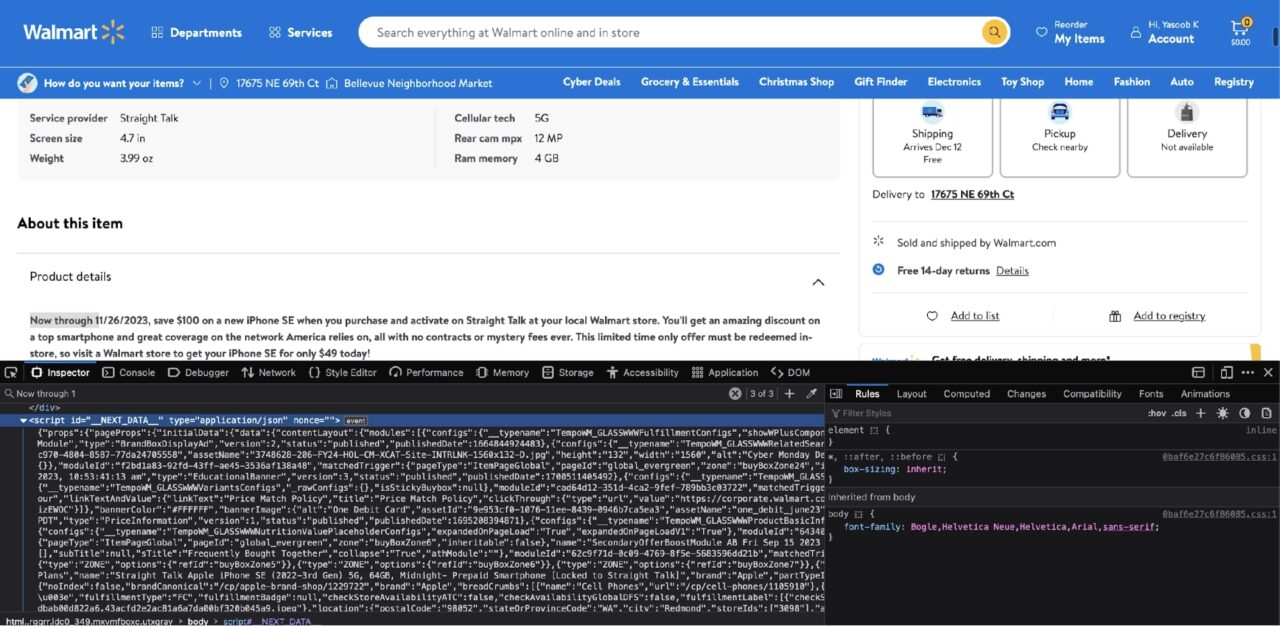
Itu script Tag berisi data yang digunakan oleh kerangka NextJS untuk mengisi UI dengan informasi yang relevan. Ini tidak lebih dari string JSON yang besar. Anda dapat memfilter berdasarkan itu script Tandai dengan BeautifulSoup, muat data yang disarangkan dengan json Perpustakaan dan kemudian mengakses informasi yang relevan menggunakan tombol yang sesuai.
Berikut tampilan data JSON yang diurai:
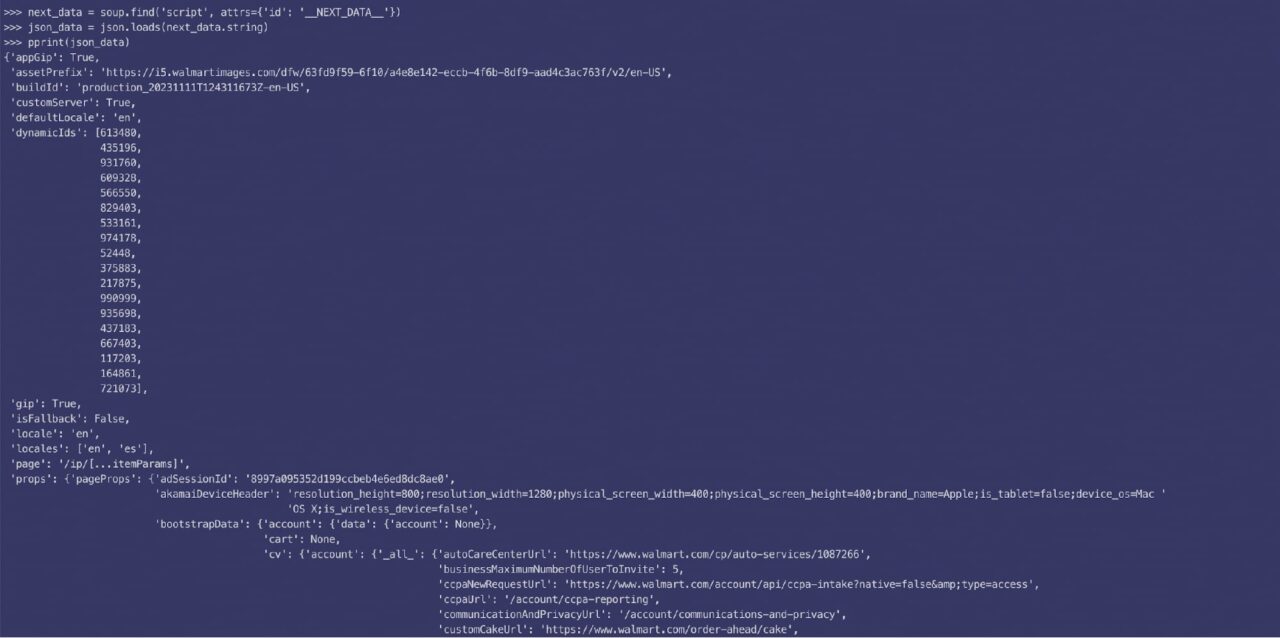
Ternyata, deskripsinya dibagi menjadi dua bagian (pendek dan panjang), dan kode ini akan memberi Anda data yang diperlukan:
next_data = soup.find("script", {"id": "__NEXT_DATA__"})
parsed_json = json.loads(next_data.string)
short_description = parsed_json("props")("pageProps")("initialData")("data")("product")(
"shortDescription"
)
long_description = parsed_json("props")("pageProps")("initialData")("data")("idml")(
"longDescription"
)
Ada masalah lain. Deskripsi yang diekstrak itu sendiri merupakan campuran tag HTML. Misalnya, berikut adalah deskripsi singkat yang bersarang di tag p:
Sekarang hingga 26/11/2023, hemat 100 $ di iPhone SE baru saat Anda membeli dan mengaktifkannya dengan Straight Talk di toko Walmart lokal Anda. Anda akan mendapatkan diskon luar biasa untuk ponsel pintar papan atas dan jangkauan luas jaringan yang diandalkan Amerika, semuanya tanpa kontrak atau biaya misteri. Penawaran waktu terbatas ini harus ditukarkan di toko. Jadi, kunjungi toko Walmart hari ini dan dapatkan iPhone SE Anda hanya dengan $49!
Performa serius berpadu dengan nilai serius dengan iPhone SE di Midnight dari Straight Talk. Chip A15 Bionic yang sangat cepat, RAM 4GB, dan 5G yang cepat1-Konektivitas menjadikannya 4,7-in yang paling kuat2 iPhone sepanjang masa. Nikmati hingga 15 jam3 Pemutaran video pada layar Retina HD yang terbuat dari kaca terkuat yang tersedia di ponsel pintar. Maksimalkan daya tahan baterai dan sistem kamera superstar dengan kamera sudut lebar 12MP, Smart HDR 4, Gaya Foto, Mode Potret, dan video 4K hingga 60 frame per detik. Bagikan momen bersama teman dan keluarga dalam detail menakjubkan dengan kamera FaceTime HD 7MP dengan perekaman video 1080p. IPhone ini hadir dengan IP67 yang kokoh dan tahan air4desain dan tombol beranda dengan Touch ID aman yang dirancang untuk kehidupan saat bepergian. Anda akan menyukai kecanggihan dan kemungkinan iOS 15, yang menawarkan fitur-fitur baru yang memungkinkan Anda melakukan lebih banyak hal dengan iPhone dibandingkan sebelumnya5. Gabungkan dengan paket telepon, pesan teks, dan data tanpa batas dan bebas kontrak dari Straight Talk untuk tetap terhubung di jaringan 5G† paling andal di Amerika dengan biaya lebih murah. Temukan Apple iPhone SE (Generasi ke-3) dengan paket Midnight dan Straight Talk secara online atau di toko di Walmart setempat.
Untungnya solusinya sederhana. Anda dapat memuat deskripsi ke dalam objek BeautifulSoup baru dan kemudian meminta BeautifulSoup untuk mengekstrak teks yang dapat dibaca dari HTML:
short_description_text = BeautifulSoup(description_1, 'lxml').text
long_description_text = BeautifulSoup(description_2, 'lxml').text
Saat Anda mencoba mencetak short_description_text Sekarang Anda akan melihat bahwa BeautifulSoup telah dengan mudah menghapus semua tag HTML dan hanya mengembalikan teks yang dapat dibaca:
>>> print(short_description_text)
Sekarang hingga 26/11/2023, hemat 100 $ di iPhone SE baru saat Anda membeli dan mengaktifkannya dengan Straight Talk di toko Walmart lokal Anda. Anda akan mendapatkan diskon luar biasa untuk ponsel pintar papan atas dan jangkauan luas jaringan yang diandalkan Amerika, semuanya tanpa kontrak atau biaya misteri. Penawaran waktu terbatas ini harus ditukarkan di toko. Jadi, kunjungi toko Walmart hari ini dan dapatkan iPhone SE Anda hanya dengan $49! Performa sejati berpadu dengan nilai sebenarnya dengan iPhone SE di Midnight dari Straight Talk. Chip A15 Bionic yang sangat cepat, RAM 4GB, dan konektivitas 5G1 yang cepat menjadikannya iPhone 4,7 inci2 paling kuat yang pernah ada. Nikmati pemutaran video hingga 15 jam3 pada layar Retina HD yang terbuat dari kaca paling tangguh yang tersedia di smartphone. Maksimalkan daya tahan baterai dan sistem kamera superstar dengan kamera sudut lebar 12MP, Smart HDR 4, Gaya Foto, Mode Potret, dan video 4K hingga 60 frame per detik. Bagikan momen bersama teman dan keluarga dalam detail menakjubkan dengan kamera FaceTime HD 7MP dengan perekaman video 1080p. Dibuat untuk digunakan saat bepergian, iPhone ini memiliki desain tahan air IP674 yang kokoh dan tombol home dengan Touch ID yang aman. Anda akan menyukai kecanggihan dan kemungkinan iOS 15, yang menghadirkan fitur-fitur baru yang memungkinkan Anda melakukan lebih banyak hal dengan iPhone dibandingkan sebelumnya5. Gabungkan dengan paket telepon, pesan teks, dan data tanpa batas dan bebas kontrak dari Straight Talk untuk tetap terhubung di jaringan 5G† paling andal di Amerika dengan biaya lebih murah. Temukan Apple iPhone SE (Generasi ke-3) dengan paket Midnight dan Straight Talk secara online atau di toko di Walmart setempat.
Langkah 8: Masukkan data ke dalam kamus
Untuk mempermudah bekerja dengan data yang diekstraksi, Anda dapat menyimpannya dalam kamus:
product_info = {
'product_name': product_name,
'rating': rating,
'review_count': review_count,
'price': price,
'all_image_urls': all_image_urls,
'short_description_text': short_description_text,
'long_description_text': long_description_text,
}
Kode yang dibagikan di TLDR Bagian di awal tutorial sedikit berbeda karena mengisi kamus saat data relevan diekstraksi. Kode di sisa artikel sengaja tidak mengikuti pola ini agar mudah dipahami tanpa menambah kerumitan tambahan.
Sekarang Anda dapat mengembalikan kamus ini sebagai bagian dari respons API atau menyimpannya ke file CSV. Langit adalah batasnya!
Bungkus
Dalam tutorial ini Anda akan:
- Pelajari cara mengekstrak data dari situs web Walmart menggunakan BeautifulSoup, Requests, dan Python
- Saya telah melihat bagaimana alat pengembang memudahkan untuk mengetahui filter BeautifulSoup mana yang harus digunakan untuk mengekstrak data yang relevan
- Membiasakan diri dengan ScraperAPI dan menyaksikan ScraperAPI menggunakan algoritme penghindaran deteksi yang canggih dan serangkaian proxy berkualitas tinggi untuk menjadikan semua tindakan anti-bot yang digunakan oleh Walmart tidak berguna
Anda dapat menggunakan pengetahuan yang diperoleh dalam tutorial ini untuk membuat saluran pipa pengikisan Walmart yang lebih canggih.
Pada titik ini tidak ada batasan untuk imajinasi Anda. Jika Anda memiliki pertanyaan atau memerlukan informasi lebih lanjut tentang berbagai produk kami, silakan hubungi kami! Kami di sini untuk membantu.
Sampai jumpa lagi, selamat menggores!