Fehlerbehandlung und -behebung: Untersuchen Sie, wie das Tool mit Fehlern umgeht, z. B. unterbrochenen Verbindungen oder unerwarteten Site-Änderungen.
Integration mit anderen Systemen: Stellen Sie fest, ob sich das Tool nahtlos in andere Systeme und Plattformen integrieren lässt, z. B. Datenbanken, Cloud-Dienste oder Datenanalysetools. Auch die Kompatibilität mit APIs kann ein wesentlicher Vorteil sein.
Datenbereinigung und -verarbeitung: Suchen Sie nach integrierten oder einfach zu integrierenden Funktionen zur Datenbereinigung und -verarbeitung, um den Arbeitsablauf von Rohdaten zu nutzbaren Informationen zu optimieren.
Datenmanagement nach dem Scraping
Nach dem Scraping ist die Datenverwaltung ebenso wichtig wie die Extraktion. Für die Integration in Geschäftssysteme ist die Bereitstellung in verwendbaren Formaten wie CSV oder JSON erforderlich. Bei ScraperAPI haben wir dedizierte Endpunkte für beliebte Websites wie Amazon, Walmart und Google entwickelt, um Roh-HTML in gebrauchsfertige Datenpunkte umzuwandeln.
Der Speicher muss skalierbar und sicher sein und große Datensätze problemlos aufnehmen können. Die Reinigung ist unerlässlich, um Fehler und irrelevante Inhalte zu entfernen und die Genauigkeit sicherzustellen.
Verwandt: Datenbereinigung 101 für Web Scraping.
Schließlich ist die Integration in bestehende Systeme der Schlüssel für umsetzbare Erkenntnisse und die Ausrichtung von Datenformaten auf die Anforderungen von Analysetools oder CRM-Systemen. Durch effizientes Management werden Rohdaten zu einem wertvollen Gut, das Geschäftsstrategien unterstützen kann.
Abschließende Gedanken: Was ist das beste Web-Scraping-Tool?
Das offene Web ist bei weitem der bedeutendste globale Speicher für menschliches Wissen, und es gibt fast keine Informationen, die Sie nicht durch die Extraktion von Webdaten finden können. Es stehen viele Tools zur Verfügung, weil Web Scraping von Menschen mit unterschiedlichen technischen Fähigkeiten und Know-how durchgeführt wird. Es gibt Web-Data-Scraping-Tools, die jedem dienen – von Leuten, die keinen Code schreiben wollen, bis hin zu erfahrenen Entwicklern, die nur nach der besten Open-Source-Lösung in ihrer Sprache suchen.
Es gibt nicht das beste Web-Scraping-Tool – alles hängt von Ihren Bedürfnissen ab. Wir hoffen, dass Ihnen diese Liste von Scraping-Tools dabei geholfen hat, die besten Webdaten-Scraping-Tools und -Dienste für Ihre spezifischen Projekte oder Unternehmen zu finden.
Viele der oben genannten Scraping-Tools bieten kostenlose oder kostengünstige Testversionen an, sodass Sie sicherstellen können, dass sie für Ihren geschäftlichen Anwendungsfall funktionieren. Einige von ihnen werden zuverlässiger und effektiver sein als andere. Wenn Sie nach einem Tool suchen, das Datenanfragen in großem Umfang und zu einem guten Preis bearbeiten kann, wenden Sie sich an einen Vertriebsmitarbeiter, um sicherzustellen, dass er liefern kann – bevor Sie Verträge unterzeichnen.
Automatisierungsfunktionen: Prüfen Sie den Grad der verfügbaren Automatisierung. Suchen Sie nach Planungsfunktionen, automatisierter Handhabung von CAPTCHA und der Möglichkeit, Cookies und Sitzungen automatisch zu verwalten.
IP-Rotation und Proxy-Unterstützung: Das Tool sollte eine robuste Unterstützung für IP-Rotation und Proxy-Verwaltung bieten, um eine Blockierung zu vermeiden.
Fehlerbehandlung und -behebung: Untersuchen Sie, wie das Tool mit Fehlern umgeht, z. B. unterbrochenen Verbindungen oder unerwarteten Site-Änderungen.
Integration mit anderen Systemen: Stellen Sie fest, ob sich das Tool nahtlos in andere Systeme und Plattformen integrieren lässt, z. B. Datenbanken, Cloud-Dienste oder Datenanalysetools. Auch die Kompatibilität mit APIs kann ein wesentlicher Vorteil sein.
Datenbereinigung und -verarbeitung: Suchen Sie nach integrierten oder einfach zu integrierenden Funktionen zur Datenbereinigung und -verarbeitung, um den Arbeitsablauf von Rohdaten zu nutzbaren Informationen zu optimieren.
Datenmanagement nach dem Scraping
Nach dem Scraping ist die Datenverwaltung ebenso wichtig wie die Extraktion. Für die Integration in Geschäftssysteme ist die Bereitstellung in verwendbaren Formaten wie CSV oder JSON erforderlich. Bei ScraperAPI haben wir dedizierte Endpunkte für beliebte Websites wie Amazon, Walmart und Google entwickelt, um Roh-HTML in gebrauchsfertige Datenpunkte umzuwandeln.
Der Speicher muss skalierbar und sicher sein und große Datensätze problemlos aufnehmen können. Die Reinigung ist unerlässlich, um Fehler und irrelevante Inhalte zu entfernen und die Genauigkeit sicherzustellen.
Verwandt: Datenbereinigung 101 für Web Scraping.
Schließlich ist die Integration in bestehende Systeme der Schlüssel für umsetzbare Erkenntnisse und die Ausrichtung von Datenformaten auf die Anforderungen von Analysetools oder CRM-Systemen. Durch effizientes Management werden Rohdaten zu einem wertvollen Gut, das Geschäftsstrategien unterstützen kann.
Abschließende Gedanken: Was ist das beste Web-Scraping-Tool?
Das offene Web ist bei weitem der bedeutendste globale Speicher für menschliches Wissen, und es gibt fast keine Informationen, die Sie nicht durch die Extraktion von Webdaten finden können. Es stehen viele Tools zur Verfügung, weil Web Scraping von Menschen mit unterschiedlichen technischen Fähigkeiten und Know-how durchgeführt wird. Es gibt Web-Data-Scraping-Tools, die jedem dienen – von Leuten, die keinen Code schreiben wollen, bis hin zu erfahrenen Entwicklern, die nur nach der besten Open-Source-Lösung in ihrer Sprache suchen.
Es gibt nicht das beste Web-Scraping-Tool – alles hängt von Ihren Bedürfnissen ab. Wir hoffen, dass Ihnen diese Liste von Scraping-Tools dabei geholfen hat, die besten Webdaten-Scraping-Tools und -Dienste für Ihre spezifischen Projekte oder Unternehmen zu finden.
Viele der oben genannten Scraping-Tools bieten kostenlose oder kostengünstige Testversionen an, sodass Sie sicherstellen können, dass sie für Ihren geschäftlichen Anwendungsfall funktionieren. Einige von ihnen werden zuverlässiger und effektiver sein als andere. Wenn Sie nach einem Tool suchen, das Datenanfragen in großem Umfang und zu einem guten Preis bearbeiten kann, wenden Sie sich an einen Vertriebsmitarbeiter, um sicherzustellen, dass er liefern kann – bevor Sie Verträge unterzeichnen.
Skalierbarkeit: Überlegen Sie, wie gut das Tool die Datenextraktion in großem Maßstab bewältigt. Sowohl die Skalierbarkeit der Leistung als auch die Fähigkeit, sich an steigende Datenmengen oder Anforderungen anzupassen, sind von entscheidender Bedeutung.
Automatisierungsfunktionen: Prüfen Sie den Grad der verfügbaren Automatisierung. Suchen Sie nach Planungsfunktionen, automatisierter Handhabung von CAPTCHA und der Möglichkeit, Cookies und Sitzungen automatisch zu verwalten.
IP-Rotation und Proxy-Unterstützung: Das Tool sollte eine robuste Unterstützung für IP-Rotation und Proxy-Verwaltung bieten, um eine Blockierung zu vermeiden.
Fehlerbehandlung und -behebung: Untersuchen Sie, wie das Tool mit Fehlern umgeht, z. B. unterbrochenen Verbindungen oder unerwarteten Site-Änderungen.
Integration mit anderen Systemen: Stellen Sie fest, ob sich das Tool nahtlos in andere Systeme und Plattformen integrieren lässt, z. B. Datenbanken, Cloud-Dienste oder Datenanalysetools. Auch die Kompatibilität mit APIs kann ein wesentlicher Vorteil sein.
Datenbereinigung und -verarbeitung: Suchen Sie nach integrierten oder einfach zu integrierenden Funktionen zur Datenbereinigung und -verarbeitung, um den Arbeitsablauf von Rohdaten zu nutzbaren Informationen zu optimieren.
Datenmanagement nach dem Scraping
Nach dem Scraping ist die Datenverwaltung ebenso wichtig wie die Extraktion. Für die Integration in Geschäftssysteme ist die Bereitstellung in verwendbaren Formaten wie CSV oder JSON erforderlich. Bei ScraperAPI haben wir dedizierte Endpunkte für beliebte Websites wie Amazon, Walmart und Google entwickelt, um Roh-HTML in gebrauchsfertige Datenpunkte umzuwandeln.
Der Speicher muss skalierbar und sicher sein und große Datensätze problemlos aufnehmen können. Die Reinigung ist unerlässlich, um Fehler und irrelevante Inhalte zu entfernen und die Genauigkeit sicherzustellen.
Verwandt: Datenbereinigung 101 für Web Scraping.
Schließlich ist die Integration in bestehende Systeme der Schlüssel für umsetzbare Erkenntnisse und die Ausrichtung von Datenformaten auf die Anforderungen von Analysetools oder CRM-Systemen. Durch effizientes Management werden Rohdaten zu einem wertvollen Gut, das Geschäftsstrategien unterstützen kann.
Abschließende Gedanken: Was ist das beste Web-Scraping-Tool?
Das offene Web ist bei weitem der bedeutendste globale Speicher für menschliches Wissen, und es gibt fast keine Informationen, die Sie nicht durch die Extraktion von Webdaten finden können. Es stehen viele Tools zur Verfügung, weil Web Scraping von Menschen mit unterschiedlichen technischen Fähigkeiten und Know-how durchgeführt wird. Es gibt Web-Data-Scraping-Tools, die jedem dienen – von Leuten, die keinen Code schreiben wollen, bis hin zu erfahrenen Entwicklern, die nur nach der besten Open-Source-Lösung in ihrer Sprache suchen.
Es gibt nicht das beste Web-Scraping-Tool – alles hängt von Ihren Bedürfnissen ab. Wir hoffen, dass Ihnen diese Liste von Scraping-Tools dabei geholfen hat, die besten Webdaten-Scraping-Tools und -Dienste für Ihre spezifischen Projekte oder Unternehmen zu finden.
Viele der oben genannten Scraping-Tools bieten kostenlose oder kostengünstige Testversionen an, sodass Sie sicherstellen können, dass sie für Ihren geschäftlichen Anwendungsfall funktionieren. Einige von ihnen werden zuverlässiger und effektiver sein als andere. Wenn Sie nach einem Tool suchen, das Datenanfragen in großem Umfang und zu einem guten Preis bearbeiten kann, wenden Sie sich an einen Vertriebsmitarbeiter, um sicherzustellen, dass er liefern kann – bevor Sie Verträge unterzeichnen.
Benutzerfreundlichkeit: Bewerten Sie die Lernkurve, die Benutzeroberfläche und die verfügbare Dokumentation des Tools. Wer es nutzt, sollte die Komplexität des Tools verstehen.
Skalierbarkeit: Überlegen Sie, wie gut das Tool die Datenextraktion in großem Maßstab bewältigt. Sowohl die Skalierbarkeit der Leistung als auch die Fähigkeit, sich an steigende Datenmengen oder Anforderungen anzupassen, sind von entscheidender Bedeutung.
Automatisierungsfunktionen: Prüfen Sie den Grad der verfügbaren Automatisierung. Suchen Sie nach Planungsfunktionen, automatisierter Handhabung von CAPTCHA und der Möglichkeit, Cookies und Sitzungen automatisch zu verwalten.
IP-Rotation und Proxy-Unterstützung: Das Tool sollte eine robuste Unterstützung für IP-Rotation und Proxy-Verwaltung bieten, um eine Blockierung zu vermeiden.
Fehlerbehandlung und -behebung: Untersuchen Sie, wie das Tool mit Fehlern umgeht, z. B. unterbrochenen Verbindungen oder unerwarteten Site-Änderungen.
Integration mit anderen Systemen: Stellen Sie fest, ob sich das Tool nahtlos in andere Systeme und Plattformen integrieren lässt, z. B. Datenbanken, Cloud-Dienste oder Datenanalysetools. Auch die Kompatibilität mit APIs kann ein wesentlicher Vorteil sein.
Datenbereinigung und -verarbeitung: Suchen Sie nach integrierten oder einfach zu integrierenden Funktionen zur Datenbereinigung und -verarbeitung, um den Arbeitsablauf von Rohdaten zu nutzbaren Informationen zu optimieren.
Datenmanagement nach dem Scraping
Nach dem Scraping ist die Datenverwaltung ebenso wichtig wie die Extraktion. Für die Integration in Geschäftssysteme ist die Bereitstellung in verwendbaren Formaten wie CSV oder JSON erforderlich. Bei ScraperAPI haben wir dedizierte Endpunkte für beliebte Websites wie Amazon, Walmart und Google entwickelt, um Roh-HTML in gebrauchsfertige Datenpunkte umzuwandeln.
Der Speicher muss skalierbar und sicher sein und große Datensätze problemlos aufnehmen können. Die Reinigung ist unerlässlich, um Fehler und irrelevante Inhalte zu entfernen und die Genauigkeit sicherzustellen.
Verwandt: Datenbereinigung 101 für Web Scraping.
Schließlich ist die Integration in bestehende Systeme der Schlüssel für umsetzbare Erkenntnisse und die Ausrichtung von Datenformaten auf die Anforderungen von Analysetools oder CRM-Systemen. Durch effizientes Management werden Rohdaten zu einem wertvollen Gut, das Geschäftsstrategien unterstützen kann.
Abschließende Gedanken: Was ist das beste Web-Scraping-Tool?
Das offene Web ist bei weitem der bedeutendste globale Speicher für menschliches Wissen, und es gibt fast keine Informationen, die Sie nicht durch die Extraktion von Webdaten finden können. Es stehen viele Tools zur Verfügung, weil Web Scraping von Menschen mit unterschiedlichen technischen Fähigkeiten und Know-how durchgeführt wird. Es gibt Web-Data-Scraping-Tools, die jedem dienen – von Leuten, die keinen Code schreiben wollen, bis hin zu erfahrenen Entwicklern, die nur nach der besten Open-Source-Lösung in ihrer Sprache suchen.
Es gibt nicht das beste Web-Scraping-Tool – alles hängt von Ihren Bedürfnissen ab. Wir hoffen, dass Ihnen diese Liste von Scraping-Tools dabei geholfen hat, die besten Webdaten-Scraping-Tools und -Dienste für Ihre spezifischen Projekte oder Unternehmen zu finden.
Viele der oben genannten Scraping-Tools bieten kostenlose oder kostengünstige Testversionen an, sodass Sie sicherstellen können, dass sie für Ihren geschäftlichen Anwendungsfall funktionieren. Einige von ihnen werden zuverlässiger und effektiver sein als andere. Wenn Sie nach einem Tool suchen, das Datenanfragen in großem Umfang und zu einem guten Preis bearbeiten kann, wenden Sie sich an einen Vertriebsmitarbeiter, um sicherzustellen, dass er liefern kann – bevor Sie Verträge unterzeichnen.
Datenextraktionsfunktionen: Ein gutes Web-Scraping-Tool unterstützt verschiedene Datenformate und kann Inhalte aus verschiedenen Webstrukturen extrahieren, einschließlich statischer HTML-Seiten und dynamischer Websites mithilfe von JavaScript.
Benutzerfreundlichkeit: Bewerten Sie die Lernkurve, die Benutzeroberfläche und die verfügbare Dokumentation des Tools. Wer es nutzt, sollte die Komplexität des Tools verstehen.
Skalierbarkeit: Überlegen Sie, wie gut das Tool die Datenextraktion in großem Maßstab bewältigt. Sowohl die Skalierbarkeit der Leistung als auch die Fähigkeit, sich an steigende Datenmengen oder Anforderungen anzupassen, sind von entscheidender Bedeutung.
Automatisierungsfunktionen: Prüfen Sie den Grad der verfügbaren Automatisierung. Suchen Sie nach Planungsfunktionen, automatisierter Handhabung von CAPTCHA und der Möglichkeit, Cookies und Sitzungen automatisch zu verwalten.
IP-Rotation und Proxy-Unterstützung: Das Tool sollte eine robuste Unterstützung für IP-Rotation und Proxy-Verwaltung bieten, um eine Blockierung zu vermeiden.
Fehlerbehandlung und -behebung: Untersuchen Sie, wie das Tool mit Fehlern umgeht, z. B. unterbrochenen Verbindungen oder unerwarteten Site-Änderungen.
Integration mit anderen Systemen: Stellen Sie fest, ob sich das Tool nahtlos in andere Systeme und Plattformen integrieren lässt, z. B. Datenbanken, Cloud-Dienste oder Datenanalysetools. Auch die Kompatibilität mit APIs kann ein wesentlicher Vorteil sein.
Datenbereinigung und -verarbeitung: Suchen Sie nach integrierten oder einfach zu integrierenden Funktionen zur Datenbereinigung und -verarbeitung, um den Arbeitsablauf von Rohdaten zu nutzbaren Informationen zu optimieren.
Datenmanagement nach dem Scraping
Nach dem Scraping ist die Datenverwaltung ebenso wichtig wie die Extraktion. Für die Integration in Geschäftssysteme ist die Bereitstellung in verwendbaren Formaten wie CSV oder JSON erforderlich. Bei ScraperAPI haben wir dedizierte Endpunkte für beliebte Websites wie Amazon, Walmart und Google entwickelt, um Roh-HTML in gebrauchsfertige Datenpunkte umzuwandeln.
Der Speicher muss skalierbar und sicher sein und große Datensätze problemlos aufnehmen können. Die Reinigung ist unerlässlich, um Fehler und irrelevante Inhalte zu entfernen und die Genauigkeit sicherzustellen.
Verwandt: Datenbereinigung 101 für Web Scraping.
Schließlich ist die Integration in bestehende Systeme der Schlüssel für umsetzbare Erkenntnisse und die Ausrichtung von Datenformaten auf die Anforderungen von Analysetools oder CRM-Systemen. Durch effizientes Management werden Rohdaten zu einem wertvollen Gut, das Geschäftsstrategien unterstützen kann.
Abschließende Gedanken: Was ist das beste Web-Scraping-Tool?
Das offene Web ist bei weitem der bedeutendste globale Speicher für menschliches Wissen, und es gibt fast keine Informationen, die Sie nicht durch die Extraktion von Webdaten finden können. Es stehen viele Tools zur Verfügung, weil Web Scraping von Menschen mit unterschiedlichen technischen Fähigkeiten und Know-how durchgeführt wird. Es gibt Web-Data-Scraping-Tools, die jedem dienen – von Leuten, die keinen Code schreiben wollen, bis hin zu erfahrenen Entwicklern, die nur nach der besten Open-Source-Lösung in ihrer Sprache suchen.
Es gibt nicht das beste Web-Scraping-Tool – alles hängt von Ihren Bedürfnissen ab. Wir hoffen, dass Ihnen diese Liste von Scraping-Tools dabei geholfen hat, die besten Webdaten-Scraping-Tools und -Dienste für Ihre spezifischen Projekte oder Unternehmen zu finden.
Viele der oben genannten Scraping-Tools bieten kostenlose oder kostengünstige Testversionen an, sodass Sie sicherstellen können, dass sie für Ihren geschäftlichen Anwendungsfall funktionieren. Einige von ihnen werden zuverlässiger und effektiver sein als andere. Wenn Sie nach einem Tool suchen, das Datenanfragen in großem Umfang und zu einem guten Preis bearbeiten kann, wenden Sie sich an einen Vertriebsmitarbeiter, um sicherzustellen, dass er liefern kann – bevor Sie Verträge unterzeichnen.
Vollständige Scraping-Lösung: ScraperAPI bietet ein komplettes Web-Scraping-Paket, das die Proxy-Verwaltung, die CAPTCHA-Lösung und die Wiederholung von Anfragen automatisiert und so das Extrahieren von Daten von fast jeder Website erleichtert.
Erweiterte Bot-Blocker-Umgehung: Es umgeht effektiv fortschrittliche Anti-Bot-Lösungen wie DataDome und PerimeterX und sorgt so für höhere Erfolgsraten auf schwer zu scannenden Websites.
Strukturierte Endpunkte: Die vorgefertigten Endpunkte von ScraperAPI liefern saubere, strukturierte Daten, reduzieren den Zeitaufwand für das Parsen und die Datenbereinigung und steigern so die Produktivität.
Kostengünstig: Das einzigartige intelligente IP-Rotationssystem von ScraperAPI nutzt maschinelles Lernen und statistische Analysen, um den besten Proxy pro Anfrage auszuwählen; Indem Proxys nur bei Bedarf rotiert werden und private und mobile Proxys als sekundäre Optionen für fehlgeschlagene Anfragen verwendet werden, wird der Proxy-Overhead erheblich reduziert und ist damit günstiger als viele Mitbewerber.
Skalierbarkeitstools: Funktionen wie DataPipeline zum Planen wiederkehrender Aufgaben und Async Scraper für die asynchrone Bearbeitung großer Anforderungsmengen ermöglichen es Benutzern, Scraping-Aufwände effizient zu skalieren und zu automatisieren.
Nachteile
Reduzierte Anzahl strukturierter Datenendpunkte im Vergleich zu einigen Mitbewerbern.
Bewertungen
Der beste Weg, ein Tool zu identifizieren, das hält, was es verspricht, besteht darin, Rezensionen und Bewertungen des Tools zu überprüfen. ScraperAPI hat seine Position an der Spitze bisher behauptet. Hier finden Sie Bewertungen der wichtigsten Bewertungsplattformen.
Trustpilot-Bewertung – 4,7
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Ein gutes Scraping-Tool sollte einfach zu bedienen sein, sonst verfehlt es seinen Zweck, und ScraperAPI sticht in diesem Fall hervor, da die Bewertungen nicht lügen.
Schauen Sie sich gerne die tollen Rezensionen darüber an, wie ScraperAPI Ihre Aufgabe erleichtert.
Preise
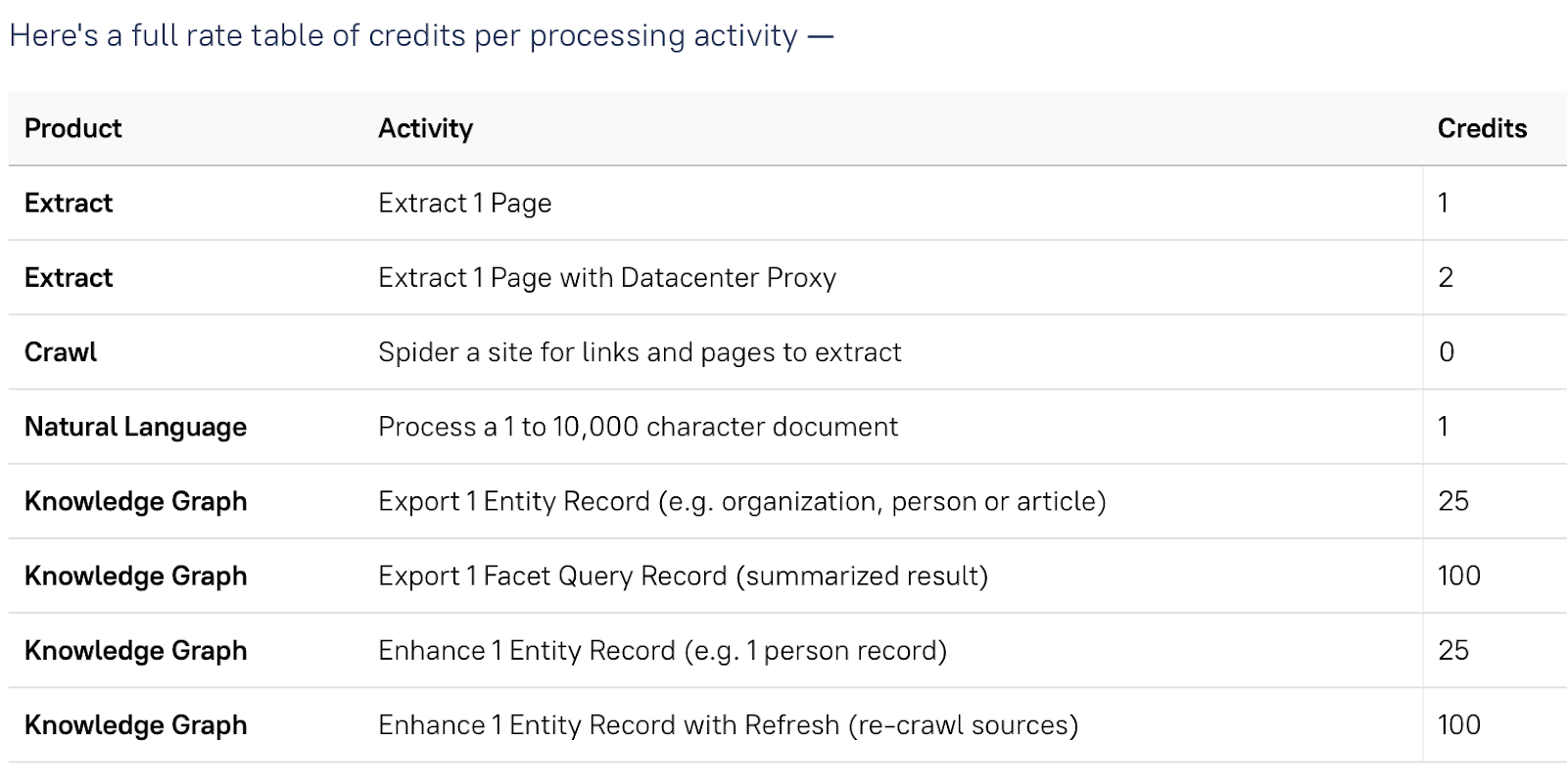
Das ScraperAPI-Preismodell ist leicht verständlich und erschwinglich, da wir pro erfolgreicher Anfrage und nicht pro GB oder Bandbreite wie bei anderen Web-Scraping-Tools abrechnen.
Die Anzahl der verbrauchten Credits hängt von der Domain, dem Schutzniveau der Website und den spezifischen Parametern ab, die Sie in Ihrer Anfrage angeben.
ScraperAPI berechnet beispielsweise 5 API-Credits pro erfolgreicher Anfrage an E-Commerce-Domains wie Amazon und Walmart, sodass Sie ganz einfach die Anzahl der Seiten berechnen können, die Sie mit Ihrem Plan scrapen können.
Hier ist eine Aufschlüsselung des Preismodells von ScraperAPI:
Planen
Preise
API-Credits
Kostenlose Testversion (7 – Tage)
Frei
5000
Hobby
49 $
100.000
Start-up
149 $
1.000.000
Geschäft
299 $
3.000.000
Unternehmen
299 $ +
3.000.000 +
Besuchen Sie die Seite „Credits und Anfragen“ von ScraperAPI, um die Credit-Nutzung im Detail zu sehen.
2. ScrapeSimple (Web-Scraping-Outsourcing)
Für wen das ist: ScrapeSimple ist der perfekte Service für Leute, die ein maßgeschneidertes Web-Scraper-Tool für sich haben möchten. Es ist so einfach wie das Ausfüllen eines Formulars mit Anweisungen für die Art der gewünschten Daten.
Warum Sie es verwenden sollten: ScrapeSimple macht seinem Namen alle Ehre und steht ganz oben auf unserer Liste der einfachen Web-Scraping-Tools mit einem vollständig verwalteten Service, der benutzerdefinierte Web-Scraper für Kunden erstellt und verwaltet.
Sagen Sie ihnen einfach, welche Informationen Sie von welchen Websites benötigen, und sie entwerfen einen benutzerdefinierten Web-Scraper, der die Informationen regelmäßig (Sie können zwischen täglich, wöchentlich oder monatlich wählen) im CSV-Format direkt in Ihren Posteingang liefert.
Dieser Service ist perfekt für Unternehmen, die einfach nur einen HTML-Scraper benötigen, ohne selbst Code schreiben zu müssen. Die Reaktionszeiten sind kurz und der Service unglaublich freundlich und hilfsbereit, was ihn perfekt für Leute macht, die sich einfach um den gesamten Datenextraktionsprozess kümmern möchten.
Vorteile
Schnelle Bearbeitungszeit von 1 – 2 Tagen für kleine Projekte
Outsourcen Sie Dienstleistungen für Unternehmen, die nur nach Daten suchen
Für den Datenerfassungsprozess ist kein technisches Fachwissen erforderlich
Nachteile
Es ist teurer als ein DIY-Ansatz
Ihr Team benötigt weiterhin technisches Fachwissen, um mit den Daten zu arbeiten und sie zu analysieren
Bewertungen
Da es sich um einen Web-Scraping-Dienst handelt, gibt es keine erwähnenswerten G2- oder Trustpilot-Bewertungen.
Benutzerfreundlichkeit
⭐⭐⭐⭐(4/5)
Preise
ScrapeSimple hat keinen festen Preis. Stattdessen verlangen sie ein Mindestbudget von 250 US-Dollar pro Monat und Projekt.
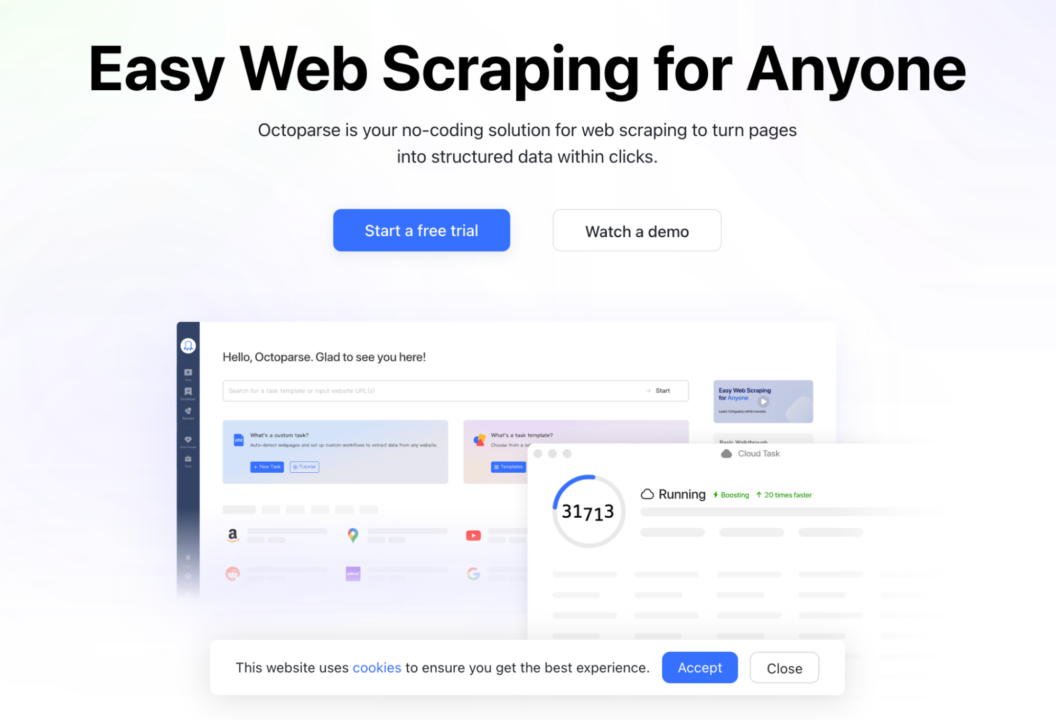
3. Octoparse (Browser-Scraping-Tool ohne Code)
Für wen das ist: Octoparse ist ein fantastisches Scraper-Tool für Leute, die Daten von Websites extrahieren möchten, ohne programmieren zu müssen, und gleichzeitig mit ihrer benutzerfreundlichen Benutzeroberfläche die Kontrolle über den gesamten Prozess haben möchten.
Warum Sie es verwenden sollten: Octoparse ist eines der besten Screen-Scraping-Tools für Leute, die Websites scrapen möchten, ohne Programmieren zu lernen. Es verfügt über einen Point-and-Click-Screen-Scraper, der es Benutzern ermöglicht, hinter Anmeldeformulare zu scrollen, Formulare auszufüllen, Suchbegriffe einzugeben, durch unendliches Scrollen zu scrollen, JavaScript zu rendern und vieles mehr.
Es umfasst außerdem einen Site-Parser und eine gehostete Lösung für Benutzer, die ihre Scraper in der Cloud ausführen möchten. Das Beste daran ist, dass es ein großzügiges kostenloses Kontingent gibt, sodass Benutzer bis zu 10 Crawler kostenlos erstellen können. Für Unternehmenskunden bieten sie außerdem vollständig angepasste Crawler und verwaltete Lösungen an, bei denen sie alles für Sie ausführen und Ihnen die Daten einfach direkt liefern.
Vorteile
Benutzerfreundlichkeit: Octoparse wird für seine benutzerfreundliche Oberfläche, insbesondere den Smart-Modus und den Assistentenmodus, hoch gelobt, wodurch es auch für jeden mit eingeschränkten technischen Fähigkeiten zugänglich ist.
Erweiterter Modus für Präzision: Der erweiterte Modus ist dafür bekannt, dass er eine präzise und genaue Datenextraktion ermöglicht und es technisch versierteren Personen ermöglicht, ihre Scraping-Aufgaben zu verfeinern.
XPath-Unterstützung: Die Octoparse-XPath-Unterstützung ist klar und benutzerfreundlich und hilft Ihnen, bestimmte Elemente effizient aus Webseiten zu extrahieren.
Geschwindigkeit und Automatisierung: Octoparse zeichnet sich durch Geschwindigkeit aus und wird besonders für die Automatisierung der Extraktion großer Datensätze geschätzt, was für Aufgaben wie das Sammeln von E-Mail-IDs oder das Scrapen von Produktdaten nützlich ist.
Keine Codierung erforderlich: Octoparse vereinfacht den Datenextraktionsprozess und ermöglicht Ihnen das Scrapen von Websites ohne jegliche Programmierung oder komplexe Regelsetzung.
Nachteile
Lernkurve für erweiterte Funktionen: Während die Grundfunktionen benutzerfreundlich sind, kann es für einige Benutzer ohne Vorkenntnisse schwierig sein, den erweiterten Modus oder die XPath-Anpassung anzupassen.
Bewertungen
Trustpilot-Bewertung – 3,0
Benutzerfreundlichkeit
⭐⭐⭐⭐(4/5)
Preise
Die Preismodelle von Octoparse sind relativ fair, da sie pro Aufgabe abrechnen. Ihr Abonnement bestimmt also die Anzahl der Aufgaben, die Sie ausführen können.
Planen
Preise
Aufgabe
Kostenlose Testversion
Frei
10
Standard
119 $
100
Prämie
299 $
250
Trotz der fairen Preise ist Octoparse im Vergleich zu ScraperAPI für mittlere und große Projekte immer noch nicht kosteneffektiv. Der kostenlose Plan von ScraperAPI bietet 5.000 API-Credits, sodass Sie bis zu 5.000 URLs ohne umfangreiche Anti-Bots scrapen können.
Der günstigste Plan von ScraperAPI bietet Geo-Targeting-Funktionen für die USA und die EU für standortbezogene Aufgaben, um Ihnen beim Extrahieren von Daten von bestimmten Standorten zu helfen.
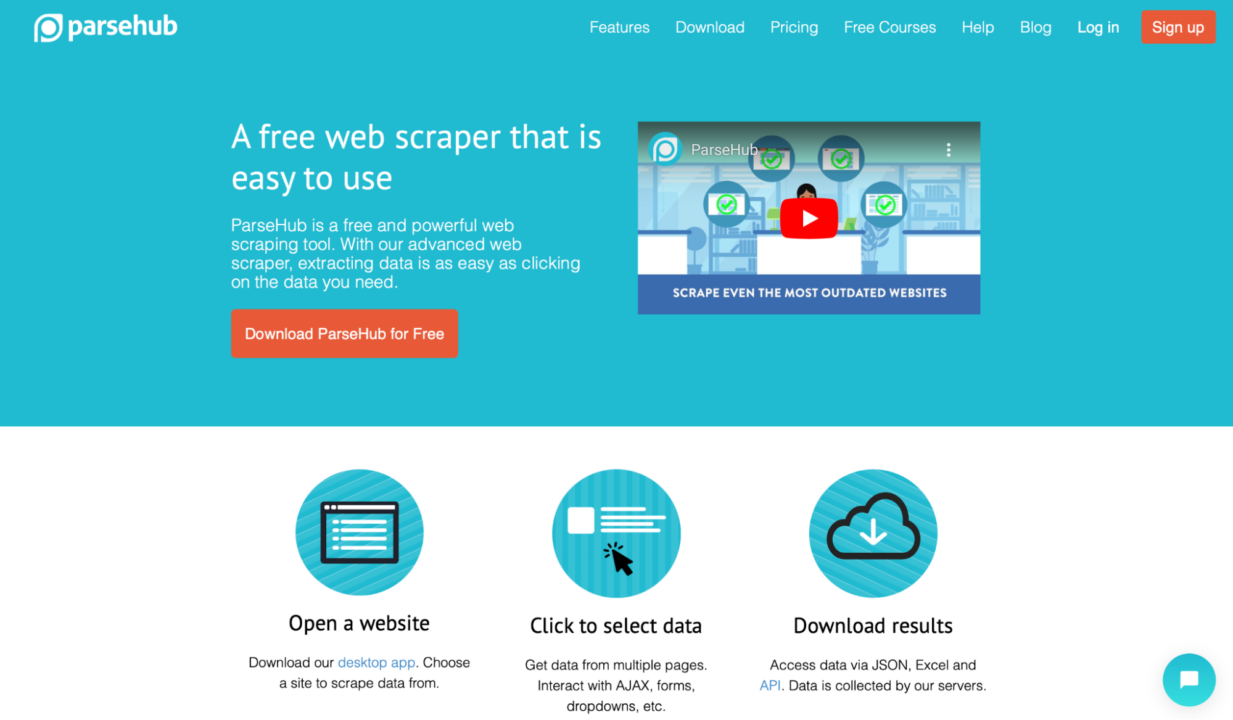
Für wen ist das: ParseHub ist ein leistungsstarkes Tool zum Erstellen von Web-Scrapern ohne Codierung – Analysten, Journalisten, Datenwissenschaftler und alle dazwischen nutzen es.
Warum Sie es verwenden sollten: ParseHub ist äußerst einfach zu bedienen. Die automatische IP-Rotation sorgt dafür, dass Ihre Scraping-Aktivitäten unentdeckt bleiben und bietet Ihnen zuverlässigen Zugriff auf die benötigten Daten, selbst von Websites mit strengen Zugriffskontrollen. Sie können Web-Scraper erstellen, indem Sie einfach auf die gewünschten Daten klicken. ParseHub exportiert die Daten dann im JSON- oder Excel-Format. Es verfügt über viele praktische Funktionen, wie zum Beispiel die automatische IP-Rotation, das Scraping von Webseiten hinter Login-Walls, das Durchsuchen von Dropdown-Listen und Registerkarten, das Abrufen von Daten aus Tabellen und Karten und vieles mehr.
Darüber hinaus gibt es ein großzügiges kostenloses Kontingent, mit dem Benutzer in nur 40 Minuten bis zu 200 Seiten Daten durchsuchen können! ParseHub ist auch deshalb nett, weil es Desktop-Clients für Windows, Mac OS und Linux bereitstellt, sodass Sie sie von Ihrem Computer aus verwenden können, egal welches System Sie verwenden.
Vorteile
Benutzerfreundlichkeit für einfache Aufgaben: ParseHub verfügt über eine benutzerfreundliche Oberfläche, die ein einfaches Web-Scraping ermöglicht, ohne dass viel technisches Fachwissen erforderlich ist.
Automatisierungsfunktionen: ParseHub verfügt über nützliche Automatisierungsfunktionen wie Planung und dynamisches Page Scraping, die es Benutzern ermöglichen, komplexe Websites mit mehreren Datenebenen zu scrapen
Kostenlose Version: Es bietet eine robuste kostenlose Version, die es für diejenigen zugänglich macht, die seine Funktionen ausprobieren möchten, bevor sie sich für einen kostenpflichtigen Plan entscheiden. Darin enthalten sind bis zu 200 Seiten pro Auflage und 5 öffentliche Projekte.
Kostengünstige Skalierbarkeit: Es bietet mehrere Preisstufen, darunter den Standardplan für 189 $/Monat, der bis zu 10.000 Seiten pro Auflage ermöglicht, und einen Professional-Plan mit erweiterten Funktionen wie schnellerem Scraping und vorrangigem Support.
Nachteile
Support-Einschränkungen: Es gab Beschwerden darüber, dass der Kundensupport stärker verkaufsorientiert sei und sich weniger auf die Lösung von Problemen konzentriere, insbesondere bei Benutzern, die kostenlose Testversionen nutzen.
Muss installiert werden: Wenn die Abstreifer lokal auf Ihrer Maschine laufen, bedeutet das, dass Sie eine größere Investition in die Ausrüstung benötigen, um Ihren Betrieb auszubauen.
Anpassungsgrenzen: Da es sich um eine Low-Code-Plattform handelt, ist sie restriktiver als dedizierte Scraping-APIs.
Bewertungen
Trustpilot-Bewertung – Null
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Die ParseHub-Preise basieren auf Geschwindigkeit und Seiten. Je höher Ihr Abonnement, desto mehr Seiten können Sie scrapen.
Planen
Preise
Seiten
Kostenlose Testversion
Frei
200 Seiten pro Durchlauf in 40 Minuten
Standard
189 $
10.000 Seiten pro Durchlauf (200 Seiten in 10 Minuten)
Professional
599 $
Unbegrenzt in weniger als 2 Minuten
ParseHub Plus
Brauch
Brauch
Basierend auf der Anzahl der Seiten ist scraperAPI wirtschaftlicher, da Sie mit dem niedrigsten Plan mit 100.000 API-Credits – 49 US-Dollar pro Monat – problemlos über 10.000 Seiten erhalten.
5. Scrapy (Crawling und Scraping der Python-Bibliothek)
Für wen ist das: Scrapy ist eine Open-Source-Web-Scraping-Bibliothek für Python-Entwickler, die skalierbare Webcrawler erstellen möchten. Es handelt sich um ein umfassendes Framework, das alle Installationen (Warteschlangenanforderungen, Proxy-Middleware usw.) verwaltet, die die Erstellung von Webcrawlern erschweren.
Warum Sie es verwenden sollten: Als Open-Source-Tool ist Scrapy völlig kostenlos. Sie ist kampferprobt und seit Jahren eine der beliebtesten Python-Bibliotheken. Es gilt als das beste Python-Web-Scraping-Tool für neue Anwendungen. Es gibt eine Lernkurve, die jedoch gut dokumentiert ist und es stehen zahlreiche Tutorials zur Verfügung, die Ihnen den Einstieg erleichtern.
Darüber hinaus ist der Einsatz der Crawler sehr einfach und zuverlässig. Sobald sie eingerichtet sind, können die Prozesse selbstständig ablaufen. Als voll funktionsfähiges Web-Scraping-Framework stehen viele Middleware-Module zur Verfügung, um verschiedene Tools zu integrieren und verschiedene Anwendungsfälle (Umgang mit Cookies, Benutzeragenten usw.) abzuwickeln.
Vorteile
Kriechen und Kratzen mit hoher Geschwindigkeit: Scrapy ist für seine Schnelligkeit bei der Abwicklung groß angelegter Web-Scraping-Projekte bekannt. Es ist mit asynchroner Netzwerkunterstützung ausgestattet, was bedeutet, dass mehrere Anfragen gleichzeitig gesendet werden können, wodurch Leerlaufzeiten reduziert werden. Dies macht es äußerst effizient bei der Extraktion großer Datenmengen von Websites in kurzer Zeit.
Fähigkeit zur Datenextraktion im großen Maßstab: Mit Scrapy können Sie riesige Datenmengen scrapen. Dank der Fähigkeit, verteilte Crawler zu verwalten, können Sie Ihre Projekte skalieren, indem Sie mehrere Spider gleichzeitig ausführen. Dies macht Scrapy ideal für Scraping-Projekte auf Unternehmensebene, bei denen täglich Tausende von Seiten gecrawlt werden müssen.
Speichereffiziente Prozesse: Scrapy nutzt eine effiziente Speicherverwaltung, um umfangreiche Web-Scraping-Aufgaben mit minimalem Ressourcenverbrauch zu verwalten. Im Gegensatz zu browserbasierten Scrapern lädt Scrapy keine vollständigen HTML-Seiten und rendert kein JavaScript, wodurch die Speichernutzung niedrig bleibt und eine große Anzahl von Anfragen ohne Leistungseinbußen verarbeitet werden kann.
Hochgradig anpassbar und erweiterbar: Die modulare Architektur von Scrapy ermöglicht es Entwicklern, ihre Scraping-Projekte einfach anzupassen. Sie können die Kernfunktionen von Scrapy ändern oder erweitern, Bibliotheken von Drittanbietern integrieren oder sogar benutzerdefinierte Middleware und Pipelines erstellen, um spezifischen Projektanforderungen gerecht zu werden. Diese Flexibilität macht es ideal für Benutzer, die eine genaue Kontrolle über ihre Schabevorgänge wünschen.
Nachteile
Unterstützt kein dynamisches Content-Rendering: Scrapy hat Probleme mit Websites, die JavaScript zum Rendern dynamischer Inhalte verwenden. Da es sich um einen HTML-Parser und nicht um einen vollständigen Browser handelt, kann Scrapy nicht mit JavaScript-gesteuerten Elementen interagieren.
Steile Lernkurve: Scrapy wurde speziell für Entwickler entwickelt, was es für Anfänger zu einer Herausforderung machen kann. Es erfordert ein solides Verständnis von Python, Web-Scraping-Techniken und asynchroner Programmierung. Für diejenigen, die neu im Web Scraping sind oder keine ausgeprägten technischen Kenntnisse haben, kann die Beherrschung von Scrapy viel Zeit und Mühe kosten.
Bewertung
Pro Github-Stern – 52,5.000
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Preise
Frei
Verwandt: So scrapen Sie Websites mit Scrapy und ScraperAPI.
Für wen ist das: Diffbot ist eine Unternehmenslösung für Unternehmen mit hochspezialisierten Daten-Crawling- und Screen-Scraping-Anforderungen, insbesondere für diejenigen, die Websites crawlen, deren HTML-Struktur häufig geändert wird.
Warum Sie es verwenden sollten: Diffbot unterscheidet sich von den meisten Webseiten-Scraping-Tools dadurch, dass es Computer Vision (anstelle von HTML-Parsing) verwendet, um relevante Informationen auf einer Seite zu identifizieren. Das bedeutet, dass Ihre Web-Scraper nicht kaputt gehen, selbst wenn sich die HTML-Struktur einer Seite ändert, solange die Seite optisch gleich aussieht. Dies ist eine unglaubliche Funktion für lang andauernde, geschäftskritische Web-Scraping-Jobs.
Diffbot ist teuer (der günstigste Plan kostet 299 $/Monat), aber sie leisten hervorragende Arbeit und bieten einen Premium-Service, der sich für Großkunden möglicherweise lohnt.
Vorteile
Automatisierte Datenextraktion mit KI: Diffbot nutzt KI, um strukturierte Daten aus unstrukturierten Webseiten zu analysieren und zu extrahieren, sodass keine manuelle Codierung erforderlich ist. Es kann bestimmte Inhaltstypen wie Artikel, Produkte, Bilder usw. automatisch erkennen und extrahieren. Dies macht es äußerst effizient für groß angelegte Datenextraktionsprojekte, ohne dass benutzerdefinierte Scraper entwickelt werden müssen.
Unterstützt dynamische Inhalte: Im Gegensatz zu einigen Web-Scraping-Tools ist Diffbot in der Lage, dynamische Inhalte zu verarbeiten, die von JavaScript generiert werden. Dies ist besonders nützlich für Websites, die Inhalte dynamisch laden oder auf clientseitiges Rendering angewiesen sind.
Umfangreiche API-Unterstützung: Diffbot bietet mehrere APIs für unterschiedliche Datenextraktionsanforderungen, einschließlich seiner Knowledge Graph API, die es Benutzern ermöglicht, strukturierte Daten über eine Vielzahl von Domänen hinweg abzufragen und abzurufen. Es bietet außerdem Artikel-, Produkt- und Bild-APIs, was es vielseitig für das Scrapen verschiedener Inhaltstypen von Websites macht.
Nachteile
Hohe Kosten: Die erweiterten Funktionen und der Unternehmensfokus von Diffbot haben einen Premium-Preis. Für kleine Betriebe oder einzelne Benutzer können die Kosten unerschwinglich sein. Das Preismodell ist nutzungsbasiert, was bedeutet, dass ein höheres Anfragevolumen zu erheblichen Kosten führen kann, sodass es für Low-Budget- oder kleine Projekte weniger geeignet ist.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Die Preise von Diffbot ähneln denen von ScraperAPI, da sie auf Guthaben basieren, Diffbot jedoch nicht pro erfolgreicher Anfrage abrechnet.
Wie Sie in der Tabelle und dem Bild unten sehen können, kostet Diffbot 299 US-Dollar für 250.000 Credits, was 250.000 Seiten (erfolgreich oder nicht) bei 1 Credit pro Seite entspricht.
Andererseits bietet ScraperAPI 1 Mio. API-Credits für nur 149 US-Dollar, sodass Sie auf 1 Mio. erfolgreiche Anfragen/Seiten zugreifen können.
Planen
Preise
Kredit
Frei
Frei
10.000 Credits (0 $ pro Credit)
Start-up
299 $
250.000 Credits (0,001 $ pro Credit)
Plus
899 $
1.000.000 Credits (0,0009 $ pro Credit)
Unternehmen
Brauch
Brauch
7. Cheerio (HTML-Parser für Node.js)
Für wen ist das: NodeJS-Entwickler, die eine unkomplizierte Möglichkeit zum Parsen von HTML suchen. Wer mit jQuery vertraut ist, wird die beste verfügbare JavaScript-Web-Scraping-Syntax sofort zu schätzen wissen.
Warum Sie es verwenden sollten: Cheerio bietet eine API ähnlich wie jQuery, sodass sich Entwickler, die mit jQuery vertraut sind, sofort zu Hause fühlen werden, wenn sie Cheerio zum Parsen von HTML verwenden. Es ist rasend schnell und bietet viele hilfreiche Methoden zum Extrahieren von Text, HTML, Klassen, IDs usw.
Es ist mit Abstand die beliebteste in NodeJS geschriebene HTML-Parsing-Bibliothek und wahrscheinlich das beste NodeJS- oder JavaScript-Web-Scraping-Tool für neue Projekte.
Vorteile
Leicht und schnell: Cheerio ist eine schnelle und effiziente Bibliothek zum Parsen und Bearbeiten von HTML und XML. Da es kein JavaScript rendert oder einen Browser simuliert, arbeitet es mit minimalem Overhead und eignet sich daher ideal für Aufgaben, die nur statischen HTML-Inhalt umfassen.
jQuery-ähnliche Syntax: Eine der herausragenden Funktionen von Cheerio ist seine jQuery-ähnliche Syntax, die es Entwicklern, die mit jQuery vertraut sind, erleichtert, schnell mit Cheerio zu beginnen. Die Manipulation von DOM-Elementen im jQuery-Stil macht das Scrapen und Extrahieren von Daten einfach und intuitiv.
Flexibel und erweiterbar: Sie können Cheerio problemlos in andere Tools und APIs integrieren. Aufgrund seines modularen Aufbaus passt es in benutzerdefinierte Scraping-Pipelines und ist somit an eine Vielzahl von Web-Scraping-Anforderungen anpassbar.
Nachteile
Bedarf an zusätzlichen Werkzeugen für komplexere Schabearbeiten: Während Cheerio für grundlegende Scraping-Aufgaben leichtgewichtig und effizient ist, erfordert die Bewältigung komplexerer Szenarien wie der Interaktion mit dynamischen Elementen oder der Umgehung von Anti-Scraping-Maßnahmen die Kombination mit fortschrittlicheren Tools. Dies erhöht die Komplexität der Scraping-Einrichtung und des Arbeitsablaufs.
Eingeschränkte Unterstützung für JavaScript-lastige Websites: Cheerio führt kein JavaScript aus, daher werden Inhalte, die von der clientseitigen JavaScript-Ausführung abhängen, nicht erfasst. Diese Einschränkung erfordert die Integration zusätzlicher Tools wie Puppeteer oder Selenium, die eine echte Browserumgebung simulieren können.
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Bewertung
Preise
Frei
Verwandt: So durchsuchen Sie HTML-Tabellen mit Axios und Cheerio.
8. BeautifulSoup (HTML-Parser für Python)
Für wen ist das: Python-Entwickler, die einfach nur eine einfache Schnittstelle zum Parsen von HTML wünschen und nicht unbedingt die Leistung und Komplexität von Scrapy benötigen.
Warum Sie es verwenden sollten: Wie Cheerio für NodeJS-Entwickler ist BeautifulSoup der beliebteste HTML-Parser für Python-Entwickler. Es gibt sie nun schon seit über einem Jahrzehnt und sie ist äußerst gut dokumentiert. In vielen Web-Parsing-Tutorials wird Entwicklern beigebracht, wie man damit verschiedene Websites in Python 2 und Python 3 durchsucht. Wenn Sie nach einer Python-HTML-Parsing-Bibliothek suchen, ist dies genau das Richtige für Sie du willst.
Vorteile
Einfach zu bedienen und zu erlernen: BeautifulSoup verfügt über eine einfache und intuitive API, wodurch es sowohl für Anfänger als auch für erfahrene Entwickler zugänglich ist. Es ermöglicht Ihnen, HTML- und XML-Dokumente einfach zu analysieren und Daten mit minimalem Code zu extrahieren.
Flexibel mit Parsern: BeautifulSoup ist mit mehreren Parsern kompatibel, beispielsweise dem integrierten HTML-Parser von Python, lxml und html5lib. Dank dieser Flexibilität können Sie den Parser auswählen, der Ihren Anforderungen am besten entspricht, unabhängig davon, ob es um Geschwindigkeit oder Vollständigkeit beim Umgang mit schlecht formatiertem HTML geht.
Integration mit anderen Bibliotheken: BeautifulSoup lässt sich gut in andere Python-Bibliotheken wie Requests und LXML integrieren und erleichtert so die Einrichtung umfassender Scraping-Pipelines zum Abrufen und Verarbeiten von Daten von Websites.
Behandelt unvollständiges HTML: BeautifulSoup ist für seine Robustheit im Umgang mit schlecht strukturiertem oder fehlerhaftem HTML bekannt. Es korrigiert automatisch Fehler in HTML-Dokumenten und erleichtert so das Scrapen von Websites mit inkonsistentem Markup.
Nachteile
Keine JavaScript-Unterstützung: BeautifulSoup kann keine Websites verarbeiten, die zum Laden von Inhalten stark auf JavaScript angewiesen sind. Da es mit statischem HTML funktioniert, ist der Zugriff auf dynamische, mit JavaScript generierte Inhalte ohne die Integration zusätzlicher Tools wie Selenium nicht möglich.
Manueller Aufwand für komplexe Aufgaben erforderlich: BeautifulSoup eignet sich gut für einfache HTML-Parsing-Aufgaben, erfordert jedoch mehr manuelle Codierung, um komplexe Aufgaben wie Paginierung, Proxy-Verwaltung oder Umgehung von Anti-Scraping-Maßnahmen zu bewältigen.
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Bewertung
Preise
Frei
Verwandt: Scraping von HTML-Websites mit BeautifulSoup und ScraperAPI.
9. Puppeteer (Headless Chrome API für Node.js)
Für wen ist das: Puppeteer ist eine Headless-Chrome-API für NodeJS-Entwickler, die eine detaillierte Kontrolle über ihre Scraping-Aktivitäten wünschen.
Warum Sie es verwenden sollten: Puppeteer ist ein Open-Source-Tool, das völlig kostenlos ist. Es wird gut unterstützt, aktiv weiterentwickelt und vom Google Chrome-Team unterstützt. Es ersetzt schnell Selenium und PhantomJS als standardmäßiges Headless-Browser-Automatisierungstool.
Es verfügt über eine durchdachte API und installiert im Rahmen des Einrichtungsprozesses automatisch eine kompatible Chromium-Binärdatei, sodass Sie nicht selbst den Überblick über die Browserversionen behalten müssen.
Obwohl es sich um viel mehr als nur eine Web-Crawling-Bibliothek handelt, wird sie häufig zum Auslesen von Website-Daten von Websites verwendet, die JavaScript zum Anzeigen von Informationen benötigen.
Es verarbeitet Skripte, Stylesheets und Schriftarten wie ein echter Browser. Es ist zwar eine hervorragende Lösung für Websites, die JavaScript zum Anzeigen von Daten benötigen, ist aber auch sehr CPU- und speicherintensiv. Daher ist es keine gute Idee, es für Websites zu verwenden, auf denen ein vollwertiger Browser nicht erforderlich ist. In den meisten Fällen reicht eine einfache GET-Anfrage aus!
Vorteile
Headless-Browser-Automatisierung: Mit Puppeteer können Sie Chrome oder Chromium im Headless-Modus steuern, was es ideal für Automatisierungsaufgaben wie Web Scraping, UI-Tests und das Generieren von PDFs aus Webseiten macht.
Plattformübergreifend: Puppeteer funktioniert auf mehreren Plattformen (Linux, macOS, Windows) und unterstützt sowohl Headless- als auch Non-Headless-Modi, was es für eine Reihe von Anwendungsfällen vielseitig macht, von der lokalen Entwicklung bis zur Bereitstellung in Cloud-Umgebungen.
Nachteile
Ressourcenintensiv: Das Ausführen von Headless-Chrome-Instanzen kann ressourcenintensiv sein, insbesondere bei der Skalierung von Scraping-Jobs oder Automatisierungsaufgaben. Es erfordert mehr CPU und Speicher im Vergleich zu einfachen Tools wie Cheerio oder nicht browserbasierten Scrapern.
Manuelle Einrichtung für erweiterte Anwendungsfälle: Puppeteer verfügt nicht über eine integrierte Planung, Datenextraktionsvorlagen oder Datenspeicherfunktionen. Sie müssen diese Prozesse manuell erstellen, was die Komplexität der Verwendung des Tools für umfangreiche Projekte erhöhen kann.
Es fehlen integrierte Scraping-Funktionen: Puppeteer ist ein Allzweck-Browser-Automatisierungstool und verfügt nicht über spezifische Web-Scraping-Optimierungen (z. B. Handhabung von CAPTCHAs oder IP-Rotation). Für das Scraping großer, geschützter Websites benötigen Sie zusätzliche Tools oder Dienste für Anti-Scraping-Bypass-Techniken wie ScraperAPI.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Preise
Frei
Verwandt: Scraping von Amazon mit Puppeteer und ScraperAPI.
10. Mozenda
Für wen ist das: Unternehmen, die nach einer cloudbasierten Self-Service-Webpage-Scraping-Plattform suchen, müssen nicht weiter suchen. Mit über 7 Milliarden gecrawlten Seiten verfügt Mozenda über Erfahrung in der Betreuung von Unternehmenskunden weltweit.
Warum Sie es verwenden sollten: Mozenda zeichnet sich durch seinen Kundenservice aus (der allen zahlenden Kunden sowohl Telefon- als auch E-Mail-Support bietet). Die Plattform ist hoch skalierbar und ermöglicht auch On-Premise-Hosting. Wie Diffbot ist es etwas teuer, wobei der niedrigste Plan bei 250 $/Monat beginnt.
Vorteile
Benutzerfreundliche Oberfläche: Mozenda ist für technisch nicht versierte Benutzer konzipiert und verfügt über eine intuitive Point-and-Click-Oberfläche, die das Einrichten und Ausführen von Scraping-Jobs ohne Programmieraufwand vereinfacht.
Automatisierung und Planung: Mozenda unterstützt die Planung und Automatisierung von Scraping-Aufgaben, sodass Sie wiederkehrende Jobs festlegen und Daten regelmäßig ohne manuelles Eingreifen scrapen können.
Flexibilität beim Datenexport: Mozenda bietet eine breite Palette an Datenexportoptionen, mit denen Sie Scraped-Daten in mehrere Formate wie CSV, Excel, XML oder direkt in eine Datenbank exportieren können. Es lässt sich auch in andere Datendienste integrieren.
Nachteile
Preise: Die Preise von Mozenda sind höher als bei einigen anderen Scraping-Tools, was für kleine Unternehmen oder Einzelpersonen mit begrenztem Budget ein Nachteil sein kann. Die Kosten steigen mit der Anzahl der gescrapten Seiten oder dem Grad der Datenkomplexität.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Die Preise von Mozenda sind auf der Website nicht klar angegeben, aber einem im Jahr 2018 veröffentlichten Preismodelldokument, das auch unten zu sehen ist, ist die Preisgestaltung von Mozenda kreditbasiert und im Vergleich zu Wettbewerbern wie ScraperAPI recht teuer.
Planen
Preise
Credits
Lagerung
Basic
99 $/Monat
Projekt
300 $/Monat
20.000
1 GB
Professional
400 $/Monat
35.000
5 GB
Unternehmen
450 $/Monat (jährliche Abrechnung)
1.000.000+ jährlich
50 GB
Hohe Kapazität
40.000 $/Jahr
Brauch
Brauch
Vor Ort
Brauch
Brauch
Brauch
11. ScrapeHero Cloud (cloudbasierte, für Sie erstellte Scraping-Dienste)
Für wen ist das: ScrapeHero ist cloudbasiert und benutzerfreundlich, was es ideal macht, wenn Sie kein Programmierer sind. Sie müssen lediglich die Eingaben vornehmen und auf „Daten sammeln“ klicken. Sie verfügen über umsetzbare Daten in den Formaten JSON, CSV oder Excel.
Warum Sie es verwenden sollten: ScrapeHero hat ein browserbasiertes, automatisiertes Scraping-Tool entwickelt, mit dem Sie mit nur wenigen Klicks alles, was Sie im Internet haben möchten, in Tabellenkalkulationen herunterladen können. Es ist günstiger als die Vollservices und es gibt eine kostenlose Testversion. Es verwendet vorgefertigte Crawler mit automatisch rotierenden Proxys. Echtzeit-APIs erfassen Daten von einigen der größten Online-Händler und -Dienste, darunter Karten, Produktpreise, aktuelle Nachrichten und mehr. Dieses Data-as-a-Service-Tool ist perfekt für Unternehmen, insbesondere für diejenigen, die sich für KI interessieren.
Vorteile
Anpassbare Lösungen: ScrapeHero bietet vollständig anpassbare Web-Scraping-Lösungen, die auf die spezifischen Bedürfnisse von Unternehmen zugeschnitten sind. Dadurch können Sie unabhängig von der Komplexität oder Größe der Website genau die Daten sammeln, die sie benötigen.
Keine Codierung erforderlich: ScrapeHero ist benutzerfreundlich und erfordert keine technischen Kenntnisse. Unternehmen können benutzerdefinierte Daten extrahieren, ohne dass interne Entwickler oder technisches Fachwissen erforderlich sind.
Nachteile
Höhere Kosten für kundenspezifische Lösungen: Während ScrapeHero eine Reihe von Preisplänen anbietet, können seine individuellen Daten-Scraping-Dienste im Vergleich zu DIY-Tools oder -Plattformen teuer sein, insbesondere für Unternehmen mit kleineren Budgets oder begrenztem Scraping-Bedarf.
Eingeschränkte Self-Service-Funktionen: Wenn Sie nach einem Self-Service-Tool zum manuellen Einrichten und Ausführen von Scraping-Jobs suchen, ist ScrapeHero möglicherweise nicht ideal. Es ist eher für verwaltete Dienste konzipiert, was die Flexibilität für diejenigen einschränken kann, die die volle Kontrolle über ihre Scraping-Prozesse wünschen.
Bewertung
Trustpilot-Bewertung – 3,7
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Aus dem Bild oben können Sie ersehen, dass das Preismodell von ScrapeHero auf der Anzahl der Seiten basiert, die Sie scrapen möchten. Dies macht es kostengünstig, wenn Sie eine kleinere Anzahl von Seiten durchschaben möchten. Andererseits bietet ScraperAPI mehr API-Anfragen zu einem niedrigeren Startpreis, was es zu einer besseren Option für große Scraping-Projekte macht.
12. Webscraper.io (Point-and-Click-Chrome-Erweiterung für Web-Scraping)
Für wen ist das: Eine weitere benutzerfreundliche Option für Nicht-Entwickler, WebScraper.io, ist eine einfache Google Chrome-Browsererweiterung. Es ist nicht so umfassend ausgestattet wie die anderen Web-Scraping-Tools auf dieser Liste, aber es ist eine ideale Option für diejenigen, die mit kleineren Datenmengen arbeiten und nicht viel Automatisierung benötigen.
Warum Sie es verwenden sollten: WebScraper.io hilft Benutzern beim Einrichten einer Sitemap, um auf einer bestimmten Website zu navigieren und genau zu bestimmen, welche Informationen erfasst werden. Das zusätzliche Plugin kann mehrere JS- und Ajax-Seiten gleichzeitig verarbeiten, und Entwickler können ihre Scraper so erstellen, dass sie Daten direkt aus dem Browser in CVS oder aus der Cloud von Web Scraper in CVS, XLSX und JSON extrahieren. Sie können auch regelmäßige Scrapes mit regelmäßiger IP-Rotation planen. Die Browser-Erweiterung ist kostenlos, aber Sie können die kostenpflichtigen Dienste mit einer kostenlosen Testversion testen.
Vorteile
Cloudbasiertes Scraping: Webscraper.io ist ein browserbasiertes Daten-Scraping-Tool, mit dem Sie Scraping-Aufgaben im Hintergrund ausführen können, ohne lokale Ressourcen zu binden. Dadurch können Sie auch große Datenmengen effizient durchsuchen.
Erschwingliche Preise: Webscraper.io verfügt über verschiedene Preispläne, darunter einen kostenlosen Plan, wodurch es für Benutzer mit unterschiedlichen Bedürfnissen und Budgets zugänglich ist. Dadurch können Sie die Plattform ohne nennenswerte Vorabkosten nutzen.
Nachteile
Beschränkt auf die Chrome-Erweiterung: Webscraper.io ist nur als Chrome-Erweiterung verfügbar, was seine Benutzerfreundlichkeit einschränkt. Es fehlt auch ein dedizierter Desktop oder eine eigenständige Anwendung, was ein Nachteil sein könnte, wenn Sie Chrome nicht verwenden.
Einschränkungen des kostenlosen Plans: Der kostenlose Plan ist zwar nützlich, schränkt jedoch die Anzahl der Seiten und Daten, die gescrapt werden, erheblich ein. Bei Großprojekten müssen Sie sich für einen der kostenpflichtigen Tarife entscheiden.
Bewertung
Trustpilot-Bewertung – 3,7
Benutzerfreundlichkeit
⭐⭐⭐(3/5)
Preise
Webscraper.io ist eines der günstigsten Web-Scraping-Tools auf dem Markt. Es gibt einen kostenlosen Plan mit einem Startpreis von 50 $. Diese Preisgestaltung basiert auf Cloud-Guthaben, wobei 1 Cloud-Guthaben = 1 Seite ist.
Planen
Preis
Cloud-Guthaben
Browser-Erweiterung
Frei
Nill (nur lokale Verwendung)
Projekt
50 $
5.000
Professional
100 $
20.000
Geschäft
200 $
50.000
Skala
200 $+
Unbegrenzt
13. Kimura
Für wen ist das: Kimura ist ein in Ruby geschriebenes Open-Source-Web-Scraping-Framework. Es macht es unglaublich einfach, einen Ruby Web Scraper zum Laufen zu bringen.
Warum Sie es verwenden sollten: Kimura wird schnell als beste Ruby-Web-Scraping-Bibliothek anerkannt. Es ist so konzipiert, dass es sofort mit Headless Chrome/Firefox, PhantomJS und normalen GET-Anfragen funktioniert. Seine Syntax ähnelt Scrapy, und Entwickler, die Ruby-Web-Scraper schreiben, werden die netten Konfigurationsoptionen zum Festlegen einer Verzögerung, zum Rotieren von Benutzeragenten und zum Festlegen von Standard-Headern lieben.
Vorteile
Rubinbasiert: Kimurai ist in Ruby erstellt, was für Entwickler von Vorteil ist, die mit der Programmiersprache Ruby vertraut sind. Es bietet ein Framework zum Schreiben von Web-Scrapern in Ruby und erleichtert Ruby-Entwicklern die Integration von Scraping in ihre Projekte.
Integrierte Web-Scraping-Tools: Kimurai verfügt über integrierte Scraping-Tools wie Sitzungsverwaltung, automatische Wiederholungsversuche, Anforderungsverzögerungen und Proxy-Unterstützung. Dies reduziert die Notwendigkeit, zusätzliche Tools oder Bibliotheken manuell zu integrieren, was den Scraping-Prozess vereinfacht.
Open Source: Da es sich um eine Open-Source-Lösung handelt, kann Kimurai kostenlos verwendet werden und der Quellcode kann geändert werden. Dies macht es zu einer kostengünstigen Lösung für Entwickler, die Web-Scraping-Anwendungen erstellen möchten.
Nachteile
Einschränkung des Ruby-Ökosystems: Kimurai ist in Ruby erstellt, einer im Vergleich zu Python weniger häufig verwendeten Sprache für Web Scraping. Dies schränkt die Community-Unterstützung und die verfügbaren Ressourcen ein, insbesondere im Vergleich zu weit verbreiteten Scraping-Frameworks wie BeautifulSoup in Python.
Eingeschränkte Dokumentation: Obwohl Kimurai ein leistungsstarkes Tool ist, ist seine Dokumentation nicht so umfangreich wie bei anderen gängigen Frameworks, was den Einstieg für Neueinsteiger erschwert.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (3/5)
Preise
Frei
14. Goutte
Für wen ist das: Goutte ist ein in PHP geschriebenes Open-Source-Webcrawler-Framework, was es äußerst nützlich für Entwickler macht, die Daten aus HTML/XML-Antworten mit PHP extrahieren möchten.
Warum Sie es verwenden sollten: Goutte ist ein sehr unkompliziertes, schnörkelloses Framework, das viele für die beste PHP-Web-Scraping-Bibliothek halten. Es ist auf Einfachheit ausgelegt und bewältigt die meisten HTML/XML-Anwendungsfälle ohne allzu großen zusätzlichen Aufwand.
Es lässt sich außerdem nahtlos in die hervorragende Guzzle-Anforderungsbibliothek integrieren, mit der Sie das Framework für komplexere Anwendungsfälle anpassen können.
Vorteile
PHP-Integration: Als PHP-basiertes Tool ist Goutte eine großartige Option für Entwickler, die bereits mit dem PHP-Ökosystem vertraut sind. Es lässt sich gut in PHP-Anwendungen integrieren und kann in vorhandenen Frameworks wie Laravel oder Symfony verwendet werden.
Kopfloses Schaben: Goutte benötigt keine Browser-Engine, was es viel schneller und weniger ressourcenintensiv macht als browserbasierte Scraper wie Puppeteer oder Selenium. Es ist effizient zum Scrapen statischer Websites, die nicht stark auf JavaScript angewiesen sind.
Verwendet Symfony-Komponenten: Goutte nutzt leistungsstarke Symfony-Komponenten wie DomCrawler und BrowserKit und ist damit eine robuste Option zum programmgesteuerten Navigieren und Scrapen von HTML-Inhalten. Dies ermöglicht es Benutzern, Benutzeraktionen wie Formularübermittlungen, Linkklicken und Sitzungsverwaltung einfach zu simulieren.
Gut für statische Websites: Goutte zeichnet sich durch das Scraping statischer Inhalte aus. Für Websites, die nicht auf JavaScript zum dynamischen Laden von Daten angewiesen sind, schneidet Goutte in Bezug auf Geschwindigkeit und Effizienz außergewöhnlich gut ab.
Nachteile
Eingeschränkte JavaScript-Unterstützung: Goutte unterstützt kein JavaScript-Rendering, was bedeutet, dass es für das Scraping dynamischer Websites, die JavaScript zum Laden von Inhalten verwenden, unwirksam ist. Diese Einschränkung macht es ungeeignet für das Scraping moderner Single-Page-Anwendungen (SPAs) oder JavaScript-lastiger Websites.
PHP-Abhängigkeit: Da es sich um ein PHP-basiertes Tool handelt, ist seine Verwendung in PHP-Umgebungen eingeschränkt. Dies ist möglicherweise nicht ideal für Entwickler, die in anderen Sprachen arbeiten oder einen sprachunabhängigeren Ansatz für Web Scraping bevorzugen, wie z. B. die Verwendung von Python mit Scrapy oder BeautifulSoup.
Nicht ideal für großflächiges Schaben: Während Goutte für kleinere Scraping-Aufgaben effizient ist, ist es nicht für die Abwicklung großer Projekte optimiert, die eine hohe Parallelität oder verteiltes Scraping über mehrere Maschinen erfordern. Robustere Frameworks wie Scrapy oder Puppeteer eignen sich besser für solche Projekte.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (3/5)
Preise
Frei
Welche Faktoren sollten Sie bei der Auswahl von Web-Scraping-Tools berücksichtigen?
Der Auswahlprozess muss sich an bestimmten technischen und praktischen Kriterien orientieren, wenn es darum geht, potenzielle Web-Scraper zu bewerten, die Sie Ihrem Arsenal hinzufügen möchten.
Folgende Faktoren sollten geprüft werden:
Datenextraktionsfunktionen: Ein gutes Web-Scraping-Tool unterstützt verschiedene Datenformate und kann Inhalte aus verschiedenen Webstrukturen extrahieren, einschließlich statischer HTML-Seiten und dynamischer Websites mithilfe von JavaScript.
Benutzerfreundlichkeit: Bewerten Sie die Lernkurve, die Benutzeroberfläche und die verfügbare Dokumentation des Tools. Wer es nutzt, sollte die Komplexität des Tools verstehen.
Skalierbarkeit: Überlegen Sie, wie gut das Tool die Datenextraktion in großem Maßstab bewältigt. Sowohl die Skalierbarkeit der Leistung als auch die Fähigkeit, sich an steigende Datenmengen oder Anforderungen anzupassen, sind von entscheidender Bedeutung.
Automatisierungsfunktionen: Prüfen Sie den Grad der verfügbaren Automatisierung. Suchen Sie nach Planungsfunktionen, automatisierter Handhabung von CAPTCHA und der Möglichkeit, Cookies und Sitzungen automatisch zu verwalten.
IP-Rotation und Proxy-Unterstützung: Das Tool sollte eine robuste Unterstützung für IP-Rotation und Proxy-Verwaltung bieten, um eine Blockierung zu vermeiden.
Fehlerbehandlung und -behebung: Untersuchen Sie, wie das Tool mit Fehlern umgeht, z. B. unterbrochenen Verbindungen oder unerwarteten Site-Änderungen.
Integration mit anderen Systemen: Stellen Sie fest, ob sich das Tool nahtlos in andere Systeme und Plattformen integrieren lässt, z. B. Datenbanken, Cloud-Dienste oder Datenanalysetools. Auch die Kompatibilität mit APIs kann ein wesentlicher Vorteil sein.
Datenbereinigung und -verarbeitung: Suchen Sie nach integrierten oder einfach zu integrierenden Funktionen zur Datenbereinigung und -verarbeitung, um den Arbeitsablauf von Rohdaten zu nutzbaren Informationen zu optimieren.
Datenmanagement nach dem Scraping
Nach dem Scraping ist die Datenverwaltung ebenso wichtig wie die Extraktion. Für die Integration in Geschäftssysteme ist die Bereitstellung in verwendbaren Formaten wie CSV oder JSON erforderlich. Bei ScraperAPI haben wir dedizierte Endpunkte für beliebte Websites wie Amazon, Walmart und Google entwickelt, um Roh-HTML in gebrauchsfertige Datenpunkte umzuwandeln.
Der Speicher muss skalierbar und sicher sein und große Datensätze problemlos aufnehmen können. Die Reinigung ist unerlässlich, um Fehler und irrelevante Inhalte zu entfernen und die Genauigkeit sicherzustellen.
Verwandt: Datenbereinigung 101 für Web Scraping.
Schließlich ist die Integration in bestehende Systeme der Schlüssel für umsetzbare Erkenntnisse und die Ausrichtung von Datenformaten auf die Anforderungen von Analysetools oder CRM-Systemen. Durch effizientes Management werden Rohdaten zu einem wertvollen Gut, das Geschäftsstrategien unterstützen kann.
Abschließende Gedanken: Was ist das beste Web-Scraping-Tool?
Das offene Web ist bei weitem der bedeutendste globale Speicher für menschliches Wissen, und es gibt fast keine Informationen, die Sie nicht durch die Extraktion von Webdaten finden können. Es stehen viele Tools zur Verfügung, weil Web Scraping von Menschen mit unterschiedlichen technischen Fähigkeiten und Know-how durchgeführt wird. Es gibt Web-Data-Scraping-Tools, die jedem dienen – von Leuten, die keinen Code schreiben wollen, bis hin zu erfahrenen Entwicklern, die nur nach der besten Open-Source-Lösung in ihrer Sprache suchen.
Es gibt nicht das beste Web-Scraping-Tool – alles hängt von Ihren Bedürfnissen ab. Wir hoffen, dass Ihnen diese Liste von Scraping-Tools dabei geholfen hat, die besten Webdaten-Scraping-Tools und -Dienste für Ihre spezifischen Projekte oder Unternehmen zu finden.
Viele der oben genannten Scraping-Tools bieten kostenlose oder kostengünstige Testversionen an, sodass Sie sicherstellen können, dass sie für Ihren geschäftlichen Anwendungsfall funktionieren. Einige von ihnen werden zuverlässiger und effektiver sein als andere. Wenn Sie nach einem Tool suchen, das Datenanfragen in großem Umfang und zu einem guten Preis bearbeiten kann, wenden Sie sich an einen Vertriebsmitarbeiter, um sicherzustellen, dass er liefern kann – bevor Sie Verträge unterzeichnen.
Warum ist das Scrapen von Webdaten so wichtig?
Veraltete Erkenntnisse veranlassen ein Unternehmen dazu, Ressourcen ineffektiv einzusetzen oder neue Chancen zu verpassen. Stellen Sie sich vor, Sie würden sich bei der Preisgestaltung für den nächsten Monat auf die FMCG-Preisdaten der Woche vor einem Feiertag verlassen.
Webdaten können der Schlüssel zur Steigerung Ihres Umsatzes und/oder Ihrer Produktivität sein. Das moderne Internet ist extrem laut – Benutzer erzeugen täglich unglaubliche 2,5 Trillionen Bytes an Daten. Ganz gleich, ob Sie gerade dabei sind, Ihr Traumprojekt zu starten, oder ob Sie Ihr Unternehmen schon seit Jahrzehnten besitzen: Die Informationen in den Daten helfen Ihnen, potenzielle Kunden von Ihren Mitbewerbern abzuwerben und sie dazu zu bringen, wiederzukommen.
Web Scraping, also das Extrahieren wertvoller Daten aus dem Internet und deren Konvertierung in ein nützliches Format (z. B. eine Tabellenkalkulation), ist entscheidend, um zu verhindern, dass Ihr Unternehmen oder Produkt ins Hintertreffen gerät.
Webdaten können Ihnen fast alles sagen, was Sie über potenzielle Verbraucher wissen müssen, von den durchschnittlichen Preisen, die sie zahlen, bis hin zu den aktuellen Must-have-Funktionen. Allerdings bedeutet die schiere Menge an Daten über potenzielle Kunden, dass Sie den Rest Ihres Lebens damit verbringen könnten, manuell Daten zu extrahieren, und Sie würden nie aufholen. Hier kommen automatisierte Scraping-Tools ins Spiel. Der Prozess, sie zu finden, kann jedoch sehr einschüchternd sein.
Die Verwendung der besten Web-Scraping-Tools ist für den Erhalt hochwertiger Daten unerlässlich. Daher möchten Sie sicherstellen, dass Sie die besten Tools für die jeweilige Aufgabe erhalten.
Herausforderungen beim Daten-Scraping
Beim Versuch, Daten zu extrahieren, benötigen Unternehmen häufig Hilfe bei der Überwindung von Hindernissen, die technisches Fachwissen und strategische Problemlösung erfordern. Eine der ersten Hürden besteht darin, die richtige Seitenquelle zu erhalten.
Heutzutage sind Websites oft dynamisch und der Inhalt wird im Handumdrehen über JavaScript generiert. Das bedeutet, dass es nicht ausreicht, einfach den HTML-Code einer Seite anzufordern. Wir haben Fälle gesehen, in denen Scraping-Bemühungen zu unvollständigen oder falschen Daten führten, was alles darauf zurückzuführen war, dass die JavaScript-Wiedergabe nicht ordnungsgemäß verarbeitet wurde.
Verwandt: Erfahren Sie, wie Sie mit Python dynamische Inhalte von großen Websites extrahieren.
Eine weitere große Herausforderung entsteht dadurch, dass Websites aktiv versuchen, Scraping zu verhindern. Viele Websites setzen Maßnahmen wie CAPTCHA-Tests, IP-Blockierung oder Inhalte, die nur nach Benutzerinteraktion angezeigt werden, ein, um die automatisierte Datenextraktion zu verhindern. Entwickler mussten Wege finden, menschliches Verhalten nachzuahmen, beispielsweise durch die Einführung zufälliger Verzögerungen oder rotierender IP-Adressen, um den Scraper an diesen Abwehrmechanismen vorbeizubringen.
Auch nach der Überwindung dieser technischen Hürden ist die Arbeit damit noch nicht beendet. Aus verschiedenen Quellen extrahierte Daten liegen häufig in unterschiedlichen Formaten vor und erfordern eine umfassende Bereinigung und Normalisierung, bevor sie verwendet werden können. Zu den langfristigen Problemen gehört, dass sich das Layout der Website häufig ändert und Skripte kaputt gehen, die einmal perfekt funktionierten.
Nicht alle Webdaten sind ein faires Spiel zum Scrapen, und Unternehmen müssen sich in einer komplexen rechtlichen Landschaft aus Vorschriften und standortspezifischen Nutzungsbedingungen zurechtfinden. Das Potenzial für rechtliche Konsequenzen ist real und dieser Bereich erfordert sorgfältige Aufmerksamkeit.
Ohne ständige Überwachung kann ein Tool, das einst wertvolle Erkenntnisse lieferte, obsolet werden und Unternehmen für wesentliche Marktveränderungen blind machen.
Die besten Web-Scraping-Tools, die Sie in Betracht ziehen sollten
Um problemlos Daten von jeder Website zu extrahieren, benötigen Sie ein zuverlässiges Web-Scraping-Tool. Hier sind einige Schlüsselfaktoren, die Sie berücksichtigen sollten, bevor Sie das richtige Werkzeug für Ihr Projekt auswählen:
Geschwindigkeit und Effizienz: Wie schnell kann das Tool Daten scrapen?
Skalierbarkeit: Kann es große Schabeaufgaben bewältigen?
Preise: Ist es für Ihre Bedürfnisse kostengünstig?
Benutzerfreundlichkeit: Wie benutzerfreundlich ist die Oberfläche?
Fehlerbehandlung: Wie gut bewältigt das Tool Ausfälle oder Unterbrechungen?
Kundensupport: Ist reaktionsschneller Support verfügbar?
Anpassung: Bietet das Tool Flexibilität für spezifische Anforderungen?
Natürlich haben wir alle diese Faktoren bei der Auswahl unserer Top-Picks für diese Liste berücksichtigt, damit Sie sicher das richtige Web-Scraping-Tool für Ihr Projekt auswählen können.
Für alle, die es eilig haben, hier ein kurzer Überblick über die Web-Scraping-Tools auf der Liste:
Ruby-basiertes Web-Scraping-Framework mit Multi-Browser-Unterstützung
⭐⭐⭐
Github-Stern – 1k
Goutte
Frei
PHP-basiertes Web-Crawling-Framework für statische Websites
⭐⭐⭐
Github-Stern – 9,3k
1. ScraperAPI (Vollständige Scraping-Lösung für Entwicklerteams)
Für wen das ist: ScraperAPI ist ein Tool für Entwickler, die Web-Scraper erstellen. Es verwaltet Proxys, Browser und CAPTCHAs, sodass Entwickler mit einem einfachen API-Aufruf den rohen HTML-Code von jeder Website abrufen können. Die automatische Proxy-Verwaltung von ScraperAPI spart Zeit und reduziert das Risiko von IP-Verboten, wodurch ein unterbrechungsfreies Daten-Scraping gewährleistet wird.
Warum Sie es verwenden sollten: ScraperAPI belastet Sie nicht mit der Verwaltung Ihrer eigenen Proxys. Stattdessen verwaltet es seinen internen Pool aus Hunderttausenden Proxys von einem Dutzend verschiedener Proxy-Anbieter und verfügt über eine intelligente Routing-Logik, die Anfragen über verschiedene Subnetze weiterleitet.
Es drosselt außerdem automatisch Anfragen, um IP-Verbote und CAPTCHAs zu vermeiden – und sorgt so für eine hervorragende Zuverlässigkeit. Es ist der ultimative Web-Scraping-Dienst für Entwickler mit einzigartigen Pools an Premium-Proxys für E-Commerce-Preis-Scraping, Suchmaschinen-Scraping, Social-Media-Scraping, Sneaker-Scraping, Ticket-Scraping und mehr!
Einfach ausgedrückt hilft ScraperAPI Unternehmen dabei, in großem Umfang wertvolle Erkenntnisse zu gewinnen, sodass Sie sich letztendlich auf die Entscheidungsfindung statt auf die Datenextraktion konzentrieren können.
Notiz: Erfahren Sie, wie saas.group ScraperAPI verwendet, um Fusions- und Übernahmemöglichkeiten zu identifizieren.
Vorteile
Vollständige Scraping-Lösung: ScraperAPI bietet ein komplettes Web-Scraping-Paket, das die Proxy-Verwaltung, die CAPTCHA-Lösung und die Wiederholung von Anfragen automatisiert und so das Extrahieren von Daten von fast jeder Website erleichtert.
Erweiterte Bot-Blocker-Umgehung: Es umgeht effektiv fortschrittliche Anti-Bot-Lösungen wie DataDome und PerimeterX und sorgt so für höhere Erfolgsraten auf schwer zu scannenden Websites.
Strukturierte Endpunkte: Die vorgefertigten Endpunkte von ScraperAPI liefern saubere, strukturierte Daten, reduzieren den Zeitaufwand für das Parsen und die Datenbereinigung und steigern so die Produktivität.
Kostengünstig: Das einzigartige intelligente IP-Rotationssystem von ScraperAPI nutzt maschinelles Lernen und statistische Analysen, um den besten Proxy pro Anfrage auszuwählen; Indem Proxys nur bei Bedarf rotiert werden und private und mobile Proxys als sekundäre Optionen für fehlgeschlagene Anfragen verwendet werden, wird der Proxy-Overhead erheblich reduziert und ist damit günstiger als viele Mitbewerber.
Skalierbarkeitstools: Funktionen wie DataPipeline zum Planen wiederkehrender Aufgaben und Async Scraper für die asynchrone Bearbeitung großer Anforderungsmengen ermöglichen es Benutzern, Scraping-Aufwände effizient zu skalieren und zu automatisieren.
Nachteile
Reduzierte Anzahl strukturierter Datenendpunkte im Vergleich zu einigen Mitbewerbern.
Bewertungen
Der beste Weg, ein Tool zu identifizieren, das hält, was es verspricht, besteht darin, Rezensionen und Bewertungen des Tools zu überprüfen. ScraperAPI hat seine Position an der Spitze bisher behauptet. Hier finden Sie Bewertungen der wichtigsten Bewertungsplattformen.
Trustpilot-Bewertung – 4,7
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Ein gutes Scraping-Tool sollte einfach zu bedienen sein, sonst verfehlt es seinen Zweck, und ScraperAPI sticht in diesem Fall hervor, da die Bewertungen nicht lügen.
Schauen Sie sich gerne die tollen Rezensionen darüber an, wie ScraperAPI Ihre Aufgabe erleichtert.
Preise
Das ScraperAPI-Preismodell ist leicht verständlich und erschwinglich, da wir pro erfolgreicher Anfrage und nicht pro GB oder Bandbreite wie bei anderen Web-Scraping-Tools abrechnen.
Die Anzahl der verbrauchten Credits hängt von der Domain, dem Schutzniveau der Website und den spezifischen Parametern ab, die Sie in Ihrer Anfrage angeben.
ScraperAPI berechnet beispielsweise 5 API-Credits pro erfolgreicher Anfrage an E-Commerce-Domains wie Amazon und Walmart, sodass Sie ganz einfach die Anzahl der Seiten berechnen können, die Sie mit Ihrem Plan scrapen können.
Hier ist eine Aufschlüsselung des Preismodells von ScraperAPI:
Planen
Preise
API-Credits
Kostenlose Testversion (7 – Tage)
Frei
5000
Hobby
49 $
100.000
Start-up
149 $
1.000.000
Geschäft
299 $
3.000.000
Unternehmen
299 $ +
3.000.000 +
Besuchen Sie die Seite „Credits und Anfragen“ von ScraperAPI, um die Credit-Nutzung im Detail zu sehen.
2. ScrapeSimple (Web-Scraping-Outsourcing)
Für wen das ist: ScrapeSimple ist der perfekte Service für Leute, die ein maßgeschneidertes Web-Scraper-Tool für sich haben möchten. Es ist so einfach wie das Ausfüllen eines Formulars mit Anweisungen für die Art der gewünschten Daten.
Warum Sie es verwenden sollten: ScrapeSimple macht seinem Namen alle Ehre und steht ganz oben auf unserer Liste der einfachen Web-Scraping-Tools mit einem vollständig verwalteten Service, der benutzerdefinierte Web-Scraper für Kunden erstellt und verwaltet.
Sagen Sie ihnen einfach, welche Informationen Sie von welchen Websites benötigen, und sie entwerfen einen benutzerdefinierten Web-Scraper, der die Informationen regelmäßig (Sie können zwischen täglich, wöchentlich oder monatlich wählen) im CSV-Format direkt in Ihren Posteingang liefert.
Dieser Service ist perfekt für Unternehmen, die einfach nur einen HTML-Scraper benötigen, ohne selbst Code schreiben zu müssen. Die Reaktionszeiten sind kurz und der Service unglaublich freundlich und hilfsbereit, was ihn perfekt für Leute macht, die sich einfach um den gesamten Datenextraktionsprozess kümmern möchten.
Vorteile
Schnelle Bearbeitungszeit von 1 – 2 Tagen für kleine Projekte
Outsourcen Sie Dienstleistungen für Unternehmen, die nur nach Daten suchen
Für den Datenerfassungsprozess ist kein technisches Fachwissen erforderlich
Nachteile
Es ist teurer als ein DIY-Ansatz
Ihr Team benötigt weiterhin technisches Fachwissen, um mit den Daten zu arbeiten und sie zu analysieren
Bewertungen
Da es sich um einen Web-Scraping-Dienst handelt, gibt es keine erwähnenswerten G2- oder Trustpilot-Bewertungen.
Benutzerfreundlichkeit
⭐⭐⭐⭐(4/5)
Preise
ScrapeSimple hat keinen festen Preis. Stattdessen verlangen sie ein Mindestbudget von 250 US-Dollar pro Monat und Projekt.
3. Octoparse (Browser-Scraping-Tool ohne Code)
Für wen das ist: Octoparse ist ein fantastisches Scraper-Tool für Leute, die Daten von Websites extrahieren möchten, ohne programmieren zu müssen, und gleichzeitig mit ihrer benutzerfreundlichen Benutzeroberfläche die Kontrolle über den gesamten Prozess haben möchten.
Warum Sie es verwenden sollten: Octoparse ist eines der besten Screen-Scraping-Tools für Leute, die Websites scrapen möchten, ohne Programmieren zu lernen. Es verfügt über einen Point-and-Click-Screen-Scraper, der es Benutzern ermöglicht, hinter Anmeldeformulare zu scrollen, Formulare auszufüllen, Suchbegriffe einzugeben, durch unendliches Scrollen zu scrollen, JavaScript zu rendern und vieles mehr.
Es umfasst außerdem einen Site-Parser und eine gehostete Lösung für Benutzer, die ihre Scraper in der Cloud ausführen möchten. Das Beste daran ist, dass es ein großzügiges kostenloses Kontingent gibt, sodass Benutzer bis zu 10 Crawler kostenlos erstellen können. Für Unternehmenskunden bieten sie außerdem vollständig angepasste Crawler und verwaltete Lösungen an, bei denen sie alles für Sie ausführen und Ihnen die Daten einfach direkt liefern.
Vorteile
Benutzerfreundlichkeit: Octoparse wird für seine benutzerfreundliche Oberfläche, insbesondere den Smart-Modus und den Assistentenmodus, hoch gelobt, wodurch es auch für jeden mit eingeschränkten technischen Fähigkeiten zugänglich ist.
Erweiterter Modus für Präzision: Der erweiterte Modus ist dafür bekannt, dass er eine präzise und genaue Datenextraktion ermöglicht und es technisch versierteren Personen ermöglicht, ihre Scraping-Aufgaben zu verfeinern.
XPath-Unterstützung: Die Octoparse-XPath-Unterstützung ist klar und benutzerfreundlich und hilft Ihnen, bestimmte Elemente effizient aus Webseiten zu extrahieren.
Geschwindigkeit und Automatisierung: Octoparse zeichnet sich durch Geschwindigkeit aus und wird besonders für die Automatisierung der Extraktion großer Datensätze geschätzt, was für Aufgaben wie das Sammeln von E-Mail-IDs oder das Scrapen von Produktdaten nützlich ist.
Keine Codierung erforderlich: Octoparse vereinfacht den Datenextraktionsprozess und ermöglicht Ihnen das Scrapen von Websites ohne jegliche Programmierung oder komplexe Regelsetzung.
Nachteile
Lernkurve für erweiterte Funktionen: Während die Grundfunktionen benutzerfreundlich sind, kann es für einige Benutzer ohne Vorkenntnisse schwierig sein, den erweiterten Modus oder die XPath-Anpassung anzupassen.
Bewertungen
Trustpilot-Bewertung – 3,0
Benutzerfreundlichkeit
⭐⭐⭐⭐(4/5)
Preise
Die Preismodelle von Octoparse sind relativ fair, da sie pro Aufgabe abrechnen. Ihr Abonnement bestimmt also die Anzahl der Aufgaben, die Sie ausführen können.
Planen
Preise
Aufgabe
Kostenlose Testversion
Frei
10
Standard
119 $
100
Prämie
299 $
250
Trotz der fairen Preise ist Octoparse im Vergleich zu ScraperAPI für mittlere und große Projekte immer noch nicht kosteneffektiv. Der kostenlose Plan von ScraperAPI bietet 5.000 API-Credits, sodass Sie bis zu 5.000 URLs ohne umfangreiche Anti-Bots scrapen können.
Der günstigste Plan von ScraperAPI bietet Geo-Targeting-Funktionen für die USA und die EU für standortbezogene Aufgaben, um Ihnen beim Extrahieren von Daten von bestimmten Standorten zu helfen.
Für wen ist das: ParseHub ist ein leistungsstarkes Tool zum Erstellen von Web-Scrapern ohne Codierung – Analysten, Journalisten, Datenwissenschaftler und alle dazwischen nutzen es.
Warum Sie es verwenden sollten: ParseHub ist äußerst einfach zu bedienen. Die automatische IP-Rotation sorgt dafür, dass Ihre Scraping-Aktivitäten unentdeckt bleiben und bietet Ihnen zuverlässigen Zugriff auf die benötigten Daten, selbst von Websites mit strengen Zugriffskontrollen. Sie können Web-Scraper erstellen, indem Sie einfach auf die gewünschten Daten klicken. ParseHub exportiert die Daten dann im JSON- oder Excel-Format. Es verfügt über viele praktische Funktionen, wie zum Beispiel die automatische IP-Rotation, das Scraping von Webseiten hinter Login-Walls, das Durchsuchen von Dropdown-Listen und Registerkarten, das Abrufen von Daten aus Tabellen und Karten und vieles mehr.
Darüber hinaus gibt es ein großzügiges kostenloses Kontingent, mit dem Benutzer in nur 40 Minuten bis zu 200 Seiten Daten durchsuchen können! ParseHub ist auch deshalb nett, weil es Desktop-Clients für Windows, Mac OS und Linux bereitstellt, sodass Sie sie von Ihrem Computer aus verwenden können, egal welches System Sie verwenden.
Vorteile
Benutzerfreundlichkeit für einfache Aufgaben: ParseHub verfügt über eine benutzerfreundliche Oberfläche, die ein einfaches Web-Scraping ermöglicht, ohne dass viel technisches Fachwissen erforderlich ist.
Automatisierungsfunktionen: ParseHub verfügt über nützliche Automatisierungsfunktionen wie Planung und dynamisches Page Scraping, die es Benutzern ermöglichen, komplexe Websites mit mehreren Datenebenen zu scrapen
Kostenlose Version: Es bietet eine robuste kostenlose Version, die es für diejenigen zugänglich macht, die seine Funktionen ausprobieren möchten, bevor sie sich für einen kostenpflichtigen Plan entscheiden. Darin enthalten sind bis zu 200 Seiten pro Auflage und 5 öffentliche Projekte.
Kostengünstige Skalierbarkeit: Es bietet mehrere Preisstufen, darunter den Standardplan für 189 $/Monat, der bis zu 10.000 Seiten pro Auflage ermöglicht, und einen Professional-Plan mit erweiterten Funktionen wie schnellerem Scraping und vorrangigem Support.
Nachteile
Support-Einschränkungen: Es gab Beschwerden darüber, dass der Kundensupport stärker verkaufsorientiert sei und sich weniger auf die Lösung von Problemen konzentriere, insbesondere bei Benutzern, die kostenlose Testversionen nutzen.
Muss installiert werden: Wenn die Abstreifer lokal auf Ihrer Maschine laufen, bedeutet das, dass Sie eine größere Investition in die Ausrüstung benötigen, um Ihren Betrieb auszubauen.
Anpassungsgrenzen: Da es sich um eine Low-Code-Plattform handelt, ist sie restriktiver als dedizierte Scraping-APIs.
Bewertungen
Trustpilot-Bewertung – Null
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Die ParseHub-Preise basieren auf Geschwindigkeit und Seiten. Je höher Ihr Abonnement, desto mehr Seiten können Sie scrapen.
Planen
Preise
Seiten
Kostenlose Testversion
Frei
200 Seiten pro Durchlauf in 40 Minuten
Standard
189 $
10.000 Seiten pro Durchlauf (200 Seiten in 10 Minuten)
Professional
599 $
Unbegrenzt in weniger als 2 Minuten
ParseHub Plus
Brauch
Brauch
Basierend auf der Anzahl der Seiten ist scraperAPI wirtschaftlicher, da Sie mit dem niedrigsten Plan mit 100.000 API-Credits – 49 US-Dollar pro Monat – problemlos über 10.000 Seiten erhalten.
5. Scrapy (Crawling und Scraping der Python-Bibliothek)
Für wen ist das: Scrapy ist eine Open-Source-Web-Scraping-Bibliothek für Python-Entwickler, die skalierbare Webcrawler erstellen möchten. Es handelt sich um ein umfassendes Framework, das alle Installationen (Warteschlangenanforderungen, Proxy-Middleware usw.) verwaltet, die die Erstellung von Webcrawlern erschweren.
Warum Sie es verwenden sollten: Als Open-Source-Tool ist Scrapy völlig kostenlos. Sie ist kampferprobt und seit Jahren eine der beliebtesten Python-Bibliotheken. Es gilt als das beste Python-Web-Scraping-Tool für neue Anwendungen. Es gibt eine Lernkurve, die jedoch gut dokumentiert ist und es stehen zahlreiche Tutorials zur Verfügung, die Ihnen den Einstieg erleichtern.
Darüber hinaus ist der Einsatz der Crawler sehr einfach und zuverlässig. Sobald sie eingerichtet sind, können die Prozesse selbstständig ablaufen. Als voll funktionsfähiges Web-Scraping-Framework stehen viele Middleware-Module zur Verfügung, um verschiedene Tools zu integrieren und verschiedene Anwendungsfälle (Umgang mit Cookies, Benutzeragenten usw.) abzuwickeln.
Vorteile
Kriechen und Kratzen mit hoher Geschwindigkeit: Scrapy ist für seine Schnelligkeit bei der Abwicklung groß angelegter Web-Scraping-Projekte bekannt. Es ist mit asynchroner Netzwerkunterstützung ausgestattet, was bedeutet, dass mehrere Anfragen gleichzeitig gesendet werden können, wodurch Leerlaufzeiten reduziert werden. Dies macht es äußerst effizient bei der Extraktion großer Datenmengen von Websites in kurzer Zeit.
Fähigkeit zur Datenextraktion im großen Maßstab: Mit Scrapy können Sie riesige Datenmengen scrapen. Dank der Fähigkeit, verteilte Crawler zu verwalten, können Sie Ihre Projekte skalieren, indem Sie mehrere Spider gleichzeitig ausführen. Dies macht Scrapy ideal für Scraping-Projekte auf Unternehmensebene, bei denen täglich Tausende von Seiten gecrawlt werden müssen.
Speichereffiziente Prozesse: Scrapy nutzt eine effiziente Speicherverwaltung, um umfangreiche Web-Scraping-Aufgaben mit minimalem Ressourcenverbrauch zu verwalten. Im Gegensatz zu browserbasierten Scrapern lädt Scrapy keine vollständigen HTML-Seiten und rendert kein JavaScript, wodurch die Speichernutzung niedrig bleibt und eine große Anzahl von Anfragen ohne Leistungseinbußen verarbeitet werden kann.
Hochgradig anpassbar und erweiterbar: Die modulare Architektur von Scrapy ermöglicht es Entwicklern, ihre Scraping-Projekte einfach anzupassen. Sie können die Kernfunktionen von Scrapy ändern oder erweitern, Bibliotheken von Drittanbietern integrieren oder sogar benutzerdefinierte Middleware und Pipelines erstellen, um spezifischen Projektanforderungen gerecht zu werden. Diese Flexibilität macht es ideal für Benutzer, die eine genaue Kontrolle über ihre Schabevorgänge wünschen.
Nachteile
Unterstützt kein dynamisches Content-Rendering: Scrapy hat Probleme mit Websites, die JavaScript zum Rendern dynamischer Inhalte verwenden. Da es sich um einen HTML-Parser und nicht um einen vollständigen Browser handelt, kann Scrapy nicht mit JavaScript-gesteuerten Elementen interagieren.
Steile Lernkurve: Scrapy wurde speziell für Entwickler entwickelt, was es für Anfänger zu einer Herausforderung machen kann. Es erfordert ein solides Verständnis von Python, Web-Scraping-Techniken und asynchroner Programmierung. Für diejenigen, die neu im Web Scraping sind oder keine ausgeprägten technischen Kenntnisse haben, kann die Beherrschung von Scrapy viel Zeit und Mühe kosten.
Bewertung
Pro Github-Stern – 52,5.000
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Preise
Frei
Verwandt: So scrapen Sie Websites mit Scrapy und ScraperAPI.
Für wen ist das: Diffbot ist eine Unternehmenslösung für Unternehmen mit hochspezialisierten Daten-Crawling- und Screen-Scraping-Anforderungen, insbesondere für diejenigen, die Websites crawlen, deren HTML-Struktur häufig geändert wird.
Warum Sie es verwenden sollten: Diffbot unterscheidet sich von den meisten Webseiten-Scraping-Tools dadurch, dass es Computer Vision (anstelle von HTML-Parsing) verwendet, um relevante Informationen auf einer Seite zu identifizieren. Das bedeutet, dass Ihre Web-Scraper nicht kaputt gehen, selbst wenn sich die HTML-Struktur einer Seite ändert, solange die Seite optisch gleich aussieht. Dies ist eine unglaubliche Funktion für lang andauernde, geschäftskritische Web-Scraping-Jobs.
Diffbot ist teuer (der günstigste Plan kostet 299 $/Monat), aber sie leisten hervorragende Arbeit und bieten einen Premium-Service, der sich für Großkunden möglicherweise lohnt.
Vorteile
Automatisierte Datenextraktion mit KI: Diffbot nutzt KI, um strukturierte Daten aus unstrukturierten Webseiten zu analysieren und zu extrahieren, sodass keine manuelle Codierung erforderlich ist. Es kann bestimmte Inhaltstypen wie Artikel, Produkte, Bilder usw. automatisch erkennen und extrahieren. Dies macht es äußerst effizient für groß angelegte Datenextraktionsprojekte, ohne dass benutzerdefinierte Scraper entwickelt werden müssen.
Unterstützt dynamische Inhalte: Im Gegensatz zu einigen Web-Scraping-Tools ist Diffbot in der Lage, dynamische Inhalte zu verarbeiten, die von JavaScript generiert werden. Dies ist besonders nützlich für Websites, die Inhalte dynamisch laden oder auf clientseitiges Rendering angewiesen sind.
Umfangreiche API-Unterstützung: Diffbot bietet mehrere APIs für unterschiedliche Datenextraktionsanforderungen, einschließlich seiner Knowledge Graph API, die es Benutzern ermöglicht, strukturierte Daten über eine Vielzahl von Domänen hinweg abzufragen und abzurufen. Es bietet außerdem Artikel-, Produkt- und Bild-APIs, was es vielseitig für das Scrapen verschiedener Inhaltstypen von Websites macht.
Nachteile
Hohe Kosten: Die erweiterten Funktionen und der Unternehmensfokus von Diffbot haben einen Premium-Preis. Für kleine Betriebe oder einzelne Benutzer können die Kosten unerschwinglich sein. Das Preismodell ist nutzungsbasiert, was bedeutet, dass ein höheres Anfragevolumen zu erheblichen Kosten führen kann, sodass es für Low-Budget- oder kleine Projekte weniger geeignet ist.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Die Preise von Diffbot ähneln denen von ScraperAPI, da sie auf Guthaben basieren, Diffbot jedoch nicht pro erfolgreicher Anfrage abrechnet.
Wie Sie in der Tabelle und dem Bild unten sehen können, kostet Diffbot 299 US-Dollar für 250.000 Credits, was 250.000 Seiten (erfolgreich oder nicht) bei 1 Credit pro Seite entspricht.
Andererseits bietet ScraperAPI 1 Mio. API-Credits für nur 149 US-Dollar, sodass Sie auf 1 Mio. erfolgreiche Anfragen/Seiten zugreifen können.
Planen
Preise
Kredit
Frei
Frei
10.000 Credits (0 $ pro Credit)
Start-up
299 $
250.000 Credits (0,001 $ pro Credit)
Plus
899 $
1.000.000 Credits (0,0009 $ pro Credit)
Unternehmen
Brauch
Brauch
7. Cheerio (HTML-Parser für Node.js)
Für wen ist das: NodeJS-Entwickler, die eine unkomplizierte Möglichkeit zum Parsen von HTML suchen. Wer mit jQuery vertraut ist, wird die beste verfügbare JavaScript-Web-Scraping-Syntax sofort zu schätzen wissen.
Warum Sie es verwenden sollten: Cheerio bietet eine API ähnlich wie jQuery, sodass sich Entwickler, die mit jQuery vertraut sind, sofort zu Hause fühlen werden, wenn sie Cheerio zum Parsen von HTML verwenden. Es ist rasend schnell und bietet viele hilfreiche Methoden zum Extrahieren von Text, HTML, Klassen, IDs usw.
Es ist mit Abstand die beliebteste in NodeJS geschriebene HTML-Parsing-Bibliothek und wahrscheinlich das beste NodeJS- oder JavaScript-Web-Scraping-Tool für neue Projekte.
Vorteile
Leicht und schnell: Cheerio ist eine schnelle und effiziente Bibliothek zum Parsen und Bearbeiten von HTML und XML. Da es kein JavaScript rendert oder einen Browser simuliert, arbeitet es mit minimalem Overhead und eignet sich daher ideal für Aufgaben, die nur statischen HTML-Inhalt umfassen.
jQuery-ähnliche Syntax: Eine der herausragenden Funktionen von Cheerio ist seine jQuery-ähnliche Syntax, die es Entwicklern, die mit jQuery vertraut sind, erleichtert, schnell mit Cheerio zu beginnen. Die Manipulation von DOM-Elementen im jQuery-Stil macht das Scrapen und Extrahieren von Daten einfach und intuitiv.
Flexibel und erweiterbar: Sie können Cheerio problemlos in andere Tools und APIs integrieren. Aufgrund seines modularen Aufbaus passt es in benutzerdefinierte Scraping-Pipelines und ist somit an eine Vielzahl von Web-Scraping-Anforderungen anpassbar.
Nachteile
Bedarf an zusätzlichen Werkzeugen für komplexere Schabearbeiten: Während Cheerio für grundlegende Scraping-Aufgaben leichtgewichtig und effizient ist, erfordert die Bewältigung komplexerer Szenarien wie der Interaktion mit dynamischen Elementen oder der Umgehung von Anti-Scraping-Maßnahmen die Kombination mit fortschrittlicheren Tools. Dies erhöht die Komplexität der Scraping-Einrichtung und des Arbeitsablaufs.
Eingeschränkte Unterstützung für JavaScript-lastige Websites: Cheerio führt kein JavaScript aus, daher werden Inhalte, die von der clientseitigen JavaScript-Ausführung abhängen, nicht erfasst. Diese Einschränkung erfordert die Integration zusätzlicher Tools wie Puppeteer oder Selenium, die eine echte Browserumgebung simulieren können.
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Bewertung
Preise
Frei
Verwandt: So durchsuchen Sie HTML-Tabellen mit Axios und Cheerio.
8. BeautifulSoup (HTML-Parser für Python)
Für wen ist das: Python-Entwickler, die einfach nur eine einfache Schnittstelle zum Parsen von HTML wünschen und nicht unbedingt die Leistung und Komplexität von Scrapy benötigen.
Warum Sie es verwenden sollten: Wie Cheerio für NodeJS-Entwickler ist BeautifulSoup der beliebteste HTML-Parser für Python-Entwickler. Es gibt sie nun schon seit über einem Jahrzehnt und sie ist äußerst gut dokumentiert. In vielen Web-Parsing-Tutorials wird Entwicklern beigebracht, wie man damit verschiedene Websites in Python 2 und Python 3 durchsucht. Wenn Sie nach einer Python-HTML-Parsing-Bibliothek suchen, ist dies genau das Richtige für Sie du willst.
Vorteile
Einfach zu bedienen und zu erlernen: BeautifulSoup verfügt über eine einfache und intuitive API, wodurch es sowohl für Anfänger als auch für erfahrene Entwickler zugänglich ist. Es ermöglicht Ihnen, HTML- und XML-Dokumente einfach zu analysieren und Daten mit minimalem Code zu extrahieren.
Flexibel mit Parsern: BeautifulSoup ist mit mehreren Parsern kompatibel, beispielsweise dem integrierten HTML-Parser von Python, lxml und html5lib. Dank dieser Flexibilität können Sie den Parser auswählen, der Ihren Anforderungen am besten entspricht, unabhängig davon, ob es um Geschwindigkeit oder Vollständigkeit beim Umgang mit schlecht formatiertem HTML geht.
Integration mit anderen Bibliotheken: BeautifulSoup lässt sich gut in andere Python-Bibliotheken wie Requests und LXML integrieren und erleichtert so die Einrichtung umfassender Scraping-Pipelines zum Abrufen und Verarbeiten von Daten von Websites.
Behandelt unvollständiges HTML: BeautifulSoup ist für seine Robustheit im Umgang mit schlecht strukturiertem oder fehlerhaftem HTML bekannt. Es korrigiert automatisch Fehler in HTML-Dokumenten und erleichtert so das Scrapen von Websites mit inkonsistentem Markup.
Nachteile
Keine JavaScript-Unterstützung: BeautifulSoup kann keine Websites verarbeiten, die zum Laden von Inhalten stark auf JavaScript angewiesen sind. Da es mit statischem HTML funktioniert, ist der Zugriff auf dynamische, mit JavaScript generierte Inhalte ohne die Integration zusätzlicher Tools wie Selenium nicht möglich.
Manueller Aufwand für komplexe Aufgaben erforderlich: BeautifulSoup eignet sich gut für einfache HTML-Parsing-Aufgaben, erfordert jedoch mehr manuelle Codierung, um komplexe Aufgaben wie Paginierung, Proxy-Verwaltung oder Umgehung von Anti-Scraping-Maßnahmen zu bewältigen.
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Bewertung
Preise
Frei
Verwandt: Scraping von HTML-Websites mit BeautifulSoup und ScraperAPI.
9. Puppeteer (Headless Chrome API für Node.js)
Für wen ist das: Puppeteer ist eine Headless-Chrome-API für NodeJS-Entwickler, die eine detaillierte Kontrolle über ihre Scraping-Aktivitäten wünschen.
Warum Sie es verwenden sollten: Puppeteer ist ein Open-Source-Tool, das völlig kostenlos ist. Es wird gut unterstützt, aktiv weiterentwickelt und vom Google Chrome-Team unterstützt. Es ersetzt schnell Selenium und PhantomJS als standardmäßiges Headless-Browser-Automatisierungstool.
Es verfügt über eine durchdachte API und installiert im Rahmen des Einrichtungsprozesses automatisch eine kompatible Chromium-Binärdatei, sodass Sie nicht selbst den Überblick über die Browserversionen behalten müssen.
Obwohl es sich um viel mehr als nur eine Web-Crawling-Bibliothek handelt, wird sie häufig zum Auslesen von Website-Daten von Websites verwendet, die JavaScript zum Anzeigen von Informationen benötigen.
Es verarbeitet Skripte, Stylesheets und Schriftarten wie ein echter Browser. Es ist zwar eine hervorragende Lösung für Websites, die JavaScript zum Anzeigen von Daten benötigen, ist aber auch sehr CPU- und speicherintensiv. Daher ist es keine gute Idee, es für Websites zu verwenden, auf denen ein vollwertiger Browser nicht erforderlich ist. In den meisten Fällen reicht eine einfache GET-Anfrage aus!
Vorteile
Headless-Browser-Automatisierung: Mit Puppeteer können Sie Chrome oder Chromium im Headless-Modus steuern, was es ideal für Automatisierungsaufgaben wie Web Scraping, UI-Tests und das Generieren von PDFs aus Webseiten macht.
Plattformübergreifend: Puppeteer funktioniert auf mehreren Plattformen (Linux, macOS, Windows) und unterstützt sowohl Headless- als auch Non-Headless-Modi, was es für eine Reihe von Anwendungsfällen vielseitig macht, von der lokalen Entwicklung bis zur Bereitstellung in Cloud-Umgebungen.
Nachteile
Ressourcenintensiv: Das Ausführen von Headless-Chrome-Instanzen kann ressourcenintensiv sein, insbesondere bei der Skalierung von Scraping-Jobs oder Automatisierungsaufgaben. Es erfordert mehr CPU und Speicher im Vergleich zu einfachen Tools wie Cheerio oder nicht browserbasierten Scrapern.
Manuelle Einrichtung für erweiterte Anwendungsfälle: Puppeteer verfügt nicht über eine integrierte Planung, Datenextraktionsvorlagen oder Datenspeicherfunktionen. Sie müssen diese Prozesse manuell erstellen, was die Komplexität der Verwendung des Tools für umfangreiche Projekte erhöhen kann.
Es fehlen integrierte Scraping-Funktionen: Puppeteer ist ein Allzweck-Browser-Automatisierungstool und verfügt nicht über spezifische Web-Scraping-Optimierungen (z. B. Handhabung von CAPTCHAs oder IP-Rotation). Für das Scraping großer, geschützter Websites benötigen Sie zusätzliche Tools oder Dienste für Anti-Scraping-Bypass-Techniken wie ScraperAPI.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Preise
Frei
Verwandt: Scraping von Amazon mit Puppeteer und ScraperAPI.
10. Mozenda
Für wen ist das: Unternehmen, die nach einer cloudbasierten Self-Service-Webpage-Scraping-Plattform suchen, müssen nicht weiter suchen. Mit über 7 Milliarden gecrawlten Seiten verfügt Mozenda über Erfahrung in der Betreuung von Unternehmenskunden weltweit.
Warum Sie es verwenden sollten: Mozenda zeichnet sich durch seinen Kundenservice aus (der allen zahlenden Kunden sowohl Telefon- als auch E-Mail-Support bietet). Die Plattform ist hoch skalierbar und ermöglicht auch On-Premise-Hosting. Wie Diffbot ist es etwas teuer, wobei der niedrigste Plan bei 250 $/Monat beginnt.
Vorteile
Benutzerfreundliche Oberfläche: Mozenda ist für technisch nicht versierte Benutzer konzipiert und verfügt über eine intuitive Point-and-Click-Oberfläche, die das Einrichten und Ausführen von Scraping-Jobs ohne Programmieraufwand vereinfacht.
Automatisierung und Planung: Mozenda unterstützt die Planung und Automatisierung von Scraping-Aufgaben, sodass Sie wiederkehrende Jobs festlegen und Daten regelmäßig ohne manuelles Eingreifen scrapen können.
Flexibilität beim Datenexport: Mozenda bietet eine breite Palette an Datenexportoptionen, mit denen Sie Scraped-Daten in mehrere Formate wie CSV, Excel, XML oder direkt in eine Datenbank exportieren können. Es lässt sich auch in andere Datendienste integrieren.
Nachteile
Preise: Die Preise von Mozenda sind höher als bei einigen anderen Scraping-Tools, was für kleine Unternehmen oder Einzelpersonen mit begrenztem Budget ein Nachteil sein kann. Die Kosten steigen mit der Anzahl der gescrapten Seiten oder dem Grad der Datenkomplexität.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Die Preise von Mozenda sind auf der Website nicht klar angegeben, aber einem im Jahr 2018 veröffentlichten Preismodelldokument, das auch unten zu sehen ist, ist die Preisgestaltung von Mozenda kreditbasiert und im Vergleich zu Wettbewerbern wie ScraperAPI recht teuer.
Planen
Preise
Credits
Lagerung
Basic
99 $/Monat
Projekt
300 $/Monat
20.000
1 GB
Professional
400 $/Monat
35.000
5 GB
Unternehmen
450 $/Monat (jährliche Abrechnung)
1.000.000+ jährlich
50 GB
Hohe Kapazität
40.000 $/Jahr
Brauch
Brauch
Vor Ort
Brauch
Brauch
Brauch
11. ScrapeHero Cloud (cloudbasierte, für Sie erstellte Scraping-Dienste)
Für wen ist das: ScrapeHero ist cloudbasiert und benutzerfreundlich, was es ideal macht, wenn Sie kein Programmierer sind. Sie müssen lediglich die Eingaben vornehmen und auf „Daten sammeln“ klicken. Sie verfügen über umsetzbare Daten in den Formaten JSON, CSV oder Excel.
Warum Sie es verwenden sollten: ScrapeHero hat ein browserbasiertes, automatisiertes Scraping-Tool entwickelt, mit dem Sie mit nur wenigen Klicks alles, was Sie im Internet haben möchten, in Tabellenkalkulationen herunterladen können. Es ist günstiger als die Vollservices und es gibt eine kostenlose Testversion. Es verwendet vorgefertigte Crawler mit automatisch rotierenden Proxys. Echtzeit-APIs erfassen Daten von einigen der größten Online-Händler und -Dienste, darunter Karten, Produktpreise, aktuelle Nachrichten und mehr. Dieses Data-as-a-Service-Tool ist perfekt für Unternehmen, insbesondere für diejenigen, die sich für KI interessieren.
Vorteile
Anpassbare Lösungen: ScrapeHero bietet vollständig anpassbare Web-Scraping-Lösungen, die auf die spezifischen Bedürfnisse von Unternehmen zugeschnitten sind. Dadurch können Sie unabhängig von der Komplexität oder Größe der Website genau die Daten sammeln, die sie benötigen.
Keine Codierung erforderlich: ScrapeHero ist benutzerfreundlich und erfordert keine technischen Kenntnisse. Unternehmen können benutzerdefinierte Daten extrahieren, ohne dass interne Entwickler oder technisches Fachwissen erforderlich sind.
Nachteile
Höhere Kosten für kundenspezifische Lösungen: Während ScrapeHero eine Reihe von Preisplänen anbietet, können seine individuellen Daten-Scraping-Dienste im Vergleich zu DIY-Tools oder -Plattformen teuer sein, insbesondere für Unternehmen mit kleineren Budgets oder begrenztem Scraping-Bedarf.
Eingeschränkte Self-Service-Funktionen: Wenn Sie nach einem Self-Service-Tool zum manuellen Einrichten und Ausführen von Scraping-Jobs suchen, ist ScrapeHero möglicherweise nicht ideal. Es ist eher für verwaltete Dienste konzipiert, was die Flexibilität für diejenigen einschränken kann, die die volle Kontrolle über ihre Scraping-Prozesse wünschen.
Bewertung
Trustpilot-Bewertung – 3,7
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Aus dem Bild oben können Sie ersehen, dass das Preismodell von ScrapeHero auf der Anzahl der Seiten basiert, die Sie scrapen möchten. Dies macht es kostengünstig, wenn Sie eine kleinere Anzahl von Seiten durchschaben möchten. Andererseits bietet ScraperAPI mehr API-Anfragen zu einem niedrigeren Startpreis, was es zu einer besseren Option für große Scraping-Projekte macht.
12. Webscraper.io (Point-and-Click-Chrome-Erweiterung für Web-Scraping)
Für wen ist das: Eine weitere benutzerfreundliche Option für Nicht-Entwickler, WebScraper.io, ist eine einfache Google Chrome-Browsererweiterung. Es ist nicht so umfassend ausgestattet wie die anderen Web-Scraping-Tools auf dieser Liste, aber es ist eine ideale Option für diejenigen, die mit kleineren Datenmengen arbeiten und nicht viel Automatisierung benötigen.
Warum Sie es verwenden sollten: WebScraper.io hilft Benutzern beim Einrichten einer Sitemap, um auf einer bestimmten Website zu navigieren und genau zu bestimmen, welche Informationen erfasst werden. Das zusätzliche Plugin kann mehrere JS- und Ajax-Seiten gleichzeitig verarbeiten, und Entwickler können ihre Scraper so erstellen, dass sie Daten direkt aus dem Browser in CVS oder aus der Cloud von Web Scraper in CVS, XLSX und JSON extrahieren. Sie können auch regelmäßige Scrapes mit regelmäßiger IP-Rotation planen. Die Browser-Erweiterung ist kostenlos, aber Sie können die kostenpflichtigen Dienste mit einer kostenlosen Testversion testen.
Vorteile
Cloudbasiertes Scraping: Webscraper.io ist ein browserbasiertes Daten-Scraping-Tool, mit dem Sie Scraping-Aufgaben im Hintergrund ausführen können, ohne lokale Ressourcen zu binden. Dadurch können Sie auch große Datenmengen effizient durchsuchen.
Erschwingliche Preise: Webscraper.io verfügt über verschiedene Preispläne, darunter einen kostenlosen Plan, wodurch es für Benutzer mit unterschiedlichen Bedürfnissen und Budgets zugänglich ist. Dadurch können Sie die Plattform ohne nennenswerte Vorabkosten nutzen.
Nachteile
Beschränkt auf die Chrome-Erweiterung: Webscraper.io ist nur als Chrome-Erweiterung verfügbar, was seine Benutzerfreundlichkeit einschränkt. Es fehlt auch ein dedizierter Desktop oder eine eigenständige Anwendung, was ein Nachteil sein könnte, wenn Sie Chrome nicht verwenden.
Einschränkungen des kostenlosen Plans: Der kostenlose Plan ist zwar nützlich, schränkt jedoch die Anzahl der Seiten und Daten, die gescrapt werden, erheblich ein. Bei Großprojekten müssen Sie sich für einen der kostenpflichtigen Tarife entscheiden.
Bewertung
Trustpilot-Bewertung – 3,7
Benutzerfreundlichkeit
⭐⭐⭐(3/5)
Preise
Webscraper.io ist eines der günstigsten Web-Scraping-Tools auf dem Markt. Es gibt einen kostenlosen Plan mit einem Startpreis von 50 $. Diese Preisgestaltung basiert auf Cloud-Guthaben, wobei 1 Cloud-Guthaben = 1 Seite ist.
Planen
Preis
Cloud-Guthaben
Browser-Erweiterung
Frei
Nill (nur lokale Verwendung)
Projekt
50 $
5.000
Professional
100 $
20.000
Geschäft
200 $
50.000
Skala
200 $+
Unbegrenzt
13. Kimura
Für wen ist das: Kimura ist ein in Ruby geschriebenes Open-Source-Web-Scraping-Framework. Es macht es unglaublich einfach, einen Ruby Web Scraper zum Laufen zu bringen.
Warum Sie es verwenden sollten: Kimura wird schnell als beste Ruby-Web-Scraping-Bibliothek anerkannt. Es ist so konzipiert, dass es sofort mit Headless Chrome/Firefox, PhantomJS und normalen GET-Anfragen funktioniert. Seine Syntax ähnelt Scrapy, und Entwickler, die Ruby-Web-Scraper schreiben, werden die netten Konfigurationsoptionen zum Festlegen einer Verzögerung, zum Rotieren von Benutzeragenten und zum Festlegen von Standard-Headern lieben.
Vorteile
Rubinbasiert: Kimurai ist in Ruby erstellt, was für Entwickler von Vorteil ist, die mit der Programmiersprache Ruby vertraut sind. Es bietet ein Framework zum Schreiben von Web-Scrapern in Ruby und erleichtert Ruby-Entwicklern die Integration von Scraping in ihre Projekte.
Integrierte Web-Scraping-Tools: Kimurai verfügt über integrierte Scraping-Tools wie Sitzungsverwaltung, automatische Wiederholungsversuche, Anforderungsverzögerungen und Proxy-Unterstützung. Dies reduziert die Notwendigkeit, zusätzliche Tools oder Bibliotheken manuell zu integrieren, was den Scraping-Prozess vereinfacht.
Open Source: Da es sich um eine Open-Source-Lösung handelt, kann Kimurai kostenlos verwendet werden und der Quellcode kann geändert werden. Dies macht es zu einer kostengünstigen Lösung für Entwickler, die Web-Scraping-Anwendungen erstellen möchten.
Nachteile
Einschränkung des Ruby-Ökosystems: Kimurai ist in Ruby erstellt, einer im Vergleich zu Python weniger häufig verwendeten Sprache für Web Scraping. Dies schränkt die Community-Unterstützung und die verfügbaren Ressourcen ein, insbesondere im Vergleich zu weit verbreiteten Scraping-Frameworks wie BeautifulSoup in Python.
Eingeschränkte Dokumentation: Obwohl Kimurai ein leistungsstarkes Tool ist, ist seine Dokumentation nicht so umfangreich wie bei anderen gängigen Frameworks, was den Einstieg für Neueinsteiger erschwert.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (3/5)
Preise
Frei
14. Goutte
Für wen ist das: Goutte ist ein in PHP geschriebenes Open-Source-Webcrawler-Framework, was es äußerst nützlich für Entwickler macht, die Daten aus HTML/XML-Antworten mit PHP extrahieren möchten.
Warum Sie es verwenden sollten: Goutte ist ein sehr unkompliziertes, schnörkelloses Framework, das viele für die beste PHP-Web-Scraping-Bibliothek halten. Es ist auf Einfachheit ausgelegt und bewältigt die meisten HTML/XML-Anwendungsfälle ohne allzu großen zusätzlichen Aufwand.
Es lässt sich außerdem nahtlos in die hervorragende Guzzle-Anforderungsbibliothek integrieren, mit der Sie das Framework für komplexere Anwendungsfälle anpassen können.
Vorteile
PHP-Integration: Als PHP-basiertes Tool ist Goutte eine großartige Option für Entwickler, die bereits mit dem PHP-Ökosystem vertraut sind. Es lässt sich gut in PHP-Anwendungen integrieren und kann in vorhandenen Frameworks wie Laravel oder Symfony verwendet werden.
Kopfloses Schaben: Goutte benötigt keine Browser-Engine, was es viel schneller und weniger ressourcenintensiv macht als browserbasierte Scraper wie Puppeteer oder Selenium. Es ist effizient zum Scrapen statischer Websites, die nicht stark auf JavaScript angewiesen sind.
Verwendet Symfony-Komponenten: Goutte nutzt leistungsstarke Symfony-Komponenten wie DomCrawler und BrowserKit und ist damit eine robuste Option zum programmgesteuerten Navigieren und Scrapen von HTML-Inhalten. Dies ermöglicht es Benutzern, Benutzeraktionen wie Formularübermittlungen, Linkklicken und Sitzungsverwaltung einfach zu simulieren.
Gut für statische Websites: Goutte zeichnet sich durch das Scraping statischer Inhalte aus. Für Websites, die nicht auf JavaScript zum dynamischen Laden von Daten angewiesen sind, schneidet Goutte in Bezug auf Geschwindigkeit und Effizienz außergewöhnlich gut ab.
Nachteile
Eingeschränkte JavaScript-Unterstützung: Goutte unterstützt kein JavaScript-Rendering, was bedeutet, dass es für das Scraping dynamischer Websites, die JavaScript zum Laden von Inhalten verwenden, unwirksam ist. Diese Einschränkung macht es ungeeignet für das Scraping moderner Single-Page-Anwendungen (SPAs) oder JavaScript-lastiger Websites.
PHP-Abhängigkeit: Da es sich um ein PHP-basiertes Tool handelt, ist seine Verwendung in PHP-Umgebungen eingeschränkt. Dies ist möglicherweise nicht ideal für Entwickler, die in anderen Sprachen arbeiten oder einen sprachunabhängigeren Ansatz für Web Scraping bevorzugen, wie z. B. die Verwendung von Python mit Scrapy oder BeautifulSoup.
Nicht ideal für großflächiges Schaben: Während Goutte für kleinere Scraping-Aufgaben effizient ist, ist es nicht für die Abwicklung großer Projekte optimiert, die eine hohe Parallelität oder verteiltes Scraping über mehrere Maschinen erfordern. Robustere Frameworks wie Scrapy oder Puppeteer eignen sich besser für solche Projekte.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (3/5)
Preise
Frei
Welche Faktoren sollten Sie bei der Auswahl von Web-Scraping-Tools berücksichtigen?
Der Auswahlprozess muss sich an bestimmten technischen und praktischen Kriterien orientieren, wenn es darum geht, potenzielle Web-Scraper zu bewerten, die Sie Ihrem Arsenal hinzufügen möchten.
Folgende Faktoren sollten geprüft werden:
Datenextraktionsfunktionen: Ein gutes Web-Scraping-Tool unterstützt verschiedene Datenformate und kann Inhalte aus verschiedenen Webstrukturen extrahieren, einschließlich statischer HTML-Seiten und dynamischer Websites mithilfe von JavaScript.
Benutzerfreundlichkeit: Bewerten Sie die Lernkurve, die Benutzeroberfläche und die verfügbare Dokumentation des Tools. Wer es nutzt, sollte die Komplexität des Tools verstehen.
Skalierbarkeit: Überlegen Sie, wie gut das Tool die Datenextraktion in großem Maßstab bewältigt. Sowohl die Skalierbarkeit der Leistung als auch die Fähigkeit, sich an steigende Datenmengen oder Anforderungen anzupassen, sind von entscheidender Bedeutung.
Automatisierungsfunktionen: Prüfen Sie den Grad der verfügbaren Automatisierung. Suchen Sie nach Planungsfunktionen, automatisierter Handhabung von CAPTCHA und der Möglichkeit, Cookies und Sitzungen automatisch zu verwalten.
IP-Rotation und Proxy-Unterstützung: Das Tool sollte eine robuste Unterstützung für IP-Rotation und Proxy-Verwaltung bieten, um eine Blockierung zu vermeiden.
Fehlerbehandlung und -behebung: Untersuchen Sie, wie das Tool mit Fehlern umgeht, z. B. unterbrochenen Verbindungen oder unerwarteten Site-Änderungen.
Integration mit anderen Systemen: Stellen Sie fest, ob sich das Tool nahtlos in andere Systeme und Plattformen integrieren lässt, z. B. Datenbanken, Cloud-Dienste oder Datenanalysetools. Auch die Kompatibilität mit APIs kann ein wesentlicher Vorteil sein.
Datenbereinigung und -verarbeitung: Suchen Sie nach integrierten oder einfach zu integrierenden Funktionen zur Datenbereinigung und -verarbeitung, um den Arbeitsablauf von Rohdaten zu nutzbaren Informationen zu optimieren.
Datenmanagement nach dem Scraping
Nach dem Scraping ist die Datenverwaltung ebenso wichtig wie die Extraktion. Für die Integration in Geschäftssysteme ist die Bereitstellung in verwendbaren Formaten wie CSV oder JSON erforderlich. Bei ScraperAPI haben wir dedizierte Endpunkte für beliebte Websites wie Amazon, Walmart und Google entwickelt, um Roh-HTML in gebrauchsfertige Datenpunkte umzuwandeln.
Der Speicher muss skalierbar und sicher sein und große Datensätze problemlos aufnehmen können. Die Reinigung ist unerlässlich, um Fehler und irrelevante Inhalte zu entfernen und die Genauigkeit sicherzustellen.
Verwandt: Datenbereinigung 101 für Web Scraping.
Schließlich ist die Integration in bestehende Systeme der Schlüssel für umsetzbare Erkenntnisse und die Ausrichtung von Datenformaten auf die Anforderungen von Analysetools oder CRM-Systemen. Durch effizientes Management werden Rohdaten zu einem wertvollen Gut, das Geschäftsstrategien unterstützen kann.
Abschließende Gedanken: Was ist das beste Web-Scraping-Tool?
Das offene Web ist bei weitem der bedeutendste globale Speicher für menschliches Wissen, und es gibt fast keine Informationen, die Sie nicht durch die Extraktion von Webdaten finden können. Es stehen viele Tools zur Verfügung, weil Web Scraping von Menschen mit unterschiedlichen technischen Fähigkeiten und Know-how durchgeführt wird. Es gibt Web-Data-Scraping-Tools, die jedem dienen – von Leuten, die keinen Code schreiben wollen, bis hin zu erfahrenen Entwicklern, die nur nach der besten Open-Source-Lösung in ihrer Sprache suchen.
Es gibt nicht das beste Web-Scraping-Tool – alles hängt von Ihren Bedürfnissen ab. Wir hoffen, dass Ihnen diese Liste von Scraping-Tools dabei geholfen hat, die besten Webdaten-Scraping-Tools und -Dienste für Ihre spezifischen Projekte oder Unternehmen zu finden.
Viele der oben genannten Scraping-Tools bieten kostenlose oder kostengünstige Testversionen an, sodass Sie sicherstellen können, dass sie für Ihren geschäftlichen Anwendungsfall funktionieren. Einige von ihnen werden zuverlässiger und effektiver sein als andere. Wenn Sie nach einem Tool suchen, das Datenanfragen in großem Umfang und zu einem guten Preis bearbeiten kann, wenden Sie sich an einen Vertriebsmitarbeiter, um sicherzustellen, dass er liefern kann – bevor Sie Verträge unterzeichnen.
Warum ist das Scrapen von Webdaten so wichtig?
Veraltete Erkenntnisse veranlassen ein Unternehmen dazu, Ressourcen ineffektiv einzusetzen oder neue Chancen zu verpassen. Stellen Sie sich vor, Sie würden sich bei der Preisgestaltung für den nächsten Monat auf die FMCG-Preisdaten der Woche vor einem Feiertag verlassen.
Webdaten können der Schlüssel zur Steigerung Ihres Umsatzes und/oder Ihrer Produktivität sein. Das moderne Internet ist extrem laut – Benutzer erzeugen täglich unglaubliche 2,5 Trillionen Bytes an Daten. Ganz gleich, ob Sie gerade dabei sind, Ihr Traumprojekt zu starten, oder ob Sie Ihr Unternehmen schon seit Jahrzehnten besitzen: Die Informationen in den Daten helfen Ihnen, potenzielle Kunden von Ihren Mitbewerbern abzuwerben und sie dazu zu bringen, wiederzukommen.
Web Scraping, also das Extrahieren wertvoller Daten aus dem Internet und deren Konvertierung in ein nützliches Format (z. B. eine Tabellenkalkulation), ist entscheidend, um zu verhindern, dass Ihr Unternehmen oder Produkt ins Hintertreffen gerät.
Webdaten können Ihnen fast alles sagen, was Sie über potenzielle Verbraucher wissen müssen, von den durchschnittlichen Preisen, die sie zahlen, bis hin zu den aktuellen Must-have-Funktionen. Allerdings bedeutet die schiere Menge an Daten über potenzielle Kunden, dass Sie den Rest Ihres Lebens damit verbringen könnten, manuell Daten zu extrahieren, und Sie würden nie aufholen. Hier kommen automatisierte Scraping-Tools ins Spiel. Der Prozess, sie zu finden, kann jedoch sehr einschüchternd sein.
Die Verwendung der besten Web-Scraping-Tools ist für den Erhalt hochwertiger Daten unerlässlich. Daher möchten Sie sicherstellen, dass Sie die besten Tools für die jeweilige Aufgabe erhalten.
Herausforderungen beim Daten-Scraping
Beim Versuch, Daten zu extrahieren, benötigen Unternehmen häufig Hilfe bei der Überwindung von Hindernissen, die technisches Fachwissen und strategische Problemlösung erfordern. Eine der ersten Hürden besteht darin, die richtige Seitenquelle zu erhalten.
Heutzutage sind Websites oft dynamisch und der Inhalt wird im Handumdrehen über JavaScript generiert. Das bedeutet, dass es nicht ausreicht, einfach den HTML-Code einer Seite anzufordern. Wir haben Fälle gesehen, in denen Scraping-Bemühungen zu unvollständigen oder falschen Daten führten, was alles darauf zurückzuführen war, dass die JavaScript-Wiedergabe nicht ordnungsgemäß verarbeitet wurde.
Verwandt: Erfahren Sie, wie Sie mit Python dynamische Inhalte von großen Websites extrahieren.
Eine weitere große Herausforderung entsteht dadurch, dass Websites aktiv versuchen, Scraping zu verhindern. Viele Websites setzen Maßnahmen wie CAPTCHA-Tests, IP-Blockierung oder Inhalte, die nur nach Benutzerinteraktion angezeigt werden, ein, um die automatisierte Datenextraktion zu verhindern. Entwickler mussten Wege finden, menschliches Verhalten nachzuahmen, beispielsweise durch die Einführung zufälliger Verzögerungen oder rotierender IP-Adressen, um den Scraper an diesen Abwehrmechanismen vorbeizubringen.
Auch nach der Überwindung dieser technischen Hürden ist die Arbeit damit noch nicht beendet. Aus verschiedenen Quellen extrahierte Daten liegen häufig in unterschiedlichen Formaten vor und erfordern eine umfassende Bereinigung und Normalisierung, bevor sie verwendet werden können. Zu den langfristigen Problemen gehört, dass sich das Layout der Website häufig ändert und Skripte kaputt gehen, die einmal perfekt funktionierten.
Nicht alle Webdaten sind ein faires Spiel zum Scrapen, und Unternehmen müssen sich in einer komplexen rechtlichen Landschaft aus Vorschriften und standortspezifischen Nutzungsbedingungen zurechtfinden. Das Potenzial für rechtliche Konsequenzen ist real und dieser Bereich erfordert sorgfältige Aufmerksamkeit.
Ohne ständige Überwachung kann ein Tool, das einst wertvolle Erkenntnisse lieferte, obsolet werden und Unternehmen für wesentliche Marktveränderungen blind machen.
Die besten Web-Scraping-Tools, die Sie in Betracht ziehen sollten
Um problemlos Daten von jeder Website zu extrahieren, benötigen Sie ein zuverlässiges Web-Scraping-Tool. Hier sind einige Schlüsselfaktoren, die Sie berücksichtigen sollten, bevor Sie das richtige Werkzeug für Ihr Projekt auswählen:
Geschwindigkeit und Effizienz: Wie schnell kann das Tool Daten scrapen?
Skalierbarkeit: Kann es große Schabeaufgaben bewältigen?
Preise: Ist es für Ihre Bedürfnisse kostengünstig?
Benutzerfreundlichkeit: Wie benutzerfreundlich ist die Oberfläche?
Fehlerbehandlung: Wie gut bewältigt das Tool Ausfälle oder Unterbrechungen?
Kundensupport: Ist reaktionsschneller Support verfügbar?
Anpassung: Bietet das Tool Flexibilität für spezifische Anforderungen?
Natürlich haben wir alle diese Faktoren bei der Auswahl unserer Top-Picks für diese Liste berücksichtigt, damit Sie sicher das richtige Web-Scraping-Tool für Ihr Projekt auswählen können.
Für alle, die es eilig haben, hier ein kurzer Überblick über die Web-Scraping-Tools auf der Liste:
Ruby-basiertes Web-Scraping-Framework mit Multi-Browser-Unterstützung
⭐⭐⭐
Github-Stern – 1k
Goutte
Frei
PHP-basiertes Web-Crawling-Framework für statische Websites
⭐⭐⭐
Github-Stern – 9,3k
1. ScraperAPI (Vollständige Scraping-Lösung für Entwicklerteams)
Für wen das ist: ScraperAPI ist ein Tool für Entwickler, die Web-Scraper erstellen. Es verwaltet Proxys, Browser und CAPTCHAs, sodass Entwickler mit einem einfachen API-Aufruf den rohen HTML-Code von jeder Website abrufen können. Die automatische Proxy-Verwaltung von ScraperAPI spart Zeit und reduziert das Risiko von IP-Verboten, wodurch ein unterbrechungsfreies Daten-Scraping gewährleistet wird.
Warum Sie es verwenden sollten: ScraperAPI belastet Sie nicht mit der Verwaltung Ihrer eigenen Proxys. Stattdessen verwaltet es seinen internen Pool aus Hunderttausenden Proxys von einem Dutzend verschiedener Proxy-Anbieter und verfügt über eine intelligente Routing-Logik, die Anfragen über verschiedene Subnetze weiterleitet.
Es drosselt außerdem automatisch Anfragen, um IP-Verbote und CAPTCHAs zu vermeiden – und sorgt so für eine hervorragende Zuverlässigkeit. Es ist der ultimative Web-Scraping-Dienst für Entwickler mit einzigartigen Pools an Premium-Proxys für E-Commerce-Preis-Scraping, Suchmaschinen-Scraping, Social-Media-Scraping, Sneaker-Scraping, Ticket-Scraping und mehr!
Einfach ausgedrückt hilft ScraperAPI Unternehmen dabei, in großem Umfang wertvolle Erkenntnisse zu gewinnen, sodass Sie sich letztendlich auf die Entscheidungsfindung statt auf die Datenextraktion konzentrieren können.
Notiz: Erfahren Sie, wie saas.group ScraperAPI verwendet, um Fusions- und Übernahmemöglichkeiten zu identifizieren.
Vorteile
Vollständige Scraping-Lösung: ScraperAPI bietet ein komplettes Web-Scraping-Paket, das die Proxy-Verwaltung, die CAPTCHA-Lösung und die Wiederholung von Anfragen automatisiert und so das Extrahieren von Daten von fast jeder Website erleichtert.
Erweiterte Bot-Blocker-Umgehung: Es umgeht effektiv fortschrittliche Anti-Bot-Lösungen wie DataDome und PerimeterX und sorgt so für höhere Erfolgsraten auf schwer zu scannenden Websites.
Strukturierte Endpunkte: Die vorgefertigten Endpunkte von ScraperAPI liefern saubere, strukturierte Daten, reduzieren den Zeitaufwand für das Parsen und die Datenbereinigung und steigern so die Produktivität.
Kostengünstig: Das einzigartige intelligente IP-Rotationssystem von ScraperAPI nutzt maschinelles Lernen und statistische Analysen, um den besten Proxy pro Anfrage auszuwählen; Indem Proxys nur bei Bedarf rotiert werden und private und mobile Proxys als sekundäre Optionen für fehlgeschlagene Anfragen verwendet werden, wird der Proxy-Overhead erheblich reduziert und ist damit günstiger als viele Mitbewerber.
Skalierbarkeitstools: Funktionen wie DataPipeline zum Planen wiederkehrender Aufgaben und Async Scraper für die asynchrone Bearbeitung großer Anforderungsmengen ermöglichen es Benutzern, Scraping-Aufwände effizient zu skalieren und zu automatisieren.
Nachteile
Reduzierte Anzahl strukturierter Datenendpunkte im Vergleich zu einigen Mitbewerbern.
Bewertungen
Der beste Weg, ein Tool zu identifizieren, das hält, was es verspricht, besteht darin, Rezensionen und Bewertungen des Tools zu überprüfen. ScraperAPI hat seine Position an der Spitze bisher behauptet. Hier finden Sie Bewertungen der wichtigsten Bewertungsplattformen.
Trustpilot-Bewertung – 4,7
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Ein gutes Scraping-Tool sollte einfach zu bedienen sein, sonst verfehlt es seinen Zweck, und ScraperAPI sticht in diesem Fall hervor, da die Bewertungen nicht lügen.
Schauen Sie sich gerne die tollen Rezensionen darüber an, wie ScraperAPI Ihre Aufgabe erleichtert.
Preise
Das ScraperAPI-Preismodell ist leicht verständlich und erschwinglich, da wir pro erfolgreicher Anfrage und nicht pro GB oder Bandbreite wie bei anderen Web-Scraping-Tools abrechnen.
Die Anzahl der verbrauchten Credits hängt von der Domain, dem Schutzniveau der Website und den spezifischen Parametern ab, die Sie in Ihrer Anfrage angeben.
ScraperAPI berechnet beispielsweise 5 API-Credits pro erfolgreicher Anfrage an E-Commerce-Domains wie Amazon und Walmart, sodass Sie ganz einfach die Anzahl der Seiten berechnen können, die Sie mit Ihrem Plan scrapen können.
Hier ist eine Aufschlüsselung des Preismodells von ScraperAPI:
Planen
Preise
API-Credits
Kostenlose Testversion (7 – Tage)
Frei
5000
Hobby
49 $
100.000
Start-up
149 $
1.000.000
Geschäft
299 $
3.000.000
Unternehmen
299 $ +
3.000.000 +
Besuchen Sie die Seite „Credits und Anfragen“ von ScraperAPI, um die Credit-Nutzung im Detail zu sehen.
2. ScrapeSimple (Web-Scraping-Outsourcing)
Für wen das ist: ScrapeSimple ist der perfekte Service für Leute, die ein maßgeschneidertes Web-Scraper-Tool für sich haben möchten. Es ist so einfach wie das Ausfüllen eines Formulars mit Anweisungen für die Art der gewünschten Daten.
Warum Sie es verwenden sollten: ScrapeSimple macht seinem Namen alle Ehre und steht ganz oben auf unserer Liste der einfachen Web-Scraping-Tools mit einem vollständig verwalteten Service, der benutzerdefinierte Web-Scraper für Kunden erstellt und verwaltet.
Sagen Sie ihnen einfach, welche Informationen Sie von welchen Websites benötigen, und sie entwerfen einen benutzerdefinierten Web-Scraper, der die Informationen regelmäßig (Sie können zwischen täglich, wöchentlich oder monatlich wählen) im CSV-Format direkt in Ihren Posteingang liefert.
Dieser Service ist perfekt für Unternehmen, die einfach nur einen HTML-Scraper benötigen, ohne selbst Code schreiben zu müssen. Die Reaktionszeiten sind kurz und der Service unglaublich freundlich und hilfsbereit, was ihn perfekt für Leute macht, die sich einfach um den gesamten Datenextraktionsprozess kümmern möchten.
Vorteile
Schnelle Bearbeitungszeit von 1 – 2 Tagen für kleine Projekte
Outsourcen Sie Dienstleistungen für Unternehmen, die nur nach Daten suchen
Für den Datenerfassungsprozess ist kein technisches Fachwissen erforderlich
Nachteile
Es ist teurer als ein DIY-Ansatz
Ihr Team benötigt weiterhin technisches Fachwissen, um mit den Daten zu arbeiten und sie zu analysieren
Bewertungen
Da es sich um einen Web-Scraping-Dienst handelt, gibt es keine erwähnenswerten G2- oder Trustpilot-Bewertungen.
Benutzerfreundlichkeit
⭐⭐⭐⭐(4/5)
Preise
ScrapeSimple hat keinen festen Preis. Stattdessen verlangen sie ein Mindestbudget von 250 US-Dollar pro Monat und Projekt.
3. Octoparse (Browser-Scraping-Tool ohne Code)
Für wen das ist: Octoparse ist ein fantastisches Scraper-Tool für Leute, die Daten von Websites extrahieren möchten, ohne programmieren zu müssen, und gleichzeitig mit ihrer benutzerfreundlichen Benutzeroberfläche die Kontrolle über den gesamten Prozess haben möchten.
Warum Sie es verwenden sollten: Octoparse ist eines der besten Screen-Scraping-Tools für Leute, die Websites scrapen möchten, ohne Programmieren zu lernen. Es verfügt über einen Point-and-Click-Screen-Scraper, der es Benutzern ermöglicht, hinter Anmeldeformulare zu scrollen, Formulare auszufüllen, Suchbegriffe einzugeben, durch unendliches Scrollen zu scrollen, JavaScript zu rendern und vieles mehr.
Es umfasst außerdem einen Site-Parser und eine gehostete Lösung für Benutzer, die ihre Scraper in der Cloud ausführen möchten. Das Beste daran ist, dass es ein großzügiges kostenloses Kontingent gibt, sodass Benutzer bis zu 10 Crawler kostenlos erstellen können. Für Unternehmenskunden bieten sie außerdem vollständig angepasste Crawler und verwaltete Lösungen an, bei denen sie alles für Sie ausführen und Ihnen die Daten einfach direkt liefern.
Vorteile
Benutzerfreundlichkeit: Octoparse wird für seine benutzerfreundliche Oberfläche, insbesondere den Smart-Modus und den Assistentenmodus, hoch gelobt, wodurch es auch für jeden mit eingeschränkten technischen Fähigkeiten zugänglich ist.
Erweiterter Modus für Präzision: Der erweiterte Modus ist dafür bekannt, dass er eine präzise und genaue Datenextraktion ermöglicht und es technisch versierteren Personen ermöglicht, ihre Scraping-Aufgaben zu verfeinern.
XPath-Unterstützung: Die Octoparse-XPath-Unterstützung ist klar und benutzerfreundlich und hilft Ihnen, bestimmte Elemente effizient aus Webseiten zu extrahieren.
Geschwindigkeit und Automatisierung: Octoparse zeichnet sich durch Geschwindigkeit aus und wird besonders für die Automatisierung der Extraktion großer Datensätze geschätzt, was für Aufgaben wie das Sammeln von E-Mail-IDs oder das Scrapen von Produktdaten nützlich ist.
Keine Codierung erforderlich: Octoparse vereinfacht den Datenextraktionsprozess und ermöglicht Ihnen das Scrapen von Websites ohne jegliche Programmierung oder komplexe Regelsetzung.
Nachteile
Lernkurve für erweiterte Funktionen: Während die Grundfunktionen benutzerfreundlich sind, kann es für einige Benutzer ohne Vorkenntnisse schwierig sein, den erweiterten Modus oder die XPath-Anpassung anzupassen.
Bewertungen
Trustpilot-Bewertung – 3,0
Benutzerfreundlichkeit
⭐⭐⭐⭐(4/5)
Preise
Die Preismodelle von Octoparse sind relativ fair, da sie pro Aufgabe abrechnen. Ihr Abonnement bestimmt also die Anzahl der Aufgaben, die Sie ausführen können.
Planen
Preise
Aufgabe
Kostenlose Testversion
Frei
10
Standard
119 $
100
Prämie
299 $
250
Trotz der fairen Preise ist Octoparse im Vergleich zu ScraperAPI für mittlere und große Projekte immer noch nicht kosteneffektiv. Der kostenlose Plan von ScraperAPI bietet 5.000 API-Credits, sodass Sie bis zu 5.000 URLs ohne umfangreiche Anti-Bots scrapen können.
Der günstigste Plan von ScraperAPI bietet Geo-Targeting-Funktionen für die USA und die EU für standortbezogene Aufgaben, um Ihnen beim Extrahieren von Daten von bestimmten Standorten zu helfen.
Für wen ist das: ParseHub ist ein leistungsstarkes Tool zum Erstellen von Web-Scrapern ohne Codierung – Analysten, Journalisten, Datenwissenschaftler und alle dazwischen nutzen es.
Warum Sie es verwenden sollten: ParseHub ist äußerst einfach zu bedienen. Die automatische IP-Rotation sorgt dafür, dass Ihre Scraping-Aktivitäten unentdeckt bleiben und bietet Ihnen zuverlässigen Zugriff auf die benötigten Daten, selbst von Websites mit strengen Zugriffskontrollen. Sie können Web-Scraper erstellen, indem Sie einfach auf die gewünschten Daten klicken. ParseHub exportiert die Daten dann im JSON- oder Excel-Format. Es verfügt über viele praktische Funktionen, wie zum Beispiel die automatische IP-Rotation, das Scraping von Webseiten hinter Login-Walls, das Durchsuchen von Dropdown-Listen und Registerkarten, das Abrufen von Daten aus Tabellen und Karten und vieles mehr.
Darüber hinaus gibt es ein großzügiges kostenloses Kontingent, mit dem Benutzer in nur 40 Minuten bis zu 200 Seiten Daten durchsuchen können! ParseHub ist auch deshalb nett, weil es Desktop-Clients für Windows, Mac OS und Linux bereitstellt, sodass Sie sie von Ihrem Computer aus verwenden können, egal welches System Sie verwenden.
Vorteile
Benutzerfreundlichkeit für einfache Aufgaben: ParseHub verfügt über eine benutzerfreundliche Oberfläche, die ein einfaches Web-Scraping ermöglicht, ohne dass viel technisches Fachwissen erforderlich ist.
Automatisierungsfunktionen: ParseHub verfügt über nützliche Automatisierungsfunktionen wie Planung und dynamisches Page Scraping, die es Benutzern ermöglichen, komplexe Websites mit mehreren Datenebenen zu scrapen
Kostenlose Version: Es bietet eine robuste kostenlose Version, die es für diejenigen zugänglich macht, die seine Funktionen ausprobieren möchten, bevor sie sich für einen kostenpflichtigen Plan entscheiden. Darin enthalten sind bis zu 200 Seiten pro Auflage und 5 öffentliche Projekte.
Kostengünstige Skalierbarkeit: Es bietet mehrere Preisstufen, darunter den Standardplan für 189 $/Monat, der bis zu 10.000 Seiten pro Auflage ermöglicht, und einen Professional-Plan mit erweiterten Funktionen wie schnellerem Scraping und vorrangigem Support.
Nachteile
Support-Einschränkungen: Es gab Beschwerden darüber, dass der Kundensupport stärker verkaufsorientiert sei und sich weniger auf die Lösung von Problemen konzentriere, insbesondere bei Benutzern, die kostenlose Testversionen nutzen.
Muss installiert werden: Wenn die Abstreifer lokal auf Ihrer Maschine laufen, bedeutet das, dass Sie eine größere Investition in die Ausrüstung benötigen, um Ihren Betrieb auszubauen.
Anpassungsgrenzen: Da es sich um eine Low-Code-Plattform handelt, ist sie restriktiver als dedizierte Scraping-APIs.
Bewertungen
Trustpilot-Bewertung – Null
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Die ParseHub-Preise basieren auf Geschwindigkeit und Seiten. Je höher Ihr Abonnement, desto mehr Seiten können Sie scrapen.
Planen
Preise
Seiten
Kostenlose Testversion
Frei
200 Seiten pro Durchlauf in 40 Minuten
Standard
189 $
10.000 Seiten pro Durchlauf (200 Seiten in 10 Minuten)
Professional
599 $
Unbegrenzt in weniger als 2 Minuten
ParseHub Plus
Brauch
Brauch
Basierend auf der Anzahl der Seiten ist scraperAPI wirtschaftlicher, da Sie mit dem niedrigsten Plan mit 100.000 API-Credits – 49 US-Dollar pro Monat – problemlos über 10.000 Seiten erhalten.
5. Scrapy (Crawling und Scraping der Python-Bibliothek)
Für wen ist das: Scrapy ist eine Open-Source-Web-Scraping-Bibliothek für Python-Entwickler, die skalierbare Webcrawler erstellen möchten. Es handelt sich um ein umfassendes Framework, das alle Installationen (Warteschlangenanforderungen, Proxy-Middleware usw.) verwaltet, die die Erstellung von Webcrawlern erschweren.
Warum Sie es verwenden sollten: Als Open-Source-Tool ist Scrapy völlig kostenlos. Sie ist kampferprobt und seit Jahren eine der beliebtesten Python-Bibliotheken. Es gilt als das beste Python-Web-Scraping-Tool für neue Anwendungen. Es gibt eine Lernkurve, die jedoch gut dokumentiert ist und es stehen zahlreiche Tutorials zur Verfügung, die Ihnen den Einstieg erleichtern.
Darüber hinaus ist der Einsatz der Crawler sehr einfach und zuverlässig. Sobald sie eingerichtet sind, können die Prozesse selbstständig ablaufen. Als voll funktionsfähiges Web-Scraping-Framework stehen viele Middleware-Module zur Verfügung, um verschiedene Tools zu integrieren und verschiedene Anwendungsfälle (Umgang mit Cookies, Benutzeragenten usw.) abzuwickeln.
Vorteile
Kriechen und Kratzen mit hoher Geschwindigkeit: Scrapy ist für seine Schnelligkeit bei der Abwicklung groß angelegter Web-Scraping-Projekte bekannt. Es ist mit asynchroner Netzwerkunterstützung ausgestattet, was bedeutet, dass mehrere Anfragen gleichzeitig gesendet werden können, wodurch Leerlaufzeiten reduziert werden. Dies macht es äußerst effizient bei der Extraktion großer Datenmengen von Websites in kurzer Zeit.
Fähigkeit zur Datenextraktion im großen Maßstab: Mit Scrapy können Sie riesige Datenmengen scrapen. Dank der Fähigkeit, verteilte Crawler zu verwalten, können Sie Ihre Projekte skalieren, indem Sie mehrere Spider gleichzeitig ausführen. Dies macht Scrapy ideal für Scraping-Projekte auf Unternehmensebene, bei denen täglich Tausende von Seiten gecrawlt werden müssen.
Speichereffiziente Prozesse: Scrapy nutzt eine effiziente Speicherverwaltung, um umfangreiche Web-Scraping-Aufgaben mit minimalem Ressourcenverbrauch zu verwalten. Im Gegensatz zu browserbasierten Scrapern lädt Scrapy keine vollständigen HTML-Seiten und rendert kein JavaScript, wodurch die Speichernutzung niedrig bleibt und eine große Anzahl von Anfragen ohne Leistungseinbußen verarbeitet werden kann.
Hochgradig anpassbar und erweiterbar: Die modulare Architektur von Scrapy ermöglicht es Entwicklern, ihre Scraping-Projekte einfach anzupassen. Sie können die Kernfunktionen von Scrapy ändern oder erweitern, Bibliotheken von Drittanbietern integrieren oder sogar benutzerdefinierte Middleware und Pipelines erstellen, um spezifischen Projektanforderungen gerecht zu werden. Diese Flexibilität macht es ideal für Benutzer, die eine genaue Kontrolle über ihre Schabevorgänge wünschen.
Nachteile
Unterstützt kein dynamisches Content-Rendering: Scrapy hat Probleme mit Websites, die JavaScript zum Rendern dynamischer Inhalte verwenden. Da es sich um einen HTML-Parser und nicht um einen vollständigen Browser handelt, kann Scrapy nicht mit JavaScript-gesteuerten Elementen interagieren.
Steile Lernkurve: Scrapy wurde speziell für Entwickler entwickelt, was es für Anfänger zu einer Herausforderung machen kann. Es erfordert ein solides Verständnis von Python, Web-Scraping-Techniken und asynchroner Programmierung. Für diejenigen, die neu im Web Scraping sind oder keine ausgeprägten technischen Kenntnisse haben, kann die Beherrschung von Scrapy viel Zeit und Mühe kosten.
Bewertung
Pro Github-Stern – 52,5.000
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Preise
Frei
Verwandt: So scrapen Sie Websites mit Scrapy und ScraperAPI.
Für wen ist das: Diffbot ist eine Unternehmenslösung für Unternehmen mit hochspezialisierten Daten-Crawling- und Screen-Scraping-Anforderungen, insbesondere für diejenigen, die Websites crawlen, deren HTML-Struktur häufig geändert wird.
Warum Sie es verwenden sollten: Diffbot unterscheidet sich von den meisten Webseiten-Scraping-Tools dadurch, dass es Computer Vision (anstelle von HTML-Parsing) verwendet, um relevante Informationen auf einer Seite zu identifizieren. Das bedeutet, dass Ihre Web-Scraper nicht kaputt gehen, selbst wenn sich die HTML-Struktur einer Seite ändert, solange die Seite optisch gleich aussieht. Dies ist eine unglaubliche Funktion für lang andauernde, geschäftskritische Web-Scraping-Jobs.
Diffbot ist teuer (der günstigste Plan kostet 299 $/Monat), aber sie leisten hervorragende Arbeit und bieten einen Premium-Service, der sich für Großkunden möglicherweise lohnt.
Vorteile
Automatisierte Datenextraktion mit KI: Diffbot nutzt KI, um strukturierte Daten aus unstrukturierten Webseiten zu analysieren und zu extrahieren, sodass keine manuelle Codierung erforderlich ist. Es kann bestimmte Inhaltstypen wie Artikel, Produkte, Bilder usw. automatisch erkennen und extrahieren. Dies macht es äußerst effizient für groß angelegte Datenextraktionsprojekte, ohne dass benutzerdefinierte Scraper entwickelt werden müssen.
Unterstützt dynamische Inhalte: Im Gegensatz zu einigen Web-Scraping-Tools ist Diffbot in der Lage, dynamische Inhalte zu verarbeiten, die von JavaScript generiert werden. Dies ist besonders nützlich für Websites, die Inhalte dynamisch laden oder auf clientseitiges Rendering angewiesen sind.
Umfangreiche API-Unterstützung: Diffbot bietet mehrere APIs für unterschiedliche Datenextraktionsanforderungen, einschließlich seiner Knowledge Graph API, die es Benutzern ermöglicht, strukturierte Daten über eine Vielzahl von Domänen hinweg abzufragen und abzurufen. Es bietet außerdem Artikel-, Produkt- und Bild-APIs, was es vielseitig für das Scrapen verschiedener Inhaltstypen von Websites macht.
Nachteile
Hohe Kosten: Die erweiterten Funktionen und der Unternehmensfokus von Diffbot haben einen Premium-Preis. Für kleine Betriebe oder einzelne Benutzer können die Kosten unerschwinglich sein. Das Preismodell ist nutzungsbasiert, was bedeutet, dass ein höheres Anfragevolumen zu erheblichen Kosten führen kann, sodass es für Low-Budget- oder kleine Projekte weniger geeignet ist.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Die Preise von Diffbot ähneln denen von ScraperAPI, da sie auf Guthaben basieren, Diffbot jedoch nicht pro erfolgreicher Anfrage abrechnet.
Wie Sie in der Tabelle und dem Bild unten sehen können, kostet Diffbot 299 US-Dollar für 250.000 Credits, was 250.000 Seiten (erfolgreich oder nicht) bei 1 Credit pro Seite entspricht.
Andererseits bietet ScraperAPI 1 Mio. API-Credits für nur 149 US-Dollar, sodass Sie auf 1 Mio. erfolgreiche Anfragen/Seiten zugreifen können.
Planen
Preise
Kredit
Frei
Frei
10.000 Credits (0 $ pro Credit)
Start-up
299 $
250.000 Credits (0,001 $ pro Credit)
Plus
899 $
1.000.000 Credits (0,0009 $ pro Credit)
Unternehmen
Brauch
Brauch
7. Cheerio (HTML-Parser für Node.js)
Für wen ist das: NodeJS-Entwickler, die eine unkomplizierte Möglichkeit zum Parsen von HTML suchen. Wer mit jQuery vertraut ist, wird die beste verfügbare JavaScript-Web-Scraping-Syntax sofort zu schätzen wissen.
Warum Sie es verwenden sollten: Cheerio bietet eine API ähnlich wie jQuery, sodass sich Entwickler, die mit jQuery vertraut sind, sofort zu Hause fühlen werden, wenn sie Cheerio zum Parsen von HTML verwenden. Es ist rasend schnell und bietet viele hilfreiche Methoden zum Extrahieren von Text, HTML, Klassen, IDs usw.
Es ist mit Abstand die beliebteste in NodeJS geschriebene HTML-Parsing-Bibliothek und wahrscheinlich das beste NodeJS- oder JavaScript-Web-Scraping-Tool für neue Projekte.
Vorteile
Leicht und schnell: Cheerio ist eine schnelle und effiziente Bibliothek zum Parsen und Bearbeiten von HTML und XML. Da es kein JavaScript rendert oder einen Browser simuliert, arbeitet es mit minimalem Overhead und eignet sich daher ideal für Aufgaben, die nur statischen HTML-Inhalt umfassen.
jQuery-ähnliche Syntax: Eine der herausragenden Funktionen von Cheerio ist seine jQuery-ähnliche Syntax, die es Entwicklern, die mit jQuery vertraut sind, erleichtert, schnell mit Cheerio zu beginnen. Die Manipulation von DOM-Elementen im jQuery-Stil macht das Scrapen und Extrahieren von Daten einfach und intuitiv.
Flexibel und erweiterbar: Sie können Cheerio problemlos in andere Tools und APIs integrieren. Aufgrund seines modularen Aufbaus passt es in benutzerdefinierte Scraping-Pipelines und ist somit an eine Vielzahl von Web-Scraping-Anforderungen anpassbar.
Nachteile
Bedarf an zusätzlichen Werkzeugen für komplexere Schabearbeiten: Während Cheerio für grundlegende Scraping-Aufgaben leichtgewichtig und effizient ist, erfordert die Bewältigung komplexerer Szenarien wie der Interaktion mit dynamischen Elementen oder der Umgehung von Anti-Scraping-Maßnahmen die Kombination mit fortschrittlicheren Tools. Dies erhöht die Komplexität der Scraping-Einrichtung und des Arbeitsablaufs.
Eingeschränkte Unterstützung für JavaScript-lastige Websites: Cheerio führt kein JavaScript aus, daher werden Inhalte, die von der clientseitigen JavaScript-Ausführung abhängen, nicht erfasst. Diese Einschränkung erfordert die Integration zusätzlicher Tools wie Puppeteer oder Selenium, die eine echte Browserumgebung simulieren können.
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Bewertung
Preise
Frei
Verwandt: So durchsuchen Sie HTML-Tabellen mit Axios und Cheerio.
8. BeautifulSoup (HTML-Parser für Python)
Für wen ist das: Python-Entwickler, die einfach nur eine einfache Schnittstelle zum Parsen von HTML wünschen und nicht unbedingt die Leistung und Komplexität von Scrapy benötigen.
Warum Sie es verwenden sollten: Wie Cheerio für NodeJS-Entwickler ist BeautifulSoup der beliebteste HTML-Parser für Python-Entwickler. Es gibt sie nun schon seit über einem Jahrzehnt und sie ist äußerst gut dokumentiert. In vielen Web-Parsing-Tutorials wird Entwicklern beigebracht, wie man damit verschiedene Websites in Python 2 und Python 3 durchsucht. Wenn Sie nach einer Python-HTML-Parsing-Bibliothek suchen, ist dies genau das Richtige für Sie du willst.
Vorteile
Einfach zu bedienen und zu erlernen: BeautifulSoup verfügt über eine einfache und intuitive API, wodurch es sowohl für Anfänger als auch für erfahrene Entwickler zugänglich ist. Es ermöglicht Ihnen, HTML- und XML-Dokumente einfach zu analysieren und Daten mit minimalem Code zu extrahieren.
Flexibel mit Parsern: BeautifulSoup ist mit mehreren Parsern kompatibel, beispielsweise dem integrierten HTML-Parser von Python, lxml und html5lib. Dank dieser Flexibilität können Sie den Parser auswählen, der Ihren Anforderungen am besten entspricht, unabhängig davon, ob es um Geschwindigkeit oder Vollständigkeit beim Umgang mit schlecht formatiertem HTML geht.
Integration mit anderen Bibliotheken: BeautifulSoup lässt sich gut in andere Python-Bibliotheken wie Requests und LXML integrieren und erleichtert so die Einrichtung umfassender Scraping-Pipelines zum Abrufen und Verarbeiten von Daten von Websites.
Behandelt unvollständiges HTML: BeautifulSoup ist für seine Robustheit im Umgang mit schlecht strukturiertem oder fehlerhaftem HTML bekannt. Es korrigiert automatisch Fehler in HTML-Dokumenten und erleichtert so das Scrapen von Websites mit inkonsistentem Markup.
Nachteile
Keine JavaScript-Unterstützung: BeautifulSoup kann keine Websites verarbeiten, die zum Laden von Inhalten stark auf JavaScript angewiesen sind. Da es mit statischem HTML funktioniert, ist der Zugriff auf dynamische, mit JavaScript generierte Inhalte ohne die Integration zusätzlicher Tools wie Selenium nicht möglich.
Manueller Aufwand für komplexe Aufgaben erforderlich: BeautifulSoup eignet sich gut für einfache HTML-Parsing-Aufgaben, erfordert jedoch mehr manuelle Codierung, um komplexe Aufgaben wie Paginierung, Proxy-Verwaltung oder Umgehung von Anti-Scraping-Maßnahmen zu bewältigen.
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Bewertung
Preise
Frei
Verwandt: Scraping von HTML-Websites mit BeautifulSoup und ScraperAPI.
9. Puppeteer (Headless Chrome API für Node.js)
Für wen ist das: Puppeteer ist eine Headless-Chrome-API für NodeJS-Entwickler, die eine detaillierte Kontrolle über ihre Scraping-Aktivitäten wünschen.
Warum Sie es verwenden sollten: Puppeteer ist ein Open-Source-Tool, das völlig kostenlos ist. Es wird gut unterstützt, aktiv weiterentwickelt und vom Google Chrome-Team unterstützt. Es ersetzt schnell Selenium und PhantomJS als standardmäßiges Headless-Browser-Automatisierungstool.
Es verfügt über eine durchdachte API und installiert im Rahmen des Einrichtungsprozesses automatisch eine kompatible Chromium-Binärdatei, sodass Sie nicht selbst den Überblick über die Browserversionen behalten müssen.
Obwohl es sich um viel mehr als nur eine Web-Crawling-Bibliothek handelt, wird sie häufig zum Auslesen von Website-Daten von Websites verwendet, die JavaScript zum Anzeigen von Informationen benötigen.
Es verarbeitet Skripte, Stylesheets und Schriftarten wie ein echter Browser. Es ist zwar eine hervorragende Lösung für Websites, die JavaScript zum Anzeigen von Daten benötigen, ist aber auch sehr CPU- und speicherintensiv. Daher ist es keine gute Idee, es für Websites zu verwenden, auf denen ein vollwertiger Browser nicht erforderlich ist. In den meisten Fällen reicht eine einfache GET-Anfrage aus!
Vorteile
Headless-Browser-Automatisierung: Mit Puppeteer können Sie Chrome oder Chromium im Headless-Modus steuern, was es ideal für Automatisierungsaufgaben wie Web Scraping, UI-Tests und das Generieren von PDFs aus Webseiten macht.
Plattformübergreifend: Puppeteer funktioniert auf mehreren Plattformen (Linux, macOS, Windows) und unterstützt sowohl Headless- als auch Non-Headless-Modi, was es für eine Reihe von Anwendungsfällen vielseitig macht, von der lokalen Entwicklung bis zur Bereitstellung in Cloud-Umgebungen.
Nachteile
Ressourcenintensiv: Das Ausführen von Headless-Chrome-Instanzen kann ressourcenintensiv sein, insbesondere bei der Skalierung von Scraping-Jobs oder Automatisierungsaufgaben. Es erfordert mehr CPU und Speicher im Vergleich zu einfachen Tools wie Cheerio oder nicht browserbasierten Scrapern.
Manuelle Einrichtung für erweiterte Anwendungsfälle: Puppeteer verfügt nicht über eine integrierte Planung, Datenextraktionsvorlagen oder Datenspeicherfunktionen. Sie müssen diese Prozesse manuell erstellen, was die Komplexität der Verwendung des Tools für umfangreiche Projekte erhöhen kann.
Es fehlen integrierte Scraping-Funktionen: Puppeteer ist ein Allzweck-Browser-Automatisierungstool und verfügt nicht über spezifische Web-Scraping-Optimierungen (z. B. Handhabung von CAPTCHAs oder IP-Rotation). Für das Scraping großer, geschützter Websites benötigen Sie zusätzliche Tools oder Dienste für Anti-Scraping-Bypass-Techniken wie ScraperAPI.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐⭐ (5/5)
Preise
Frei
Verwandt: Scraping von Amazon mit Puppeteer und ScraperAPI.
10. Mozenda
Für wen ist das: Unternehmen, die nach einer cloudbasierten Self-Service-Webpage-Scraping-Plattform suchen, müssen nicht weiter suchen. Mit über 7 Milliarden gecrawlten Seiten verfügt Mozenda über Erfahrung in der Betreuung von Unternehmenskunden weltweit.
Warum Sie es verwenden sollten: Mozenda zeichnet sich durch seinen Kundenservice aus (der allen zahlenden Kunden sowohl Telefon- als auch E-Mail-Support bietet). Die Plattform ist hoch skalierbar und ermöglicht auch On-Premise-Hosting. Wie Diffbot ist es etwas teuer, wobei der niedrigste Plan bei 250 $/Monat beginnt.
Vorteile
Benutzerfreundliche Oberfläche: Mozenda ist für technisch nicht versierte Benutzer konzipiert und verfügt über eine intuitive Point-and-Click-Oberfläche, die das Einrichten und Ausführen von Scraping-Jobs ohne Programmieraufwand vereinfacht.
Automatisierung und Planung: Mozenda unterstützt die Planung und Automatisierung von Scraping-Aufgaben, sodass Sie wiederkehrende Jobs festlegen und Daten regelmäßig ohne manuelles Eingreifen scrapen können.
Flexibilität beim Datenexport: Mozenda bietet eine breite Palette an Datenexportoptionen, mit denen Sie Scraped-Daten in mehrere Formate wie CSV, Excel, XML oder direkt in eine Datenbank exportieren können. Es lässt sich auch in andere Datendienste integrieren.
Nachteile
Preise: Die Preise von Mozenda sind höher als bei einigen anderen Scraping-Tools, was für kleine Unternehmen oder Einzelpersonen mit begrenztem Budget ein Nachteil sein kann. Die Kosten steigen mit der Anzahl der gescrapten Seiten oder dem Grad der Datenkomplexität.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Die Preise von Mozenda sind auf der Website nicht klar angegeben, aber einem im Jahr 2018 veröffentlichten Preismodelldokument, das auch unten zu sehen ist, ist die Preisgestaltung von Mozenda kreditbasiert und im Vergleich zu Wettbewerbern wie ScraperAPI recht teuer.
Planen
Preise
Credits
Lagerung
Basic
99 $/Monat
Projekt
300 $/Monat
20.000
1 GB
Professional
400 $/Monat
35.000
5 GB
Unternehmen
450 $/Monat (jährliche Abrechnung)
1.000.000+ jährlich
50 GB
Hohe Kapazität
40.000 $/Jahr
Brauch
Brauch
Vor Ort
Brauch
Brauch
Brauch
11. ScrapeHero Cloud (cloudbasierte, für Sie erstellte Scraping-Dienste)
Für wen ist das: ScrapeHero ist cloudbasiert und benutzerfreundlich, was es ideal macht, wenn Sie kein Programmierer sind. Sie müssen lediglich die Eingaben vornehmen und auf „Daten sammeln“ klicken. Sie verfügen über umsetzbare Daten in den Formaten JSON, CSV oder Excel.
Warum Sie es verwenden sollten: ScrapeHero hat ein browserbasiertes, automatisiertes Scraping-Tool entwickelt, mit dem Sie mit nur wenigen Klicks alles, was Sie im Internet haben möchten, in Tabellenkalkulationen herunterladen können. Es ist günstiger als die Vollservices und es gibt eine kostenlose Testversion. Es verwendet vorgefertigte Crawler mit automatisch rotierenden Proxys. Echtzeit-APIs erfassen Daten von einigen der größten Online-Händler und -Dienste, darunter Karten, Produktpreise, aktuelle Nachrichten und mehr. Dieses Data-as-a-Service-Tool ist perfekt für Unternehmen, insbesondere für diejenigen, die sich für KI interessieren.
Vorteile
Anpassbare Lösungen: ScrapeHero bietet vollständig anpassbare Web-Scraping-Lösungen, die auf die spezifischen Bedürfnisse von Unternehmen zugeschnitten sind. Dadurch können Sie unabhängig von der Komplexität oder Größe der Website genau die Daten sammeln, die sie benötigen.
Keine Codierung erforderlich: ScrapeHero ist benutzerfreundlich und erfordert keine technischen Kenntnisse. Unternehmen können benutzerdefinierte Daten extrahieren, ohne dass interne Entwickler oder technisches Fachwissen erforderlich sind.
Nachteile
Höhere Kosten für kundenspezifische Lösungen: Während ScrapeHero eine Reihe von Preisplänen anbietet, können seine individuellen Daten-Scraping-Dienste im Vergleich zu DIY-Tools oder -Plattformen teuer sein, insbesondere für Unternehmen mit kleineren Budgets oder begrenztem Scraping-Bedarf.
Eingeschränkte Self-Service-Funktionen: Wenn Sie nach einem Self-Service-Tool zum manuellen Einrichten und Ausführen von Scraping-Jobs suchen, ist ScrapeHero möglicherweise nicht ideal. Es ist eher für verwaltete Dienste konzipiert, was die Flexibilität für diejenigen einschränken kann, die die volle Kontrolle über ihre Scraping-Prozesse wünschen.
Bewertung
Trustpilot-Bewertung – 3,7
Benutzerfreundlichkeit
⭐⭐⭐⭐ (4/5)
Preise
Aus dem Bild oben können Sie ersehen, dass das Preismodell von ScrapeHero auf der Anzahl der Seiten basiert, die Sie scrapen möchten. Dies macht es kostengünstig, wenn Sie eine kleinere Anzahl von Seiten durchschaben möchten. Andererseits bietet ScraperAPI mehr API-Anfragen zu einem niedrigeren Startpreis, was es zu einer besseren Option für große Scraping-Projekte macht.
12. Webscraper.io (Point-and-Click-Chrome-Erweiterung für Web-Scraping)
Für wen ist das: Eine weitere benutzerfreundliche Option für Nicht-Entwickler, WebScraper.io, ist eine einfache Google Chrome-Browsererweiterung. Es ist nicht so umfassend ausgestattet wie die anderen Web-Scraping-Tools auf dieser Liste, aber es ist eine ideale Option für diejenigen, die mit kleineren Datenmengen arbeiten und nicht viel Automatisierung benötigen.
Warum Sie es verwenden sollten: WebScraper.io hilft Benutzern beim Einrichten einer Sitemap, um auf einer bestimmten Website zu navigieren und genau zu bestimmen, welche Informationen erfasst werden. Das zusätzliche Plugin kann mehrere JS- und Ajax-Seiten gleichzeitig verarbeiten, und Entwickler können ihre Scraper so erstellen, dass sie Daten direkt aus dem Browser in CVS oder aus der Cloud von Web Scraper in CVS, XLSX und JSON extrahieren. Sie können auch regelmäßige Scrapes mit regelmäßiger IP-Rotation planen. Die Browser-Erweiterung ist kostenlos, aber Sie können die kostenpflichtigen Dienste mit einer kostenlosen Testversion testen.
Vorteile
Cloudbasiertes Scraping: Webscraper.io ist ein browserbasiertes Daten-Scraping-Tool, mit dem Sie Scraping-Aufgaben im Hintergrund ausführen können, ohne lokale Ressourcen zu binden. Dadurch können Sie auch große Datenmengen effizient durchsuchen.
Erschwingliche Preise: Webscraper.io verfügt über verschiedene Preispläne, darunter einen kostenlosen Plan, wodurch es für Benutzer mit unterschiedlichen Bedürfnissen und Budgets zugänglich ist. Dadurch können Sie die Plattform ohne nennenswerte Vorabkosten nutzen.
Nachteile
Beschränkt auf die Chrome-Erweiterung: Webscraper.io ist nur als Chrome-Erweiterung verfügbar, was seine Benutzerfreundlichkeit einschränkt. Es fehlt auch ein dedizierter Desktop oder eine eigenständige Anwendung, was ein Nachteil sein könnte, wenn Sie Chrome nicht verwenden.
Einschränkungen des kostenlosen Plans: Der kostenlose Plan ist zwar nützlich, schränkt jedoch die Anzahl der Seiten und Daten, die gescrapt werden, erheblich ein. Bei Großprojekten müssen Sie sich für einen der kostenpflichtigen Tarife entscheiden.
Bewertung
Trustpilot-Bewertung – 3,7
Benutzerfreundlichkeit
⭐⭐⭐(3/5)
Preise
Webscraper.io ist eines der günstigsten Web-Scraping-Tools auf dem Markt. Es gibt einen kostenlosen Plan mit einem Startpreis von 50 $. Diese Preisgestaltung basiert auf Cloud-Guthaben, wobei 1 Cloud-Guthaben = 1 Seite ist.
Planen
Preis
Cloud-Guthaben
Browser-Erweiterung
Frei
Nill (nur lokale Verwendung)
Projekt
50 $
5.000
Professional
100 $
20.000
Geschäft
200 $
50.000
Skala
200 $+
Unbegrenzt
13. Kimura
Für wen ist das: Kimura ist ein in Ruby geschriebenes Open-Source-Web-Scraping-Framework. Es macht es unglaublich einfach, einen Ruby Web Scraper zum Laufen zu bringen.
Warum Sie es verwenden sollten: Kimura wird schnell als beste Ruby-Web-Scraping-Bibliothek anerkannt. Es ist so konzipiert, dass es sofort mit Headless Chrome/Firefox, PhantomJS und normalen GET-Anfragen funktioniert. Seine Syntax ähnelt Scrapy, und Entwickler, die Ruby-Web-Scraper schreiben, werden die netten Konfigurationsoptionen zum Festlegen einer Verzögerung, zum Rotieren von Benutzeragenten und zum Festlegen von Standard-Headern lieben.
Vorteile
Rubinbasiert: Kimurai ist in Ruby erstellt, was für Entwickler von Vorteil ist, die mit der Programmiersprache Ruby vertraut sind. Es bietet ein Framework zum Schreiben von Web-Scrapern in Ruby und erleichtert Ruby-Entwicklern die Integration von Scraping in ihre Projekte.
Integrierte Web-Scraping-Tools: Kimurai verfügt über integrierte Scraping-Tools wie Sitzungsverwaltung, automatische Wiederholungsversuche, Anforderungsverzögerungen und Proxy-Unterstützung. Dies reduziert die Notwendigkeit, zusätzliche Tools oder Bibliotheken manuell zu integrieren, was den Scraping-Prozess vereinfacht.
Open Source: Da es sich um eine Open-Source-Lösung handelt, kann Kimurai kostenlos verwendet werden und der Quellcode kann geändert werden. Dies macht es zu einer kostengünstigen Lösung für Entwickler, die Web-Scraping-Anwendungen erstellen möchten.
Nachteile
Einschränkung des Ruby-Ökosystems: Kimurai ist in Ruby erstellt, einer im Vergleich zu Python weniger häufig verwendeten Sprache für Web Scraping. Dies schränkt die Community-Unterstützung und die verfügbaren Ressourcen ein, insbesondere im Vergleich zu weit verbreiteten Scraping-Frameworks wie BeautifulSoup in Python.
Eingeschränkte Dokumentation: Obwohl Kimurai ein leistungsstarkes Tool ist, ist seine Dokumentation nicht so umfangreich wie bei anderen gängigen Frameworks, was den Einstieg für Neueinsteiger erschwert.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (3/5)
Preise
Frei
14. Goutte
Für wen ist das: Goutte ist ein in PHP geschriebenes Open-Source-Webcrawler-Framework, was es äußerst nützlich für Entwickler macht, die Daten aus HTML/XML-Antworten mit PHP extrahieren möchten.
Warum Sie es verwenden sollten: Goutte ist ein sehr unkompliziertes, schnörkelloses Framework, das viele für die beste PHP-Web-Scraping-Bibliothek halten. Es ist auf Einfachheit ausgelegt und bewältigt die meisten HTML/XML-Anwendungsfälle ohne allzu großen zusätzlichen Aufwand.
Es lässt sich außerdem nahtlos in die hervorragende Guzzle-Anforderungsbibliothek integrieren, mit der Sie das Framework für komplexere Anwendungsfälle anpassen können.
Vorteile
PHP-Integration: Als PHP-basiertes Tool ist Goutte eine großartige Option für Entwickler, die bereits mit dem PHP-Ökosystem vertraut sind. Es lässt sich gut in PHP-Anwendungen integrieren und kann in vorhandenen Frameworks wie Laravel oder Symfony verwendet werden.
Kopfloses Schaben: Goutte benötigt keine Browser-Engine, was es viel schneller und weniger ressourcenintensiv macht als browserbasierte Scraper wie Puppeteer oder Selenium. Es ist effizient zum Scrapen statischer Websites, die nicht stark auf JavaScript angewiesen sind.
Verwendet Symfony-Komponenten: Goutte nutzt leistungsstarke Symfony-Komponenten wie DomCrawler und BrowserKit und ist damit eine robuste Option zum programmgesteuerten Navigieren und Scrapen von HTML-Inhalten. Dies ermöglicht es Benutzern, Benutzeraktionen wie Formularübermittlungen, Linkklicken und Sitzungsverwaltung einfach zu simulieren.
Gut für statische Websites: Goutte zeichnet sich durch das Scraping statischer Inhalte aus. Für Websites, die nicht auf JavaScript zum dynamischen Laden von Daten angewiesen sind, schneidet Goutte in Bezug auf Geschwindigkeit und Effizienz außergewöhnlich gut ab.
Nachteile
Eingeschränkte JavaScript-Unterstützung: Goutte unterstützt kein JavaScript-Rendering, was bedeutet, dass es für das Scraping dynamischer Websites, die JavaScript zum Laden von Inhalten verwenden, unwirksam ist. Diese Einschränkung macht es ungeeignet für das Scraping moderner Single-Page-Anwendungen (SPAs) oder JavaScript-lastiger Websites.
PHP-Abhängigkeit: Da es sich um ein PHP-basiertes Tool handelt, ist seine Verwendung in PHP-Umgebungen eingeschränkt. Dies ist möglicherweise nicht ideal für Entwickler, die in anderen Sprachen arbeiten oder einen sprachunabhängigeren Ansatz für Web Scraping bevorzugen, wie z. B. die Verwendung von Python mit Scrapy oder BeautifulSoup.
Nicht ideal für großflächiges Schaben: Während Goutte für kleinere Scraping-Aufgaben effizient ist, ist es nicht für die Abwicklung großer Projekte optimiert, die eine hohe Parallelität oder verteiltes Scraping über mehrere Maschinen erfordern. Robustere Frameworks wie Scrapy oder Puppeteer eignen sich besser für solche Projekte.
Bewertung
Benutzerfreundlichkeit
⭐⭐⭐⭐ (3/5)
Preise
Frei
Welche Faktoren sollten Sie bei der Auswahl von Web-Scraping-Tools berücksichtigen?
Der Auswahlprozess muss sich an bestimmten technischen und praktischen Kriterien orientieren, wenn es darum geht, potenzielle Web-Scraper zu bewerten, die Sie Ihrem Arsenal hinzufügen möchten.
Folgende Faktoren sollten geprüft werden:
Datenextraktionsfunktionen: Ein gutes Web-Scraping-Tool unterstützt verschiedene Datenformate und kann Inhalte aus verschiedenen Webstrukturen extrahieren, einschließlich statischer HTML-Seiten und dynamischer Websites mithilfe von JavaScript.
Benutzerfreundlichkeit: Bewerten Sie die Lernkurve, die Benutzeroberfläche und die verfügbare Dokumentation des Tools. Wer es nutzt, sollte die Komplexität des Tools verstehen.
Skalierbarkeit: Überlegen Sie, wie gut das Tool die Datenextraktion in großem Maßstab bewältigt. Sowohl die Skalierbarkeit der Leistung als auch die Fähigkeit, sich an steigende Datenmengen oder Anforderungen anzupassen, sind von entscheidender Bedeutung.
Automatisierungsfunktionen: Prüfen Sie den Grad der verfügbaren Automatisierung. Suchen Sie nach Planungsfunktionen, automatisierter Handhabung von CAPTCHA und der Möglichkeit, Cookies und Sitzungen automatisch zu verwalten.
IP-Rotation und Proxy-Unterstützung: Das Tool sollte eine robuste Unterstützung für IP-Rotation und Proxy-Verwaltung bieten, um eine Blockierung zu vermeiden.
Fehlerbehandlung und -behebung: Untersuchen Sie, wie das Tool mit Fehlern umgeht, z. B. unterbrochenen Verbindungen oder unerwarteten Site-Änderungen.
Integration mit anderen Systemen: Stellen Sie fest, ob sich das Tool nahtlos in andere Systeme und Plattformen integrieren lässt, z. B. Datenbanken, Cloud-Dienste oder Datenanalysetools. Auch die Kompatibilität mit APIs kann ein wesentlicher Vorteil sein.
Datenbereinigung und -verarbeitung: Suchen Sie nach integrierten oder einfach zu integrierenden Funktionen zur Datenbereinigung und -verarbeitung, um den Arbeitsablauf von Rohdaten zu nutzbaren Informationen zu optimieren.
Datenmanagement nach dem Scraping
Nach dem Scraping ist die Datenverwaltung ebenso wichtig wie die Extraktion. Für die Integration in Geschäftssysteme ist die Bereitstellung in verwendbaren Formaten wie CSV oder JSON erforderlich. Bei ScraperAPI haben wir dedizierte Endpunkte für beliebte Websites wie Amazon, Walmart und Google entwickelt, um Roh-HTML in gebrauchsfertige Datenpunkte umzuwandeln.
Der Speicher muss skalierbar und sicher sein und große Datensätze problemlos aufnehmen können. Die Reinigung ist unerlässlich, um Fehler und irrelevante Inhalte zu entfernen und die Genauigkeit sicherzustellen.
Verwandt: Datenbereinigung 101 für Web Scraping.
Schließlich ist die Integration in bestehende Systeme der Schlüssel für umsetzbare Erkenntnisse und die Ausrichtung von Datenformaten auf die Anforderungen von Analysetools oder CRM-Systemen. Durch effizientes Management werden Rohdaten zu einem wertvollen Gut, das Geschäftsstrategien unterstützen kann.
Abschließende Gedanken: Was ist das beste Web-Scraping-Tool?
Das offene Web ist bei weitem der bedeutendste globale Speicher für menschliches Wissen, und es gibt fast keine Informationen, die Sie nicht durch die Extraktion von Webdaten finden können. Es stehen viele Tools zur Verfügung, weil Web Scraping von Menschen mit unterschiedlichen technischen Fähigkeiten und Know-how durchgeführt wird. Es gibt Web-Data-Scraping-Tools, die jedem dienen – von Leuten, die keinen Code schreiben wollen, bis hin zu erfahrenen Entwicklern, die nur nach der besten Open-Source-Lösung in ihrer Sprache suchen.
Es gibt nicht das beste Web-Scraping-Tool – alles hängt von Ihren Bedürfnissen ab. Wir hoffen, dass Ihnen diese Liste von Scraping-Tools dabei geholfen hat, die besten Webdaten-Scraping-Tools und -Dienste für Ihre spezifischen Projekte oder Unternehmen zu finden.
Viele der oben genannten Scraping-Tools bieten kostenlose oder kostengünstige Testversionen an, sodass Sie sicherstellen können, dass sie für Ihren geschäftlichen Anwendungsfall funktionieren. Einige von ihnen werden zuverlässiger und effektiver sein als andere. Wenn Sie nach einem Tool suchen, das Datenanfragen in großem Umfang und zu einem guten Preis bearbeiten kann, wenden Sie sich an einen Vertriebsmitarbeiter, um sicherzustellen, dass er liefern kann – bevor Sie Verträge unterzeichnen.
Mein Name ist Kadek und ich bin ein Student aus Indonesien und studiere derzeit Informatik in Deutschland.
Dieser Blog dient als Plattform, auf der ich mein Wissen zu Themen wie Web Scraping, Screen Scraping, Web Data Mining, Web Harvesting, Web Data Extraction und Web Data Parsing teilen kann.