
Bezahlte Werbung (PPC) ist ein wettbewerbsintensiver Bereich, der kluge Taktiken erfordert, um erfolgreich zu sein. Da dieser Werbekanal ausgereifter wird und die Werbekosten weiterhin erheblich steigen, konzentrieren wir uns immer stärker auf Daten.
Das Scrapen von Werbedaten kann Marketingfachleuten helfen, ihre Kunden zu verstehen und zu verstehen, wie sie mit ihren Diensten interagieren. Es kann ihnen auch helfen, die Strategien der Wettbewerber zu verstehen und fehlende Lücken zu finden.
In diesem Artikel beleuchten wir, dass Web Scraping ein skalierbarer Ansatz für die PPC-Recherche, Prospektion und allgemeine Trendanalyse ist. Wir zeigen Ihnen, wie Sie einen Google Ads-Daten-Scraper erstellen, damit Sie sicher online konkurrieren können – ohne Ihr Team (oder Ihren Geldbeutel) zu belasten.
Warum Google Ads-Daten extrahieren?
Bei bezahlter Werbung ist es eine gute Möglichkeit, Ihre Strategie zu beeinflussen, wenn Sie wissen, wo und wie Ihre Konkurrenz in den Google-Suchergebnissen erscheint. Wenn Sie zunächst einen Web Scraper verwenden, können Sie Google Ads-Daten aus Millionen von Suchanfragen in nur wenigen Stunden extrahieren – was manuell unmöglich wäre.
Anschließend können Sie diese gesammelten Google Ads-Daten verwenden, um Ihre PPC-Strategien zu verbessern, wie unten aufgeführt.
Verstehen Sie die Marketingpositionierung Ihrer Konkurrenten anhand von Anzeigentiteln und -beschreibungen
Google Ads sind im Wesentlichen Textwerbung. Sie verlassen sich auf ihre Kopie, um Benutzer zum Klicken auf den Link zu verleiten. Mit anderen Worten: Ihre Konkurrenten legen großen Wert auf die Formulierung in ihren Titeln und Anzeigenbeschreibungen.
Wenn Sie beispielsweise nach Projektmanagement-Software suchen, finden Sie die folgende ClickUp-Anzeige:
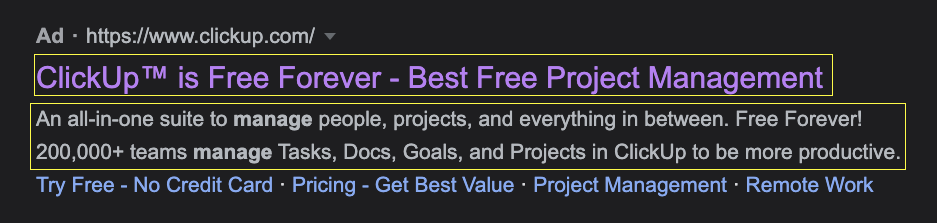
Allein beim Lesen der Kopie können Sie sehen, dass viel Wert auf ihr kostenloses Angebot gelegt wird – sogar die Verwendung von Site-Links, um auf „keine Kreditkarte“ aufzubauen, was uns einen Hinweis auf ihre Werbebotschaft gibt.
Durch die Skalierung dieses Datenextraktionsprozesses auf alle zugehörigen Schlüsselwörter können Sie nun eine vollständige Datenbank mit Titeln und Beschreibungen der Anzeigen Ihrer Mitbewerber für jedes relevante Schlüsselwort erstellen. Erstellen Sie damit eine übersichtliche Karte, die Ihnen Folgendes ermöglicht:
- Differenzieren Sie ihre Angebote und Lösungen von der Konkurrenz, indem Sie durch den Text ihre einzigartige Marke und ihren USP zeigen.
- Verbessern Sie die Angebote der Konkurrenz, um die Klicks potenzieller Kunden zu gewinnen
- Identifizieren Sie relevante Keywords mit schwachen Anzeigentexten, die Sie überzeugen können
Verschaffen Sie sich einen Überblick über die PPC-Kosten Ihrer Mitbewerber, basierend auf der Häufigkeit, mit der sie auf den SERPs erscheinen
Wenn Sie die Werbeausgaben Ihrer Konkurrenten (auch nur annähernd) kennen, können Sie einen klaren Arbeitsplan planen und präsentieren, der Wettbewerb und Budget berücksichtigt. Wenn Sie wissen, wie viel Ihre Konkurrenten in ihre PPC-Kampagnen investieren, können Sie:
- Prognostizieren Sie, wie viel Ihr Unternehmen investieren müsste, um in den SERPs zu konkurrieren, und helfen Sie Ihnen, Ihre Strategie Ihren Stakeholdern besser zu verkaufen
- Wenn wir die Anzeigenposition zum Mix hinzufügen, können Sie herausfinden, bei welchen Keywords Ihr Konkurrent den Rest überbietet, und anhand der durchschnittlichen CPC-Kosten Orte finden, an denen es kosteneffizienter wäre, zu konkurrieren
- Wenn Sie eine Agentur betreiben, können Sie Anzeigendaten nutzen, um das Werbebudget Ihrer Kunden zu skalieren und konkrete Gründe für das von Ihnen vorgeschlagene Budget aufzuzeigen
- Kategorisieren Sie die Werbeinvestitionen Ihrer Konkurrenten nach Standort (z. B. Land), Schlüsselwort und Suchabsicht sowie der Phase der Käuferreise – um nur einige Kategorien zu nennen
Um noch weiter zu gehen, können Sie Ihren Web Scraper so einstellen, dass er die SERPs regelmäßig durchsucht, um diese Informationen zu aktualisieren und Strategieänderungen zu erkennen oder Trends von verschiedenen Wettbewerbern zu generieren.
Identifizieren und analysieren Sie die Landingpages Ihrer Konkurrenten, indem Sie deren Anzeigenlinks folgen
Landingpages sind der Verkäufer hinter der Werbung, und Sie können viel über Ihre Konkurrenz erfahren, indem Sie den Text, die Struktur und das Angebot ihrer Landingpages analysieren.
Sie können einen Web-Scraper erstellen, der Anzeigeninformationen extrahiert und dann jedem mit der Anzeige verknüpften Link folgt, um die Überschrift, den Inhalt, die Meta-Beschreibung, den Meta-Titel, die Bilder, Videos usw. der Zielseite zu scannen und eine Vogelperspektive der Anzeige zu erstellen gesamte PPC-Kampagne, die sie implementieren. Im Gegenzug können Sie Lücken in ihrem Marketing finden, Möglichkeiten anbieten, Content-Ideen und Funnel-Ideen für den Start Ihrer Kampagne entwickeln.
Finden Sie heraus, wer Ihre Hauptkonkurrenten für bestimmte Keywords sind
Nicht nur Ihre bekannten Konkurrenten investieren in PPC und Google Ads. Durch das Scrapen von Anzeigendaten in großem Maßstab können Sie schnell Unternehmen identifizieren, die um dieselben Keywords konkurrieren, nach denen Sie suchen. Dies ist besonders nützlich, wenn Ihr Unternehmen in einen neuen geografischen Markt eintreten möchte.
Durch die Erstellung eines Google Ads-Scrapers können Sie eine riesige Menge an Anzeigendaten sammeln, um große lokale Player und das Ausmaß der Konkurrenz zu identifizieren, mit der Sie konfrontiert sind, um Marktanteile zu gewinnen.
So extrahieren Sie mit Scrapy Google Ads-Daten aus Suchergebnisseiten
Es gibt viele Tools zum Scrapen von Google, die beim Scrapen einiger Suchanfragen nützlich sein können. Wenn Sie jedoch Millionen von Scraping-Anfragen senden möchten, benötigen Sie eine fortschrittlichere Lösung wie ScraperAPI.
Unsere API übernimmt die ganze schwere Arbeit der IP-Rotation, der Auswahl der richtigen Header und der Änderung der Geolokalisierung Ihrer Anfragen – so können Sie Anzeigendaten von überall aus abrufen. Darüber hinaus verfügt es über einen automatischen Parser, der speziell für Google entwickelt wurde, sodass Sie sich keine Gedanken über Selektoren oder zukünftige Änderungen an der Google-Plattform machen müssen.
Für dieses Projekt verwenden wir ScraperAPI, um diese Komplexitäten zu bewältigen, und Scrapy, um das Skript zu erstellen.
Notiz: Wenn Sie Scrapy noch nie verwendet haben, schauen Sie sich unseren Scrapy-Einsteigerleitfaden an, der alle Grundlagen behandelt.
1. Einrichten unseres Google Ads-Webextraktionsprojekts
Um loszulegen, müssen Sie eine virtuelle Umgebung erstellen, um Scrapy zu installieren. Öffnen Sie Ihr Terminal, navigieren Sie zum Desktop (oder dorthin, wo Sie das Projekt erstellen möchten) und verwenden Sie den folgenden Befehl:
python -m venv g-ad-tutorial
Sie werden feststellen, dass ein neuer Ordner erstellt wurde. Dies ist Ihre virtuelle Umgebung; Um es zu aktivieren – auf dem Mac – verwenden Sie den folgenden Befehl:
source g-ad-tutorial/bin/activate
Wenn es aktiv ist, sollte der Name Ihres VENV wie folgt angezeigt werden:

Erstellen Sie als Nächstes ein neues Projekt in Ihrem VENV:
cd g-ad-tutorial
>pip3 install scrapy
scrapy startproject g_ad_scraper
… und öffnen Sie es mit VScode oder Ihrem bevorzugten Code-Editor. Erstellen Sie im Ordner „spiders“ Ihre Python-Datei. In unserem Fall haben wir es g_adscraper.py genannt, aber Sie können es nach Belieben benennen.
Um die Konfiguration des Projekts abzuschließen, fügen Sie den folgenden Codeausschnitt hinzu, um alle erforderlichen Abhängigkeiten zu importieren:
import scrapy
from urllib.parse import urlencode
from urllib.parse import urlparse
#ScraperAPI autoparser will return data in JSON format
import json
API_KEY='YOUR_API_KEY'
Notiz: Denken Sie daran, Ihren API-Schlüssel zur Variablen API_KEY hinzuzufügen. Hier können Sie ein kostenloses ScraperAPI-Konto erstellen.
2. Erstellen der Google-Such-URL
Google implementiert eine standardmäßige und abfragbare URL-Struktur, die wir nutzen können, wenn wir ihre Parameter verstehen. Es beginnt immer mit „http://www.google.com/search?“ und von dort aus können wir mehrere Parameter hinzufügen, um anzugeben, was wir wollen. Für dieses Projekt konzentrieren wir uns nur auf zwei davon:
Wenn Sie bereits Suchoperatoren verwendet haben, sind Ihnen diese bereits vertraut. Falls nicht, finden Sie hier eine vollständige Liste der Suchoperatoren, die Sie immer griffbereit haben sollten.
Lassen Sie uns nun unsere erste Funktion erstellen und unsere Zielsuchabfrage erstellen:
defcreate_google_url(query, site=''):
google_dict = {'q': query}
if site :
web = urlparse(site).netloc
google_dict('as_sitesearch') = web
return 'http://www.google.com/search?' + urlencode(google_dict)
return 'http://www.google.com/search?' + urlencode(google_dict)
Wir werden unsere Abfragen später im Skript festlegen, also weisen wir zunächst die Abfrage dem q-Parameter zu – das erleichtert Ihnen auch das Vornehmen von Änderungen.
Wichtiger Hinweis
Beim Scraping organischer Ergebnisse würden wir den Parameter „num“ verwenden, damit Google die maximale Anzahl von Ergebnissen pro Anfrage anzeigt (derzeit 100 Ergebnisse pro Seite). Allerdings werden Google-Anzeigen seitenweise präsentiert und werden nicht von der Anzahl der Ergebnisse auf der Seite, auf der sie erscheinen, beeinflusst.
Mit anderen Worten: Dieser Parameter muss nicht verwendet werden, da wir nur die Anzeigendaten benötigen. Wenn wir mehr „Anzeigenergebnisse“ für ein einzelnes Keyword wünschen, möchten wir tatsächlich mehr Anfragen senden – und nicht weniger –, um mehr Anzeigen von jeder Seite mit 10 Ergebnissen zu extrahieren.
3. Verwendung von ScraperAPI mit Scrapy
Um die ScraperAPI-Funktionen nutzen zu können, müssen wir die Anfrage über die Server von ScraperAPI senden. Dazu müssen wir Payload und URL-Code verwenden, um die Struktur zu erstellen, und sie dann in Verbindung mit der Google-Abfrage verwenden, die wir gerade erstellt haben.
Fügen wir die folgende Logik vor unserer Funktion create_google_url() hinzu:
def get_url ( url ):
payload = { 'api_key' : API_KEY , 'url' : url , 'autoparse' : 'true' , 'country_code' : 'us' }
proxy_url = 'http://api.scraperapi.com/?' + urlencode ( payload )
return proxy_url
Innerhalb der Nutzlast können wir die verschiedenen Komponenten für ScraperAPI festlegen:
- Der erste ist natürlich unser API-Schlüssel, den wir oben bereits festgelegt haben
- Bei der URL handelt es sich um die Ziel-URL, die ScraperAPI analysieren soll. Diese URL generieren wir mithilfe der Funktion „create_google_url()“.
- Wir setzen die automatische Analyse auf „true“, damit ScraperAPI weiß, dass es uns die JSON-Daten senden muss
- Abschließend geben wir an, dass wir alle Anfragen von US-IP-Adressen senden möchten
Und das war's, wir sind bereit, unsere Spinne zu schreiben!
4. Erstellen einer benutzerdefinierten Spinne
Um unser Skript auszuführen, müssen wir einen Spider (auch als Klasse bezeichnet) scrapen. In Scrapy können wir in einem einzigen Projekt so viele Spider erstellen, wie wir möchten, was die Verwaltung großer Projekte erleichtert, die das Scrapen mehrerer Websites erfordern.
Wir müssen den Endpunkt von ScraperAPI zulassen, da unsere Anfrage an den Server geht und ScraperAPI die Antwort von der Zielabfrage abruft.
class GoogleAdSpider(scrapy.Spider):
name = 'adsy'
allowed_domains = ('api.scraperapi.com')
custom_settings = {'LOG_LEVEL': 'INFO',
'CONCURRENT_REQUESTS_PER_DOMAIN': 10,
'RETRY_TIMES': 5}
Wir konfigurieren auch einige in Scrapy integrierte benutzerdefinierte Einstellungen. Am wichtigsten ist, dass wir unsere gleichzeitigen Anfragen und die maximale Anzahl von Versuchen konfigurieren.
Wenn Sie mehr über diese benutzerdefinierten Einstellungen erfahren möchten, hat Scrapy sie sehr gut dokumentiert.
5. Senden der HTTP-Anfragen
Scrapy macht es super einfach, unsere Anfragen mit der Methode scrapy.Request() zu senden, aber um die Anfragen zu versenden, müssen wir zuerst die URL festlegen und dafür benötigen wir eine Reihe von Abfragen.
In diesem Schritt muss Ihr Team entscheiden, welche Schlüsselwörter für Ihr Unternehmen wichtig sind. Dies wird normalerweise von Ihrem PPC-Team, Marketingmanager oder SEO-Team durchgeführt.
Nehmen wir zum Spaß an, wir sind ein Unternehmen für Projektmanagement-Software und möchten sehen, welche Anzeigen bei diesen zehn Keywords geschaltet werden:
- Projektmanagement-Software
- Projektmanagement-App
- beste Projektmanagement-Software
- Aufgabenverwaltungssoftware
- Projektmanagement-Tools
- Vergleich von Projektmanagement-Software
- Projektplanung und -management
- agile Projektmanagement-Software
- Projekt-Tracker
- Projektmanagement für Softwareentwicklung
Wir können SEO-Tools verwenden, um diese Begriffe basierend auf Umfang und Schwierigkeitsgrad zu ermitteln, oder Google mit einem Seed-Keyword durchsuchen und dann die Links zu allen verwandten Begriffen extrahieren und zu ihnen navigieren.
Wenn Sie diesen Weg gehen möchten, haben wir eine Anleitung zum Scrapen organischer Google-Ergebnisse mit Scrapy erstellt, die Sie sich ansehen können.
Beginnen wir nun mit der Erstellung unserer Funktion mithilfe dieser Abfragen:
def start_requests(self):
queries = (
'project+management+software',
'best+project+management+software',
'project+management+tools',
'project+planning+management',
'project+tracker',
'project+management+app',
'task+management+software',
'comparing+project+management+software',
'agile+project+management+software'
)
Beachten Sie, dass wir alle Leerzeichen durch ein Pluszeichen (+) ersetzen. Dies ist Teil der Standardstruktur von Google, also achten Sie darauf.
Was kommt also als nächstes? Wenn wir die Suchanfragen haben, können wir jetzt unsere Google-Suchanfrage erstellen. Wie Sie sich vorstellen können, möchten wir für jede Abfrage eine andere URL erstellen. Dazu können wir die Liste durchlaufen und jede einzelne an unsere Funktion create_google_url() übergeben:
for query in queries:
url = create_google_url(query)
Und innerhalb derselben Schleife übergeben wir die neue URL an die Funktion get_url(), übergeben sie also als Parameter und erstellen eine vollständige ScraperAPI-Methode.
yield scrapy.Request(get_url(url), callback=self.parse)
6. Extrahieren von Google-Anzeigendaten aus dem ScraperAPI Auto Parser
Sobald ScraperAPI die Anfragen an Google sendet, werden JSON-Daten zurückgegeben. In diesem JSON können wir alle wichtigen Elemente der Suchergebnisseite finden.
Hier ist ein vollständiges Beispiel der Antwort des automatischen Parsers von Google. Um es prägnant zu halten, konzentrieren wir uns auf die Anzeigendaten:
"ads": (
{
"position": 1,
"block_position": "top",
"title": "7 Best VPN Services for 2019 | Unlimited Worldwide Access",
"link": "https://www.vpnmentor.com/greatvpn/",
"displayed_link": "www.vpnmentor.com/Best-VPN/For-2019",
"tracking_link": "https://www.googleadservices.com/pagead/aclk?sa=L&ai=DChcSEwjphbjWlprlAhUHyN4KHR9YC10YABAAGgJ3Yg&ohost=www.google.ca&cid=CAASE-Roa2AtpPVJRsK0-RiAG_RCb3U&sig=AOD64_0dARmaWACDb7wQ5rCwGfAERVWsdg&q=&ved=2ahUKEwj9gLPWlprlAhUztHEKHdnCBBwQ0Qx6BAgSEAE&adurl=",
"description": "Our Best VPN for Streaming Online, Find Your Ideal VPN and Stream Anywhere",
"sitelinks": ()
},
{
"position": 2,
"block_position": "top",
"title": "Top 10 Best VPN Egypt | Super Fast VPNs for 2019",
"link": "https://www.top10vpn.com/top10/free-trials/",
"displayed_link": "www.top10vpn.com/Best-VPN/Egypt",
"tracking_link": "https://www.googleadservices.com/pagead/aclk?sa=L&ai=DChcSEwjphbjWlprlAhUHyN4KHR9YC10YABABGgJ3Yg&ohost=www.google.ca&cid=CAASE-Roa2AtpPVJRsK0-RiAG_RCb3U&sig=AOD64_3hbcS-4qdyR_QK0mSCy2UJb61xiw&q=&ved=2ahUKEwj9gLPWlprlAhUztHEKHdnCBBwQ0Qx6BAgTEAE&adurl=",
"description": "Enjoy Unrestricted Access to the Internet. Compare Now & Find the Perfect VPN. Stay Safe & Private Online with a VPN. Access Your Websites & Apps from Anywhere. 24/7 Support. Free Trials. Coupons. Instant Setup. Strong Encryption. Fast Speeds. Beat Censorship.",
"sitelinks": ()
}
)
Alle Daten befinden sich im Anzeigenobjekt. Wenn wir also alle Elemente im Objekt durchlaufen, können wir alle benötigten Elemente auswählen.
Lassen Sie uns den Titel, die Beschreibung, den angezeigten_Link und den Link abrufen. Damit es sinnvoller ist, erhalten wir außerdem den query_desplayed-Wert aus dem search_information-Objekt.
"search_information": {
"total_results": 338000000,
"time_taken_displayed": 0.47,
"query_displayed": "vpn"
}
Auf diese Weise behalten wir den Überblick, aus welcher Abfrage jede Anzeige in der Liste stammt.
def parse(self, response):
all_data = json.loads(response.text)
keyword = all_data('search_information')('query_displayed')
Nachdem wir die JSON-Daten in die Variable all_data geladen haben, können wir damit durch die Antwort navigieren und das Element query_displayed abrufen. Das Gleiche können wir für die restlichen Anzeigendaten innerhalb einer Schleife tun:
for ads in all_data('ads'):
title = ads('title')
description = ads('description')
displayed_link = ads('displayed_link')
link = ads('link')
Mit anderen Worten: Wir weisen jedes Element im JSON-Objekt „ads“ einer Variablen „ads“ zu und wählen dann jedes Element aus, um seinen Wert zu extrahieren.
Zum Schluss organisieren wir jeden Satz von Attributen in einem Anzeigenobjekt und liefern es – immer innerhalb der Schleife:
ad = {
'keyword': keyword,'title': title, 'description': description, 'Displayed Link': displayed_link, 'Link': link
}
yield ad
Jetzt haben wir für jede Iteration der Schleife ein Anzeigenelement, in dem alle Daten organisiert gespeichert sind.
7. Führen Sie Spider aus und exportieren Sie die Daten in eine JSON-Datei
Wenn Sie uns bisher gefolgt sind, sehen Sie hier, wie Ihr Python-Skript aussehen sollte:
import scrapy
from urllib.parse import urlencode
from urllib.parse import urlparse
import json
API_KEY = 'your_api_key'
#constructing the ScraperAPI method
def get_url(url):
payload = {'api_key': API_KEY, 'url': url, 'autoparse': 'true', 'country_code': 'us'}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
#building the Google search query
def create_google_url(query, site=''):
google_dict = {'q': query, 'num': 10, }
if site:
web = urlparse(site).netloc
google_dict('as_sitesearch') = web
return 'http://www.google.com/search?' + urlencode(google_dict)
return 'http://www.google.com/search?' + urlencode(google_dict)
class GoogleAdSpider(scrapy.Spider):
name = 'adsy'
allowed_domains = ('api.scraperapi.com')
custom_settings = {'ROBOTSTXT_OBEY': False, 'LOG_LEVEL': 'INFO',
'CONCURRENT_REQUESTS_PER_DOMAIN': 10,
'RETRY_TIMES': 5}
#sending the requests
def start_requests(self):
queries = (
'project+management+sotware',
'best+project+management+software',
'project+management+tools',
'project+planning+&+management',
'project+tracker',
'project+management+app',
'task+management+software',
'comparing+project+management+software',
'agile+project+management+software'
)
for query in queries:
#constructing the Google search query
url = create_google_url(query)
#adding the url to ScraperAPI endpoint
yield scrapy.Request(get_url(url), callback=self.parse)
def parse(self, response):
all_data = json.loads(response.text)
#grabbing the keyword for organization
keyword = all_data('search_information')('query_displayed')
#lopping through each item inside the ads object
for ads in all_data('ads'):
title = ads('title')
description = ads('description')
displayed_link = ads('displayed_link')
link = ads('link')
ad = {
'keyword': keyword,'title': title, 'description': description, 'Displayed Link': displayed_link, 'Link': link
}
yield ad
Erinnern: Damit dies funktioniert, müssen Sie Ihren API-Schlüssel hinzufügen.
Um Ihren Spider auszuführen und alle Daten in eine JSON-Datei zu exportieren, verwenden Sie den Befehl…
scrapy runspider g_adscraper.py -o ad_data.json
…und voilà! Wir scannen einfach 48 Anzeigen in 34 Sekunden und fügen alles einer JSON-Datei hinzu.
Wenn Sie es noch nicht ausgeführt haben, zeigen wir Ihnen einige Beispiele aus der Datei, die Sie erstellen möchten:
{
"keyword": "comparing+project+management+software",
"title": "10 Best Project Management - Side-by-Side Comparison (2022)",
"description": "Compare the Best Project Management Software. Plan, Track, Organize, and Manage Your Time. Powerful, Flexible Project Management for Any Team. Task Management & Custom...",
"Displayed Link": "https://www.consumervoice.org/top-software/project-manager",
"Link": "https://www.consumervoice.org/top-project-management-software"
},
{
"keyword": "project+management+sotware",
"title": "Project Management Software - Plan, Track, Collaborate",
"description": "Plan projects, track progress, and collaborate with your team. Sign up for free!",
"Displayed Link": "https://www.zoho.com/",
"Link": "https://www.zoho.com/projects/"
},
{
"keyword": "task+management+software",
"title": "10 Best Task Management Tools - 10 Best Task Management App",
"description": "The Comfort Of a Simple Task Management Software Is Priceless. Apply Today & Save! Team Tasks Management Made Oh-So Easy! Get Your Work Going with These Great...",
"Displayed Link": "https://www.top10.com/task_management/special_offer",
"Link": "https://www.top10.com/project-management/task-manager-comparison"
},
Notiz: Wenn Sie das Schlüsselwortelement sauberer machen möchten, können Sie das verwenden .replace() Methode wie folgt:
keyword = all_data('search_information')('query_displayed').replace("+", " ")
Ersetzen Sie effektiv das Pluszeichen (+) durch ein Leerzeichen.
{
"keyword": "best project management software",
"title": "Project Management Software - Plan, Track, Execute, Report",
"description": "Plan projects, track progress, and collaborate with your team. Sign up for free! Get work done on time, all the time. Start with 2 projects free today! Simplify complex tasks.",
"Displayed Link": "https://www.zoho.com/projects",
"Link": "https://www.zoho.com/projects/"
}
Konzentrieren Sie sich darauf, die Anzeigen auf der ersten Google-Seite zu entfernen
Auf jeder Seite in der SERPs-Reihe einer Abfrage werden unterschiedliche Anzeigen geschaltet. Daher ist es möglicherweise eine gute Idee, diesen Links für jede Abfrage zu folgen und alle Daten zu extrahieren, die Sie können.
Auch wenn dies einen gewissen Wert haben könnte, ist die Realität so, dass nur ein kleiner Prozentsatz des Traffics auf Seite 2 landet und fast kein Klick auf Seite 3. Denken Sie nur an das letzte Mal, als Sie auf Seite 2 geklickt haben.
ScraperAPI stellt Ihnen den folgenden Link innerhalb des Objekts ('pagination')('nextPageUrl') zur Verfügung. Dies wird jedoch eher zum Scrapen organischer Suchergebnisse, verwandter Suchen und auch von Personen-Fragefeldern empfohlen.
Wir empfehlen, Seite 1 für jede Keyword-Variation für Google Ads-Daten zu durchsuchen.
Skalieren Sie Ihre Google Web Scraping-Projekte
Das hast du bisher großartig gemacht! Wir hoffen, dass Sie aus diesem Google Ads-Web-Scraping-Tutorial etwas gelernt haben, und sind gespannt, was Sie damit erreichen.
Wenn Sie nicht wissen, wie es weitergehen soll, können Sie dieses Projekt skalieren, indem Sie eine längere Liste mit Schlüsselwörtern erstellen. Wir empfehlen die Verwendung eines Tools wie Answer the Public, um eine Liste relevanter Schlüsselwörter zu erstellen und Ihr Skript die Abfragen von dort lesen zu lassen.
Zur ständigen Überwachung können Sie auch festlegen, dass Ihr Google Ads-Scraper jedes Mal, wenn Sie die Tabelle mit neuen Schlüsselwörtern aktualisieren, eine neue Anfrage dafür sendet.
Wenn Sie in PPC investieren möchten, aber in verschiedenen Sprachen, können Sie auch einen neuen Spider erstellen und den Parameter „country_code“ in der Nutzlast ändern. Dies ist beispielsweise nützlich, wenn Sie Anzeigen in verschiedenen Ländern schalten möchten, die dieselbe Sprache sprechen (z. B. Großbritannien, USA, Kanada usw.).
Solange Sie offen für die Möglichkeiten bleiben, werden Sie immer mehr Möglichkeiten finden, Daten schneller zu sammeln und sie für die Erstellung von ROI-positiven Kampagnen zu nutzen.
Wenn Sie mehr über Marketing und Web Scraping erfahren möchten, haben wir alle Möglichkeiten aufgeschlüsselt, wie Web Scraping Ihnen dabei helfen kann, bessere Marketingentscheidungen zu treffen.
Sind Sie daran interessiert, ScraperAPI zur Unterstützung Ihrer Datenextraktionsanforderungen einzusetzen? Melden Sie sich noch heute an und erhalten Sie eine 7-tägige kostenlose Testversion!
Bis zum nächsten Mal, viel Spaß beim Schaben!
