
Cheerio und Puppeteer sind Bibliotheken für Node.js (eine Backend-Laufzeitumgebung für JavaScript), die zum Durchsuchen des Webs verwendet werden können. Es gibt jedoch erhebliche Unterschiede, die Sie berücksichtigen müssen, bevor Sie ein Werkzeug für Ihr Projekt auswählen.
In diesem Web-Scraping-Leitfaden vergleichen wir Cheerio und Puppeteer, damit Sie wissen, welches Sie für ein bestimmtes Web-Scraping-Projekt wählen sollten. Anschließend zeigen wir Ihnen, wie Sie mit Cheerio und Puppeteer ein Web-Scraping erstellen, einschließlich des vollständigen Codes. Fangen wir an!
Was ist Cheerio?
Cheerio ist ein Node.js-Framework, das rohe HTML- und XML-Daten analysiert und ein konsistentes DOM-Modell bereitstellt, das uns beim Durchlaufen und Bearbeiten der Ergebnisdatenstruktur hilft. Um Elemente auszuwählen, können wir CSS- und XPath-Selektoren verwenden, was die Navigation im DOM erleichtert.
Cheerio ist jedoch für seine Geschwindigkeit bekannt. Da Cheerio die Website nicht wie ein Browser rendert (es wendet kein CSS an und lädt keine externen Ressourcen), ist Cheerio leichtgewichtig und schnell. Obwohl wir es bei kleinen Projekten nicht bemerken, wird es bei großen Scraping-Aufgaben zu einer großen Zeitersparnis.
Was ist Puppenspieler?
Andererseits ist Puppeteer eigentlich ein Browser-Automatisierungstool, das das Verhalten von Benutzern nachahmen soll, um Websites und Webanwendungen zu testen. Es „bietet eine High-Level-API zur Steuerung von Headless Chrome oder Chromium über das DevTools-Protokoll.“
Beim Web-Scraping verleiht Puppeteer unserem Skript die gesamte Leistung einer Browser-Engine und ermöglicht uns das Scrapen von Seiten, die eine Javascript-Ausführung erfordern (wie SPAs), das Scrapen von unendlichem Scrollen, dynamischen Inhalten und mehr.
Bevor wir auf die Details der einzelnen Bibliotheken eingehen, finden Sie hier einen Übersichtsvergleich zwischen Cheerio und Puppeteer:
Cheerio |
Puppenspieler |
|
|
|
|
|
|
|
|
|
|
|
|
Da Sie nun einen Überblick über das Gesamtbild haben, werfen wir einen genaueren Blick auf die Angebote der einzelnen Bibliotheken und darauf, wie Sie diese nutzen können, um alternative Daten aus dem Internet zu extrahieren.
Sollten Sie Cheerio oder Puppeteer für Web Scraping verwenden?
Auch wenn Sie vielleicht bereits eine Vorstellung von den besten Szenarien haben, lassen Sie uns alle Zweifel ausräumen. Cheerio ist die beste Option zum Scrapen statischer Seiten, die keine Interaktionen wie Klicks, JS-Rendering oder das Absenden von Formularen erfordern. Wenn die Website jedoch irgendeine Form von Javascript verwendet, um neue Inhalte einzufügen, müssen Sie Puppeteer verwenden.
Der Grund für unsere Empfehlung ist, dass Puppeteer für statische Websites einfach übertrieben ist. Mit Cheerio können Sie mehr Seiten schneller und in weniger Codezeilen durchsuchen.
Allerdings gibt es mehrere Fälle, in denen die Verwendung beider Bibliotheken die beste Lösung ist. Schließlich kann Cheerio das Analysieren und Auswählen von Elementen erleichtern, während Puppeteer Ihnen Zugriff auf Inhalte hinter Skripten ermöglicht und Ihnen dabei hilft, Ereignisse wie das Herunterscrollen für unendliche Seitenumbrüche zu automatisieren.
So bauen Sie einen Scraper mit Cheerio und Puppeteer (Codebeispiel)
Um die Nachvollziehbarkeit dieses Beispiels zu erleichtern, erstellen wir mit Puppeteer und Cheerio einen Scraper, der zu https://quotes.toscrape.com/ navigiert und alle Zitate und Autoren von Seite 1 zurückbringt.

Schritt 1. Node.js, Cheerio und Puppeteer installieren
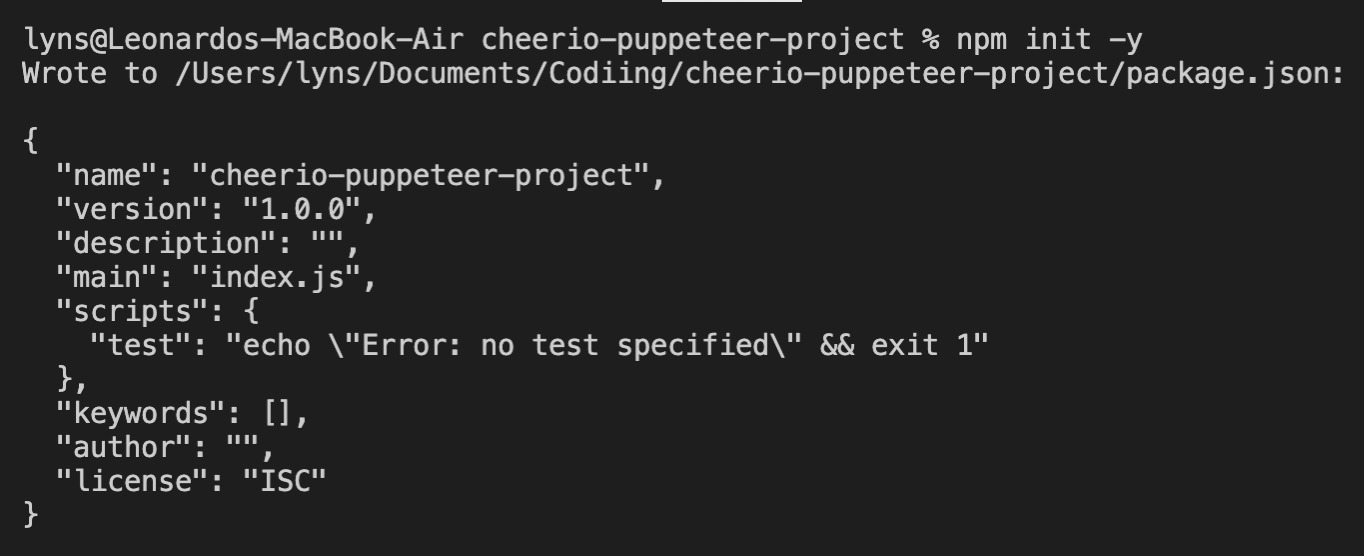
Wir laden Node.js von der offiziellen Website herunter und befolgen die Anweisungen des Installationsprogramms. Anschließend erstellen wir einen neuen Projektordner (wir nennen ihn „cheerio-puppeteer-project“) und öffnen ihn in VScode – Sie können jeden anderen Editor Ihrer Wahl verwenden. Öffnen Sie in Ihrem Projektordner ein neues Terminal und geben Sie Folgendes ein npm init -y um Ihr Projekt anzukurbeln.
Schritt 2. Öffnen Sie die Zielwebsite mit Puppeteer
Jetzt können wir unsere Abhängigkeiten mit npm install installieren cheerio puppeteer. Nach ein paar Sekunden sollten wir startklar sein. Erstellen Sie eine neue Datei mit dem Namen „index.js“ und importieren Sie oben unsere Abhängigkeiten.
const puppeteer = require('puppeteer');
const cheerio = require('cheerio');
Als Nächstes erstellen wir eine leere Liste mit dem Namen scraped_quotes um alle unsere Ergebnisse zu speichern, gefolgt von unserem async Funktion, damit wir Zugriff auf den Wait-Operator haben. Damit wir es nicht vergessen, schreiben wir eine browser.close() Methode am Ende unserer Funktion.
scraped_quotes = ();
(async () => {
await browser.close();
});
Lassen Sie uns mit Puppeteer eine neue Browserinstanz starten, eine neue Seite öffnen und zu unserer Zielwebsite navigieren.
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://quotes.toscrape.com/');
Parsen des HTML mit Cheerio
Um Zugriff auf den HTML-Code der Website zu erhalten, können wir verwenden evaluate und die rohen HTML-Daten zurückgeben – dies ist ein wichtiger Schritt, da Cheerio nur mit HTML- oder XML-Daten arbeiten kann, wir also darauf zugreifen müssen, bevor wir sie analysieren können.
const pageData = await page.evaluate(() => {
return {
html: document.documentElement.innerHTML,
};
});
Zu Testzwecken können wir verwenden console.log(pageData) um die Antwort auf unserem Terminal zu protokollieren. Da wir bereits wissen, dass es funktioniert, senden wir den rohen HTML-Code zur Analyse an Cheerio.
const $ = cheerio.load(pageData.html);
Jetzt können wir es verwenden $ um für den Rest unseres Projekts auf die analysierte Version der HTML-Datei zu verweisen.
Schritt 3. Elemente mit Cheerio auswählen
Bevor wir unseren Code tatsächlich schreiben können, müssen wir zunächst herausfinden, wie die Seite aufgebaut ist. Gehen wir in unserem Browser zur Seite selbst und sehen uns die Karten mit den Zitaten an.
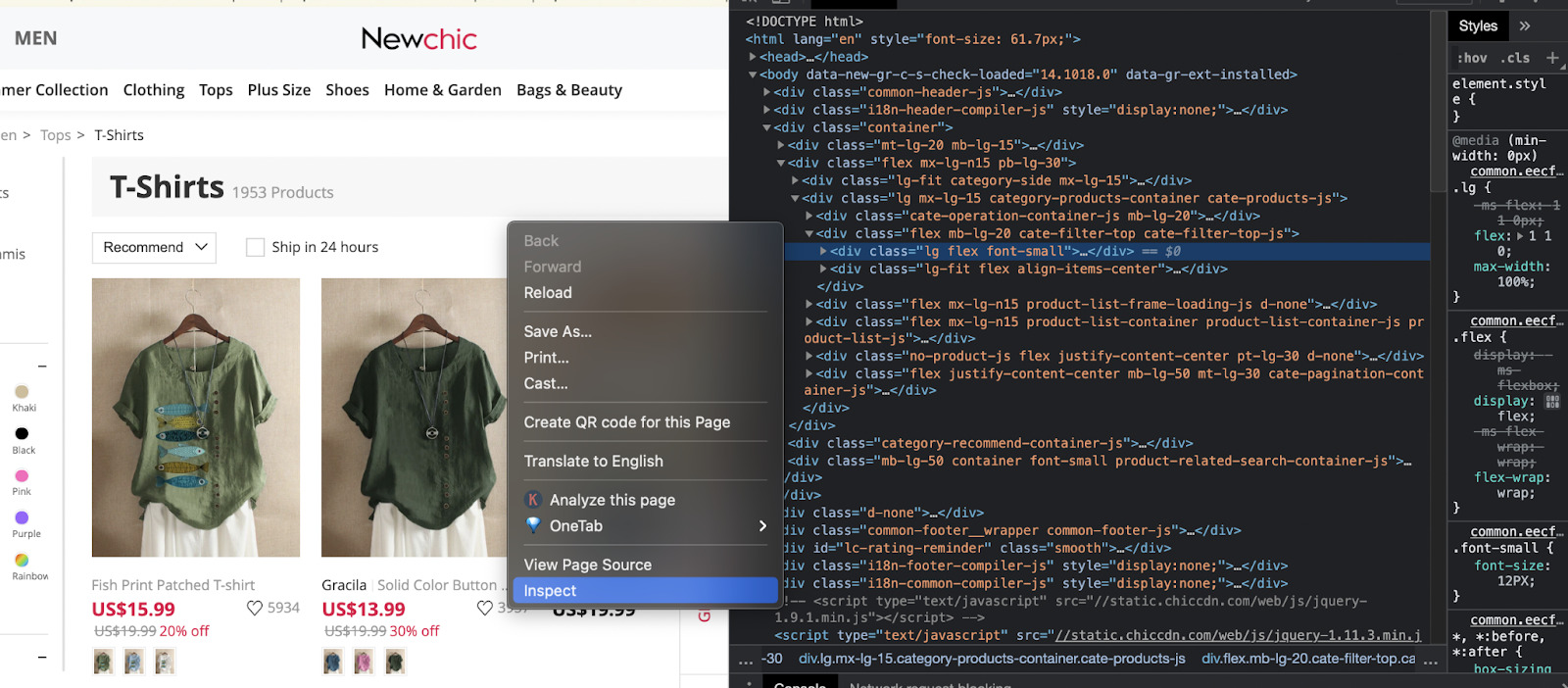
Mit dem Klassenanführungszeichen können wir sehen, dass sich die Elemente, an denen wir interessiert sind, in einem Div befinden. Wir können sie also auswählen und alle Divs durchlaufen, um den Zitattext und den Autor zu extrahieren.
Nach der Prüfung dieser Elemente sind hier unsere Ziele:
- Divs, die unsere Zielelemente enthalten:
$('div.quote') - Zitattext:
$(element).find('span.text') - Zitat Autor:
$(element).find('.author')
Lassen Sie uns dies in Code übersetzen:
let quote_cards = $('div.quote');
quote_cards.each((index, element) => {
quote = $(element).find('span.text').text();
author = $(element).find('.author').text();
});
Mit der Methode text() können wir auf den Text innerhalb des Elements zugreifen, anstatt die HTML-Zeichenfolge zurückzugeben.
Schritt 4. Übertragen der gecrackten Daten in eine formatierte Liste
Wenn wir console.log() Wenn unsere Daten zu diesem Zeitpunkt vorliegen, handelt es sich um einen unordentlichen Textblock. Stattdessen verwenden wir die leere Liste, die wir außerhalb unserer Funktion erstellt haben, und übertragen die Daten dorthin. Fügen Sie dazu direkt nach Ihrer Autorenvariable diese beiden neuen Zeilen zu Ihrem Skript hinzu:
scraped_quotes.push({
'Quote': quote,
'By': author,
})
Vollständiger Web-Scraper-Code, erstellt mit Cheerio und Puppeteer
Jetzt, da alles an Ort und Stelle ist, können wir es tun console.log(scraped_quotes) Bevor Sie den Browser schließen:
//dependencies
const puppeteer = require('puppeteer');
const cheerio = require('cheerio');
//empty list to store our data
scraped_quotes = ();
//main function for our scraper
(async () => {
//launching and opening our page
const browser = await puppeteer.launch();
const page = await browser.newPage();
//navigating to a URL
await page.goto('https://quotes.toscrape.com/');
//getting access to the raw HTML
const pageData = await page.evaluate(() => {
return {
html: document.documentElement.innerHTML,
};
});
//parsing the HTML and picking our elements
const $ = cheerio.load(pageData.html);
let quote_cards = $('div.quote');
quote_cards.each((index, element) => {
quote = $(element).find('span.text').text();
author = $(element).find('.author').text();
//pushing our data into a formatted list
scraped_quotes.push({
'Quote': quote,
'By': author,
})
});
//console logging the results
console.log(scraped_quotes);
//closing the browser
await browser.close();
})();
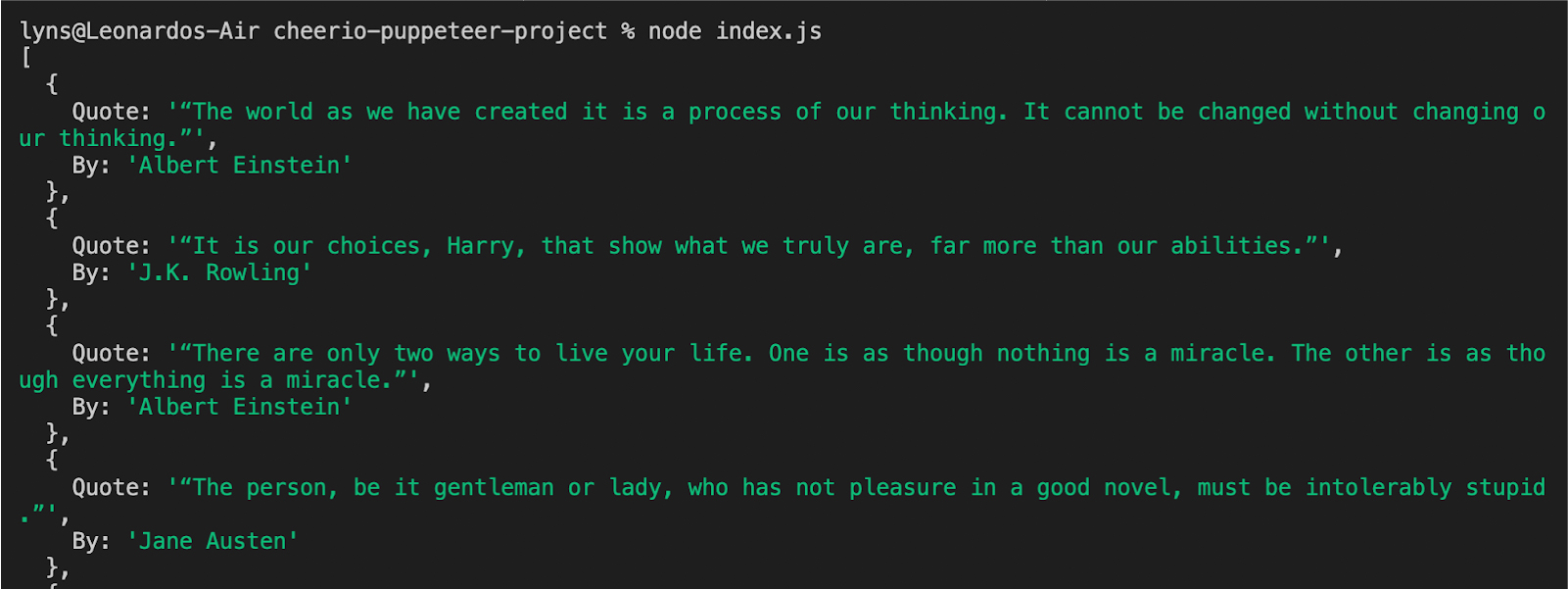
Das Ergebnis ist eine formatierte Datenliste:
Cheerio vs. Puppeteer beim Web Scraping: Beide gewinnen
Wir hoffen, Ihnen hat dieser kurze Überblick über die zwei wohl besten verfügbaren Web-Scraping-Tools für Javascript/Node.js gefallen. Obwohl Sie in den meisten Fällen Cheerio anstelle von Puppeteer verwenden möchten, bietet Puppeteer für besonders komplexe Projekte die zusätzlichen Tools, die Sie zum Erledigen Ihrer Aufgabe benötigen.
Wir haben ein ausführlicheres Cheerio- und Puppenspieler-Tutorial für Anfänger erstellt. Sie können mehr über diese beiden Bibliotheken erfahren.
Sie können ScraperAPI jedoch auch verwenden, um die Komplexität des Codes zu verringern, indem Sie unsere Javascript-Rendering-Funktionen nutzen. Durch einfaches Setzen des Parameters „render=true“ innerhalb der Anfrage rendert ScraperAPI die Seite, bevor es die rohen HTML-Daten zurücksendet, damit Cheerio sie verwenden kann.
ScraperAPI hilft Ihnen, die Entwicklungszeit zu verkürzen und zu verhindern, dass Ihr Skript durch fortschrittliche Anti-Scraping-Mechanismen wie Browser-Profiling und CAPTCHAs blockiert wird, indem es die IP-Rotation, die CAPTCHA-Verwaltung automatisiert und jahrelange statistische Analysen verwendet, um die besten Header für jede Anfrage zu ermitteln.
Sie können sich bei ScraperAPI anmelden und 5.000 kostenlose API-Credits erhalten, um Ihr Projekt anzukurbeln.
Bis zum nächsten Mal, viel Spaß beim Schaben!
Weitere Puppeteer- und beliebte Web-Scraping-Tutorials, die Sie interessieren könnten:
