
Für große Unternehmen ist es leicht, bei der Datenerfassung tief in die Tasche zu greifen. Sie verfügen über Budgets, um verschiedene Methoden zur Analyse von Datenpunkten einzusetzen und so genauere Entscheidungen zu treffen. Im Gegenzug verschaffen sie anderen einen unfairen Vorteil.
Allerdings sind Daten nicht nur großen Unternehmen vorbehalten; Es ist eine Denkweise, die sich ändern muss. Jedes kleine Unternehmen kann Web Scraping nutzen, um seine Datenerfassungsbemühungen zu skalieren und von den gleichen Vorteilen zu profitieren. (Tatsächlich kann Web Scraping Ihnen helfen, Ihre Kosten zu senken, indem es Ihre Entscheidungsfindung optimiert und sich wiederholende, zeitaufwändige Aufgaben automatisiert.)
Um Ihnen den Einstieg zu erleichtern, finden Sie hier fünf Anwendungsfälle, mit denen Sie Ihr Unternehmen ausbauen können (einschließlich Code-Snippets!), ohne Ihr Budget zu verbrennen:
1. Markenüberwachung und Online-Reputationsmanagement
Es ist wichtig zu wissen, wie Ihr Publikum über Ihre Marke, Ihr Produkt und Ihre Dienstleistungen denkt. Wenn Sie dies verstehen, können Sie das Gespräch verschieben, indem Sie Schwachstellen oder Dinge ansprechen, die nicht funktionieren.
Durch die Überwachung von Online-Gesprächen rund um Ihre Marke können Sie auch jederzeit erkennen, welche Richtung Sie einschlagen müssen (z. B. neue Produkte auf den Markt bringen oder Funktionen hinzufügen), oder sogar mögliche PR-Katastrophen verhindern, sodass Ihr Team aktiv statt nur reagieren kann.
Dazu müsste Ihr Team ständig durch soziale Medien, Websites, Foren und Aggregatoren scrollen, um die stattfindenden Konversationen zu erfassen, und wie Sie sich vorstellen können, ist es unabhängig von der Größe Ihres Teams eine unmögliche Aufgabe, diese manuell zu erledigen, ohne einen zuzuweisen Sie stecken einen großen Teil Ihres Marketing- oder PR-Budgets hinein. Stattdessen können Sie einen Web Scraper verwenden, um die Plattformen, auf denen diese Gespräche stattfinden, wie Foren und soziale Medien, zu crawlen und den Prozess zu automatisieren.
Indem Sie diese Daten auswerten, können Sie die Gespräche rund um Ihre Branche und Marke analysieren, um zu verstehen, ob die geteilte Stimmung positiv oder negativ ist, und interessante Erkenntnisse von Ihren Kunden zu gewinnen.
Beispielskript: Twitter-Daten mit Python extrahieren
Obwohl es viele Quellen gibt, die Sie durchsuchen können, finden Sie hier ein einfaches, aber leistungsstarkes Python-Skript zum Abrufen von Twitter-Daten in eine CSV-Datei:
import snscrape.modules.twitter as sntwitter
import pandas as pd
hashtag = ‘scraperapi’
limit = 10
tweets = ()
for tweet in sntwitter.TwitterHashtagScraper(hashtag).get_items():
if len(tweets) == limit:
break
else:
tweets.append((tweet.date, tweet.user.username, tweet.rawContentcontent))
df = pd.DataFrame(tweets, columns=(‘Date’, ‘User’, ‘Tweet’))
df.to_csv(‘scraped-tweets.csv’, index=False, encoding=‘utf-8’)
Mit diesem Skript können Sie Daten von jedem Twitter-Hashtag sammeln. Genauer gesagt können Sie das Datum, den Benutzernamen und den Inhalt jedes Tweets in den Hashtag-Ergebnissen erfassen und alles als CSV-Datei exportieren lassen. Für dieses Beispiel haben wir nach #scraperapi gesucht und den Grenzwert auf 10 gesetzt. Hier ist die resultierende CSV-Datei:
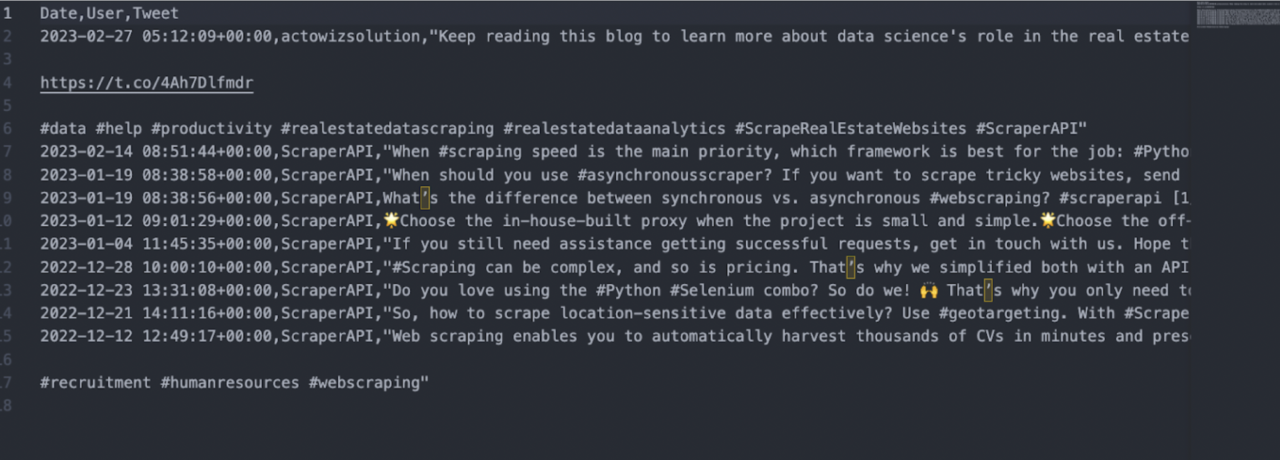
Einige Überlegungen bei der Verwendung des Skripts:
- Sie können den Hashtag, den Sie scrapen möchten, ändern, indem Sie das Wort in der Variablen >hashtag> ändern
- Fügen Sie dem Hashtag kein Pfund-Symbol hinzu, sonst funktioniert es nicht
- Sie können die Anzahl der zurückgegebenen Tweets ändern, indem Sie die Zahl in der Limit-Variable ändern
- Auf Ihrem Computer müssen Python und die Requests-Bibliothek installiert sein
Wenn Sie nicht sicher sind, wie man es einrichtet, oder lernen möchten, wie man erweiterte Abfragen und Hashtags scrapt, sehen Sie sich unser Tutorial zum Scrapen von Twitter-Daten an.
2. Preisintelligenz
Ein entscheidender Teil Ihrer Geschäftsstrategie ist die Preisgestaltung Ihrer Produkte.
Eine gute Preisstrategie stellt sicher, dass Sie den Wert Ihrer Produkte optimieren und Ihre Gewinnspannen steigern, ohne Ihren Umsatz zu beeinträchtigen oder Ihre Kunden zu verärgern. Um Ihre Preisgestaltung zu optimieren, benötigen Sie mehr als nur die Rohkosten Ihrer Abläufe. Sie müssen Marktveränderungen und die Preismodelle Ihrer Wettbewerber verstehen, damit Sie eine Strategie entwickeln können, die Wettbewerbsfähigkeit garantiert. Das Sammeln ausreichender Daten (in Bezug auf Menge und Vielfalt), um aussagekräftige Schlussfolgerungen zu ziehen, wäre jedoch für Ihr Team zu aufwändig.
Stattdessen können Sie Web Scraping verwenden, um diese Informationen automatisch von Marktplätzen und Preisseiten der Wettbewerber abzurufen, um nur einige zu nennen. Für den Anfang und wenn Sie in der E-Commerce-Nische tätig sind, empfehlen wir Ihnen, mit zwei der größten Produktdatenquellen zu beginnen:
Amazon und Google Shopping.
Indem Sie Preisdaten von diesen Plattformen abrufen, können Sie Erkenntnisse darüber gewinnen, wie viel der durchschnittliche Kunde für ähnliche Produkte zahlt, wie viel Ihre Konkurrenten verlangen und sogar über die üblichen Preise, die Wiederverkäufer festlegen. Darüber hinaus können Sie durch die regelmäßige Erfassung von Produktdaten einen historischen Datensatz erstellen, den Sie dann analysieren können, um Preistrends und -verschiebungen vor Ihren Mitbewerbern zu erkennen und sogar automatisierte Systeme einzurichten, um Ihre Preise dynamisch zu ändern.
Beispielskript: Produktdaten aus Google Shopping extrahieren
Hier ist ein gebrauchsfertiges Skript, mit dem Sie Preisinformationen von Google Shopping innerhalb einer bestimmten Suchanfrage sammeln können:
import requests
import json
products = ()
payload = {
‘api_key’: ‘YOUR_API_KEY’,
‘query’: ‘gps+tracker’
}
response = requests.get(‘https://api.scraperapi.com/structured/google/shopping’, params=payload)
product_data = response.json()
for product in product_data(“shopping_results”):
products.append({
‘Product Name’: product(“title”),
‘Price’: product(“price”),
‘URL’: product(“link”),
})
with open(‘prices.json’, ‘w’, encoding=‘utf-8’) as file:
json.dump(products, file, ensure_ascii=False, indent=4)
In diesem Beispiel haben wir die Suchanfrage „GPS-Tracker“ gescrapt und den Namen, den Preis und die URL jedes Produkts in den Suchergebnissen extrahiert. Nach der Ausführung des Skripts ist das Endergebnis eine JSON-Datei mit 60 Produkten:
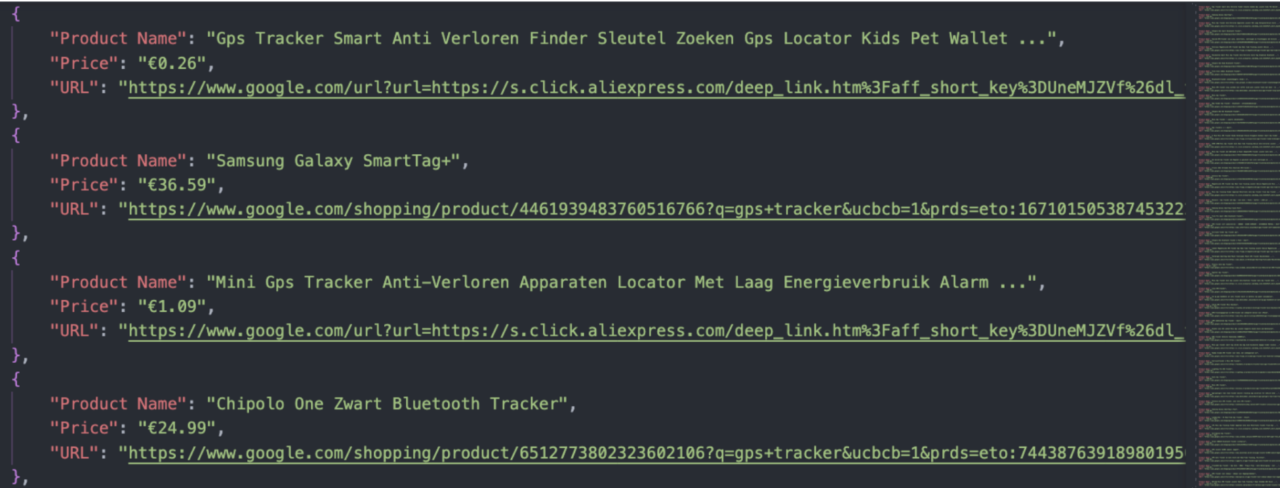
Einige Überlegungen bei der Verwendung des Skripts:
- Um den Code zu vereinfachen, verwenden wir den Goolge Shopping-Endpunkt von ScraperAPI, der die meisten technischen Komplexitäten für uns übernimmt, sodass wir uns nur auf die Abfragen konzentrieren können, aus denen wir Daten extrahieren möchten
- Sie müssen ein kostenloses ScraperAPI-Konto erstellen, um Zugriff auf Ihren API-Schlüssel zu haben. Dadurch erhalten Sie 5.000 kostenlose API-Credits, sodass Sie sich nicht auf einen kostenpflichtigen Plan festlegen müssen, um dieses Skript zu verwenden
- Fügen Sie Ihren API-Schlüssel im Parameter api_key hinzu
- Ändern Sie das Schlüsselwort, das Sie durchsuchen möchten, innerhalb des Abfrageparameters. Beachten Sie jedoch, dass Sie Leerzeichen durch ein Pluszeichen ersetzen müssen
- Dieses Skript erstellt immer eine neue Datei oder überschreibt eine vorhandene Datei mit demselben Namen. Es gibt zwei schnelle Lösungen, um dieses Verhalten zu ändern, wenn Sie möchten
- Ändern Sie den Namen „with open('(file_name).json', 'w', binding='utf-8′) as file:“, um eine neue Datei zu erstellen, oder
- Ändern Sie den Parameter „w“ in „a“, damit das Skript weiß, dass es die Daten an die gleichnamige Datei anhängen muss, „mit open('prices.json', 'a',kodierung='utf-8′) als Datei :“
Um Ihr Wissen zu vertiefen, finden Sie hier ein vollständiges Tutorial zum Scrapen von Amazon-Produktdaten (einschließlich Preisen und Bildern), dem Sie folgen können.
Weitere Informationen zum E-Commerce-Scraping finden Sie in unserem Leitfaden zum Extrahieren von Produktdaten aus Etsy und den Grundlagen zum Web-Scraping bei eBay.
3. B2B-Lead-Generierung
Leads sind das Herzstück Ihrer Geschäftsabläufe, aber ein System zu schaffen, das eine Konstante gewährleistet, ist nicht so einfach, wie andere vielleicht denken.
Für B2B-Unternehmen ist die Generierung eines ständigen Stroms neuer Interessenten, die Ihre Dienstleistungen und Produkte anbieten, so wichtig wie Luft für einen Menschen.
Ohne ordnungsgemäße Planung und moderne Werkzeuge kann dieser Prozess zu einem hohen Aufwand werden und Ihr Geschäft leicht ruinieren. Schließlich wirkt sich die Lead-Generierung direkt auf Ihre Kundenakquisekosten aus.
Sie wissen wahrscheinlich schon, wohin wir damit wollen, oder?
Mit Web Scraping können B2B-Leads zu deutlich geringeren Kosten und in größerem Umfang gesammelt werden. Die Erstellung eigener Lead-Pipelines sorgt für niedrigere CACs und ermöglicht Ihrem Vertriebsteam, das zu tun, was es am besten kann: verkaufen! Sie können Unternehmensdaten aus offenen Verzeichnissen und öffentlichen Plattformen im gesamten Web sammeln. Es geht also eher darum, klare Kriterien dafür festzulegen, wo und welche Art von Informationen Sie sammeln. Machen Sie sich keine Sorgen mehr darüber, ob Sie gute Interessenten finden oder nicht.
Einige Plattformen, die Sie zunächst in Betracht ziehen können, sind:
- Kupplung
- G2
- Google Maps
- DnB
- Glastür
Sie können aber auch nischenspezifische Plattformen nach der Art von Leads durchsuchen, die Sie suchen.
Beispielskript: Scrapen Sie Glassdoor-Unternehmensdaten
Als Beispiel sehen Sie hier ein Skript, das die bestplatzierten Unternehmen in der Bildungskategorie von Glassdoor abruft:
import requests
from bs4 import BeautifulSoup
import json
companies_data = ()
payload = {
‘api_key’: ‘YOUR_API_KEY’,
‘render’: ‘true’,
‘url’: ‘https://www.glassdoor.com/Explore/browse-companies.htm?overall_rating_low=3.5&page=1§or=10009&filterType=RATING_OVERALL’
}
response = requests.get(‘https://api.scraperapi.com’, params=payload)
soup = BeautifulSoup(response.content, ‘html.parser’)
company_cards = soup.select(‘div(data-test=”employer-card-single”)’)
for company in company_cards:
company_name = company.find(‘h2’, attrs={‘data-test’: ’employer-short-name’}).text
company_size = company.find(‘span’, attrs={‘data-test’: ’employer-size’}).text
industry = company.find(‘span’, attrs={‘data-test’: ’employer-industry’}).text
description = company.find(‘p’, class_=‘css-1sj9xzx’).text
companies_data.append({
‘Company’: company_name,
‘Size’: company_size,
‘Industry’: industry,
‘Description’: description
})
with open(‘companies.json’, ‘w’, encoding=‘utf-8’) as file:
json.dump(companies_data, file, ensure_ascii=False, indent=4)
Im Gegensatz zu unseren beiden vorherigen Beispielen erfordert Glassdoor ein individuelleres Skript. Wir haben dieses mithilfe der Python-Bibliotheken „Requests“ und „BeautifulSoup“ geschrieben, um den Namen, die Größe, die Branche und die Beschreibung jedes Unternehmens zu extrahieren. (Wir verwenden auch den Endpunkt von ScraperAPI, um das Anti-Scraping von Glassdoor zu umgehen und eine Blockierung unserer IP zu vermeiden.)
Hier ist die resultierende JSON-Datei:
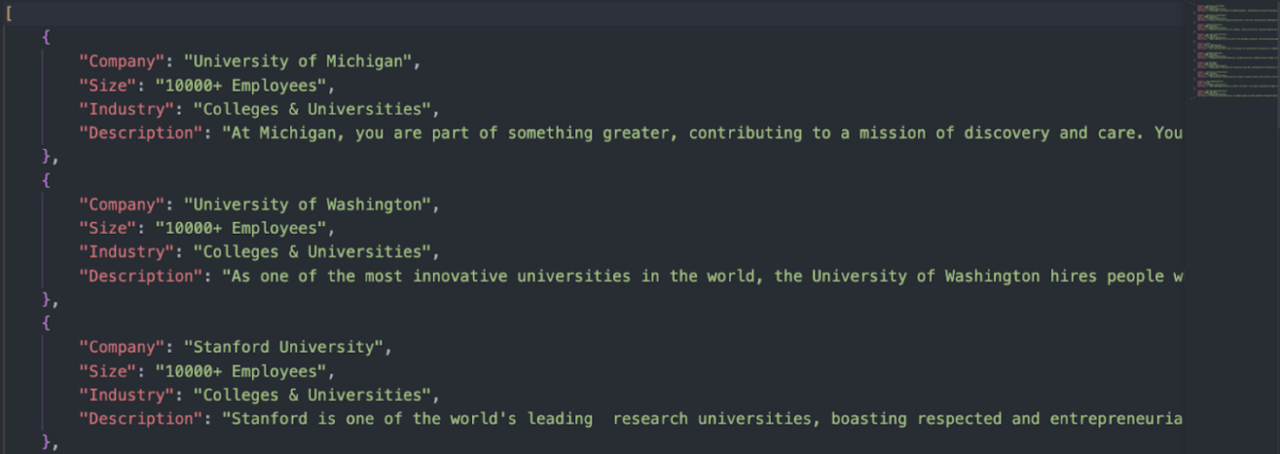
Natürlich können Sie noch weiter gehen und mehrere Kategorien und die gesamte paginierte Serie dieser Kategorie durchsuchen und in nur wenigen Minuten eine Liste mit Hunderten von Unternehmen erstellen. Um die genauen Schritte zu erfahren, die wir bei der Erstellung dieses Skripts befolgt haben, und um zu verstehen, wie Sie dieses Projekt für Ihr Unternehmen skalieren können, schauen Sie sich unser Glassdoor-Scraping-Tutorial an.
Nachdem Sie das Tutorial gelesen haben, können Sie dasselbe Skript verwenden, um Daten aus anderen Kategorien zu extrahieren und verschiedene Filteroptionen festzulegen, um Ihre Lead-Liste auf die Unternehmen einzugrenzen, an denen Sie interessiert sind.
4. Überwachen Sie die Suchanzeigen Ihrer Konkurrenten
Anzeigen gehören zu den größten Marketingausgaben. Daher ist die gezielte Auswahl der richtigen Keywords und die Optimierung des Textes Ihrer Anzeigen und Zielseiten von entscheidender Bedeutung, um die CTR und die Konversionsraten zu steigern. Wie bei jeder anderen Investition kann das Sammeln relevanter Daten zur Erstellung faktenbasierter Hypothesen Ihnen dabei helfen, sicherer zu investieren und den gesamten Prozess zu optimieren.
Bei Anzeigen ist es wichtig, die Positionierung Ihrer Konkurrenten zu verstehen, wo sie investieren, wie oft sie auf den Suchmaschinen-Ergebnisseiten (SERPs) erscheinen und welche Zielseiten die beste Leistung erbringen. Dies kann Ihrem Anzeigenteam ein klares Bild liefern, das diese Daten nutzen kann, um Ihre Kampagnen zu optimieren, Kosten zu senken und den ROI zu verbessern.
Beispielskript: Anzeigendaten aus Google-Suchergebnissen extrahieren
Dieses Mal verwenden wir den Google Search-Endpunkt von ScraperAPI, um die Anzeigen auf den SERPs unseres Ziel-Keywords zu extrahieren:
import requests
import json
all_ads = ()
payload = {
‘api_key’: ‘YOUR_API_KEY’,
‘country’: “us”,
‘query’: ‘web+hosting’
}
response = requests.get(‘https://api.scraperapi.com/structured/google/search’, params=payload)
results = response.json()
for ad in results(“ads”):
all_ads.append({
‘Title’: ad(“title”),
‘Description’: ad(“description”),
‘Landing’: ad(“link”)
})
with open(‘search_ads.json’, ‘w’, encoding=‘utf-8’) as file:
json.dump(all_ads, file, ensure_ascii=False, indent=4)
Beim Ausführen des Skripts extrahiert ScraperAPI den Titel, die Beschreibung und die URL jeder Anzeige, die es auf der Suchergebnisseite für das Zielschlüsselwort findet, und sendet die Daten an eine JSON-Datei. Sie könnten zwar weitere Seiten durchsuchen, aber es werden fast keine Klicks auf diese Anzeigen generiert. Daher ist es in Ordnung, bei den Anzeigen auf Seite eins jedes Keywords zu bleiben, an dem Sie interessiert sind.
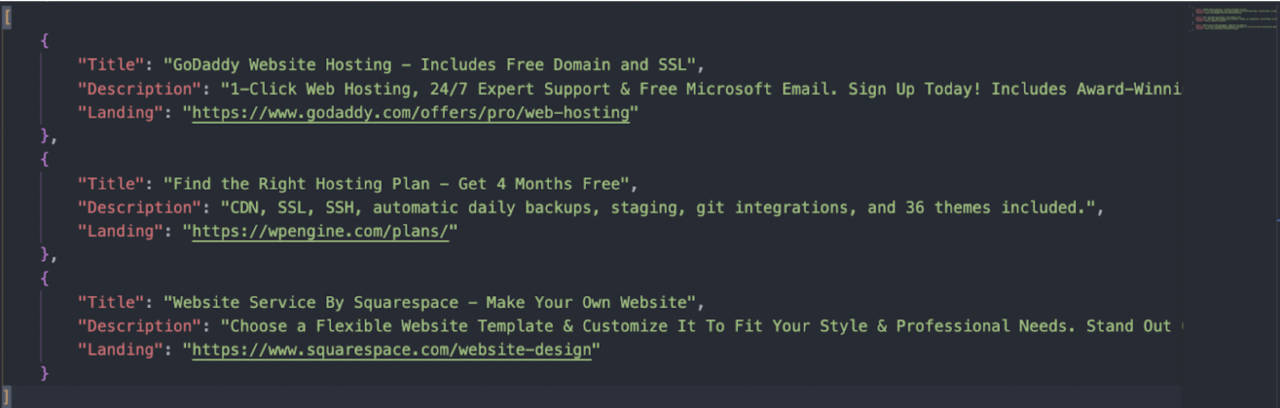
Einige Überlegungen bei der Verwendung dieses Skripts:
- Wie zuvor benötigen Sie ein kostenloses ScraperAPI-Konto und fügen die API im api_key-Parameter innerhalb der Nutzlast hinzu
- Legen Sie das Schlüsselwort, auf das Sie abzielen möchten, innerhalb des Abfrageparameters fest und ersetzen Sie die Leerzeichen durch ein Pluszeichen (+).
- Da Anzeigen standortabhängig sind, ändern Sie den Länderwert mithilfe eines dieser Ländercodes in den gewünschten Standort
- Ändern Sie den Namen der Datei oder legen Sie fest, dass sie angehängt wird ('a'), um den Verlust früherer Daten zu vermeiden
Weitere Informationen finden Sie in unserem Leitfaden zum Scraping von Mitbewerberdaten zur Verbesserung Ihrer Werbekampagnen und wie Web Scraping die Entscheidungsfindung im Marketing verbessern kann.
5. Bestands- und Finanzüberwachung
Kleine Investmentfirmen wissen, wie wichtig Daten für leistungsstarke und risikoarme Investitionen sind. Ohne genaue Daten ist es schwierig, Marktbewegungen zu verstehen und vorherzusagen. Dies führt zum Verlust großer Chancen oder, schlimmer noch, dazu, dass Verluste nicht vorhersehbar und verhindert werden.
Für KMUs im Finanzwesen kann jeder Rückschlag potenziell dazu führen, dass sie aus dem Rennen ausscheiden, wodurch die Datenerfassung für Ihren Betrieb wichtiger wird. Mit Web Scraping können Sie alternative Datenpipelines aufbauen, um so viele Daten wie möglich über die Unternehmen zu sammeln, in die Sie investieren möchten.
Zu den wichtigsten Datenpunkten, die Sie automatisch und konsistent erfassen können, gehören Produktdaten, Aktienkurse und Finanznachrichten in Echtzeit.
Beispielskript: Aktiendaten von Investing.com extrahieren
Um Ihnen den Start dieser Reise zu erleichtern, finden Sie hier ein benutzerfreundliches Skript zum Sammeln von Aktiendaten von Investing.com:
import requests
from bs4 import BeautifulSoup
import csv
from urllib.parse import urlencode
urls = (
‘https://www.investing.com/equities/nike’,
‘https://www.investing.com/equities/coca-cola-co’,
‘https://www.investing.com/equities/microsoft-corp’,
)
file = open(‘stockprices.csv’, ‘w’)
writer = csv.writer(file)
writer.writerow((‘Company’, ‘Price’, ‘Change’))
for url in urls:
params = {‘api_key’: ‘YOUR_API_KEY’, ‘render’: ‘true’, ‘url’: url}
page = requests.get(‘http://api.scraperapi.com/’, params=urlencode(params))
soup = BeautifulSoup(page.text, ‘html.parser’)
company = soup.find(‘h1’, {‘class’:‘text-2xl font-semibold instrument-header_title__gCaMF mobile:mb-2’}).text
price = soup.find(‘div’, {‘class’: ‘instrument-price_instrument-price__xfgbB flex items-end flex-wrap font-bold’}).select(‘span’)(0).text
change = soup.find(‘div’, {‘class’: ‘instrument-price_instrument-price__xfgbB flex items-end flex-wrap font-bold’}).select(‘span’)(2).text
print(‘Loading :’, url)
print(company, price, change)
writer.writerow((company.encode(‘utf-8’), price.encode(‘utf-8’), change.encode(‘utf-8’)))
file.close()
Wenn Sie das Skript ausführen, wird eine neue CSV-Datei mit dem Namen, dem Preis und der prozentualen Änderung aller Aktien erstellt, die Sie der >Liste hinzugefügt haben. In diesem Beispiel haben wir Daten für Nike, Coca-Cola und Microsoft gesammelt:

Einige Überlegungen bei der Verwendung dieses Skripts:
- Erstellen Sie vor der Ausführung ein kostenloses ScraperAPI-Konto und fügen Sie Ihren API-Schlüssel im entsprechenden Parameter hinzu
- Wenn Sie zu einer Aktienseite in Investing.com navigieren, wird eine URL wie https://www.investing.com/equities/amazon-com-inc generiert. Fügen Sie alle URLs, die Sie überwachen möchten, zur URL-Liste hinzu – es ist keine zusätzliche Konfiguration erforderlich
- So wie es ist, erstellt das Skript jedes Mal eine neue Datei. Sie können dieses Verhalten jedoch ändern, sodass eine neue Spalte in einer vorhandenen Datei erstellt wird. Auf diese Weise können Sie mit dem Aufbau eines historischen Datensatzes beginnen und nicht nur mit einmaligen Datenpunkten
Wenn Sie erfahren möchten, wie wir dieses Skript erstellt haben, sehen Sie sich unseren Leitfaden zum Aktienkurs-Scraping an. Sie können unseren Denkprozess Schritt für Schritt verfolgen.
Zusammenfassung
Anstatt dass ganze Teams Daten sammeln, bereinigen und analysieren müssen, können Sie mit Web Scraping all diese zeitaufwändigen Aufgaben automatisieren.
In diesem Artikel haben wir nur die Oberfläche des Meeres an Möglichkeiten gekratzt, die Web Scraping für Ihr Unternehmen eröffnen kann. Wenn Sie Ihren Geist offen halten, kann ein Scraper ein leistungsstarkes Werkzeug sein, um Ihre Entscheidungsfindung zu stärken, ganze Prozesse wie Datenmigration und Dateneingabe zu automatisieren, Datenquellen in eine einzige Datenbank oder ein einziges Dashboard zu integrieren und vieles mehr.
Wir hoffen, dass eines dieser fünf Skripte Ihnen den Einstieg in das Web Scraping erleichtern kann. Wenn Sie ganz neu sind, werfen Sie einen Blick auf unseren Blog. Er ist voller Projekte, von denen Sie lernen und sich inspirieren lassen können.
Bis zum nächsten Mal, viel Spaß beim Schaben!
