
XPath (XML Path Language) ist eine Abfragesprache, die speziell für die Navigation und das Extrahieren von Elementen aus XML-Dokumenten entwickelt wurde. Es bietet eine präzise Möglichkeit, bestimmte Knoten innerhalb einer XML-Struktur zu identifizieren und auszuwählen, was es zu einem wertvollen Werkzeug für die Datenanalyse und -verarbeitung macht.
Im Vergleich zu CSS-Selektoren bietet XPath eine größere Flexibilität und Funktionalität für die Datenbearbeitung und den Datenabruf. Während wir bereits zuvor die Fähigkeiten und Vorteile von XPath untersucht haben, konzentriert sich dieser Artikel auf seine Anwendung für die Textverarbeitung und -suche.
Die Textauswahl ist ein grundlegender Vorgang in XPath, da ein erheblicher Teil der Daten in XML-Dokumenten in Textform vorliegt. Durch die Beherrschung der Textauswahl können Sie die erforderlichen Daten aus XML extrahieren und je nach Anwendungs- oder Aufgabenanforderungen weiterverarbeiten.
Grundlegende Methoden zum Auswählen von Elementen nach Text
XPath bietet mehrere Kernmethoden für die Arbeit mit Text und einige, die ursprünglich nicht für diesen Zweck entwickelt wurden, aber dennoch sehr benutzerfreundlich sind. Beginnen wir damit, über die grundlegenden Methoden der Textsuche zu sprechen. Wir werden sie beispielhaft auf dieser Demoseite testen.
text(): Elemente mit exakter Textübereinstimmung auswählen
Die erste Methode ist text(), mit dem Sie Elemente anhand ihres Volltextinhalts finden können. Dies macht es zu einer präzisen Möglichkeit, Elemente basierend auf ihrem Textinhalt gezielt anzusprechen. Um beispielsweise dieses Element auszuwählen:
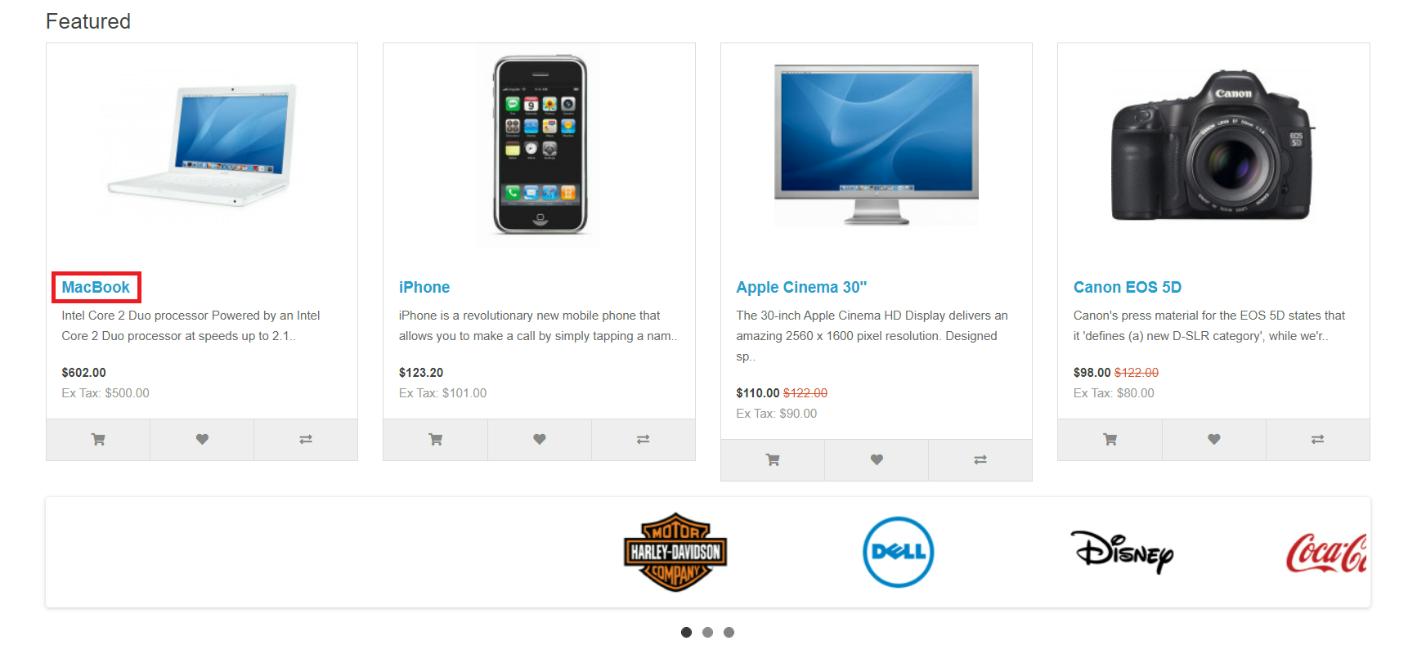
Wir können den folgenden XPath verwenden:
//*(text()='MacBook')Um es im Browser zu überprüfen, können wir die Suchfunktion des Browsers verwenden und einen Punkt (.) vor den XPath setzen oder die Konsole verwenden und ausführen $x() oder $$() Funktion, um das Element zu finden.
Lassen Sie uns das Element überprüfen und versuchen, es zu finden:
Während text() Die Methode eignet sich zum Auswählen von Elementen nach exaktem Text, ihre Verwendung kann jedoch aufgrund einiger Nachteile eingeschränkt sein:
- Der
text()Die Methode erfordert eine exakte Textübereinstimmung. Wenn das Element zusätzliche Formatierungs- oder Leerzeichen enthält, stimmt der Text möglicherweise nicht mit der genauen Suchzeichenfolge überein. - Außerdem wird die Groß-/Kleinschreibung beachtet, was bedeutet, dass der Text hinsichtlich der Groß- und Kleinschreibung genau übereinstimmen muss. Beispielsweise würden „MacBook“ und „macbook“ als unterschiedliche Texte betrachtet.
- Zuletzt die
text()Die Methode ignoriert untergeordnete Elemente und deren Textinhalt. Es darf nicht ausgewählt werden, wenn ein Element untergeordnete Elemente mit Text enthält.
Daher kann in einigen Fällen die Verwendung komplexerer Elementauswahlstrategien basierend auf anderen Elementeigenschaften oder deren Kontext erforderlich sein.
enthält(): Elemente auswählen, die einen Teilstring enthalten
Mit dieser Methode können Sie im Text oder Attributwert eines Elements nach einer Teilzeichenfolge suchen. Im Gegensatz zur vorherigen Methode müssen Sie nicht den gesamten Text des Elements kennen, sondern nur einen Teil davon. Diese Methode ist besonders nützlich, wenn Sie Elemente auswählen, die bestimmte Schlüsselwörter oder Textteile enthalten.
Es ist jedoch wichtig zu beachten, dass die contains() Bei der Methode wird standardmäßig die Groß-/Kleinschreibung beachtet. Dies bedeutet, dass nur dann Übereinstimmungen gefunden werden, wenn die gesuchte Teilzeichenfolge die gleiche Groß-/Kleinschreibung aufweist wie der Text im Element.
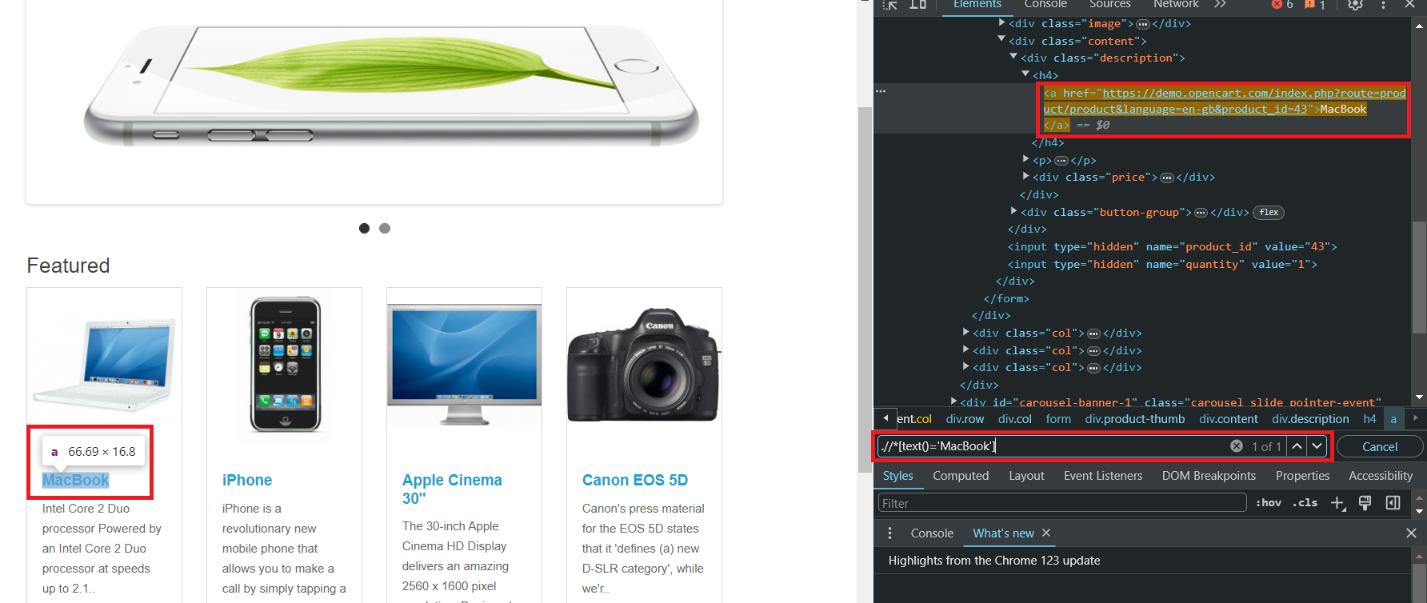
Kehren wir zur Demo-Site zurück und versuchen, alle Zeilen zu finden, die die Teilzeichenfolge „EOS“ enthalten. Wir können hierfür den folgenden XPath verwenden:
.//*(contains(text(), 'EOS'))Als Ergebnis finden wir zwei Elemente:
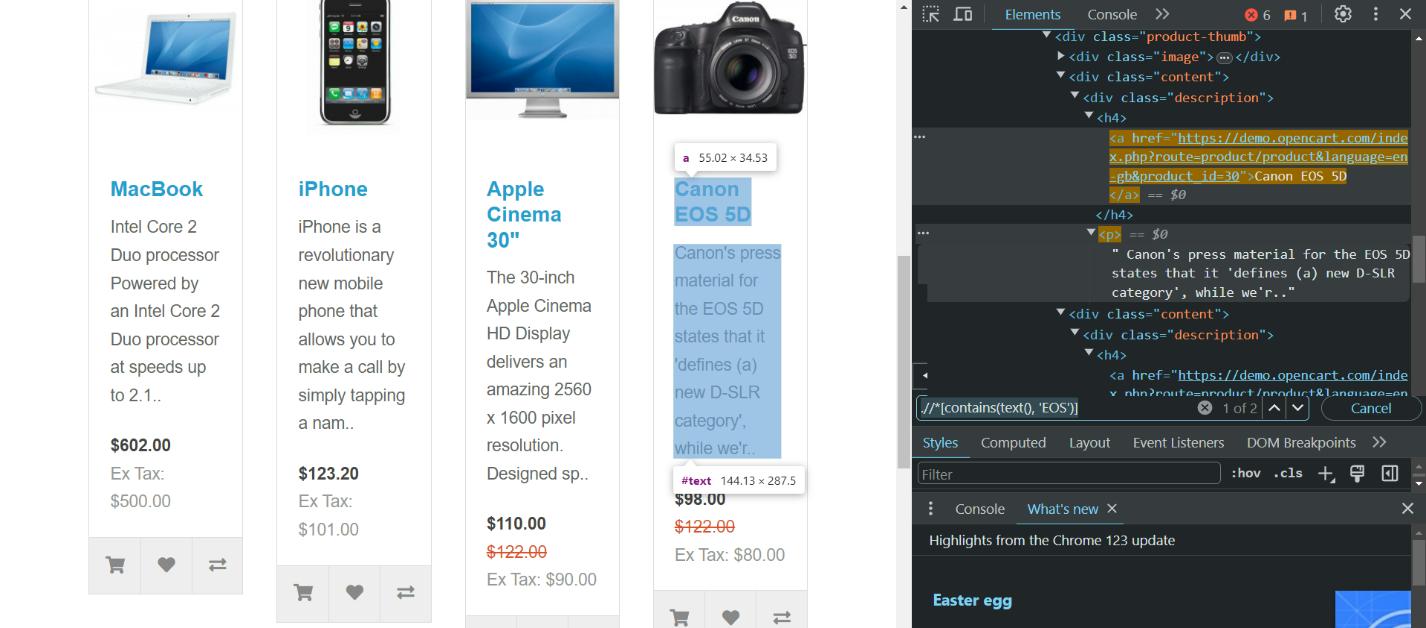
Wenn Sie genauere Ergebnisse erzielen möchten, können Sie den zuvor betrachteten XPath leicht modifizieren und ein bestimmtes Tag angeben, zum Beispiel:
.//p(contains(text(), 'EOS'))Diese Variante liefert nur ein Ergebnis – die Produktbeschreibung.
Starts-with(): Elemente auswählen, die mit einem Teilstring beginnen
Wenn Sie Elemente finden müssen, die mit einem bestimmten Wort oder einer bestimmten Silbe beginnen, ist die starts-with() Methode ist die am besten geeignete Option. Diese Methode ist besonders nützlich, wenn nach Elementen mit einem bestimmten Präfix oder einer bestimmten Anfangszeichenfolge gesucht wird.
Suchen wir nach Produkten, die mit bestimmten Zeichen beginnen:
.//*(starts-with(text(), 'Ap'))Daher wird es nur eines geben:
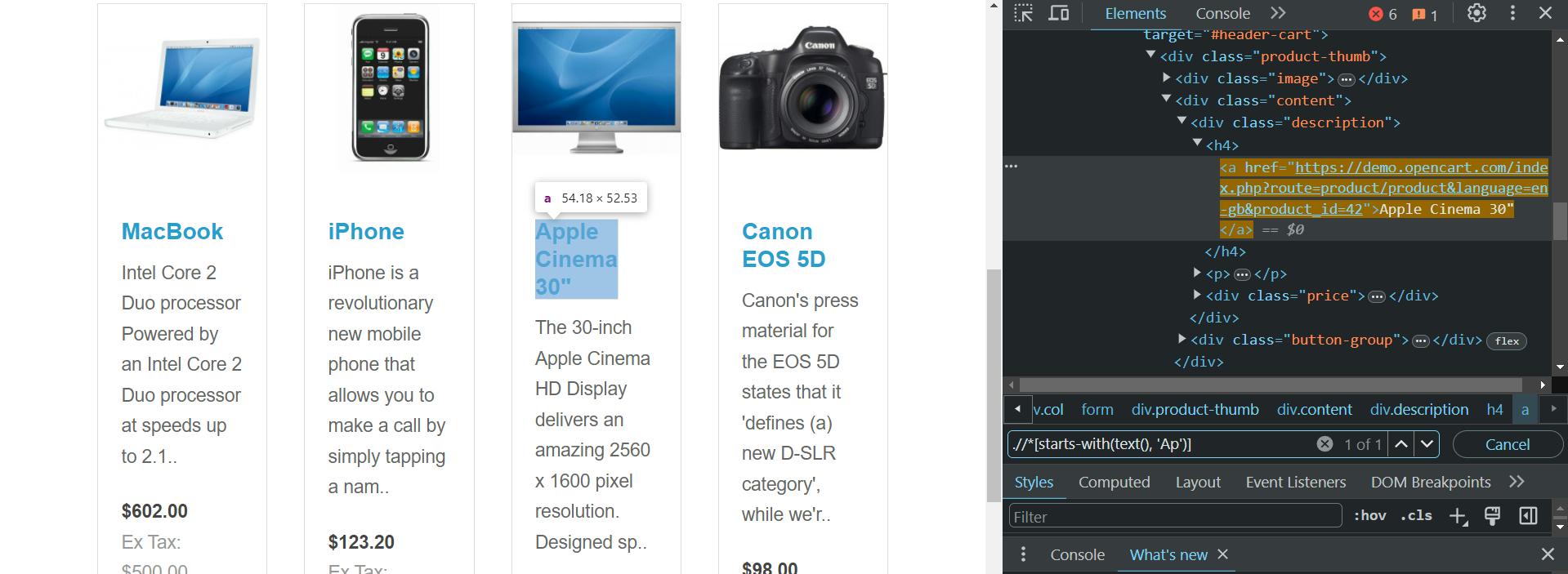
Beachten Sie, dass bei dieser Methode auch die Groß-/Kleinschreibung beachtet wird. Wenn Sie möchten, dass Ihr XPath die Groß-/Kleinschreibung nicht beachtet, können Sie mit dem nächsten Abschnitt fortfahren, in dem wir besprechen, wie Sie dies erreichen können.
endet-with(): Elemente auswählen, die mit einer Teilzeichenfolge enden
Diese Methode ist das Gegenteil der vorherigen und sucht nicht am Anfang des Textes, sondern am Ende nach Übereinstimmungen. Dies kann besonders nützlich sein, wenn Sie Elemente auswählen müssen, die durch ihre Attribute identifiziert werden, die mit einer bestimmten Zeichenfolge enden.
Leider funktioniert diese Methode nicht für XPath 1.0. Obwohl die meisten Tools es unterstützen, verfügt es über eine eingeschränkte Syntax für die Arbeit mit Textdaten:
.//*(ends-with(text(), 'ok'))Anstatt den gesamten Text zu durchsuchen, können Sie ein bestimmtes Tag oder Attribut angeben oder den gewünschten Suchbereich auf andere Weise festlegen.
Zusätzliche Methoden zur Textauswahl
Wie bereits erwähnt, gibt es neben den grundlegenden Methoden noch weitere Methoden zur Textsuche und -verarbeitung. In diesem Abschnitt wird erläutert, wie Sie mithilfe zusätzlicher XPath-Methoden, die sich gut für die Arbeit mit Zeichenfolgen eignen, die erforderlichen Elemente genauer identifizieren können.
Translate(): Groß-/Kleinschreibung wird ignoriert
Um Elemente unabhängig von der Groß-/Kleinschreibung zu finden, können wir den Text normalisieren, indem wir alle Buchstaben in Kleinbuchstaben umwandeln. So können wir es machen:
//*(starts-with(translate(text(), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'), 'mac'))Dieser Code verwendet die translate() Methode zum Ersetzen aller Großbuchstaben durch Kleinbuchstaben. Dann verwenden wir die starts-with() Funktion zum Suchen von Elementen, die mit der Kleinbuchstabenzeichenfolge „mac“ beginnen.
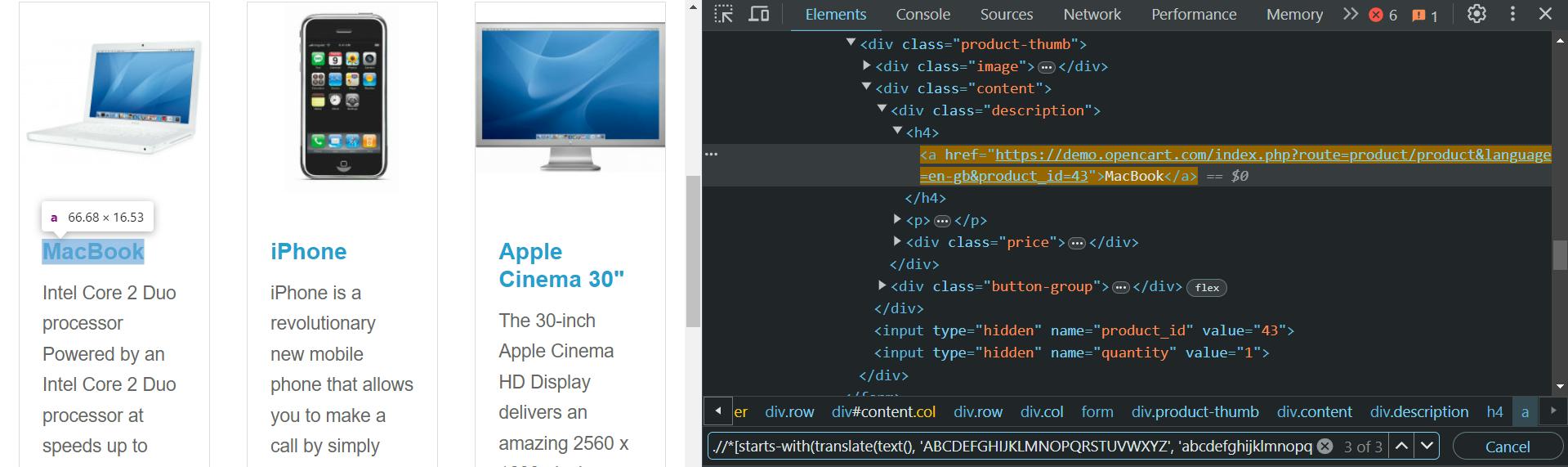
Darüber hinaus können Sie die verwenden lower-case() Und upper-case() Funktionen, aber wie die ends-with() Methode, sie werden nicht immer funktionieren.
not(): Elemente ausschließen, die mit einem bestimmten Text übereinstimmen
Die XPath-Methode, not() wird verwendet, um Elemente auszuschließen, die einem bestimmten Text oder Muster entsprechen. Damit können Sie Elemente in einem Dokument filtern und nur diejenigen auswählen, die keinen bestimmten Text enthalten oder einem bestimmten Muster entsprechen.
Verwendung der not() Die Methode ist besonders nützlich, wenn Sie bestimmte Elemente aus Ihren Abfrageergebnissen ausschließen. Lassen Sie uns beispielsweise Produkt-Tags verfeinern und MacBook ausschließen:
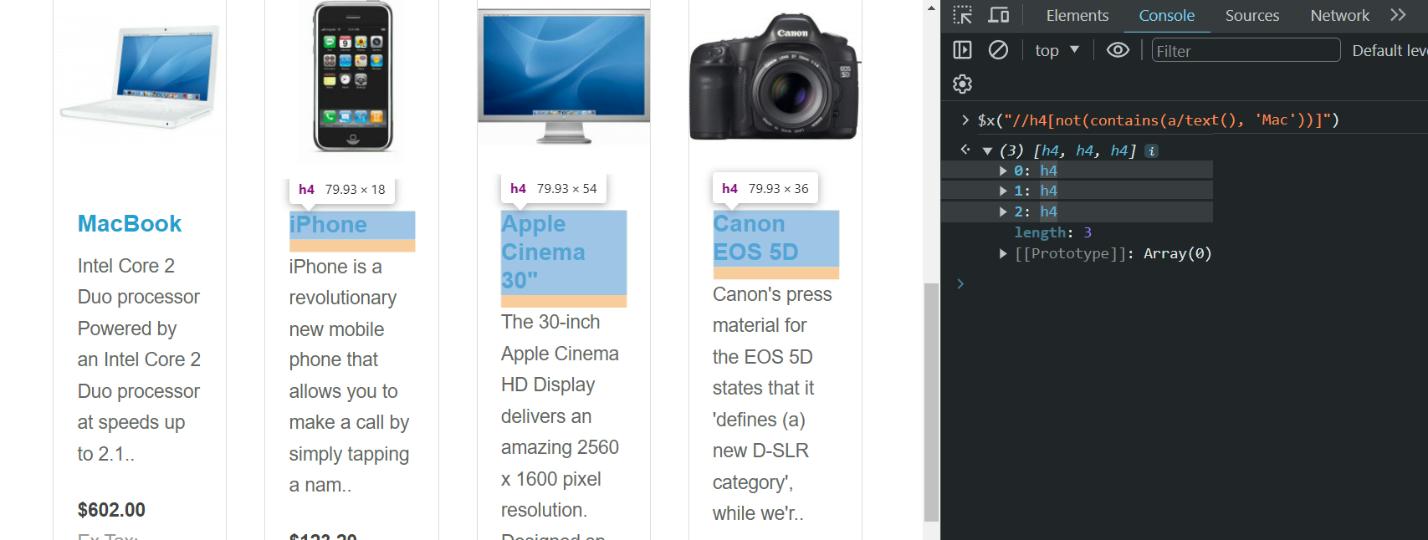
Wir haben den folgenden XPath-Ausdruck verwendet, um alle h4-Elemente auszuwählen, die nicht den Text „Mac“ in ihrem untergeordneten Element enthalten:
//h4(not(contains(a/text(), 'Mac')))Um das Ergebnis übersichtlicher zu gestalten, haben wir die Abfrage in der Browserkonsole ausgeführt, sodass wir direkt auf die Ergebnisse zugreifen können. Um das Beispiel noch prägnanter zu gestalten, zeigen wir nur den Text der ausgewählten Elemente und nicht die gesamten Elemente selbst an:
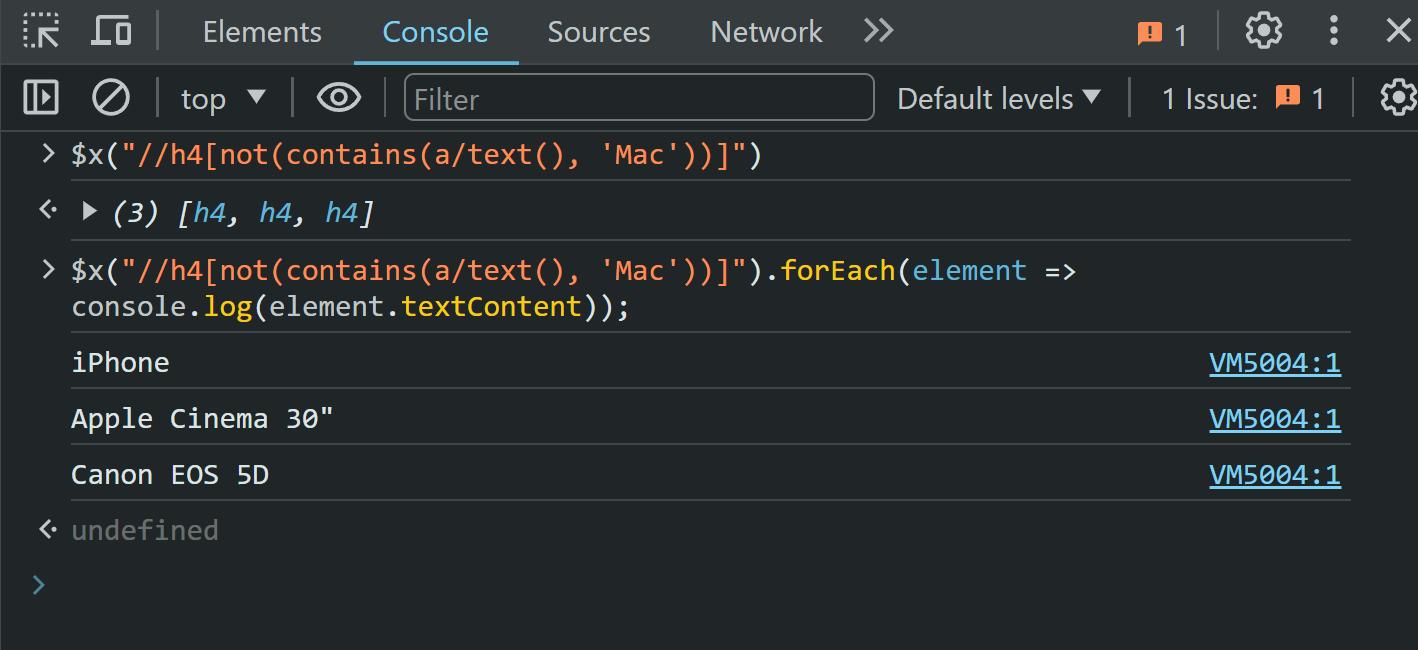
So verwenden Sie die not() Methode haben wir alle Artikel außer MacBook bekommen.
position(): Elemente anhand ihrer Position in der Liste auswählen
Der XPath position() Die Methode wählt Elemente basierend auf ihrer Position in einer Liste aus. Prädikate verwenden es häufig, um bestimmte Elemente anhand ihrer Ordnungszahl auszuwählen. Dies ist beispielsweise sehr praktisch, wenn wir nur das erste Element einer Liste und nicht die gesamte Liste abrufen möchten.
Um Daten zum ersten Element abzurufen, können Sie den folgenden XPath verwenden:
//h4(position() = 1)Um das letzte Element zu erhalten:
//h4(position() = last())Sie können auch einen Bereich von Elementen angeben:
//h4(position() >= 2 and position() <= 4)Dies macht die Methode besonders nützlich, wenn Sie mit bestimmten Elementen basierend auf ihrer Position im Dokument arbeiten möchten.
Der normalize-space() Die Methode ist ein leistungsstarkes Tool in XPath, mit dem Sie effizienter mit Textdaten arbeiten können. Obwohl es Elemente nicht direkt findet oder ausschließt, spielt es eine entscheidende Rolle bei der Textverarbeitung, indem es unnötige Leerzeichen entfernt.
Dies kann äußerst nützlich sein, wenn Sie mit Textdaten arbeiten, die zusätzliche Leerzeichen, Tabulatoren oder Zeilenumbrüche enthalten, was die Datenverarbeitung erschweren kann. Benutzen normalize-space()entfernt XPath automatisch alle führenden und nachgestellten Leerzeichen aus dem Text und ersetzt jede Leerzeichenfolge im Text durch ein einzelnes Leerzeichen. Dies führt zu saubereren und konsistenteren Textdaten, die sich einfacher weiterverarbeiten lassen.
normalize-space(" This is an example")Wenn wir verwenden normalize-space() Auf diesen Text erhalten wir folgendes Ergebnis:
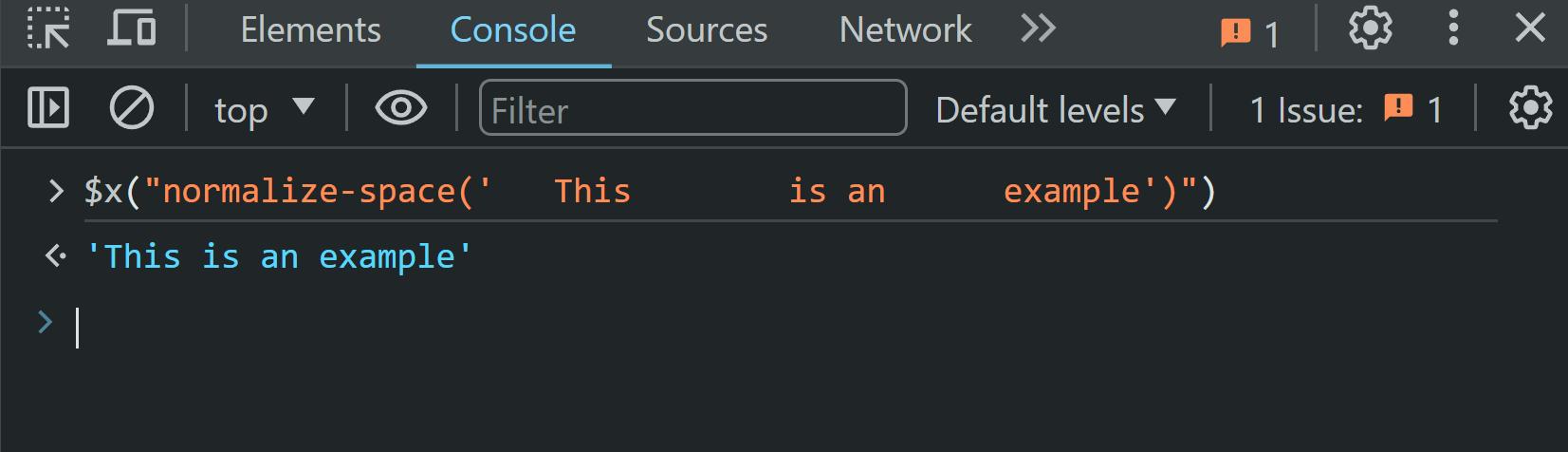
Wie Sie sehen können, wurden die zusätzlichen Leerzeichen, Tabulatoren und Zeilenumbrüche entfernt, sodass wir eine saubere und prägnante Zeichenfolge haben.
Fortgeschrittene Techniken zur Textauswahl
Nachdem wir nun die wichtigsten Methoden zum Suchen und Verarbeiten von Text behandelt haben, wollen wir uns mit fortgeschritteneren XPath-Techniken für die Arbeit mit Text befassen. Wir beginnen damit, zu untersuchen, wie man reguläre Ausdrücke zum Suchen von Elementen verwendet.
Verwendung regulärer Ausdrücke für den Textabgleich
Reguläre Ausdrücke (Regex) sind leistungsstarke Werkzeuge zum Suchen und Abgleichen von Mustern in Texten. Sie bieten mehr Flexibilität als die contains() Methode, mit der Sie nach Mustern statt nach exakten Zeichenfolgenübereinstimmungen suchen können.
Betrachten wir zum Beispiel E-Mail-Adressen. Sie haben alle die gleiche Struktur: (email protected). Wir können Regex verwenden, um alle E-Mail-Adressen auf einer Seite zu finden, auch wenn wir die spezifischen Adressen nicht kennen:
//*(matches(text(), '(\w\.-)+@(\w\.-)+'))Standard-XPath (wird in Browsern und Automatisierungstools verwendet) unterstützt oft nur XPath 1.0, dem die Funktion „matches()“ fehlt. Um Regex mit XPath zu verwenden, benötigen Sie XPath 2.0 oder höher.
Reguläre Ausdrücke sind ein leistungsstarkes Werkzeug zur Textbearbeitung, mit dem Sie verschiedene Such- und Bearbeitungsvorgänge für Textdaten durchführen können. Ihr praktischer Einsatz setzt jedoch ein Verständnis ihrer Syntax und Grundkonzepte voraus.
Während reguläre Ausdrücke in vielen verschiedenen Kontexten verwendet werden können, werden sie häufig in Verbindung mit Programmiersprachen, beispielsweise JavaScript oder Python, verwendet. Dies liegt daran, dass Programmiersprachen eine bequeme Möglichkeit bieten, Code mit regulären Ausdrücken zu schreiben und auszuführen. Wenn Sie Daten scrapen möchten, finden Sie in unserem Artikel über die Verwendung von XPath im Selenium-Webdriver etwas Nützliches.
Kombination verschiedener XPath-Methoden für komplexe Auswahlen
Wie bereits erwähnt, wird die Match-Funktion nur in XPath 2.0+ unterstützt und funktioniert daher in den meisten Browsern nicht. Stattdessen können wir die zuvor besprochenen Methoden kombinieren, um E-Mail-Adressen mithilfe des folgenden XPath-Ausdrucks zu extrahieren:
//div(contains(text(),'@') and contains(text(),'.') and not(contains(text(),' ')))/text()Dieser Ausdruck verwendet mehrere Kriterien, um zu bestimmen, ob es sich bei einer Zeichenfolge um eine E-Mail-Adresse handelt:
- Es muss das @-Symbol enthalten.
- Es muss mindestens einen Punkt (.) enthalten.
- Es darf keine Leerzeichen enthalten.
Das Element wird ignoriert, wenn eine dieser Bedingungen nicht erfüllt ist.
Best Practices und Tipps
Wir haben ein paar Tipps und Tricks zusammengestellt, um Ihre XPath-Nutzung noch effizienter und produktiver zu gestalten. Hier gehen wir auf häufig auftretende Probleme und deren Lösung ein.
Auswahl der richtigen Textauswahlmethode basierend auf dem Kontext
Die Methode zum Auswählen von Text in XPath sollte auf die spezifische Dokumentstruktur und Ihre Aufgabenanforderungen zugeschnitten sein. Wenn sich der Text beispielsweise innerhalb eines Tags befindet, können Sie Methoden wie verwenden text(), string()oder normalize-space()je nach Kontext.
Bei der Auswahl von XPath ist es wichtig, das gewünschte Ergebnis zu visualisieren und die geeignete Ebene für jede Methode zu verstehen. Sie können beispielsweise mehrere Methoden auf derselben Ebene verwenden, um ein Element zu verfeinern:
//h4(not(contains(a/text(), 'Mac')))(position() = 1)Hier verwenden wir sie nacheinander, um alle Elemente zu entfernen, die nicht „Mac“ enthalten, und identifizieren dann das erste Element unter den verbleibenden. Wenn Sie dieses Element weiter verfeinern möchten, beispielsweise angeben, dass es das erste sein soll und nicht die Teilzeichenfolge „Mac“ enthalten soll, wäre der XPath anders:
//h4(not(contains(a/text(), 'Mac')) and position() = 1)Denken Sie daran, dass die Anpassung von XPath an Ihre Dokumentstruktur und Aufgabenanforderungen von entscheidender Bedeutung ist.
Häufige Fehler bei der XPath-Textauswahl vermeiden
Die falsche Verwendung von Achsen oder Bedingungen ist ein häufiger XPath-Fehler, der zu einer falschen Datenauswahl oder unerwünschten Ergebnissen führen kann. Analysieren Sie die Struktur sorgfältig und überprüfen Sie die Richtigkeit Ihrer XPath-Ausdrücke.
Beispielsweise wäre die folgende Variante des vorherigen Beispiels falsch:
//h4(not(contains(a/text(), 'Mac'))) and (position() = 1)Dies liegt daran, dass XPath es dem „and“-Operator nicht erlaubt, zwei verschiedene Bedingungen in diesem Format zu kombinieren. Damit es richtig funktioniert, sollten wir beide Bedingungen in einem einzigen Prädikat kombinieren.
Testen von XPath-Ausdrücken auf Genauigkeit und Effizienz
Es stehen zahlreiche Tools und Ressourcen zur Verfügung, die Sie beim Erstellen und Testen von XPath-Ausdrücken unterstützen. Einige Browser-Entwicklertools wie Chrome DevTools oder Firefox Developer Tools bieten praktische Möglichkeiten, XPath auf echten Webseiten zu testen. Es gibt auch Online-Tools und Bibliotheken zum Testen und Debuggen von XPath-Ausdrücken.
Wir haben Chrome DevTools verwendet, um die erstellten XPath-Ausdrücke zu überprüfen und zu demonstrieren. Wir empfehlen dringend, diesen Ansatz zu verwenden, bevor Sie XPath-Ausdrücke in Ihren Skripts implementieren. Es ist viel schneller als andere Methoden und ermöglicht es Ihnen, die erforderlichen Elemente sofort zu verfolgen und die Echtzeitausführung Ihrer Ausdrücke zu beobachten. Sie können auch detaillierte Informationen zu jedem gefundenen Element erhalten.
Fazit und Erkenntnisse
In diesem Tutorial haben wir verschiedene Methoden zum Auffinden von Elementen auf einer Webseite anhand ihres Textinhalts mithilfe von XPath-Ausdrücken untersucht. XPath ist ein Standardtool für die Arbeit mit XML- und HTML-Dokumenten und damit ein vielseitiges Tool für Web Scraping und Automatisierung, unabhängig von der verwendeten Technologie oder Plattform.
Bei der Automatisierung von Webaktionen wie dem Ausfüllen von Formularen, dem Klicken auf Schaltflächen und dem Sammeln von Informationen ist häufig die gezielte Ausrichtung auf bestimmte Textelemente auf einer Seite erforderlich. XPath hilft beim Auffinden und Interagieren mit diesen Elementen und vereinfacht so den Automatisierungsprozess.
Web Scraping erfordert oft das Extrahieren spezifischer Daten von Webseiten, wie zum Beispiel Titel, Preise und Beschreibungen. XPath ermöglicht ein präzises Element-Targeting auf einer Webseite und macht den Datenextraktionsprozess effizienter und genauer als CSS-Selektoren oder andere Methoden.
