
In diesem Tutorial erfahren Sie alles, was Sie wissen müssen, um effektiv Daten von Walmart zu extrahieren.
TL;DR: Vollständiger Walmart-Schaber
Wenn Sie es eilig haben und nur den endgültigen Code lesen möchten, finden Sie ihn hier:
import json
import requests
from bs4 import BeautifulSoup
url = "https://www.walmart.com/ip/Straight-Talk-Apple-iPhone-SE-2022-3rd-Gen-5G-64GB-Midnight-Prepaid-Smartphone-Locked-to-Straight-Talk/616074177"
payload = {"api_key": "YOUR_API_KEY", "url": url, "render": "true"}
html = requests.get("http://api.scraperapi.com", params=payload)
product_info = {}
soup = BeautifulSoup(html.text)
product_info('product_name') = soup.find("h1", attrs={"itemprop": "name"}).text
product_info('rating') = soup.find("span", class_="rating-number").text
product_info('review_count') = soup.find("a", attrs={"itemprop": "ratingCount"}).text
image_divs = soup.findAll("div", attrs={"data-testid": "media-thumbnail"})
all_image_urls = ()
for div in image_divs:
image = div.find("img", attrs={"loading": "lazy"})
if image:
image_url = image("src")
all_image_urls.append(image_url)
product_info('all_image_urls') = all_image_urls
product_info('price') = soup.find("span", attrs={"itemprop": "price"}).text
next_data = soup.find("script", {"id": "__NEXT_DATA__"})
parsed_json = json.loads(next_data.string)
description_1 = parsed_json("props")("pageProps")("initialData")("data")("product")(
"shortDescription"
)
description_2 = parsed_json("props")("pageProps")("initialData")("data")("idml")(
"longDescription"
)
product_info('description_1_text') = BeautifulSoup(description_1, 'html.parser').text
product_info('description_2_text') = BeautifulSoup(description_2, 'html.parser').text
print(product_info)
Notiz: Vergessen Sie nicht, ihn auszutauschen YOUR_API_KEY mit Ihrem ScraperAPI-API-Schlüssel.
Bitte lesen Sie das Tutorial weiter, um zu verstehen, wie der Code funktioniert.
Scraping von Walmart-Produktdaten
In diesem Tutorial erfahren Sie, wie Sie Daten von einer einzelnen Walmart-Produktseite extrahieren und die folgenden annotierten Informationen (und die Produktbeschreibung) extrahieren:
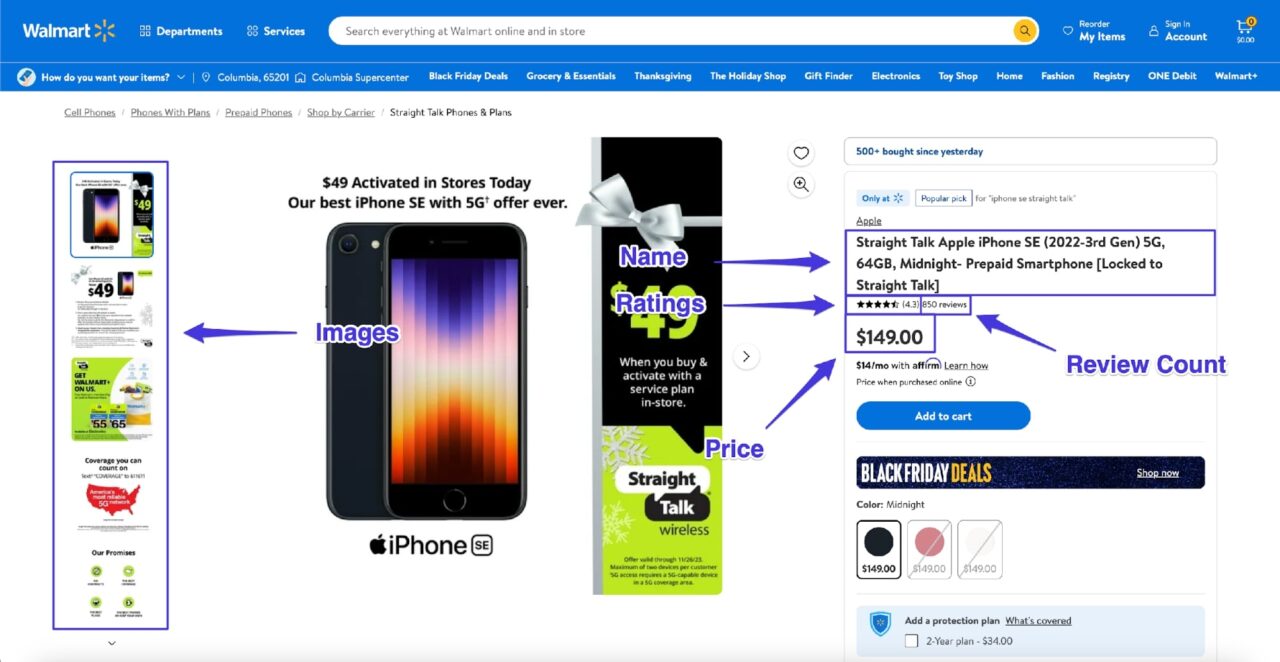
Anforderungen
Dieses Tutorial basiert auf Python Version 3.12. Wenn Sie eine Python-Version größer als 3.8 haben, sollte alles in Ordnung sein. Wenn jedoch etwas nicht wie gezeigt funktioniert, versuchen Sie, Ihre Python-Version auf 3.12 zu aktualisieren.
Sie können Ihre Python-Version überprüfen, indem Sie diesen Code im Terminal ausführen:
Um alles organisiert zu halten, erstellen Sie einen neuen Ordner mit einem app.py Datei darin:
$ mkdir walmart_scraper
$ cd walmart_scraper
$ touch app.py
Sie können auch eine virtuelle Umgebung einrichten, wenn Sie eine weitere Isolation wünschen:
python -m venv venv
source venv/bin/activate
Als nächstes müssen Sie Requests und BeautifulSoup installieren. Sie verwenden Requests zum Senden von HTTP-Anfragen und BeautifulSoup zum Parsen der Antwortdaten. Sie können beide ganz einfach mit PIP installieren:
$ pip install requests, beautifulsoup4
Schritt 1: Registrieren Sie sich bei ScraperAPI
So sehr Sie Walmart aus dem Verkehr ziehen möchten, so sehr möchte der Einzelhandelsriese nicht, dass seine Daten gescrapt werden. Aus diesem Grund setzt die Walmart-Website zahlreiche Anti-Bot-Maßnahmen ein, die als Reaktion auf automatisierte Anfragen falsche/nutzlose Daten zurückgeben.
Es gibt verschiedene Möglichkeiten, dieses Problem zu umgehen.
Sie können entweder versuchen, den Bot so weit wie möglich das Verhalten eines echten Benutzers nachahmen zu lassen, oder Sie können Proxys von Drittanbietern verwenden.
Die erste Option kann in einigen einfachen Fällen funktionieren, ist aber zu fragil, und da Walmart seine Anti-Bot-Maßnahmen ständig aktualisiert, ist es eine Frage, „wann“ Ihr Bot kaputt geht und nicht, „ob“.
Dies macht die Proxy-Option sehr attraktiv. Mit dieser Option entlasten Sie die schwierige Aufgabe, sicherzustellen, dass Walmart die richtige Antwort an einen Dritten zurücksendet, und haben so mehr Zeit, sich auf Ihre Geschäftslogik zu konzentrieren.
In diesem Tutorial behandeln wir die Proxy-Option und verwenden ScraperAPI als unseren Proxy-Anbieter.
Das Beste daran ist, dass ScraperAPI 5.000 kostenlose API-Credits für 7 Tage als Testversion bereitstellt und anschließend einen großzügigen kostenlosen Plan mit wiederkehrenden 1.000 API-Credits bereitstellt, um Sie am Laufen zu halten. Dies reicht aus, um Daten für den allgemeinen Gebrauch zu extrahieren.
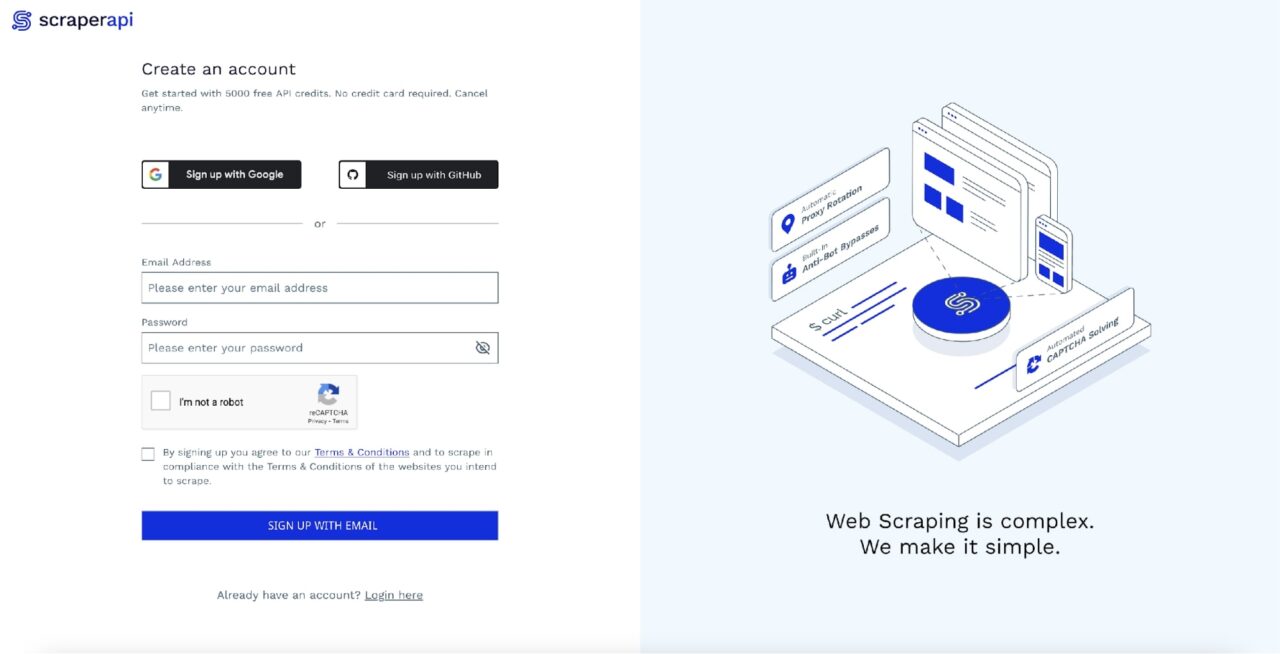
Sie können schnell loslegen, indem Sie zur ScraperAPI-Dashboard-Seite gehen und sich für ein neues Konto anmelden:
Nach der Anmeldung sehen Sie Ihren API-Schlüssel:
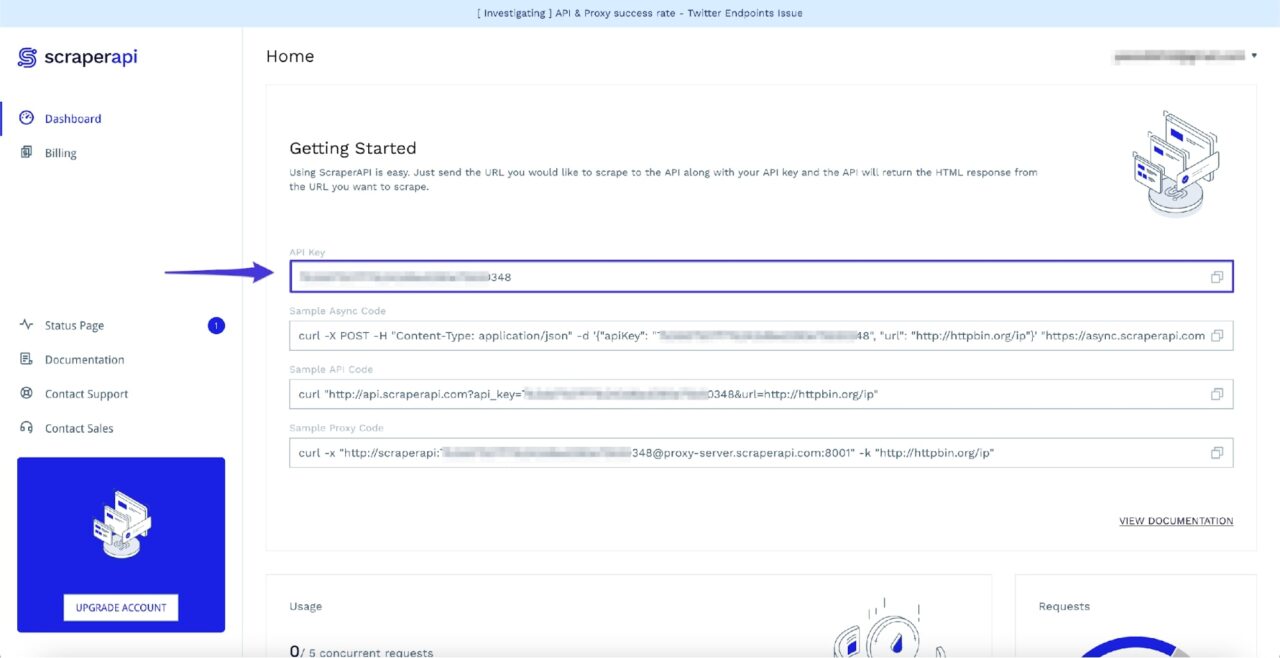
Notieren Sie sich diesen API-Schlüssel vorerst, da Sie ihn im nächsten Schritt benötigen.
Schritt 2: Abrufen der Walmart-Produktseite
Sobald Sie Ihr ScraperAPI-Konto eingerichtet haben, können Sie mit Python die erste Anfrage stellen, um die Produktseite von Walmart herunterzuladen. Zum Mitverfolgen können Sie diese Produktseite nutzen.
Sie haben verschiedene Möglichkeiten, wie Sie Ihre Anfragen über ScraperAPI weiterleiten möchten.
- Sie können ScraperAPI entweder als Proxy konfigurieren, während Sie Anfragen verwenden, oder…
- Sie können eine Anfrage an den API-Endpunkt von ScraperAPI senden und die Ziel-Walmart-URL als Nutzlast übergeben.
Weitere Informationen zu diesen Optionen finden Sie in der offiziellen Dokumentation.
In unserem Fall nutzen wir die letztere Option und übergeben eine URL als payload zum API-Endpunkt von ScraperAPI.
Sie können den folgenden Code verwenden, um die Produktseite von Walmart über ScraperAPI abzurufen:
import requests
url = "https://www.walmart.com/ip/Straight-Talk-Apple-iPhone-SE-2022-3rd-Gen-5G-64GB-Midnight-Prepaid-Smartphone-Locked-to-Straight-Talk/616074177"
payload = {"api_key": "YOUR_API_KEY", "url": url, "render": "true"}
html = requests.get("http://api.scraperapi.com", params=payload)
Notiz: Stellen Sie sicher, dass Sie ersetzen YOUR_API_KEY mit Ihrem ScraperAPI-API-Schlüssel
Sobald Sie die HTML-Antwort erhalten, können Sie damit ein BeautifulSoup-Objekt erstellen und es später zum Scrapen der erforderlichen Daten verwenden:
from bs4 import BeautifulSoup
# ...
soup = BeautifulSoup(html.text, 'html.parser')
Es ist der perfekte Zeitpunkt, mit dem Scraping von Daten mit BeautifulSoup zu beginnen.
Schritt 3: Extrahieren des Produktnamens
BeautifulSoup bietet eine find() Methode, die verschiedene Arten von Filtern aufnimmt und diese dann zum Scannen und Filtern des HTML-Baums verwendet.
Die wichtigsten Filter, die Sie kennen müssen, sind die String- und Attributfilter.
- Der String-Filter nimmt eine Zeichenfolge auf, die BeautifulSoup verwendet, um einen HTML-Tag-Namen abzugleichen.
- Der Attributfilter Hilft außerdem beim Filtern aller übereinstimmenden HTML-Tags nach einem bestimmten Attributwert.
Aber woher wissen Sie, welches HTML-Tag die gewünschten Daten enthält? Hier kommen Entwicklertools ins Spiel.
Die Entwicklertools sind im Lieferumfang der meisten bekannten Browser enthalten und ermöglichen es Ihnen, ganz einfach herauszufinden, welches HTML-Tag die Daten enthält, die Sie extrahieren möchten.
Sie können einfach auf die Entwicklertools zugreifen Rechtsklick auf dem Produktnamen und Klicken An prüfen.
So wird es aussehen, wenn die Entwicklertools in Firefox geöffnet sind (Chrome sollte auch etwas ähnlich aussehen):
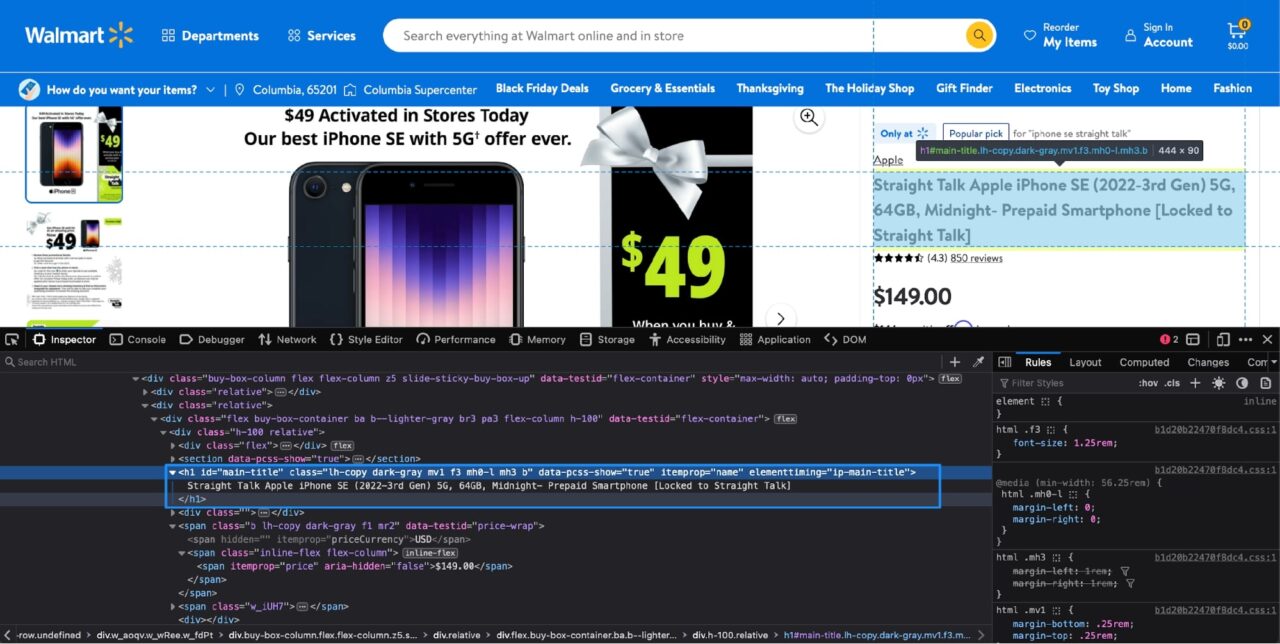
Der hervorgehobene Abschnitt im Inspektor Auf der Registerkarte erfahren Sie, dass der Produktname in einem gespeichert ist h1 Tag mit dem itemprop Attribut auf gesetzt name.
Notiz: Einem Tag können mehrere Attribute zugewiesen werden. Ihre Aufgabe besteht darin, herauszufinden, welche Kombination von Attributen ausreicht, um dieses bestimmte Tag eindeutig zu identifizieren. Glücklicherweise benötigen Sie in diesem Fall nur das itemprop Attribut, da es kein anderes gibt h1 Tag auf dieser Seite, der das hat itemprop Attribut auf gesetzt name.
Sie können dieses Wissen nutzen, um diesen Methodenaufruf zu erstellen, um den Produktnamen mit BeautifulSoup zu extrahieren:
product_name = soup.find("h1", attrs={"itemprop": "name"}).text
Der text -Attribut am Ende des Methodenaufrufs extrahiert einfach den Text aus dem passenden HTML-Element.
Wenn Sie versuchen, den Wert von auszudrucken product_name Variable, Sie sollten diese Ausgabe sehen:
>>> print(product_name)
Straight Talk Apple iPhone SE (2022-3rd Gen) 5G, 64GB, Midnight- Prepaid Smartphone (Locked to Straight Talk)
Süß! Das hat funktioniert! Jetzt können Sie versuchen, die restlichen Daten von der Seite zu entfernen.
Schritt 4: Extrahieren des Produktpreises
Es ist ein ähnlicher Prozess, den Produktpreis zu ermitteln. Wenn du Prüfen den Preis mit den Entwicklertools, das wird Ihnen angezeigt:
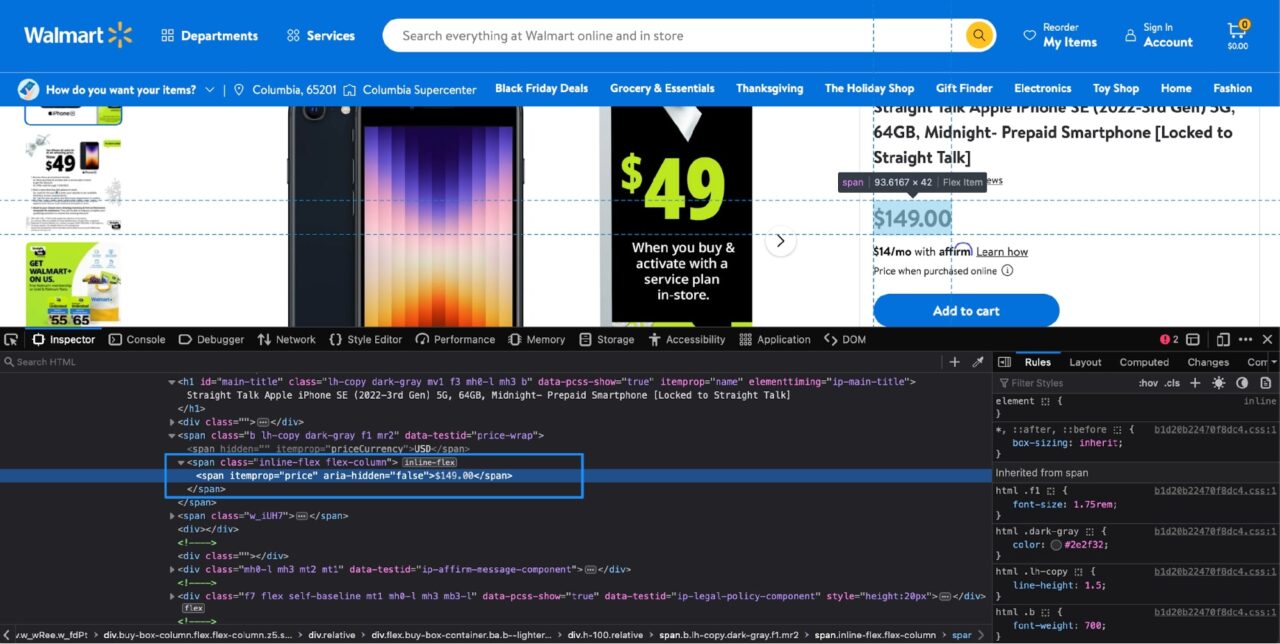
Die Preisinformationen sind in einem enthalten span Tag mit dem itemprop Attribut auf gesetzt price. Dies führt zu folgendem Python-Code:
price = soup.find("span", attrs={"itemprop": "price"}).text
Schritt 5: Extrahieren der Anzahl der Produktbewertungen und Rezensionen
Es sind ungefähr die gleichen Schritte erforderlich, um alle Informationen aus der Produktseite zu extrahieren. Wenn du Prüfen Nach den Bewertungen sollten Sie die folgende DOM-Struktur sehen:
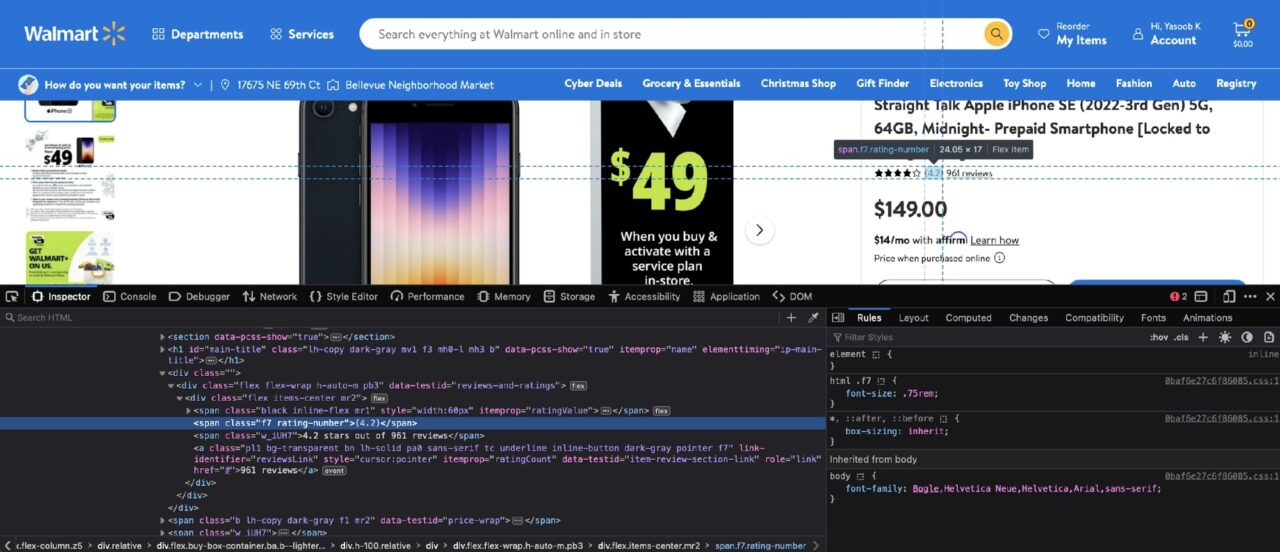
Die Bewertungsnummer ist in einem enthalten span mit einer Klasse von rating-numberund die Anzahl der Bewertungen ist in einer enthalten a Tag mit dem itemprop-Attribut auf gesetzt ratingCount.
Hier ist der resultierende Python-Code:
rating = soup.find("span", class_="rating-number").text
review_count = soup.find("a", attrs={"itemprop": "ratingCount"}).text
Der einzige Unterschied zwischen diesem Code und den vorherigen Extraktionscodes besteht darin, dass Sie den verwenden class_ Argument zur Übergabe des Klassennamens an BeautifulSoup. Dies ist lediglich eine andere Möglichkeit, nach Klassennamen zu filtern. Weitere Informationen zu den verschiedenen Filtern finden Sie in der offiziellen Dokumentation.
Schritt 6: Extrahieren der Produktbilder
Jetzt ist es an der Zeit, sich mit den Produktbildern zu befassen. So sieht die DOM-Struktur für Produktbilder aus:
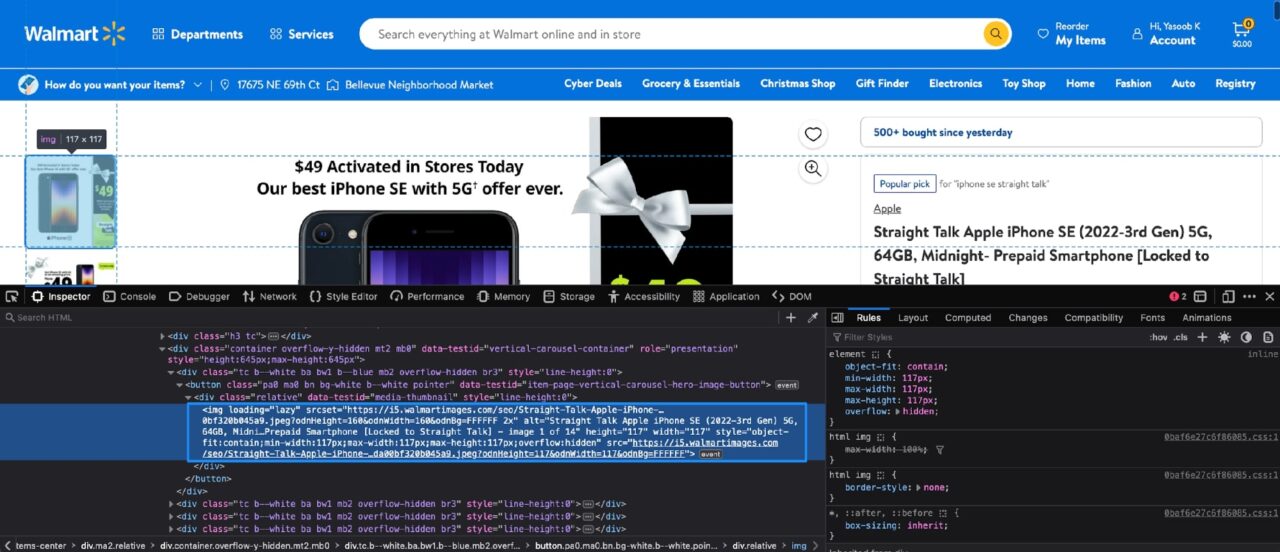
Jedes Produktbild ist in einer ähnlichen Abbildung enthalten img Tag mit dem loading Attribut auf Lazy gesetzt.
Sie können BeautifulSoup verwenden und einen Filter anwenden, um diese zu erhalten img Tags und extrahieren Sie dann die src Attribut, das die eigentliche Bild-URL enthält.
Es gibt nur ein kleines Problem. Da sind andere img Tags auf dieser Seite, die das haben loading Attribut auf gesetzt lazy. Wenn wir keine zusätzliche Filterung hinzufügen, gibt BeautifulSoup mehr Tags zurück als erwartet.
Eine Lösung besteht darin, zunächst nach einem anderen Tag zu filtern, um den Suchbereich einzugrenzen, und dann einen zusätzlichen Filter für dieses zurückgegebene Tag auszuführen, um alle erforderlichen verschachtelten Tags zu erhalten img Stichworte.
Wenn Sie genau hinsehen, können Sie das Elternteil beobachten div Tag enthält a data-testid Attribut auf gesetzt media-thumbnail. Mit diesem Wissen können Sie den folgenden Python-Code schreiben:
image_divs = soup.find_all("div", attrs={"data-testid": "media-thumbnail"})
all_image_urls = ()
for div in image_divs:
image = div.find("img", attrs={"loading": "lazy"})
if image:
image_url = image("src")
all_image_urls.append(image_url)
Dieser Code findet zunächst alle divs, die das Produktbild enthalten, und dann für jedes div Es wird eine zusätzliche Filterung angewendet, um die relevanten Informationen zu erhalten img Quellattribut des Tags.
Schritt 7: Extrahieren der Produktbeschreibung
Sie sind jetzt fast auf der Zielgeraden. Die letzte verbleibende Information, die Sie extrahieren müssen, ist die Produktbeschreibung.
Allerdings ist dies, wie Sie gleich sehen werden, auch die verwirrendste. Wenn du Prüfen In der Produktbeschreibung werden Sie auf die folgende DOM-Struktur stoßen:
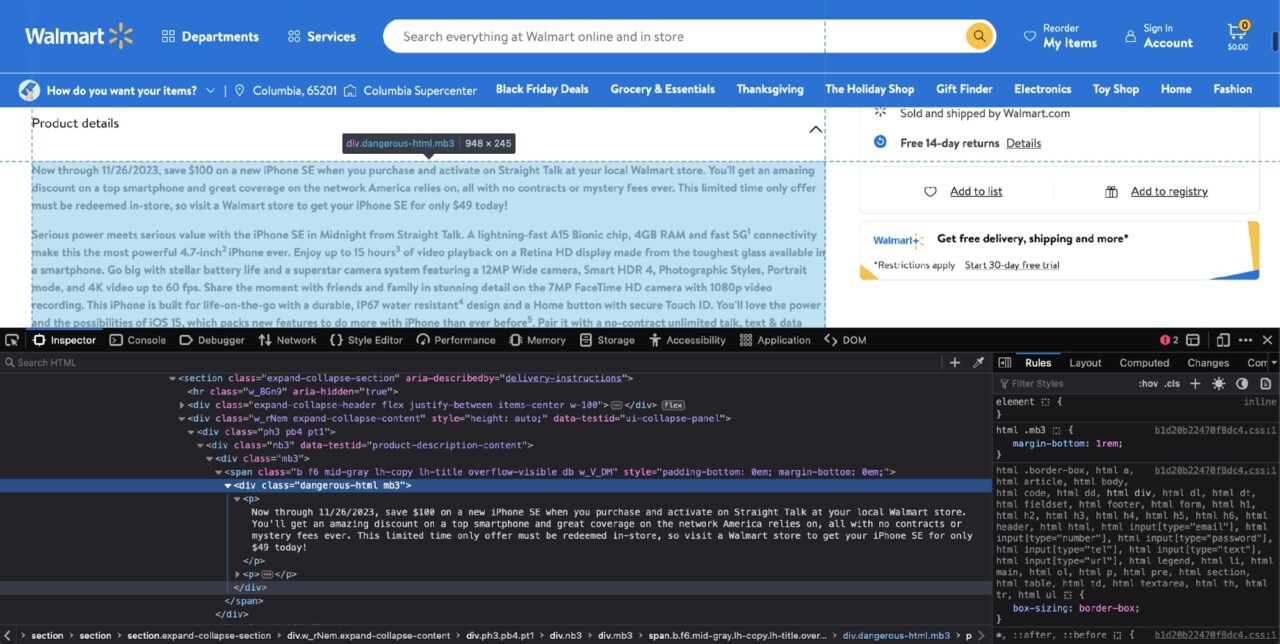
Auf den ersten Blick scheint es sich um einen einfachen Fall zu handeln div Filtern mit dem dangerous-html Klassenfilter:
soup.find("div", class_="dangerous-html")
Dies gibt jedoch keine passenden Tags zurück! Was ist das für eine Zauberei?
Wie sich herausstellt, verwendet Walmart das NextJS-Framework für seine Website und dieses Tag wird von NextJS auf der Clientseite ausgefüllt.
Normalerweise gibt es zwei mögliche Szenarien, wenn BeautifulSoup kein passendes Tag zurückgibt:
- Ein Szenario besteht darin, dass die Informationen nach dem ersten Laden der Seite über eine AJAX-Anfrage geladen werden
- Das zweite Szenario besteht darin, dass sich die Informationen bereits irgendwo im HTML-Dokument befinden, aber an ihrem endgültigen Zielort mit etwas JavaScript gefüllt werden
Das zweite Szenario besteht darin, dass sich die Informationen bereits irgendwo im HTML-Dokument befinden, aber an ihrem endgültigen Zielort mit etwas JavaScript gefüllt werden.
Wenn Sie nach der Produktbeschreibung in suchen Prüfen Auf der Registerkarte werden Sie schnell feststellen, dass die Produktbeschreibung in einem gespeichert ist script auch markieren:
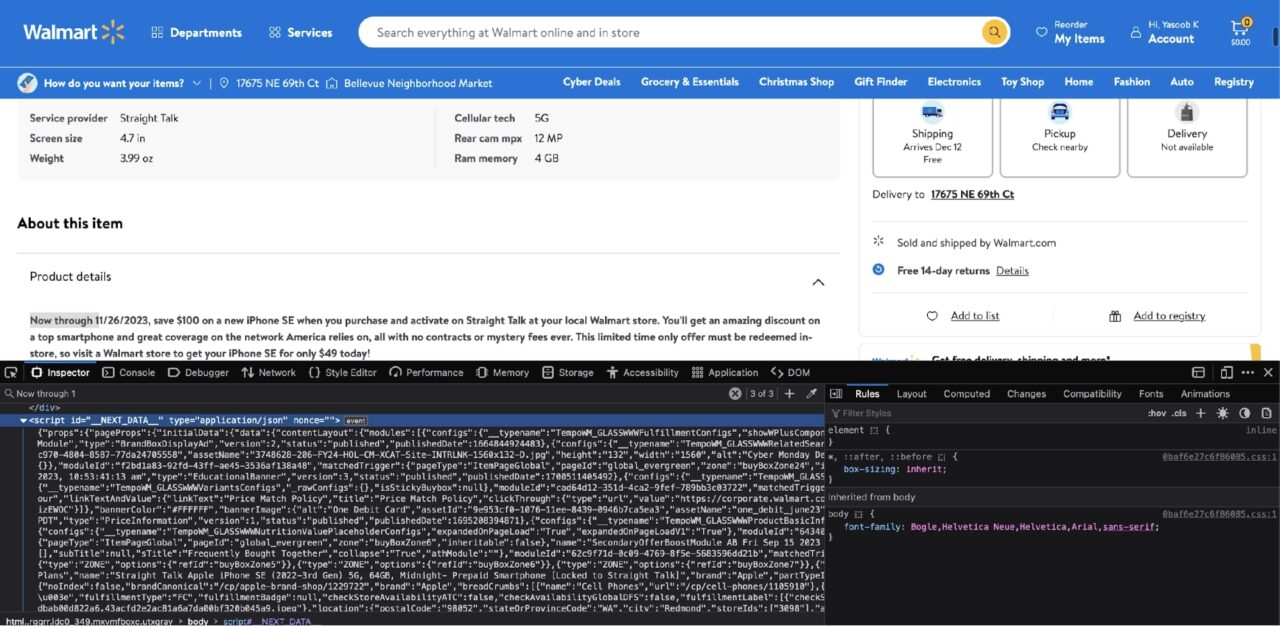
Das script Das Tag enthält die Daten, die vom NextJS-Framework verwendet werden, um die Benutzeroberfläche mit relevanten Informationen zu füllen. Dies ist nichts weiter als ein großer JSON-String. Sie können danach filtern script Tag mit BeautifulSoup, laden Sie die verschachtelten Daten mit json Bibliothek und greifen Sie dann mit den entsprechenden Schlüsseln auf die relevanten Informationen zu.
So sehen die geparsten JSON-Daten aus:
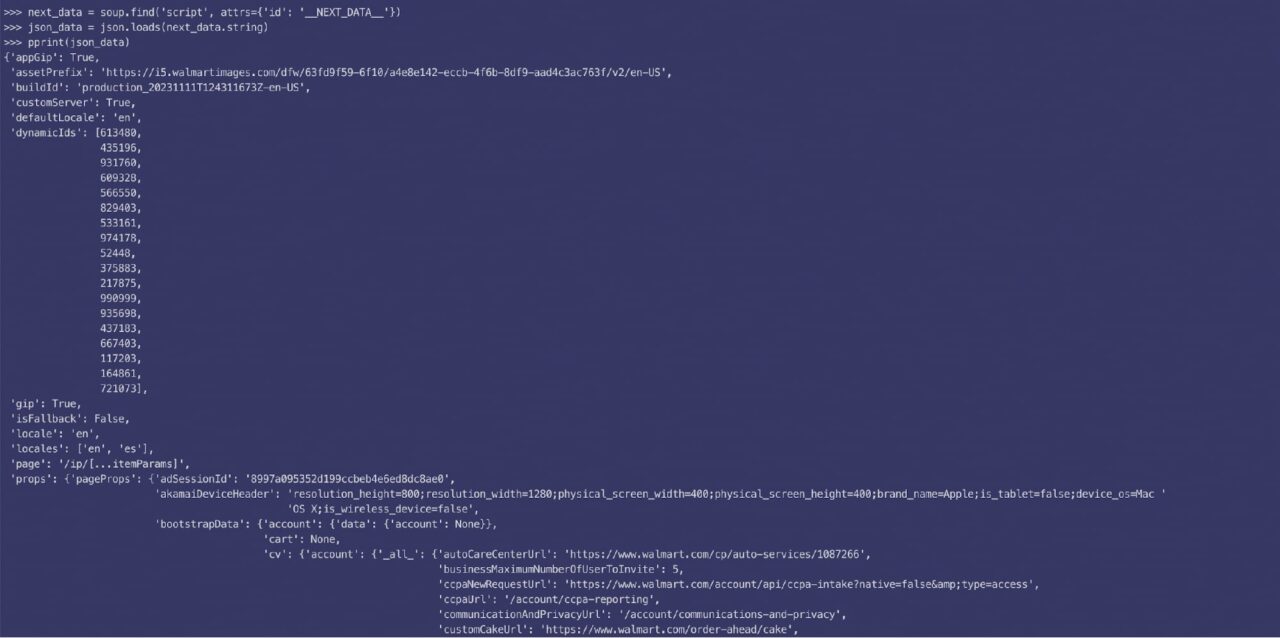
Wie sich herausstellt, ist die Beschreibung in zwei Teile (kurz und lang) unterteilt, und dieser Code liefert Ihnen die erforderlichen Daten:
next_data = soup.find("script", {"id": "__NEXT_DATA__"})
parsed_json = json.loads(next_data.string)
short_description = parsed_json("props")("pageProps")("initialData")("data")("product")(
"shortDescription"
)
long_description = parsed_json("props")("pageProps")("initialData")("data")("idml")(
"longDescription"
)
Es gibt noch ein weiteres Problem. Die extrahierte Beschreibung ist selbst eine Mischung aus HTML-Tags. Hier ist zum Beispiel die in p-Tags verschachtelte Kurzbeschreibung:
Sparen Sie jetzt bis zum 26.11.2023 100 $ beim Kauf eines neuen iPhone SE, wenn Sie es bei Straight Talk in Ihrem örtlichen Walmart-Geschäft kaufen und aktivieren. Sie erhalten einen erstaunlichen Rabatt auf ein Top-Smartphone und eine hervorragende Abdeckung des Netzwerks, auf das sich Amerika verlässt, und das alles ohne Verträge oder Mystery-Gebühren. Dieses zeitlich begrenzte Angebot muss im Geschäft eingelöst werden. Besuchen Sie also noch heute einen Walmart-Shop und holen Sie sich Ihr iPhone SE für nur 49 US-Dollar!
Erhebliche Leistung trifft auf ernsthaften Wert mit dem iPhone SE in Midnight von Straight Talk. Ein blitzschneller A15 Bionic-Chip, 4 GB RAM und schnelle 5G1-Konnektivität machen es zum leistungsstärksten 4,7-Zoll2 iPhone aller Zeiten. Genießen Sie bis zu 15 Stunden3 Videowiedergabe auf einem Retina HD-Display aus dem härtesten Glas, das es in einem Smartphone gibt. Gehen Sie groß raus mit hervorragender Akkulaufzeit und einem Superstar-Kamerasystem mit einer 12-MP-Weitwinkelkamera, Smart HDR 4, Fotostilen, Porträtmodus und 4K-Video mit bis zu 60 Bildern pro Sekunde. Teilen Sie den Moment mit Freunden und Familie in atemberaubender Detailgenauigkeit mit der 7-MP-FaceTime-HD-Kamera mit 1080p-Videoaufzeichnung. Dieses iPhone ist mit einem robusten, wasserdichten IP674-Design und einer Home-Taste mit sicherer Touch ID für das Leben unterwegs konzipiert. Sie werden die Leistung und die Möglichkeiten von iOS 15 lieben, das neue Funktionen bietet, mit denen Sie mehr mit dem iPhone machen können als je zuvor5. Kombinieren Sie es mit einem vertragsfreien, unbegrenzten Gesprächs-, Text- und Datentarif von Straight Talk, um im zuverlässigsten 5G†-Netzwerk Amerikas für weniger Geld verbunden zu bleiben. Finden Sie das Apple iPhone SE (3. Generation) in den Midnight- und Straight Talk-Plänen online oder im Geschäft bei Ihrem Walmart vor Ort.
Zum Glück ist die Lösung einfach. Sie können die Beschreibungen in neue BeautifulSoup-Objekte laden und dann BeautifulSoup bitten, den lesbaren Text aus dem HTML zu extrahieren:
short_description_text = BeautifulSoup(description_1, 'lxml').text
long_description_text = BeautifulSoup(description_2, 'lxml').text
Wenn Sie versuchen zu drucken short_description_text Jetzt werden Sie sehen, dass BeautifulSoup bequem alle HTML-Tags entfernt und nur den lesbaren Text zurückgegeben hat:
>>> print(short_description_text)
Sparen Sie jetzt bis zum 26.11.2023 100 $ beim Kauf eines neuen iPhone SE, wenn Sie es bei Straight Talk in Ihrem örtlichen Walmart-Geschäft kaufen und aktivieren. Sie erhalten einen erstaunlichen Rabatt auf ein Top-Smartphone und eine hervorragende Abdeckung des Netzwerks, auf das sich Amerika verlässt, und das alles ohne Verträge oder Mystery-Gebühren. Dieses zeitlich begrenzte Angebot muss im Geschäft eingelöst werden. Besuchen Sie also noch heute einen Walmart-Shop und holen Sie sich Ihr iPhone SE für nur 49 US-Dollar! Mit dem iPhone SE in Midnight von Straight Talk trifft echte Leistung auf echtes Preis-Leistungs-Verhältnis. Ein blitzschneller A15 Bionic-Chip, 4 GB RAM und schnelle 5G1-Konnektivität machen es zum leistungsstärksten 4,7-Zoll2-iPhone aller Zeiten. Genießen Sie bis zu 15 Stunden3 Videowiedergabe auf einem Retina HD-Display aus dem härtesten Glas, das es in einem Smartphone gibt. Gehen Sie groß raus mit hervorragender Akkulaufzeit und einem Superstar-Kamerasystem mit einer 12-MP-Weitwinkelkamera, Smart HDR 4, Fotostilen, Porträtmodus und 4K-Video mit bis zu 60 Bildern pro Sekunde. Teilen Sie den Moment mit Freunden und Familie in atemberaubender Detailgenauigkeit mit der 7-MP-FaceTime-HD-Kamera mit 1080p-Videoaufzeichnung. Dieses iPhone ist für das Leben unterwegs konzipiert und verfügt über ein robustes, wasserdichtes IP67-Design4 und eine Home-Taste mit sicherer Touch ID. Sie werden die Leistung und die Möglichkeiten von iOS 15 lieben, das neue Funktionen bietet, mit denen Sie mehr mit dem iPhone machen können als je zuvor5. Kombinieren Sie es mit einem vertragsfreien, unbegrenzten Gesprächs-, Text- und Datentarif von Straight Talk, um im zuverlässigsten 5G†-Netzwerk Amerikas für weniger Geld verbunden zu bleiben. Finden Sie das Apple iPhone SE (3. Generation) in den Midnight- und Straight Talk-Plänen online oder im Geschäft bei Ihrem örtlichen Walmart.
Schritt 8: Einfügen der Daten in ein Wörterbuch
Um die Arbeit mit den extrahierten Daten zu vereinfachen, können Sie sie in einem Wörterbuch speichern:
product_info = {
'product_name': product_name,
'rating': rating,
'review_count': review_count,
'price': price,
'all_image_urls': all_image_urls,
'short_description_text': short_description_text,
'long_description_text': long_description_text,
}
Der in der geteilte Code TLDR Der Abschnitt am Anfang des Tutorials unterscheidet sich geringfügig, da er das Wörterbuch füllt, sobald die relevanten Daten extrahiert werden. Der Code im Rest des Artikels folgt absichtlich nicht diesem Muster, damit er ohne zusätzliche Komplexität leicht zu verstehen ist.
Jetzt können Sie dieses Wörterbuch als Teil einer API-Antwort zurückgeben oder in einer CSV-Datei speichern. Der Himmel ist die Grenze!
Einpacken
In diesem Tutorial werden Sie:
- Erfahren Sie, wie Sie mit BeautifulSoup, Requests und Python Daten von der Walmart-Website extrahieren
- Ich habe gesehen, wie die Entwicklertools es einfach machen, herauszufinden, welche BeautifulSoup-Filter zum Extrahieren der relevanten Daten verwendet werden sollten
- Habe mich mit ScraperAPI vertraut gemacht und beobachtet, wie es mithilfe seiner fortschrittlichen Erkennungs-Umgehungsalgorithmen und einer Gruppe hochwertiger Proxys alle von Walmart verwendeten Anti-Bot-Maßnahmen unbrauchbar macht
Sie können die in diesem Tutorial gewonnenen Erkenntnisse nutzen, um ausgefeiltere Walmart-Scraping-Pipelines zu erstellen.
An diesem Punkt sind Ihrer Fantasie keine Grenzen gesetzt. Wenn Sie Fragen haben oder weitere Informationen zu unseren verschiedenen Produkten benötigen, wenden Sie sich bitte an uns! Wir helfen Ihnen gerne weiter.
Bis zum nächsten Mal, viel Spaß beim Schaben!
