
"css-18z4q2i eu4oa1w0"und angeben, ob die Rolle Vollzeit, Teilzeit oder Vertragsbasierte ist:
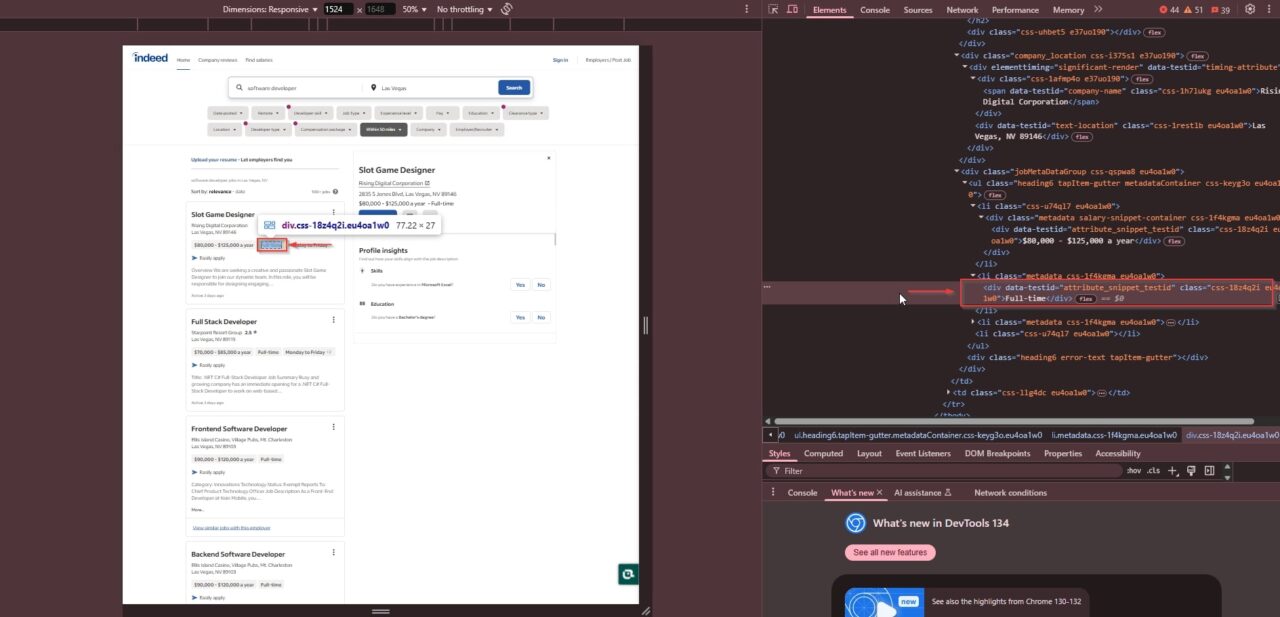
Nachdem wir nun wissen, wie tatsächlich Joblisten organisiert werden, können wir einen Schaber mit Scraperapi und Python schreiben, um diese Daten effizient zu extrahieren.
Projektanforderungen
Sie benötigen die richtigen Tools und das Einrichten, um die Stellenangebote zu kratzen. Hier sind die wichtigsten Anforderungen, um einen reibungslosen und effizienten Schablonenprozess zu gewährleisten:
1. Python installiert
Du brauchst Python 3.x auf Ihrem System installiert. Sie können die neueste Version von python.org herunterladen.
2. Erforderliche Python -Bibliotheken
Wir werden die folgenden Python -Bibliotheken verwenden, um Anfragen zu bearbeiten, Daten zu analysieren und mit dynamischen Inhalten zu interagieren:
requests– So senden Sie HTTP -Anfragen und abrufen HTML -InhalteBeautifulSoup– Analyse und Extrahieren von Jobdaten von HTMLSelenium– Um mit einem kopflosen Browser mit dynamischen Joblisten zu interagierenJSONUndCSV– Umkratzte Daten zu speichern und zu organisieren
Sie können diese Bibliotheken mit:
pip install requests beautifulsoup4 selenium
3.. Schakerapi -Konto
In der Tat hat strenge Anti-Scraping-Maßnahmen, sodass die Verwendung von Schaferapi die Erkennung und Bypass-Beschränkungen wie Captchas und IP-Blockierungen vermieden. Sie müssen sich für ein Konto bei Scraperapi anmelden und einen API -Schlüssel erhalten.
V.
Wenn Sie Selen verwenden, müssen Sie den entsprechenden Webdriver für Ihren Browser herunterladen:
Stellen Sie sicher, dass die Treiberversion mit Ihrer Browserversion übereinstimmt.
Wenn diese Tools und Bibliotheken eingerichtet sind, werden Sie bereit sein, tatsächlich Joblisten effizient zu kratzen!
Nachdem Sie über die erforderlichen Werkzeuge verfügen, ist es an der Zeit, in der Tat Stellenangebote mit Python und Scraperapi zu beginnen. Da in der Tat dynamisch Joblisten mit JavaScript geladen werden, verwenden wir den Render -Anweisungssatz von Scraperapi, um das Rendering von JavaScript zu verarbeiten und Jobdaten effizient zu extrahieren.
Wie man in der Tat Jobs Postings mit Python und Scraperapi kratzt
Jetzt, da wir verstehen, wie tatsächlich die Auflistungen für Joblisten strukturiert werden, schreiben wir ein Python -Skript, um die Jobsuche effizient zu kratzen. Wir werden Scraperapi verwenden, um Anti-BOT-Schutzmaßnahmen und wunderschöne Gruppen zu umgehen, um den HTML-Inhalt zu analysieren.
Schritt 1: Installieren Sie die erforderlichen Bibliotheken
Stellen Sie vor dem Schreiben eines Codes sicher, dass Sie über die erforderlichen Python -Bibliotheken installiert sind. Öffnen Sie Ihr Terminal oder Eingabeaufforderung und führen Sie aus:
pip install requests beautifulsoup4
Importieren Sie dann die erforderlichen Module in Ihr Python -Skript:
import requests
import json
import time
import random
from bs4 import BeautifulSoup
Schritt 2: Einrichten von Schaferapi
Für diesen Schritt benötigen Sie Ihre API -Taste, wenn Sie keinen haben, gehen Sie zum Schaker und melden Sie sich kostenlos an.
Ersetzen "YOUR_API_KEY" Mit Ihrem tatsächlichen Schaker -Schlüssel hier:
API_KEY = "YOUR_API_KEY"
SCRAPERAPI_URL = "https://api.scraperapi.com/"
BASE_URL = "https://www.indeed.com/jobs?q=software+developer&l=Las+Vegas&start={page}"
BASE_URL: Definiert die Tatsache der Jobsuche -URL für „Softwareentwickler“ -Jobs in Las Vegas. Der{page}Der Parameter hilft uns dabei, mehrere Stellenangebote zu pagieren.
Schritt 3: In der Tat extrahieren in der Tat Jobdaten
Lassen Sie uns als nächstes eine Funktion namens erstellen scrape_indeed_jobs(). Diese Funktion wird behandelt:
- Anfragen an in der Tat senden
- Jobdetails extrahieren
- Umgang mit Wiederholungen, wenn etwas schief geht
def scrape_indeed_jobs(start_page):
jobs = () # Store job listings
page_number = start_page
Listet in der Tat etwa 10 Jobs pro Seite auf. Wir werden mehrere Seiten durch Inkrementierung kratzen page_number.
for _ in range(MAX_PAGES):
attempt = 0 # Keep track of retry attempts
Hier, MAX_PAGES definiert, wie viele Seiten wir kratzen. Wenn MAX_PAGES = 5Wir kratzen 5 Seiten (~ 50 Jobs).
Jedes Mal, wenn wir eine neue Seite anfordern, übergeben wir die richtige URL an Scraperapi:
Wie es funktioniert:
- Wir ersetzen
{page}InBASE_URLmit dem tatsächlichenpage_number. - Scraperapi holt die Seite ab, während sie die Bot -Erkennung für uns bearbeiten.
Wenn die Anfrage erfolgreich ist (200 OK), extrahieren wir Stellendetails mit BeautifulSoup:
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
job_elements = soup.find("div", attrs={"id": "mosaic-jobResults"})
individual_job_elements = job_elements.find_all("li", class_="css-1ac2h1w eu4oa1w0")
Dies extrahiert alle Stellenangebote im Inneren
Wir durchlaufen jede Stellenangebote und extrahieren Folgendes:
- Berufsbezeichnung
- Name der Firma
- Standort
- Gehalt (falls verfügbar)
Jobtyp (Vollzeit, Teilzeit usw.)
for job_element in individual_job_elements:
job_title = job_element.find_next("a", class_="jcs-JobTitle css-1baag51 eu4oa1w0").find("span").text if job_element.find_next("a", class_="jcs-JobTitle css-1baag51 eu4oa1w0") else "N/A"
company_element = job_element.find_next("span", class_="css-1h7lukg eu4oa1w0") if job_element.find_next("span", class_="css-1h7lukg eu4oa1w0") else "N/A"
location_element = job_element.find_next("div", class_="css-1restlb eu4oa1w0") if job_element.find_next("div", class_="css-1restlb eu4oa1w0") else "N/A"
job_type_element = job_element.find_next("h2", class_="css-1rqpxry e1tiznh50") if job_element.find_next("h2", class_="css-1rqpxry e1tiznh50") else "N/A"
salary_element = job_element.find_next("div", class_="css-18z4q2i eu4oa1w0") if job_element.find_next("div", class_="css-18z4q2i eu4oa1w0") else "N/A
Sobald wir die Daten extrahiert haben, format wir sie gut und speichern sie in einer Liste:
jobs.append({
"Job Title": job_title,
"Company": company_element.text.strip() if company_element != "N/A" else "N/A",
"Location": location_element.text.strip() if location_element != "N/A" else "N/A",
"Salary": salary_element.text.strip() if salary_element != "N/A" else "N/A",
"Job Type": job_type_element.text.strip() if job_type_element != "N/A" else "N/A"
})
Jetzt haben wir alle Joblistings in der Lage jobs!
Wenn wir eine bekommen 500 Fehler, wir wiederholen uns bis zu MAX_RETRIES mal:
elif response.status_code == 500:
print(f"Error 500 on attempt {attempt + 1}. Retrying in {2 ** attempt} seconds...")
time.sleep(2 ** attempt)
attempt += 1
Am Ende jeder Schleife wechseln wir zur nächsten Seite und fügen eine zufällige Verzögerung hinzu (um die Erkennung zu vermeiden):
page_number += 10 # Move to the next page
time.sleep(random.uniform(5, 10))
Schritt 4: Speichern der extrahierten Daten
Schließlich führen wir unseren Schaber aus und speichern die Ergebnisse in einer JSON -Datei:
if __name__ == "__main__":
job_listings = scrape_indeed_jobs(START_PAGE)
if job_listings:
with open("indeed_jobs.json", "w", encoding="utf-8") as json_file:
json.dump(job_listings, json_file, indent=4, ensure_ascii=False)
print("Saved job posting(s) to 'indeed_jobs.json'")
Es speichert eine JSON -Datei, die so aussieht:
(
{
"Job Title": "Slot Game Designer",
"Company": "Rising Digital Corporation",
"Location": "Las Vegas, NV 89146",
"Salary": "$80,000 - $125,000 a year",
"Job Type": "N/A"
},
{
"Job Title": "Slot Game Designer",
"Company": "Rising Digital Corporation",
"Location": "Las Vegas, NV 89146",
"Salary": "$80,000 - $125,000 a year",
"Job Type": "N/A"
},
{
"Job Title": "Full Stack Developer",
"Company": "Starpoint Resort Group",
"Location": "Las Vegas, NV 89119",
"Salary": "$70,000 - $85,000 a year",
"Job Type": "N/A"
},
{
"Job Title": "Software Developer -- Entry Level",
"Company": "CGI Group, Inc.",
"Location": "Henderson, NV 89077",
"Salary": "$55,600 - $91,700 a year",
"Job Type": "N/A"
},
{
"Job Title": "Frontend Software Developer",
"Company": "Ellis Island Casino, Village Pubs, Mt. Charleston",
"Location": "Las Vegas, NV 89103",
"Salary": "$90,000 - $120,000 a year",
"Job Type": "N/A"
}.....
Jetzt haben wir alle Arbeitsplätze, die wir brauchen!
Hier ist der komplette Code für den Schaber:
import requests
import json
import time
import random
from bs4 import BeautifulSoup
API_KEY = "YOUR_API_KEY"
SCRAPERAPI_URL = "https://api.scraperapi.com/"
BASE_URL = "https://www.indeed.com/jobs?q=software+developer&l=Las+Vegas&start={page}"
START_PAGE = 0
MAX_RETRIES = 3
MAX_PAGES = 5
def scrape_indeed_jobs(start_page):
jobs = ()
page_number = start_page
for _ in range(MAX_PAGES):
attempt = 0
while attempt
In der Tat Jobpostings mit einem kopflosen Browser abkratzen
Bisher haben wir in der Tat erfolgreich Stellenausschreibungen mit Scraperapi mit Anfragen und wunderschönen Gruppen gekratzt. Aber was ist, wenn wir eine alternative Methode benötigen, um mit einem automatisierten Browser versehene Inhalte mit JavaScript-gerenderten Inhalten zu verarbeiten? Hier kommt Selen mit einem kopflosen Browser ins Spiel!
Selen an sich selbst wird oft als Bot nachgewiesen, wenn Websites in der Tat kratzt. Um dies zu vermeiden, verwenden wir SeleniumWirewas es uns ermöglicht, einen Proxy für den gesamten Browserverkehr zu konfigurieren. Anstatt direkt Anfragen zu stellen, werden wir alles über Scraperapi im Proxy -Modus weiterleiten. Dadurch sieht unsere Browseraktivität eher wie ein tatsächlicher Benutzer aus und hilft uns dabei, die Bot -Erkennung zu umgehen.
Schritt 1: Installieren Sie die erforderlichen Bibliotheken
Installieren Sie zunächst die erforderlichen Python -Bibliotheken:
pip install undetected-chromedriver selenium selenium-wire beautifulsoup4 csv
Folgendes verwenden wir:
undetected-chromedriver: Hilft bei der Umstellung der Bot -Erkennung durch Vermeidung von Selenfingerabdrückenselenium-wire: Lassen Sie uns den Verkehr über Scraperapi als Proxy steuernbeautifulsoup4: Extrahiert Jobdaten aus HTMLcsv: Speichert die abgekratzten Daten in eine Datei
Schritt 2: Selenium mit Schakerapi im Proxy -Modus einrichten
Als nächstes müssen wir Selenium mit Scraperapi als Proxy einrichten. Wir beginnen zunächst die URL der Scraperapi -Proxy, die unseren API -Schlüssel enthält. Die Proxy -URL ist formatiert, um Scraperapi mitzuteilen, dass wir JavaScript -Rendering aktivieren und dass der Verkehr von den USA stammt:
APIKEY = 'YOUR_API_KEY'
indeed_url = "https://www.indeed.com/jobs?q=software+developer&l=Las+Vegas"
proxy_url = f"http://scraperapi.render=true.country_code=us:{APIKEY}@proxy-server.scraperapi.com:8001"
Anschließend konfigurieren wir Seleniumoptionen, um zu verhindern, dass sie als automatisierter Browser erkannt werden. Eine übliche Art und Weise, wie Websites Bots erkennen, sind „Blink -Funktionen“, die Automatisierungsflags sind, die Selen hinterlässt. Durch Deaktivieren lassen wir den Browser eher wie eine normale Benutzersitzung aussehen:
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
Jetzt konfigurieren wir Seleniumwire, um den gesamten Browserverkehr über Scraperapi zu leiten. Anstatt Anfragen von unserer lokalen IP zu stellen, wird der gesamte Datenverkehr durch Scraperapi verläuft, wodurch IPS und Captchas automatisch gedreht werden:
seleniumwire_options = {
'proxy': {
'http': proxy_url,
'https': proxy_url,
},
'verify_ssl': False,
}
Als nächstes starten wir einen unentdeckten Chrombrowser mit Seleniumwire, um sicherzustellen, dass Ascraperapi alle Netzwerkanforderungen abwickelt
import undetected_chromedriver as uc
driver = uc.Chrome(options=options, seleniumwire_options=seleniumwire_options)
print(f"Fetching URL: {indeed_url}")
driver.get(indeed_url)
Dieser Befehl startet einen Chrome -Browser, leitet seine Anfragen über Scraperapi und öffnet in der Tat Jobsuchseite für Softwareentwickler in Las Vegas.
from time import sleep
print("Waiting for page to load...")
sleep(20)
Wenn wir zu schnell kratzen, werden wir möglicherweise blockiert oder erhalten unvollständige Ergebnisse. Eine 20-Sekunden-Wartezeit sorgt dafür, dass die Seite vor dem Fortfahren vollständig geladen wird.
Schritt 3: Dynamische Extrahieren von Joblisten
Nachdem die Seite geladen wurde, warten wir, bis der Container des Joblisten angezeigt wird. Websites verzögern manchmal das Rendern von Inhalten, sodass wir Webdriverwait verwenden, um sicherzustellen, dass die Daten verfügbar sind, bevor wir sie extrahieren.
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
try:
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, "mosaic-jobResults"))
)
except:
print("Could not locate job results.")
driver.quit()
exit()
Wenn tatsächlich unsere Anfrage blockiert oder nach einem Captcha fragt, wird das Skript beendet, um unnötige Wiederholungen zu verhindern. Andernfalls werden wir mit der BeautifulSoup die Stellenangebote analysieren.
soup = BeautifulSoup(driver.page_source, 'html.parser')
driver.quit()
job_results = soup.find("div", attrs={"id": "mosaic-jobResults"})
job_elements = job_results.find_all("li", class_="css-1ac2h1w eu4oa1w0") if job_results else ()
Schritt 4: Arbeitsdetails extrahieren
Sobald wir die Joblisten haben, durchlaufen wir jede Liste und extrahieren wichtige Details:
jobs_data = ()
for job_element in job_elements:
job_title_tag = job_element.find("a", class_="jcs-JobTitle css-1baag51 eu4oa1w0")
job_title = job_title_tag.find("span").text if job_title_tag else "N/A"
company_element = job_element.find("span", class_="css-1h7lukg eu4oa1w0")
company_name = company_element.text.strip() if company_element else "N/A"
location_element = job_element.find("div", class_="css-1restlb eu4oa1w0")
job_location = location_element.text.strip() if location_element else "N/A"
job_type_element = job_element.find("h2", class_="css-1rqpxry e1tiznh50")
job_type = job_type_element.text.strip() if job_type_element else "N/A"
salary_element = job_element.find("div", class_="css-18z4q2i eu4oa1w0")
salary = salary_element.text.strip() if salary_element else "N/A"
job_link = f"https://www.indeed.com{job_title_tag('href')}" if job_title_tag and job_title_tag.has_attr("href") else "N/A"
jobs_data.append((job_title, company_name, job_location, salary, job_type, job_link))
Wir überprüfen, ob jedes Jobdetail vorhanden ist, bevor wir es extrahieren. Wenn ein bestimmtes Element nicht verfügbar ist, geben wir „n/a“ zurück, anstatt einen Fehler zu verursachen.
Schritt 5: Speichern Sie die Daten in einer CSV -Datei
Sobald wir alle Stellenausschreibungen gesammelt haben, speichern wir sie in einer CSV -Datei, damit wir sie später analysieren können.
import csv
if jobs_data:
with open("indeed_jobs.csv", "w", newline="", encoding="utf-8") as csv_file:
writer = csv.writer(csv_file)
writer.writerow(("Title", "Company", "Location", "Salary", "Job Type", "Job Link"))
writer.writerows(jobs_data)
print("Saved job posting(s) to 'indeed_jobs.csv'")
print("Scraping session complete.")
Dies stellt sicher, dass alle Stellenangebote in einem strukturierten Format gespeichert werden, das Sie zur Analyse, Jobverfolgung oder Marktforschung verwenden können.
Hier ist der komplette Code für den Schaber:
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import undetected_chromedriver as uc
from bs4 import BeautifulSoup
import csv
from time import sleep
APIKEY = 'YOUR_API_KEY'
indeed_url = "https://www.indeed.com/jobs?q=software+developer&l=Las+Vegas"
proxy_url = f"http://scraperapi.render=true.country_code=us:{APIKEY}@proxy-server.scraperapi.com:8001"
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
seleniumwire_options = {
'proxy': {
'http': proxy_url,
'https': proxy_url,
},
'verify_ssl': False,
}
driver = uc.Chrome(options=options, seleniumwire_options=seleniumwire_options)
print(f"Fetching URL: {indeed_url}")
driver.get(indeed_url)
print("Waiting for page to load...")
sleep(20)
try:
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, "mosaic-jobResults"))
)
except:
print("Could not locate job results")
driver.quit()
exit()
soup = BeautifulSoup(driver.page_source, 'html.parser')
driver.quit()
job_results = soup.find("div", attrs={"id": "mosaic-jobResults"})
job_elements = job_results.find_all("li", class_="css-1ac2h1w eu4oa1w0") if job_results else ()
jobs_data = ()
for job_element in job_elements:
job_title_tag = job_element.find("a", class_="jcs-JobTitle css-1baag51 eu4oa1w0")
job_title = job_title_tag.find("span").text if job_title_tag else "N/A"
company_element = job_element.find("span", class_="css-1h7lukg eu4oa1w0")
company_name = company_element.text.strip() if company_element else "N/A"
location_element = job_element.find("div", class_="css-1restlb eu4oa1w0")
job_location = location_element.text.strip() if location_element else "N/A"
job_type_element = job_element.find("h2", class_="css-1rqpxry e1tiznh50")
job_type = job_type_element.text.strip() if job_type_element else "N/A"
salary_element = job_element.find("div", class_="css-18z4q2i eu4oa1w0")
salary = salary_element.text.strip() if salary_element else "N/A"
job_link = f"https://www.indeed.com{job_title_tag('href')}" if job_title_tag and job_title_tag.has_attr("href") else "N/A"
jobs_data.append((job_title, company_name, job_location, salary, job_type, job_link))
if jobs_data:
with open("indeed_jobs.csv", "w", newline="", encoding="utf-8") as csv_file:
writer = csv.writer(csv_file)
writer.writerow(("Title", "Company", "Location", "Salary", "Job Type", "Job Link"))
writer.writerows(jobs_data)
print("Saved job posting(s) to 'indeed_jobs.csv'")
print("Scraping session complete.")
So sollte die Ausgabe auf das Schaben passen:

Schlussfolgerung: Wählen Sie die beste Methode, um in der Tat Jobpostings zu kratzen
Durch das Abkratzen von Stellenangeboten von Tatsächlich haben Sie Zugang zu Echtzeit-Einstellungstrends, Gehaltserkenntnissen und gefragten Fähigkeiten ohne manuelle Suche. In diesem Leitfaden haben Sie gelernt, wie man in der Tat mit Python, Scraperapi und Selen zusammen mit Strategien zur Umgehung von Anti-BOT-Schutzmaßnahmen und Struktur Ihrer Daten effizient kratzt.
Scraperapi mit Anfragen ist die beste Methode für die meisten Krabbungsanforderungen – es ist schnell, leicht und vermeidet den Overhead, einen Browser auszuführen. Wenn JavaScript-hochwertige Seiten jedoch Automatisierung erfordern, kann ein kopfloser Browser mit Selen hilfreich sein, obwohl es mit zusätzlichen Komplexitäts- und Erkennungsrisiken ausgestattet ist.
Wenn Sie schnell, zuverlässig und ohne den Ärger von Captchas oder IP -Blöcken schnell, zuverlässig und ohne IP -Blöcke kratzen möchten, ist Scraperapi der richtige Weg. Versuchen Sie es noch heute und schälen Sie intelligenter!
Melden Sie sich für Scraperapi an und beginnen Sie!
Viel Spaß beim Kratzen!
FAQ
Ist es legal, intell.com zu kratzen?
Web Scraping Inal.com fällt in eine legale Grauzone. Während öffentlich zugängliche Daten häufig nach Prinzipien für faire Nutzung abgekratzt werden können, verbieten die Service -Nutzungsbedingungen in der Tat die automatisierte Datenextraktion. Verstoß gegen diese Begriffe kann zu rechtlichen Konsequenzen oder zu blockiertem IP -Zugriff führen. Um konform zu bleiben, ist es am besten, Robots.txt -Dateien zu respektieren und persönliche oder sensible Daten zu vermeiden.
Kann in der Tat mit kopflosen Browsern wie Dramatikern abgekratzt werden?
Ja, Dramatiker kann tatsächlich Joblisten kratzen, indem sie einen kopflosen Browser automatisiert, um Javascript-renderierte Inhalte zu laden. In der Tat beruht jedoch nicht stark auf JavaScript für Joblisten, was bedeutet, dass eine Proxy-basierte Lösung wie Scraperapi mit Anfragen ein schnellerer und effizienterer Ansatz ist. Kopflose Browser wie Dramatiker sollten nur bei Bedarf verwendet werden, da sie ressourcenintensiv sind und eher Anti-BOT-Schutzschutz auslösen.
Welche Tools eignen sich am besten für Web -Scraping -Stellenangebote von in der Tat?
Zu den besten Tools für das Scraping-Auflagen gehören Scraperapi für schnelles und effizientes Proxybasis, Anfragen und wunderschöne Gruppen für das Parsen statischer Inhalte sowie Selenium oder Dramatiker für die Behandlung von JavaScript-Heavy-Seiten bei Bedarf. Scraperapi ist die Top -Wahl für das Scraping, da es IP -Blöcke umgehen, Captchas verarbeiten und bei Bedarf JavaScript rendern kann, was es zu einer zuverlässigen und skalierbaren Lösung macht.
(tagstotranslate) Web Scraping (T) Web Scraping Tools
