Forex, auch Devisenhandel genannt, ist ein internationaler Markt, auf dem Menschen verschiedene Währungen elektronisch außerbörslich (OTC) handeln – mit der Besonderheit, dass es keinen zentralen Marktplatz gibt.
Es ist ein bisschen so, als würde man Geld tauschen, wenn man in den Urlaub fährt, nur dass (auf dem Devisenmarkt) Menschen Währungen kaufen und verkaufen, um von Wertänderungen zu profitieren.
Menschen aus aller Welt handeln rund um die Uhr, fünf Tage die Woche, mit Währungen, was ihn zu einem der größten Finanzmärkte der Welt macht. Und wie bei jeder finanziellen Entscheidung helfen Ihnen die richtigen Daten dabei, genaue und profitable Investitionen zu tätigen.
Der Forex-Markt unterliegt starken Schwankungen. Daher verschafft Ihnen die Vorhersage potenzieller Aufwärts- oder Abwärtsbewegungen einen unfairen Vorteil und erzielt die gewünschten Ergebnisse.
In diesem Artikel extrahieren wir Währungsdaten aus Yahoo Finance mit Pythons Requests und Beautiful Soup und exportieren sie mit Pandas in eine CSV-Datei.
TL;DR über das Scraping von Forex-Daten mit Beautiful Soup (BS4)
Für diejenigen mit Erfahrung gibt es hier die vollständige Codebasis:
Um zu erfahren, wie wir es aufgebaut haben und welchen Denkprozess dahinter steckt, lesen Sie bitte weiter.
1. Grundlegendes zur HTML-Struktur von Yahoo Finance
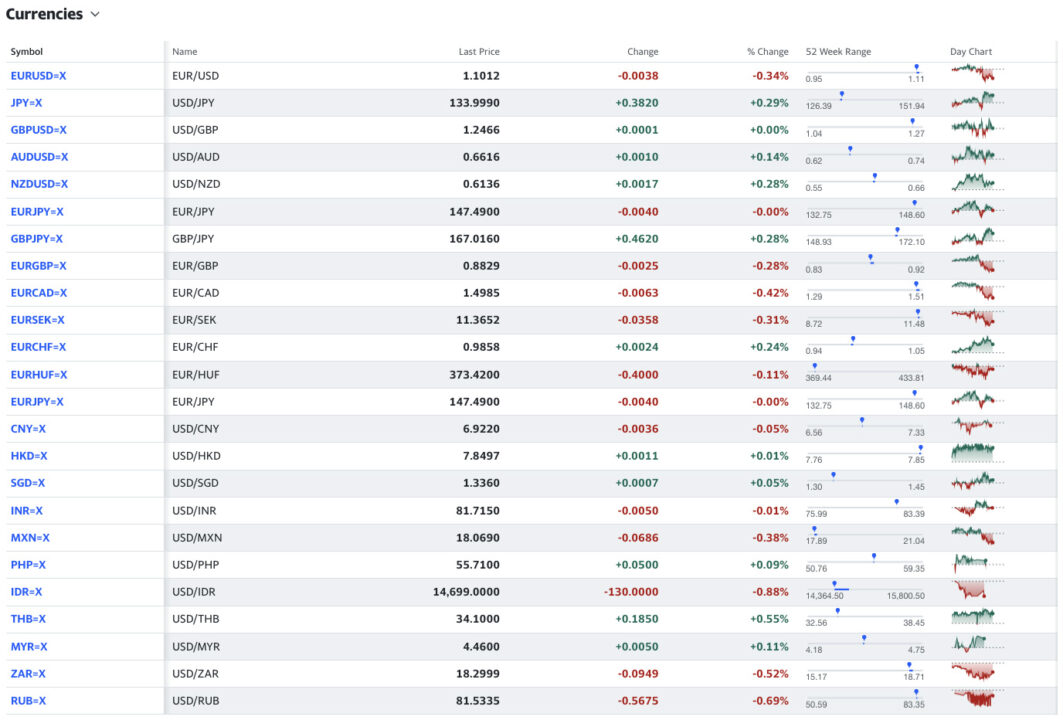
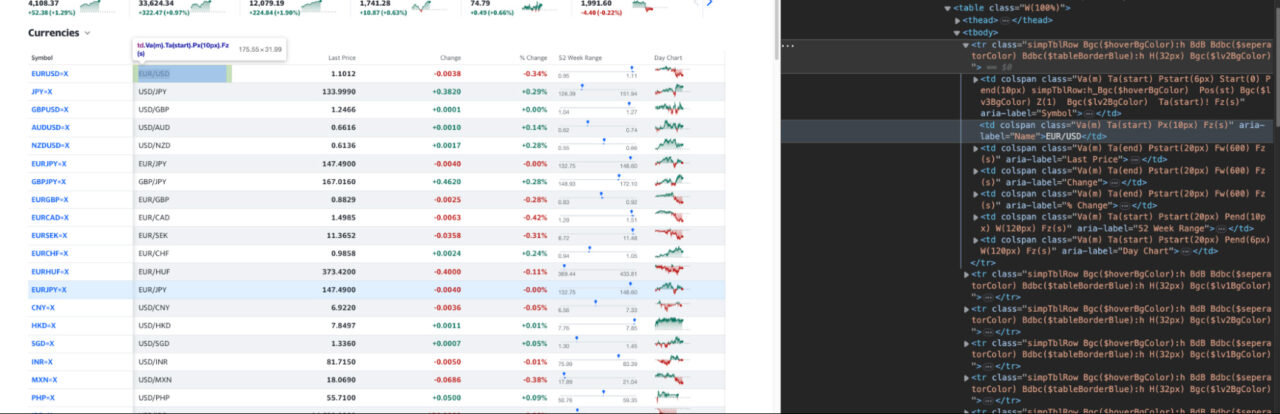
Bevor wir mit dem Codieren beginnen, werfen wir zunächst einen Blick auf die Währungsseite von Yahoo, um zu verstehen, womit wir es zu tun haben.
Die verfügbaren Währungen auf der Seite scheinen zumindest optisch in einem Tabellenformat angezeigt zu werden.
An dieser Stelle müssen wir zwei Dinge überprüfen:
Stellen Sie sicher, dass wir aus der rohen HTML-Datei auf diese Daten zugreifen können – mit anderen Worten, dass der Inhalt nicht über AJAX eingefügt wird.
Stellen Sie sicher, dass der HTML-Code auch als Tabelle strukturiert ist.
Um Nummer eins zu erledigen, kopieren Sie einen der Währungsnamen und klicken Sie mit der rechten Maustaste auf die Seite > Seitenquelle anzeigen.
Jetzt suchen wir nach dem Text, den wir kopiert haben. Wenn es im Quellcode erscheint, können wir die Daten mit einer einfachen Anfrage extrahieren.
Super, wir haben es gefunden! Diese Prüfung ist wichtig, denn wenn der Inhalt über JavaScript eingefügt wird, müssen wir einen anderen Ansatz wählen. Wir könnten beispielsweise auf die „versteckte API“ abzielen, von der die Seite die Daten erhält, wie wir es beim Scrapen dieser dynamischen Tabelle getan haben, oder wir könnten auch einen Headless-Browser wie Selenium oder Puppeteer (Option Node.js) verwenden.
Bei der zweiten Überprüfung werden Sie überrascht sein, wie oft Websites Tabellen ohne das Traditionelle anzeigen table > thead > tbody > tr > td Wenn Sie also eine Tabelle wie diese finden, überprüfen Sie vor dem Feiern immer den HTML-Code im Browser.
Weitere tolle Neuigkeiten! Die Daten in einer gut strukturierten Tabelle zu haben, erleichtert den gesamten Prozess und wir könnten mit Pandas sogar die gesamte Tabelle extrahieren. In diesem Tutorial verwenden wir jedoch BS4 zum Parsen der Tabelle und verwenden Pandas nur zum Exportieren der Ergebnisse.
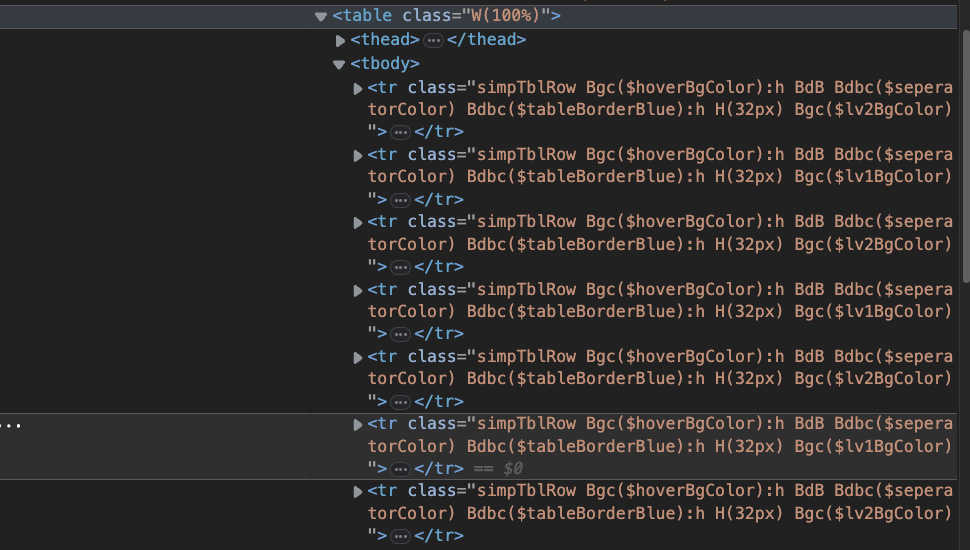
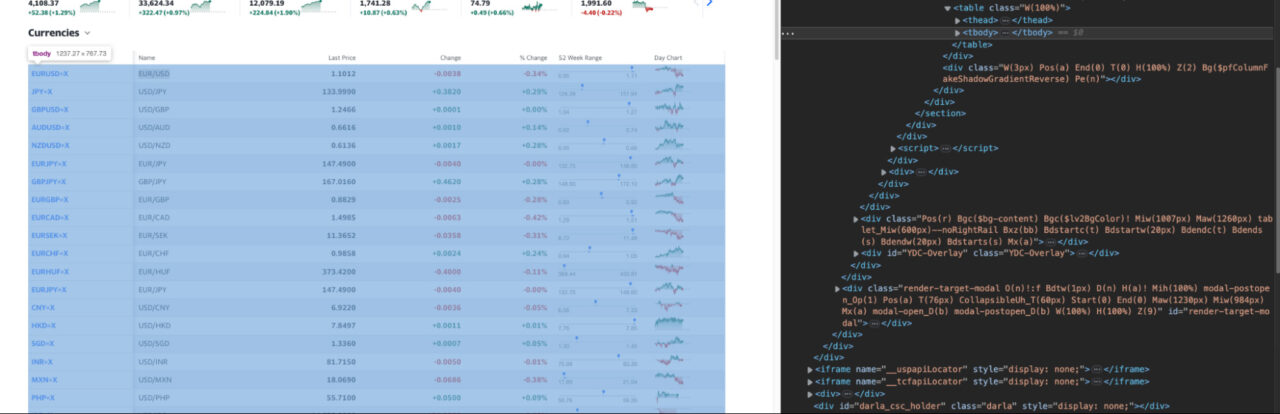
Weiter geht's. Jedes tr-Tag stellt eine Zeile in der Tabelle dar – die Sie visuell sehen können, indem Sie mit der Maus darüber fahren.
Jede Zelle wird durch ein td-Tag dargestellt…
… und alle Zeilen befinden sich innerhalb des tbody-Tags.
Das wissend. Ein guter Plan wäre, auf den Körper zu zielen und dann alle Zeilen in einer Variablen zu speichern. Dann können wir die Liste der Zeilen durchlaufen und den Namen, den letzten Preis, die Änderung und die prozentuale Änderung jeder Währung extrahieren.
Nachdem wir nun unseren Spielplan haben, programmieren wir unseren Scraper!
2. Starten des Forex-Datenextraktionsprojekts
Erstellen wir zunächst ein neues Verzeichnis für unser Projekt und unsere Python-Datei. Wir haben unsere forex_scraper.py genannt – sehr originell, oder?
Als nächstes importieren wir alle notwendigen Abhängigkeiten:
import requests
from bs4 import BeautifulSoup
import pandas as pd
Nachdem unsere Abhängigkeiten fertig sind, ist es an der Zeit, unsere Initialen zu senden get() Anfrage. Obwohl Yahoo Finance über viele öffentliche Daten verfügt, heißt das nicht, dass sie nicht versuchen werden, Ihre Skripte zu blockieren. Wenn Sie Ihre Anfrage direkt von Ihrem Computer aus senden, kann dies dazu führen, dass Ihre IP vorübergehend oder sogar dauerhaft gesperrt wird.
Um dieses Problem zu vermeiden, verwenden wir ScraperAPI, um alle gefundenen Anti-Scraping-Mechanismen zu umgehen und sicherzustellen, dass wir eine erfolgreiche Antwort vom Server erhalten. Machen Sie sich an dieser Stelle keine Gedanken über die Preise, denn der kostenlose Plan bietet Ihnen 5.000 API-Credits für die ersten 7 Tage und 1.000 API-Credits pro Monat.
Erstellen Sie einfach ein kostenloses ScraperAPI-Konto und kopieren Sie Ihren API-Schlüssel. Wir übergeben dann den Schlüssel und unsere Ziel-URL über eine Nutzlast, die als Parameter zum Endpunkt von ScraperAPI hinzugefügt wird:
Außerdem verwenden wir die country_code Parameter, um ScraperAPI anzuweisen, beim Senden unserer Anfragen immer US-Proxys zu verwenden.
Um eine Erfolgsquote von 99,99 % zu gewährleisten, nutzt ScraperAPI maschinelles Lernen und jahrelange statistische Analysen, um die beste Kombination aus IP und Headern auszuwählen und etwaige zusätzliche Komplexitäten zu bewältigen.
Da wir nichts weiter hinzuzufügen haben, senden wir die Anfrage und print() den Statuscode, um zu überprüfen, ob es funktioniert, indem Sie:
print(response.status_code)
Nachdem Sie das Skript ausgeführt haben, sollte in Ihrem Terminal eine 200 angezeigt werden.
3. Zugriff auf Daten aus der ersten Zelle
Wenn Sie dem folgen, gibt das Skript an dieser Stelle den gesamten Roh-HTML-Code zurück – Sie können ihn sehen, wenn Sie (response) anstelle des status_code ausgeben – wir müssen ihn also mit Beautiful Soup analysieren, um ihn in einen analysierten Code umzuwandeln Baum, der es uns ermöglicht, die verschiedenen Knoten zu durchlaufen und die Daten zu extrahieren.
Jetzt befinden sich alle Knoten in einem Suppenobjekt, auf das wir das verwenden können .find() Und .select() Methoden zur gezielten Ausrichtung auf bestimmte Elemente. Nach dem Plan wählen wir nun den Körper des Tisches aus, der dazwischen gewickelt wird
tags.
table = soup.find('tbody')
.find() gibt das erste gefundene Element zurück, und da es nur ein tbody-Element gibt, funktioniert es für uns einwandfrei.
Im Fall der Zeilen möchten wir, dass unser Skript eine Liste mit allen zurückgibt tr Elemente und nicht nur das erste, also werden wir es verwenden .select() – das eine Liste aller Elemente zurückgibt, die den von uns übergebenen Kriterien entsprechen – in unserer Tabellenvariablen.
all_currencies = table.select('tr')
Notiz: wir könnten auch das nutzen .find_all() Methode, aber wir wollen zeigen, wie man beide verwendet.
Nachdem wir nun unsere Zeilenliste haben, können wir jede Zelle durchlaufen und Daten daraus extrahieren. Das heißt, jede Zelle ist eine td Element, wie können wir unserem Scraper also mitteilen, aus welchen Zellen er die Daten extrahieren soll?
Wenn Sie die Struktur richtig verstanden haben, alle
has a series of
tags. So we can imagine each row like this:
Jedes Rechteck ist ein td Element, und die Liste beginnt bei 0. Theoretisch könnten Sie alle td-Tags innerhalb der Zeile als Ziel verwenden und dann jede Spalte anhand ihrer Position im Index auswählen.
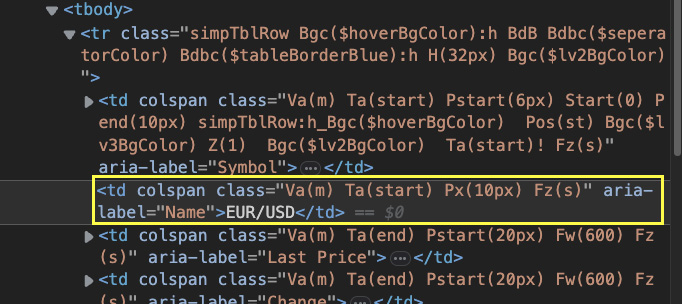
Zum Glück offenbart uns eine nähere Betrachtung der Elemente einen einfacheren Weg. Alle Elemente innerhalb der Zeilen haben ein aria-label Attribut mit einem sehr beschreibenden Wert.
Beispielsweise hat das Währungspaar den Wert „Name“ und der letzte Preis darunter den Wert „Letzter Preis“. Um den Namen jeder Währung anzusprechen, können wir eine Schleife wie diese erstellen:
for currency in all_currencies:
name = currency.find('td', attrs={'aria-label': 'Name'}).text
print(name)
Sie erhalten eine Liste mit 24 Währungen auf Ihrem Terminal ausgedruckt, was bedeutet, dass unser Skript bisher funktioniert!
4. Alle Daten zu einem Array hinzufügen
Die Ausrichtung auf die restlichen Datenpunkte erfolgt nach einem sehr ähnlichen Prozess, jedoch mit einigen geringfügigen Änderungen.
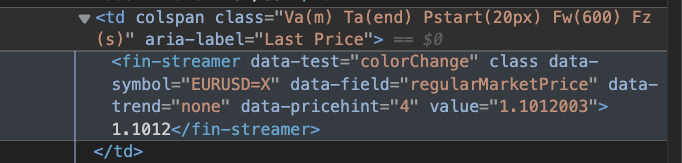
Im Gegensatz zum Währungsnamen befindet sich der Text der Zellen „Letzter Preis“ in einem anderen – seltsam aussehenden – Element innerhalb der Währung td.
Bei Verwendung des .find() Methode, es gab das Element zurück, aber wir konnten die Daten damit nicht extrahieren .text. Stattdessen haben wir die verwendet select_one() Methode, die eine etwas andere Syntax verwendet, um auf ein einzelnes Element abzuzielen, und es hat funktioniert:
Und schließlich mussten wir bei der prozentualen Änderung etwas kreativer werden, um das Ziel zu erreichen span Element, in dem der Text bereitgestellt wird, ohne dass eine Menge geschrieben werden muss .find() Methoden:
Notiz: Achten Sie auf die Unterschiede zwischen den find() Und select() Methoden, da sie Ihr Hauptwerkzeug zum einfachen Extrahieren von Daten mithilfe von CSS-Selektoren sind.
Da alle Daten von unserem Parser abgerufen werden, fügen wir vor der Nutzlast ein leeres Array hinzu ...
… und nutzen Sie die .append() Methode zum Formatieren und Speichern aller Daten in forex_data:
Dieses letzte Snippet wird in die for-Schleife eingefügt, nachdem das letzte Element extrahiert wurde. Im Grunde extrahiert unser Skript jedes Element und hängt es dann an das Array an, wobei jedes Element einen Namen hat und das Ganze ein einzelnes Element bildet.
Folgendes erhalten wir nach dem Drucken des Arrays:
Notiz: Wir haben einen JSON-Formatierer verwendet, um das Ergebnis visuell zu organisieren, da es in Ihrem Terminal ausgedruckt nicht so aussieht. Dennoch kommt es auf die Name:Wert-Organisation an.
5. Exportieren der gecrackten Forex-Finanzdaten in eine CSV-Datei
Hier wird sich unsere Initiative, die Daten in einem Array zu speichern, auszahlen! Da wir die Reihenfolge und alle Informationen bereits in forex_data haben, können wir einfach einen Datenrahmen mit Pandas erstellen:
df = pd.DataFrame(forex_data)
Die Namen werden zu Spalten und jeder Datenpunkt wird unter dem bereits angegebenen liegen.
Für die letzte Berührung verwenden wir die .to_csv() Methode zum Erstellen der Datei im Verzeichnis unseres Projekts:
df.to_csv('forex.csv', index=False)
Wenn Sie mitgemacht haben, sollte Ihr Projekt so aussehen:
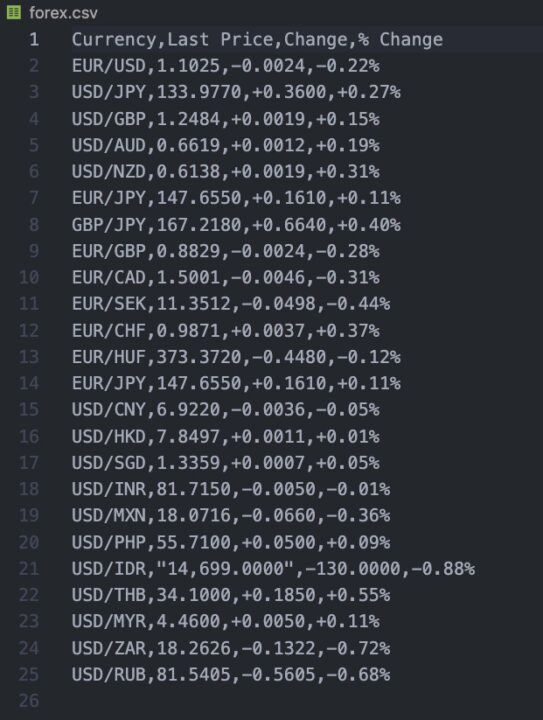
Nachdem Sie dieses Skript ausgeführt haben, finden Sie die folgende CSV-Datei:
Sammeln Sie Forex-Finanzdaten automatisch mit ScraperAPI
Herzlichen Glückwunsch, Sie haben Ihren ersten Forex-Scraper gebaut! Wir hoffen, dass Ihnen dieses Web-Scraping-Tutorial genauso viel Spaß gemacht hat wie uns das Schreiben. Natürlich ist das erst der Anfang.
Wenn Sie beide Male, als wir Ihnen die Ergebnisse angezeigt haben, aufmerksam gemacht haben, sind die Werte für jedes Währungspaar unterschiedlich. Das liegt daran, dass Yahoo Finance die Preise auf der Seite ständig aktualisiert, sodass Sie bei jeder Anfrage einen leicht unterschiedlichen Wert erhalten.
Mit anderen Worten: Der nächste Schritt auf diesem Weg besteht darin, einen Web-Scraping-Planer so einzurichten, dass das Skript einige Male am Tag oder in der Woche automatisch ausgeführt wird. Auf diese Weise können Sie mit der Erstellung historischer Daten beginnen, die Sie in Ihre Handelsalgorithmen einspeisen können.
Ihre Web-Scraping-Lösung bietet keine automatische Scraping-Funktion? Schauen Sie sich ScraperAPI an. Mit unserer DataPipeline-Lösung können Sie bis zu 10.000 URLs termingerecht erfassen und Benachrichtigungen erhalten, wenn die Aufgaben erledigt sind. Melden Sie sich hier bei ScraperAPI an, um es auszuprobieren.
Darüber hinaus können Sie diese Informationen auch vergleichen, indem Sie andere Forex-Datenquellen wie TradingView auswerten. Denken Sie daran: Je mehr Daten Sie haben, desto bessere Vorhersagen können Sie treffen. Beginnen Sie also jetzt mit der Erstellung.
Mein Name ist Kadek und ich bin ein Student aus Indonesien und studiere derzeit Informatik in Deutschland.
Dieser Blog dient als Plattform, auf der ich mein Wissen zu Themen wie Web Scraping, Screen Scraping, Web Data Mining, Web Harvesting, Web Data Extraction und Web Data Parsing teilen kann.