
Sind Sie es leid, Daten manuell von Websites zu extrahieren? Möchten Sie Zeit und Mühe sparen und gleichzeitig wertvolle Informationen sammeln? Dann sind Sie bei Web Scraping genau richtig! Diese leistungsstarke Technik nutzt automatisierte Skripte oder Webcrawler, um bestimmte Daten von Websites schnell und genau zu extrahieren.
In diesem Artikel werden die Besonderheiten des Web-Scrapings untersucht – einschließlich seiner Vorteile, Techniken, Tools, Anwendungsfälle und rechtlichen Überlegungen. Egal, ob Sie ein erfahrener Entwickler oder ein Neuling in den Bereichen Datenwissenschaft, Marketing, Finanzen, Investitionen usw. sind, dieser Leitfaden ist genau das Richtige für Sie. Lassen Sie uns eintauchen und entdecken, wie Web Scraping Ihre Arbeitsprozesse revolutionieren kann!
Was ist Web Scraping?
Web Scraping ist eine Technik zum Extrahieren von Daten von Websites mithilfe automatisierter Skripte, auch Webcrawler oder Spider genannt. Dabei wird der HTML-Code einer Website heruntergeladen und analysiert, um bestimmte Informationen wie Text, Bilder, Links usw. zu extrahieren. Die extrahierten Daten können dann zur weiteren Analyse oder Bearbeitung in einer Datenbank gespeichert werden. Einzelpersonen und ganze Unternehmen nutzen Web Scraping, um intelligentere Entscheidungen zu treffen.
Der Hauptvorteil von Web Scraping besteht in der Möglichkeit, große Datenmengen schnell und genau zu verarbeiten, indem der gesamte Prozess automatisiert wird und nur minimale menschliche Eingriffe Ihrerseits erforderlich sind. Darüber hinaus können Sie auf große Mengen öffentlich verfügbarer Informationen zugreifen, die auf andere Weise, beispielsweise durch den Kauf von Datensätzen, möglicherweise nur schwer oder kostspielig zu erhalten sind.
Da sich die meisten Websitebesitzer darüber hinaus nicht darüber im Klaren sind, dass ihre Websites gecrackt werden, gibt es keine rechtlichen Probleme im Zusammenhang mit dem Extrahieren öffentlich verfügbarer Daten von verschiedenen Websites im Internet, vorausgesetzt, sie befolgen alle geltenden Gesetze in ihrem Land/ihrer Region in Bezug auf Datenschutzrichtlinien und -bedingungen. Bedingungen usw.
Web-Scraping-Techniken
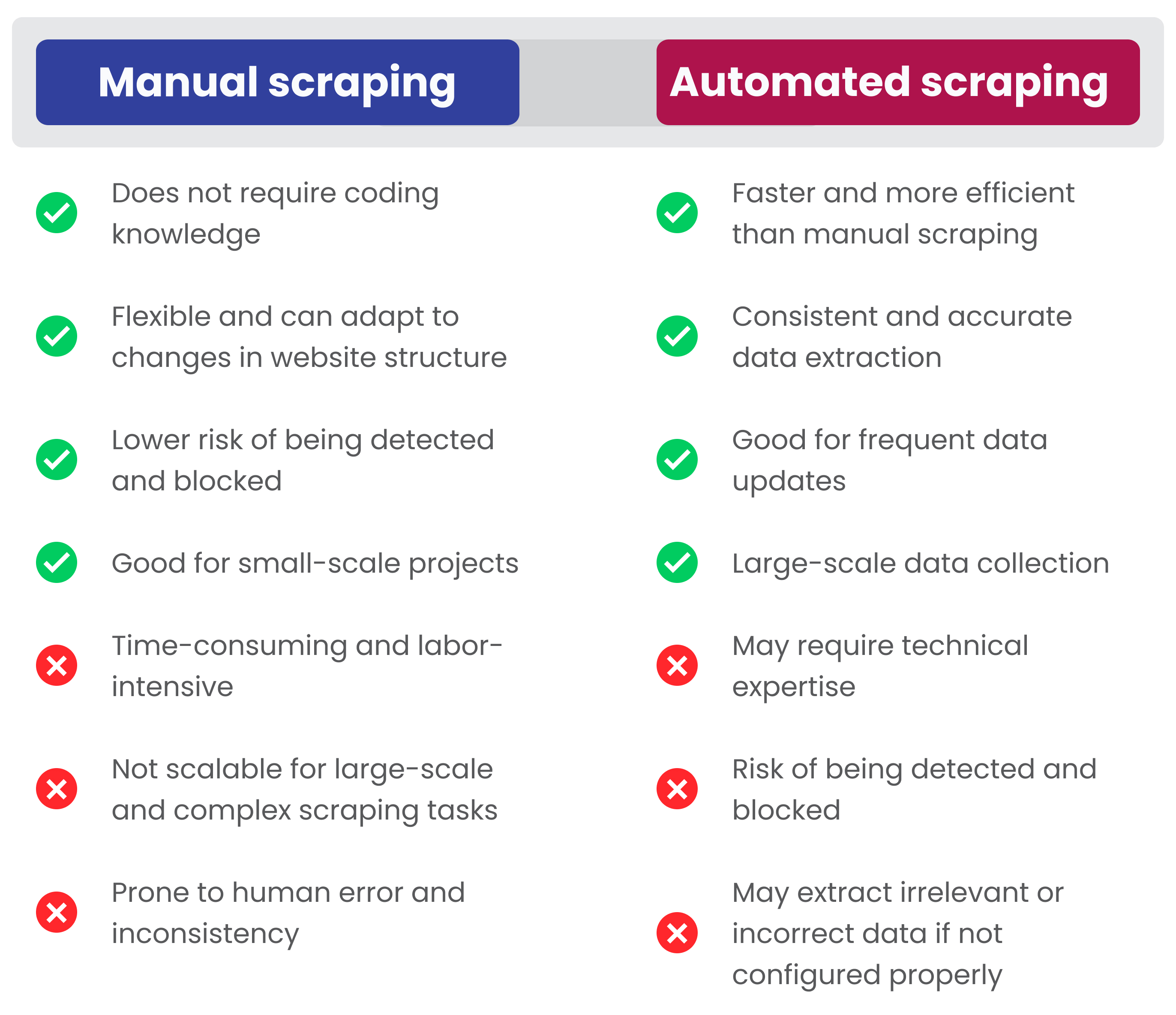
Wenn Sie Daten von einer Website extrahieren müssen, sind die beiden gängigsten Techniken manuelles und automatisches Web-Scraping.
- Beim manuellen Web Scraping wird der HTML-Code einer Website manuell auf bestimmte Elemente überprüft, die extrahiert werden können.
- Für das automatische Web-Scraping ist eine spezielle Software erforderlich, die automatisch durch Websites navigiert und dabei Informationen sammelt.
Beide Methoden haben je nach Art des Projekts ihre Vor- und Nachteile.
Manuelles Web Scraping
Beim manuellen Web Scraping handelt es sich um das manuelle Kopieren von Text oder anderen Inhalten von einer Website-Seite, anstatt ein automatisiertes Programm zu verwenden, das dies für Sie erledigt. Dies ist die einfachste Methode des Web-Scrapings, bei der Benutzer auswählen können, welche spezifischen Elemente sie von jeder besuchten Seite entfernen möchten. Wenn Sie beispielsweise nur ein paar Telefonnummern oder Adressen finden müssen, ist die manuelle Datenextraktion eine gute Möglichkeit, dies zu tun.
Diese Art der Extraktion erfordert keine Programmierkenntnisse, ist jedoch die langsamste und zeitaufwändigste Methode des Web Scrapings und birgt das Risiko menschlicher Fehler. Und menschliches Versagen kann Sie viel kosten.
Automatisiertes Web Scraping
Beim automatisierten Web-Scraping werden Softwareprogramme verwendet, die speziell dafür entwickelt wurden, Daten von Websites zu extrahieren, ohne dass nach der Einrichtung ein menschliches Eingreifen erforderlich ist. Diese Programme gehen auf gezielte Seiten innerhalb einer bestimmten Website oder auf Wunsch auf mehrere Websites und „scrapen“ alle dort gefundenen relevanten Informationen, bevor sie sie in einer praktischen Ausgabedatei zusammenfassen, die genau das enthält, was angefordert wurde, in der am besten verwendbaren Form (z. B. Google Sheets, JSON, XLSX, CSV, XML usw.). Ein Vorteil gegenüber den oben genannten manuellen Methoden besteht darin, dass durch die Automatisierung potenzielle Benutzerfehler vermieden und Prozesse erheblich beschleunigt werden – was viel Zeit spart!
Außerdem sind Ihnen möglicherweise nicht nur die Wörter Web Scraping, sondern auch Web Crawling, Data Mining und Screen Scraping begegnet. Eine unbekannte Person könnte denken, dass dies dasselbe ist. Aber hier erklären wir Ihnen, wie sie sich voneinander unterscheiden.
| Technik | Definition | Hauptzweck | Hauptmerkmale | Ausgabe |
|---|---|---|---|---|
| Web Scraping | Extrahieren von Daten von Websites mithilfe von Code oder Software | Extrahieren spezifischer Datenpunkte von Websites | Kann strukturierte und unstrukturierte Daten extrahieren | Strukturierte Daten in verschiedenen Formaten wie CSV, JSON oder Excel |
| Screen Scraping | Extrahieren von Daten aus einer visuellen Anzeigeausgabe | Extrahieren von Daten aus Altsystemen oder Nicht-Webanwendungen | Extrahiert Daten aus der visuellen Anzeige und kann verschiedene Dateiformate verarbeiten | Von der GUI extrahierte Daten |
| Web-Crawling | Automatisierter Prozess zum Sammeln von Webdaten durch das Folgen von Links | Indizieren und Sammeln von Daten von mehreren Websites | Kann Millionen von Webseiten crawlen und für Suchmaschinen verwendet werden | Unstrukturierte Daten wie HTML oder XML |
| Data Mining | Prozess der Analyse großer Datensätze, um Erkenntnisse und Wissen zu gewinnen | Daten analysieren, um Muster und Zusammenhänge zu erkennen | Kann mit strukturierten und unstrukturierten Daten arbeiten und mit komplexen Algorithmen umgehen | Aus großen Datensätzen gewonnene Erkenntnisse und Erkenntnisse |
Web Scraping vs. Data Mining
Der Hauptunterschied zwischen Web Scraping und Data Mining liegt in ihrem Zweck: Während Web Scraper bestimmte Arten unstrukturierter Inhalte von Websites zur weiteren Verarbeitung sammeln, konzentrieren sich Data Miner darauf, versteckte Muster in bereits vorhandenen Datensätzen mit verschiedenen Tools wie der Verarbeitung natürlicher Sprache (NLP) zu entdecken. , maschinelles Lernen (ML), künstliche Intelligenz (KI) usw. Da beide Prozesse außerdem unterschiedliche Fähigkeiten erfordern – Codierung für Web Scraping und Datenanalyse/Statistik für Data Mining – werden die beiden Aufgaben häufig von unterschiedlichen Fachleuten bearbeitet.
Web Scraping vs. Web Crawling
Wenn Sie kein technischer Fachmann sind, könnten die Wörter „Web-Crawling“ und „Web-Scraping“ so klingen, als ob sie dasselbe bedeuten würden. In Wirklichkeit handelt es sich um zwei sehr unterschiedliche Prozesse, die oft miteinander verwechselt werden.
Webcrawler, auch „Spider“ oder „Bots“ genannt, sind automatisierte Computerprogramme, die Algorithmen der künstlichen Intelligenz nutzen, um automatisch Informationen im World Wide Web zu entdecken und zu sammeln. Ein Crawler beginnt normalerweise mit einer Liste der zu besuchenden URLs, dem so genannten Seed-Set. Wenn der Crawler diese Websites besucht, erkennt er Links zu anderen Websites und fügt sie seiner Warteschlange hinzu. Der Crawler crawlt weiter, bis er alle Websites in seiner Warteschlange besucht hat oder eine vorab festgelegte Stoppbedingung erreicht.

Im Gegensatz zu Webcrawlern, die automatisch Links folgen, um den gesamten Inhalt einer Website zu finden, extrahieren Webscraper nur die spezifischen Daten, nach denen sie suchen sollen.
Sowohl Web-Crawling als auch Web-Scraping können zum Sammeln von Daten von Websites verwendet werden. Bei der Entscheidung, welches Tool in Ihrem Fall am besten geeignet ist, ist es wichtig, die Art der benötigten Daten und die Quelle dieser Daten zu berücksichtigen. Wenn Sie große Datenmengen aus mehreren Quellen benötigen, ist ein Webcrawler wahrscheinlich die beste Option. Wenn Sie jedoch nur Daten aus einigen wenigen spezifischen Quellen benötigen, wird ein Web-Scraper wahrscheinlich ausreichen.
Web Scraping vs. Screen Scraping
Web Scraping und Screen Scraping sind zwei Begriffe, die oft synonym verwendet werden; Sie haben jedoch leicht unterschiedliche Bedeutungen.
Screen Scraping ist eine Technik, die sich darauf konzentriert, visuelle UI-Elemente wie Textfelder oder Dropdowns aus Desktop-Anwendungen zu extrahieren – anstatt rohen HTML-Code einer Website zu sammeln – und sie dann in maschinenlesbare Formate wie CSV-Dateien umzuwandeln. Diese Methode wurde ursprünglich entwickelt, um Altsysteme in moderne Systeme umzuwandeln, indem ihre Benutzeroberflächen Schicht für Schicht entfernt werden, bevor sie um jeden Preis auf eine neue Systemplattform migriert werden, ohne dass es zu Unterbrechungen bei der Servicebereitstellung oder Ausfallzeiten kommt.
Bei der Auswahl eines Web-Scraping-Tools gibt es keine allgemeingültige Lösung; Jedes Projekt erfordert je nach Komplexität und Umfang unterschiedliche Funktionen. Sie sollten dies daher immer im Hinterkopf behalten, wenn Sie das richtige Tool für Ihre Anforderungen auswählen. Zu den häufigsten Typen gehören:
- Browsererweiterungen
- Installierbare Software
- Web-Scraping-API
- Cloudbasierte Scraper
- Selbstgebaute Schaber
- Robotische Prozessautomatisierung (RPA)
| Werkzeugtyp | Vorteile | Einschränkungen | Bester Anwendungsfall | Benutzerfreundlichkeit |
|---|---|---|---|---|
| Browsererweiterungen | Einfach zu bedienen, direkt in den Webbrowser integriert | Eingeschränkte Funktionen, erweiterte Funktionen können nicht ausgeführt werden | Kleine Datensammlung | ⭐️⭐️⭐️ |
| Installierbare Software | Erweiterte Funktionen wie rotierende IP-Adressen, gleichzeitige Datenerfassung und Planung | Erfordert Installation und Konfiguration, kann jedoch komplexer in der Verwendung sein | Datenextraktion aus mehreren Seiten | ⭐️⭐️ |
| Web-Scraping-API | Präzise Datenextraktion, erweiterte Funktionen wie JavaScript-Rendering und CAPTCHA-Vermeidung | Für die Implementierung und Verwendung ist möglicherweise technisches Fachwissen erforderlich | Erweiterte Datenextraktion | ⭐️⭐️ |
| Cloudbasierte Scraper | Skalierbarkeit, keine Hardware-Anforderungen, Datenerfassung in regelmäßigen Abständen ohne manuelle Eingabe möglich | Erfordert Cloud-Computing-Dienste, kann zusätzliche Kosten verursachen | Umfangreiche Datenerfassung | ⭐️⭐️ |
| Selbstgebaute Schaber | Anpassbar, keine Abhängigkeit von Drittanbieterdiensten, effizienter im Hinblick auf Zeit- und Kosteninvestitionen | Erfordert technisches Fachwissen für den Aufbau und die Wartung | Benutzerdefinierte Datenextraktion | ⭐️ |
| Robotische Prozessautomatisierung |
Kann komplexe Aufgaben automatisieren, ist skalierbar und kann mehrere Quellen gleichzeitig verarbeiten | Erfordert Entwicklungs- und Einrichtungszeit und funktioniert möglicherweise nicht mit allen Websites | Automatisierung komplexer Web-Scraping-Aufgaben | ⭐️⭐️ |
Browsererweiterungen
Bei diesen Web Scrapern handelt es sich um Erweiterungen, die in Ihren Browser wie Google Chrome oder Firefox eingebunden werden, um jede von Ihnen besuchte Webseite automatisch zu erfassen. Der Vorteil besteht darin, dass sie einfach zu bedienen und direkt in den Webbrowser integriert sind und sich gut für diejenigen eignen, die kleine Datenmengen sammeln möchten. Allerdings unterliegen sie Einschränkungen in ihrer Funktionsweise. Beispielsweise können erweiterte Funktionen, die über Ihren Browser hinausgehen, nicht mit browserbasierten Web-Scraper-Erweiterungen ausgeführt werden.
Installierbare Software
Web Scraper als installierte Software verfügen im Gegensatz zu Browsererweiterungen über viele zusätzliche Funktionen, wie z. B. das Rotieren der IP-Adresse für eine effizientere Datenerfassung, das gleichzeitige Sammeln von Informationen von mehreren Webseiten, die Ausführung im Hintergrund getrennt vom Browser, die Anzeige von Daten in verschiedenen Formaten, Durchsuchen der Datenbank, Planen von Scraping-Sitzungen und viele andere Funktionen.
Web-Scraping-API
Eine Web Scraping API ist ein automatisiertes Tool, das es der Software ermöglicht, Daten von Websites zu extrahieren und sie über einen API-Aufruf in eine andere Software zu integrieren. Diese Art von Tool umfasst häufig fortgeschrittene Techniken wie rotierende IP-Adressen, JavaScript-Rendering mithilfe eines Headless-Browsers zur Erfassung dynamischer Inhalte, CAPTCHA-Vermeidung und die Vermeidung blockierender Anti-Scraper. All diese Funktionen garantieren eine genaue Extraktion und vermeiden gleichzeitig eine Blockierung durch von Website-Eigentümern eingerichtete Anti-Scrapping-Maßnahmen.
Weiterlesen: Web Scraping vs. API: Was ist der beste Weg, Daten zu extrahieren?
Cloudbasierte Scraper
Cloudbasierte Scraper nutzen Cloud-Computing-Dienste wie Amazon Web Services (AWS) oder Microsoft Azure, um automatisierte Skripte auszuführen, die in regelmäßigen Abständen Daten von Websites sammeln, ohne dass zusätzliche manuelle Eingaben des Benutzers erforderlich sind, abgesehen von der anfänglichen Konfiguration des Scrapers selbst bei der Einrichtung. Diese Art von Lösung bietet Skalierbarkeit, da es keine Begrenzung gibt, wie viele Daten auf einmal erfasst werden können. Außerdem entfallen Hardware-Anforderungen, sodass Benutzer sich keine Sorgen machen müssen, dass der Speicherplatz aufgrund übermäßiger Nutzung/Scraping-Aktivitäten im Laufe der Zeit voll wird innerhalb einer Sitzung/Zeitspanne stattfinden).
Selbstgebaute Schaber
Für diejenigen mit technischen Kenntnissen ist die Erstellung eines eigenen benutzerdefinierten Scrapers mit Programmiersprachen wie Python oder JavaScript oft die effizienteste Lösung im Hinblick auf Zeit- und Kosteninvestitionen. Selbstgebaute Schaber erfordern im Vorfeld etwas mehr Aufwand, ermöglichen Ihnen aber, die Ergebnisse an Ihre spezifischen Bedürfnisse anzupassen, ohne auf die Dienste Dritter angewiesen zu sein. Beliebte Python-Bibliotheken, die zum Erstellen hausgemachter Scraper verwendet werden, sind Beautiful Soup, Scrapy, Selenium, urllib.request und lxml. Für JavaScript sind dies Cheerio, Axios, Puppeteer, NightmareJS und Request-Promise. Diese Bibliotheken erleichtern das Schreiben von Code, indem sie es Entwicklern ermöglichen, HTML-Dokumente schneller zu analysieren, als wenn sie Code von Grund auf nur in reiner Sprachform schreiben würden.
Wenn Sie mehr über Web Scraping mit Python und NodeJS erfahren möchten, können unsere Tutorials hilfreich sein.
Robotische Prozessautomatisierung (RPA)
Bei RPA werden Bots oder Roboterprozesse eingesetzt, die menschliche Interaktionen mit Websites nachahmen, indem sie komplexe Aufgaben auf der Grundlage vordefinierter Regeln automatisieren. RPA-Bots können Daten von Webseiten extrahieren, verarbeiten und analysieren und die Ergebnisse dann zur weiteren Verwendung in einer Datenbank oder einem anderen System speichern. Diese Tools erfreuen sich immer größerer Beliebtheit, da sie niedrige Eintrittsbarrieren, schnellere Entwicklungszyklen, robuste Leistungsskalierbarkeit, Zuverlässigkeit, Sicherheitskonformität und die Möglichkeit bieten, mehrere Quellen gleichzeitig zu verarbeiten.
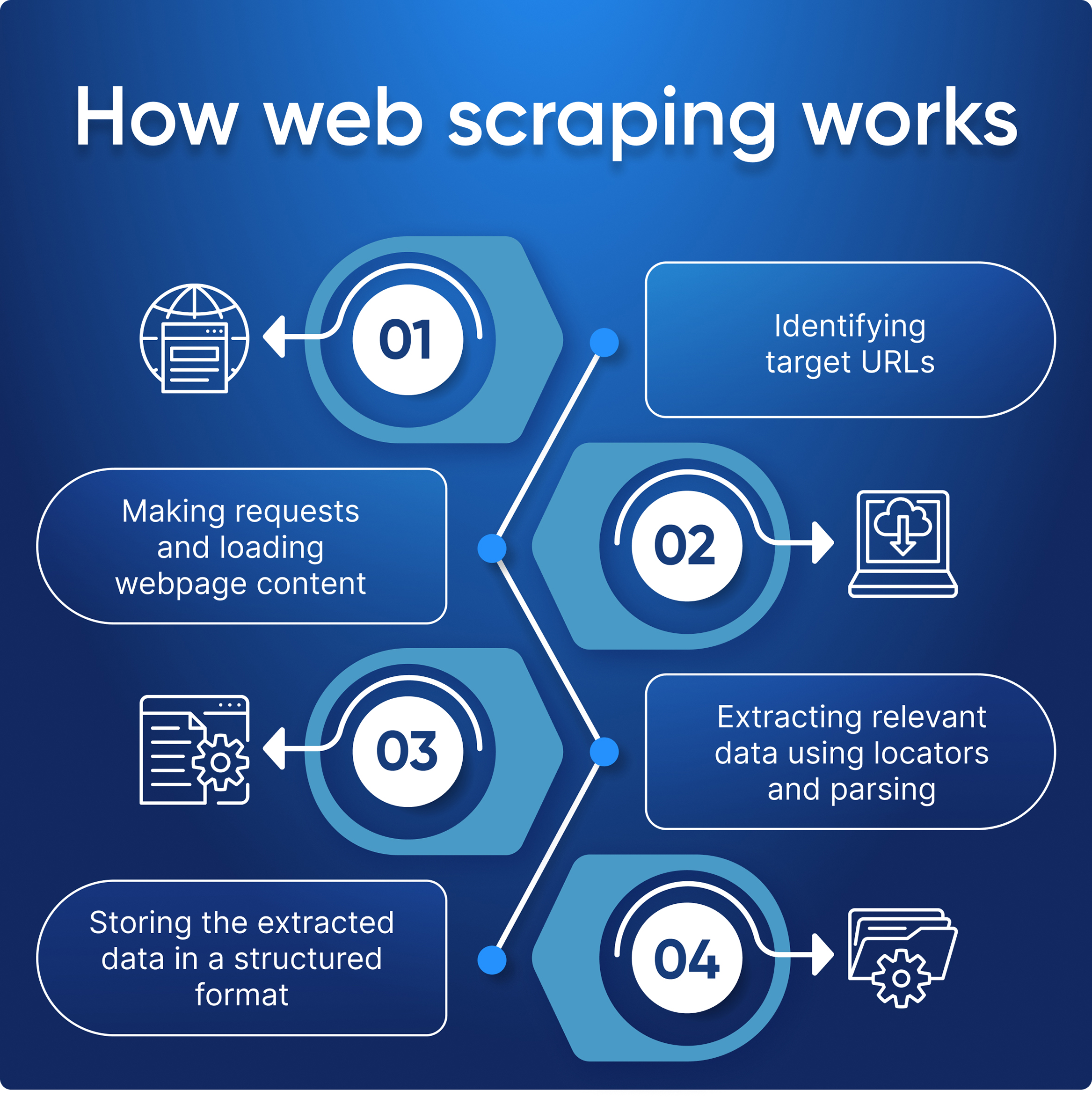
Wie funktionieren Web Scraper?
Das Ziel eines Web Scrapers besteht darin, die Struktur der Website zu verstehen, um alle benötigten Daten zu extrahieren. Die Effektivität Ihres Data Scraping hängt vor allem davon ab, dass Sie klar definieren, welche Elemente Sie extrahieren möchten, und ob Sie in der Lage sind, mit Fehlern umzugehen.
- Erstellen einer HTTP-Anfrage, um den HTML-Seiteninhalt von einer Ziel-URL abzurufen;
- Parsen des HTML-Codes, um den gewünschten Inhalt in ein strukturiertes Format wie CSV oder JSON zu extrahieren;
- Extrahierte Daten auf eine für Sie nützliche Weise speichern und anzeigen.
Zunächst erhält der Web Scraper eine bestimmte URL (oder mehrere), von der er Daten extrahieren kann. Anschließend lädt der Scraper den HTML-Code der entsprechenden Seite. Fortgeschrittenere Scraper verarbeiten Anfragen, führen JavaScript aus, laden externe Ressourcen und wenden CSS-Stile an. Sobald die Webseite geladen und analysiert wurde, erkennt und extrahiert der Scraper mithilfe von Softwaremethoden entweder absolut alle Daten von der Seite oder nach vorgegebenen Kriterien.
Am Ende gibt der Web Scraper alle gesammelten Daten in einem strukturierten Format aus – JSON, CSV, XML oder Excel-Tabellen.
Wofür wird Web Scraping verwendet?
Web Scraping ist ein leistungsstarkes Tool mit zahlreichen Anwendungsfällen. Abhängig von der Art der Daten, die Sie benötigen, und der Art Ihres Projekts kann Web Scraping auf unzählige Arten verwendet werden, um Informationen von Websites und anderen Online-Quellen zu sammeln.
Datenwissenschaftler könnten Web-Scraper einsetzen, um große Datensätze für maschinelles Lernen oder statistische Analysen zu sammeln. Webentwickler möchten möglicherweise Inhalte von Websites Dritter abrufen, um sie auf ihren eigenen Seiten anzuzeigen, während Vermarkter damit Preisdaten von Mitbewerbern zu Vergleichszwecken extrahieren könnten.
Egal in welcher Branche Sie tätig sind, die Chancen stehen gut, dass es eine Anwendung für Web Scraping gibt, die dabei hilft, Prozesse zu rationalisieren und das Leben einfacher zu machen.
Werfen wir einen Blick auf einige der häufigsten Anwendungsfälle für Web Scraping:
Marktforschung
Wenn es um Marktforschung geht, kann Web Scraping verwendet werden, um Informationen über die Produkte der Wettbewerber, Preisstrategien, Rezensionen oder andere relevante Inhalte zu sammeln, die Ihnen helfen können, Ihre Branche besser zu verstehen. Es hilft auch dabei, Informationen über potenzielle Kunden zu sammeln, indem E-Mails oder Telefonnummern für weitere Kontaktzwecke extrahiert werden. Durch die Automatisierung des Prozesses der gleichzeitigen Erfassung von Daten aus mehreren Quellen erleichtert diese Technologie es Unternehmen erheblich, aktuelle Einblicke in ihre Branche zu erhalten und fundierte Entscheidungen über ihre Strategie zu treffen.
Lead-Generierung
Unternehmen nutzen Web Scraper auch häufig als Teil ihres Lead-Generierungsprozesses. Durch die automatische Erfassung von Kontaktinformationen wie E-Mail-Adressen oder Telefonnummern von verschiedenen Websites können Unternehmen Listen potenzieller Leads erstellen, die sie mit Marketingkampagnen oder Vertriebsmaßnahmen effektiver als bisher ansprechen können. Dies erhöht die Effizienz und senkt gleichzeitig die mit der Lead-Akquise verbundenen Kosten, da keine Personalressourcen eingesetzt werden müssen, damit alles ordnungsgemäß funktioniert.
Preisintelligenz
Mit Web Scraping können Sie Produktbeschreibungen und Preisdaten aus dem gesamten Internet sammeln, um bessere E-Commerce-Entscheidungen zu treffen. So können Sie schnell auf allgemeine Preisänderungen reagieren und Ihre eigenen optimieren. Zum Beispiel, um die Konkurrenz in Schwellenländern zu übertreffen und gleichzeitig die Preise anderswo zu senken. Sie können Einkaufstrends überwachen, die Marketingstrategien der Wettbewerber analysieren und MAP und andere Preisvorschriften einhalten.
Finanzen und Investitionen
Finanz- und Wertpapierfirmen nutzen Daten, um Anlageentscheidungen zu treffen. Mit Web Scraping können Sie die aktuellen Finanzmarktbedingungen analysieren, aufkommende Trends verfolgen und deren Auswirkungen analysieren sowie Nachrichten überwachen, die sich auf Aktien und die Wirtschaft auswirken. Mit Scraping können Sie Unternehmensdokumente analysieren und die öffentliche Meinung zu Branchen überwachen.
Immobilien
Mit Web Scrapern können Immobilienmakler und Makler in nur wenigen Minuten problemlos detaillierte Angebote von mehreren Websites sammeln. Dies ermöglicht es ihnen, mit dem sich ständig verändernden Markt Schritt zu halten und über Wohnungstrends auf dem Laufenden zu bleiben, ohne stundenlang jede Website einzeln durchsuchen zu müssen. Darüber hinaus stellt es sicher, dass alle relevanten Immobilienangebote präzise und effizient erfasst werden, was es Maklern/Maklern erleichtert, wichtige Entscheidungen über ihre Investitionen oder Portfolios schneller als bisher zu treffen.
Weiterlesen: Vorteile von Web Scraping für Immobilien
Aktuelle Nachrichten und Inhalte
Mit Web Scraping können Sie aktuelle Trends im Zusammenhang mit globalen und regionalen Angelegenheiten oder Nachrichtenartikeln verfolgen, um zeitnah darauf zu reagieren. Sie können öffentliche Reaktionen auf Trends analysieren, Investitions- oder Kaufentscheidungen treffen, Wettbewerber beobachten und gezielte Kampagnen, beispielsweise politische, durchführen.
SEO-Überwachung
Web Scraping kann zur Überwachung des Website-Rankings auf Suchmaschinen-Ergebnisseiten (SERPs) verwendet werden. Dadurch können Unternehmen ihren Fortschritt in den organischen Suchergebnissen verfolgen und ihre Inhalte entsprechend optimieren. Darüber hinaus können Web Scraper verwendet werden, um SERPs nach Websites von Mitbewerbern zu durchsuchen, sodass Unternehmen über die Aktivitäten ihrer Konkurrenten auf dem Laufenden bleiben können. Mit unserer Google SERP API können Unternehmen diesen Prozess ganz einfach optimieren, ohne Zeit mit der Entwicklung benutzerdefinierter Crawler zu verbringen oder sich Gedanken über Ratenbeschränkungen und andere Probleme im Zusammenhang mit manuellen Crawling-Prozessen machen zu müssen.
Maschinelles Lernen
Web Scraping kann Daten über das Verhalten und Internet-Kommunikationsmuster von Menschen sammeln, um die Informationen später für maschinelle Lernprojekte, das Training von Vorhersagemodellen und die Optimierung von NLP-Modellen zu verwenden.
Analyse der Verbraucherstimmung
Social-Media-Scraping ist voll von unterschiedlichen Meinungen zu Produkten und sozialen Themen und ermöglicht es Ihnen, die Stimmung der Verbraucher zu verfolgen und die Werte und Wünsche der Zielgruppe zu verstehen, für die Sie Werbung machen und der Sie Ihr Produkt anbieten. Die gesammelten Daten sind sowohl bei der Entwicklung neuer Projekte als auch bei der Verbesserung bestehender Projekte nützlich.
Markenüberwachung
Eine starke Marke hebt Ihr Produkt von der Konkurrenz ab und weckt das Vertrauen der Verbraucher. Die Analyse von Markenerwähnungen gibt Aufschluss darüber, wie Sie derzeit wahrgenommen werden und wie Sie Ihren Kundenservice und Ihre Marketingstrategien anpassen können, um Ihren Ruf und Ihre Bekanntheit zu verbessern.
Ist Web-Scraping-Daten legal?
Web Scraping ist sowohl bei kleinen als auch bei großen Unternehmen allgegenwärtig und bereits Teil der Geschäftsmodelle vieler Unternehmen. Dennoch ist die damit verbundene Rechtmäßigkeit äußerst komplex. Web Scraping ist im Allgemeinen nirgendwo auf der Welt illegal, aber Probleme entstehen, wenn Menschen geistige Eigentumsrechte nicht respektieren und persönliche Daten und urheberrechtlich geschütztes Material sammeln. Wenn Sie Informationen sammeln, müssen Sie sicherstellen, dass Ihre Aktivitäten im Einklang mit dem Gesetz erfolgen.
Weiterlesen: Rechtliche und ethische Aspekte von Web Scraping
Fazit und Erkenntnisse
Zusammenfassend lässt sich sagen, dass Web Scraping eine leistungsstarke Technik ist, mit der Sie schnell und genau wertvolle Daten von Websites extrahieren können. Es bietet zahlreiche Vorteile in verschiedenen Branchen, darunter Marktforschung, Lead-Generierung, Preisinformationen, Finanz- und Investitionsanalysen, Immobilienanalysen und die Überwachung der Verbraucherstimmung in sozialen Medien.
Trotz der Vorteile ist jedoch zu bedenken, dass beim Einsatz dieser Technologie rechtliche Aspekte zu beachten sind. Stellen Sie stets sicher, dass Ihre Aktivitäten den Datenschutzrichtlinien und Geschäftsbedingungen der Website-Eigentümer entsprechen.
Insgesamt kann Web Scraping bei richtiger Anwendung einen erheblichen Mehrwert für jeden Geschäftsprozess bringen, indem es eine bessere Entscheidungsfindung auf der Grundlage präziser Erkenntnisse ermöglicht, die aus relevanten Datensätzen gewonnen werden, die durch automatisierte Prozesse gesammelt werden.
