
Das Extrahieren von Daten ist ein wesentlicher Bestandteil der Arbeit an neuen und innovativen Ideen. Aber wie erhält man große Datenmengen aus dem gesamten Internet, die viele Geschäftsprozesse verändern?
Gängige Methoden zum Abrufen von Daten aus dem Internet sind APIs und Web Scraping. In diesem Artikel erklären wir, wie diese beiden Lösungen funktionieren und ob es noch eine bessere Lösung für das Datenerfassungsproblem gibt.
Was ist Web Scraping?
Web Scraping ist eine Technik zum automatischen Extrahieren von Zieldaten aus dem Internet. Scraping hilft dabei, Rohdaten in Form von HTML-Code von Websites zu übernehmen und in ein verwendbares strukturiertes Format umzuwandeln. Es ist ein unschätzbar wertvolles Werkzeug für Projekte wie Marktforschung, Stimmungsanalyse, Wettbewerbsanalyse oder Datenaggregation.
Wir haben bereits einen ausführlichen Artikel darüber, was Web Scraping ist und wofür es verwendet wird. Für diejenigen, die tiefer in das Thema eintauchen möchten, haben wir auch Artikel über die Legalität von Web Scraping und seine Vor- und Nachteile. Dadurch erhalten Sie alle Informationen, die Sie benötigen, um eine fundierte Entscheidung darüber zu treffen, ob Sie diese Technik in Ihrem Geschäftsbetrieb einsetzen sollten.

Was ist API?
Bevor wir uns mit den Besonderheiten des API-Scraping befassen, ist es wichtig, das Konzept einer API selbst zu verstehen.
API steht für Application Programming Interface und fungiert als Vermittler, der es Websites und Software ermöglicht, Daten und Informationen zu kommunizieren und auszutauschen.
Um die API zu kontaktieren, müssen Sie ihr eine Anfrage senden. Der Client muss die URL und die HTTP-Methode bereitstellen, um die Anfrage korrekt zu verarbeiten. Abhängig von der Methode können Sie Header, Text und Anforderungsparameter hinzufügen. Anschließend verarbeitet die API die Anfrage und sendet die vom Webserver empfangene Antwort.
Endpunkte arbeiten in Verbindung mit API-Methoden. Endpunkte sind spezifische URLs, die die Anwendung verwendet, um mit Drittanbieterdiensten und ihren Benutzern zu kommunizieren.
Was ist API-Scraping?
Beim API-Scraping werden Daten aus einer API extrahiert, die den Zugriff auf Webanwendungen, Datenbanken und andere Onlinedienste ermöglicht. Im Gegensatz zum Extrahieren aus den visuellen Komponenten einer Website verwendet diese Methode einfache API-Aufrufe, um mit dem Backend eines Dienstes zu interagieren und so einen strukturierteren und zuverlässigeren Datenabruf zu gewährleisten.
APIs bieten direkten Zugriff auf bestimmte Datenteilmengen über dedizierte Endpunkte, sodass kein umfangreicher Rohcode oder eine HTML-Struktur durchwühlt werden muss.

Wie funktioniert API Scraping?
Das Sammeln von Daten über eine API umfasst normalerweise die folgenden Schritte:
- Erste Anfrage: Der Scraper oder Client initiiert eine Anfrage an den API-Server mit Einzelheiten zu den angeforderten Daten oder Aktionen.
- Authentifizierung: Um eine sichere Kommunikation zwischen Anforderer und Server zu gewährleisten, werden verschiedene Authentifizierungstechniken – beispielsweise ein API-Schlüssel – eingesetzt.
- Datenerfassung: Nach Erhalt der Anfrage verarbeitet der API-Server diese und gibt relevante Informationen in strukturierten Formaten wie JSON oder XML zurück.
- Datenmanipulation: Die erfassten Daten werden dann gemäß den Programmanforderungen für die beabsichtigte Anwendung gefiltert, geändert und formatiert.
Web Scraping vs. API: Was ist das Beste?
Mit Web Scraping haben Sie mehr Kontrolle darüber, wie viele Daten Sie sammeln möchten und wie oft Sie nach neuen Informationen suchen möchten. Dies ermöglicht eine größere Flexibilität im Vergleich zur Verwendung von APIs, die hinsichtlich der Datenerfassung und -häufigkeit möglicherweise eingeschränktere Optionen bieten.
Beide Ansätze können zum Sammeln von Daten von Websites verwendet werden. Welche sich am besten eignet, hängt oft von Ihren spezifischen Projektanforderungen ab. Mit Web Scraping können Sie Daten schnell extrahieren, da dafür nur grundlegende Programmierkenntnisse erforderlich sind, während der API-Zugriff aufgrund seiner gut definierten Konnektivitätsprotokolle den Vorteil hat, relativ schnelle Ergebnisse zu liefern.
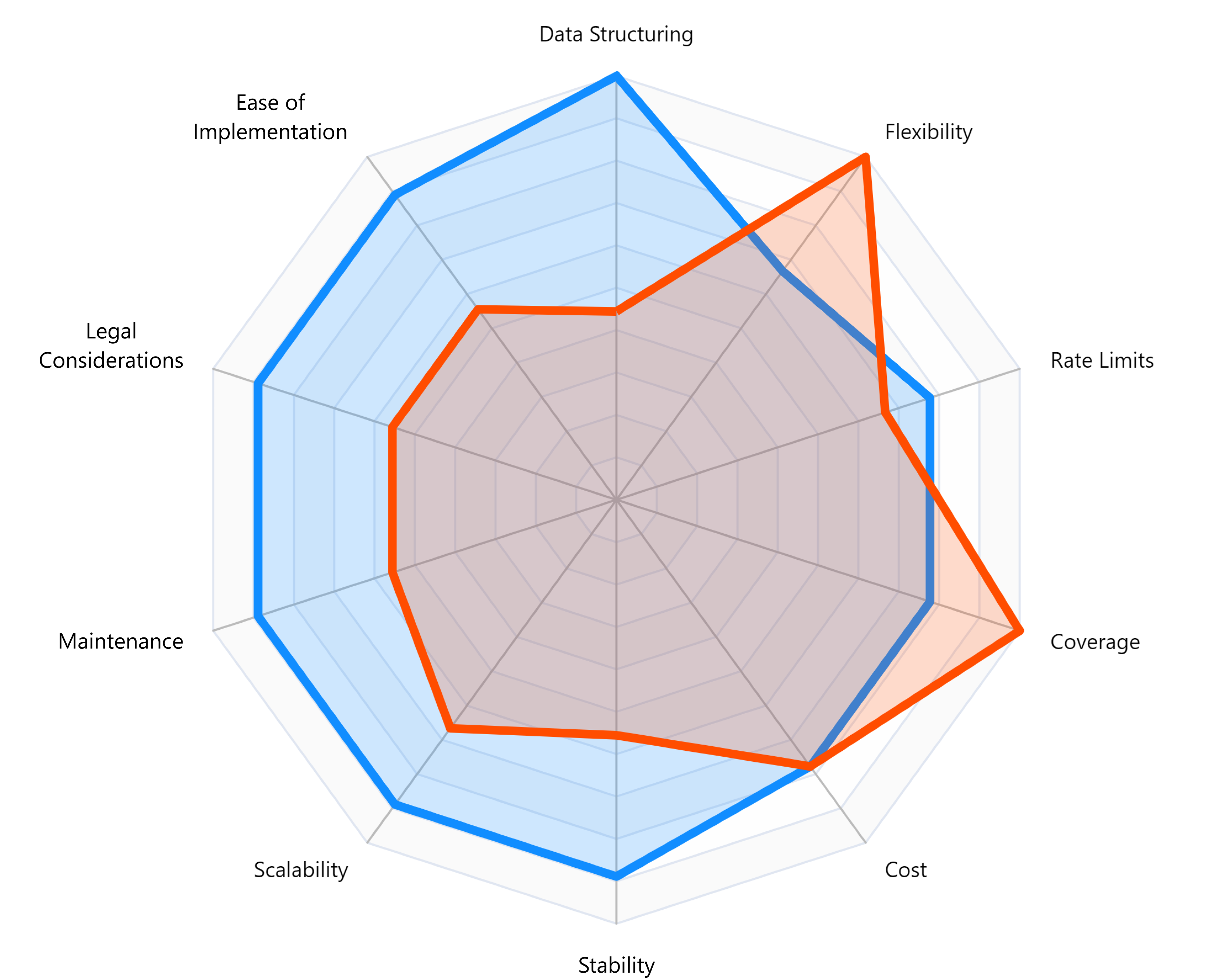
Zusammenfassend lässt sich sagen, dass ein API-Ansatz möglicherweise besser ist, wenn für eine Aufgabe eine schnelle Reaktionszeit oder ein genauer Abruf sich häufig ändernder Daten erforderlich ist. Wenn jedoch Flexibilität beim Zugriff auf verschiedene Arten von Website-Inhalten wichtiger ist als Geschwindigkeit, sollte ein Web Scraper ausreichen.
Gilt die Verwendung einer API als Web Scraping?
API-Scraping bietet eine andere Methode zum Abrufen von Daten aus dem Web als herkömmliches Web-Scraping. API-Aufrufe ermöglichen es Benutzern, direkt mit dem Backend eines Dienstes zu interagieren, um strukturierte Daten abzurufen, anstatt rohe HTML-Inhalte zu analysieren. Dieser Ansatz ist tendenziell stabiler und effizienter, da APIs für den programmgesteuerten Zugriff konzipiert sind und häufig Standardformate wie JSON oder XML zurückgeben.
Was die Rechtmäßigkeit betrifft, ist es wichtig zu beachten, dass API Scraping zwar eine allgemein akzeptierte Praxis ist, es jedoch dennoch Einschränkungen durch die Dienste geben kann, die regeln, wie Sie auf die Daten zugreifen und sie verwenden können. Das Überschreiten dieser Parameter – beispielsweise durch zu schnelle Anfragen – kann zu einer Drosselung oder völligen Blockierung der Plattform führen. Daher ist es wichtig, sicherzustellen, dass Sie die Nutzungsrichtlinien für alle APIs, mit denen Sie interagieren, verstehen und einhalten.
Was ist die Web Scraping API?
Eine Web-Scraping-API ist ein Tool, das über einen API-Aufruf Daten von Websites extrahiert und so eine nahtlose Integration in andere Software ermöglicht. Es umgeht Herausforderungen wie JavaScript-Rendering, CAPTCHAs und Blöcke und bietet strukturierte, typischerweise JSON-formatierte Daten.
Sie müssen keine Scraping-Anwendung von Grund auf erstellen und sich um Proxys, Infrastrukturwartung, Skalierung usw. kümmern. Es reicht aus, eine Anfrage über die bereitgestellte API zu stellen und den Inhalt der benötigten Webseite abzurufen. Bei Bedarf können Sie in einer Anfrage optional Land und Typ des Proxys, benutzerdefinierte Header, Cookies und Wartezeit senden und sogar JavaScript in der Anfrage ausführen.
Mit anderen Worten: Die Web-Scraping-API verbindet die vom Dienstanbieter entwickelte Datenextraktionssoftware mit den Websites, die Sie scrapen müssen.
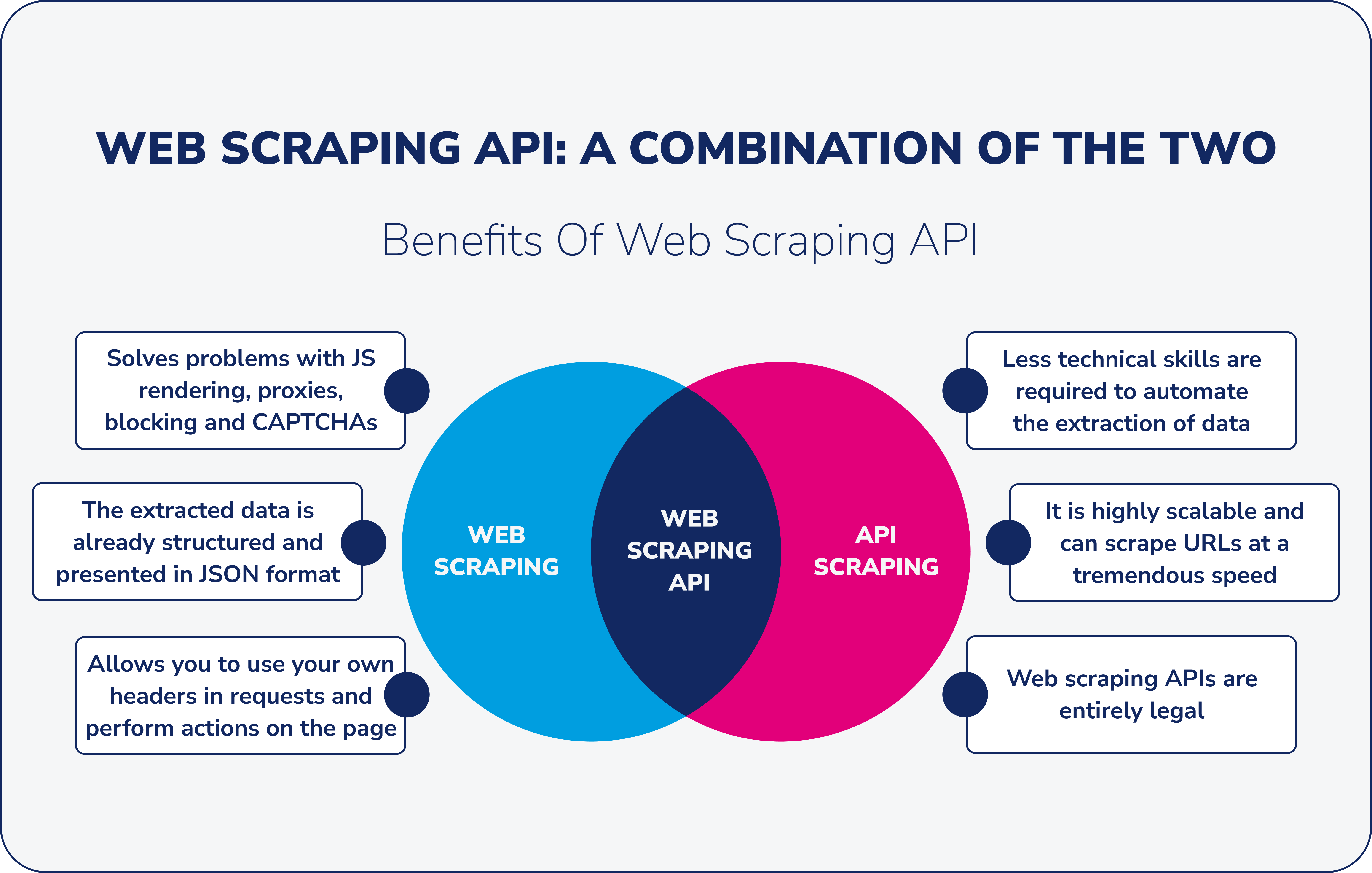
Es gibt zwei Haupttypen von Web-Scraping-APIs:
- Für allgemeine Zwecke, wenn Dienste mit beliebigen Webdaten arbeiten;
- Nischenspezifisch konzentriert sich auf bestimmte Arten von Daten oder Quellen und eignet sich besser für bestimmte Websites, Webseiten, Anwendungen und andere Dienste, beispielsweise Google SERP API oder Google Maps API.
Wofür wird die Web Scraping API verwendet?
Die Web-Scraping-API wird für verschiedene Zwecke wie Analyse, Lead-Generierung, Stimmungsanalyse, Marktforschung und Content-Marketing für ein besseres Ranking in Suchmaschinen verwendet. Es kann auch spezifische Daten von jeder Website oder jedem Blog extrahieren.
Unternehmen nutzen dieses Tool, wenn in der Regel keine Zeit, keine Spezialisten oder kein Budget vorhanden ist, um eine eigene Scraping-Lösung zu entwickeln, die unterstützt und gewartet werden muss.
Vorteile der Verwendung einer API für Web Scraping
Die Web-Scraping-API bietet im Vergleich zum direkten Web-Scraping einen effizienteren Datenextraktionsprozess. Während beide Methoden darauf abzielen, Daten aus dem Web abzurufen, reduziert die Verwendung einer API von Natur aus viele der Herausforderungen, die mit der herkömmlichen Scraping-Methode verbunden sind. Es fungiert als Brücke und stellt sicher, dass die Datenextraktion nicht nur effizient, sondern auch zuverlässig ist. Diese Zuverlässigkeit ist besonders bei dynamischen Websites oder Websites mit komplexen Strukturen von entscheidender Bedeutung.
Über diese grundlegenden Vorteile hinaus bietet die Wahl einer Web-Scraping-API gegenüber dem direkten Ansatz mehrere spezifische Vorteile. Lassen Sie uns genauer darauf eingehen:
- Löst Probleme mit JS-Rendering, Proxys, Blockierungen und CAPTCHAs.
- Die extrahierten Daten liegen bereits strukturiert vor und werden in der Regel im JSON-Format dargestellt.
- Mit der Web-Scraping-API können Sie auf einfache Weise Ihre eigenen benutzerdefinierten Header (Benutzeragenten, Cookies usw.) verwenden, wenn Sie Anfragen an eine Website stellen.
- Es kann von jedem verwendet werden, der die mit dem Scraping von Inhalten aus dem Web verbundenen Aufgaben autonom automatisieren möchte.
- Die meisten Web-Scraping-API-Dienste sind skalierbar, was bedeutet, dass sie URLs mit enormer Geschwindigkeit scannen können, oft Tausende von Seiten pro Sekunde scannen und täglich Daten abrufen.
- Web-Scraping-APIs sind völlig legal. Es ist jedoch besser, die Website-Eigentümer zu respektieren und Websites nicht zu schnell zu löschen, da Websites möglicherweise nicht für eine große Anzahl von Anfragen konzipiert sind.
Obwohl die Vorteile der Verwendung von APIs für Web Scraping klar sind, ist es wichtig zu sehen, wie sie im Vergleich zu anderen Techniken abschneiden. Lassen Sie uns in einen Vergleich der drei Methoden eintauchen, die wir in diesem Artikel besprochen haben.
| Kriterien | Direktes Web Scraping | API-Scraping | Web-Scraping-API |
|---|---|---|---|
| Stabilität | Mäßig: Hängt von Änderungen der Site-Struktur ab. | Hoch: APIs sind normalerweise stabil. | Hoch: Kombiniert die Stabilität von APIs mit Extraktionsfunktionen. |
| Geschwindigkeit | Variiert: Kann langsam sein, da das Laden ganzer Seiten erforderlich ist. | Schnell: Direkter Datenzugriff ohne Laden visueller Inhalte. | Schnell: Optimiert für die Datenextraktion mit Blick auf Geschwindigkeit. |
| Technische Schwierigkeit | Hoch: Erfordert das Parsen von HTML, die Verarbeitung dynamischer Inhalte usw. | Mäßig: Erfordert Kenntnisse über API-Endpunkte und -Antworten. | Moderat: Vereinfacht die Herausforderungen beider Methoden. |
| Kosten | Variiert: Proxys, CAPTCHA-Löser und Infrastruktur können zusätzliche Kosten verursachen. | Variiert: Viele APIs haben Ratenbegrenzungen oder kostenpflichtige Stufen. | Beides ist mit Kosten verbunden, bietet jedoch häufig skalierbare Lösungen. |
| Datenqualität | Kann chaotisch sein: Die Daten müssen möglicherweise umfassend bereinigt werden. | Hoch: Strukturierte Daten, häufig in JSON. | Hoch: Bietet strukturierte Daten, optimiert für Benutzerfreundlichkeit. |
| Juristische Folgen | Riskant: Nicht alle Websites erlauben Scraping. | Moderat: Beachten Sie die Nutzungsbedingungen und -beschränkungen der API. | Moderat: Kombiniert die rechtlichen Überlegungen beider Methoden. |
| Wann zu verwenden | Wenn keine API verfügbar ist oder bestimmte Daten benötigt werden. | Wenn eine Site eine öffentliche API mit den benötigten Daten anbietet. | Wenn es keine öffentliche API gibt und direktes Web-Scraping durch Herausforderungen wie CAPTCHAs, Blöcke und JavaScript-Rendering erschwert wird. |
| Skalierbarkeit | Moderat: Kann bei großen Volumina ressourcenintensiv sein. | Hoch: APIs sind für die Verarbeitung mehrerer Anfragen konzipiert. | Hoch: Entwickelt für Großbetriebe und mehrere Standorte. |
| Wartung | Hoch: Aufgrund von Site-Änderungen können häufige Aktualisierungen erforderlich sein. | Moderat: APIs können sich ändern, normalerweise jedoch mit Vorankündigung. | Moderat: Gleicht den Wartungsbedarf beider Methoden aus. |
| Flexibilität | Mäßig: Kann angepasst werden, erfordert aber Aufwand. | Moderat: Beschränkt auf die von der API bereitgestellten Daten. | Hoch: Kombiniert die Flexibilität des Scrapings mit strukturierten Daten von APIs. |
| Einfache Integration | Moderat: Erfordert Datenbereinigung und -strukturierung. | Hoch: Strukturierte Daten erleichtern die Integration. | Hoch: Stellt strukturierte Daten bereit für die Integration. |
| Zuverlässigkeit | Variiert: Abhängig von Website-Strukturen und Anti-Scraping-Maßnahmen. | Hoch: APIs sind normalerweise zuverlässig. | Hoch: Optimiert für zuverlässigen Datenabruf. |
| Abdeckung | Hoch: Kann auf alle sichtbaren Inhalte einer Seite zugreifen. | Moderat: Beschränkt auf die von der API bereitgestellten Daten. | Hoch: Umfassender Datenzugriff durch Kombination beider Methoden. |
| Echtzeitfähigkeit | Niedrig: Erfordert das Laden der gesamten Seite und mögliche Verzögerungen. | Hoch: Der direkte Datenzugriff ermöglicht den Abruf nahezu in Echtzeit. | Hoch: Optimiert für schnelle Datenextraktion und Echtzeitfähigkeiten. |
Wie funktioniert die Web Scraping API?
-
Um Daten zu sammeln, verwenden Sie einfach den Basis-API-Endpunkt und fügen Sie die URL, die Sie scannen möchten, als Body-Parameter und Ihren API-Schlüssel als Header hinzu.
Es gibt auch einige optionale Parameter, die Sie auswählen können. Dazu gehören benutzerdefinierte Titel, die Verwendung rotierender Proxys, deren Typ und Land, das Blockieren von Bildern und CSS, Zeitüberschreitungen, Browserfenstergrößen und JS-Szenarien wie das Ausfüllen eines Formulars oder das Klicken auf eine Schaltfläche.
-
Senden Sie die extrahierten Daten an Ihre eigenen Tools zur weiteren HTML-Verarbeitung, beispielsweise zum Parsen mit regulären Ausdrücken und zum Erhalten spezifischer Daten in strukturierter Form.
Mit unserem Service können Sie Extraktionsregeln verwenden, um nur die Daten zu erhalten, die Sie im JSON-Format benötigen, ohne die Rohdaten speichern zu müssen.
-
Streamen Sie Daten in Ihre Datenbank. Sie können Ihre eigenen Softwaretools oder Integrationsplattformen wie Zapier oder Make verwenden. Im Artikel über Web Scraping mit Zapier haben wir ausführlicher darüber geschrieben.
So wählen Sie die beste Web-Scraping-API aus
Die Auswahl der richtigen Web-Scraping-API für Ihre spezifischen Anforderungen kann ein verwirrender Prozess sein. Daher sollten Sie bei der Auswahl eines Dienstes zunächst über Folgendes nachdenken:
-
Die Preisstruktur für ein optimiertes Instrument sollte transparent sein und etwaige versteckte Kosten sollten nicht zu einem späteren Zeitpunkt auftauchen. Jedes Detail sollte in der Preisstruktur klar dargelegt werden. Achten Sie also auf den Preisplan und die Kosten pro Anfrage über die Data-Scraping-API und schätzen Sie ab, von wie vielen Seiten Sie Daten abrufen müssen.
-
Achten Sie bei der Auswahl eines Dienstes auf die Geschwindigkeit der Datenerfassung. Denn wer Tausende oder Hunderttausende Daten sammeln muss, kann viel Zeit verlieren, wenn er sich an den falschen Anbieter wendet.
-
Einige Standorte verfügen über Anti-Scraping-Maßnahmen. Wenn Sie bei der Auswahl eines Tools befürchten, dass keine Daten erfasst werden können, achten Sie darauf, welche Funktionen der Dienst bietet und wie er Probleme durch Umgehung der Blockierung löst.
-
Beim Ausführen des Web-Scraping-API-Tools können Probleme auftreten und Sie benötigen möglicherweise Hilfe bei der Lösung des Problems. Hier lohnt es sich, darauf zu achten, ob der Dienst Kundensupport bietet, denn so müssen Sie sich keine Sorgen machen, dass etwas schief geht, und Sie erhalten eine Lösung für Ihr Problem.
-
Es lohnt sich darauf zu achten, ob der Dienst eine detaillierte Dokumentation bereitstellt. In einer solchen Dokumentation sollten alle Servicefunktionen und die Schritte beschrieben werden, die zur Nutzung dieser Funktionen erforderlich sind. Die bereitgestellte Dokumentation sollte aktuell, klar strukturiert und für jedermann verständlich sein.
-
Für das Scraping verschiedener Websites sind möglicherweise unterschiedliche Arten von Proxys erforderlich. Achten Sie daher bei der Auswahl eines Dienstes auf die Möglichkeit, Proxy-Typen (Rechenzentrum und Privathaushalt) und Geolokalisierungseinstellungen auszuwählen.
-
Privat-Proxys verwenden echte IP-Adressen, die an echte physische Geräte gebunden sind. Durch die Verwendung von Wohn-Proxys kann tatsächliches menschliches Verhalten nachgebildet werden.
-
Rechenzentrums-Proxys stammen typischerweise aus Rechenzentren und Cloud-Hosting-Diensten und werden von vielen gleichzeitig genutzt. ISPs listen solche Proxys nicht auf und es können bestimmte Sicherheitsvorkehrungen für IP-Adressen gelten.
-
Abschließende Gedanken
Die Bedeutung der effizienten Extraktion von Webdaten kann nicht genug betont werden. Während sowohl Web Scraping als auch API Scraping ihre einzigartigen Vorteile bieten, stellt das Aufkommen von Web Scraping APIs eine harmonische Mischung beider Methoden dar. Diese APIs optimieren nicht nur den Datenextraktionsprozess, sondern umgehen auch viele der Herausforderungen, die mit herkömmlichem Scraping verbunden sind.
Angesichts der Agilität, Zuverlässigkeit und des umfassenden Datenzugriffs, die sie bieten, erweisen sich Web-Scraping-APIs als die beste Wahl für Unternehmen und Entwickler. Wenn Sie sich in den Bereich der Datenextraktion wagen, ist es wichtig, Ihre Wahl auf Ihre spezifischen Bedürfnisse zuzuschneiden. Wenn Sie jedoch nach einer robusten, vielseitigen und effizienten Lösung suchen, ist eine Web-Scraping-API möglicherweise die beste Wahl.
