
Durch die ständige Datenerfassung bleiben Sie über laufende Änderungen auf dem Laufenden und können fundierte, zeitnahe Entscheidungen treffen. Als eine der beliebtesten Suchmaschinen kann Google aktuelle Informationen und die relevantesten Daten anbieten. Ob Sie nach Hotels oder Immobilienagenturen suchen, Google liefert relevante Daten.
Es gibt viele Möglichkeiten, Daten zu scrapen: von der manuellen Datenerfassung über die Bestellung eines Datenpakets auf Marktplätzen bis hin zur Verwendung von Web-Scraping-APIs und der Erstellung benutzerdefinierter Scraper.
Was können wir von Google entfernen?
Google verfügt über viele Dienste, in denen Sie die benötigten Informationen finden können. Es gibt die Suchmaschinen-Ergebnisseite (SERP), Karten, Bilder, Nachrichten und mehr. Durch das Scrapen von Google können Sie Ihr eigenes Ranking und das Ihrer Konkurrenten auf der Google-Suchergebnisseite verfolgen. Sie können Lead-Informationen von Google Maps sammeln oder für verschiedene Zwecke verwenden.
Suchergebnisse
Eine der am häufigsten nachgefragten Aufgaben ist das Extrahieren von Informationen aus Google SERP, einschließlich Titeln, URLs, Beschreibungen und Snippets. Das Scraping von Google SERP wäre beispielsweise eine gute Lösung, wenn Sie eine Liste der in einem bestimmten Bereich tätigen Ressourcen oder Dienstleister zusammenstellen müssen.
Google Maps
Das Scraping von Google Maps ist das zweite Scraping-Ziel. Mit Scraping-Karten können Sie schnell Informationen über Unternehmen in einem bestimmten Gebiet sammeln und deren Kontaktinformationen, Rezensionen und Bewertungen sammeln.
Google Nachrichten
Nachrichtenaggregatoren durchsuchen normalerweise Google News, um aktuelle Ereignisse zu sammeln. Google News bietet Zugriff auf Nachrichtenartikel, Schlagzeilen und Veröffentlichungsdetails, und Scraping kann Ihnen bei der Automatisierung der Datenbeschaffung helfen.
Andere Google-Dienste
Neben den zuvor genannten bietet Google noch weitere Dienste an, beispielsweise Google Bilder und Google Shopping. Sie können auch gescrapt werden, obwohl die von ihnen bereitgestellten Informationen für Web-Scraping-Zwecke möglicherweise weniger interessant sind.
Warum sollten wir Google streichen?
Es gibt verschiedene Gründe, warum Menschen und Unternehmen Google Data Scraping nutzen können. Forscher können beispielsweise mit Google Scraping auf eine riesige Datenmenge für akademische Forschung und Analyse zugreifen. Ebenso können Unternehmen die resultierenden Daten für Marktforschung, Wettbewerbsanalysen oder die Gewinnung potenzieller Kunden nutzen.
Darüber hinaus wird Web Scraping auch für SEO-Spezialisten hilfreich sein. Mit den gesammelten Daten können sie Suchmaschinenrankings und -trends besser analysieren. Und Content-Ersteller können sogar Google Scraping nutzen, um Informationen zu sammeln und wertvolle Inhalte zu erstellen.
So kratzen Sie Google-Daten
Wie bereits erwähnt, gibt es mehrere Möglichkeiten, an die erforderlichen Daten zu gelangen. Wir werden uns nicht mit der manuellen Datenerfassung oder dem Kauf eines vorgefertigten Datensatzes befassen. Vielmehr möchten wir gerne die Beschaffung der gewünschten Daten selbst besprechen. Sie haben hier also zwei Möglichkeiten:
- Verwenden Sie spezielle Scraping-Tools wie Programme, No-Code-Scraper und Plug-Ins.
- Erstellen Sie Ihren Schaber. Hier können Sie es von Grund auf erstellen und Herausforderungen wie das Umgehen von Blöcken, das Lösen von Captchas, JS-Rendering, die Verwendung von Proxys und mehr lösen. Alternativ können Sie eine API verwenden, um den Prozess zu automatisieren und diese Probleme mit einer einzigen Lösung zu lösen.
Schauen wir uns jede dieser Optionen genauer an.
Verwendung von Google Scraper ohne Code
Der einfachste Weg, Daten zu erhalten, ist die Verwendung von Google Maps oder Google SERP No-Code-Scrapern. Sie benötigen hierfür keine Programmierkenntnisse oder -fähigkeiten. Um Daten von Google SERP oder Maps zu erhalten, melden Sie sich auf unserer Website an und öffnen Sie den erforderlichen No-Code-Scraper. Um beispielsweise den No-Code-Scraper von Google Maps zu verwenden, füllen Sie einfach die erforderlichen Felder aus und klicken Sie auf die Schaltfläche „Scraper ausführen“.
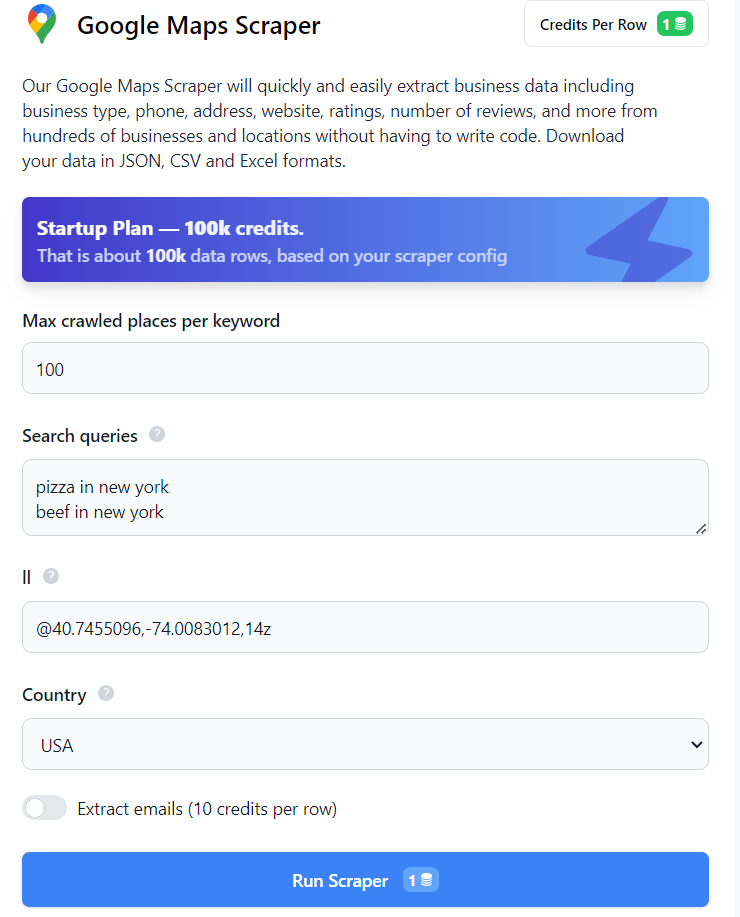
Anschließend können Sie die Daten im gewünschten Format herunterladen. Auf die gleiche Weise können Sie Daten von Google SERP abrufen. Sie können auch zusätzliche Daten von Google-Diensten abrufen, indem Sie Tools wie Google Trends oder den No-Code-Scraper von Google Reviews verwenden.
Erstellen Sie Ihr eigenes Google Web-Scraping-Tool
Die zweite Option erfordert Programmierkenntnisse, ermöglicht Ihnen aber die Erstellung eines flexiblen Tools, das Ihren Anforderungen entspricht. Um Ihren Scraper zu erstellen, können Sie eine der gängigen Programmiersprachen wie NodeJS, Python oder R verwenden.
NodeJS bietet im Vergleich zu anderen Programmiersprachen mehrere Vorteile. Es verfügt über eine große Auswahl an NPM-Paketen, mit denen Sie jede Aufgabe lösen können, einschließlich Web Scraping. Darüber hinaus eignet sich NodeJS gut für den Umgang mit dynamisch generierten Seiten wie denen von Google.
Allerdings hat dieser Ansatz auch seine Nachteile. Wenn Sie beispielsweise häufig eine Website scannen, können Ihre Aktionen als verdächtig angesehen werden und der Dienst kann Ihnen anbieten, das CAPTCHA zu lösen oder sogar Ihre IP-Adresse zu sperren. In diesem Fall müssen Sie häufig Ihre IP über einen Proxy ändern.
Bei der Entwicklung Ihres Schabers ist es wichtig, diese potenziellen Herausforderungen zu berücksichtigen, um ein effektives Werkzeug zu schaffen.
Vorbereitung zum Schaben
Bevor Sie mit dem Web Scraping beginnen, müssen unbedingt die notwendigen Vorbereitungen getroffen werden. Beginnen wir mit der Einrichtung der Umgebung, der Installation der erforderlichen npm-Pakete und der Untersuchung der Seiten, die wir durchsuchen möchten.
Umgebung installieren
NodeJS ist eine Shell, die es Ihnen ermöglicht, JavaScript außerhalb eines Webbrowsers auszuführen und zu verarbeiten. Der Hauptvorteil von NodeJS besteht darin, dass es eine asynchrone Architektur in einem einzelnen Thread implementiert, sodass Ihre Anwendungen schnell ausgeführt werden.
Um mit dem Schreiben eines Scrapers mit NodeJS zu beginnen, installieren wir ihn und aktualisieren das NPM. Laden Sie die neueste stabile Version von NodeJS von der offiziellen Website herunter und befolgen Sie die Anweisungen zur Installation. Um sicherzustellen, dass alles erfolgreich installiert wurde, können Sie den folgenden Befehl ausführen:
node -vSie sollten eine Zeichenfolge erhalten, die die installierte Version von NodeJS anzeigt. Fahren wir nun mit der Aktualisierung von NPM fort.
npm install -g npmNachdem dies erledigt ist, können wir mit der Installation der Bibliotheken fortfahren.
Installieren der Bibliotheken
In diesem Tutorial werden Axios-, Cheerio-, Puppeteer- und Scrape-It.Cloud-NPMs verwendet. Wir haben bereits darüber geschrieben, wie man Axios und Cheerio zum Scrapen von Daten verwendet, da sie sich hervorragend für Anfänger eignen. Puppeteer ist ein komplexeres, aber auch funktionaleres NPM-Paket. Wir bieten auch NPM-Pakete an, die auf unseren Google Maps- und Google SERP-APIs basieren, also werden wir uns auch diese ansehen.
Erstellen Sie zunächst einen Ordner zum Speichern des Projekts und öffnen Sie die Eingabeaufforderung in diesem Ordner (gehen Sie zu dem Ordner, geben Sie „cmd“ in die Adressleiste ein und drücken Sie die Eingabetaste). Dann initialisieren Sie npm:
npm init -yDadurch wird eine Datei erstellt, in der Abhängigkeiten aufgelistet werden. Jetzt können Sie die Bibliotheken selbst installieren:
npm i axios
npm i cheerio
npm i puppeteer puppeteer-core chromium
npm i @scrapeit-cloud/google-maps-api
npm i @scrapeit-cloud/google-serp-apiNachdem nun die erforderlichen Elemente installiert sind, untersuchen wir die Webseiten, die wir durchsuchen werden. Wir haben zum Beispiel die beliebtesten ausgewählt – Google SERP und Google Maps.
Google SERP-Seitenanalyse
Lassen Sie uns mit Google nach „cafe new york“ suchen und die Ergebnisse finden. Gehen Sie dann zu DevTools (F12 oder klicken Sie mit der rechten Maustaste auf den Bildschirm und wählen Sie „Inspizieren“) und untersuchen Sie die Elemente genau. Wie wir sehen können, verfügen alle Elemente über automatisch generierte Klassen. Dennoch bleibt die Gesamtstruktur konstant und die Elemente haben, abgesehen von ihren sich ändernden Klassen, eine Klasse namens „g“.
Beispielsweise rufen wir den Titel und einen Link zur Ressource ab. Die übrigen Elemente werden auf ähnliche Weise gescrapt, sodass wir uns nicht auf sie konzentrieren.
Der Titel befindet sich im h3-Tag und der Link wird im „a“-Tag innerhalb des href-Attributs gespeichert.
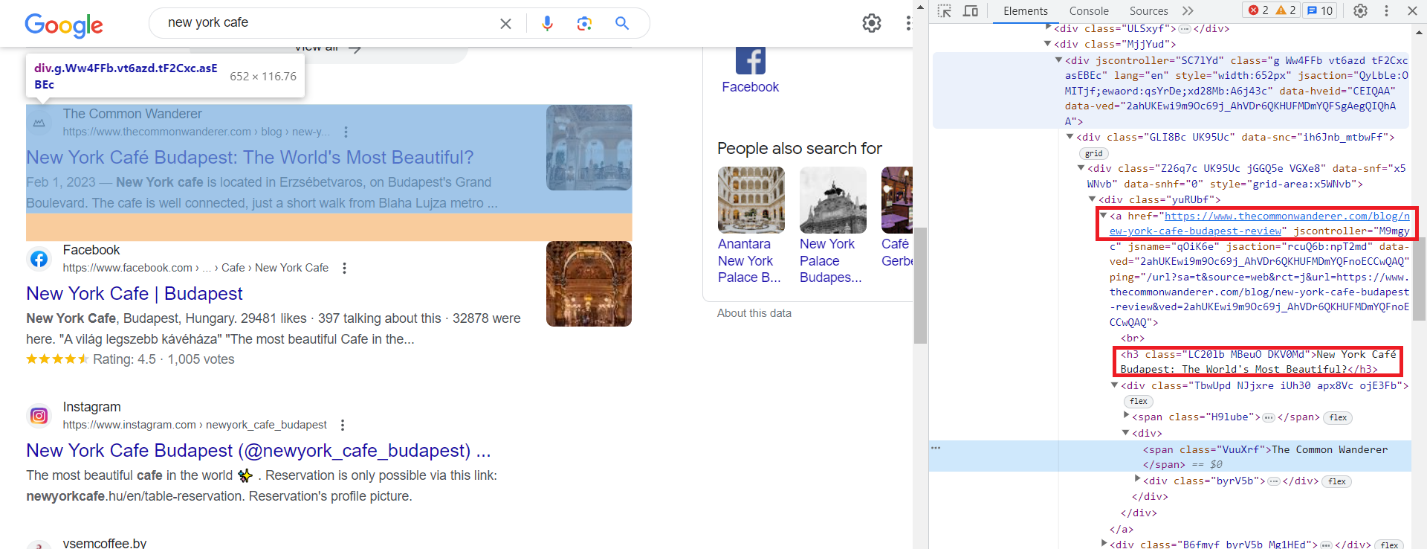
Wenn Sie weitere Daten benötigen, suchen Sie diese auf der Seite, im Code und finden Sie die Muster, anhand derer Sie ein bestimmtes Element identifizieren können.
Analyse der Google Map-Seite
Machen wir nun dasselbe für Google Maps. Gehen Sie zur Registerkarte „Google Maps“ und öffnen Sie DevTools. Lassen Sie uns dieses Mal einen Titel, eine Bewertung und eine Beschreibung erstellen. Sie können eine große Datenmenge von Google Maps abrufen. Wir zeigen es am Beispiel des Scrapings mit der API. Wenn Sie jedoch einen vollwertigen Scraper erstellen, um alle verfügbaren Daten von Google Maps zu sammeln, müssen Sie sich auf lange und harte Arbeit einstellen.
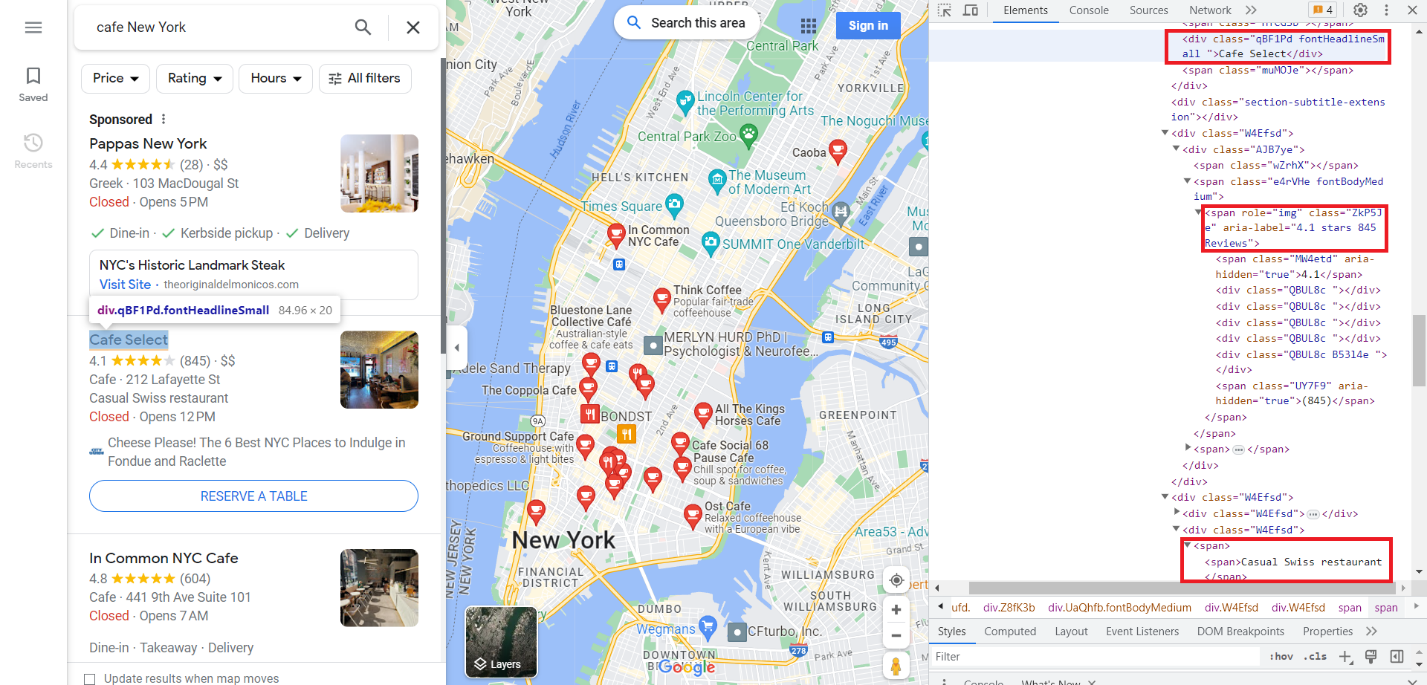
Wie wir sehen, benötigen wir die Daten aus der Klasse „fontHeadlineSmall“, aus dem Span-Tag mit dem Attribut Role=“img“ und aus dem Span-Tag.
Scraping von Google SERP mit NodeJS
Beginnen wir mit dem Scrapen der Google SERPs. Wir haben die Seite zuvor analysiert, daher müssen wir nur die Pakete importieren und sie zum Erstellen des Scrapers verwenden.
Scrapen Sie Google SERP mit Axios und Cheerio
Lassen Sie uns Axios- und Cheerio-Pakete importieren. Erstellen Sie dazu eine *.js-Datei und schreiben Sie:
const axios = require('axios');
const cheerio = require('cheerio');Lassen Sie uns nun eine Abfrage ausführen, um die erforderlichen Daten zu erhalten:
axios.get('https://www.google.com/search?q=cafe+in+new+york') Denken Sie daran, dass alle Elemente, die wir benötigen, die Klasse „g“ haben. Wir haben den HTML-Code der Seite, also müssen wir ihn verarbeiten und alle Elemente mit der Klasse „g“ auswählen.
.then(response => {
const html = response.data;
const $ = cheerio.load(html);
console.log($.text())
const elements = $('.g'); Danach müssen wir nur noch alle Elemente durchgehen und den Titel und den Link auswählen. Dann können wir sie auf dem Bildschirm anzeigen.
elements.each((index, element) => {
const title = $(element).find('h3').text();
const link = $(element).find('a').attr('href');
console.log('Title:', title);
console.log('Link:', link);
console.log('');
});Der Code ist einsatzbereit. Und es würde funktionieren, wenn die Seiten von Google nicht dynamisch generiert würden. Selbst wenn wir diesen Code ausführen, können wir leider nicht die gewünschten Daten erhalten. Dies liegt daran, dass Axios und Cheerio nur mit statischen Seiten funktionieren. Wir können lediglich den HTML-Code der Anfrage, die wir erhalten, auf dem Bildschirm anzeigen und sicherstellen, dass er aus einer Reihe von Skripten besteht, die beim Laden den Inhalt generieren sollen.
Scrapen Sie Google SERP mit Puppeteer
Verwenden wir Puppeteer, das sich hervorragend für die Arbeit mit dynamischen Seiten eignet. Wir schreiben einen Scraper, der den Browser startet, zur gewünschten Seite navigiert und die notwendigen Daten sammelt. Wenn Sie mehr über dieses npm-Paket erfahren möchten, finden Sie hier viele Beispiele für die Verwendung durch Puppeteer.
Schließen Sie nun die Bibliothek an und bereiten Sie die Datei für unseren Scraper vor:
const puppeteer = require('puppeteer');
(async () => {
//Here will be the code of our scraper
})();Starten wir nun den Browser und gehen zur gewünschten Seite:
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.google.com/search?q=cafe+in+new+york');Warten Sie dann, bis die Seite geladen ist, und rufen Sie alle Elemente mit der Klasse „g“ ab.
await page.waitForSelector('.g');
const elements = await page.$$('.g');Gehen wir nun alle Elemente einzeln durch und wählen für jedes einen Titel und einen Link. Zeigen Sie dann die Daten auf dem Bildschirm an.
for (const element of elements) {
const title = await element.$eval('h3', node => node.innerText);
const link = await element.$eval('a', node => node.getAttribute('href'));
console.log('Title:', title);
console.log('Link:', link);
console.log('');
}Und vergessen Sie am Ende nicht, den Browser zu schließen.
await browser.close();Und dieses Mal erhalten wir die Daten, die wir benötigen, wenn wir dieses Skript ausführen.
D:\scripts>node serp_pu.js
Title: THE 10 BEST Cafés in New York City (Updated 2023)
Link: https://www.tripadvisor.com/Restaurants-g60763-c8-New_York_City_New_York.html
Title: Cafés In New York You Need To Try - Bucket Listers
Link: https://bucketlisters.com/inspiration/cafes-in-new-york-you-need-to-try
Title: Best Places To Get Coffee in New York - EspressoWorks
Link: https://espresso-works.com/blogs/coffee-life/new-york-coffee
Title: Caffe Reggio - Wikipedia
Link: https://en.wikipedia.org/wiki/Caffe_Reggio
...Da Sie nun wissen, wie Sie die benötigten Daten erhalten, können Sie Ihr Skript mithilfe von CSS-Selektoren für die gewünschten Elemente problemlos ändern.
Scrapen mit der Google SERP API
Mit der Google SERP API wird das Scraping noch einfacher. Melden Sie sich dazu einfach auf unserer Website an, kopieren Sie den API-Schlüssel aus Ihrem Dashboard im Konto und stellen Sie eine GET-Anfrage mit den erforderlichen Parametern.
Beginnen wir mit der Verbindung der erforderlichen Bibliotheken und der Angabe des API-Links. Geben Sie außerdem den Titel an, in den Sie Ihren API-Schlüssel einfügen müssen.
const fetch = require('node-fetch');
const url="https://api.scrape-it.cloud/scrape/google?";
const headers = {
'x-api-key': 'YOUR-API-KEY'
};Lassen Sie uns nun die Anforderungseinstellungen festlegen. Nur einer davon ist erforderlich – „q“, der Rest ist optional. Weitere Informationen zu den Einstellungen finden Sie in unserer Dokumentation.
const params = new URLSearchParams({
q: 'Coffee',
location: 'Austin, Texas, United States',
domain: 'google.com',
deviceType: 'desktop',
num: '100'
});Und schließlich zeigen wir alle Ergebnisse in der Konsole an.
fetch(`${url}${params.toString()}`, { headers })
.then(response => response.text())
.then(data => console.log(data))
.catch(error => console.error(error));Sie können die API ganz einfach nutzen und erhalten dadurch dieselben Daten ohne Einschränkungen oder die Notwendigkeit von Proxys.
Scraping von Google Maps mit NodeJS
Nachdem wir uns nun mit dem Scraping von Daten aus Google SERP befasst haben, wird das Scraping von Daten aus Google Maps für Sie viel einfacher sein, da es nicht viel anders ist.
Scrapen Sie Google Maps mit Axios und Cheerio
Wie bereits erwähnt, ist es mit Axios und Cheerio nicht möglich, Daten aus Google SERP oder Maps zu extrahieren. Dies liegt daran, dass der Inhalt dynamisch generiert wird. Wenn wir versuchen, die Daten mithilfe dieser NPM-Pakete zu extrahieren, erhalten wir ein HTML-Dokument mit Skripten zum Generieren des Seiteninhalts. Daher wird es nicht funktionieren, selbst wenn wir ein Skript schreiben, um die erforderlichen Daten zu extrahieren.
Kommen wir also zur Puppeteer-Bibliothek, die es uns ermöglicht, einen Headless-Browser zu verwenden und mit dynamischen Inhalten zu interagieren. Mit Puppeteer können wir Einschränkungen überwinden und Daten effektiv aus Google Maps entfernen.
Scrapen Sie Google Maps mit Puppeteer
Lassen Sie uns dieses Mal Google Maps verwenden, um eine Liste der Cafés in New York, ihre Bewertungen und die Anzahl der Rezensionen abzurufen. Wir verwenden Puppeteer, um einen Browser zu starten und zu der Seite zu navigieren, um dies zu tun. Dieser Teil ähnelt dem Beispiel der Verwendung von Google SERP, daher gehen wir nicht näher darauf ein. Schließen Sie außerdem den Browser und beenden Sie die Funktion.
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.google.com/maps/search/cafe+near+New+York,+USA', { timeout: 60000 });
// Here will be information about data to scrape
await browser.close();
})();Jetzt müssen wir nur noch das übergeordnete Tag aller Elemente identifizieren und jedes Element durchlaufen, um Daten über seine Bewertung und die Anzahl der Bewertungen zu sammeln.
const elements = await page.$$('div(role="article")');
for (const element of elements) {
const title = await element.$eval('.fontHeadlineSmall', node => node.innerText);
const rating = await element.$eval('(role="img")(aria-label*=stars)', node => node.getAttribute('aria-label'));
console.log('Title:', title);
console.log('Rating:', rating);
console.log('');
}Als Ergebnis erhalten wir eine Liste mit Cafénamen und deren Bewertung.
D:\scripts>node maps_pu.js
Title: Victory Sweet Shop/Victory Garden Cafe
Rating: 4.5 stars 341 Reviews
Title: New York Booze Cruise
Rating: 3.0 stars 4 Reviews
Title: In Common NYC Cafe
Rating: 4.8 stars 606 Reviews
Title: Cafe Select
Rating: 4.1 stars 845 Reviews
Title: Pause Cafe
Rating: 4.6 stars 887 Reviews
...Nachdem wir nun die Bibliotheken erkundet haben, wollen wir sehen, wie einfach es ist, alle Daten mithilfe unserer Google Maps-API abzurufen.
Scrapen Sie mit der Google Map API
Um die Web-Scraping-API nutzen zu können, benötigen Sie Ihren einzigartigen API-Schlüssel, den Sie nach der Anmeldung auf unserer Website kostenlos erhalten, zusammen mit einer bestimmten Menge an Gratis-Credits.
Verbinden wir nun die Bibliothek mit unserem Projekt.
const ScrapeitSDK = require('@scrapeit-cloud/google-serp-api');Als Nächstes erstellen wir eine Funktion zum Ausführen der HTTP-Anfrage und fügen unseren API-Schlüssel hinzu. Um eine vollständige Wiederholung früherer Beispiele zu vermeiden, ändern wir es und fügen try…catch-Blöcke hinzu, um Fehler abzufangen, die während der Skriptausführung auftreten können.
(async() => {
const scrapeit = new ScrapeitSDK('YOUR-API-KEY');
try {
//Here will be a request
} catch(e) {
console.log(e.message);
}
})();Jetzt müssen wir nur noch eine Anfrage an die Scrape-It.Cloud API stellen und die Daten auf dem Bildschirm anzeigen.
const response = await scrapeit.scrape({
"keyword": "pizza",
"country": "US",
"num_results": 100,
"domain": "com"
});
console.log(response);Als Ergebnis erhalten wir eine JSON-Antwort, die Informationen zu den ersten hundert Artikeln und einige andere Informationen anzeigt:
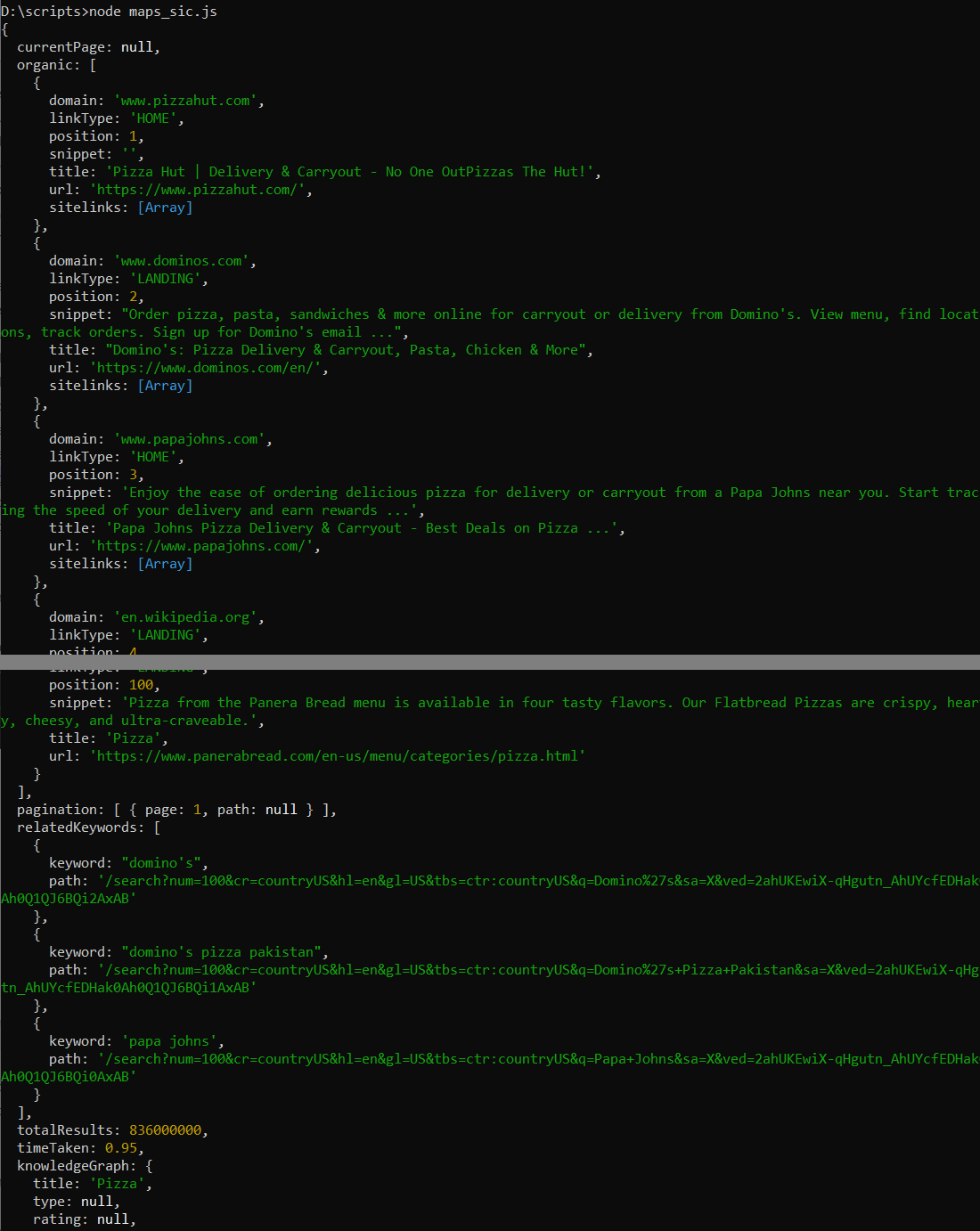
Da der vorherige Vorgang zu einfach war und wir über eine große Datenmenge verfügen, speichern wir diese zusätzlich in einer CSV-Datei. Dazu müssen wir das NPM-Paket „csv-writer“ installieren, das wir zuvor noch nicht installiert haben.
npm i csv-writerFügen wir nun den Import des NPM-Pakets zum Skript hinzu.
const createCsvWriter = require('csv-writer').createObjectCsvWriter;Jetzt müssen wir nur noch den Try-Block effizienter machen. Definieren Sie zunächst den CSV-Writer mit einem Semikolon als Trennzeichen nach der Antwort.
const csvWriter = createCsvWriter({
path: 'scraped_data.csv',
header: (
{ id: 'position', title: 'Position' },
{ id: 'title', title: 'Title' },
{ id: 'domain', title: 'Domain' },
{ id: 'url', title: 'URL' },
{ id: 'snippet', title: 'Snippet' }
),
fieldDelimiter: ';'
});Extrahieren Sie dann die relevanten Daten aus der Antwort:
const data = response.organic.map(item => ({
position: item.position,
title: item.title,
domain: item.domain,
url: item.url,
snippet: item.snippet
}));Und am Ende schreiben Sie die Daten in die CSV-Datei und zeigen die Meldung über das erfolgreiche Speichern an:
await csvWriter.writeRecords(data);
console.log('Data saved to CSV file.');Nachdem wir dieses Skript ausgeführt haben, haben wir eine CSV-Datei generiert, die detaillierte Informationen zu den ersten hundert Positionen auf Google Maps für das gewünschte Schlüsselwort enthält.
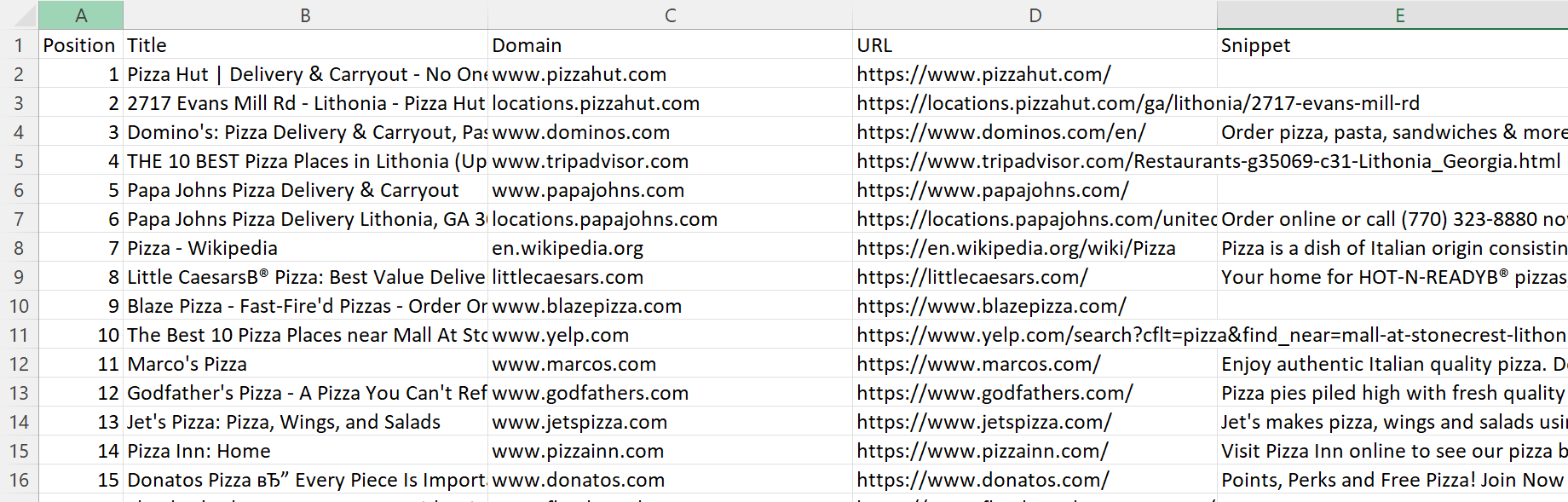
Vollständiger Code:
const ScrapeitSDK = require('@scrapeit-cloud/google-serp-api');
const createCsvWriter = require('csv-writer').createObjectCsvWriter;
(async() => {
const scrapeit = new ScrapeitSDK('YOUR-API-KEY');
try {
const response = await scrapeit.scrape({
"keyword": "pizza",
"country": "US",
"num_results": 100,
"domain": "com"
});
const csvWriter = createCsvWriter({
path: 'scraped_data.csv',
header: (
{ id: 'position', title: 'Position' },
{ id: 'title', title: 'Title' },
{ id: 'domain', title: 'Domain' },
{ id: 'url', title: 'URL' },
{ id: 'snippet', title: 'Snippet' }
),
fieldDelimiter: ';'
});
const data = response.organic.map(item => ({
position: item.position,
title: item.title,
domain: item.domain,
url: item.url,
snippet: item.snippet
}));
await csvWriter.writeRecords(data);
console.log('Data saved to CSV file.');
} catch(e) {
console.log(e.message);
}
})();Wir können also sehen, dass die Verwendung der Web-Scraping-API das Extrahieren von Daten aus Google Maps sehr einfach macht.
Herausforderungen beim Web Scraping von Google
Es reicht nicht aus, einen Scraper zu erstellen, der alle erforderlichen Daten sammelt. Es ist auch wichtig, darauf zu achten, dass Schwierigkeiten beim Schaben vermieden werden. Sie sollten darüber nachdenken, einige Herausforderungen im Voraus zu lösen und Vorkehrungen treffen, um sie zu umgehen, falls sie auftreten.
Anti-Kratzer-Mechanismen
Viele Websites verwenden unterschiedliche Methoden zum Schutz vor Bots, einschließlich Scrapern. Die ständige Ausführung von Anfragen an die Site stellt eine zu große Belastung für die Ressource dar, sodass Antworten verzögert und dann nicht mehr in der richtigen Reihenfolge zurückgegeben werden. Daher ergreifen Websites Maßnahmen zum Schutz vor häufigen Anfragen durch Bots. Eine dieser Schutzmöglichkeiten sind beispielsweise spezielle Traps, Elemente, die nicht auf der Seite, sondern im Code der Seite sichtbar sind. Die Weitergabe eines solchen Elements kann dazu führen, dass Sie blockiert werden oder auf nicht vorhandene Seiten in einer Schleife weitergeleitet werden.
CAPTCHAs
Eine weitere gängige Möglichkeit, sich vor Bots zu schützen, ist die Verwendung eines Captchas. Um dieses Problem zu umgehen, können Sie spezielle Dienste zur Lösung eines Captchas oder eine API nutzen, die vorgefertigte Daten zurückgibt.
Ratenbegrenzung
Wie bereits erwähnt, können zu viele Abfragen der Zielseite schaden. Darüber hinaus ist die Geschwindigkeit von Bot-Anfragen viel schneller als die von Menschen. Daher können Dienste relativ einfach feststellen, dass ein Bot Aktionen ausführt.
Zur Sicherheit Ihres Scrapers und um die Zielressource nicht zu schädigen, lohnt es sich, die Scraping-Geschwindigkeit auf mindestens 30 Anfragen pro Minute zu reduzieren.
Ändern der HTML-Struktur
Eine weitere Herausforderung beim Web Scraping ist die sich ändernde Struktur der Website. Sie haben es bereits am Beispiel von Google gesehen. Die Klassennamen und Elemente werden automatisch generiert, was das Abrufen der Daten erschwert. Die Struktur der Seite bleibt jedoch unverändert. Der Schlüssel liegt darin, es genau zu analysieren und effektiv zu nutzen.
IP-Blockierung
IP-Blockierung ist eine weitere Möglichkeit, sich vor Bots und Spam zu schützen. Wenn Ihre Aktionen einer Website verdächtig erscheinen, werden Sie möglicherweise blockiert. Aus diesem Grund müssen Sie wahrscheinlich einen Proxy verwenden. Ein Proxy fungiert als Vermittler zwischen Ihnen und der Zielwebsite. Damit können Sie sogar auf Ressourcen zugreifen, die in Ihrem Land oder speziell für Ihre IP-Adresse gesperrt sind.
Fazit und Erkenntnisse
Das Daten-Scraping aus Google Maps kann je nach den gewählten Tools komplex und einfach sein. Aufgrund von Herausforderungen wie JavaScript-Rendering und starkem Bot-Schutz kann die Entwicklung eines benutzerdefinierten Scrapers recht schwierig sein.
Darüber hinaus hat das heutige Beispiel gezeigt, dass nicht alle Bibliotheken für das Scraping von Google SERP und Google Maps geeignet sind. Dennoch haben wir auch gezeigt, wie wir diese Herausforderungen meistern können. Um beispielsweise die Herausforderung der dynamischen Strukturerstellung zu lösen, haben wir das Puppeteer NPM verwendet. Darüber hinaus zeigen wir Anfängern oder denjenigen, die lieber Zeit und Aufwand beim Umgang mit Captcha und Proxys sparen möchten, wie man eine Web-Scraping-API verwendet, um die gewünschten Daten zu extrahieren.
