
Beim Erstellen eines Web Scrapers lohnt es sich, die Möglichkeit einer Blockierung in Betracht zu ziehen – nicht alle Dienste sind bereit, ihre Daten zu scrapen.
Um die Anzahl der Bots, die die Website nutzen, zu reduzieren, verwenden Entwickler die Erkennung von IP-Adressen, die Überprüfung von HTTP-Anforderungsheadern, CAPTCHA und andere Methoden zur Erkennung des Bot-Verkehrs. Diese können jedoch weiterhin umgangen werden. Dazu müssen Sie beim Schaben einige Regeln beachten.
Aber auch wenn die Website keine Verbote vorsieht, lohnt es sich, Respekt zu zeigen und den Webseiten keinen Schaden zuzufügen. Befolgen Sie die in aufgeführten Regeln robots.txtScrapen Sie während der Spitzenzeiten keine Daten, begrenzen Sie Anfragen, die von derselben IP-Adresse kommen, und legen Sie Verzögerungen zwischen ihnen fest.
Sets für Nicht-Blöcke
Stellen Sie zunächst den Schaber richtig auf.
Legen Sie Anforderungsintervalle fest
Der häufigste Fehler beim Erstellen von Web Scrapern ist die Verwendung fester Intervalle. Personen können nach einem streng festgelegten Zeitraum nicht rund um die Uhr auf die Website zugreifen.
Daher ist es notwendig, ein Intervall festzulegen, innerhalb dessen sich die Zeit zwischen den Iterationen ändert. In der Regel ist es besser, die Installation zwei Sekunden oder länger durchzuführen.
Blättern Sie außerdem nicht zu schnell durch die Seiten. Bleiben Sie eine Weile auf der Webseite. Eine solche Nachahmung des Nutzerverhaltens verringert das Risiko einer Sperrung.
Legen Sie den Benutzeragenten fest
Der User-Agent enthält Informationen über den Benutzer und das verwendete Gerät. Mit anderen Worten handelt es sich dabei um die Daten, die der Server zum Zeitpunkt des Nutzerbesuchs empfängt. Es hilft dem Server, jeden Besucher zu identifizieren. Und wenn ein Benutzer mit demselben User-Agent zu viele Anfragen stellt, kann es sein, dass der Server ihn sperrt.
Daher lohnt es sich, darüber nachzudenken, in den Web Scraper die Möglichkeit einzuführen, den User-Agent-Header regelmäßig und auf zufällige Weise in einen anderen aus der gesamten Liste zu ändern. Dies ermöglicht es, eine Blockierung zu vermeiden und weiterhin Informationen zu sammeln.
Um Ihren eigenen Benutzeragenten anzuzeigen, gehen Sie zu DevTools (F12) und dann zur Registerkarte Netzwerk.
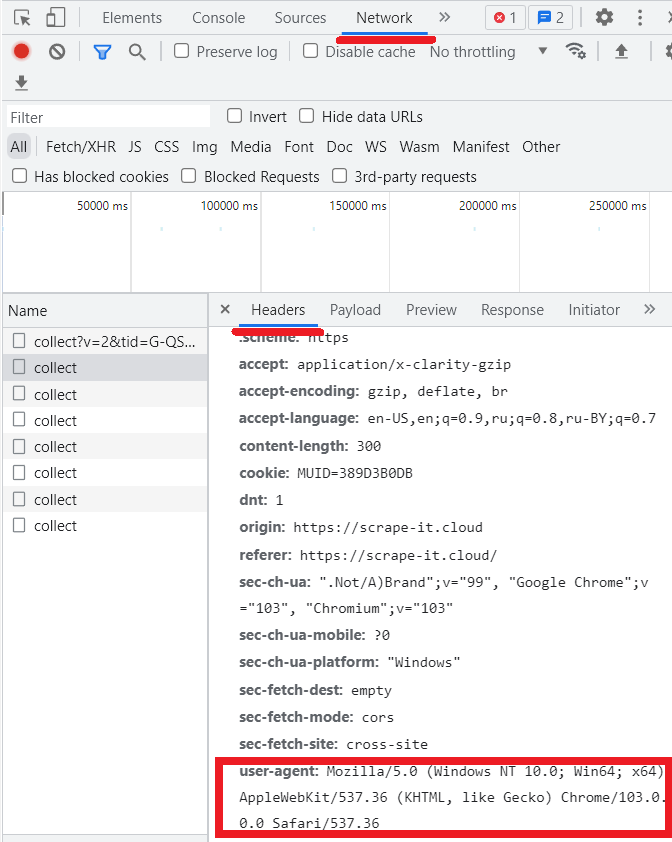
Allerdings gibt es neben Benutzeragenten noch andere Header, die die Arbeit des Scrapers sabotieren können. Leider senden Web-Scraper und Crawler häufig Header, die sich von denen unterscheiden, die von echten Webbrowsern gesendet werden. Daher lohnt es sich, sich die Zeit zu nehmen, alle Header so zu ändern, dass sie nicht wie automatische Anfragen aussehen, die der Bot sendet.
In der Regel werden bei der Verwendung eines Browsers durch einen echten Benutzer auch die Header „Accept“, „Accept-Encoding“, „Accept-Language“ und „Upgrade-Insecure-Requests“ ausgefüllt. Vergessen Sie sie daher nicht entweder. Ein Beispiel für das Ausfüllen solcher Felder:
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
upgrade-insecure-requests: 1Referrer festlegen
Der Referrer-Header zeigt die Site an, von der der Benutzer kam. Wenn Sie nicht wissen, was Sie in dieses Feld eingeben sollen, können Sie „google.com“ verwenden. Dabei kann es sich entweder um eine beliebige andere Suchmaschine (Yahoo.com, Bing.com usw.) oder eine beliebige Social-Media-Seite handeln. Es könnte zum Beispiel so aussehen:
Referer: https://www.google.com/Stellen Sie Ihren Fingerabdruck richtig ein
Immer wenn jemand eine Verbindung zu einer Zielwebsite herstellt, sendet sein Gerät eine Anfrage, die HTTP-Header enthält. Diese Header enthalten Informationen wie die Zeitzone des Geräts, die Sprache, Datenschutzeinstellungen, Cookies und mehr. Web-Header werden bei jedem Besuch einer Website vom Browser übertragen und sind in ihrer Gesamtheit ziemlich eindeutig.
Beispielsweise kann eine bestimmte Kombination solcher Parameter für etwa 200.000 Benutzer eindeutig sein. Daher lohnt es sich, über solche Informationen auf dem Laufenden zu bleiben. Eine Alternative besteht darin, Scraping-Dienste von Drittanbietern oder residente IPs zu nutzen. Zur Überprüfung der eigenen Fingerabdrücke können im nächsten Service verwendet werden.
Allerdings sollten nicht nur die Browser-Fingerprints stimmen, sondern auch die TLS-Fingerprints. Es ist besonders wichtig, den Überblick über TLS/HTTP-Fingerabdrücke zu behalten, die von verschiedenen Websites erfasst werden. Beispielsweise verwenden die meisten Parser HTTP/1.1 und die meisten Browser verwenden HTTP/2, sofern verfügbar. Daher sind Anfragen über HTTP/1.1 für die meisten Websites verdächtig.
Andere Möglichkeiten, Blockaden zu vermeiden
Wenn also alle Einstellungen abgeschlossen sind, ist es an der Zeit, mit den wichtigsten Fallen und Regeln fortzufahren, die es zu befolgen gilt.
Verwenden Sie einen Headless-Browser
Zunächst ist zu beachten, dass es sich nach Möglichkeit lohnt, einen Headless-Browser zu verwenden. Sie ermöglichen die Nachahmung des Benutzerverhaltens und verringern so das Risiko einer Blockierung. Sollte ein solcher Browser stören, besteht jederzeit die Möglichkeit, ihn auszublenden und alles im Hintergrundmodus zu erledigen.
Es hilft auch dabei, selbst die Daten zu empfangen, die über JavaScript oder dynamische AJAX-Webseiten geladen werden. Der gebräuchlichste Headless-Browser ist Chrome Headless, mit dem die meisten Scraping-Bibliotheken (z. B. Selenium) arbeiten.
Headless-Browser führen verschiedene Stilelemente wie Schriftarten, Layouts und Farben ein, sodass sie von einem echten Benutzer schwerer zu erkennen und zu unterscheiden sind.
Verwenden Sie einen Proxyserver
Wenn über einen längeren Zeitraum hinweg in geringem Abstand Anfragen von derselben Stelle kommen, ähnelt dieses Verhalten nicht dem eines normalen Benutzers. Es ist eher wie ein Bot. Damit die Zielwebsite jedoch nichts vermutet, kann man einen Proxyserver verwenden.
Vereinfacht ausgedrückt ist ein Proxy ein zwischengeschalteter Computer, der eine Anfrage an den Server und nicht an den Client stellt und ein Ergebnis an den Client zurückgibt. Daher geht der Zielserver davon aus, dass die Anfrage von einem völlig anderen Ort und daher von einem völlig anderen Benutzer stammt.
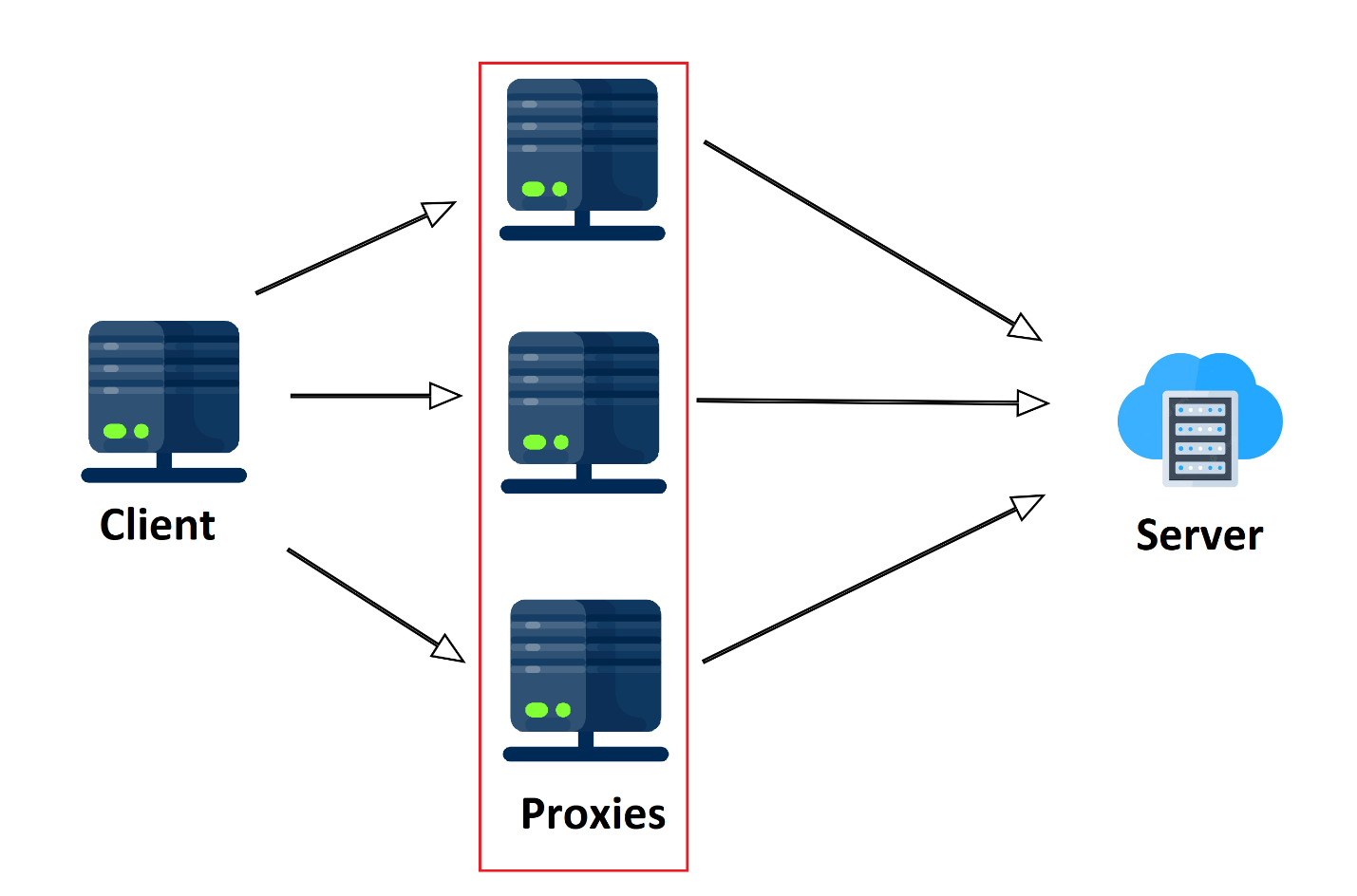
Proxys sind sowohl kostenlos als auch kostenpflichtig. Es ist jedoch besser, keine kostenlosen Proxys für das Daten-Scraping zu verwenden – sie sind extrem langsam und unzuverlässig. Idealerweise sollte man private oder mobile Proxys verwenden. Darüber hinaus reicht es nicht aus, einen Proxy zu verwenden. Für das Scraping ist es besser, einen ganzen Proxy-Pool zu erstellen.
Außerdem ist es sehr wichtig, die IP-Adresse im Auge zu behalten, von der aus die Anfrage gestellt wird. Falls der Standort nicht den Erwartungen der Website entspricht, können diese einfach blockiert werden. Beispielsweise ist es unwahrscheinlich, dass lokale Infrastrukturen für ausländische Nutzer von Nutzen sein werden. Daher ist es besser, lokale Proxys zum Parsen von Websites zu verwenden, um keinen Verdacht zu erregen.
Nutzen Sie CAPTCHA-Lösungsdienste
Wenn es zu viele Anfragen gibt, bietet die Website möglicherweise an, ein Captcha zu lösen, um sicherzustellen, dass die Anfrage von einem echten Benutzer und nicht von einem Bot stammt. In diesem Fall können Dienste helfen, die gegen eine geringe Gebühr das vorgeschlagene Captcha automatisch erkennen.
Vermeiden Sie Honeypot-Fallen
Um einen Bot zu fangen, verwenden viele Websites Honeypot-Fallen. Im Allgemeinen ist ein Honeypot ein leerer Link, der auf der Seite nicht vorhanden ist, aber im Quell-HTML-Code vorhanden ist. Bei automatischer Erfassung können diese Hooks den Web-Scraper auf Täuschungsseiten oder leere Seiten umleiten.
Tatsächlich sind sie sehr leicht zu erkennen. Für solche Links werden verschiedene „maskierende“ CSS-Eigenschaften angegeben. Beispielsweise „Anzeige: keine“, „Sichtbarkeit: ausgeblendet“ oder die Farbe des Links ist identisch mit dem Hintergrund der Website.
Vermeiden Sie JavaScript
Das Scraping von JavaScript führt, wie bei Bildern, nicht wirklich zu einer Blockierung. Es ist jedoch anzumerken, dass nicht alle Bibliotheken das Scrapen solcher Daten zulassen, was bedeutet, dass ein Web Scraper, der dynamische Daten sammeln kann, über komplexeren Code verfügt und mehr Rechenleistung erfordert.
Verwendung der Ready API in Web Scrapern
Wenn Sie den Eindruck haben, dass die aufgeführten Einstellungen und Regeln zu zahlreich sind und die Kosten für Proxys und Captcha-Lösungsdienste zu hoch sind, können Sie es einfacher machen und die Interaktion mit der Website auf Ressourcen Dritter „umleiten“.
Scrape-it.Cloud bietet eine REST-API zum Scrapen von Webseiten jeder Größenordnung. Der Dienst kümmert sich um IP-Blockierungen, IP-Rotationen, Captchas, JavaScript-Rendering, die Suche und Verwendung von Proxys für Privathaushalte oder Rechenzentren sowie das Setzen von HTTP-Headern und benutzerdefinierten Cookies. Der Benutzer stellt die Abfrage ein und die API gibt Daten zurück.
Tipps & Tricks zum Schaben
Das Letzte, was auch erwähnenswert ist, ist der Zeitpunkt, zu dem es besser ist, Websites zu scrapen, und die Reverse-Engineering-Methode beim Scraping. Dies ist nicht nur notwendig, um eine Blockierung zu vermeiden, sondern auch, um der Website keinen Schaden zuzufügen.
Kratzen außerhalb der Hauptverkehrszeiten
Da sich Crawler schneller durch die Seiten bewegen als echte Benutzer, erhöhen sie die Belastung des Servers erheblich. Wenn gleichzeitig das Parsen bei hoher Auslastung des Servers durchgeführt wird, sinkt die Arbeitsgeschwindigkeit der Dienste und die Site wird langsamer geladen.
Dies wirkt sich nicht nur negativ auf den Traffic der Website durch echte Benutzer aus, sondern erhöht auch den Zeitaufwand für die Datenerfassung.
Daher lohnt es sich, Daten in Momenten minimaler Site-Auslastung zu sammeln und zu extrahieren. Im Allgemeinen wird empfohlen, den Parser nach Mitternacht der Ortszeit auszuführen.

Kratzen Sie zu unterschiedlichen Tageszeiten
Wenn die Seite täglich von 8.00 bis 8.20 Uhr stark ausgelastet ist, entsteht Verdacht. Daher lohnt es sich, einen Zufallswert anzugeben, innerhalb dessen sich die Scraping-Zeit ändert.
Reverse Engineering für besseres Schaben
Reverse Engineering ist eine häufig verwendete Entwicklungsmethode. Kurz gesagt umfasst Reverse Engineering die Erforschung von Softwareanwendungen, um deren Funktionsweise zu verstehen.
Im Falle der Entwicklung eines Scrapers bedeutet dieser Ansatz, eine primäre Analyse für die Zusammenstellung zukünftiger Anfragen zu haben. Die Entwicklertools oder einfach DevTools im Browser (drücken Sie F12) können bei der Analyse von Webseiten helfen.
Versuchen wir, Google SERP genauer unter die Lupe zu nehmen. Gehen Sie zu den DevTools auf der Registerkarte „Netzwerk“, versuchen Sie dann, etwas auf google.com zu finden, und sehen Sie sich die abgeschlossene Anfrage an. Um die Antwort anzuzeigen, klicken Sie einfach auf die eingegangene Anfrage und gehen Sie zur Registerkarte „Vorschau“:
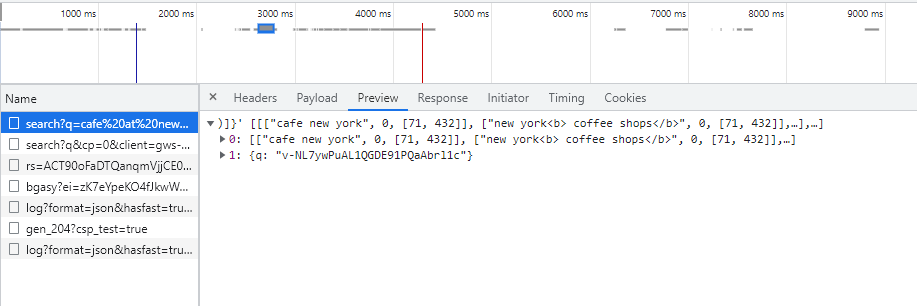
Diese Daten helfen zu verstehen, was genau die Anfrage zurückgeben soll und in welcher Form. Die Daten auf der Registerkarte „Header“ helfen zu verstehen, welche Daten zum Kompilieren der Anfrage gesendet werden sollen. Die Hauptsache ist, Anfragen richtig auszuführen und die Antworten richtig zu interpretieren.
Reverse Engineering mobiler Anwendungen
Die Situation ähnelt dem Reverse Engineering mobiler Anwendungen. Nur in diesem Fall ist es notwendig, die von der mobilen Anwendung an den Server gesendete Anfrage abzufangen. Im Gegensatz zum Abfangen normaler Anfragen sollte man für mobile Anwendungen einen Man-In-The-Middle-Proxy wie den Charles-Proxy verwenden.
Vergessen Sie auch nicht, dass die von der mobilen Anwendung gesendeten Anfragen komplexer und verwirrender sind.
Fazit und Erkenntnisse
Werfen wir abschließend einen Blick darauf, welche Sicherheitsmaßnahmen Websites ergreifen können und welche Gegenmaßnahmen ergriffen werden können, um diese zu umgehen.
|
Sicherheitsmaßnahme |
Gegenmaßnahme |
|
Browser-Fingerprinting |
Kopfloser Browser |
|
Speichern von Daten in JavaScript |
Kopfloser Browser |
|
IP-Ratenbegrenzungen |
Proxy-Rotation |
|
TLS-Fingerprinting |
TLS-Fingerabdruck fälschen |
|
CAPTCHA |
CAPTCHA-Lösungsdienste |
Durch Befolgen einer Reihe einfacher Regeln, die oben aufgeführt wurden, können Sie nicht nur Blockaden vermeiden, sondern auch die Effizienz des Schabers erheblich steigern.
Darüber hinaus ist beim Erstellen eines Scrapers zu berücksichtigen, dass viele Websites eine API zum Abrufen von Daten bereitstellen. Und wenn es eine solche Möglichkeit gibt, ist es besser, sie zu nutzen, als manuell Daten von der Website zu sammeln.
