
Beim Data Scraping besteht der erste Schritt darin, die Daten selbst zu finden. Dies kann auf viele Arten erfolgen – durch eindeutige Attribute, Klassennamen, IDs oder CSS-Selektoren. Aufgrund des Vorhandenseins dynamischer Elemente wird es jedoch manchmal schwieriger, nach Daten zu suchen und HTML-Elemente zu identifizieren. Hier kommt XPath zum Einsatz.
Wenn eine Webseite in einen Browser geladen wird, generiert sie eine DOM-Struktur (Document Object Model). Gleichzeitig ist XPath eine Abfragesprache, die Objekte im DOM abfragt. Dies macht XPath zu einer guten Möglichkeit, auch mit Selenium nach Webelementen auf einer Webseite zu suchen.
Syntax von XPath
XML Path oder allgemein bekannt als XPath ist eine Abfragesprache für XML-Dokumente. Es ermöglicht das Schreiben eines XML-Dokumentnavigationsflusses zur Suche nach beliebigen Webelementen.
Die XPath-Syntax besteht aus DOM-Attributen und -Tags, wodurch es möglich ist, jedes Element auf einer Webseite mithilfe des DOM zu finden. Im Allgemeinen beginnt XPath mit „//“ und sieht folgendermaßen aus:
//tag_name(@Attribute_name = "Value")/child nodesDabei ist der Tag-Name der Knotenname, @ bedeutet den Anfang des Namens des ausgewählten Attributs und der Wert hilft beim Filtern der Ergebnisse.
Ein Beispiel für XPath könnte das nächste sein:
//*(@id="w-node")/div/a(1)Arten von XPath
In Selenium gibt es nur zwei Arten von XPaths: absolute XPaths und relative XPaths.
Im Beispiel wird eine Webseite mit dem folgenden HTML-Code verwendet:
<!DOCTYPE html>
<html>
<head>
<title>A sample shop</title>
</head>
<body>
<div class="product-item">
<img src="https://scrape-it.cloud/blog/example.com\item1.jpg">
<div class="product-list">
<h3>Pen</h3>
<span class="price">10$</span>
<a href="example.com\item1.html" class="button">Buy</a>
</div>
</div>
<div class="product-item">
<img src="example.com\item2.jpg">
<div class="product-list">
<h3>Book</h3>
<span class="price">20$</span>
<a href="example.com\item2.html" class="button">Buy</a>
</div>
</div>
</body>
</html>Absoluter XPath
Die Verwendung von absolutem XPath hilft dabei, ein bestimmtes gegebenes Element genau zu finden. Schreiben wir beispielsweise einen absoluten XPath für den Produktnamen:
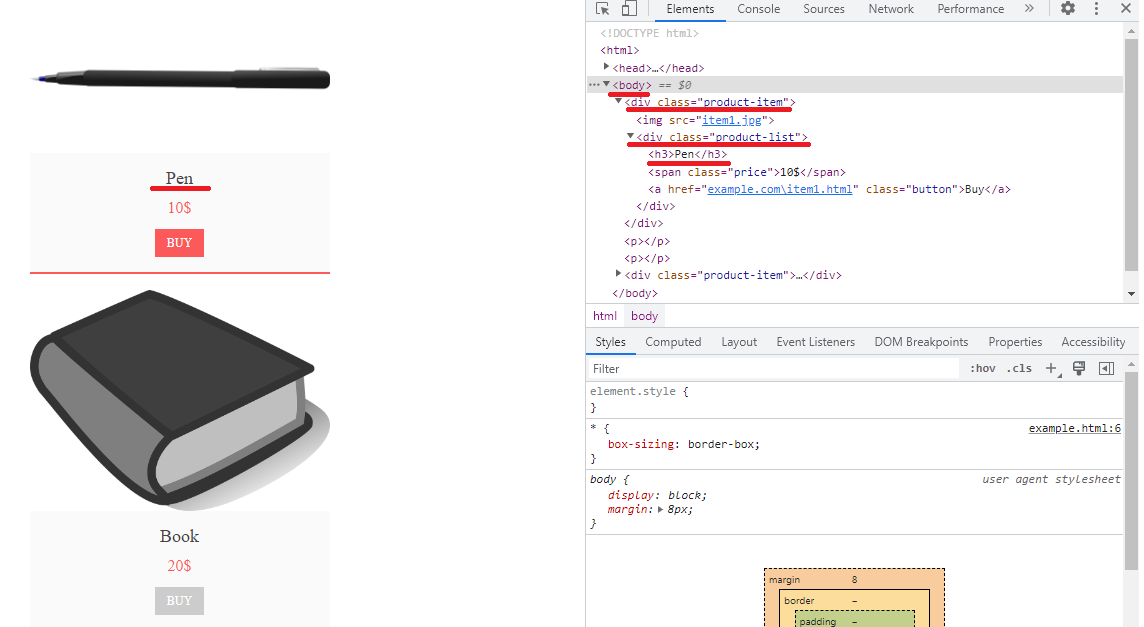
Absoluter XPath:
/html/body/div(1)/div/h3Um XPath aus Chrome DevTools zu kopieren (zum Öffnen F12 drücken), prüfen Sie einfach das Element (Strg+Umschalt+C oder unten prüfen):
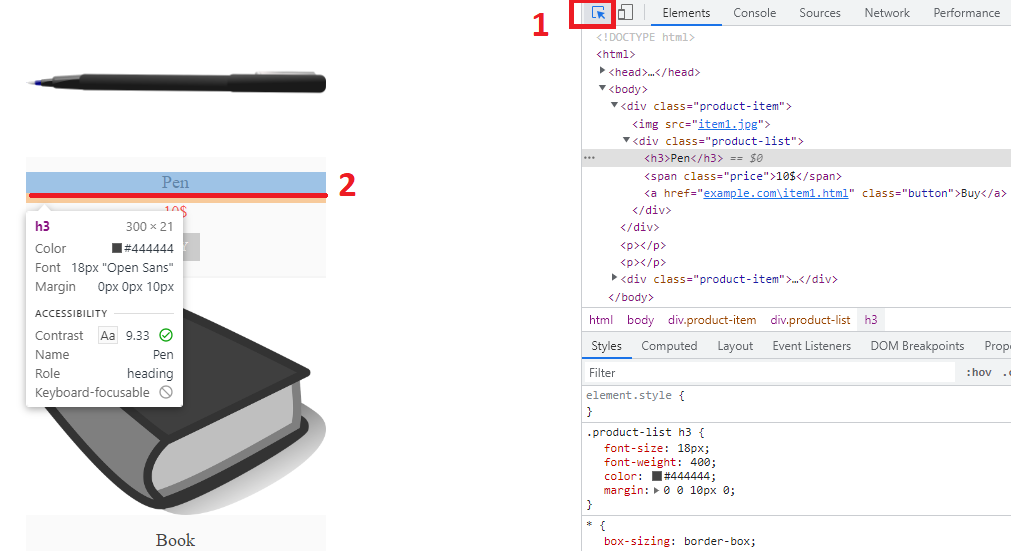
Klicken Sie dann mit der rechten Maustaste auf die Hervorhebungszeile im Elementfenster und wählen Sie „Kopieren/Kopieren des vollständigen XPath“:
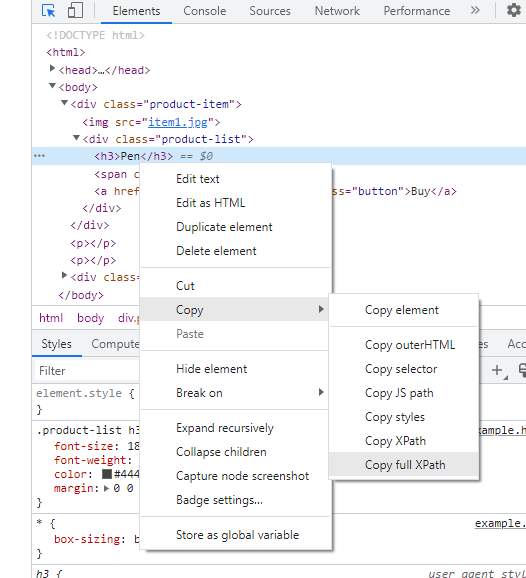
Der resultierende XPath kann in der Konsole überprüft werden:
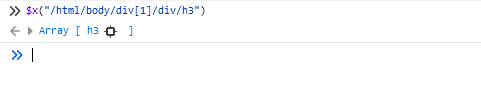
Hier kann man auch den HTML-Code dieses Elements kopieren. Klicken Sie einfach mit der rechten Maustaste auf das Ergebnis und wählen Sie „Objekt kopieren“:

Das Ergebnis:
<h3>Pen</h3>Diese Methode wird auch als Single-Slash-Suche bezeichnet und ist am anfälligsten für geringfügige Änderungen in der Struktur der Seite.
Relativer XPath
Relativer XPath ist flexibler und hängt nicht von geringfügigen Änderungen in der Seitenstruktur ab. Der nächste relative XPath findet dasselbe Element wie ein absoluter XPath unten:
//*(@class="product-list")/h3Lass uns das Prüfen:

Das Ergebnis:
( {<h3>Pen</h3>}, {<h3>Book</h3>} )Relativer XPath kann an einer beliebigen Stelle in der DOM-Struktur mit der Suche beginnen. Darüber hinaus ist es kürzer als Absolute XPath.
XPath VS CSS-Selektoren
Jemand, der bereits über CSS-Selektoren gelesen hat, kann möglicherweise nicht zwischen ihnen wählen. Der Hauptunterschied zwischen XPath- und CSS-Selektoren besteht darin, dass man sich mit XPath sowohl vorwärts als auch rückwärts bewegen kann, während sich der CSS-Selektor nur vorwärts bewegt und keine übergeordneten Elemente sieht. Allerdings ist XPath in jedem Browser unterschiedlich, sodass sie nicht universell einsetzbar sind.
Daraus lässt sich schließen, dass CSS-Selektoren am besten dann eingesetzt werden, wenn es darum geht, die Zeit zu verkürzen oder den Code zu vereinfachen. Wobei XPath eher für komplexere Aufgaben geeignet ist. Den vollständigen Artikel über CSS-Selektoren finden Sie hier.
Verwendung von XPath in Selenium
Zum Scrapen von Daten mit Selenium wird die By-Klasse verwendet. Es gibt zwei Methoden, die zum Auffinden von Seitenelementen in Kombination mit der Klasse „By“ zum Auswählen von Attributen nützlich sein können. Sie sind:
find_elementgibt die erste Instanz mehrerer Webelemente mit einem bestimmten Attribut im DOM zurück. Wenn kein Element gefunden wird, löst die Methode eine NoSuchElementException aus.find_elementsGibt einen leeren Wert zurück, wenn das Element nicht gefunden wird, oder eine Liste aller Webelementinstanzen, die mit dem angegebenen Attribut übereinstimmen.
Also, für die Suche nach dem Produktnamen des Stifts mit XPath in Selenium:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//*(@class="product-list")/h3')Und die Liste enthält alle Produktnamen:
from selenium.webdriver.common.by import By
driver.find_elements(By.XPATH, '//*(@class="product-list")/h3')Dynamischer XPath in Selenium
Um bestimmte Abfragen durchzuführen, können spezielle Befehle und XPath-Operatoren verwendet werden.
XPath mit logischen Operatoren: OR & AND
Logische Operatoren werden benötigt, um abhängig von den angegebenen Bedingungen genauer nach Elementen suchen zu können. XPath kann zwei logische Operatoren verwenden: oder & und. Man sollte bedenken, dass die Groß-/Kleinschreibung beachtet wird. Daher ist die Verwendung von „OR“ und „AND“ falsch.
Logischer Operator ODER
Diese XPath-Abfrage gibt die untergeordneten Elemente zurück, die mit dem ersten Wert, dem zweiten Wert oder beiden übereinstimmen. Zum Beispiel:
//tag_name(@Attribute_name = "Value" or @Attribute_name2 = "Value2")Es wird zurückgegeben:
| Attribut 1 | Attribut 2 | Ergebnis |
| FALSCH | FALSCH | Keine Elemente |
| WAHR | FALSCH | Gibt A zurück |
| FALSCH | WAHR | Gibt B zurück |
| WAHR | WAHR | Gibt beides zurück |
Ändern wir das obige Beispiel und überprüfen wir die Funktion des logischen Operators oder. Stellen Sie sich vor, dass der Stift in einem Behälter aufbewahrt wird:
<span time-in="150" class="price">10$</span>Und Buchpreis:
<span time-in="100" class="price">20$</span>Verwenden Sie den logischen Operator oder:
//span(@time-in = "100" or @class = "price")Das Ergebnis:
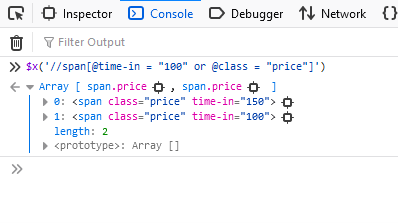
Die Abfrage ergab beide Produkte, da beide die Klasse „Preis“ hatten.
Logischer Operator UND
Diese XPath-Abfrage gibt die untergeordneten Elemente zurück, die nur mit beiden Werten übereinstimmen. Zum Beispiel:
//tag_name(@Attribute_name = “Value” and @Attribute_name2 = “Value2”)Es wird zurückgegeben:
| Attribut 1 | Attribut 2 | Ergebnis |
| FALSCH | FALSCH | Keine Elemente |
| WAHR | FALSCH | Keine Elemente |
| FALSCH | WAHR | Keine Elemente |
| WAHR | WAHR | Gibt beides zurück |
Um dies zu überprüfen, verwenden Sie einfach das obige Beispiel und ändern Sie den Operator OR in AND:

XPath mit Starts-With()
Diese Methode hilft dabei, Elemente zu finden, die auf besondere Weise begonnen haben. Hier finden Sie beispielsweise den Artikel „Web Scraping mit Python: Von den Grundlagen zur Praxis“.
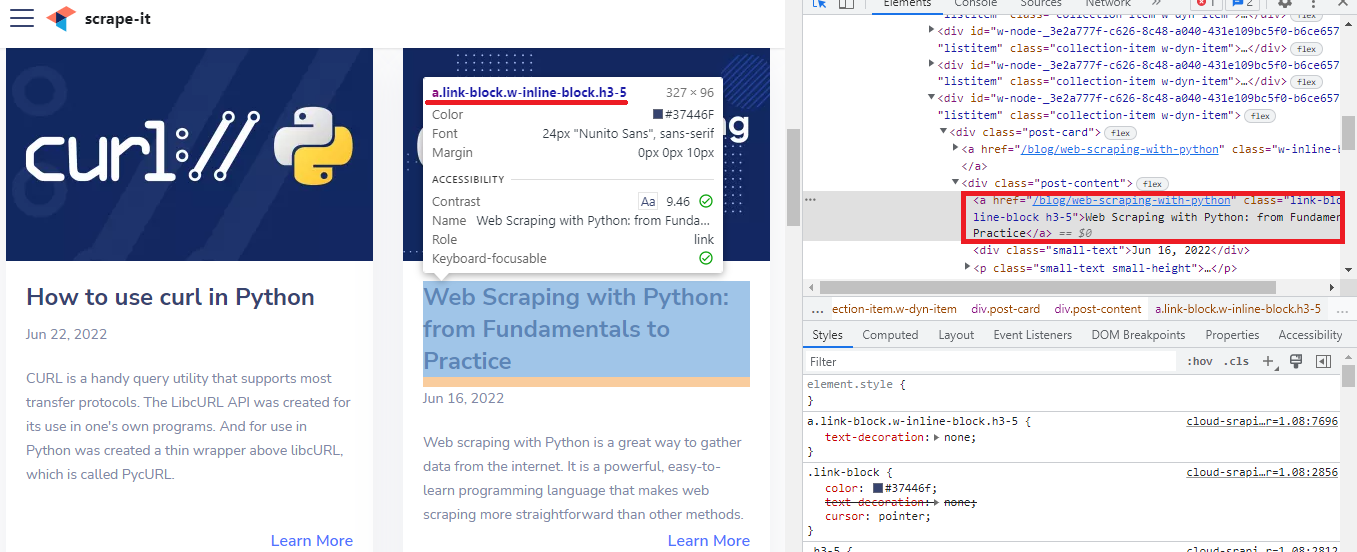
Der XPath wird der nächste sein:
//a(starts-with(text(),'Web Scraping'))oder
//a(starts-with(text(),'Web'))Lass uns das Prüfen:
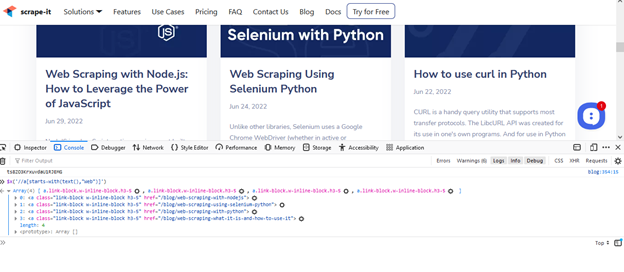
Aber das nächste wird falsch sein:
//a(starts-with(text(),'Scraping with Python'))Diese Methode kann nicht nur für statische Elemente, sondern auch für dynamische (als Schaltfläche) verwendet werden. Zum Beispiel:
//span(starts-with(@class, 'read-more-link'))XPath mit Index
Diese Methode ist nützlich, wenn man ein bestimmtes Element im DOM finden muss. Zum Beispiel:
//tag(@attribute_name="value")(element_num)Kehren wir zum Operator-OR-Beispiel zurück und versuchen, nur das erste Ergebnis zu finden:
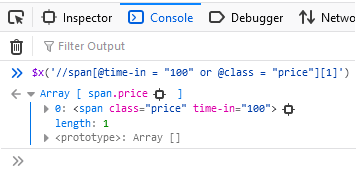
XPath mit Folgendem
Diese Methode wird verwendet, um das Webelement oder die Webelemente zu finden, die einem bekannten Element folgen. Die folgende Syntax ist die nächste:
//tag(@attribute_name="value")//following::tagEs sollte jedoch nicht neben einem bekannten Tag oder auf derselben Ebene liegen. Selenium wählt das nächstgelegene aus:
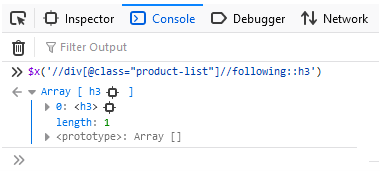
XPath mit Following-Sibling
Diese Methode findet das nächstgelegene Element mit demselben übergeordneten Element. Es hat die nächste Syntax:
//tag(@attribute_name="value")//following-sibiling::tag
Das Ergebnis ist das gleiche wie im vorherigen Beispiel.
XPath mit Preceding
Die vorhergehende Methode findet alle Elemente vor dem aktuellen Knoten:
//tag(@attribute_name="value")//preceding::tagSucht auf allen Ebenen nach dem nächstgelegenen.
XPath mit Preceding-Sibling
Das Gleiche wie der vorherige, aber Suche nach Elementen vor dem aktuellen Knoten mit demselben übergeordneten Knoten:
//tag(@attribute_name="value")//preceding-sibling::tagXPath mit Child
Diese Methode wird verwendet, um alle untergeordneten Elemente eines bestimmten Knotens zu finden:
//tag(@attribute_name="value")//child::tag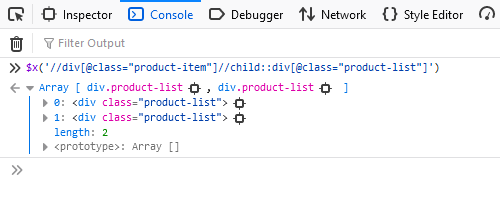
XPath mit Parent
Diese Methode wird verwendet, um alle übergeordneten Elemente eines bestimmten Knotens zu finden:
//tag(@attribute_name="value")//parent::tagXPath mit Nachkommen
Diese Methode wird verwendet, um alle Nachkommen (untergeordnete Knoten, Enkelknoten usw.) eines bestimmten Knotens zu finden:
//tag(@attribute_name="value")//descendants::tagXPath mit Ancestors
Diese Methode wird verwendet, um alle Vorfahren (übergeordnete Knoten, Großelternknoten usw.) eines bestimmten Knotens zu finden:
//tag(@attribute_name="value")//ancestors::tagFazit und Erkenntnisse
XPath in Selenium kann also dabei helfen, Elemente für das weitere Scraping zu finden. Es kann mit statischen und dynamischen Daten arbeiten. Darüber hinaus kann XPath im Gegensatz zu Selektoren auf allen Ebenen der DOM-Struktur, einschließlich übergeordneter Elemente, operieren.
