
Rust ist eine schnelle Programmiersprache ähnlich C, die sich zum Erstellen von Systemprogrammen (Treiber und Betriebssysteme) sowie regulären Programmen und Webanwendungen eignet. Wählen Sie Rust als Programmiersprache für die Erstellung eines Web Scrapers, wenn Sie eine umfassendere und untergeordnetere Kontrolle über Ihre Anwendung benötigen. Wenn Sie beispielsweise genutzte Ressourcen verfolgen, den Speicher verwalten und vieles mehr tun möchten.
In diesem Artikel werden wir die Nuancen des Aufbaus eines effizienten Web Scrapers mit Rust untersuchen und am Ende dessen Vor- und Nachteile hervorheben. Unabhängig davon, ob Sie Datenänderungen in Echtzeit verfolgen, Marktforschung betreiben oder einfach nur Daten zur Analyse sammeln, können Sie mit den Funktionen von Rust einen Web-Scraper erstellen, der sowohl leistungsstark als auch zuverlässig ist.
Erste Schritte mit Rust
Um Rust zu installieren, gehen Sie auf die offizielle Website und laden Sie die Distribution herunter (für Windows-Betriebssysteme) oder kopieren Sie den Installationsbefehl (für Linux).
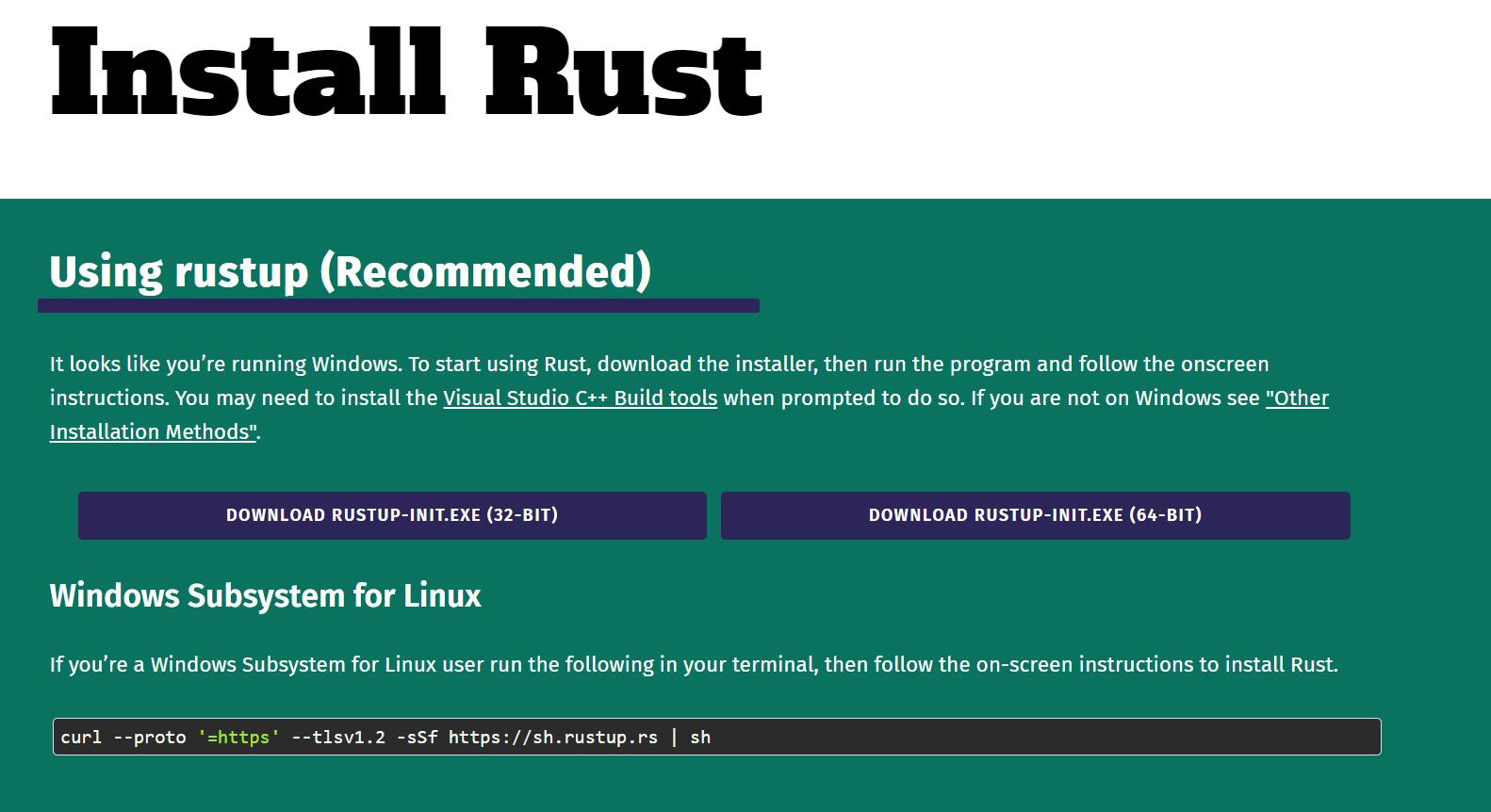
Wenn Sie die Datei für Windows ausführen, wird eine Eingabeaufforderung geöffnet und ein Installationsprogramm bietet Ihnen die Wahl zwischen einer von drei Funktionen:
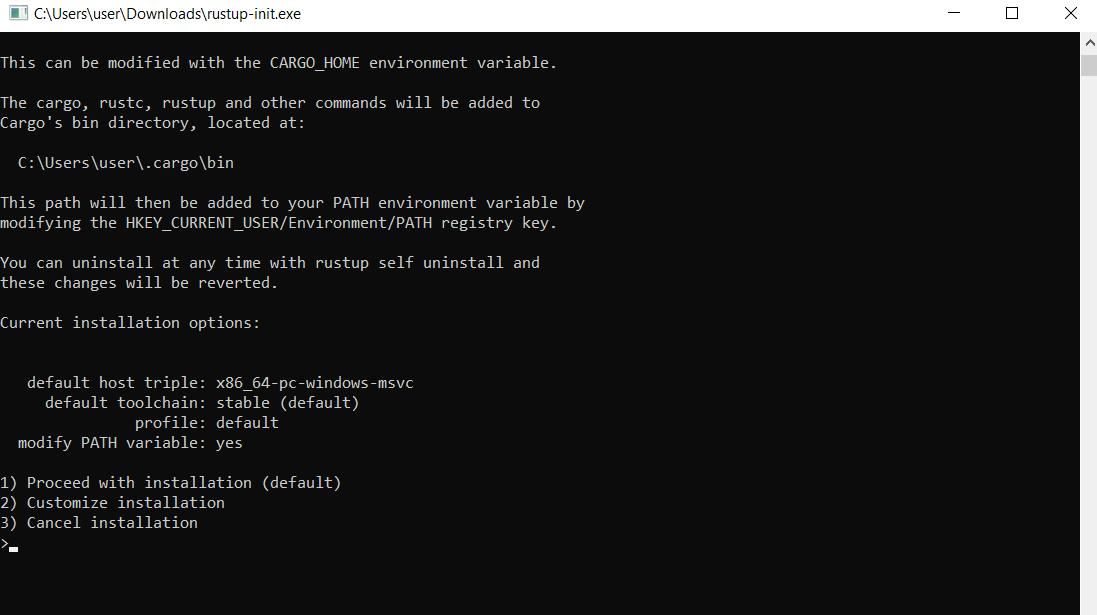
Da wir die Abhängigkeiten nicht manuell konfigurieren möchten, wählen wir Option 1 für die automatische Installation. Anschließend ist die Installation abgeschlossen und Sie erhalten eine Meldung, dass Rust und alle erforderlichen Komponenten erfolgreich installiert wurden.
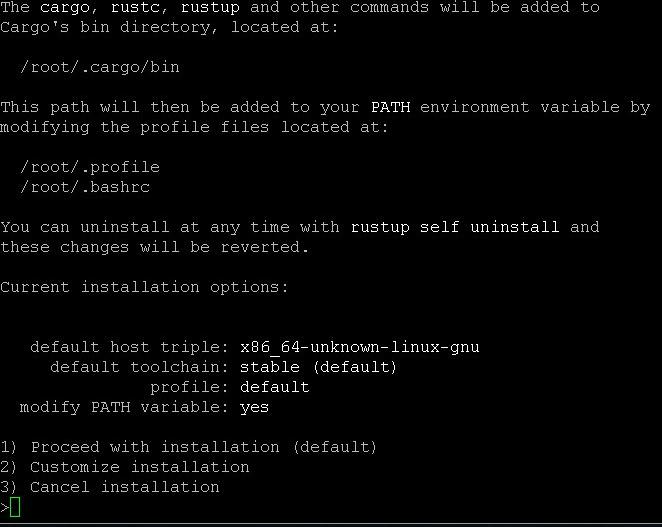
Um die Standardkomponenten auf einem Linux-System zu installieren, geben Sie im Terminal den Befehl ein:
$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | shWählen Sie dann während des Installationsvorgangs Punkt 1 aus.
Sie können Rust auch im Terminal aktualisieren:
$ rustup updateÜberprüfen Sie die Updates:
$ rustc --versionUnd deinstallieren Sie es:
$ rustup self uninstallDer Installations- und Einrichtungsvorgang ist nun abgeschlossen. Erstellen Sie eine neue Datei mit der RS-Datei, um ein Rust-Skript zu erstellen. Sie können auch Cargo, den Paketmanager von Rust, verwenden, um ein neues Projekt zu erstellen. Verwenden Sie diesen Befehl:
cargo new project_nameWie üblich verwenden wir Visual Studio Code, um den Code zu schreiben. Zur Vereinfachung werden wir auch das Rust-Analyzer-Plugin verwenden.
Im Gegensatz zu Python gibt es in Rust nur wenige Scraping-Bibliotheken, die beliebtesten sind jedoch:
- Reqwest und Scraper. Führen Sie eine Anfrage an eine Webseite aus und analysieren Sie das Ergebnis. Nur für statische Seiten geeignet.
- Headless_Chrome. Ermöglicht die Verwendung eines Headless-Browsers und die Automatisierung von Aktionen auf der Seite (Ausfüllen von Formularen, Klicks usw.). Es verfügt über ähnliche Funktionen wie Puppeteer für NodeJS und Selenium für Python.
Schauen wir sie uns genauer an.
Anfrage
Reqwest ist eine sehr einfache asynchrone Bibliothek für die Programmiersprache Rust zur Verarbeitung von HTTP-Anfragen. Es bietet eine bequeme und effiziente Möglichkeit, HTTP-Anfragen an Remote-Server zu senden und HTTP-Antworten zu verarbeiten.
Um es in Ihrem Projekt verwenden zu können, müssen Sie eine Abhängigkeit installieren:
cargo add reqwest --features "reqwest/blocking"Anschließend können Sie es in Ihrem Projekt verwenden und verschiedene Aspekte von Anforderungen konfigurieren, wie z. B. Header, Parameter und Autorisierung.
Schaber
Diese Rust-Bibliothek kann im Gegensatz zur vorherigen keine Anfragen ausführen. Es ist jedoch gut darin, Daten aus XML- und HTML-Dokumenten abzurufen. Aus diesem Grund werden diese Bibliotheken normalerweise zusammen verwendet.
Um die benötigten Teile zu verbinden und die Bibliothek in einem Rust-Projekt zu verwenden, verwenden Sie diesen Befehl:
cargo add scraperAnschließend können Sie das benötigte HTML-Dokument mithilfe von CSS-Selektoren analysieren.
Headless_Chrome
Und die letzte Bibliothek ist „headless_chrome“ für Rust. Es funktioniert mit dem Chrome-Browser im „Headless“-Modus für Web-Scraping und Automatisierung. Um es zu verwenden, verbinden Sie Abhängigkeiten mit dem folgenden Befehl:
cargo add headless_chromeMit der Rust-Bibliothek „headless_chrome“ können Sie den Chrome-Browser über das DevTools-Protokoll steuern. Es bietet eine Rust-Schnittstelle zum Senden von Befehlen an den Browser, etwa zum Laden von Webseiten, zum Ausführen von JavaScript, zum Simulieren von Ereignissen und mehr.
Grundlegendes Web Scraping in Rust
Um die Verwendung von Bibliotheken zu vereinfachen, schauen wir uns ein einfaches Beispiel für das Scrapen mit ihnen an. Als Beispiel werden wir die Demo-OpenCart-Website durchsuchen.
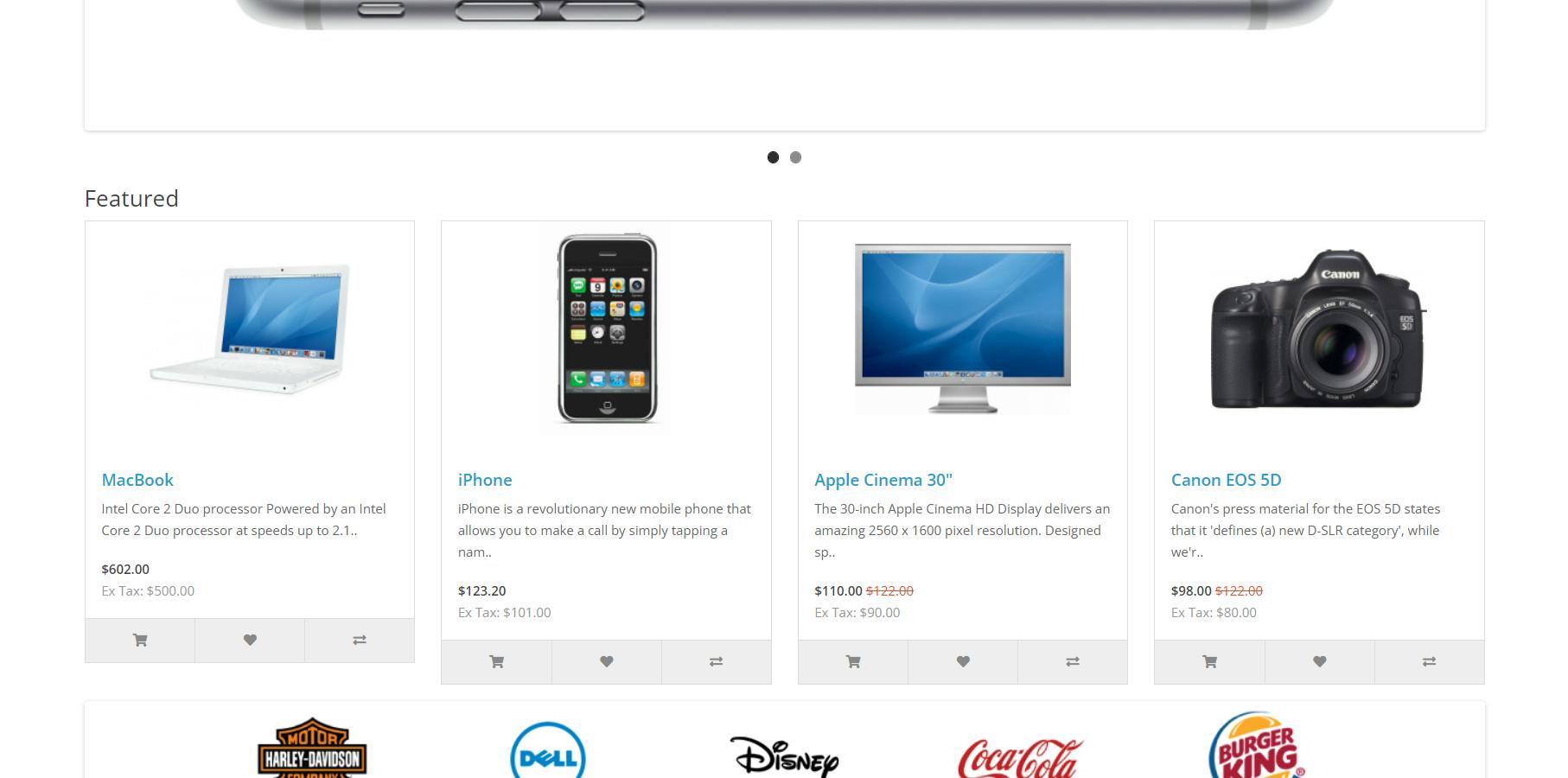
Wir haben Elemente auf dieser Seite besprochen, damit wir uns nicht noch einmal damit befassen.
Eine HTTP-Anfrage stellen
Wir werden mit der Datei arbeiten, die automatisch mit „cargo new project_name“ erstellt wurde. Die Datei main.rs befindet sich im Projektordner im Unterordner src. Es wird sofort mit einer Beispielfunktion generiert, um „Hallo Welt!“ anzuzeigen.
Für den Web Scraper verwenden wir die automatisch erstellte Funktion, um den Code unseres Rust Scrapers zu schreiben.
fn main() {
// Here will be code
}Beginnen wir zunächst damit, den HTML-Code der Website zu erhalten. Verwenden Sie diesen Befehl, um eine Anfrage zu senden:
let response = reqwest::blocking::get("https://demo.opencart.com/");Und dann dieses, um die resultierende Antwort zu extrahieren:
let data = response.unwrap().text().unwrap();Wenn Sie testen möchten, wie das funktioniert, fügen Sie einen Bildschirmausgabebefehl hinzu:
println!("{data}");Um das Projekt zu erstellen und auszuführen, verwenden Sie an der Eingabeaufforderung Folgendes:
cargo build
cargo runDie Laufzeit liefert Ihnen den gesamten HTML-Code der Seite.
HTML-Dokument analysieren
Zum Parsen von Daten verwenden wir die Scraper-Bibliothek und ihre Fähigkeit, Daten mithilfe von CSS-Selektoren zu extrahieren. Dazu benötigen wir eine Struktur und ein Array zur Speicherung der Daten:
struct DemoProduct {
image: Option<String>,
url: Option<String>,
title: Option<String>,
description: Option<String>,
new: Option<String>,
tax: Option<String>,
}
let mut demo_products: Vec<DemoProduct> = Vec::new();Verwenden Sie dann die Methode „select“, um Informationen zu allen Produkten zu extrahieren:
let html_product_selector = scraper::Selector::parse("div.col").unwrap();
let html_products = document.select(&html_product_selector);Lassen Sie uns abschließend jedes Produkt durchgehen und mithilfe des CSS-Selektors die Daten der benötigten HTML-Elemente in einem Array speichern.
for html_product in html_products {
let image = html_product
.select(&scraper::Selector::parse(".image a").unwrap())
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned);
let url = html_product
.select(&scraper::Selector::parse("h4 a").unwrap())
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned);
let title = html_product
.select(&scraper::Selector::parse(".description h4").unwrap())
.next()
.map(|h4| h4.text().collect::<String>());
let description = html_product
.select(&scraper::Selector::parse(".description p").unwrap())
.next()
.map(|p| p.text().collect::<String>());
let new = html_product
.select(&scraper::Selector::parse(".price-new").unwrap())
.next()
.map(|price| price.text().collect::<String>());
let tax = html_product
.select(&scraper::Selector::parse(".price-tax").unwrap())
.next()
.map(|price| price.text().collect::<String>());
let demo_product = DemoProduct {
image,
url,
title,
description,
new,
tax,
};
demo_products.push(demo_product);
}Um diese Daten auf dem Bildschirm anzuzeigen, müssen Sie alle Elemente noch einmal durchgehen und das gesamte Array Zeile für Zeile anzeigen:
for (index, product) in demo_products.iter().enumerate() {
println!("Product #{}", index + 1);
println!("Image: {:?}", product.image);
println!("URL: {:?}", product.url);
println!("Title: {:?}", product.title);
println!("Description: {:?}", product.description);
println!("New Price: {:?}", product.new);
println!("Tax: {:?}", product.tax);
println!("-----------------------------");
}Da wir die Daten jedoch selten auf dem Bildschirm anzeigen müssen, speichern wir die erhaltenen Daten in einer CSV-Datei.
Speichern der Scraped-Daten in einer CSV-Datei
Für die Arbeit mit Excel-Dateien steht eine CSV-Bibliothek zur Verfügung. Um es zu installieren, verwenden wir Cargo:
cargo add csvKehren wir nun zu unserem Skript zurück. Geben Sie den Pfad zum Speichern der Datei und die erforderlichen Spalten an.
let mut csv_writer = csv::Writer::from_path("products.csv").unwrap();
csv_writer.write_record(&("Image", "URL", "Title", "Description", "New Price", "Tax")).unwrap();Verarbeiten Sie dann jedes Element des Arrays Zeile für Zeile und fügen Sie es in eine Datei ein:
for product in demo_products {
let image = product.image.unwrap();
let url = product.url.unwrap();
let title = product.title.unwrap();
let description = product.description.unwrap();
let new = product.new.unwrap();
let tax = product.tax.unwrap();
csv_writer.write_record(&(image, url, title, description, new, tax)).unwrap();
}Und beenden Sie die Arbeit an der Datei:
csv_writer.flush().unwrap();Sie können println verwenden! und drucken Sie die Daten über das Ende des Skripts aus, oder Sie können einfach auf seine Ausführung warten. Als Ergebnis erhalten Sie eine Datei mit der folgenden Ausgabe:

Herzlichen Glückwunsch, Sie haben gerade einen klassischen Web-Scraper mit Rust erstellt und dabei die Speichersicherheit und -geschwindigkeit voll ausgenutzt. Sie haben gelernt, wie Sie Anfragen stellen, HTML-Dokumente analysieren und sogar die gescrapten Daten in eine CSV-Datei schreiben – alles innerhalb des Rust-Ökosystems.
Diese Methode eignet sich jedoch nur für statische Webseiten und ermöglicht nicht die Arbeit mit dynamischen Inhalten. Außerdem besteht ein sehr hohes Blockierungsrisiko, da Websites Ihren Scraper leicht erkennen können. Um diese Schwierigkeiten zu lösen, können Sie Headless-Browser verwenden.
Umgang mit dynamischen Inhalten
Erweitern wir unser Beispiel. Wir verwenden eine Bibliothek, die einen Headless-Browser verwendet, um zu einer Seite zu navigieren und Daten zu sammeln. Dadurch werden einige Probleme gelöst und dynamische Inhalte von der Seite entfernt.
Um den Browser nutzen zu können, benötigen Sie eine entsprechende Bibliothek, z. B. headless_chrome. Das Skript ähnelt dem ersten Beispiel, mit der Ausnahme, dass der Übergang zur Seite und die Sammlung des HTML-Codes der Seite von der headless_chrome-Bibliothek übernommen werden. Erstellen Sie ein neues Rust-Projekt mit ähnlichem Code wie im ersten Beispiel. Fügen Sie dann die Hauptfunktion hinzu:
let browser = headless_chrome::Browser::default().unwrap();
let tab = browser.new_tab().unwrap();
tab.navigate_to("https://demo.opencart.com/").unwrap();Auch die Verarbeitung von Daten mithilfe von CSS-Selektoren unterscheidet sich geringfügig.
let html_products = tab.wait_for_elements("div.col").unwrap();
for html_product in html_products {
let image = html_product
.wait_for_element("image a")
.unwrap()
.get_attributes()
.unwrap()
.unwrap()
.get(1)
.unwrap()
.to_owned();
let url = html_product
.wait_for_element("h4 a")
.unwrap()
.get_attributes()
.unwrap()
.unwrap()
.get(1)
.unwrap()
.to_owned();
let title = html_product
.wait_for_element(".description h4")
.unwrap()
.get_inner_text()
.unwrap();
let description = html_product
.wait_for_element(".description p")
.unwrap()
.get_inner_text()
.unwrap();
let new = html_product
.wait_for_element(".price-new")
.unwrap()
.get_inner_text()
.unwrap();
let tax = html_product
.wait_for_element(".price-tax")
.unwrap()
.get_inner_text()
.unwrap();
let demo_product = DemoProduct {
image: Some(image),
url: Some(url),
title: Some(title),
description: Some(description),
new: Some(new),
tax: Some(tax),
};
demo_products.push(demo_product);
}Alles andere bleibt wie im ersten Beispiel. Allerdings bringt diese Methode auch einige Herausforderungen mit sich. Während dieser Ansatz Ihnen eine detaillierte Kontrolle über den Scraping-Prozess ermöglicht, kann er für Anfänger oder diejenigen, die schnelle und vereinfachte Lösungen benötigen, überwältigend sein. Hier kommen spezielle Web-Scraping-APIs wie Scrape-It.Cloud ins Spiel.
Diese APIs bieten den Vorteil, dass sie viele Komplexitäten für Sie bewältigen, wie z. B. rotierende Proxys, die Handhabung von CAPTCHAs und die Verwaltung von Browsersitzungen, sodass Sie sich mehr auf die benötigten Daten konzentrieren können, statt auf die Feinheiten des Scraping-Prozesses.
Wenn dies nach einer attraktiven Alternative klingt, schauen wir uns an, wie Sie diese APIs für Ihre Web-Scraping-Anforderungen verwenden können.
Web Scraping in Rust mit API
Bevor wir uns mit dem Code befassen, wollen wir kurz darauf eingehen, was Web-Scraping-APIs sind. Im Wesentlichen handelt es sich hierbei um spezialisierte Dienste, die den Web-Scraping-Prozess vereinfachen sollen, indem sie sich um die damit verbundenen Komplexitäten kümmern, wie z. B. die Handhabung von CAPTCHAs, rotierende Proxys und die Verwaltung von Headless-Browsern.
Einen detaillierteren Überblick finden Sie in unserem separaten Artikel zu diesem Thema.
Sehen wir uns nun an, wie wir eine solche API in unser Rust-Projekt integrieren können. Da die API Daten im JSON-Format zurückgibt, benötigen Sie die optionale Serde-Bibliothek und das zugehörige Modul serde_json. Sie können sie auch über Cargo verbinden:
cargo add serde
cargo add serde_jsonAnschließend benötigen Sie den API-Schlüssel, den Sie nach der Registrierung bei scrape-it.cloud auf der Registerkarte „Dashboard“ in Ihrem Konto finden. Lassen Sie uns ein neues Projekt erstellen und das Clientobjekt und die Anforderungsheader in der Hauptfunktion festlegen:
let client = Client::builder().build()?;
let mut headers = HeaderMap::new();
headers.insert("x-api-key", HeaderValue::from_static("YOUR-API-KEY"));
headers.insert("Content-Type", HeaderValue::from_static("application/json"));Dann nutzen wir die Möglichkeit, Extraktionsregeln hinzuzufügen und sie dem Hauptteil der Abfrage hinzuzufügen, um die erforderlichen Daten auf einmal zu erhalten:
let mut extract_rules = HashMap::new();
extract_rules.insert("Image", "div.image > a > img @src"); // Use space to identify src or href attribute
extract_rules.insert("Title", "h4");
extract_rules.insert("Link", "h4 > a @href");
extract_rules.insert("Description", "p");
extract_rules.insert("Old Price", "span.price-old");
extract_rules.insert("New Price", "span.price-new");
extract_rules.insert("Tax", "span.price-tax");
let extract_rules_json: Value = serde_json::to_value(extract_rules)?;Legen Sie die restlichen Abfrageparameter fest:
let data = json!({
"extract_rules": extract_rules_json,
"url": "https://demo.opencart.com/"
});Und stellen Sie eine POST-Anfrage an die API:
let request = client.post("https://api.scrape-it.cloud/scrape")
.headers(headers)
.body(serde_json::to_string(&data)?);
let response = request.send()?;Jetzt gibt das Skript eine Antwort zurück und Sie können die benötigten Daten abrufen:
let body = response.text()?;Drucken Sie es auf dem Bildschirm aus:
println!("{}", body);Oder verwenden Sie die vorherigen Beispiele und speichern Sie diese Daten in einer CSV-Datei.
Web-Crawling mit Rust
Das letzte Codebeispiel in diesem Artikel ist ein einfacher Crawler, der die Seiten einer Website rekursiv durchläuft und alle Links sammelt. Wir haben bereits über den Unterschied zwischen einem Scraper und einem Crawler geschrieben, daher werden wir sie hier nicht vergleichen.
Importieren wir explizit die erforderlichen Module in die Datei:
use reqwest::blocking::Client;
use select::document::Document;
use select::predicate::Name;
use std::collections::HashSet;Dann legen wir in der Hauptfunktion die Anfangsparameter fest und rufen die Crawl-Funktion auf, die die Links umgeht.
fn main() {
let client = Client::new();
let start_url = "https://demo.opencart.com/";
let mut visited_links = HashSet::new();
crawl(&client, start_url, &mut visited_links).unwrap();
}Schließlich gibt es noch die Crawl-Funktion, mit der wir prüfen, ob wir den aktuellen Link durchlaufen haben, und wenn nicht, führen wir einen Crawl durch.
fn crawl(client: &Client, url: &str, visited_links: &mut HashSet<String>) -> Result<(), reqwest::Error> {
if visited_links.contains(url) {
return Ok(());
}
visited_links.insert(url.to_string());
let res = client.get(url).send()?;
if !res.status().is_success() {
return Ok(());
}
let body = res.text()?;
let document = Document::from(body.as_str());
for link in document.find(Name("a")) {
if let Some(href) = link.attr("href") {
if href.starts_with("http") && href.contains("demo.opencart.com") {
println!("{}", link.text());
println!("{}", href);
println!("---");
crawl(client, href, visited_links)?;
}
}
}
Ok(())
}Das Ergebnis:
Auf diese Weise können Sie alle Seiten der Site durchsuchen und sie auf der Konsole ausgeben oder die erlernten Fähigkeiten nutzen und sie im CSV-Format speichern.
Vor- und Nachteile der Verwendung von Rust für Web Scraping
Rost hat neben vielen Nachteilen auch viele Vorteile. Trotz der Schwierigkeit des Lernens und der begrenzten Ressourcen zum Erlernen von Scraping in Rust ist es aufgrund seiner hohen Leistung und der Fähigkeit, Prozesse auf niedriger Ebene zu verwalten, von entscheidender Bedeutung.
Parallelität ist eine weitere Stärke von Rust, die es Programmierern ermöglicht, gleichzeitige Programme zu schreiben, die Systemressourcen effizient nutzen. Darüber hinaus bietet die Rust-Community wichtige Unterstützung und Möglichkeiten zur Zusammenarbeit. Entwickler können ihr Wissen frei teilen und über verschiedene Foren, Chatrooms und Online-Communities von anderen lernen.
Dennoch gibt es bei der Arbeit mit Rust einige Nachteile zu beachten. Was die Browser-Automatisierung speziell betrifft, so ist es in Rust zwar möglich, externe Tools oder Crates wie Selenium WebDriver-Bindungen für andere Sprachen (nicht nativ) zu verwenden, die direkte Unterstützung innerhalb des reinen Rust-Ökosystems bleibt jedoch im Vergleich zu einigen Alternativen, die direkt von Browsern unterstützt werden, relativ begrenzt.
In der Tabelle finden Sie die wichtigsten Vor- und Nachteile von Rust:
|
Vorteile |
Nachteile |
|---|---|
|
1. Leistung |
1. Lernkurve |
|
2. Speichersicherheit |
2. Ökosystemreife |
|
3. Parallelität |
3. Eingeschränkte Browser-Automatisierung |
|
4. Community-Unterstützung |
4. Dokumentation und Ressourcen |
|
5. Integration mit anderen Rust-Bibliotheken |
5. Weniger Werkzeug |
Insgesamt zeigen diese Aspekte, wie Rust wesentliche Schwachstellen angeht, Sicherheitsbedenken berücksichtigt und ein besseres Leistungspotenzial bietet, was es zu einer zunehmend attraktiven Wahl für viele moderne Anwendungsbereiche macht.
Herausforderungen des Web Scraping in Rust
Web Scraping kann eine Herausforderung sein, insbesondere wenn die Sprache Rust verwendet wird. Lassen Sie uns einige der Schwierigkeiten untersuchen, mit denen Web Scraper in Rust konfrontiert sind, und mögliche Lösungen diskutieren.
Begrenzte Verfügbarkeit des Ökosystems und der Bibliothek
Eine der Herausforderungen beim Web Scraping mit Rust ist die begrenzte Verfügbarkeit von Bibliotheken und Tools, die speziell auf das Scraping zugeschnitten sind. Rust verfügt über ein weniger umfangreiches Ökosystem für Web Scraping als andere beliebte Sprachen wie Python oder JavaScript. Infolgedessen müssen Entwickler möglicherweise mehr Zeit damit verbringen, ihre eigenen benutzerdefinierten Scraping-Dienstprogramme zu erstellen oder mit vorhandenen, aber weniger umfassenden Bibliotheken zu arbeiten.
Dynamischer Inhalt und JavaScript
Viele moderne Websites verwenden dynamische Inhalte, die durch die Ausführung von JavaScript auf der Clientseite generiert werden. Dieser dynamische Inhalt stellt eine weitere Hürde beim Web-Scraping dar, da mehr als das herkömmliche HTML-Parsing erforderlich ist, um alle gewünschten Informationen genau zu extrahieren.
Um diese Einschränkung zu überwinden, besteht eine Lösung darin, Headless-Browser mit WebDriver-Bindungen wie Headless_Chrome zu nutzen. Dieses Tool ermöglicht die skriptgesteuerte Interaktion mit Websites, als ob Sie einen tatsächlichen Browser steuern würden, und ermöglicht so das effektive Scrapen dynamischer Inhalte.
CAPTCHA, Zugriffsbeschränkungen und IP-Blockierung
Über diese Schwierigkeiten und wie man sie vermeidet, haben wir bereits in einem anderen Artikel geschrieben, deshalb wollen wir es hier ganz kurz sagen. Um ihre Daten zu schützen und Scraping zu verhindern, setzen Websites Maßnahmen wie CAPTCHAs, Zugriffsbeschränkungen basierend auf User-Agent- oder IP-Adressen oder sogar die vorübergehende Blockierung verdächtiger Aktivitäten ein. Der Umgang mit diesen Hindernissen kann beim Web-Scraping mit Rust schwierig sein.
Es gibt einige Strategien, um diese Herausforderungen zu mildern, z. B. das Rotieren von IP-Adressen mithilfe von Proxyservern oder den Einsatz von Bibliotheken, die dabei helfen, CAPTCHA zu umgehen. Indem Entwickler diese Herausforderungen direkt verstehen und angehen, können sie die Leistungsfähigkeit der Sicherheitsgarantien von Rust nutzen und gleichzeitig effektive und effiziente Web-Scraper entwickeln.
Fazit und Erkenntnisse
Während das Web-Scraping mit Rust aufgrund des begrenzten Ökosystems der Sprache für diesen speziellen Anwendungsfall einige Herausforderungen mit sich bringen könnte, ist es dennoch durchaus machbar, diese durch die Erkundung verfügbarer Bibliotheken und die Implementierung geeigneter Techniken wie asynchroner Programmierung oder die Nutzung kopfloser Browser zu überwinden. Durch das Verständnis der damit verbundenen Hürden und die Anwendung geeigneter Lösungen können Entwickler Web-Scraping-Aufgaben in Rust erfolgreich und effizient durchführen.
