Unter Web Scraping versteht man das automatische Extrahieren von Informationen aus Webseiten. Es handelt sich um eine leistungsstarke Technik, die es Entwicklern ermöglicht, schnell und einfach Daten von Websites zu sammeln, ohne diese manuell eingeben oder herunterladen zu müssen. Web Scraping kann für viele verschiedene Zwecke eingesetzt werden, beispielsweise zum Erfassen von Produktpreisen, zum Sammeln von Kontaktinformationen oder zum Analysieren von Trends auf Social-Media-Websites.
Eine der beliebtesten Programmiersprachen für Web Scraping ist Ruby aufgrund seiner Open Source, Flexibilität und Benutzerfreundlichkeit. Wir haben Web Scraping in Python, C#, NodeJS und R bereits besprochen, aber in diesem Artikel werfen wir einen Blick auf Ruby. Mit Ruby können Sie komplexe Skripte schreiben, die den gesamten Datenerfassungsprozess automatisieren – vom Zugriff auf eine Website-Seite bis zum Parsen relevanter Informationen (wie E-Mail-Adressen). Ruby verfügt außerdem über eine breite Palette zusätzlicher Bibliotheken, die speziell für Web-Scraping-Zwecke entwickelt wurden. Bei Github finden Sie zahlreiche Bibliotheken zur Auswahl. In diesem Artikel konzentrieren wir uns jedoch nur auf die am weitesten verbreiteten und bekanntesten.
Vorbereitung für Web Scraping mit Ruby
Bevor wir mit der Erstellung eines Ruby-basierten Web Scrapers beginnen, müssen wir die Umgebung vorbereiten, die erforderlichen Bibliotheken berücksichtigen und installieren. Bereiten Sie zunächst die Umgebung vor und installieren Sie Ruby. Anschließend schauen wir uns die Bibliotheken an und installieren sie.
Umgebung installieren
Die offizielle Ruby-Website bietet Befehle zur Installation von Ruby auf allen gängigen Betriebssystemen, sei es Debian, CentOS, Snap, MacOS, OpenBSD, Windows oder andere. Wir weisen darauf hin, dass es auch einen Build für Windows gibt, der Ruby und die Basispakete enthält. Diese Option eignet sich für diejenigen, die ihre Ruby-Installation vereinfachen möchten. Wenn Sie sich für die Verwendung des Installationsprogramms entscheiden, vergessen Sie nicht, während der Installation die Kontrollkästchen an den erforderlichen Stellen zu aktivieren:

Dies ist notwendig, damit der Computer weiß, wo sich die ausführbare Datei befindet, und alle Dateien mit den Erweiterungen *.rb und *.rbw mit Ruby verknüpfen kann.
Nachdem Sie Ruby installiert haben, können Sie überprüfen, ob alles gut gelaufen ist, indem Sie den folgenden Befehl in der Befehlszeile ausführen:
ruby -vDies sollte eine Zeile mit der Ruby-Version zurückgeben:
ruby 3.2.2 (2023-03-30 revision e51014f9c0) (x64-mingw-ucrt)Entscheiden Sie nun, wo Sie den Code schreiben möchten. Tatsächlich ist dies nicht sehr wichtig. Sie können die Codedatei über die Befehlszeile ausführen und den Code sogar im Notepad schreiben. Allerdings ist es besser, hierfür spezielle Tools zu verwenden, die die Syntax hervorheben und Ihnen sagen, wo die Fehler liegen. Für diese Zwecke können Sie Sublime, Visual Code oder etwas anderes verwenden.
Installieren der Bibliotheken
Wenn dieser Teil abgeschlossen ist, können Sie mit der Installation der Bibliotheken beginnen. In diesem Tutorial werden wir uns die folgenden Bibliotheken ansehen:
- HTTParty. Voll ausgestattete Abfragebibliothek, mit der Sie GET-, POST-, PUT- und DELETE-Abfragen ausführen können. Obwohl es nicht speziell für das Web-Scraping konzipiert ist, kann es zum Abrufen von Daten von Webseiten und APIs nützlich sein.
- Net::HTTP. Eine weitere Bibliothek, mit der Sie Abfragen ausführen und verarbeiten können.
- Nokogiri. Dies ist eine vollständige Bibliothek zum Parsen und Verarbeiten von XML- und HTML-Dokumenten. Es kann keine Abfragen ausführen, eignet sich aber hervorragend für die Verarbeitung von Ausgabedaten. Sein Hauptvorteil ist die Möglichkeit, mit CSS-Selektoren zu arbeiten, jedoch nicht mit XPath.
- Mechanisieren. Dies ist die zweitbeliebteste Bibliothek, die für Ruby Web Scraping verwendet wird. Im Gegensatz zu Nokogiri bietet es die Möglichkeit, Daten selbst anzufordern.
- Watir. Es handelt sich um ein Framework zum Testen von Webanwendungen, das auch für Web Scraping verwendet werden kann. Es ermöglicht Ihnen, Interaktionen mit Webseiten auf ähnliche Weise wie Mechanize zu automatisieren. Es kann aber auch ein Headless-Browser verwendet werden.
Neben den zuvor erwähnten gibt es noch viele andere Ruby-Gems für das Web-Scraping, wie PhantomJS, Capybara oder Kimurai Gemfile. Allerdings sind die oben vorgeschlagenen Bibliotheken beliebter und besser dokumentiert, daher konzentrieren wir uns in diesem Artikel auf sie.
Um Pakete in Ruby zu installieren, verwenden Sie die Gem installieren Befehl:
gem install httparty
gem install nokogiri
gem install mechanize
gem install watirNet::HTTP muss nicht installiert werden, da es vorinstalliert ist. Sie können Ruby Gem verwenden, um dies zu überprüfen:
Seitenanalyse
Nehmen wir als Beispiel eine Testseite mit Büchern, die wir durchsuchen können. Gehen wir zunächst zur Seite und schauen uns den HTML-Code an. Um den HTML-Seitencode zu öffnen, gehen Sie zu DevTools (drücken Sie F12 oder klicken Sie mit der rechten Maustaste auf eine leere Stelle auf der Seite und gehen Sie zu „Inspizieren“).
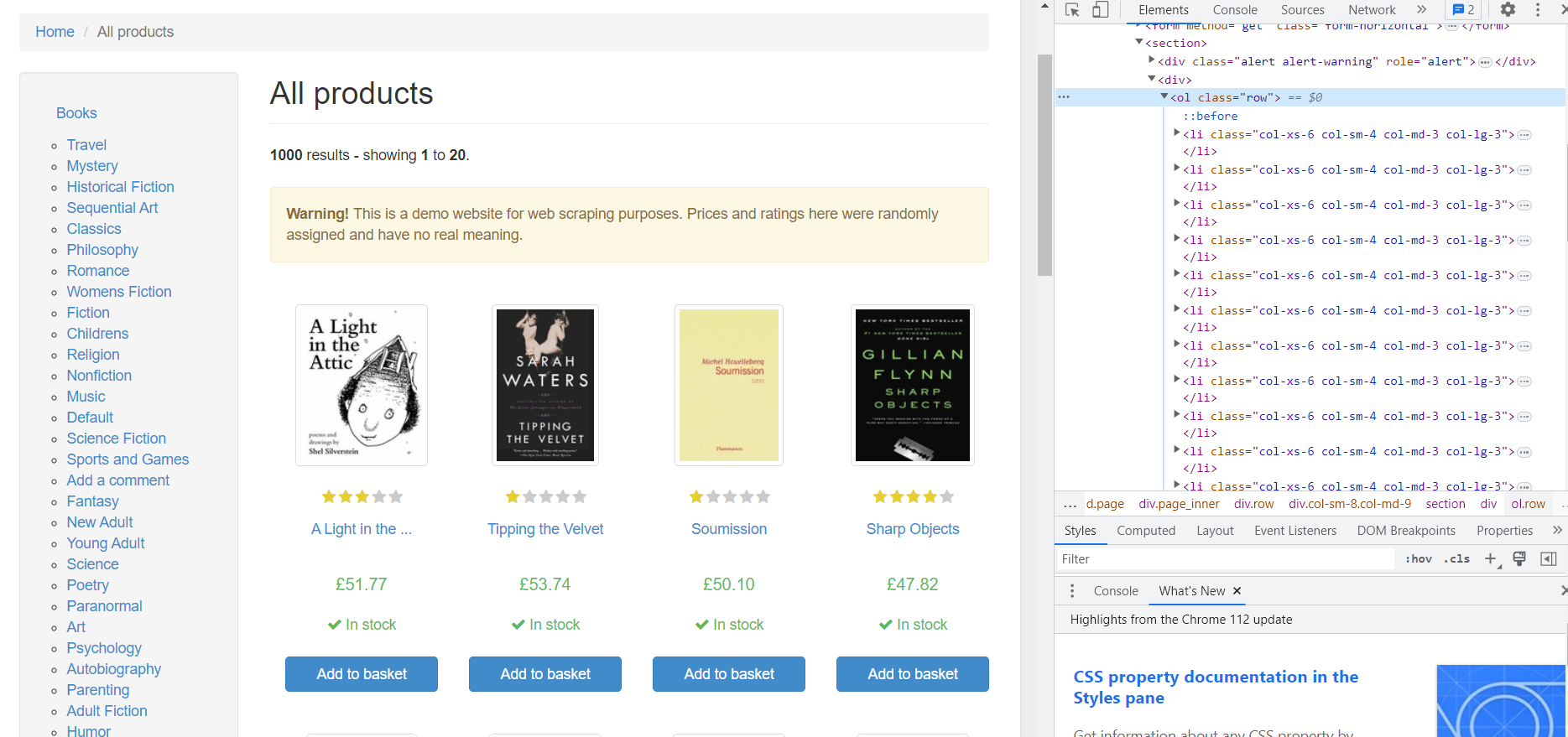
Alle Produkte auf der Seite werden im
- -Tag mit der Klasse „row“ und jedes einzelne Produkt im Sub-Tag
- platziert. Schauen wir uns eines der Produkte genauer an:

Basierend auf dem HTML-Code können wir die folgenden Daten erhalten:
- Bildlink. Befindet sich im -Tag und ist der Inhalt des „href“-Attributs.
- Bewertung. Es gibt zwei Klassen im
-Tag: Sternebewertung und Buchbewertung. In unserem Beispiel beträgt die Buchbewertung 3.
- Titel. Der Titel des Buches steht im -Tag. Allerdings ist es im Tag nicht vollständig spezifiziert. Der vollständige Titel steht im Attribut „title“.
- Preis. Hier müssen wir nur den Inhalt des
-Tags mit der Klasse „product_price“ abrufen.
- Verfügbarkeit. Hier ist auf die Klasse zu achten. Für die verfügbaren Bücher wird die Klasse „icon-ok“ verwendet.
Nachdem Sie nun alle erforderlichen Komponenten installiert haben, ist es an der Zeit, mit dem Bau Ihres Schabers zu beginnen. Mit Ruby und den richtigen Tools ist das Scrapen von Daten von Websites relativ einfach.
Einen Web-Scraper erstellen
Erstellen Sie eine neue *.rb-Datei, zum Beispiel „scraper.rb“, und öffnen Sie sie. In dieser Datei schreiben wir Code zum Scrapen von Daten mit Ruby. Zunächst schauen wir uns jede der installierten Bibliotheken einzeln an, um zu sehen, wie sie uns beim Abrufen von Informationen von Websites oder anderen Quellen helfen können.
Stellen Sie HTTP-Anfragen mit HTTParty
Die erste Bibliothek auf unserer Liste ist die HTTParty-Bibliothek. Es ermöglicht Ihnen nicht, Daten zu verarbeiten oder zu analysieren, aber es ermöglicht Ihnen, Abfragen auszuführen. Verbinden wir es:
require "httparty"Lassen Sie uns die Abfrage ausführen und den Code der Seite „books.toscrape.com“ abrufen:
response = HTTParty.get("https://books.toscrape.com/catalogue/page-1.html")Um das Ergebnis anzuzeigen, können Sie das verwenden puts() Befehl:
puts(response)Als Ergebnis erhalten wir den HTML-Code der Seite:
D:\scripts\ruby>ruby scraper.rb <!DOCTYPE html> <!--(if lt IE 7)> <html lang="en-us" class="no-js lt-ie9 lt-ie8 lt-ie7"> <!(endif)--> <!--(if IE 7)> <html lang="en-us" class="no-js lt-ie9 lt-ie8"> <!(endif)--> <!--(if IE 8)> <html lang="en-us" class="no-js lt-ie9"> <!(endif)--> <!--(if gt IE 8)><!--> <html lang="en-us" class="no-js"> <!--<!(endif)--> <head> <title> All products | Books to Scrape - Sandbox ... </title> </head> </html>Leider versuchen viele Websites, Scrapern den Zugriff auf ihre Daten zu verweigern. Um Ihren Scraper so zu tarnen, dass er auf die Daten zugreifen kann, gibt es einige Methoden, die Sie verwenden können: Verwendung von Proxys und Web-Scraping-APIs; Einrichten zufälliger Verzögerungen zwischen Anfragen; Verwendung von Headless-Browsern. Es ist außerdem wichtig, in jeder gesendeten Anfrage einen Benutzeragenten anzugeben. Dadurch wird die Wahrscheinlichkeit erhöht, dass Ihr Scraper einer Blockierung entgeht.
response = HTTParty.get("https://books.toscrape.com/catalogue/page-1.html", { headers: { "User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36" }, })Denken Sie daran, dass es besser ist, einen echten User-Agent zu verwenden.
Scrapen Sie Daten mit HTTParty und Web Scraping API
Wie bereits erwähnt, ist die HTTParty-Bibliothek nur für das Versenden von Anfragen konzipiert. Wir können jedoch die Web-Scraping-API verwenden, um die Daten zu verarbeiten. Dazu benötigen wir einen API-Schlüssel, den Sie nach der Anmeldung bei Scrape-It.Cloud erhalten. Wir benötigen außerdem eine zusätzliche Bibliothek:
gem install jsonVerbinden Sie diese Bibliothek in unserer Datei:
require "json"Stellen wir nun eine Anfrage an die API. Wir müssen einige Informationen bereitstellen, die verraten, wonach wir suchen. Dazu gehört die Angabe der Anfrage-Header (z. B. welche Art von Daten wir wollen und Ihr API-Schlüssel) und des Hauptteils (der eigentliche Inhalt unserer Anfrage):
url = "https://api.scrape-it.cloud/scrape" headers = { "x-api-key" => "YOUR-API-KEY", "Content-Type" => "application/json" } payload = { extract_rules: { title: "h3>a @title", price: "div.product_price>p.price_color", image: "div.image_container>a @href", rating: "p.star-rating @class", available: "p.availability>i @class" }, wait: 0, screenshot: true, block_resources: false, url: "https://books.toscrape.com/catalogue/page-1.html" }.to_jsonDann führen wir die Abfrage aus:
response = HTTParty.post(url, headers: headers, body: payload) parsed_page = JSON.parse(response.body)Jetzt können wir auf die Attribute der JSON-Antwort verweisen, die uns von der Scrape-It.Cloud-API zurückgegeben wird und die die erforderlichen Daten enthält:
parsed_page = JSON.parse(response.body) extracted_data = parsed_page("scrapingResult")("extractedData")Da die Daten nun vorliegen, speichern wir sie in einer CSV-Datei.
Daten im CSV-Format speichern
Beginnen wir mit der Installation der CSV-Bibliothek:
gem install csvVerbinden Sie die Bibliothek mit einer Datei:
require "csv"Um die Daten in einer Datei zu speichern, müssen wir sie mit den richtigen Einstellungen öffnen. Wir verwenden „w“ – wenn die Datei noch nicht existiert, wird dadurch eine für uns erstellt. Wenn es vorhanden ist, werden alle vorhandenen Inhalte überschrieben. Außerdem können wir definieren, welches Zeichen die einzelnen Informationen trennt – wir verwenden dazu ein Semikolon (;):
CSV.open("data.csv", "w", col_sep: ";") do |csv| … endLegen wir die Spaltentitel fest:
csv << ("Title", "Price", "Image", "Rating", "Availability")Lassen Sie uns zum Schluss alle Arrays, die wir erhalten haben, Zeile für Zeile durchgehen und die Daten in eine Datei schreiben:
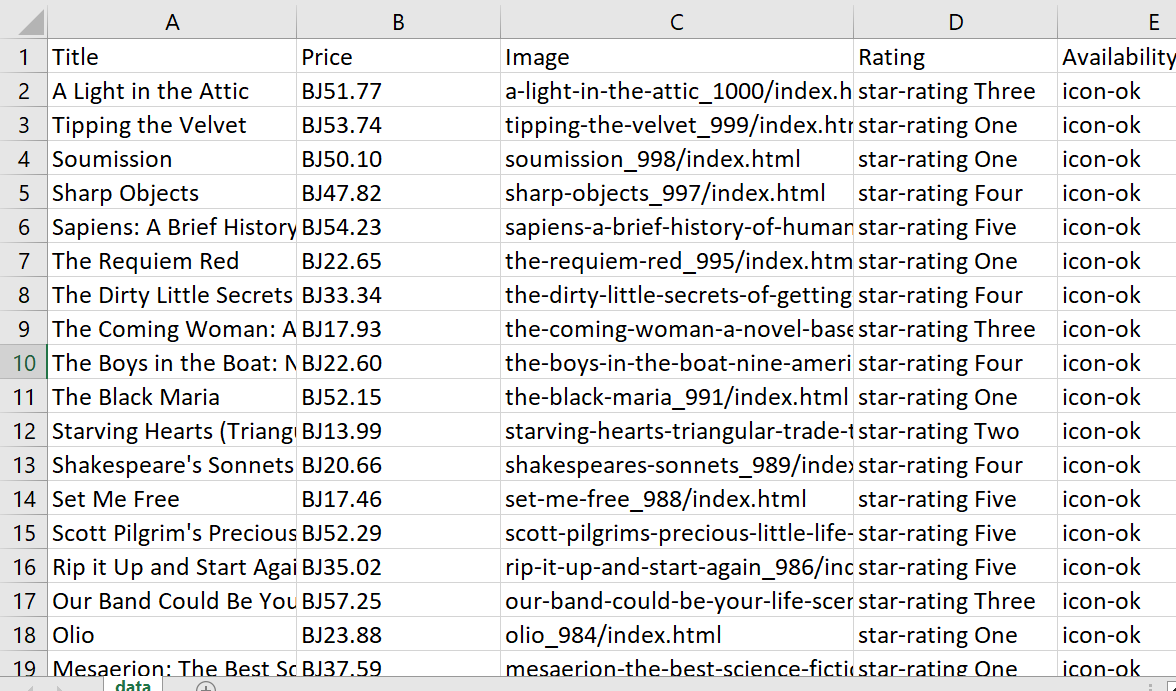
(extracted_data("title"), extracted_data("price"), extracted_data("image"), extracted_data("rating"), extracted_data("available")).transpose.each do |row| csv << row endAls Ergebnis haben wir die folgende Tabelle erhalten:
Es sieht großartig aus, aber wir können es noch besser machen, indem wir die Daten bereinigen. Glücklicherweise ist dies mit den integrierten Funktionen von Ruby einfach zu bewerkstelligen. Wir können mit den Pfund-Symbolen (£) in den Preisen beginnen, die beim Speichern in einer Datei als „BJ“ angezeigt werden:
extracted_data("price") = extracted_data("price").map { |price| price.gsub("£", "") }In der Spalte „Bewertung“ haben wir zwei verschiedene Klassen. Wir brauchen nur die zweite, also lösen wir dieses Problem mit der Methode split(). Dadurch wird unsere Zeichenfolge genommen und basierend auf einem angegebenen Muster oder Zeichen in ein Array von Zeichenfolgen aufgeteilt:
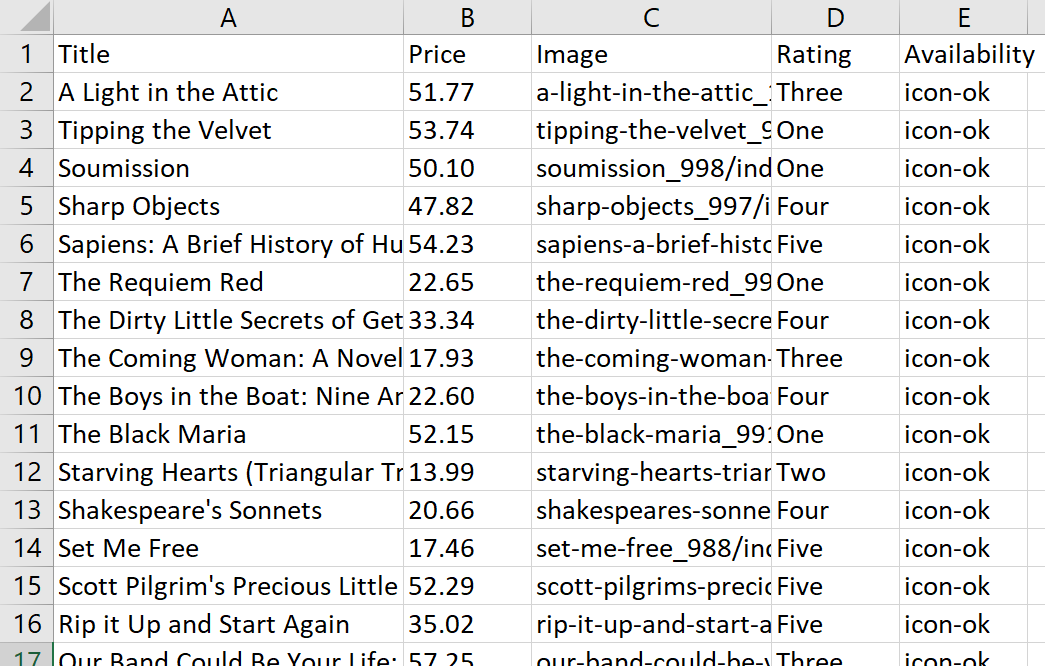
extracted_data("rating") = extracted_data("rating").map { |rating| rating.split(" ").last }Lassen Sie uns nun die Abfrage erneut ausführen und uns die Tabelle ansehen:
Jetzt sieht das Ergebnis besser aus und lässt sich in Zukunft leichter bearbeiten.
Resultierender Code:
require "httparty" require "json" require "csv" url = "https://api.scrape-it.cloud/scrape" headers = { "x-api-key" => "YOUR-API-KEY", "Content-Type" => "application/json" } payload = { extract_rules: { title: "h3>a @title", price: "div.product_price>p.price_color", image: "div.image_container>a @href", rating: "p.star-rating @class", available: "p.availability>i @class" }, wait: 0, screenshot: true, block_resources: false, url: "https://books.toscrape.com/catalogue/page-1.html" }.to_json response = HTTParty.post(url, headers: headers, body: payload) parsed_response = JSON.parse(response.body) extracted_data = parsed_response("scrapingResult")("extractedData") # Remove pound symbol (£) from price values extracted_data("price") = extracted_data("price").map { |price| price.gsub("£", "") } # Extract only the second word from the rating values extracted_data("rating") = extracted_data("rating").map { |rating| rating.split(" ").last } CSV.open("data.csv", "w", col_sep: ";") do |csv| csv << ("Title", "Price", "Image", "Rating", "Availability") (extracted_data("title"), extracted_data("price"), extracted_data("image"), extracted_data("rating"), extracted_data("available")).transpose.each do |row| csv << row end end puts "Data saved to data.csv"Nachdem wir uns nun die HTTParty-Bibliothek angesehen haben, werfen wir einen Blick darauf, wie sie aussehen würde, wenn wir stattdessen Net::HTTP verwenden würden. Wir werden in der Lage sein, zu verstehen, was diese Bibliotheken einzigartig macht, und herauszufinden, welche für unsere Scraping-Anforderungen am besten geeignet ist.
Stellen Sie Anfragen mit NET::HTTP
Die Net::HTTP-Bibliothek, die vom net-http-Gem bereitgestellt wird, kann für zusätzliche Funktionalität in Kombination mit dem open-uri-Gem verwendet werden. Net::HTTP bietet Zugriff auf das zugrunde liegende HTTP-Protokoll, während open-uri das Anfordern von Daten von einem Remote-Server einfacher und effizienter macht. Zusammen stellen sie eine effektive Möglichkeit dar, schnell Informationen von Websites abzurufen.
Verbinden wir zunächst die Bibliotheken:
require "uri" require "net/http"Dann müssen wir die URL-Zeichenfolge in ein URI-Objekt (Uniform Resource Identifier) analysieren:
url = URI.parse("https://books.toscrape.com/catalogue/page-1.html")Es hilft dabei, die URL in ihre Bestandteile zu zerlegen und ermöglicht so den einfachen Zugriff und die Bearbeitung verschiedener Komponenten nach Bedarf. Und schließlich können wir eine Abfrage ausführen und in der Befehlszeile ausgeben:
request = Net::HTTP.get_response(url) puts request.bodyMit der Net::HTTP-Bibliothek können Sie auf diese Weise eine einfache „GET“-Anfrage stellen, um Daten aus dem Web abzurufen. Dies kann eine großartige Möglichkeit sein, schnell auf Daten von jeder Website zuzugreifen und diese zu extrahieren.
Scrapen Sie Daten mit Net::HTTP und der Web Scraping API
Für diese Aufgabe verwenden wir die Scrape-It.Cloud-API. Zuerst müssen wir den API-Endpunkt definieren, an den unsere Anfrage gesendet werden soll. Wir müssen auch die Header und den Text der POST-Anfrage angeben. Im Grunde bedeutet das, dass wir der API die Details dessen bereitstellen, was wir auswerten möchten. Wir müssen ihm die URL der Seite geben, die wir durchsuchen möchten, und ihm mitteilen, welchen Inhalt wir extrahieren möchten:
url = URI("https://api.scrape-it.cloud/scrape") https = Net::HTTP.new(url.host, url.port) https.use_ssl = true request = Net::HTTP::Post.new(url) request("x-api-key") = "YOUR-API-KEY" request("Content-Type") = "application/json" request.body = JSON.dump({ "extract_rules": { "title": "h3>a @title", "price": "div.product_price>p.price_color", "image": "div.image_container>a @href", "rating": "p.star-rating @class", "available": "p.availability>i @class" }, "wait": 0, "screenshot": true, "block_resources": false, "url": "https://books.toscrape.com/catalogue/page-1.html" })Führen Sie dann die Abfrage aus und zeigen Sie die Daten auf dem Bildschirm an:
response = https.request(request) puts response.bodyWie wir sehen, unterscheidet sich die Verwendung dieser Bibliothek nicht wesentlich von der, die wir zuvor betrachtet haben. Verwenden wir also denselben Code wie im vorherigen Beispiel und speichern wir die Daten im CSV-Format. Um viele Wiederholungen zu vermeiden, zeigen wir die Vollversion des fertigen Skripts:
require "uri" require "json" require "net/http" require "csv" url = URI("https://api.scrape-it.cloud/scrape") https = Net::HTTP.new(url.host, url.port) https.use_ssl = true request = Net::HTTP::Post.new(url) request("x-api-key") = "YOUR-API-KEY" request("Content-Type") = "application/json" request.body = JSON.dump({ "extract_rules": { "title": "h3>a @title", "price": "div.product_price>p.price_color", "image": "div.image_container>a @href", "rating": "p.star-rating @class", "available": "p.availability>i @class" }, "wait": 0, "screenshot": true, "block_resources": false, "url": "https://books.toscrape.com/catalogue/page-1.html" }) response = https.request(request) parsed_response = JSON.parse(response.body) extracted_data = parsed_response("scrapingResult")("extractedData") extracted_data("price") = extracted_data("price").map { |price| price.gsub("£", "") } extracted_data("rating") = extracted_data("rating").map { |rating| rating.split(" ").last } CSV.open("data.csv", "w", col_sep: ";") do |csv| csv << ("Title", "Price", "Image", "Rating", "Availability") (extracted_data("title"), extracted_data("price"), extracted_data("image"), extracted_data("rating"), extracted_data("available")).transpose.each do |row| csv << row end end puts "Data saved to data.csv"Nachdem wir uns nun die Abfragebibliotheken angesehen haben, wollen wir mit der Erkundung der Bibliotheken fortfahren, die Datenverarbeitungsfunktionen bereitstellen. Diese Bibliotheken ermöglichen es uns, die von uns erfassten Daten auf sinnvolle Weise zu transformieren und zu manipulieren.
Analysieren Sie die Daten mit Nokogiri
Nokogiri ist eine unglaublich nützliche Bibliothek sowohl zum Verarbeiten als auch zum Parsen von Daten. Es ist einfach zu bedienen und bei Ruby-Entwicklern sehr beliebt. Es bietet eine effektive Möglichkeit, mit HTML- und XML-Dokumenten zu arbeiten und macht das Scraping von Daten schnell und einfach.
Leider ist Nokogiri keine eigenständige Scraping-Bibliothek und es fehlt die Möglichkeit, Anfragen zu versenden. Darüber hinaus eignet es sich hervorragend zum Abrufen von Daten von statischen Seiten, Sie können es jedoch nicht zum Abfragen und Verarbeiten von Daten von dynamischen Seiten verwenden. In den vorherigen Beispielen haben wir diese Probleme mithilfe der Web-Scraping-API gelöst. Bei Nokogiri sind das alles Probleme, die der Entwickler selbst lösen muss.
Wenn Sie jedoch nur Daten von statischen Seiten extrahieren müssen, keine Aktionen auf der Seite durchführen müssen (z. B. Autorisierung durchführen) und eine einfache Bibliothek benötigen, dann ist Nokogiri genau das, was Sie brauchen.
Um es nutzen zu können, benötigen wir eine Abfragebibliothek. Hier verwenden wir HTTParty, aber Sie können jede Bibliothek verwenden, die Ihren Anforderungen entspricht. Lassen Sie uns zunächst die beiden Bibliotheken verbinden und den gesamten Code unserer Seite erhalten:
require 'httparty' require 'nokogiri' headers = { 'User-Agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' } url = https://books.toscrape.com/catalogue/page-1.html" response = HTTParty.get(url, headers: headers)Übergeben Sie nun den Code, den Sie erhalten haben, an das Nokogiri-Objekt. Anschließend wird die Seitenstruktur analysiert und Sie können leichter auf verschiedene Elemente auf dieser Seite zugreifen:
doc = Nokogiri::HTML(response.body)Jetzt können wir mithilfe von CSS-Selektoren die erforderlichen Daten von der Seite abrufen:
titles = doc.css('h3 > a').map { |element| element('title') } prices = doc.css('div.product_price > p.price_color').map { |element| element.text.gsub("£", "") } images = doc.css('div.image_container > a').map { |element| element('href') } ratings = doc.css('p.star-rating').map { |element| element('class').split(' ').last } availabilities = doc.css('p.availability > i').map { |element| element('class').split('-').last }Wir haben die Informationen, über die wir verfügen, mithilfe von Taktiken verbessert, um Probleme anzugehen, auf die wir zuvor gestoßen sind. Zu Beginn haben wir eine Funktion namens { |element| verwendet element(‚Attribute‘) }, das „Attribute“ durch den Namen eines Attributs ersetzt, auf dessen Inhalt Sie zugreifen möchten. Dadurch können wir den Attributinhalt jedes Elements anstelle von Text abrufen.
Anschließend haben wir den Befehl gsub(„£“, „“) verwendet, um jedes Element im Preisarray zu bereinigen. Wir müssen das Nummernzeichen entfernen, da es beim Speichern der Daten in einer Datei falsch angezeigt wird. Schließlich haben wir split(„“) verwendet, um die Bewertungs- und Verfügbarkeits-Arrays in zwei Teile zu trennen. Wir haben dann .last für jedes Array verwendet, sodass nur der zweite Teil übrig blieb.
Wie wir sehen, ist die Verwendung von Nokogiri recht einfach und wird selbst Anfängern keine Schwierigkeiten bereiten.
Mehrere Seiten kratzen
Nachdem wir nun wissen, wie man Daten aus einer einzelnen Seite extrahiert, wollen wir damit Informationen von jeder Seite der Website sammeln. Schließlich ist das Erstellen von Scrapern normalerweise nicht nur für eine Seite gedacht; Sie werden häufig zum Durchsuchen einer gesamten Website oder eines Online-Shops verwendet.
Leider können wir mit Nokogiri nicht durch Drücken der Taste zur nächsten Seite wechseln. Wir können jedoch das Muster ermitteln, nach dem Links auf der Website erstellt werden, und vorschlagen, wie die folgenden Seiten aussehen werden.
Schauen Sie sich dazu die Seitenlinks genau an:
https://books.toscrape.com/catalogue/page-1.html https://books.toscrape.com/catalogue/page-2.html ... https://books.toscrape.com/catalogue/page-50.htmlWie wir sehen können, ändert sich auf dieser Beispielseite nur die Seitenzahl. Insgesamt sind es 50 Seiten. Fügen wir den unveränderten Startteil in die Variable base_url ein:
base_url="https://books.toscrape.com/catalogue/page-"Außerdem haben wir für alle Anfragen einen konstanten Benutzeragenten:
headers = { 'User-Agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' }Schließlich müssen wir die Anzahl der Seiten und die Variable festlegen, in der die Daten aller Seiten gespeichert werden:
total_pages = 50 data = ()Eigentlich könnten wir unseren Scraper auf die nächste Stufe bringen und müssten nicht manuell angeben, wie viele Seiten es gibt. Stattdessen können wir Code verwenden, der die Anzahl der Seiten von der Seite selbst abruft, oder eine Schleife ausführen, bis der Fehler „404 Nicht gefunden“ auftritt. In diesem Fall ist eine solche Codekomplikation jedoch nicht erforderlich, da die Links eine klare Struktur haben und leicht vorhersehbar sind.
Erstellen wir nun eine Schleife, um jede Seite durchzugehen und den entsprechenden Link zu generieren. Die Anzahl der Iterationen in der Schleife entspricht der Seitenzahl. Beispielsweise erstellen wir beim ersten Durchlauf der Schleife einen Link für die erste Seite; bei der zweiten Iteration – zweite Seite; und so weiter:
(1..total_pages).each do |page| url = "#{base_url}#{page}.html" response = HTTParty.get(url, headers: headers) doc = Nokogiri::HTML(response.body) endCSS-Selektoren und abrufbare Variablen bleiben unverändert. Kommen wir also dazu, die Daten in einen Hash einzufügen:
page_data = titles.zip(prices, images, ratings, availabilities).map do |title, price, image, rating, availability| { title: title, price: price, image: image, rating: rating, availability: availability } endAbschließend fügen wir die Daten am Ende ein Daten Variable, die wir zu Beginn erstellt haben:
data.concat(page_data)Außerdem wird empfohlen, eine zufällige Verzögerung hinzuzufügen, um die Wahrscheinlichkeit einer Umgehung der Blockierung zu erhöhen:
sleep(rand(1..3))Speichern Sie die Daten nach dem Ausführen des Zyklus in einer CSV-Datei:
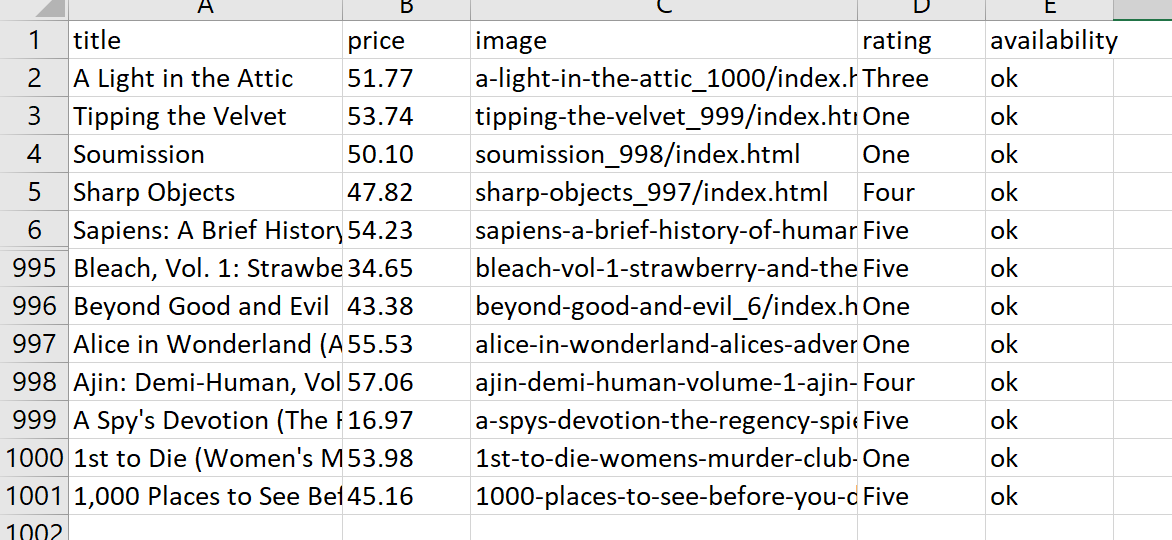
CSV.open('book_data.csv', 'w', col_sep: ";") do |csv| csv << data.first.keys # Write the headers data.each { |hash| csv << hash.values } # Write the data rows endInfolgedessen umgeht unser Skript alle Seiten, sammelt Daten und fügt sie in eine CSV-Datei ein:
Vollständiger Code:
require 'httparty' require 'nokogiri' require 'csv' base_url="https://books.toscrape.com/catalogue/page-" headers = { 'User-Agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' } total_pages = 50 data = () (1..total_pages).each do |page| url = "#{base_url}#{page}.html" response = HTTParty.get(url, headers: headers) doc = Nokogiri::HTML(response.body) # Extracting data titles = doc.css('h3 > a').map { |element| element('title') } prices = doc.css('div.product_price > p.price_color').map { |element| element.text.gsub("£", "") } images = doc.css('div.image_container > a').map { |element| element('href') } ratings = doc.css('p.star-rating').map { |element| element('class').split(' ').last } availabilities = doc.css('p.availability > i').map { |element| element('class').split('-').last } # Combine the extracted data into an array of hashes page_data = titles.zip(prices, images, ratings, availabilities).map do |title, price, image, rating, availability| { title: title, price: price, image: image, rating: rating, availability: availability } end data.concat(page_data) sleep(rand(1..3)) end # Save the data to a CSV file CSV.open('book_data.csv', 'w', col_sep: ";") do |csv| csv << data.first.keys # Write the headers data.each { |hash| csv << hash.values } # Write the data rows end puts 'Data saved to book_data.csv'Wie wir sehen, können sogar die Fähigkeiten der Nokogiri-Bibliothek zum Scrapen von Websites ausreichen.
Web Scraping mit Mechanize
Mechanize ist eine umfassende Bibliothek für Web Scraping. Damit benötigen Sie keine zusätzlichen Bibliotheken – alle notwendigen Tools sind im Lieferumfang enthalten. Sie können Mechanize sowohl zum Senden von Abfragen als auch zum Verarbeiten der Ergebnisse verwenden.
Um die Mechanize-Bibliothek zu verwenden, verbinden wir sie in unserer Datei:
require 'mechanize'Wir können auch die integrierten Funktionen der Bibliothek verwenden, um die Anfrage auszuführen:
agent = Mechanize.new page = agent.get('https://books.toscrape.com/catalogue/page-1.html')Mit den gleichen CSS-Selektoren wie zuvor können Sie mit Mechanize auf die Daten zugreifen und diese extrahieren:
titles = page.css('h3 > a').map { |element| element('title') } prices = page.css('div.product_price > p.price_color').map { |element| element.text.gsub("£", "") } images = page.css('div.image_container > a').map { |element| element('href') } ratings = page.css('p.star-rating').map { |element| element('class').split(' ').last } availabilities = page.css('p.availability > i').map { |element| element('class').split('-').last }Ansonsten ist die Verwendung dieser Bibliothek dasselbe wie die Verwendung von Nokogiri.
Kategorien mit Mechanize abrufen
Nehmen wir an, wir möchten Daten aus verschiedenen Kategorien sammeln. Wir beginnen mit einem Durchlauf durch jede Kategorie und gehen dann zu den einzelnen Seiten innerhalb dieser Kategorie über. Für jedes Produkt speichern wir es zusammen mit der zugehörigen Kategoriebezeichnung in einer Tabelle.
Gehen Sie zunächst zur Startseite und rufen Sie die Namen und Links aller Kategorien ab:
base_url="https://books.toscrape.com" category_links = () category_names = () product_data = () agent = Mechanize.new agent.user_agent_alias="Mac Safari" # Set the User-Agent header page = agent.get(base_url) page.css('div.side_categories > ul > li > ul > li > a').each do |element| category_links << element('href') category_names << element.text.gsub(" ", "").strip endHier haben wir gsub() verwendet, um zusätzliche Leerzeichen zu entfernen, und strip, um leere Zeilen zu entfernen. Um alle Kategorien zu durchlaufen, verwenden wir eine Schleife:
category_links.each_with_index do |category_link, index| … endDie CSS-Selektoren bleiben gleich, wir werden sie also nicht duplizieren, aber der Hash wird sich ein wenig ändern, damit wir den Kategorienamen beibehalten können:
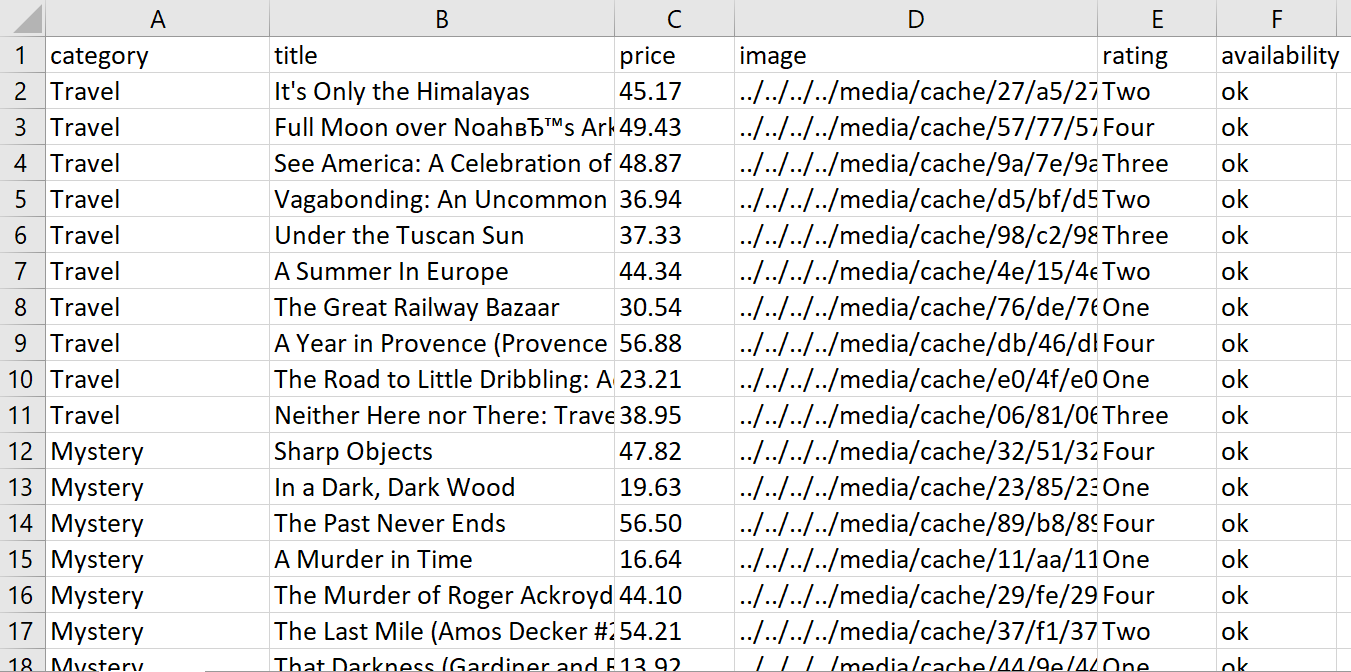
product_data << { category: category_names(index), title: title, price: price, image: image, rating: rating, availability: availability }Durch Ausführen unseres Skripts erhalten wir eine Datentabelle:
Vollständiger Code:
require 'mechanize' require 'csv' base_url="https://books.toscrape.com" category_links = () category_names = () product_data = () agent = Mechanize.new agent.user_agent_alias="Mac Safari" # Set the User-Agent header # Get category links and names page = agent.get(base_url) page.css('div.side_categories > ul > li > ul > li > a').each do |element| category_links << element('href') category_names << element.text.gsub(" ", "").strip end # Iterate over each category category_links.each_with_index do |category_link, index| category_url = "#{base_url}/#{category_link}" page = agent.get(category_url) # Scrape product data page.css('article.product_pod').each do |product| title = product.css('h3 > a').first('title') price = product.css('div.product_price > p.price_color').text.gsub("£", "") image = product.css('div.image_container > a > img').first('src') rating = product.css('p.star-rating').first('class').split(' ').last availability = product.css('p.availability > i').first('class').split('-').last product_data << { category: category_names(index), title: title, price: price, image: image, rating: rating, availability: availability } end sleep(rand(1..3)) # Add a random delay between requests end # Save the data to a CSV file CSV.open('book_data.csv', 'w', col_sep: ";") do |csv| csv << product_data.first.keys # Write the headers product_data.each { |hash| csv << hash.values } # Write the data rows end puts 'Data saved to book_data.csv'Zusammenfassend lässt sich sagen, dass es nicht allzu schwer ist, Produktdetails wie Kategorienamen zu extrahieren und in einer CSV-Datei zu speichern, wenn Sie die Mechanize-Bibliothek verwenden.
Scrapen Sie dynamische Daten mit Watir mithilfe eines Headless-Browsers
Das Watir-Framework unterscheidet sich von den anderen Scraping-Bibliotheken dadurch, dass es mit einem Headless-Browser verwendet werden kann. Das bedeutet, dass unser Code wie ein echter Benutzer agiert und eine größere Chance hat, nicht blockiert zu werden. Dies funktioniert, indem es uns ermöglicht, das Browserfenster ein- oder auszublenden und gleichzeitig auf alle seine Funktionen zuzugreifen, wie z. B. das Klicken auf Links und das Ausfüllen von Formularen.
Um zu beginnen, müssen wir einen Webtreiber installieren. Hierbei handelt es sich um eine Software, die uns hilft, mit dem Internet zu interagieren, um Daten zu extrahieren.
gem install webdriversFür dieses Tutorial verwenden wir den Chrome-Webtreiber, Sie können aber auch andere von Watir unterstützte Webtreiber wie Firefox oder Safari verwenden. Verbinden wir also die erforderlichen Bibliotheken und erstellen ein Browserobjekt:
require 'watir' require 'webdrivers' browser = Watir::Browser.new(:chrome)Für das gleiche Ergebnis können Sie auch Selen verwenden:
browser = Selenium::WebDriver::Chrome::Options.newDer Befehl goto() wird verwendet, um zu einer anderen Seite zu navigieren. Es kann zum schnellen Wechseln zwischen Seiten verwendet werden, während Sie Daten aus mehreren Quellen abrufen:
browser.goto(' https://books.toscrape.com/index.html')Scraping mit Watir hat einen großen Vorteil: Sie müssen bei der Abfrage keine zusätzlichen Parameter hinzufügen. Denn das Skript erstellt ein echtes Browserfenster und kümmert sich um alle Übergänge zwischen den Seiten, sodass es bereits alle notwendigen Informationen enthält.
Gehen Sie mit Watir zur nächsten Seite
Lassen Sie uns unseren bisherigen Code verbessern. Angenommen, wir möchten immer noch alle Artikel aus jeder Kategorie sammeln, aber dieses Mal gehen wir die Seiten dieser Kategorie so lange durch, bis es keinen „Weiter“-Button mehr gibt.
Sehen Sie sich die Schaltfläche „Weiter“ an:
Es speichert einen Link zur nächsten Seite und hat die Klasse „next“. Das heißt, wir können eine Schleife mit der folgenden Bedingung erstellen:
base_url="https://books.toscrape.com" loop do … next_link = browser.li(class: 'next').a break unless next_link.exists? browser.goto("#{base_url}/#{next_link.href}") endIndem wir eine Schleife in eine bestehende Kategorieschleife einbetten, können wir jede Seite in allen Kategorien schnell und effizient durchlaufen. Dadurch können wir die anstrengende Aufgabe umgehen, manuell durch jede Seite jeder Kategorie zu navigieren.
Der Datenzugriff mit Watir unterscheidet sich von den zuvor behandelten Bibliotheken, erleichtert jedoch die Interaktion mit Elementen in der DOM-Struktur (Document Object Model) erheblich. Erhalten Sie beispielsweise dieselben Daten wie zuvor:
product_data =() browser.articles(class: 'product_pod').each do |product| title = product.h3.a.title price = product.div(class: 'product_price').p(class: 'price_color').text.gsub('£', '') image = product.div(class: 'image_container').a.href rating = product.p(class: 'star-rating').class_name.split(' ').last availability = product.p(class: 'availability').i.class_name.split('-').last product_data << { category: category_names(index), title: title, price: price, image: image, rating: rating, availability: availability } endGeben Sie am Ende des Skripts unbedingt einen Befehl zum Schließen des Browsers an:
browser.quitVollständiger Code:
require 'watir' require 'webdrivers' require 'csv' base_url="https://books.toscrape.com" category_links = () category_names = () product_data = () # Launch a browser (in this case, Chrome) browser = Watir::Browser.new(:chrome) # Navigate to the main page browser.goto(base_url) # Get category links and names browser.div(class: 'side_categories').ul(class: 'nav').li(class: 'active').ul.lis.each do |li| link = li.a.href name = li.a.text.gsub(' ', '') category_links << link category_names << name end # Iterate over each category category_links.each_with_index do |category_link, index| category_url = "#{base_url}/#{category_link}" browser.goto(category_url) loop do # Scrape product data from the current page browser.articles(class: 'product_pod').each do |product| title = product.h3.a.title price = product.div(class: 'product_price').p(class: 'price_color').text.gsub('£', '') image = product.div(class: 'image_container').a.href rating = product.p(class: 'star-rating').class_name.split(' ').last availability = product.p(class: 'availability').i.class_name.split('-').last product_data << { category: category_names(index), title: title, price: price, image: image, rating: rating, availability: availability } end # Check if there's a "Next" link next_link = browser.link(class: 'next') break unless next_link.exists? # Navigate to the next page browser.goto(next_link.href) sleep(rand(1..3)) # Add a random delay between requests end end # Close the browser browser.quit # Save the data to a CSV file CSV.open('book_data.csv', 'w', col_sep: ';') do |csv| csv << product_data.first.keys # Write the headers product_data.each { |hash| csv << hash.values } # Write the data rows end puts 'Data saved to book_data.csv'Nachdem wir Watir in der Praxis verwendet haben, können wir sagen, dass es sich um eine leistungsstarke Ruby-Bibliothek handelt, die eine einfache Möglichkeit zur Automatisierung von Browserinteraktionen bietet.
Während es in Ruby andere Alternativen für Web Scraping gibt, wie etwa Nokogiri und Mechanize, bietet Watir eine umfassendere Lösung zur Automatisierung von Browserinteraktionen und bietet ein höheres Maß an Kontrolle über Web Scraping-Aufgaben.
Fazit und Erkenntnisse
Ruby macht Web Scraping zu einer großartigen Option für Entwickler, die schnell und genau große Datenmengen sammeln müssen. In diesem Artikel haben wir die verschiedenen Möglichkeiten zum Scrapen von Daten mit Ruby besprochen. Wir begannen mit den einfachsten Optionen wie der Abfragebibliothek und der Web-Scraping-API, bevor wir uns mit komplexeren Lösungen wie der Verwendung von Watir und Web-Treibern beschäftigten.
Denken Sie daran, bei der Entscheidung, welche Bibliothek oder Technik Sie verwenden möchten, Faktoren wie die Komplexität der Zielwebsite, die Notwendigkeit der JavaScript-Wiedergabe, die Anforderungen an die Browserautomatisierung und Ihre Vertrautheit mit der Bibliothek zu berücksichtigen.
Wenn Sie gerade erst mit Ruby beginnen, ist die Verwendung einer API für Web Scraping eine gute Option. Auf diese Weise müssen Sie sich nicht um komplizierte Dinge wie JavaScript-Rendering, CAPTCHA-Lösung, Verwendung von Proxys oder das Vermeiden von Blöcken kümmern. Wenn dies nicht der Fall ist und Sie etwas Einfaches benötigen, sind Nokogiri oder Mechanize ideal zum Scrapen statischer Ressourcen. Wenn Sie jedoch erweiterte Funktionen benötigen – beispielsweise die Möglichkeit, echtes Benutzerverhalten auf einer Seite zu emulieren – dann sind Watir und Webdriver (oder ähnliches, zum Beispiel Ruby on Rails) die beste Wahl.