
Das Extrahieren von Daten aus Websites ist in verschiedenen Bereichen unverzichtbar geworden, von der Datenerfassung bis zur Wettbewerbsanalyse. Herkömmliche Web-Scraping-Methoden erfordern häufig das Laden eines vollständigen Browsers, was aufgrund der Darstellung von UI-Elementen wie Symbolleisten und Schaltflächen erhebliche Ressourcen und Zeit in Anspruch nehmen kann. Hier kommen Headless-Browser-Automatisierungstools wie Puppeteer ins Spiel.
In diesem ausführlichen Blog befassen wir uns mit der Verwendung von Puppeteer für das Web-Scraping. Wir werden seine Vorteile, das Scraping einzelner und mehrerer Seiten, die Fehlerbehandlung, das Klicken auf Schaltflächen, das Senden von Formularen und wichtige Techniken wie die Nutzung von Anforderungsheadern und Proxys zur Umgehung der Erkennung untersuchen. Darüber hinaus erfahren Sie, warum Web-Scraping-APIs die besten Optionen für effizientes Scraping im großen Maßstab sind.
Warum Puppeteer für Web Scraping verwenden?
Puppeteer ist ein Browser-Automatisierungstool, das es Entwicklern ermöglicht, einen Browser programmgesteuert über eine High-Level-API zu steuern und dabei das DevTools-Protokoll zu nutzen.
Browsersteuerung
Puppeteer bietet eine ausgefeilte Kontrolle über Browseraktionen und ermöglicht die Interaktion mit Elementen wie Schaltflächen und Formularen, das Scrollen von Seiten sowie Funktionen wie das Aufnehmen von Screenshots oder das Ausführen von benutzerdefiniertem JavaScript.
Unterstützung für Headless-Browser
Standardmäßig arbeitet Puppeteer im Headless-Modus, was bedeutet, dass es ohne grafische Oberfläche ausgeführt wird, was die Geschwindigkeit und Speichereffizienz erhöht. Es kann jedoch auch so konfiguriert werden, dass es in einem vollständigen („kopfreichen“) Chrome/Chromium-Fenster ausgeführt wird. Es verwendet standardmäßig den Chromium-Browser, kann aber auch so konfiguriert werden, dass Chrome oder Firefox mit den inoffiziellen Bibliotheken verwendet werden.
Robuste API
Puppeteer bietet eine High-Level-API für die nahtlose Steuerung und Interaktion mit Webseiten über Code und ermöglicht die Elementinteraktion, Webseitenmanipulation und seitenübergreifende Navigation.
Abfangen von Netzwerkanfragen
Puppeteer bietet erweiterte Funktionen wie das Abfangen und Ändern von Netzwerkanfragen. Sie können die Details jeder Anfrage anzeigen, z. B. URL, Header und Text, und die Antworten analysieren. Diese Funktionalität ermöglicht die dynamische Extraktion von Inhalten und die Änderung von API-Antworten.
Benutzerfreundlichkeit
Puppeteer ist bekannt für seine Flexibilität und Benutzerfreundlichkeit. Es vereinfacht Web-Scraping- und Automatisierungsaufgaben und macht es auch für Entwickler mit minimaler Erfahrung in diesen Bereichen zugänglich.
Vorbereitung der Umgebung
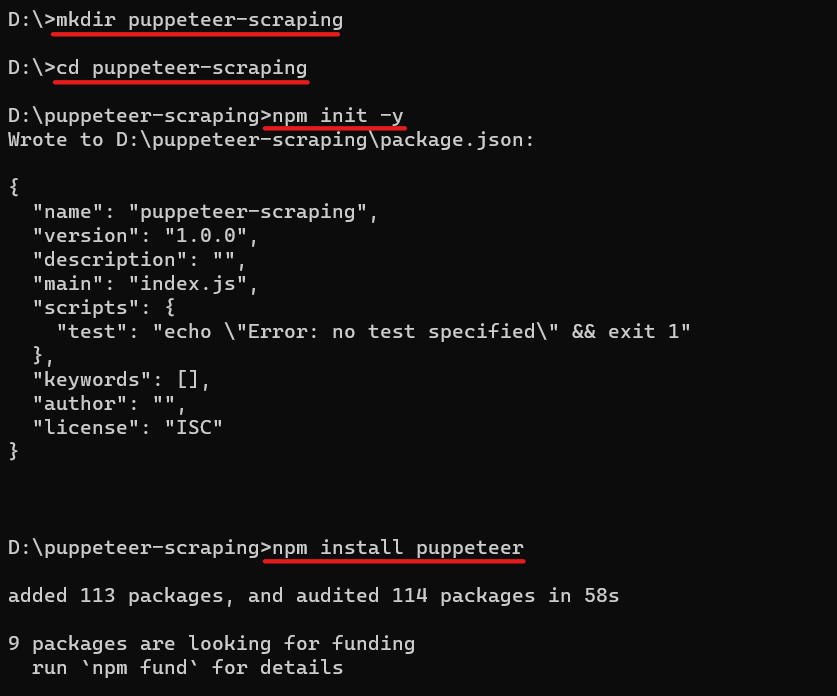
Bevor wir uns mit dem Schaben befassen, bereiten wir unsere Umgebung vor. Laden Sie Node.js von der offiziellen Website herunter und installieren Sie es, falls Sie dies noch nicht getan haben. Erstellen Sie dann bitte ein neues Verzeichnis für Ihr Projekt, navigieren Sie dorthin und initialisieren Sie ein Node.js-Projekt, indem Sie es ausführen npm init. Der npm init -y Der Befehl erstellt eine package.json Datei mit allen Abhängigkeiten.
mkdir puppeteer-scraping
cd puppeteer-scraping
npm init -yJetzt können Sie Puppeteer mit NPM (Node Package Manager) installieren. So installieren Sie Puppeteer mit NPM: Navigieren Sie mit zu Ihrem Projektverzeichnis cd Befehl und führen Sie den folgenden Befehl aus:
npm install puppeteerDieser Befehl lädt Puppeteer herunter und fügt es als Abhängigkeit zu Ihrem Projekt und einem dedizierten Browser hinzu, den es verwendet (Chromium).
So sieht der komplette Prozess aus:
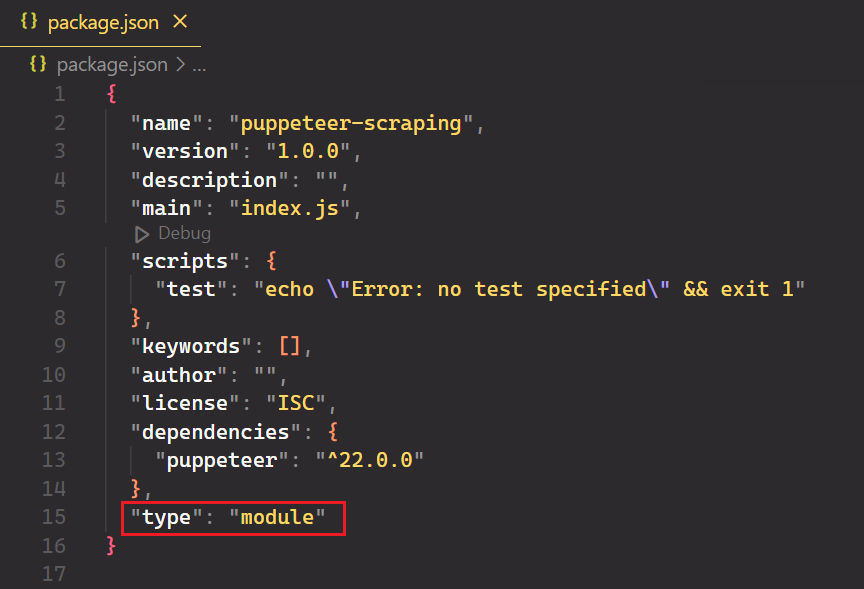
Öffnen Sie das Projekt in Ihrem bevorzugten Code-Editor und erstellen Sie eine neue Datei mit dem Namen index.js. Öffnen Sie abschließend die package.json Datei hinzufügen und hinzufügen "type": "module" zur Unterstützung moderner JavaScript-Syntax.
Scraping-Grundlagen mit Puppeteer
Nachdem Ihre Umgebung nun eingerichtet ist, beginnen wir mit dem einfachen Web-Scraping mit Puppeteer. Sie können alles, was Sie normalerweise manuell tun, im Browser tun, vom Erstellen von Screenshots bis zum Crawlen mehrerer Seiten.
Auswählen der Daten zum Scrapen
Wir werden Daten aus GitHub-Themen extrahieren. Auf diese Weise können Sie das Thema und die Anzahl der Repositorys auswählen, die Sie extrahieren möchten. Der Scraper gibt dann die mit dem ausgewählten Thema verknüpften Informationen zurück.
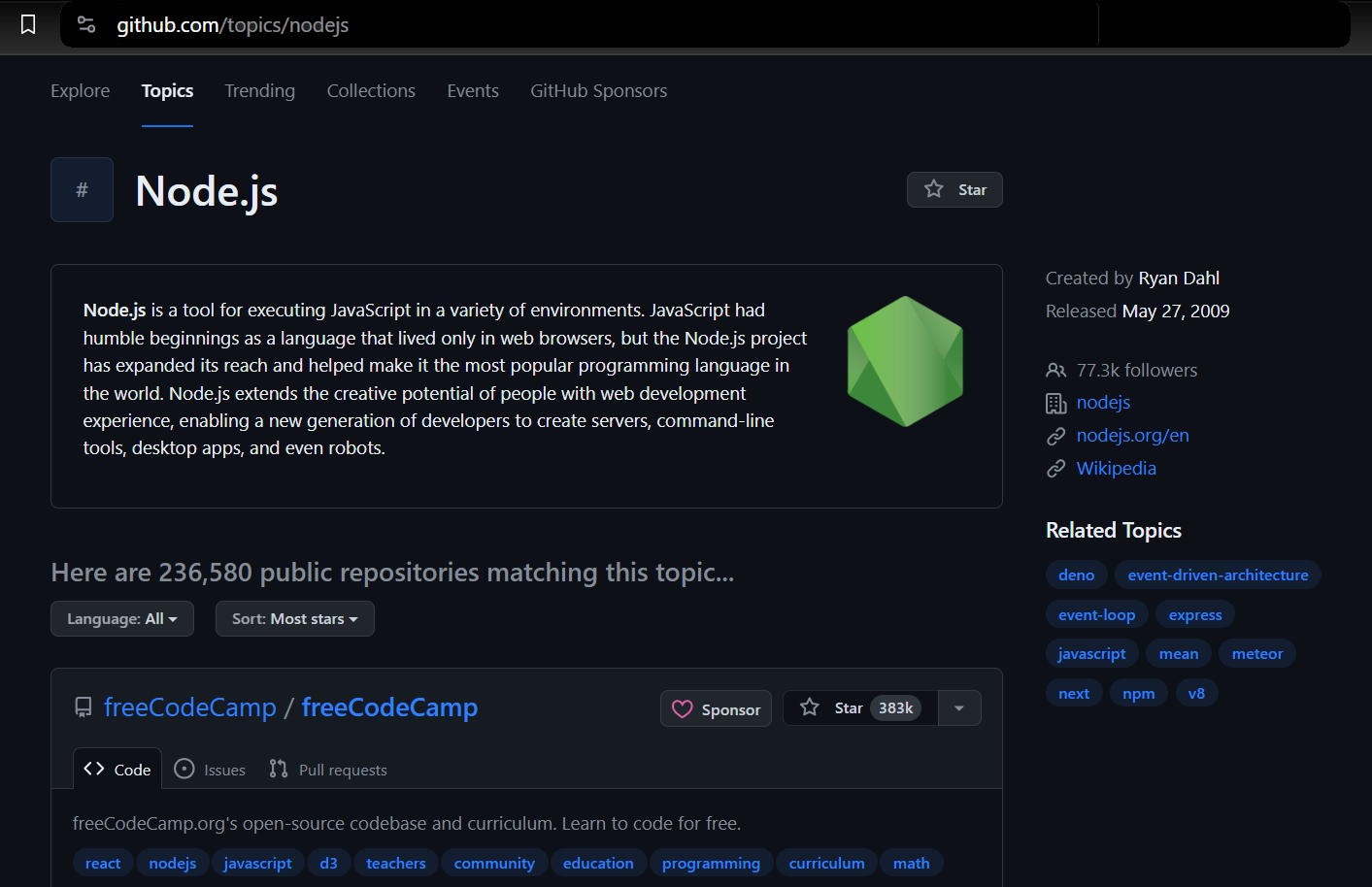
Wir verwenden Puppeteer, um einen Browser zu starten, zur GitHub-Themenseite zu navigieren und die erforderlichen Informationen zu extrahieren. Dazu gehören Details wie der Repository-Eigentümer, der Repository-Name, die Repository-URL, die Anzahl der Sterne des Repositorys, seine Beschreibung und alle zugehörigen Tags.
Navigieren zu einer Seite
Um zu beginnen, müssen Sie mit Puppeteer ein neues Browserfenster öffnen und eine bestimmte URL aufrufen. Im folgenden Codeausschnitt ist der puppeteer.launch() Funktion startet eine neue Browserinstanz und browser.newPage() erstellt eine neue Seite innerhalb dieser Instanz. Der page.goto() Die Funktion navigiert dann zur angegebenen URL.
import puppeteer from "puppeteer";
const browser = await puppeteer.launch({
headless: true,
defaultViewport: null
});
const page = await browser.newPage();
await page.goto('<https://github.com/topics/nodejs>');Screenshot-Erfassung von Webseiten
Mit Puppeteer können Sie Screenshots von Webseiten aufnehmen. Diese Funktion ist für die visuelle Überprüfung wertvoll, da sie es Ihnen ermöglicht, den Schnappschuss zu jedem Zeitpunkt zu erfassen.
import puppeteer from "puppeteer";
const browser = await puppeteer.launch({
headless: true,
defaultViewport: null
});
const page = await browser.newPage();
await page.goto('<https://github.com/topics/nodejs>');
await page.screenshot({ path: 'Images/screenshot.png' });
await browser.close();Um die gesamte Seite zu erfassen, legen Sie fest fullPage Eigentum zu true. Sie können auch das Bildformat ändern jpg oder jpeg zum Speichern in verschiedenen Formaten.
await page.screenshot({ path: 'Images/screenshot.jpg', fullPage: true });Scraping einer einzelnen Seite
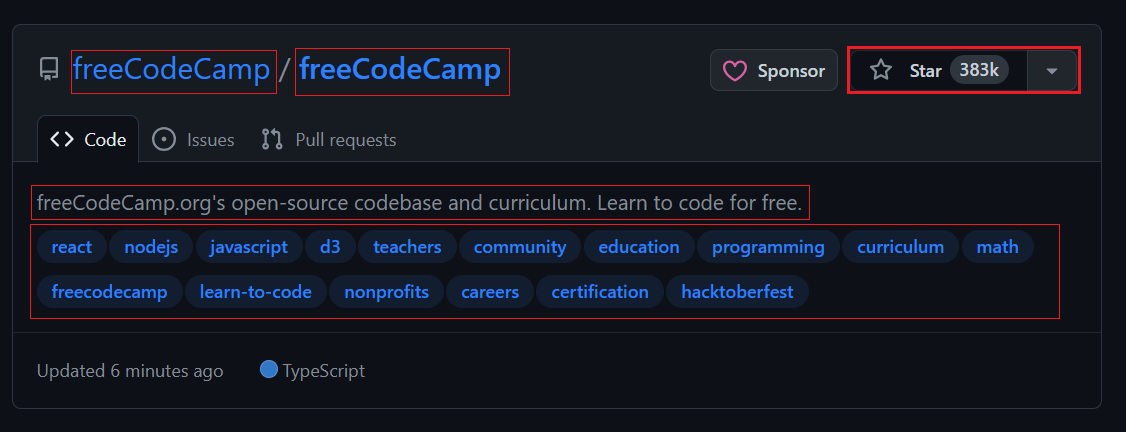
Wenn Sie die Themenseite öffnen, sehen Sie 20 Repositorys. Jeder Eintrag wird als angezeigt <article> -Element zeigt Informationen zu einem bestimmten Repository an. Sie können jedes Element erweitern, um detailliertere Informationen zum entsprechenden Repository anzuzeigen.
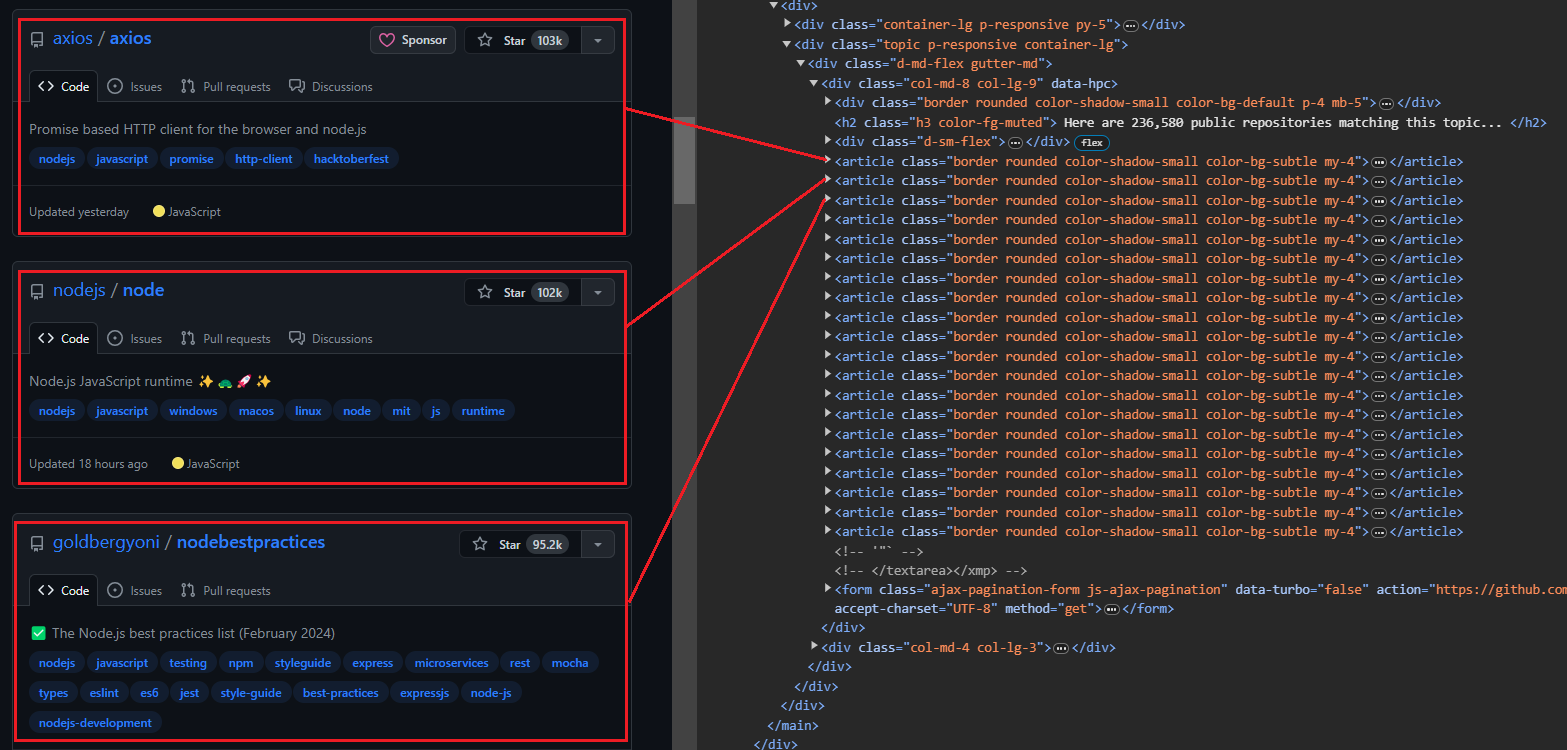
Das Bild unten zeigt eine erweiterte Darstellung <article> Element, das alle Informationen über das Repository anzeigt.
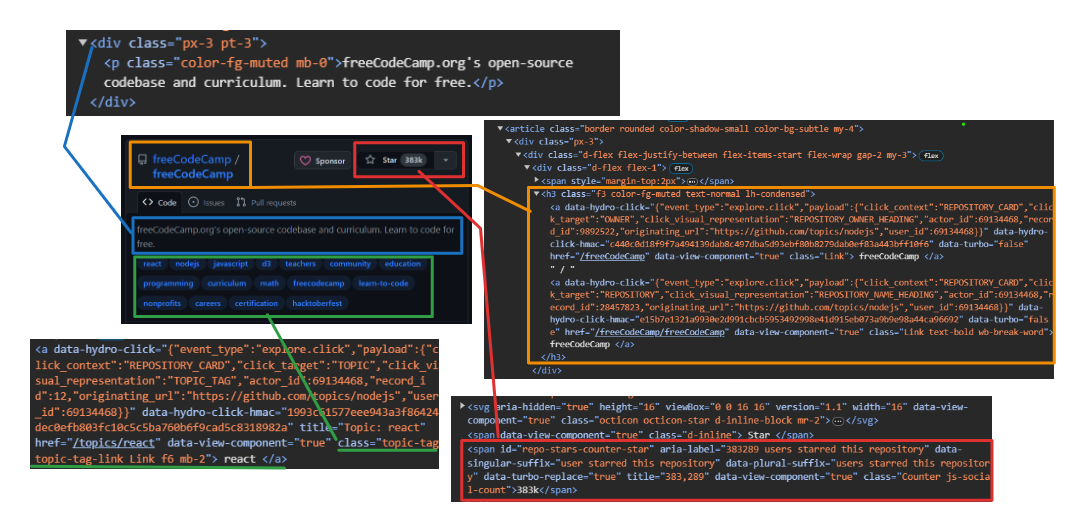
Extrahieren von Benutzer- und Repository-Informationen:
- Benutzer: Verwenden
h3 > a:first-childum das erste Anker-Tag direkt innerhalb von a anzusprechen<h3>Etikett. - Repository-Name: Zielen Sie auf das zweite untergeordnete Element desselben
<h3>Elternteil. Dieses Kind enthält sowohl den Namen als auch die URL. Benutzen Sie dietextContentEigenschaft zum Extrahieren des Namens und dergetAttribute('href')Methode zum Extrahieren der URL. - Anzahl Sterne: Verwenden
#repo-stars-counter-starum das Element auszuwählen und die tatsächliche Zahl daraus zu extrahierentitleAttribut. - Repository-Beschreibung: Verwenden
div.px-3 > pum den ersten Absatz innerhalb von a auszuwählendivmit der Klassepx-3. - Repository-Tags: Verwenden
a.topic-tagum alle Ankertags mit der Klasse auszuwählentopic-tag.
Der querySelector wählt das erste Element aus, das einem bestimmten CSS-Selektor in einem Dokument oder Element entspricht querySelectorAll wählt alle Elemente aus, die einem Selektor entsprechen.
Hier ist ein Codeausschnitt:
repos.forEach(repo => {
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());
});Sehen wir uns den gesamten Prozess zum Extrahieren aller Repositorys von einer einzelnen Seite an.
Der Prozess beginnt mit dem page.evaluate Methode, die JavaScript auf der Seite ausführt. Dies ist nützlich, um Daten zu extrahieren, ohne den gesamten HTML-Inhalt herunterzuladen. Wir definieren alle Variablen und Selektoren innerhalb dieser Methode.
const repos = await page.evaluate(() => { ... });Wählt dann alle Elemente mit der Klasse aus border innerhalb der article Tag und wandelt sie in ein Array namens repos. Erstellen Sie außerdem ein leeres Array mit dem Namen repoData um die extrahierten Informationen zu speichern.
const repos = Array.from(document.querySelectorAll('article.border'));
const repoData = ();Durchläuft jedes Element im repos Array, um alle relevanten Daten für jedes Repository mithilfe der bereitgestellten Selektoren zu extrahieren.
repos.forEach(repo => { ... });Abschließend werden die extrahierten Daten für jedes Repository dem hinzugefügt repoData Array, und das Array wird zurückgegeben.
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });Hier ist der Code für alle oben genannten Schritte.
const extractedRepos = await page.evaluate(() => {
const repos = Array.from(document.querySelectorAll('article.border'));
const repoData = ();
repos.forEach(repo => {
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
return repoData;
});Hier ist der vollständige Code. Mit diesem Code können Sie ganz einfach Daten von einer einzelnen Seite erfassen. Führen Sie es einfach aus und genießen Sie die Ergebnisse!
// Import the Puppeteer library
import puppeteer from "puppeteer";
(async () => {
// Launch a headless browser
const browser = await puppeteer.launch({ headless: true });
// Open a new page
const page = await browser.newPage();
// Navigate to the Node.js topic page on GitHub
await page.goto('<https://github.com/topics/nodejs>');
const extractedRepos = await page.evaluate(() => {
// Select all repository elements
const repos = Array.from(document.querySelectorAll('article.border'));
// Create an empty array to store extracted data
const repoData = ();
// Loop through each repository element
repos.forEach(repo => {
// Extract specific details from the repository element
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());
// Add extracted data to the main array
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
// Return the extracted data
return repoData;
});
console.log(`We extracted ${extractedRepos.length} repositories.\\n`);
// Print the extracted data to the console
console.dir(extractedRepos, { depth: null }); // Show all nested data
// Close the browser
await browser.close();
})();Das Ergebnis ist:
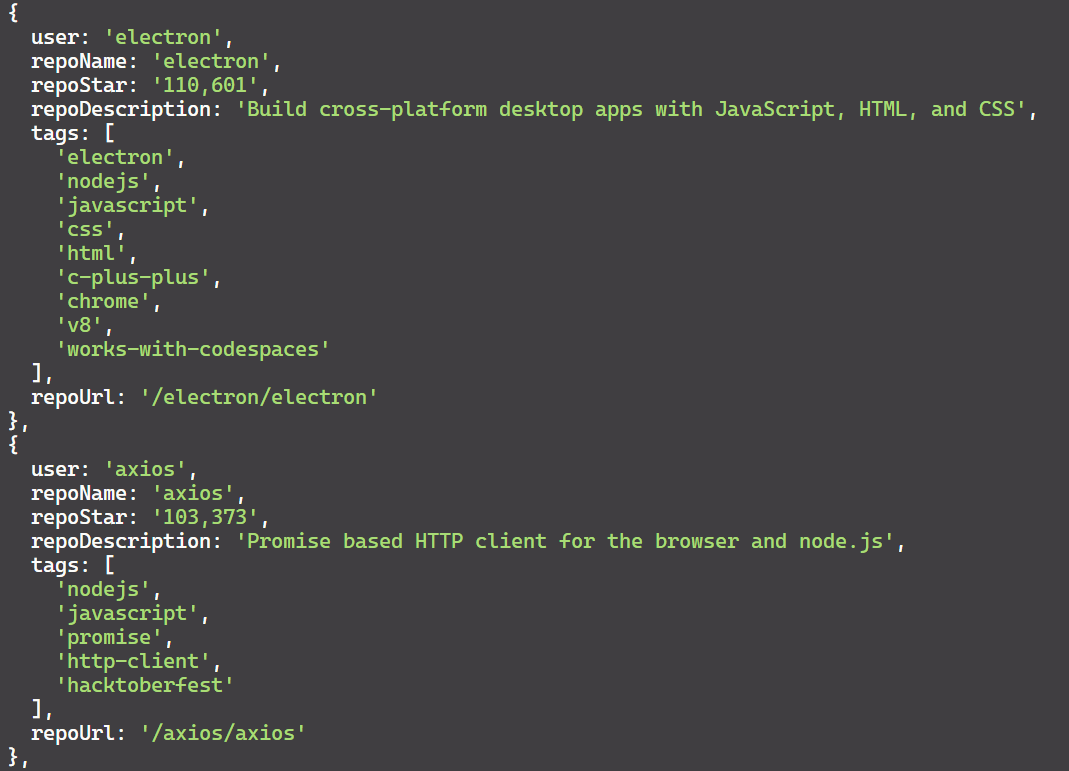
Wenn Sie über Puppeteer hinaus mehr über Web Scraping mit Node.js erfahren möchten, könnte Ihnen unser umfassender Leitfaden zum Web Scraping mit Node.js hilfreich sein. In diesem Artikel werden zusätzliche Bibliotheken und Techniken zur Verbesserung Ihrer Scraping-Funktionen mit Node.js behandelt.
Fortgeschrittene Schabetechniken
Wir haben die einzelne Seite erfolgreich gelöscht. Kommen wir nun zum fortgeschrittenen Scraping mit Puppeteer. Sie können auf Schaltflächen klicken, Formulare ausfüllen, mehrere Seiten crawlen und Header und Proxys drehen, um Ihr Scraping zuverlässiger zu machen.
Auf Schaltflächen klicken und auf Aktionen warten
Sie können weitere Repositorys laden, indem Sie unten auf der Seite auf die Schaltfläche „Mehr laden…“ klicken. Hier sind die Aktionen, mit denen Puppeteer angewiesen wird, weitere Repositorys zu laden:
- Warten Sie, bis die Schaltfläche „Mehr laden…“ angezeigt wird.
- Klicken Sie auf die Schaltfläche „Mehr laden…“.
- Warten Sie, bis die neuen Repositorys geladen sind, bevor Sie fortfahren.
Das Klicken auf Schaltflächen mit Puppeteer ist unkompliziert! Stellen Sie Ihrer Suche einfach voran "text/" gefolgt vom gesuchten Text. Puppeteer sucht dann das Element, das diesen Text enthält, und klickt darauf.
const buttonSelector = "text/Load more";
await page.waitForSelector(buttonSelector);
await page.click(buttonSelector);Crawlen mehrerer Seiten
Um mehrere Seiten zu crawlen, müssen Sie wiederholt auf die Schaltfläche „Mehr laden“ klicken, bis Sie das Ende erreicht haben. Wir können jedoch Code schreiben, um diesen Prozess zu automatisieren und eine bestimmte Anzahl von gewünschten Repositorys zu durchsuchen. Stellen Sie sich zum Beispiel vor, dass es 10.000 Repositorys für „nodejs“ gibt und Sie nur Daten für 1.000 davon extrahieren möchten.
So crawlt das Skript mehrere Seiten:
- Öffnen Sie die Themenseite „nodejs“ auf GitHub.
- Erstellen Sie einen leeren Satz zum Speichern eindeutiger Repository-Dateneinträge.
- Warten Sie auf das
article.borderZu ladendes Element, das das Vorhandensein von Repositorys anzeigt. - Verwenden Sie Puppenspieler
evaluateFunktion zum Extrahieren von Daten aus jedem Repository. - Überprüfen Sie mithilfe des JSON-String-Vergleichs, ob die extrahierten Daten bereits im Satz vorhanden sind. Wenn es einzigartig ist, fügen Sie es dem Set hinzu.
- Wenn die festgelegte Größe die gewünschte Anzahl von Repositorys erreicht (in diesem Fall 30), beenden Sie die Iteration.
- Versuchen Sie andernfalls, die Schaltfläche „Mehr laden“ zu finden und darauf zu klicken, um zur nächsten Seite mit Repositorys zu navigieren.
Hier ist der Code:
import puppeteer from "puppeteer";
import { exit } from "process";
async function scrapeData(numRepos) {
try {
// Launch headless browser with default viewport
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Navigate to nodejs
await page.goto("<https://github.com/topics/nodejs>");
// Use a Set to store unique entries efficiently
let uniqueRepos = new Set();
// Flag to track if there are more repos to load
let hasMoreRepos = true;
while (hasMoreRepos && uniqueRepos.size < numRepos) {
try {
// Extract data from repositories
const extractedData = await page.evaluate(() => {
const repos = document.querySelectorAll("article.border");
const repoData = ();
repos.forEach((repo) => {
const userLink = repo.querySelector("h3 > a:first-child");
const repoLink = repo.querySelector("h3 > a:last-child");
const user = userLink.textContent.trim();
const repoName = repoLink.textContent.trim();
const repoStar = repo.querySelector("#repo-stars-counter-star").title;
const repoDescription = repo.querySelector("div.px-3 > p")?.textContent.trim() || "";
const tags = Array.from(repo.querySelectorAll("a.topic-tag")).map((tag) => tag.textContent.trim());
const repoUrl = repoLink.href;
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
return repoData;
});
extractedData.forEach((entry) => uniqueRepos.add(JSON.stringify(entry)));
// Check if enough repos have been scraped
if (uniqueRepos.size >= numRepos) {
uniqueRepos = Array.from(uniqueRepos).slice(0, numRepos);
hasMoreRepos = false;
break;
}
// Click "Load more" button if available
const buttonSelector = "text/Load more";
const button = await page.waitForSelector(buttonSelector, { timeout: 5000 });
if (button) {
await button.click();
} else {
console.log("No more repos found. All data scraped.");
hasMoreRepos = false;
}
} catch (error) {
console.error("Error while extracting data:", error);
exit(1);
}
}
// Convert unique entries to an array and format JSON content
const uniqueList = Array.from(uniqueRepos).map((entry) => JSON.parse(entry));
console.dir(uniqueList, { depth: null });
await browser.close();
} catch (error) {
console.error("Error during scraping process:", error);
exit(1);
}
}
scrapeData(30);Ausfüllen von Formularen und Simulieren von Benutzerinteraktionen
Wir werden zwei wichtige Puppeteer-Funktionen verwenden: type um die Abfrage einzugeben und press Um das Formular abzuschicken, drücken Sie die Eingabetaste.
import puppeteer from "puppeteer";
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('<https://youtube.com/>');
const input = await page.$('input(id="search")');
await input.type('nasa');
await page.keyboard.press('Enter');
await page.waitForSelector('ytd-video-renderer');
await page.screenshot({ path: 'youtube_search_image.png' });
await browser.close();
})();Im obigen Code:
- Gebraucht
page.$('input(id="search")')um das Suchleistenelement zu finden. - Drücken Sie die „Enter“-Taste mit
page.keyboard.press('Enter'). - Wartete auf das Vorhandensein eines Elements in der Klasse
ytd-video-rendererwas darauf hinweist, dass Suchergebnisse geladen wurden. - Zum Schluss habe ich einen Screenshot gemacht.
Das Ausgabebild ist:
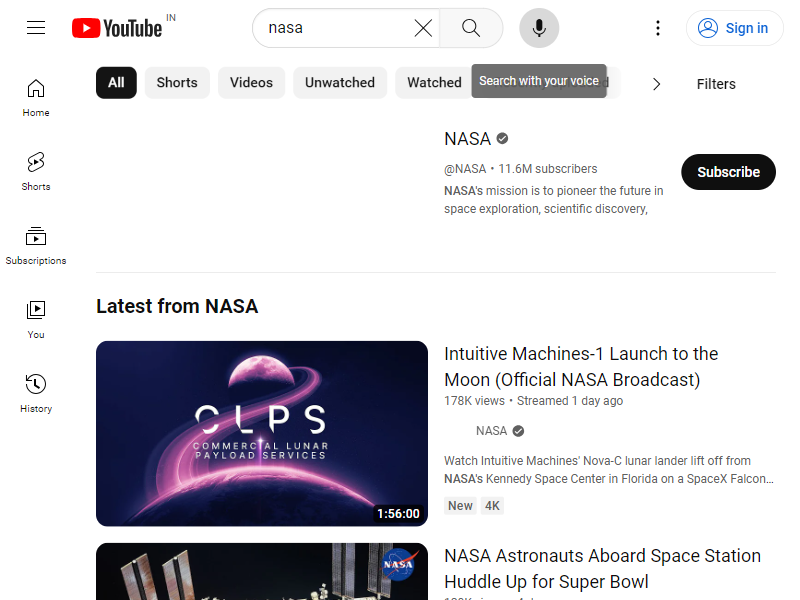
Um die Benutzerinteraktion zu simulieren, klicken wir mit Puppeteer auf die Registerkarte „Shorts“. mouse.click(x, y) Methode, die das Klicken auf bestimmte Bildschirmkoordinaten ermöglicht.
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto("<https://youtube.com/>");
// Wait for the search input element with ID "search"
await page.waitForSelector('input(id="search")');
// Type "nasa channel" into the search input
await page.type('input(id="search")', "nasa channel");
// Press Enter to submit the search
await page.keyboard.press("Enter");
// Wait for the channel title element with ID "channel-title"
await page.waitForSelector('#channel-title');
// Click the mouse at coordinates (200, 80)
await page.mouse.click(200, 80);
// Wait for a video renderer element
await page.waitForSelector('ytd-video-renderer');
// Take a screenshot
await page.screenshot({ path: "shorts.png" });
// Close the browser
await browser.close();
})();Der Tab „Shorts“ wurde erfolgreich angeklickt.
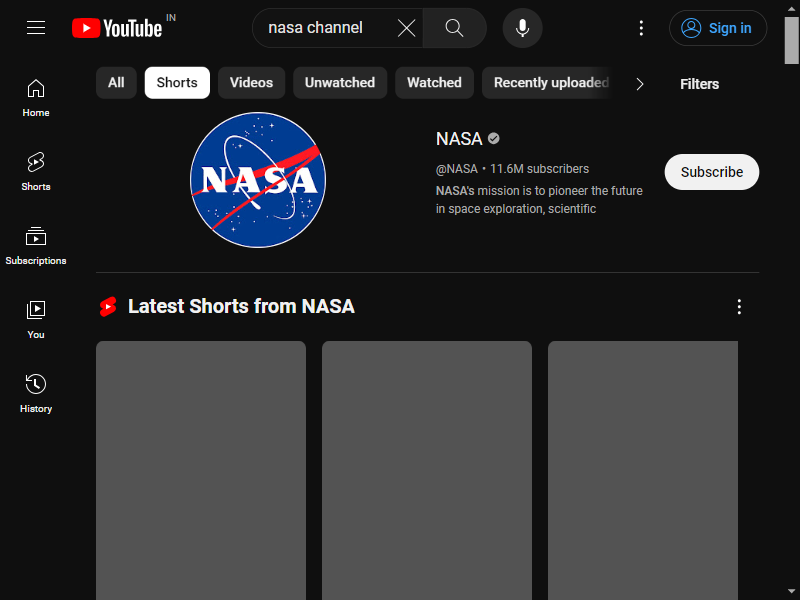
Puppeteer bietet verschiedene Methoden zur Mausinteraktion, wie z mouse.drop(), mouse.reset(), mouse.drag()Und mouse.move(). Erfahren Sie hier mehr über diese Methoden.
Anforderungsheader sind entscheidend dafür, wie Server Ihre Anforderungen verarbeiten und darauf reagieren. In Puppeteer ist die häufigste Methode zum Festlegen benutzerdefinierter Header für alle Anforderungen die setExtraHTTPHeaders() Methode.
Legen Sie zunächst die Header fest, die Sie verwenden möchten.
const requestHeaders = {
'referer': 'www.google.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'max-age=0',
'accept-encoding': 'gzip, deflate, br',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
};Diese Header enthalten Informationen über den Browser, bevorzugte Inhaltsformate, Spracheinstellungen und vor allem den Benutzeragenten. Diese Informationen helfen dem Server, dem Benutzer die am besten geeignete Antwort zu liefern. Standardmäßig sendet Puppeteer HeadlessChrome als Benutzeragent.
Hier ist der vollständige Code:
import puppeteer from 'puppeteer';
const requestHeaders = {
'referer': 'www.google.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'max-age=0',
'accept-encoding': 'gzip, deflate, br',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
};
(async () => {
const browser = await puppeteer.launch({
headless: true,
});
const page = await browser.newPage();
// Set extra HTTP headers
await page.setExtraHTTPHeaders({ ...requestHeaders });
await page.goto('<https://httpbin.io/headers>');
const content = await page.evaluate(() => document.body.textContent);
console.log(content);
await browser.close()
})();Die Ausgabe von Puppeteer bestätigt, dass die Anforderungsheader erfolgreich geändert wurden. Die Konsolenprotokolle zeigen, dass der „User-Agent“-Header aktualisiert wurde und auch andere relevante Parameter aktualisiert wurden.
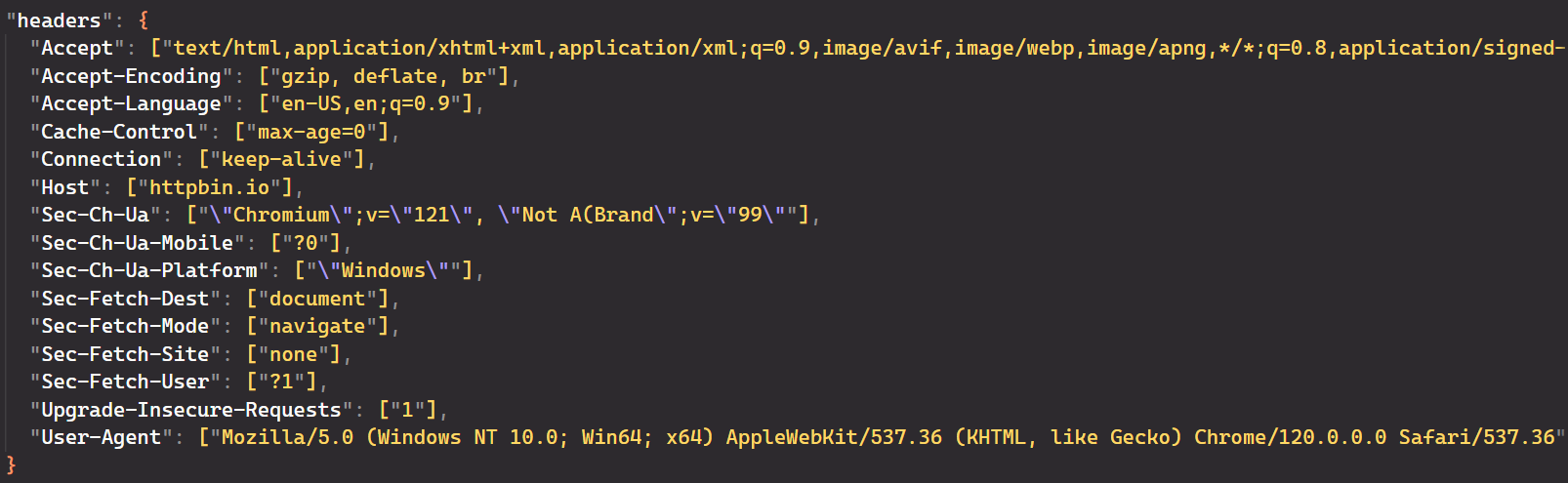
Verwendung von Proxys zum Scraping der Anonymität
Das Scrapen von Daten von Websites kann manchmal eine Herausforderung sein. Websites können den Zugriff basierend auf Ihrem Standort einschränken oder Ihre IP-Adresse blockieren. Hier kommen Proxys zum Einsatz. Proxys helfen dabei, diese Einschränkungen zu umgehen, indem sie Ihre echte IP-Adresse und Ihren Standort verbergen.
Holen Sie sich zunächst Ihren Proxy aus der Liste der kostenlosen Proxys. Konfigurieren Sie dann Puppeteer so, dass Chrome mit gestartet wird --proxy-server Möglichkeit:
import puppeteer from "puppeteer";
async function scrapeIp() {
const proxyServerUrl="<http://20.210.113.32:80>";
const browser = await puppeteer.launch({
args: (`--proxy-server=${proxyServerUrl}`)
});
const page = await browser.newPage();
await page.goto('<https://httpbin.org/ip>');
const bodyElement = await page.waitForSelector('body');
const ipText = await bodyElement.getProperty('textContent');
const ipAddress = await ipText.jsonValue();
console.log(ipAddress);
await browser.close();
}
scrapeIp();Die Ausgabe ist:
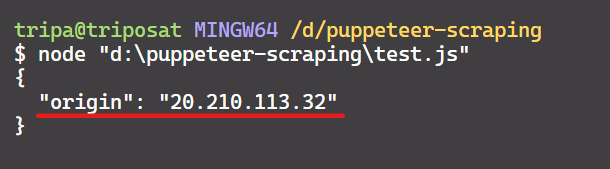
Wir haben es geschafft! Die IP-Adresse stimmt mit der auf der Webseite überein und bestätigt, dass Puppeteer den angegebenen Proxy verwendet.
Hüten Sie sich davor, durch die obige Code-Implementierung gesperrt zu werden. Das wiederholte Senden aller Anfragen über denselben Proxy kann die Website alarmieren und eine Sperre auslösen.
Glücklicherweise helfen uns andere Optionen bei der Verwaltung von Proxys. Einige davon sind:
- Rotierende Proxys: Zu viele schnelle Anfragen können Ihr Skript als Bedrohung kennzeichnen und dazu führen, dass Ihre IP gesperrt wird. Ein rotierender Proxy verhindert dies, indem er einen IP-Pool verwendet und nach jeder Anfrage automatisch wechselt.
- puppeteer-page-proxy: Diese Bibliothek erweitert Puppeteer und ermöglicht Ihnen das Festlegen von Proxys pro Seite oder sogar pro Anfrage und bietet so eine differenzierte Kontrolle.
- puppeteer-extra-plugin-proxy: Dieses Plugin für Puppeteer-extra bietet Proxy-Unterstützung, die speziell entwickelt wurde, um Ratenbegrenzungen beim Web-Scraping zu vermeiden und gleichzeitig Anonymität und Flexibilität für Automatisierungsaufgaben zu bieten.
Notiz: Kostenlose Proxys werden aufgrund ihrer Unzuverlässigkeit nicht empfohlen. Insbesondere ihre kurze Lebensdauer macht sie für reale Szenarien ungeeignet.
Fehlerbehandlung
Beim Scrapen von Webseiten können viele Fehler auftreten. Es gibt verschiedene Strategien, um diese Herausforderungen zu meistern. Ein gängiger Ansatz ist die Verwendung try/catch Blöcke, um Fehler wie elegant zu behandeln Seitennavigation fehlgeschlagen. Dadurch wird verhindert, dass Ihr Code abstürzt, und Sie können die Ausführung fortsetzen.
Darüber hinaus können Sie Puppenspieler nutzen waitForSelector Methode zur Einführung von Verzögerungen. Dadurch wird sichergestellt, dass bestimmte Elemente geladen werden, bevor mit ihnen interagiert wird.
Hier ist der vollständige Code mit Fehlerbehandlung:
import puppeteer from "puppeteer";
import { exit } from "process";
async function scrapeData(numRepos) {
try {
// Launch headless browser with default viewport
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Navigate to Node.js topic page
await page.goto("<https://github.com/topics/nodejs>");
// Use a Set to store unique entries efficiently
let uniqueRepos = new Set();
// Flag to track if there are more repos to load
let hasMoreRepos = true;
while (hasMoreRepos && uniqueRepos.size < numRepos) {
try {
// Extract data from repositories
const extractedData = await page.evaluate(() => {
const repos = document.querySelectorAll("article.border");
const repoData = ();
repos.forEach((repo) => {
const userLink = repo.querySelector("h3 > a:first-child");
const repoLink = repo.querySelector("h3 > a:last-child");
const user = userLink.textContent.trim();
const repoName = repoLink.textContent.trim();
const repoStar = repo.querySelector("#repo-stars-counter-star").title;
const repoDescription = repo.querySelector("div.px-3 > p")?.textContent.trim() || "";
const tags = Array.from(repo.querySelectorAll("a.topic-tag")).map((tag) => tag.textContent.trim());
const repoUrl = repoLink.href;
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
return repoData;
});
extractedData.forEach((entry) => uniqueRepos.add(JSON.stringify(entry)));
// Check if enough repos have been scraped
if (uniqueRepos.size >= numRepos) {
uniqueRepos = Array.from(uniqueRepos).slice(0, numRepos);
hasMoreRepos = false;
break;
}
// Click "Load more" button if available
const buttonSelector = "text/Load more";
const button = await page.waitForSelector(buttonSelector, { timeout: 5000 });
if (button) {
await button.click();
} else {
console.log("No more repos found. All data scraped.");
hasMoreRepos = false;
}
} catch (error) {
console.error("Error while extracting data:", error);
exit(1);
}
}
// Convert unique entries to an array and format JSON content
const uniqueList = Array.from(uniqueRepos).map((entry) => JSON.parse(entry));
console.dir(uniqueList, { depth: null });
await browser.close();
} catch (error) {
console.error("Error during scraping process:", error);
exit(1);
}
}
scrapeData(50);Gekratzte Daten in einer Datei speichern
Eindrucksvoll! Wir haben die Daten erfolgreich gelöscht. Speichern wir es in einer JSON-Datei, anstatt es auf der Konsole auszudrucken. JSON ist ein strukturiertes Format, das es Ihnen ermöglicht, komplexe Daten klar und konsistent zu speichern und zu organisieren.
Wir importieren die fs Modul und Verwendung fs.writeFile() um die Daten in die Datei zu schreiben. Aber bevor wir dies tun, konvertieren wir das JavaScript-Objekt uniqueList in einen JSON-String mit JSON.stringify().
const uniqueList = Array.from(uniqueRepos).map((entry) => JSON.parse(entry));
const jsonContent = JSON.stringify(uniqueList, null, 2);
await fs.writeFile("github_repos.json", jsonContent);Hier ist der vollständige Code:
import puppeteer from "puppeteer";
import fs from "fs";
import { exit } from "process";
async function scrapeData(numRepos) {
try {
// Launch headless browser with default viewport
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Navigate to Node.js topic page
await page.goto("<https://github.com/topics/nodejs>");
// Use a Set to store unique entries efficiently
let uniqueRepos = new Set();
// Flag to track if there are more repos to load
let hasMoreRepos = true;
while (hasMoreRepos && uniqueRepos.size < numRepos) {
try {
// Extract data from repositories
const extractedData = await page.evaluate(() => {
const repos = document.querySelectorAll("article.border");
const repoData = ();
repos.forEach((repo) => {
const userLink = repo.querySelector("h3 > a:first-child");
const repoLink = repo.querySelector("h3 > a:last-child");
const user = userLink.textContent.trim();
const repoName = repoLink.textContent.trim();
const repoStar = repo.querySelector("#repo-stars-counter-star").title;
const repoDescription = repo.querySelector("div.px-3 > p")?.textContent.trim() || "";
const tags = Array.from(repo.querySelectorAll("a.topic-tag")).map((tag) => tag.textContent.trim());
const repoUrl = repoLink.href;
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
return repoData;
});
extractedData.forEach((entry) => uniqueRepos.add(JSON.stringify(entry)));
// Check if enough repos have been scraped
if (uniqueRepos.size >= numRepos) {
uniqueRepos = Array.from(uniqueRepos).slice(0, numRepos);
hasMoreRepos = false;
break;
}
// Click "Load more" button if available
const buttonSelector = "text/Load more";
const button = await page.waitForSelector(buttonSelector, { timeout: 5000 });
if (button) {
await button.click();
} else {
console.log("No more repos found. All data scraped.");
hasMoreRepos = false;
}
} catch (error) {
console.error("Error while extracting data:", error);
exit(1);
}
}
// Convert unique entries to an array and format JSON content
const uniqueList = Array.from(uniqueRepos).map((entry) => JSON.parse(entry));
const jsonContent = JSON.stringify(uniqueList, null, 2);
await fs.writeFile("github_repos.json", jsonContent);
console.log(`${uniqueList.length} unique repositories scraped and saved to 'github_repos.json'.`);
await browser.close();
} catch (error) {
console.error("Error during scraping process:", error);
exit(1);
}
}
scrapeData(50);JSON-Datei:
Alternativen zum Puppenspieler
Puppeteer ist wegen seiner direkten Browserkommunikation über das DevTools-Protokoll und seiner Benutzerfreundlichkeit beliebt. Es gibt jedoch Einschränkungen, einschließlich eingeschränkter Browserunterstützung und Abhängigkeit von einer einzigen Sprache. Diese Einschränkungen können Entwickler dazu veranlassen, andere Optionen zu erkunden.
Hier sind einige der beliebtesten Alternativen zu Puppeteer:
Selen: Es handelt sich um ein beliebtes Browser-Automatisierungstool, das mit vielen Browsern (Chrome, Firefox, Safari usw.) funktioniert und Ihnen die Verwendung verschiedener Programmiersprachen (Python, Java, JavaScript usw.) ermöglicht. Im Vergleich zu Puppeteer kann Selenium jedoch langsamer sein und mehr Ressourcen verbrauchen, insbesondere bei großen Scraping-Aufgaben.
Dramatiker: Diese Open-Source-Bibliothek bietet umfassendere Browserunterstützung wie Chrome-, Firefox-, Edge- und WebKit-Browser. Sein Hauptvorteil liegt in der browserübergreifenden Unterstützung, die es Ihnen ermöglicht, Webanwendungen auf mehreren Browsern gleichzeitig zu testen. Es unterstützt außerdem mehrere Programmiersprachen und ist somit für verschiedene Entwickler flexibel.
Scrape-it.Cloud NodeJS SDK: Im Gegensatz zu den vorherigen Tools ist Scrape-It.Cloud ein cloudbasierter Web-Scraping-Dienst, der die Verwaltung Ihrer eigenen Infrastruktur überflüssig macht. Es kümmert sich um die Komplexität der Browser-Automatisierung und kümmert sich um Dinge wie die Verwaltung von Proxys, den Umgang mit Anti-Bot-Maßnahmen und die Darstellung von JavaScript. Dadurch können Sie sich auf das Schreiben von Code zum Extrahieren der benötigten Daten konzentrieren, ohne sich um die zugrunde liegende Infrastruktur kümmern zu müssen.
Die Wahl des richtigen Schabewerkzeugs hängt von Ihrem Projekt ab. Puppenspieler ist großartig, aber andere Optionen könnten besser zu Ihnen passen. Probieren Sie sie aus, um zu sehen, was funktioniert.
Abschluss
Puppeteer bietet ein leistungsstarkes und vielseitiges Toolkit für Web-Scraping-Aufgaben. Durch die Nutzung seiner Funktionen können Sie wertvolle Daten effizient aus Websites extrahieren, sich wiederholende Browserinteraktionen automatisieren und verschiedene Arbeitsabläufe optimieren.
In diesem Leitfaden haben wir uns auf die GitHub-Themenseite konzentriert, auf der Sie ein Thema (z. B. NodeJS) auswählen und die Anzahl der Repositorys zum Scrapen angeben können. Wir behandelten den Umgang mit Fehlern beim Scraping, die Vermeidung von Erkennung und diskutierten die Vorteile von Web-Scraping-APIs für eine einfachere und effizientere Datenextraktion.
Erkunden Sie mit zunehmender Erfahrung fortgeschrittene Techniken wie Proxy-Rotation und Browser-Plugins, um Ihre Scraping-Fähigkeiten zu verbessern und durch komplexe Website-Strukturen zu navigieren. Mit Engagement und Erkundung kann Puppeteer Sie dabei unterstützen, wertvolle Erkenntnisse aus dem riesigen Internet zu gewinnen.
