
Das Extrahieren von Daten aus Websites ist in verschiedenen Bereichen unverzichtbar geworden, von der Datenerfassung bis zur Wettbewerbsanalyse. Allerdings kann es schwierig sein, Inhalte, die über JavaScript, AJAX-Anfragen und komplexe Interaktionen geladen werden, mit einfachen Tools zu erfassen. Hier kommen Headless-Browser-Automatisierungstools wie Playwright ins Spiel.
In diesem Blog befassen wir uns mit der Verwendung von Playwright zum Web-Scraping. Wir werden seine Vorteile, das Scraping einzelner und mehrerer Seiten, die Fehlerbehandlung, das Klicken auf Schaltflächen, das Senden von Formularen und wichtige Techniken wie die Nutzung von Proxys zur Umgehung der Erkennung und zum Abfangen von Anfragen untersuchen. Darüber hinaus der Vergleich mit anderen Web-Scraping- und Automatisierungstools wie Puppeteer und Selenium.
Was ist Dramatiker?
Playwright ist ein beliebtes Open-Source-Framework, das auf Node.js für Webtests und Automatisierung basiert. Es ermöglicht das Testen von Chromium, Firefox und WebKit mit einer einzigen API. Playwright wurde von Microsoft entwickelt und bietet effiziente, zuverlässige und schnelle browserübergreifende Webautomatisierung. Es funktioniert auf mehreren Plattformen, einschließlich Windows, Linux und macOS, und unterstützt alle modernen Webbrowser. Darüber hinaus bietet Playwright sprachübergreifende Unterstützung für TypeScript, JavaScript, Python, .NET und Java.
Erste Schritte mit Dramatiker
Vor dem Scrapen von Websites bereiten wir die Node.js- und Python-Umgebungen unseres Systems für Playwright vor.
Projekteinrichtung und -installation
Für Nodejs:
Stellen Sie sicher, dass auf Ihrem System die neueste Version von Node.js installiert ist. Für dieses Projekt verwenden wir Node.js v20.9.0.
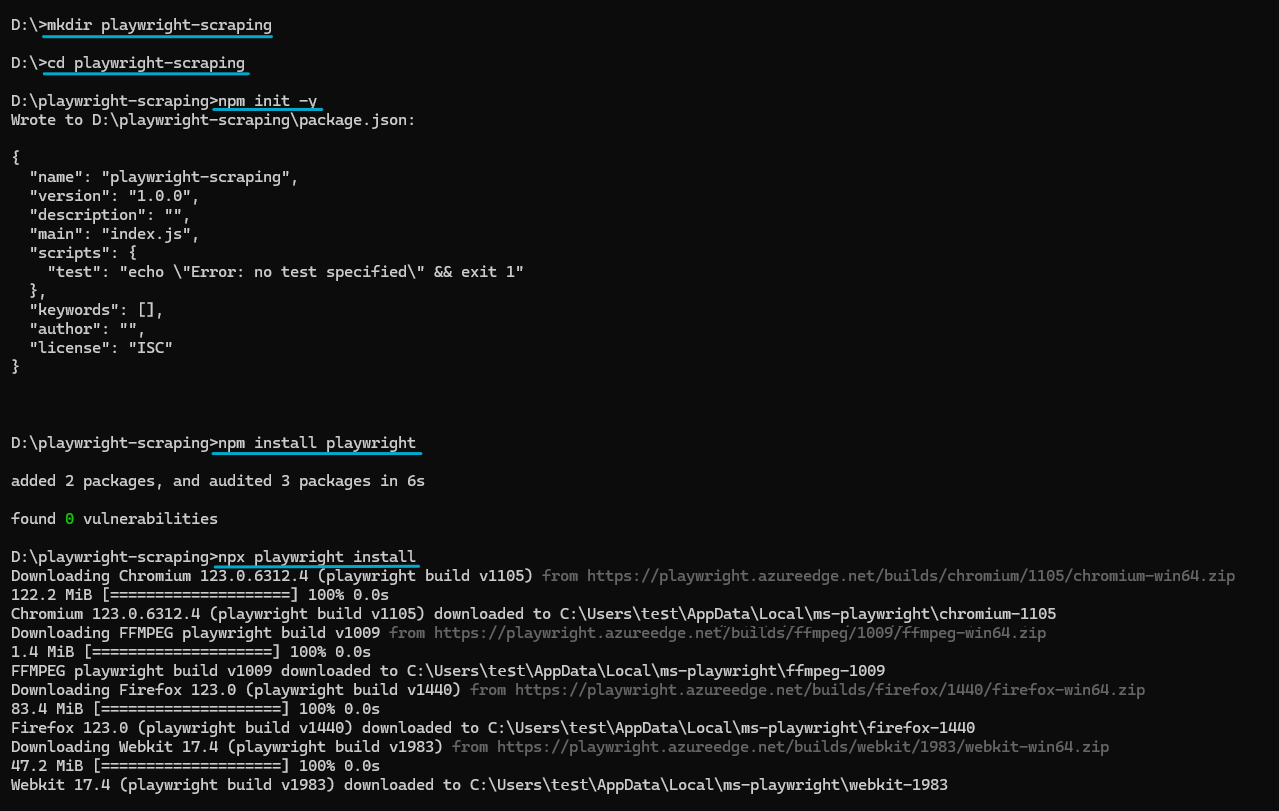
Erstellen Sie ein neues Verzeichnis für Ihr Projekt, navigieren Sie dorthin und initialisieren Sie durch Ausführen ein Node.js-Projekt npm init. Der npm init -y Der Befehl erstellt eine package.json Datei mit allen Abhängigkeiten.
mkdir playwright-scraping
cd playwright-scraping
npm init -yJetzt können Sie Playwright mit NPM installieren:
npm install playwrightUm Playwright nutzen zu können, müssen Sie außerdem einen kompatiblen Browser installieren. Für jede Playwright-Version sind bestimmte Browser-Binärversionen erforderlich. Führen Sie den folgenden Befehl aus, um die neuesten Browserversionen zu installieren:
npx playwright installDadurch werden die neuesten Versionen von Chromium, Firefox und WebKit installiert. Sie können jeden dieser Browser in Ihrem Code verwenden, für dieses Tutorial verwenden wir jedoch Chromium.
So sieht der komplette Prozess aus:
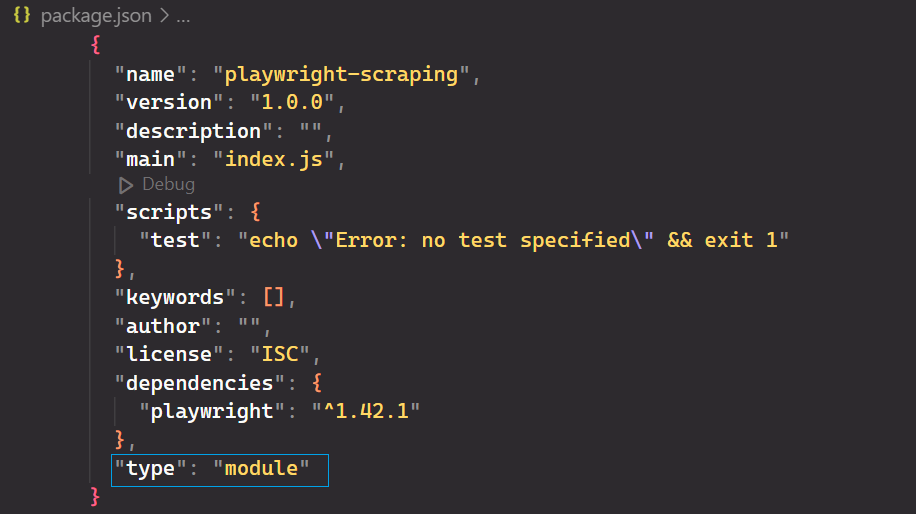
Öffne das package.json Datei hinzufügen und hinzufügen "type": "module" zur Unterstützung moderner JavaScript-Syntax.
Öffnen Sie abschließend das Projekt in Ihrem bevorzugten Code-Editor und erstellen Sie eine neue Datei mit dem Namen index.js.
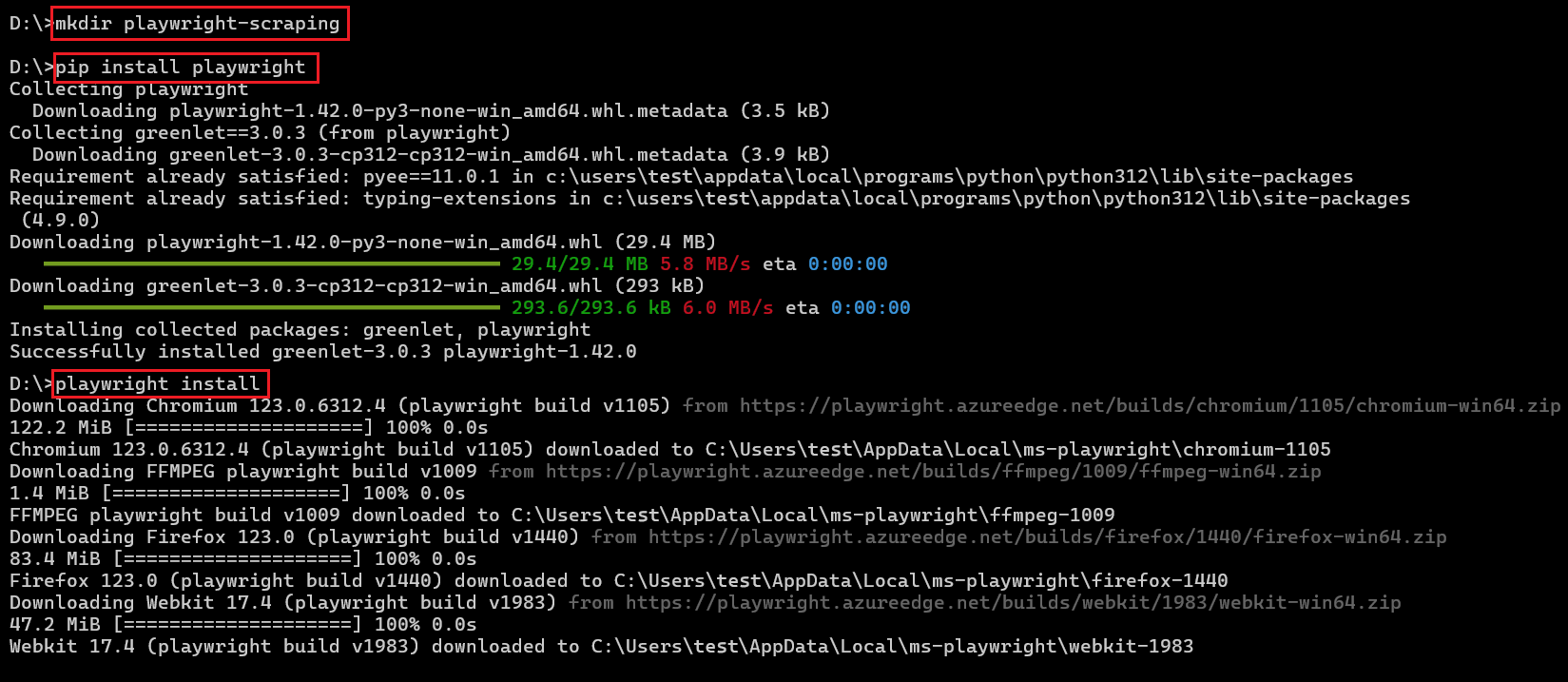
Für Python:
Stellen Sie sicher, dass auf Ihrem System die neueste Version von Python installiert ist. Als nächstes installieren Sie die Playwright Python-Bibliothek und die erforderlichen Browser.
pip install playwright
playwright installSo sieht der komplette Prozess aus:
Start von Playwright
Für Nodejs:
Schreiben wir unseren ersten Playwright-Code, der eine neue Seite in einem Chromium-Browser öffnet.
import { chromium } from 'playwright';
async function main() {
// Launch a new instance of a Chromium browser with headless mode
// disabled for visibility
const browser = await chromium.launch({
headless: false
});
// Create a new Playwright context to isolate browsing session
const context = await browser.newContext();
// Open a new page/tab within the context
const page = await context.newPage();
// Navigate to the GitHub topics homepage
await page.goto('<https://github.com/topics>');
// Wait for 1 second to ensure page content loads properly
await page.waitForTimeout(1000);
// Close the browser instance after task completion
await browser.close();
}
// Execute the main function
main();Der obige Code importiert die chromium Modul zur Steuerung von Chromium-basierten Browsern. Anschließend wird eine neue, sichtbare Instanz des Chromium-Browsers gestartet chromium.launch() mit dem headless Option auf eingestellt False. Eine neue Browserseite wird geöffnet und die page.goto() Die Funktion navigiert zur GitHub-Themen-Webseite. Nach einer Wartezeit von einer Sekunde kann der Benutzer die Seite sehen, bevor sie endgültig geschlossen wird.
Für Python:
Playwright für Python bietet sowohl synchrone als auch asynchrone APIs. Das folgende Beispiel zeigt die asynchrone API in Aktion:
from playwright.async_api import async_playwright
import asyncio
async def main():
# Initialize Playwright asynchronously
async with async_playwright() as p:
# Launch a Chromium browser instance with headless mode disabled
browser = await p.chromium.launch(headless=False)
# Create a new context within the browser to isolate browsing session
context = await browser.new_context()
# Create a new page/tab within the context
page = await context.new_page()
# Navigate to the GitHub topics homepage
await page.goto('<https://github.com/topics>')
# Wait for 1 second to ensure page content loads properly
await page.wait_for_timeout(1000)
# Close the browser instance after task completion
await browser.close()
# Run the main function asynchronously
asyncio.run(main())Sowohl Node.js- als auch Python-Code weisen Ähnlichkeiten auf, es gibt jedoch einige wesentliche Unterschiede. Python verwendet die Asyncio-Bibliothek für asynchrone Vorgänge. Darüber hinaus unterscheiden sich die Konventionen zur Benennung von Funktionen, wobei Python „snake_case“ verwendet (z. B. wait_for_timeout) und JavaScript mit camelCase (z. B. waitForTimeout).
Das folgende Beispiel zeigt die synchrone API in Aktion:
from playwright.sync_api import sync_playwright
def main():
# Initialize Playwright synchronously
with sync_playwright() as p:
# Launch a Chromium browser instance with headless mode disabled
browser = p.chromium.launch(headless=False)
# Create a new context within the browser to isolate browsing session
context = browser.new_context()
# Create a new page/tab within the context
page = context.new_page()
# Navigate to the GitHub topics homepage
page.goto('<https://github.com/topics>')
# Wait for 1 second to ensure page content loads properly
page.wait_for_timeout(1000)
# Close the browser instance after task completion
browser.close()
if __name__ == '__main__':
main()Die oben genannten Node.js- und Python-Codes öffnen die folgende Seite.
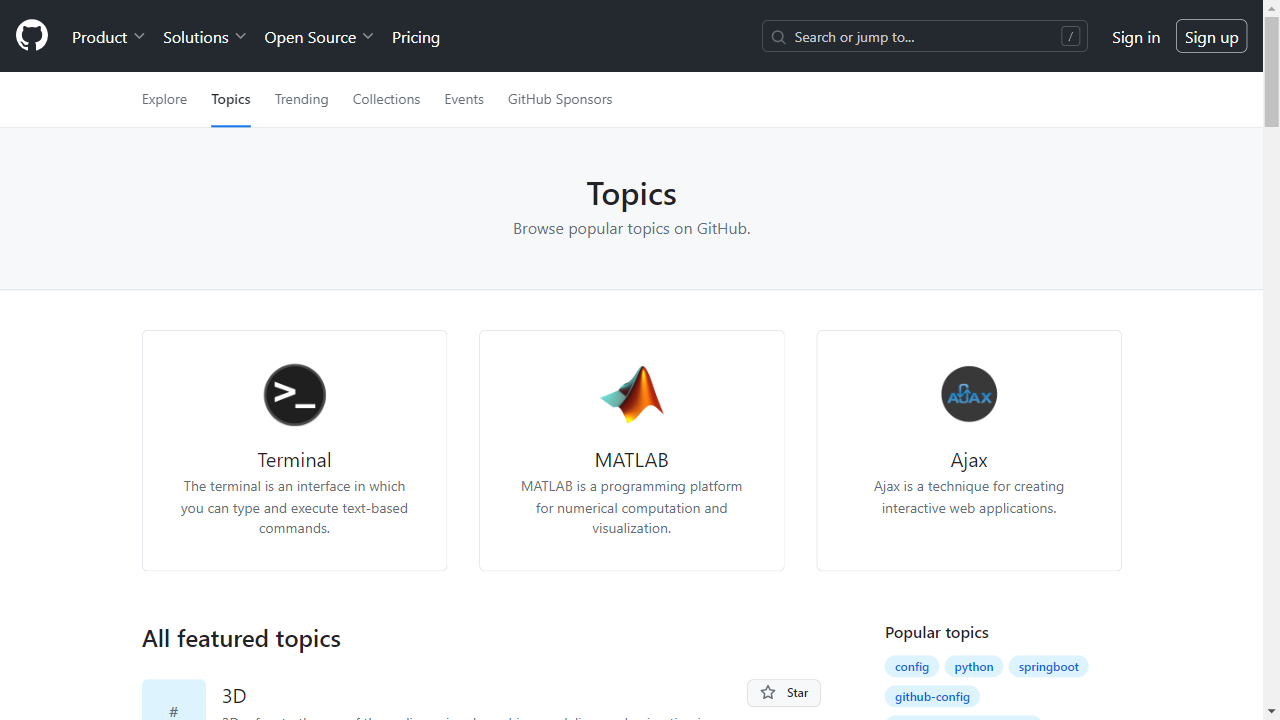
Grundlegendes Schaben mit Dramatiker
Nachdem Ihre Umgebung nun eingerichtet ist, tauchen wir mit Playwright in ein grundlegendes Web-Scraping ein. Sie können alles, was Sie normalerweise manuell tun, im Browser tun, vom Erstellen von Screenshots bis zum Crawlen mehrerer Seiten.
Auswählen der Daten zum Scrapen
Wir werden Daten aus GitHub-Themen extrahieren. Auf diese Weise können Sie das Thema und die Anzahl der Repositorys auswählen, die Sie extrahieren möchten. Der Scraper gibt dann die mit dem ausgewählten Thema verknüpften Informationen zurück.
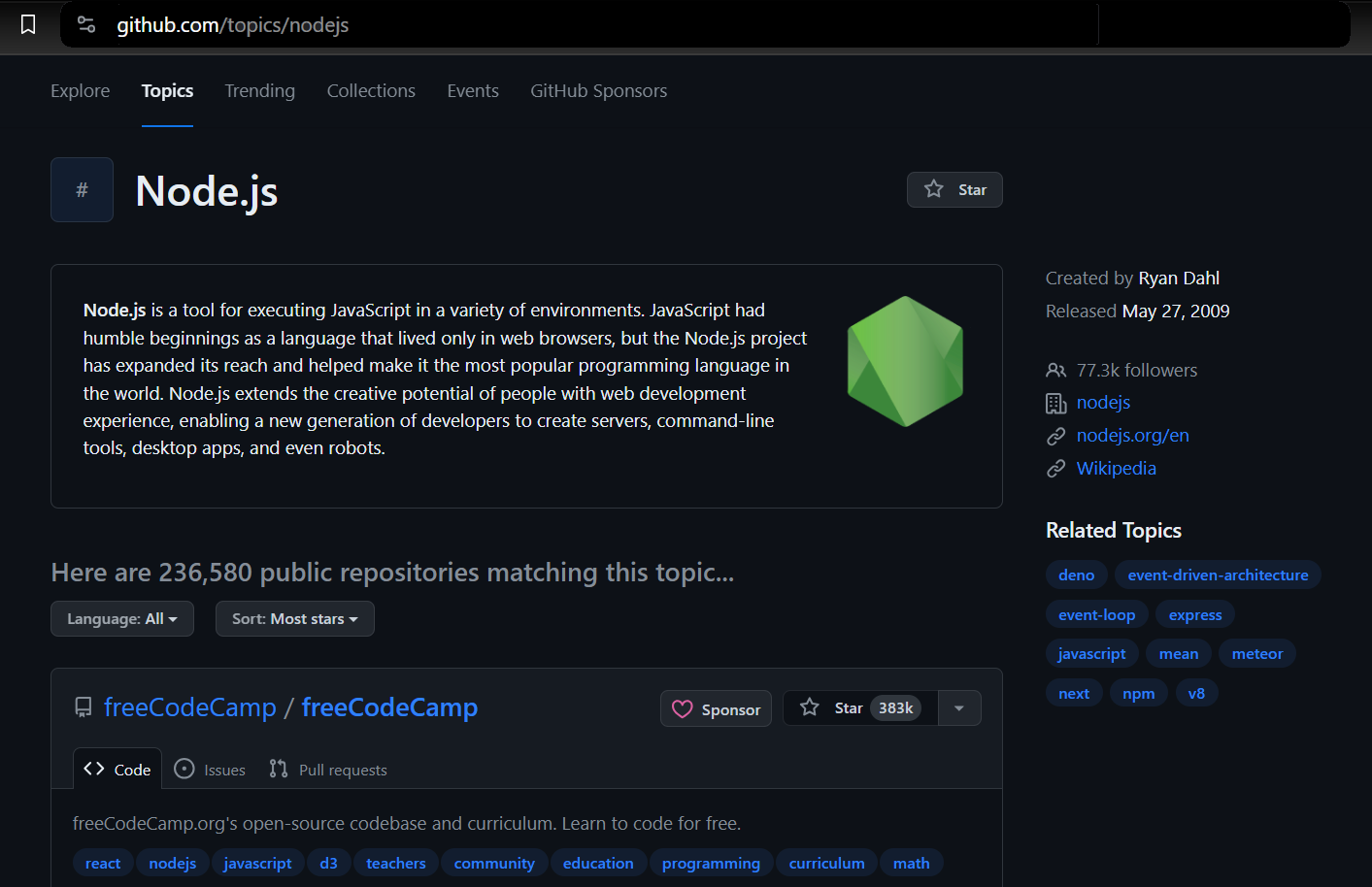
Wir verwenden Playwright, um einen Browser zu starten, zur GitHub-Themenseite zu navigieren und die erforderlichen Informationen zu extrahieren. Dazu gehören Details wie der Repository-Eigentümer, der Repository-Name, die Repository-URL, die Anzahl der Sterne des Repositorys, seine Beschreibung und alle zugehörigen Tags.
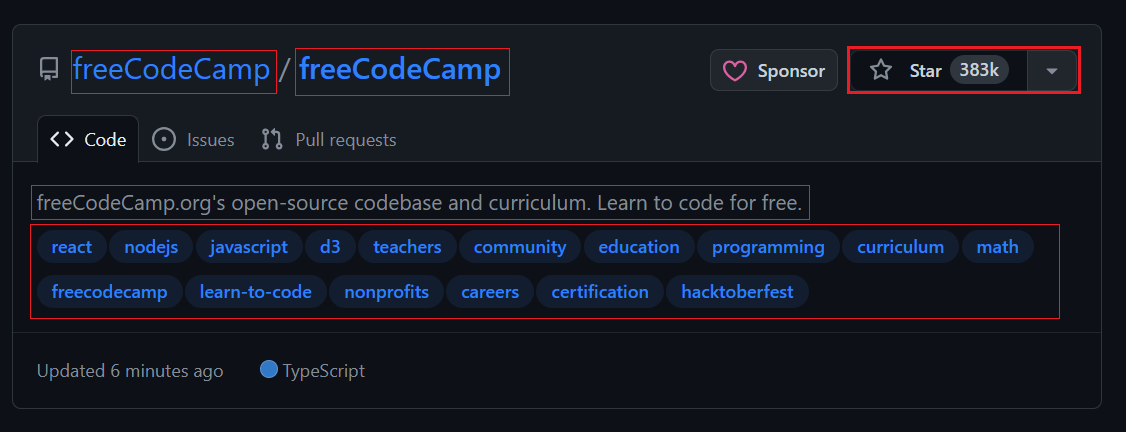
Auffinden von Elementen und Extrahieren von Daten
Wenn Sie die Themenseite öffnen, sehen Sie 20 Repositorys. Jeder Eintrag wird als angezeigt <article> -Element zeigt Informationen zu einem bestimmten Repository an. Sie können jedes Element erweitern, um detailliertere Informationen zum entsprechenden Repository anzuzeigen.
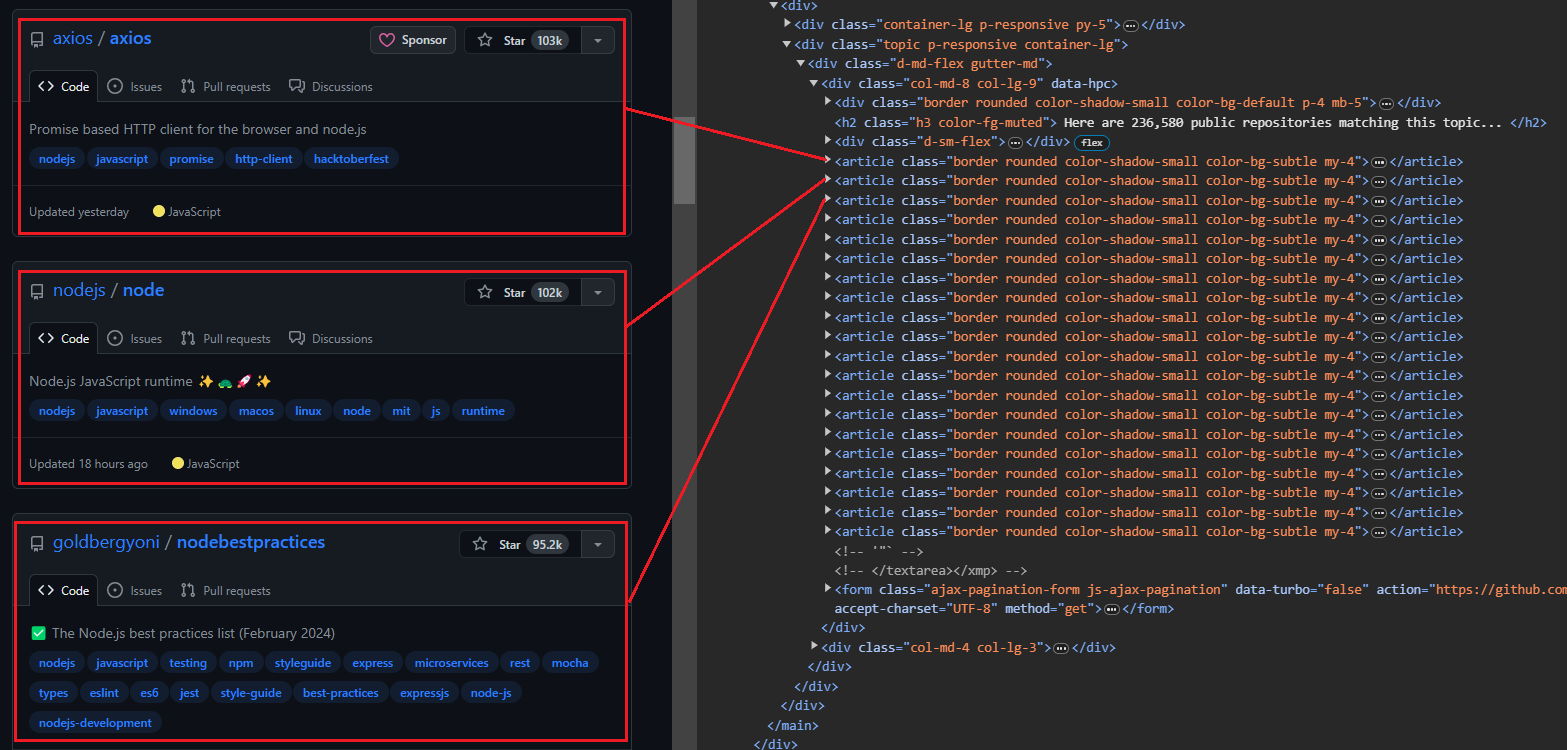
Das Bild unten zeigt eine erweiterte Darstellung <article> Element, das alle Informationen über das Repository anzeigt.
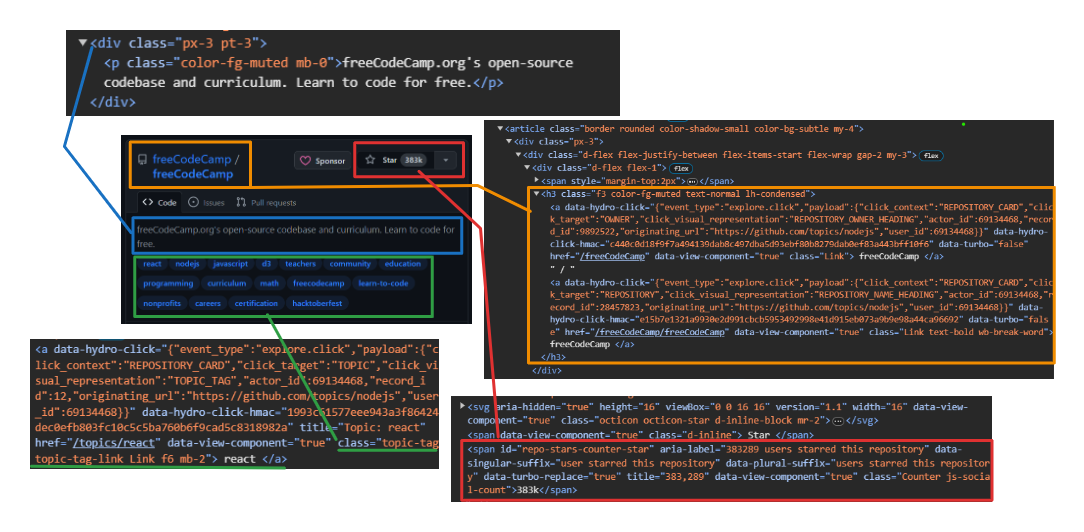
Extrahieren von Benutzer- und Repository-Informationen:
- Benutzer: Verwenden
h3 > a:first-childum das erste Anker-Tag direkt innerhalb von a anzusprechen<h3>Etikett. - Repository-Name: Zielt auf das zweite untergeordnete Element innerhalb desselben
<h3>Elternteil. Dieses Kind enthält sowohl den Namen als auch die URL. Benutzen Sie dietextContentEigenschaft zum Extrahieren des Namens und dergetAttribute('href')Methode zum Extrahieren der URL. - Anzahl der Sterne: Verwendung
#repo-stars-counter-starum das Element auszuwählen und die tatsächliche Zahl daraus zu extrahierentitleAttribut. - Repository-Beschreibung: Verwendung
div.px-3 > pum den ersten Absatz innerhalb von a auszuwählendivmit der Klassepx-3. - Repository-Tags: Verwendung
a.topic-tagum alle Ankertags mit der Klasse auszuwählentopic-tag.
Gemeinsame Funktionen:
Um die oben genannten Selektoren effektiv zu nutzen, sind hier die allgemeinen Funktionen:
$$eval(selector, function): Diese Funktion wählt alle Elemente aus, die mit übereinstimmenselectorund übergibt sie als Array an diefunction. Anschließend wird der Rückgabewert der Funktion zurückgegeben.$eval(selector, function): Diese Funktion wählt das erste Element aus, das mit dem übereinstimmtselectorund übergibt es als Argument an diefunction. Anschließend wird der Rückgabewert der Funktion zurückgegeben.querySelector(selector): Diese Funktion gibt das erste Element zurück, das mit dem übereinstimmtselector.querySelectorAll(selector): Diese Funktion gibt eine Liste aller Elemente zurück, die mit übereinstimmenselector.
Hier ist ein Codeausschnitt:
repos.forEach(repo => {
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());Sehen wir uns den gesamten Prozess zum Extrahieren aller Repositorys von einer einzelnen Seite an.
Der Prozess beginnt mit der page.$$eval-Funktion. Diese Funktion wählt alle Elemente mit der Klasse aus border innerhalb der article Tag und übergibt sie als Array an die bereitgestellte Funktion. Wir definieren alle Variablen und Selektoren innerhalb dieser Funktion.
const extractedRepos = await page.$$eval('article.border', repos => { ... });Erstellen Sie außerdem ein leeres Array mit dem Namen repoData um die extrahierten Informationen zu speichern.
const repoData = ();Durchläuft jedes Element im repos Array, um alle relevanten Daten für jedes Repository mithilfe der bereitgestellten Selektoren zu extrahieren.
repos.forEach(repo => { ... });Abschließend werden die extrahierten Daten für jedes Repository dem hinzugefügt repoData Array, und das Array wird zurückgegeben.
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });Hier ist der Code für alle oben genannten Schritte.
const extractedRepos = await page.$$eval('article.border', repos => {
const repoData = ();
repos.forEach(repo => {
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
return repoData;
});Hier ist der vollständige Code. Wenn Sie diesen Code ausführen, wird die erste Seite von GitHub Topics extrahiert.
import { chromium } from 'playwright';
(async () => {
// Launch a headless browser
const browser = await chromium.launch({ headless: true });
// Open a new page
const context = await browser.newContext();
const page = await context.newPage();
// Navigate to the Node.js topic page on GitHub
await page.goto('<https://github.com/topics/nodejs>');
const extractedRepos = await page.$$eval('article.border', repos => {
// Array to store extracted data
const repoData = ();
// Extract data from each repository element
repos.forEach(repo => {
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());
// Add extracted data to the array
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
// Return the extracted data
return repoData;
});
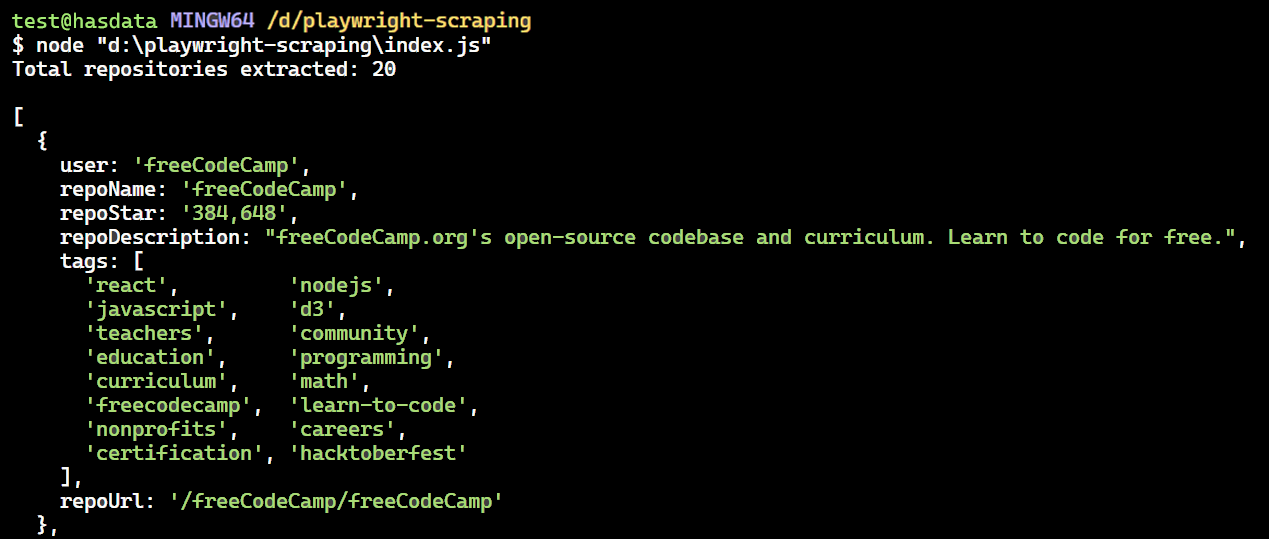
console.log(`Total repositories extracted: ${extractedRepos.length}\\n`);
// Print extracted data to the console
console.dir(extractedRepos, { depth: null }); // Show all nested data
// Close the browser
await browser.close();
})();Das Ergebnis ist:
Wenn Sie über Playwright hinaus mehr über Web Scraping mit Node.js erfahren möchten, könnte Ihnen unser umfassender Leitfaden zum Web Scraping mit Node.js hilfreich sein. In diesem Artikel werden zusätzliche Bibliotheken und Techniken zur Verbesserung Ihrer Scraping-Funktionen mit Node.js behandelt
Fortgeschrittene Schabetechniken
Wir haben die einzelne Seite erfolgreich gelöscht. Kommen wir nun zum erweiterten Scraping mit Playwright. Sie können auf Schaltflächen klicken, Formulare ausfüllen, mehrere Seiten crawlen und Header und Proxys drehen, um Ihr Scraping zuverlässiger zu machen …
Auf Schaltflächen klicken und auf Aktionen warten
Sie können weitere Repositorys laden, indem Sie unten auf der Seite auf die Schaltfläche „Mehr laden…“ klicken. Hier sind die Aktionen, um Playwright anzuweisen, weitere Repositorys zu laden:
- Warten Sie, bis die Schaltfläche „Mehr laden…“ angezeigt wird.
- Klicken Sie auf die Schaltfläche „Mehr laden…“.
- Warten Sie, bis die neuen Repositorys geladen sind, bevor Sie fortfahren.
Das Klicken auf Schaltflächen in Playwright ist unkompliziert! Übergeben Sie einfach einen gültigen CSS-Selektor an locator Methode, die das Element auf der Seite effizient findet.
const button = await page.locator('button(type="submit").ajax-pagination-btn.f6');
await button.click();In diesem Fall ist die page.locator() Die Methode sucht nach einem Schaltflächenelement mit Attributen type="submit" und CSS-Klassen ajax-pagination-btn Und f6.
Umgang mit dynamischen Inhalten und Navigation
Um mehrere Seiten mit Playwright zu scrappen, müssen Sie wiederholt auf die Schaltfläche „Mehr laden…“ klicken, bis Sie das Ende erreichen. Wir können jedoch Code schreiben, um diesen Prozess zu automatisieren und eine bestimmte Anzahl von gewünschten Repositorys zu durchsuchen. Stellen Sie sich zum Beispiel vor, dass es 10.000 Repositorys für „nodejs“ gibt und Sie nur Daten für 1.000 davon extrahieren möchten.
So crawlt das Skript mehrere Seiten:
- Öffnen Sie die Themenseite „nodejs“ auf GitHub.
- Erstellen Sie einen leeren Satz zum Speichern eindeutiger Repository-Dateneinträge.
$$evalDie Funktion extrahiert Daten aus jedem Repository wie Benutzername, Repository-Name, Sternanzahl, Beschreibung, Tags und URL.- Die extrahierten Daten werden nur gespeichert, wenn sie eindeutig sind.
- Der Code sucht mithilfe eines bestimmten Locators nach einer „Nächsten Seite“. Falls verfügbar, klickt es auf die Schaltfläche, um zur nächsten Seite zu wechseln und den Scraping-Vorgang zu wiederholen.
- Wenn keine Schaltfläche gefunden wird, wird die Schleife beendet.
- Abschließend wird die gestartete Browserinstanz geschlossen.
Hier ist der Code:
import { chromium } from 'playwright';
async function scrapeData(numRepos) {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('<https://github.com/topics/nodejs>');
const uniqueRepos = new Set();
while (uniqueRepos.size < numRepos) {
const extractedData = await page.$$eval('article.border', repos => {
return repos.map(repo => {
const userLink = repo.querySelector('h3 > a:first-child');
const repoLink = repo.querySelector('h3 > a:last-child');
const user = userLink?.textContent.trim() || '';
const repoName = repoLink?.textContent.trim() || '';
const repoStar = repo.querySelector('#repo-stars-counter-star')?.title || '';
const repoDescription = repo.querySelector('div.px-3 > p')?.textContent.trim() || '';
const tags = Array.from(repo.querySelectorAll('a.topic-tag')).map(tag => tag.textContent.trim());
const repoUrl = repoLink?.href || '';
return { user, repoName, repoStar, repoDescription, tags, repoUrl };
});
});
extractedData.forEach(entry => uniqueRepos.add(JSON.stringify(entry)));
if (uniqueRepos.size >= numRepos) {
break;
}
const button = await page.locator('button(type="submit").ajax-pagination-btn.f6');
if (!button) {
console.log('Pagination button not found. All data scraped.');
break;
}
await button.click();
await page.waitForLoadState('networkidle');
}
const uniqueList = Array.from(uniqueRepos).slice(0, numRepos).map(entry => JSON.parse(entry));
console.dir(uniqueList, { depth: null });
await browser.close();
}
scrapeData(30);Umgang mit Fehlern
Beim Scraping von Webseiten können aufgrund verschiedener Faktoren mehrere Fehler auftreten, darunter menschliche Fehler wie die Angabe einer nicht funktionierenden URL oder das Versäumnis, auf eine Schaltfläche zu klicken. Darüber hinaus fehlt möglicherweise das Zieldatenelement auf der Seite, beispielsweise fehlt in einem Code-Repository möglicherweise eine Beschreibung oder Sterne.
Glücklicherweise gibt es Strategien, mit diesen Herausforderungen umzugehen. Eine häufige Variante ist die Verwendung try/catch Blöcke. Mit diesen Blöcken können Sie Fehler wie fehlgeschlagene Seitennavigation oder Zeitüberschreitungen reibungslos behandeln, so verhindern, dass Ihr Code abstürzt, und eine fortgesetzte Ausführung ermöglichen.
Hier ist der vollständige Code mit Fehlerbehandlung und Randfällen:
import { chromium } from 'playwright';
async function scrapeData(numRepos) {
let browser;
try {
browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('<https://github.com/topics/nodejs>');
const uniqueRepos = new Set();
while (uniqueRepos.size < numRepos) {
const extractedData = await page.$$eval('article.border', repos => {
return repos.map(repo => {
const userLink = repo.querySelector('h3 > a:first-child');
const repoLink = repo.querySelector('h3 > a:last-child');
const user = userLink?.textContent.trim() || '';
const repoName = repoLink?.textContent.trim() || '';
const repoStar = repo.querySelector('#repo-stars-counter-star')?.title || '';
const repoDescription = repo.querySelector('div.px-3 > p')?.textContent.trim() || '';
const tags = Array.from(repo.querySelectorAll('a.topic-tag')).map(tag => tag.textContent.trim());
const repoUrl = repoLink?.href || '';
return { user, repoName, repoStar, repoDescription, tags, repoUrl };
});
});
if (extractedData.length === 0) {
console.log('No articles found on this page.');
break;
}
extractedData.forEach(entry => uniqueRepos.add(JSON.stringify(entry)));
if (uniqueRepos.size >= numRepos) {
break;
}
const button = await page.locator('button(type="submit").ajax-pagination-btn.f6');
if (!button) {
console.log('Next button not found. All data scraped.');
break;
}
await button.click();
await page.waitForLoadState('networkidle');
}
const uniqueList = Array.from(uniqueRepos).slice(0, numRepos).map(entry => JSON.parse(entry));
console.dir(uniqueList, { depth: null });
} catch (error) {
console.error('Error during scraping:', error);
} finally {
if (browser) {
await browser.close();
}
}
}
scrapeData(30).catch(error => console.error('Unhandled error:', error));Verwenden von Proxys mit Playwright
Das Scrapen von Daten von Websites kann manchmal eine Herausforderung sein. Websites können den Zugriff basierend auf Ihrem Standort einschränken oder Ihre IP-Adresse blockieren. Hier kommen Proxys zum Einsatz. Proxys helfen dabei, diese Einschränkungen zu umgehen, indem sie Ihre echte IP-Adresse und Ihren Standort verbergen.
Holen Sie sich zunächst Ihren Proxy aus der Liste der kostenlosen Proxys. Fügen Sie dann ein Proxy-Objekt zu Ihren Browser-Startoptionen hinzu. Legen Sie im Proxy-Objekt fest server Parameter zu Ihrem proxyUrl. Starten Sie abschließend den Browser, indem Sie die aufrufen chromium.launch Funktion, Bereitstellung der launchOptions Objekt, das Sie gerade definiert haben.
import { chromium } from 'playwright';
const proxyUrl="<http://20.210.113.32:80>";
const launchOptions = {
proxy: {
server: proxyUrl
}
};
(async () => {
const browser = await chromium.launch(launchOptions);
const page = await browser.newPage();
await page.goto('<http://httpbin.org/ip>');
const pageContent = await page.textContent('body');
console.log(pageContent);
})();Das Ergebnis ist:
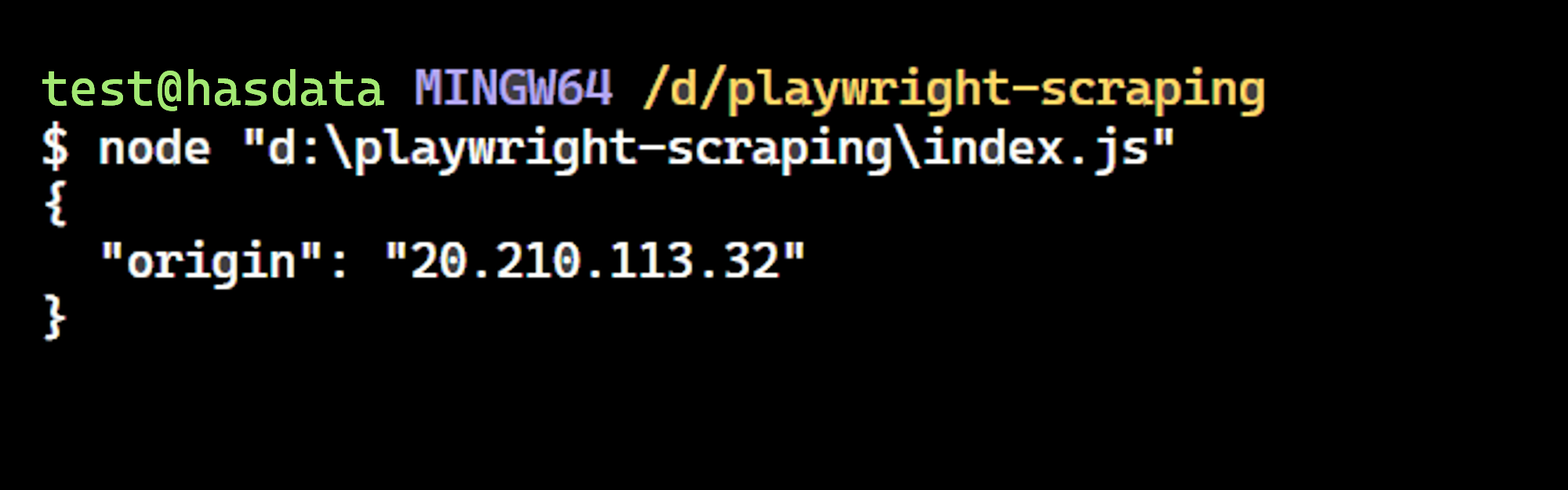
Wir haben es geschafft! Die IP-Adresse stimmt mit der auf der Webseite überein und bestätigt, dass Playwright den angegebenen Proxy verwendet.
Notiz: Kostenlose Proxys werden aufgrund ihrer Unzuverlässigkeit nicht empfohlen. Insbesondere ihre kurze Lebensdauer macht sie für reale Szenarien ungeeignet.
Abfangen von HTTP-Anfragen
Mit Playwright können Sie den Netzwerkverkehr wie HTTP- und HTTPS-Anfragen, XMLHttpRequests (XHRs) und Abrufanfragen einfach überwachen und ändern. Unten finden Sie einen Codeausschnitt, der zeigt, wie ein Anforderungsheader geändert wird.
import { chromium } from 'playwright';
(async () => {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.route('<https://httpbin.org/headers>', (route, request) => {
// Get original headers
const originalHeaders = request.headers();
// Modify the Accept-Language and User-Agent headers
const modifiedHeaders = { ...originalHeaders };
modifiedHeaders('accept-language') = 'fr-FR'; // Change to French
modifiedHeaders('user-agent') = 'Mozilla/5.0 (Windows Phone 10.0; Android 4.2.1; Microsoft; RM-1127_16056) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Mobile Safari/537.36 Edge/12.10536';
// Continue the request with modified headers
route.continue({
headers: modifiedHeaders,
});
});
// Make the request with modified headers
await page.goto('<https://httpbin.org/headers>');
// Extract the data to see if the fields are updated
const response = await page.evaluate(() => {
return JSON.parse(document.querySelector('pre').textContent);
});
console.log('Response:', response);
await browser.close();
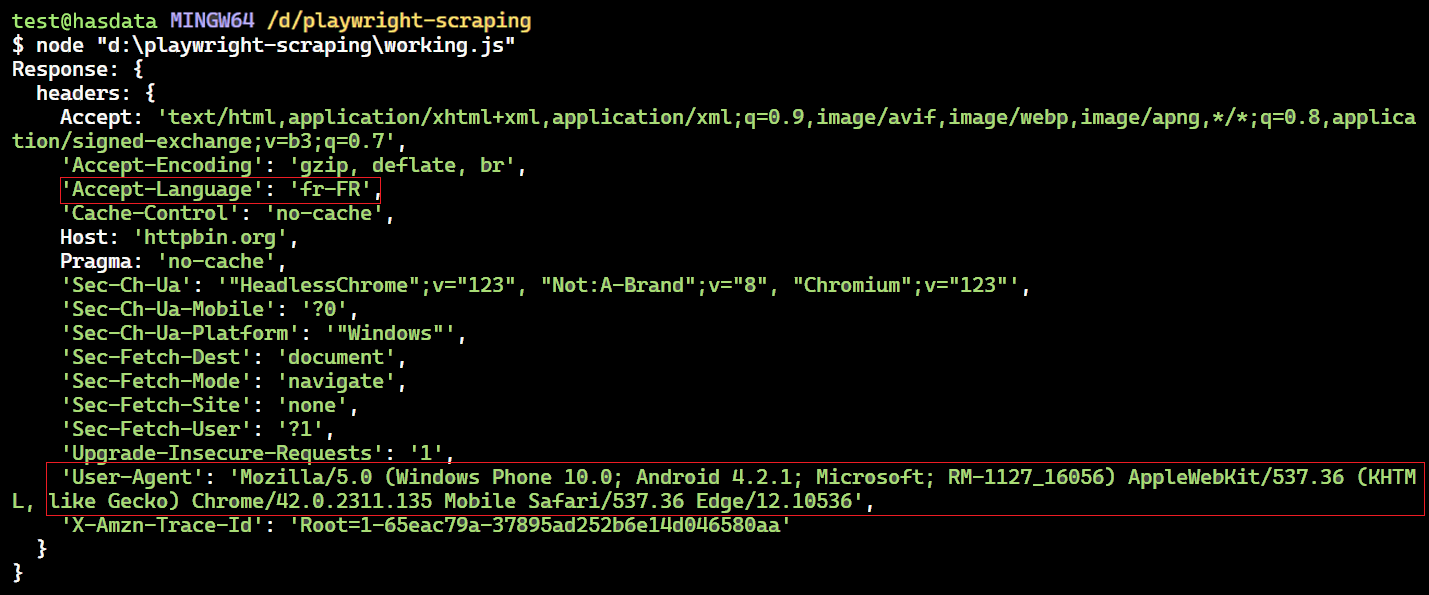
})();Der Code richtet einen Routenhandler für die URL ein https://httpbin.org/headers. Dieser Handler fängt Anfragen ab und ändert bestimmte Header wie „Accept-Language“ und „User-Agent“, bevor er sie sendet.
Innerhalb der Handlerfunktion wird die geändert Accept-Language Kopfzeile zu 'fr-FR' (Französisch) und die User-Agent auch die Kopfzeile. Nach diesen Änderungen setzt der Handler die Anforderung mit den aktualisierten Headern fort route.continue().
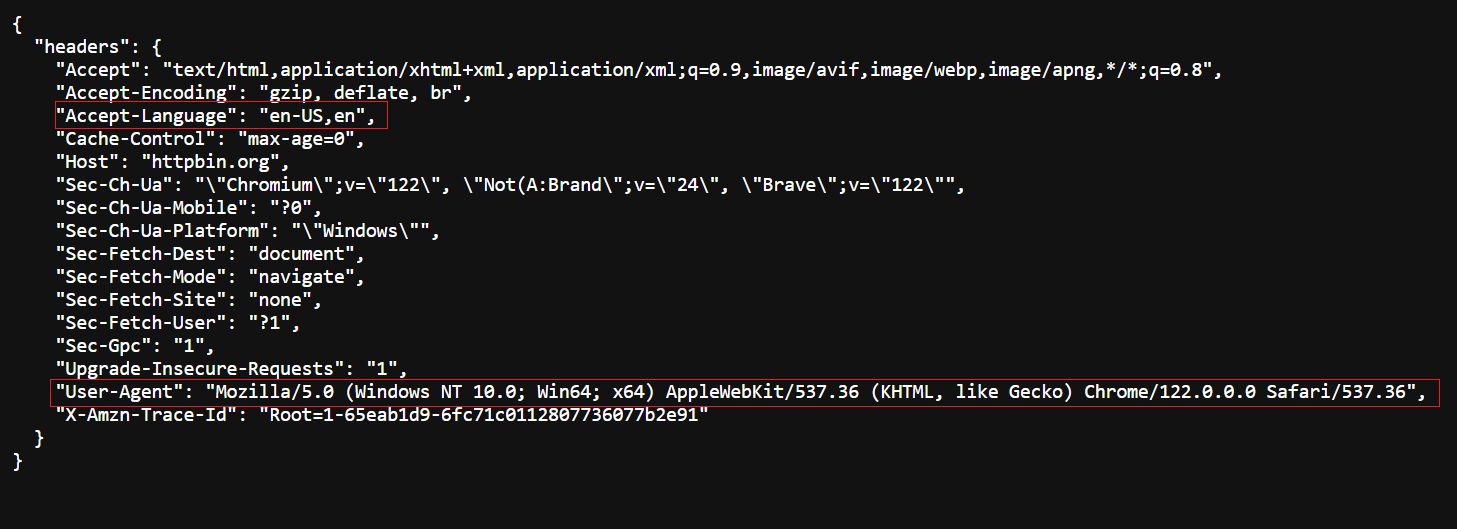
Original-Header – besuchen Sie https://httpbin.org/headers, um den Original-Header anzuzeigen.
Geänderter Header – von unserem Code zurückgegeben.
Ausfüllen von Formularen
Das Ausfüllen und Absenden von Formularen ist mit Playwright ganz einfach. Sie müssen nur die Selektoren an übergeben .fill() Funktion zum Ausfüllen der Werte in den Eingabefeldern wie Benutzername und Passwort. Dann nutzen Sie die .click() Funktion zum Absenden des Formulars.
Sehen wir uns dies in Aktion an, indem wir uns mit Playwright bei unserem Reddit-Konto anmelden.
import { chromium } from 'playwright';
(async () => {
const browser = await chromium.launch({ headless: true });
const page = await browser.newPage();
await page.goto('<https://reddit.com/login>');
await page.fill('input(name="username")', "satyamtri");
await page.fill('input(name="password")', "<secret-password>");
await page.click('.login');
await page.waitForNavigation();
await page.screenshot({
path: "reddit.png",
fullPage: false
});
await browser.close();
})();Das Ergebnis ist:
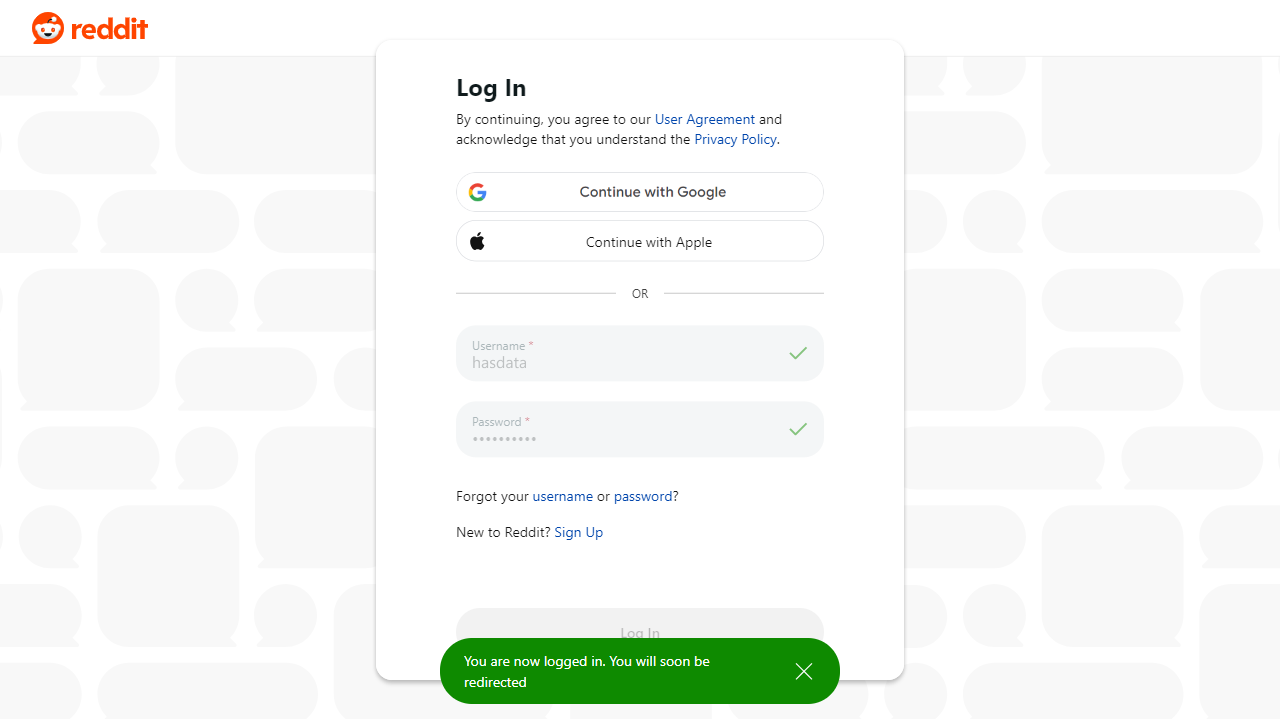
Screenshot-Erfassung von Webseiten
Mit Playwright können Sie Screenshots von Webseiten aufnehmen. Diese Funktion ist für die visuelle Überprüfung wertvoll, da sie es Ihnen ermöglicht, den Schnappschuss zu jedem Zeitpunkt zu erfassen.
import { chromium } from 'playwright';
async function screenShot() {
const browser = await chromium.launch({
headless: true
});
const context = await browser.newContext();
const page = await context.newPage();
await page.setViewportSize({ width: 1280, height: 800 }); // set screenshot dimension
await page.goto('<https://github.com/topics/nodejs>')
await page.screenshot({ path: 'images/screenshot.png' })
await browser.close()
}
screenShot();Das Ergebnis ist:
Um die gesamte Seite zu erfassen, legen Sie fest fullPage Eigentum zu true. Sie können auch das Bildformat ändern jpg oder jpeg zum Speichern in verschiedenen Formaten.
await page.screenshot({ path: 'images/screenshot.jpg', fullPage: true });Um einen bestimmten Bereich auf einer Webseite zu erfassen, verwenden Sie die clip Eigentum. Es erfordert die Definition von vier Werten:
x: Horizontaler Abstand von der oberen linken Ecke des Erfassungsbereichs.y: Vertikaler Abstand von der oberen linken Ecke des Erfassungsbereichs.width: Breite des Erfassungsbereichs.height: Höhe des Erfassungsbereichs.
await page.screenshot({
path: "images/screenshot.png", fullPage: false, clip: {
x: 5,
y: 5,
width: 320,
height: 160
}
});Das Ergebnis ist:
Gekratzte Daten in Excel speichern
Eindrucksvoll! Wir haben die Daten erfolgreich gelöscht. Speichern wir es in einer Excel-Datei, anstatt es auf der Konsole auszudrucken.
Wir werden das verwenden exceljs Paket zum Schreiben der Daten in die Excel-Datei. Aber bevor Sie dies tun, installieren Sie es mit dem folgenden Befehl:
npm install exceljsHier ist der Codeausschnitt zum Speichern von Daten in der Excel-Datei:
const workbook = new ExcelJS.Workbook();
const sheet = workbook.addWorksheet('GitHub Repositories');
sheet.columns = (
{ header: 'User', key: 'user' },
{ header: 'Repository Name', key: 'repoName' },
{ header: 'Stars', key: 'repoStar' },
{ header: 'Description', key: 'repoDescription' },
{ header: 'Repository URL', key: 'repoUrl' },
{ header: 'Tags', key: 'tags' }
);
uniqueList.forEach(entry => {
sheet.addRow(entry);
});
await workbook.xlsx.writeFile('github_repos.xlsx');Das Code-Snippet nutzt mehrere Funktionen:
new ExcelJS.Workbook(): Erstellt ein neues ExcelJS-Arbeitsmappenobjekt.workbook.addWorksheet('GitHub Repositories'): Fügt der Arbeitsmappe ein neues Arbeitsblatt mit dem Namen „GitHub Repositories“ hinzu.sheet.columns: Definiert die Spalten im Arbeitsblatt. Jedes Spaltenobjekt gibt den Header und den Schlüssel für diese Spalte an.sheet.addRow(entry): Fügt dem Arbeitsblatt eine Zeile mit Daten aus dem Eintragsobjekt hinzu (stellt Daten für eine einzelne Zeile dar).workbook.xlsx.writeFile('github_repos.xlsx'): Schreibt die Arbeitsmappe in eine Datei mit dem Namen „github_repos.xlsx“ im XLSX-Format.
Der vollständige Code:
import { chromium } from 'playwright';
import ExcelJS from 'exceljs';
async function scrapeData(numRepos) {
let browser;
try {
browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('<https://github.com/topics/nodejs>');
const uniqueRepos = new Set();
while (uniqueRepos.size < numRepos) {
const extractedData = await page.$$eval('article.border', repos => {
return repos.map(repo => {
const userLink = repo.querySelector('h3 > a:first-child');
const repoLink = repo.querySelector('h3 > a:last-child');
const user = userLink?.textContent.trim() || '';
const repoName = repoLink?.textContent.trim() || '';
const repoStar = repo.querySelector('#repo-stars-counter-star')?.title || '';
const repoDescription = repo.querySelector('div.px-3 > p')?.textContent.trim() || '';
const tags = Array.from(repo.querySelectorAll('a.topic-tag')).map(tag => tag.textContent.trim());
const repoUrl = repoLink?.href || '';
return { user, repoName, repoStar, repoDescription, tags, repoUrl };
});
});
if (extractedData.length === 0) {
console.log('No articles found on this page.');
break;
}
extractedData.forEach(entry => uniqueRepos.add(JSON.stringify(entry)));
if (uniqueRepos.size >= numRepos) {
break;
}
const button = await page.locator('button(type="submit").ajax-pagination-btn.f6');
if (!button) {
console.log('Next button not found. All data scraped.');
break;
}
await button.click();
await page.waitForLoadState('networkidle');
}
const uniqueList = Array.from(uniqueRepos).slice(0, numRepos).map(entry => JSON.parse(entry));
// Save data to Excel file
const workbook = new ExcelJS.Workbook();
const sheet = workbook.addWorksheet('GitHub Repositories');
sheet.columns = (
{ header: 'User', key: 'user' },
{ header: 'Repository Name', key: 'repoName' },
{ header: 'Stars', key: 'repoStar' },
{ header: 'Description', key: 'repoDescription' },
{ header: 'Repository URL', key: 'repoUrl' },
{ header: 'Tags', key: 'tags' }
);
uniqueList.forEach(entry => {
sheet.addRow(entry);
});
await workbook.xlsx.writeFile('github_repos.xlsx');
console.log('Data saved to excel file.');
} catch (error) {
console.error('Error during scraping:', error);
} finally {
if (browser) {
await browser.close();
}
}
}
scrapeData(30).catch(error => console.error('Unhandled error:', error));Das Ergebnis ist:

Andere Tools wie Selenium und Puppeteer bieten ähnliche Funktionalitäten wie Playwright. Allerdings hat jedes Tool seine Stärken in Bezug auf Ausführungsgeschwindigkeit, Entwicklererfahrung und Community-Support.
Playwright zeichnet sich durch seine Fähigkeit aus, mithilfe einer einzigen API nahtlos in mehreren Browsern (einschließlich Chromium, WebKit und Firefox) zu laufen. Es verfügt außerdem über eine umfangreiche Dokumentation und unterstützt verschiedene Programmiersprachen wie Python, Node.js, Java und .NET.
Während Puppeteer auch entwicklerfreundlich und einfach einzurichten ist, ist es auf JavaScript- und Chromium-Browser beschränkt. Selenium hingegen bietet die umfassendste Browser- und Sprachunterstützung, kann jedoch langsamer und weniger benutzerfreundlich sein.
Was die Geschwindigkeit betrifft, liegt Puppeteer im Allgemeinen an der Spitze, dicht gefolgt von Playwright (wobei Playwright in einigen Fällen sogar Puppeteer übertrifft). Selen hinkt in der Leistung hinterher.
Lassen Sie uns die NPM-Trends und die Beliebtheit dieser drei Bibliotheken untersuchen. Die Daten deuten darauf hin, dass die Akzeptanz von Playwright bei Entwicklern zunimmt.
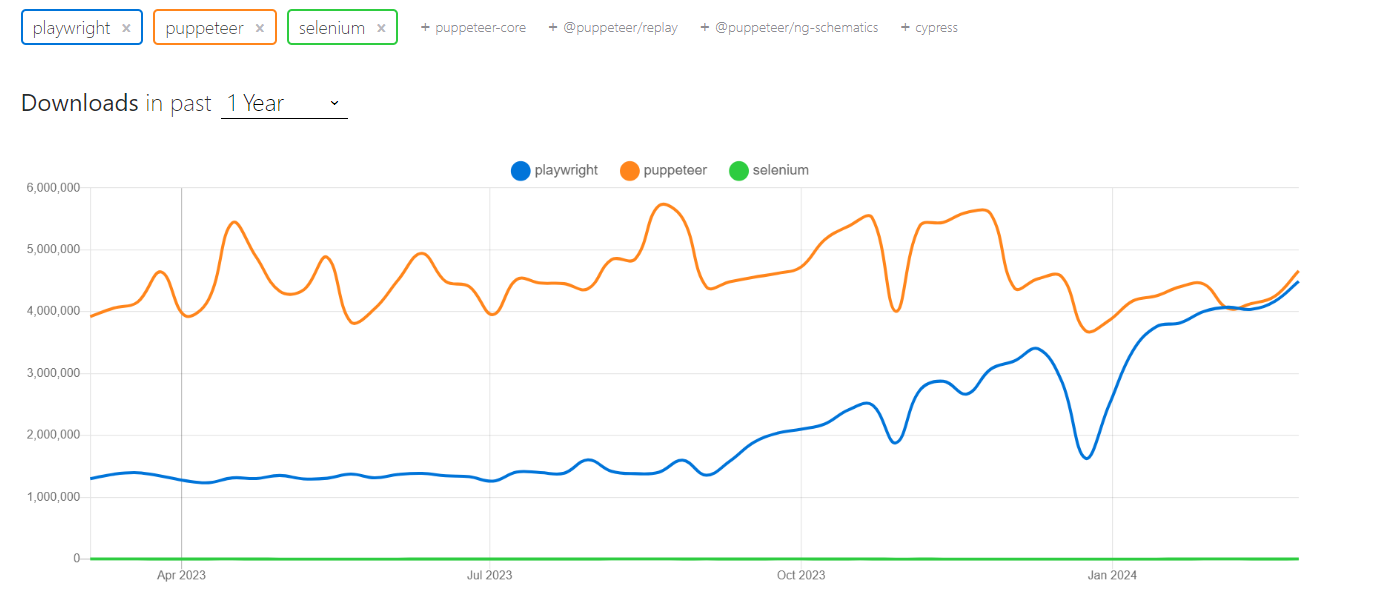
Werfen wir einen Blick auf die Vergleichstabelle:
| Parameter | Dramatiker | Puppenspieler | Selen |
|---|---|---|---|
| Geschwindigkeit | Schnell | Schnell | Langsam |
| Dokumentation | Exzellent | Exzellent | Gerecht |
| Entwicklererfahrung | Am besten | Gut | Gerecht |
| Sprachunterstützung | JavaScript, Python, C#, Java | JavaScript | Java, Python, C#, Ruby, JavaScript, Kotlin |
| Von | Microsoft | Community und Sponsoren | |
| Gemeinschaft | Klein, aber aktiv | Groß und aktiv | Groß und aktiv |
| Browser-Unterstützung | Chromium, Firefox und WebKit | Chrom | Chrome, Firefox, IE, Edge, Opera, Safari |
Abschluss
Playwright bietet ein leistungsstarkes und vielseitiges Toolkit für Web-Scraping-Aufgaben mit hervorragender Dokumentation und einer wachsenden Community. Durch die Nutzung seiner Funktionen können Sie wertvolle Daten effizient aus Websites extrahieren, sich wiederholende Browserinteraktionen automatisieren und verschiedene Arbeitsabläufe optimieren.
In diesem Leitfaden haben wir uns auf die GitHub-Themenseite konzentriert, auf der Sie ein Thema (z. B. NodeJS) auswählen und die Anzahl der Repositorys zum Scrapen angeben können. Wir haben den Umgang mit Fehlern und Randfällen beim Scraping, die Verwendung von Proxys zur Vermeidung von Erkennung und den Vergleich mit Selenium und Puppeteer erläutert.
Wenn Sie Erfahrung sammeln, lernen Sie fortgeschrittene Techniken im Detail kennen, z. B. das Konfigurieren von Proxys, das Abfangen von Anfragen, das Verwalten von Cookies und das Blockieren unnötiger Ressourcen und Bilder. Sie können mehr über Playwright erfahren, indem Sie die offizielle Dokumentation besuchen, die leicht verständlich und detailliert ist.
