
Go, auch bekannt als Golang, ist eine von Google entwickelte Open-Source-Programmiersprache. Durch den Verzicht auf komplexe Sprachkonstrukte und einen minimalen Satz an Schlüsselwörtern und integrierten Typen erfreut sich Go selbst bei Anfängern großer Beliebtheit.
Darüber hinaus bietet Go integrierte Unterstützung für Parallelität durch Goroutinen und Kanäle. Goroutinen sind leichtgewichtige Threads, die eine parallele Ausführung ermöglichen, während Kanäle ein sicheres Mittel zur Kommunikation und Datensynchronisierung zwischen Goroutinen bieten. Dies erleichtert das Schreiben gleichzeitiger und skalierbarer Programme.
Neben seiner Einfachheit und der integrierten Unterstützung für Parallelität verfügt Go über zahlreiche verfügbare Bibliotheken und Tools, die seine Fähigkeiten erheblich erweitern. Diese Ressourcen decken verschiedene Bereiche ab, einschließlich Web Scraping, und ermöglichen es Entwicklern, Daten aus Websites und Online-Quellen effizient zu extrahieren und zu verarbeiten.
Erste Schritte mit Go
Bevor wir die Daten Schritt für Schritt durchsuchen und verschiedene Bibliotheken erkunden, bereiten wir unsere Umgebung vor und richten sie ein. Als Erstes installieren wir Git, damit wir Go-Bibliotheken direkt von GitHub abrufen können. Laden Sie die erforderliche Version von der offiziellen Website herunter und installieren Sie sie. Wenn Sie Anfänger sind und Git noch nie verwendet haben, empfehlen wir, die Standardeinstellungen unverändert beizubehalten.
Jetzt ist es tatsächlich an der Zeit, Go zu installieren. Besuchen Sie dazu einfach die offizielle Go-Website, laden Sie die Installationsdatei herunter und befolgen Sie die Anweisungen während der Installation.
Um sicherzustellen, dass Sie Go erfolgreich installiert haben, können Sie den Befehl „go version“ verwenden:
C:\Scripts>go-Version
go-Version go1.20.5 Windows/AMD64
Sie können jeden beliebigen Texteditor zum Schreiben von Code verwenden, es ist jedoch besser, zur Vereinfachung und Syntaxhervorhebung spezielle Tools zu verwenden. Wir werden Visual Studio Code verwenden.
Nachdem die Einrichtung der Umgebung abgeschlossen ist, schauen wir uns die Beispielseiten und Go-Bibliotheken zum Scrapen an. Wir werden besprechen, wie man mithilfe dieser Bibliotheken einfache Scraper installiert und erstellt, und deren Funktionalität demonstrieren.
Inspektion der Zielwebsite
Vor dem Scrapen von Webseiten ist es wichtig, die Zielwebsite zu analysieren. Dies ist notwendig, um genau herauszufinden, wo sich die von uns benötigten Informationen befinden. Wir sollten wissen, welche Tags und Klassen die erforderlichen Elemente enthalten. Beispielsweise können wir innerhalb von
Beispielseite
Um die Webseite „example.com“ zu analysieren, müssen wir ihre Struktur und ihren Inhalt untersuchen. Durch die Untersuchung des HTML-Codes der Seite können wir die Tags und Klassen identifizieren, die die erforderlichen Informationen enthalten. Gehen Sie dazu auf die Seite und öffnen Sie die DevTools (drücken Sie F12 oder klicken Sie mit der rechten Maustaste auf den Bildschirm und wählen Sie „Inspizieren“).
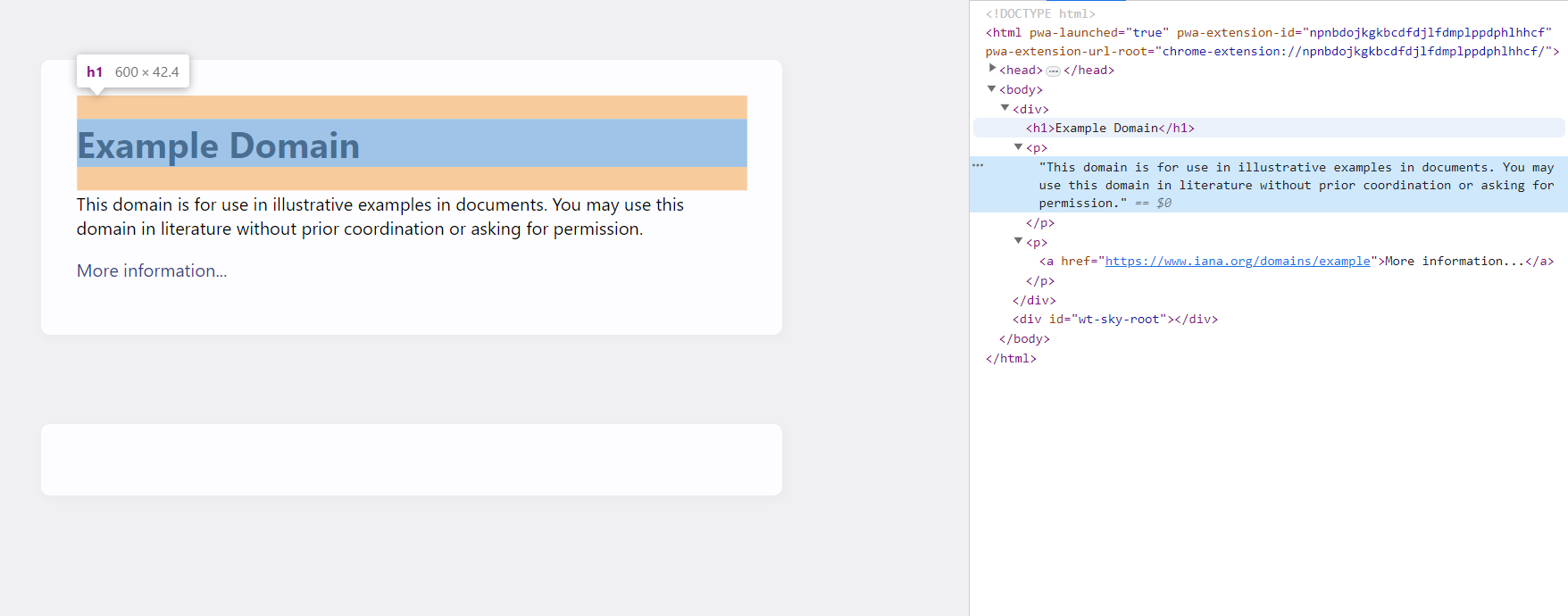
Wie wir sehen können, befindet sich der Seitentitel im h1-Tag und der Rest des Textes wird in den p-Tags gespeichert. Wir können jetzt CSS-Selektoren oder XPATH verwenden, um die gewünschten Informationen zu extrahieren.
Beispielshop
Diese Website verfügt über viel mehr Daten und eine Struktur, die näher an der Realität ist. Jedes Element verfügt über ein div-Element mit der Klasse „col“, und in diesem div finden Sie die folgenden Informationen:
- Das Bild befindet sich in einem div-Tag mit der Klasse „image“ innerhalb eines verschachtelten „a“-Tags mit dem „href“-Attribut.
- Der Produktname befindet sich in einem „h4“-Tag. Darin befindet sich auch der Link zur Produktseite in einem verschachtelten „a“-Tag mit dem „href“-Attribut.
- Die Produktbeschreibung befindet sich in einem „p“-Tag.
- Der Preis befindet sich in einem div-Tag mit der Klasse „price“. Es hat auch verschachtelte Tags:
- Der Originalpreis steht in einem „span“-Tag mit der Klasse „price-old“.
- Der reduzierte Preis befindet sich in einem „span“-Tag mit der Klasse „price-new“.
- Die Steuerinformationen befinden sich in einem „span“-Tag mit der Klasse „price-tax“.
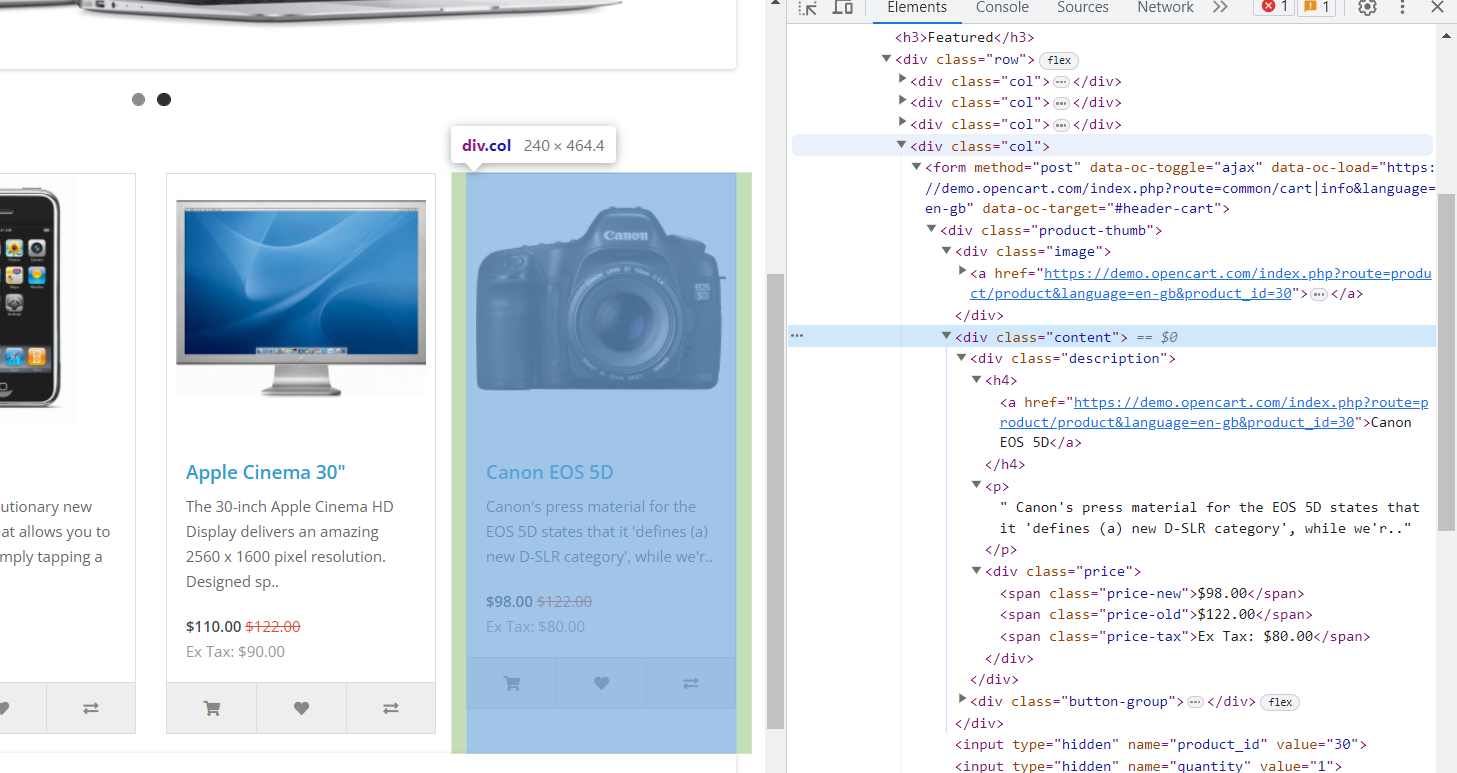
Da wir nun die Struktur beider Websites kennen, die wir durchsuchen werden, können wir die Bibliotheken auswählen.
Die besten Go Web Scraping-Bibliotheken
Go verfügt über eine wachsende und aktive Entwicklergemeinschaft. Es verfügt über ein starkes Bibliotheks- und Framework-Ökosystem, das eine breite Palette von Anwendungen abdeckt, darunter Webentwicklung, Netzwerke, Datenbanken und Web-Scraping. Aber heute konzentrieren wir uns auf drei beliebte Go-Bibliotheken zum Scrapen:
- Goquery;
- Colly;
- Pholkus.
Abhängig von der gewählten Bibliothek können Sie einfache Anforderungsfunktionen oder erweiterte Funktionen wie dynamisches Seitenrendering, Extraktion regulärer Ausdrücke und verteiltes Scraping verwenden.
Um Anfängern das Golang-Web-Scraping zu erleichtern und ihnen vielseitige Beispiele zur Verfügung zu stellen, demonstrieren wir zusätzlich zu den drei aufgeführten Bibliotheken auch die Verwendung unserer Web-Scraping-API. Es ermöglicht Ihnen, Daten automatisch zu extrahieren, verwaltet die Proxy-Nutzung, löst JavaScript-Rendering-Probleme und umgeht Captchas und Blöcke.
Erhalten Sie Daten mit der Scrape-It.Cloud-API
Die Web-Scraping-API mit rotierenden Proxys von Scrape-It.Cloud bietet einige große Vorteile. Es erleichtert das Scrapen von Daten von Websites, da Sie sich keine Gedanken über Proxys machen müssen. Die API ist einfach zu verwenden und funktioniert mit verschiedenen Programmiersprachen wie Golang, Python oder NodeJS.
Es kann Websites verarbeiten, die JavaScript verwenden, sodass Sie dynamische Inhalte extrahieren können. Die Funktion für rotierende Proxys hilft Ihnen, anonym zu bleiben und Blockierungen zu vermeiden. Der Dienst kann sowohl kleine als auch große Scraping-Aufgaben erledigen. Die Preispläne sind flexibel; Sie können sie sogar kostenlos ausprobieren. Insgesamt handelt es sich um eine einfache und bequeme Lösung zur Datenextraktion von Websites.
Bereiten Sie sich auf das Schaben vor
Wir werden die net/http-Bibliothek verwenden, um HTTP-Anfragen für die Scrapi-It.Cloud-API zu stellen. Es handelt sich um eine Bibliothek zum Stellen von Anfragen, die uns dabei hilft, Anfragen an Websites zu stellen. Um die Net/http-Bibliothek zu installieren, müssen Sie nichts Besonderes tun. Es handelt sich um ein integriertes Paket in der Programmiersprache Go. Wenn Sie Go auf Ihrem System installieren, wird die Net/http-Bibliothek automatisch mitgeliefert. Sie können es ohne zusätzliche Installationsschritte in Ihren Go-Programmen verwenden.
Wir benötigen außerdem einen API-Schlüssel, den Sie nach der Anmeldung bei Scrape-It.Cloud erhalten, sowie ein paar kostenlose Credits für die Nutzung der API.
Beispiel verwenden
Lassen Sie uns zuerst die Daten für example.com abrufen. Deklarieren Sie zunächst die Bibliotheken:
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
"strings"
)Wir werden den gesamten Code in die Hauptfunktion schreiben, also deklarieren wir ihn:
func main() { }In dieser Funktion müssen wir nun mit den erforderlichen Parametern auf die Scrape-It.Cloud-API zugreifen, eine JSON-Antwort mit den Daten erhalten und die erforderlichen Informationen auf dem Bildschirm anzeigen.
Lassen Sie uns den Anfragetyp deklarieren und seine Parameter festlegen (Anfragetext):
url := "https://api.scrape-it.cloud/scrape"
method := "POST"
payload := strings.NewReader(`{
"extract_rules": {
"Title": "h1",
"Description": "p"
},
"wait": 0,
"screenshot": true,
"block_resources": false,
"url": "https://example.com/"
}`)
client := &http.Client{}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
Zusätzlich zum Anfragetext deklarieren wir auch die Anfrageheader.
req.Header.Add("x-api-key", "YOUR-API-KEY")
req.Header.Add("Content-Type", "application/json")Als nächstes können wir eine Anfrage stellen und die Daten abrufen:
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()Jetzt müssen wir die Daten nur noch so verarbeiten, dass wir nur die Elemente extrahieren, die sich in („scrapingResult“) („extractedData“) („Title“) und („scrapingResult“) („extractedData“) („Description“) befinden. aus dem JSON-Code, den wir erhalten haben. Um sicherzustellen, dass wir auf die richtigen Attribute abzielen, können Sie die JSON-Antwort auf dem Bildschirm anzeigen oder sich die Beispielantwort in unserer API-Dokumentation ansehen.
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
var response map(string)interface{}
err = json.Unmarshal(body, &response)
if err != nil {
fmt.Println(err)
return
}
if response("status") != "ok" {
fmt.Println("Error: Request failed")
return
}
scrapingResult := response("scrapingResult").(map(string)interface{})
extractedData := scrapingResult("extractedData").(map(string)interface{})
Jetzt müssen wir nur noch diese Variablen auf dem Bildschirm anzeigen:
fmt.Println("Title:", extractedData("Title"))
fmt.Println("Description:", extractedData("Description"))Sammeln wir Daten von der zweiten Website, um sicherzustellen, dass dieser Ansatz einfach ist. Dafür müssen wir keine wesentlichen Änderungen an unserem Code vornehmen. Wir müssen den Anfragetext ersetzen und Variablen hinzufügen, um die Daten abzurufen. Wir zeigen nicht die Teile des Codes an, die unverändert bleiben, sondern stellen am Ende den vollständigen Code zum Scrapen der Produktwebsite bereit.
Ändern wir also den Anforderungstext:
payload := strings.NewReader(`{
"extract_rules": {
"Title":"h4",
"Link":"h4 > a @href",
"Description":"p",
"Old":"span.price-old",
"New":"span.price-new",
"Tax":"span.price-tax",
"Image":".image > a @href"
},
"wait": 0,
"screenshot": true,
"block_resources": false,
"url": "https://demo.opencart.com/"
}`)
Fügen Sie am Ende die Ausgabe neuer Daten hinzu:
fmt.Println("Titles:", extractedData("Title"))
fmt.Println("Links:", extractedData("Link"))
fmt.Println("Descriptions:", extractedData("Description"))
fmt.Println("Old Prices:", extractedData("Old"))
fmt.Println("New Prices:", extractedData("New"))
fmt.Println("Taxes:", extractedData("Tax"))
fmt.Println("Images:", extractedData("Image"))Das sind alle vorgenommenen Skriptänderungen. Lassen Sie es uns ausführen und alle Daten abrufen, die wir benötigen.
D:\scripts>go run scraper.go
Titles: (MacBook iPhone Apple Cinema 30" Canon EOS 5D)
Links: (https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=43 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=40 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=42 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=30)
Descriptions: (Your shopping cart is empty!
Intel Core 2 Duo processor
Powered by an Intel Core 2 Duo processor at speeds up to 2.1..
iPhone is a revolutionary new mobile phone that allows you to make a call by simply tapping a nam..
The 30-inch Apple Cinema HD Display delivers an amazing 2560 x 1600 pixel resolution. Designed sp..
Canon's press material for the EOS 5D states that it 'defines (a) new D-SLR category', while we'r.. Powered By OpenCart Your Store © 2023)
Old Prices: ($122.00 $122.00)
New Prices: ($602.00 $123.20 $110.00 $98.00)
Taxes: (Ex Tax: $500.00 Ex Tax: $101.00 Ex Tax: $90.00 Ex Tax: $80.00)
Images: (https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=43 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=40 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=42 https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=30)Vollständiger Code:
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
"strings"
)
func main() {
url := "https://api.scrape-it.cloud/scrape"
method := "POST"
payload := strings.NewReader(`{
"extract_rules": {
"Title":"h4",
"Link":"h4 > a @href",
"Description":"p",
"Old":"span.price-old",
"New":"span.price-new",
"Tax":"span.price-tax",
"Image":".image > a @href"
},
"wait": 0,
"screenshot": true,
"block_resources": false,
"url": "https://demo.opencart.com/"
}`)
client := &http.Client{}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("x-api-key", "1cb2a4a1-a569-423e-835e-07c3b1308bfe")
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
var response map(string)interface{}
err = json.Unmarshal(body, &response)
if err != nil {
fmt.Println(err)
return
}
if response("status") != "ok" {
fmt.Println("Error: Request failed")
return
}
scrapingResult := response("scrapingResult").(map(string)interface{})
extractedData := scrapingResult("extractedData").(map(string)interface{})
fmt.Println("Titles:", extractedData("Title"))
fmt.Println("Links:", extractedData("Link"))
fmt.Println("Descriptions:", extractedData("Description"))
fmt.Println("Old Prices:", extractedData("Old"))
fmt.Println("New Prices:", extractedData("New"))
fmt.Println("Taxes:", extractedData("Tax"))
fmt.Println("Images:", extractedData("Image"))
}Wie Sie sehen, ist es ziemlich einfach und selbst Anfänger können dieses Beispiel für ihre eigenen Zwecke modifizieren.
Einfaches Parsen mit GoQuery
Goquery ist eine beliebte Go-Bibliothek, die eine bequeme Möglichkeit bietet, HTML- oder XML-Dokumente zu analysieren und Daten mithilfe von CSS-Selektoren zu extrahieren. Es basiert auf jQuery, einer weit verbreiteten JavaScript-Bibliothek zum Bearbeiten und Durchsuchen von HTML-Dokumenten.
Installieren Sie die GoQuery-Bibliothek
Um die GoQuery-Bibliothek nutzen zu können, müssen wir sie zunächst installieren. Sie können dies tun, indem Sie den folgenden Befehl im Terminal verwenden:
go get github.com/PuerkitoBio/goqueryUnd jetzt können Sie es in Ihren Projekten verwenden.
Beispiel verwenden
Beginnen wir wie im vorherigen Beispiel damit, die erforderlichen Bibliotheken einzubinden und die Hauptfunktion zu deklarieren:
package main
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() { }Lassen Sie uns eine Anfrage stellen und die Daten, die wir erhalten, in einer Variablen speichern. Es ist auch wichtig, die Fehlerprüfung nicht zu vergessen.
url := "https://example.com"
resp, err := http.Get(url)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatal(err)
}Lassen Sie uns nun mithilfe der integrierten Funktionen der GoQuery-Bibliothek die gewünschten Daten mithilfe von CSS-Selektoren finden.
doc.Find("h1").Each(func(_ int, s *goquery.Selection) {
fmt.Println(s.Text())
})Als Ergebnis erhalten wir den Seitentitel.
D:\scripts>go run scraper.go
Example DomainVollständiger Code:
package main
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() {
url := "https://example.com"
resp, err := http.Get(url)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatal(err)
}
doc.Find("h1").Each(func(_ int, s *goquery.Selection) {
fmt.Println(s.Text())
})
}Wir haben das Scraping der Website example.com mithilfe einer API und einer Bibliothek besprochen, aber da dieses Beispiel zu einfach war, werden wir nicht noch einmal darauf zurückkommen. Schreiben wir einen Scraper für eine Website, die Produkte verkauft.
Die Bibliotheksdeklaration bleibt, wie der Großteil des Skripts, unverändert. Wir müssen lediglich den Link zur Seite und die Selektoren ersetzen, um die erforderlichen Daten zu erhalten. Ändern wir zunächst den Link zur Seite:
url := "https://demo.opencart.com/" Wir müssen jedes Produkt überprüfen und von jedem die benötigten Tags extrahieren. Zur Vereinfachung speichern wir die Daten in Variablen und zeigen sie auf dem Bildschirm an.
doc.Find("div.col").Each(func(_ int, s *goquery.Selection) {
image := s.Find(".image a").AttrOr("href", "")
productName := s.Find("h4 a").Text()
productLink := s.Find("h4 a").AttrOr("href", "")
description := s.Find("p").Text()
oldPrice := s.Find(".price-old").Text()
newPrice := s.Find(".price-new").Text()
tax := s.Find(".price-tax").Text()
fmt.Println("Image:", image)
fmt.Println("Product Name:", productName)
fmt.Println("Product Link:", productLink)
fmt.Println("Description:", description)
fmt.Println("Old Price:", oldPrice)
fmt.Println("New Price:", newPrice)
fmt.Println("Tax:", tax)
fmt.Println()
})Das Skript zeigt alle Produkte an und lässt der Einfachheit halber eine Leerzeile dazwischen. Hier ist ein Beispiel für die Ausgabe eines der Elemente:
Image: https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=30
Product Name: Canon EOS 5D
Product Link: https://demo.opencart.com/index.php?route=product/product&language=en-gb&product_id=30
Description:
Canon's press material for the EOS 5D states that it 'defines (a) new D-SLR category', while we'r..
Old Price: $122.00
New Price: $98.00
Tax: Ex Tax: $80.00Wie Sie sehen, ist das Erstellen eines Scraping-Skripts in Go mithilfe der GoQuery-Bibliothek eine relativ einfache Aufgabe.
Allerdings weist die GoQuery-Bibliothek einige Nachteile auf, die möglicherweise die Verwendung anderer, funktionalerer Bibliotheken erforderlich machen. Einer dieser Nachteile besteht darin, dass GoQuery nur eine begrenzte Anzahl von CSS-Selektoren unterstützt, was Ihre Möglichkeiten beim Extrahieren von Daten aus einem HTML-Dokument einschränken kann.
Darüber hinaus funktioniert GoQuery nur mit statischem HTML-Code. Wenn Ihre Zielseite dynamisches JavaScript zum Generieren oder Ändern von Inhalten verwendet, kann GoQuery diese Inhalte nicht verarbeiten, da es nicht über eine integrierte JavaScript-Engine verfügt.
Gehen wir also zur nächsten Bibliothek.
Scrapen Sie dynamische Daten mit Colly
Die Colly-Bibliothek ist ein weiteres beliebtes Tool zum Scrapen von Webseiten in der Go-Sprache. Es unterstützt verschiedene Funktionen wie das Navigieren auf Seiten, das Extrahieren von Daten, die Fehlerbehandlung, das Arbeiten mit Formularen und mehr.
Darüber hinaus ermöglicht Colly die asynchrone Ausführung von Webseitenanfragen. Dies bedeutet, dass Sie mehrere Seiten gleichzeitig scannen und verarbeiten können, wodurch die Leistung verbessert und die Scraping-Zeit verkürzt wird.
Darüber hinaus verwaltet die Colly-Bibliothek mit ihren Headless-Browser-Funktionen effektiv JavaScript auf der Seite. Es bietet außerdem benutzerfreundliche Methoden für die Seitennavigation, das Folgen von Links, das Senden von Formularen und verschiedene andere Website-Interaktionen.
Installieren Sie die Colly-Bibliothek
In der Vergangenheit verwendete Colly PhantomJS, um JavaScript auf Webseiten zu verarbeiten. Ab Version 2.0 wechselte Colly jedoch dazu, die Standard-Go-Bibliothek für die Verarbeitung von JavaScript zu verwenden.
Um Colly nutzen zu können, müssen wir lediglich die Colly-Bibliothek installieren:
go get -u github.com/gocolly/colly/v2Jetzt können wir mit Colly einen Scraper schreiben.
Beispiel verwenden
Wie bereits erwähnt, werden wir example.com nicht mehr verwenden. Beginnen wir also direkt mit dem Scrapen einer Produktseite aus einem Test-Onlineshop. Lassen Sie uns zunächst Bibliotheken deklarieren, die Webseitenadresse angeben und einen Collector erstellen, der für die Navigation und das Sammeln von Daten von der Webseite verwendet wird.
package main
import (
"fmt"
"log"
"github.com/gocolly/colly/v2"
)
func main() {
url := "https://demo.opencart.com/"
c := colly.NewCollector()
}
Als Nächstes definieren wir mithilfe der OnHTML-Methode Ereignishandler für verschiedene Elemente auf der Seite. In diesen Handlern legen wir fest, welche Daten wir aus den entsprechenden HTML-Elementen extrahieren müssen.
c.OnHTML("div.col", func(e *colly.HTMLElement) {
image := e.ChildAttr("div.image a", "href")
productName := e.ChildText("h4 a")
productLink := e.ChildAttr("h4 a", "href")
description := e.ChildText("p")
oldPrice := e.ChildText(".price-old")
newPrice := e.ChildText(".price-new")
tax := e.ChildText(".price-tax")
fmt.Println("Image:", image)
fmt.Println("Product Name:", productName)
fmt.Println("Product Link:", productLink)
fmt.Println("Description:", description)
fmt.Println("Old Price:", oldPrice)
fmt.Println("New Price:", newPrice)
fmt.Println("Tax:", tax)
fmt.Println()
})
Nachdem wir die Handler definiert haben, verwenden wir die Callback-Funktion, um den Collector zur URL navigieren zu lassen. Zu diesem Zeitpunkt besucht der Collector die Seite, löst die relevanten Handler aus und extrahiert Daten.
err := c.Visit(url)
if err != nil {
log.Fatal(err)
}Dadurch erzielen wir das gleiche Ergebnis wie bei Verwendung der GoQuery-Bibliothek, jedoch mit höherer Geschwindigkeit und Funktionalität. Allerdings ist Colly eine leistungsstarke Bibliothek und damit etwas komplexer als einfachere Bibliotheken wie GoQuery, das sich besser zum Parsen einfacher Websites eignet.
Funktionelles Scraping mit Pholcus Framework
Das Pholcus-Framework (auch bekannt als „Pholcus-WebCrawler“) ist ein vielseitiges Web-Scraping-Framework, das mit der Programmiersprache Go erstellt wurde. Sein Zweck besteht darin, die Erstellung und Verwaltung von Web-Scrapern zu vereinfachen.
Pholcus bietet einen umfassenden Satz an Tools zum Extrahieren von Daten aus Webseiten. Es unterstützt Techniken wie reguläre Ausdrücke, XPath und CSS-Selektoren. Darüber hinaus bietet das Framework die Möglichkeit, Proxyserver zu verwenden, die dabei helfen können, Websites mit IP-Beschränkungen zu entfernen oder Anonymität zu gewährleisten.
Installieren Sie das Pholcus Framework
Um Pholcus und seine Abhängigkeiten zu installieren, können Sie den folgenden Befehl in der Eingabeaufforderung verwenden:
go get -u github.com/henrylee2cn/pholcusNach der Installation können Sie die Bibliothek importieren und in Ihren Skripten verwenden.
Beispiel verwenden
Die Verwendung dieses Frameworks ist der Verwendung der Colly-Bibliothek sehr ähnlich. Wenn Sie also das vorherige Beispiel gesehen haben, werden Sie keine Schwierigkeiten haben, mit Pholcus einen ähnlichen Go-Scraper oder Crawler zu schreiben.
Zunächst importieren wir die erforderlichen Bibliotheken und erstellen die Hauptfunktion:
package main
import (
"fmt"
"github.com/henrylee2cn/pholcus/app"
"github.com/henrylee2cn/pholcus/logs"
)
func main() { }Legen wir nun die Parameter für die Aufgabe fest, beispielsweise die grundlegenden URLs, die gescrapt werden:
task := app.NewTask()
task.SetBaseUrls("https://demo.opencart.com/")Als Nächstes erstellen wir einen Collector und definieren Handler für die HTML-Elemente, die wir extrahieren möchten. In jedem Handler rufen wir die spezifischen Daten ab, die wir benötigen:
collector := app.NewCollector()
collector.OnHTML("div.col", func(element *app.HTMLElement) {
image := element.ChildAttr(".image a", "href")
productName := element.ChildText("h4 a")
productLink := element.ChildAttr("h4 a", "href")
description := element.ChildText("p")
oldPrice := element.ChildText(".price-old")
newPrice := element.ChildText(".price-new")
tax := element.ChildText(".price-tax")
fmt.Println("Image:", image)
fmt.Println("Product Name:", productName)
fmt.Println("Product Link:", productLink)
fmt.Println("Description:", description)
fmt.Println("Old Price:", oldPrice)
fmt.Println("New Price:", newPrice)
fmt.Println("Tax:", tax)
fmt.Println()
})Sobald die Aufgabe und der Collector eingerichtet sind, initiieren wir die Aufgabenausführung mithilfe der Funktion app.Run(task). Die Aufgabe löst Anfragen an die angegebenen URLs aus und verarbeitet die empfangenen Antworten gemäß den definierten Handlern.
task.Collector(collector)
if err := app.Run(task); err != nil {
logs.Log.Error(err)
}
Auf diese Weise haben wir die gleichen Daten erhalten, aber ein neues Tool verwendet. Leider kann es für Anfänger eine große Herausforderung sein, dieses Framework zu verwenden, da es weniger Beispiele, eine weniger detaillierte Dokumentation und eine viel kleinere Community als GoQuery oder Colly enthält.
Datenspeicherung und -verarbeitung
Um diese Beispiele zu vervollständigen, untersuchen wir, wie die abgerufenen Daten in einer CSV-Datei gespeichert werden. Wir verwenden das von uns geschriebene Skript als Beispiel für die Verwendung der Colly-Bibliothek als Ausgangspunkt. Da wir die abgerufenen Daten jedoch nicht auf dem Bildschirm anzeigen müssen, entfernen wir die Ausgabebefehle. Stattdessen fügen wir eine Variable hinzu, in die wir unsere Daten Zeile für Zeile schreiben, um sie später in eine Datei zu schreiben.
package main
import (
"encoding/csv"
"fmt"
"log"
"os"
"github.com/gocolly/colly/v2"
)
func main() {
url := "https://demo.opencart.com/"
c := colly.NewCollector()
var data ()()string
c.OnHTML("div.col", func(e *colly.HTMLElement) {
image := e.ChildAttr("div.image a", "href")
productName := e.ChildText("h4 a")
productLink := e.ChildAttr("h4 a", "href")
description := e.ChildText("p")
oldPrice := e.ChildText(".price-old")
newPrice := e.ChildText(".price-new")
tax := e.ChildText(".price-tax")
data = append(data, ()string{image, productName, productLink, description, oldPrice, newPrice, tax})
})
err := c.Visit(url)
if err != nil {
log.Fatal(err)
}
Erstellen Sie eine CSV-Datei und legen Sie das Trennzeichen auf „;“ fest. Wir geben außerdem Spaltennamen an und speichern die Daten aus der Variablen in der Datei.
file, err := os.Create("data.csv")
if err != nil {
log.Fatal(err)
}
defer file.Close()
writer := csv.NewWriter(file)
writer.Comma=";"
defer writer.Flush()
header := ()string{"Image", "Product Name", "Product Link", "Description", "Old Price", "New Price", "Tax"}
err = writer.Write(header)
if err != nil {
log.Fatal(err)
}
err = writer.WriteAll(data)
if err != nil {
log.Fatal(err)
}
Nachdem wir das Skript ausgeführt haben, erhalten wir eine CSV-Datei, die im selben Ordner wie das Skript gespeichert wird. Diese Datei enthält alle gesammelten Daten:

Normalerweise verarbeiten wir in dieser Phase zusätzlich zum Speichern auch die Daten, um leere Zellen, falsche Daten oder unnötige Symbole zu entfernen. Dies wird als Datenverarbeitung und -bereinigung bezeichnet. Typischerweise hängen davon die Qualität der Ausgabedaten sowie die Genauigkeit und der Erfolg der darauf basierenden Analyse ab.
Dies ist besonders wichtig für diejenigen, die mit großen Datenmengen arbeiten oder Analysen durchführen, um wichtige Entscheidungen zu treffen. Saubere und genaue Daten ermöglichen zuverlässigere Ergebnisse und fundiertere Entscheidungen.
Best Practices und Tipps
Das Befolgen spezifischer Regeln beim Web Scraping ist wichtig, um es einfacher und sicherer zu machen. Es ist auch vorzuziehen, die Ressourcen in den Zeiten mit der geringsten Auslastung zu nutzen, um eine Überlastung zu vermeiden, da sie möglicherweise nicht mit starkem Verkehr umgehen können und ausfallen könnten.
Go-Funktionen effektiv nutzen
Verwenden Sie aussagekräftige Namen, die den Zweck von Variablen, Funktionen und Typen genau beschreiben. Dies verbessert die Lesbarkeit des Codes und macht es für andere einfacher, Ihren Code zu verstehen.
Nutzen Sie außerdem Goroutinen und Kanäle, um Parallelität zu erreichen. Nutzen Sie sie, um effiziente und parallele Programme zu schreiben.
Organisieren Sie Ihren Code in wiederverwendbaren Paketen, um die Codemodularität zu verbessern und die Wiederverwendbarkeit zu erleichtern.
Nutzen Sie gut dokumentierte Bibliotheken
Im Allgemeinen gilt: Je besser die Dokumentation, desto größer ist die Benutzergemeinschaft für diese Bibliothek. So finden Sie immer Anwendungsbeispiele für die von Ihnen benötigten Funktionen und Unterstützung von echten Benutzern, wenn Sie auf Probleme stoßen, die Sie nicht alleine lösen können.
Befolgen Sie die Regeln für effizientes Schaben
Wenn Sie bestimmte Regeln nicht befolgen, können Probleme auftreten, z. B. dass Ihre IP von der Ressource blockiert wird oder Captchas gelöst werden müssen. Daher ist es wichtig, einige Regeln einzuhalten. Führen Sie beispielsweise kleine Intervalle zwischen Anfragen ein, verwenden Sie einen Benutzeragenten, vermeiden Sie das Scraping großer Datenmengen und erwägen Sie die Verwendung von Proxys.
Andererseits können all diese Probleme jedoch mithilfe einer Web-Scraping-API gelöst werden, beispielsweise der Google SERP-API zum Scraping von Google-Suchergebnissen, die die Herausforderungen der Umgehung von Blöcken beim Scraping bewältigt.
Fazit und Erkenntnisse
Golang ist eine leistungsstarke und einsteigerfreundliche Programmiersprache, die von Google entwickelt wurde. Seine Einfachheit, die integrierte Unterstützung für Parallelität und die umfangreiche Bibliothekssammlung machen es zu einer hervorragenden Wahl für Web-Scraping-Aufgaben.
Mit Hilfe beliebter Bibliotheken wie Goquery, Colly, Pholcus und Scrape-It.Cloud API und unseren Tutorials können Entwickler problemlos Daten von Websites extrahieren und verarbeiten. Egal, ob Sie Anfänger oder erfahrener Entwickler sind, Go bietet eine nahtlose und effiziente Umgebung für Web-Scraping-Projekte.
