
Was ist eine Scraping-API?
Scraping-APIs sind Web-Scraping-Dienstleister, die Web-Scraper dabei helfen, ein Verbot zu vermeiden, indem sie verschiedene von Websites eingeführte Anti-Scraping-Techniken umgehen. Sie nutzen IP-Rotation, CAPTCHA-Lösung und andere interne Techniken, um sicherzustellen, dass die von Ihnen angeforderte Seite für Sie heruntergeladen wird.
Die Verwendung einer Web-Scraping-API ist so einfach wie das Senden einer API-Anfrage, insbesondere mit ScraperAPI. Sie können große Datenmengen schnell und effizient verarbeiten und stellen sicher, dass Sie die benötigten Informationen ohne manuelle Eingriffe erhalten.
Ihre Flexibilität bedeutet auch, dass sie verschiedene Programmiersprachen unterstützen und problemlos in bestehende Arbeitsabläufe integriert werden können, sodass Sie problemlos Daten aus Websites extrahieren können, ohne Ihre bestehenden Prozesse zu stören.
7 Anwendungsfälle für Web Scraping in SEO
Die Beschaffung aktueller Suchmaschinendaten ist für SEO-Initiativen unerlässlich. Es bildet die Grundlage, um Rankings zu verstehen und die Markensichtbarkeit in Suchmaschinen pragmatisch und effektiv zu verbessern.
Sehen wir uns einige der wichtigsten Anwendungsfälle von SEO-Scraping an:
1. Automatisierung der Keyword-Recherche und -Überwachung
Die Keyword-Recherche ist das Rückgrat jeder SEO-Strategie, daher muss der Keyword-Auswahl und -Leistung große Aufmerksamkeit gewidmet werden. Mit SEO Scraping können Unternehmen den Prozess der Erfassung von Keyword-Rankings automatisieren und diese im Laufe der Zeit überwachen. Dies spart Zeit und bietet Echtzeit-Einblicke in die Keyword-Leistung verschiedener Kunden.
Über das einfache Keyword-Tracking hinaus kann Web Scraping fortgeschrittenere Techniken wie die TF-IDF-Analyse (Term Frequency-Inverse Document Frequency) ermöglichen, die misst, wie häufig ein Wort in einem Dokument im Verhältnis zu seiner Seltenheit in einem großen Datensatz vorkommt, und so dabei hilft, wichtige Begriffe darin zu identifizieren eine Sammlung von Inhalten.
Durch die Integration von TF-IDF-Modellen mit Scraped-Daten können Unternehmen ihre Keyword-Strategien über das hinaus, was Standardtools bieten, verfeinern und so eine effektivere Optimierung erreichen.
Wenn Sie nicht wissen, wo Sie anfangen sollen, finden Sie hier einige unserer Anleitungen zur Keyword-Recherche mithilfe von Web Scraping:
2. Sammeln von Anzeigendaten von Mitbewerbern
SEO Web Scraping ermöglicht das Sammeln wertvoller Daten über die Werbestrategien der Wettbewerber. Diese Informationen können Ihnen helfen, ihre SEO-Strategie zu verstehen und potenzielle Keywords für die Ausrichtung zu identifizieren. So können Unternehmen ihre Strategien verfeinern und neue Möglichkeiten identifizieren.
So können Sie erkennen, ob Ihre Konkurrenten Anzeigen für die Keywords kaufen, an denen Sie interessiert sind, oder ob sie organisch höher ranken – was bedeutet, dass sie im Laufe der Zeit mehr Traffic erhalten oder (mehr) qualitativ hochwertige Inhalte bereitstellen.
Durch das Sammeln der Anzeigendaten von Wettbewerbern können Unternehmen:
- Schätzen Sie die PPC-Investitionen der Wettbewerber basierend auf der Anzeigenhäufigkeit in den SERPs: Dies hilft, Budgets vorherzusagen, Wettbewerbsstrategien zu planen und vorgeschlagene Werbeausgaben gegenüber Kunden oder Stakeholdern zu rechtfertigen.
- Identifizieren und analysieren Sie die Zielseiten der Wettbewerber, indem Sie deren Anzeigenlinks folgen: Indem Sie Anzeigeninformationen extrahieren und jedem Anzeigenlink folgen, können Sie die Überschriften, Inhalte, Meta-Beschreibungen, Titel, Bilder und Videos der Zielseite analysieren. Dies bietet einen umfassenden Überblick über ihre PPC-Kampagnen und hilft Ihnen, Lücken in ihrem Marketing zu finden, Content-Ideen zu generieren und effektive Funnels für Ihre Kampagnen zu entwickeln.
- Finden Sie heraus, wer Ihre Hauptkonkurrenten für bestimmte Keywords sind: Ihre bekannten Konkurrenten sind nicht die einzigen, die in PPC investieren. Durch das Scraping von Anzeigendaten in großem Maßstab können Sie schnell andere Unternehmen identifizieren, die um dieselben Keywords konkurrieren. Dies ist besonders nützlich bei der Erschließung neuer geografischer Märkte.
Mithilfe von SEO-Daten können Startups fundierte Entscheidungen über Keyword-Targeting, Anzeigenbudgetierung und allgemeine PPC-Strategie treffen, was letztendlich zu effektiveren Kampagnen für ihre Kunden führt.
Um Ihnen den Einstieg zu erleichtern, lesen Sie unseren Leitfaden zum Auslesen der Anzeigen- und Inhaltsdaten von Mitbewerbern aus der Google-Suche.
3. Überwachen Sie SERP-Snippets
SERP-Funktionen sind einzigartige Elemente auf der Suchergebnisseite von Google, die über herkömmliche organische Einträge hinausgehen. Diese Funktionen können die Sichtbarkeit und Klickraten einer Website erheblich beeinflussen. Daher können Sie Ihre Inhalte für eine bessere Sichtbarkeit und Interaktion optimieren, indem Sie SERP-Snippets überwachen.
Zu den wichtigsten zu überwachenden SERP-Funktionen gehören:
- Ausgewählte Ausschnitte: Prägnante Antworten werden oben in den organischen Ergebnissen angezeigt (Position 0). Diese werden von relevanten Webseiten abgerufen und können erheblichen Traffic generieren.
- Die Leute fragen auch: Verwandte Fragen und Antworten werden unterhalb des Hauptsuchergebnisses angezeigt.
- Wissenspanels: Informationsboxen über Entitäten wie Personen, Orte und Dinge.
- Videokarussells: Rotierende Sammlungen von Videoergebnissen, die für die Suchanfrage relevant sind.
- Lokales Paket: Karte und Einträge für lokale Unternehmen, die für die Suchanfrage relevant sind.
- Bildpakete: Raster mit Miniaturansichten, die visuell relevante Bilder präsentieren.
- Rich Snippets: Erweiterte Informationen wie Rezensionen, Bewertungen und Rezeptzutaten direkt in den Suchergebnissen.
Mithilfe von Scraping-APIs können Sie diese Daten extrahieren und den Erfolg der Wettbewerber bei der Erfassung dieser Daten überwachen. Durch die Verfolgung dieser Snippets können Unternehmen Möglichkeiten erkennen, die Inhalte ihrer Kunden für eine bessere Sichtbarkeit und Klickraten zu optimieren.
Profi-Tipp:
Der Google Search-Endpunkt von ScraperAPI gibt alle diese Elemente im JSON- oder CSV-Format zurück, sodass Sie SERP-Snippets (oder Rich-Suchergebnisse) überwachen können, indem Sie eine Liste von Schlüsselwörtern über die API übermitteln. Weitere Informationen finden Sie in der Dokumentation zum strukturierten Endpunkt der Google-Suche.
4. Aggregieren Sie lokalisierte SERP-Daten
Web Scraper mit Geotargeting-Funktionen ermöglichen die Erfassung und Analyse lokalisierter SERP-Daten. Durch die Anpassung von Ländercodes oder Geolokalisierungsparametern können Unternehmen beobachten, wie sich Rankings und Suchergebnisse in verschiedenen Regionen unterscheiden. Dies ermöglicht ihnen auch:
- Sammeln Sie SERP-Daten aus mehreren Ländern und Regionen
- Vergleichen Sie Suchergebnisse an verschiedenen Standorten
- Identifizieren Sie lokale Rankingfaktoren und Trends
- Optimieren Sie Inhalte für bestimmte geografische Ziele
ScraperAPI bietet vorkonfigurierte Endpunkte für bestimmte beliebte Websites, einschließlich der Google-Suche. Diese Google Scraper wurden von Grund auf für SEO- und Entwicklungsteams entwickelt, die SERP-Daten von allen wichtigen Google-Domains aggregieren möchten. Sie bieten ununterbrochene Datenströme, die sich perfekt für die Keyword-Überwachung nahezu in Echtzeit eignen.
Mit den strukturierten Datenendpunkten von ScraperAPI können Sie:
- Sammeln Sie strukturierte Daten in einem JSON-Format
- Passen Sie Ihre Datensätze mit umfangreichen Parametern an
- Arbeiten Sie mit sauberen Daten für einen schnelleren Arbeitsablauf
Lassen Sie uns kurz die Verwendung von Google SDE von ScraperAPI zum Sammeln lokalisierter SERP-Daten vorführen. Wir vergleichen Suchergebnisse für die Suchanfrage „Sofa” in den Vereinigten Staaten und im Vereinigten Königreich.
Wenn Sie bereits mit ScraperAPI vertraut sind, kopieren Sie diesen Code und führen Sie ihn aus. Andernfalls erstellen Sie ein kostenloses ScraperAPI-Konto, um auf Ihren API-Schlüssel zuzugreifen, und verwenden Sie den folgenden Codeausschnitt.
Rufen wir zunächst die Ergebnisse für die USA ab:
import requests
import json
APIKEY = "YOUR_API_KEY"
QUERY = "Sofa"
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'us'}
r = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
data = r.json()
with open('us_google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in us_google_results.json")
Ausgabe:
{
"position": 9,
"title": "Lifestyle Solutions Watford Sofa",
"thumbnail": "data:image/webp;base64,UklGRrIsAABXRUJQVlA4IKYsAACQow...",
"price": "$305.11",
"seller": "Home Depot",
"stars": 3.1,
"rating_num": 401
},
{
"position": 10,
"title": "Article Timber Olio Sofa",
"thumbnail": "data:image/webp;base64,UklGRtY1AABXRUJQVlA4IMo1AABwpI...",
"price": "$1,299.00",
"seller": "Article",
"stars": 4.3,
"rating_num": 280
},...
Jetzt ändern Sie einfach die country_code Parameter von 'us' Zu 'uk' So rufen Sie britische Ergebnisse ab:
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'uk'}
r = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
data = r.json()
with open('uk_google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in uk_google_results.json")
Ausgabe:
Notiz: Aus Platzgründen zeigen wir nur einen Teil der Antwort.
Durch den Vergleich der us_google_results.json Und uk_google_results.json Dateien werden Sie Unterschiede in den Suchergebnissen bemerken, wie zum Beispiel:
- Verschiedene Top-Ranking-Websites
- Währungsunterschiede in den Einkaufsergebnissen (USD vs. GBP)
- Regionsspezifische Produktnamen oder Beschreibungen
- Lokalisierter Anzeigeninhalt
Diese Unterschiede unterstreichen die Bedeutung von Geo-Targeting in SEO-Strategien. Startups können wertvolle Erkenntnisse darüber gewinnen, wie Suchergebnisse in verschiedenen Regionen variieren, was ihnen ermöglicht, ihre Strategien auf bestimmte geografische Märkte abzustimmen und die globale SEO-Leistung ihrer Kunden zu verbessern.
5. Benutzerdefinierte Dashboards füttern
Web Scraper können zum Sammeln großer Datenmengen verwendet werden, die in benutzerdefinierte Dashboards eingespeist werden und so eine interaktive Plattform für Analysen bieten. Durch die Integration von Echtzeitdaten in diese Dashboards können Unternehmen komplexe Informationen auf zugängliche und optisch ansprechende Weise präsentieren.
Kurz gesagt sind dies die Vorteile der Versorgung benutzerdefinierter Dashboards mit Scraping-Daten:
- Echtzeit-Ranking-Updates: SEO-Unternehmen können schwankende Keyword-Rankings verfolgen und so sofortige Strategieanpassungen ermöglichen. Echtzeitdaten stellen sicher, dass Sie und Ihre Kunden stets über die aktuelle Position in den Suchergebnissen informiert sind.
- Wettbewerbsanalysediagramme: Dashboards machen es einfacher zu visualisieren, wie Ihre Kunden im Vergleich zu Mitbewerbern in Bezug auf verschiedene SEO-Kennzahlen abschneiden. Diagramme und Grafiken können Bereiche hervorheben, in denen Ihre Kunden herausragende Leistungen erbringen oder Verbesserungen benötigen.
- Keyword-Performance-Trends: Sie können die Leistung bestimmter Keywords im Zeitverlauf überwachen. Trendlinien und historische Daten helfen dabei, zu erkennen, welche Keywords den Traffic steigern und welche möglicherweise optimiert werden müssen.
6. Erstellen Sie benutzerdefinierte Tools
Ihre Website sollte darauf abzielen, unter den ersten fünf Ergebnissen zu landen. SEO-Tools spielen in diesem Prozess eine wichtige Rolle, indem sie dabei helfen, Ihre Webinhalte so zu optimieren, dass sie den Anforderungen von Suchmaschinen entsprechen, Aufgaben automatisieren und die Effizienz steigern.
Es gibt drei gängige Kategorien von SEO-Tools:
- Keyword-Tools: Keyword-Tools wie Generatoren, Analysatoren und Monitore helfen Ihnen, neue Keyword-Ideen zu entdecken, ihre Wettbewerbsfähigkeit zu analysieren und ihre Leistung im Laufe der Zeit zu verfolgen.
- Backlink-Tools: Mit Backlink-Tools können Sie nach Möglichkeiten suchen, indem Sie die Backlink-Profile erstklassiger Websites untersuchen. Sie helfen Ihnen auch dabei, Ihre bestehenden Backlinks zu überwachen, um sicherzustellen, dass sie wertvoll bleiben und das Ranking Ihrer Website nicht beeinträchtigen.
- Domain-Audit-Tools: Auch als Site-Audit-Tools bekannt, stellen diese sicher, dass Ihre Website technisch einwandfrei ist. Sie helfen dabei, Elemente wie Website-Geschwindigkeit, Ladezeit, Reaktionsfähigkeit, Sicherheitszertifikate (SSL) und mehr zu optimieren.
Eine einfache, aber effiziente Möglichkeit, benutzerdefinierte SEO-Tools zu erstellen, ist die Verwendung von APIs bestehender Dienste wie ScraperAPI. Indem Sie die API an Ihre spezifischen Anforderungen anpassen, können Sie Tools entwickeln, ohne bei Null anfangen zu müssen. Der Aufbau eines benutzerdefinierten SEO-Tools über eine API erfordert zwar immer noch technisches Wissen, ist aber weniger komplex als der Aufbau eines komplett eigenen Tools.
7. Automatisierung der Google Trends-Recherche
Google Trends ist ein Tool, das Trends darstellt. Es zeigt nicht das Suchvolumen für Schlüsselwörter an, sondern zeigt diese Trends in einem Diagramm an, das auf der Grundlage des höchsten Interessenspitzenwerts über den von Ihnen angegebenen Zeitraum skaliert ist.
Warum also den Prozess durch die Erstellung eines Skripts verkomplizieren? Wie bei den meisten Dingen beim Web Scraping kommt es auf Zeit und Skalierbarkeit an. Sie können jedes Schlüsselwort einzeln eingeben und verschiedene Zeitrahmen verfolgen. Das ist in Ordnung, bis Sie eine Liste mit Hunderten von Schlüsselwörtern haben.
Die manuelle Überprüfung jedes Einzelnen führt zu einer großen Zeitverschwendung. Stattdessen können Sie mithilfe einer Scraping-API die Berichte für eine Liste von Schlüsselwörtern in wenigen Sekunden oder Minuten ganz einfach automatisieren.
Durch den Einsatz einer Scraping-API zur Automatisierung der Google Trends-Datenerfassung können Unternehmen:
- Verfolgen Sie Trendthemen in den Branchen Ihrer Kunden
- Identifizieren Sie saisonale Trends für die Inhaltsplanung
- Vergleichen Sie das Suchinteresse über mehrere Schlüsselwörter hinweg
- Entdecken Sie verwandte Fragen und Themen
Mehr lesen: So kratzen Sie Google Trends
Verwendung von ScraperAPI zum Scrapen der Google-Suche im großen Maßstab
ScraperAPI ist eine Proxy-Verwaltungs-API und Web-Scraping-Lösung, die alles von der Rotation und Verwaltung von Proxys bis hin zur Handhabung von CAPTCHAs und Browsern, Wiederholungsversuchen und Datenbereinigung übernimmt, damit unsere Anfragen nicht gesperrt werden. Das ist großartig für eine schwierig zu durchsuchende Website wie Google.
Was ScraperAPI jedoch für Websites wie Google besonders nützlich macht, ist, dass es die automatische Parsing-Funktionalität kostenlos bereitstellt, sodass Sie keine eigenen Parser schreiben und pflegen müssen.
Sehen wir uns nun an, wie wir ScraperAPI verwenden können, um Daten von 10 verschiedenen Schlüsselwörtern mithilfe des strukturierten Datenendpunkts (SDE) von ScraperAPI für die Google-Suche zu sammeln.
Voraussetzungen
Schritt 1: Einrichten des Skripts und Definieren von Schlüsselwörtern
Wir beginnen mit dem Importieren der erforderlichen Bibliotheken, dem Einrichten unseres API-Schlüssels und dem Definieren der Liste der Schlüsselwörter, nach denen wir suchen möchten.
import requests
import json
# Replace with your ScraperAPI key
api_key = 'Your_ScraperAPI_KEY'
# List of keywords to search
keywords = ('SEO tools', 'content marketing', 'link building', 'local SEO',
'technical SEO', 'keyword research', 'on-page SEO',
'off-page SEO', 'mobile SEO', 'voice search optimization')
base_url = 'https://api.scraperapi.com/structured/google/search'
Hier importieren wir die erforderlichen Anfragen und JSON-Bibliotheken, richten unseren ScraperAPI-Schlüssel ein (den Sie durch Ihren tatsächlichen Schlüssel ersetzen sollten) und definieren eine Liste SEO-bezogener Schlüsselwörter. Der base_url Die Variable enthält den Endpunkt für die Datenextraktionsfunktion der Google-Suche von ScraperAPI.
Schritt 2: Daten für jedes Schlüsselwort abrufen
Jetzt durchlaufen wir unsere Liste mit Schlüsselwörtern, senden für jedes einzelne eine Anfrage an ScraperAPI und speichern die Ergebnisse.
results = ()
for keyword in keywords:
params = {
'api_key': api_key,
'query': keyword,
'country': 'us'
}
response = requests.get(base_url, params=params)
if response.status_code == 200:
print(f"fetching data for '{keyword}'")
data = response.json()
results.append({
'keyword': keyword,
'organic_results': data.get('organic_results', ())
})
else:
print(f"Error fetching data for '{keyword}': {response.status_code}
Dieser Code durchläuft jedes Schlüsselwort in unserer Liste und sendet eine GET-Anfrage an den ScraperAPI-Endpunkt.
Wenn die Anfrage erfolgreich ist (status code 200), gibt es eine Meldung aus, die angibt, dass Daten für das Schlüsselwort abgerufen werden. Dann extrahiert es die 'organic_results' aus der JSON-Antwort und fügt sie zusammen mit dem Schlüsselwort unserer Ergebnisliste hinzu. Wenn ein Fehler vorliegt, wird eine Fehlermeldung mit dem Statuscode gedruckt.
Schritt 3: Speichern der Ergebnisse in einer JSON-Datei
Abschließend speichern wir alle gesammelten Daten zur einfachen Analyse und Verwendung in anderen Anwendungen in einer JSON-Datei.
Dieser Code öffnet eine neue Datei mit dem Namen 'seo_search_results.json' im Schreibmodus und schreibt unsere Ergebnisliste im JSON-Format, mit einem Einzug von 2 Leerzeichen zur besseren Lesbarkeit. Abschließend wird eine Meldung gedruckt, die bestätigt, dass die Ergebnisse in der Datei gespeichert wurden.
Vollständiges Skript
Hier ist das gesamte Skript zum einfachen Kopieren und Einfügen zusammengefasst:
import requests
import json
# Replace with your ScraperAPI key
api_key = 'Your_ScraperAPI_KEY'
# List of keywords to search
keywords = ('SEO tools', 'content marketing', 'link building', 'local SEO',
'technical SEO', 'keyword research', 'on-page SEO',
'off-page SEO', 'mobile SEO', 'voice search optimization')
base_url = 'https://api.scraperapi.com/structured/google/search'
# Initialize a list to store results
results = ()
for keyword in keywords:
params = {
'api_key': api_key,
'query': keyword,
'country': 'us'
}
response = requests.get(base_url, params=params)
if response.status_code == 200:
print(f"Fetching data for '{keyword}'")
data = response.json()
results.append({
'keyword': keyword,
'organic_results': data.get('organic_results', ())
})
else:
print(f"Error fetching data for '{keyword}': {response.status_code}")
# Save results to a JSON file
with open('seo_search_results.json', 'w') as f:
json.dump(results, f, indent=2)
print("Search results saved to 'seo_search_results.json'")
Verwenden der visuellen Schnittstelle von DataPipeline (Low-Code)
Für diejenigen, die eine Low-Code-Lösung bevorzugen, bietet DataPipeline von ScraperAPI eine visuelle Schnittstelle zum Einrichten von Scraping-Aufgaben, ohne Code schreiben zu müssen.
DataPipeline ist der integrierte Scraping-Planer von ScraperAPI. Es ermöglicht Ihnen, den gesamten Schabeprozess von Anfang bis Ende zu automatisieren. Die Integration dieses Tools mit den Google SDEs von ScraperAPI ist sogar noch besser. Mit diesen Tools können Unternehmen wiederkehrende Google-Keyword-Scraping-Jobs einrichten, um Suchergebnisse zu überwachen, Tools zu erstellen und Dashboards mit SERP-Daten von Erstanbietern zu füttern, ohne Hunderte von Stunden mit dem Aufbau oder der Wartung komplexer Infrastrukturen und Parser verbringen zu müssen.
Auf die extrahierten Daten kann in verschiedenen Formaten zugegriffen werden, darunter JSON, CSV oder Webhooks, was die Integration in Ihre bestehenden Projekte und Arbeitsabläufe erleichtert.
Lasst uns verwenden Datenpipeline um dieselbe Aufgabe mit mehr Effizienz und weniger Code auszuführen:
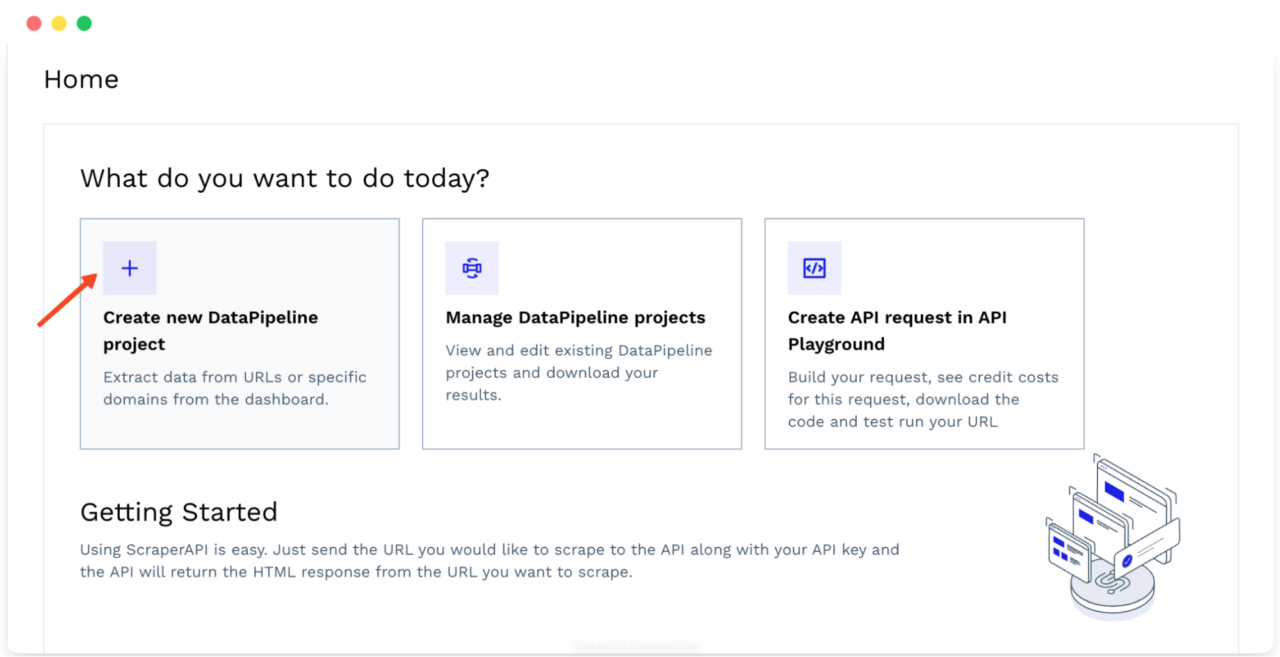
- Melden Sie sich bei Ihrem ScraperAPI-Konto an und klicken Sie auf „Erstellen Sie ein neues DataPipeline-Projekt„. Dies ist Ihr zentraler Knotenpunkt für die Verwaltung all Ihrer Scraping-Aufgaben.
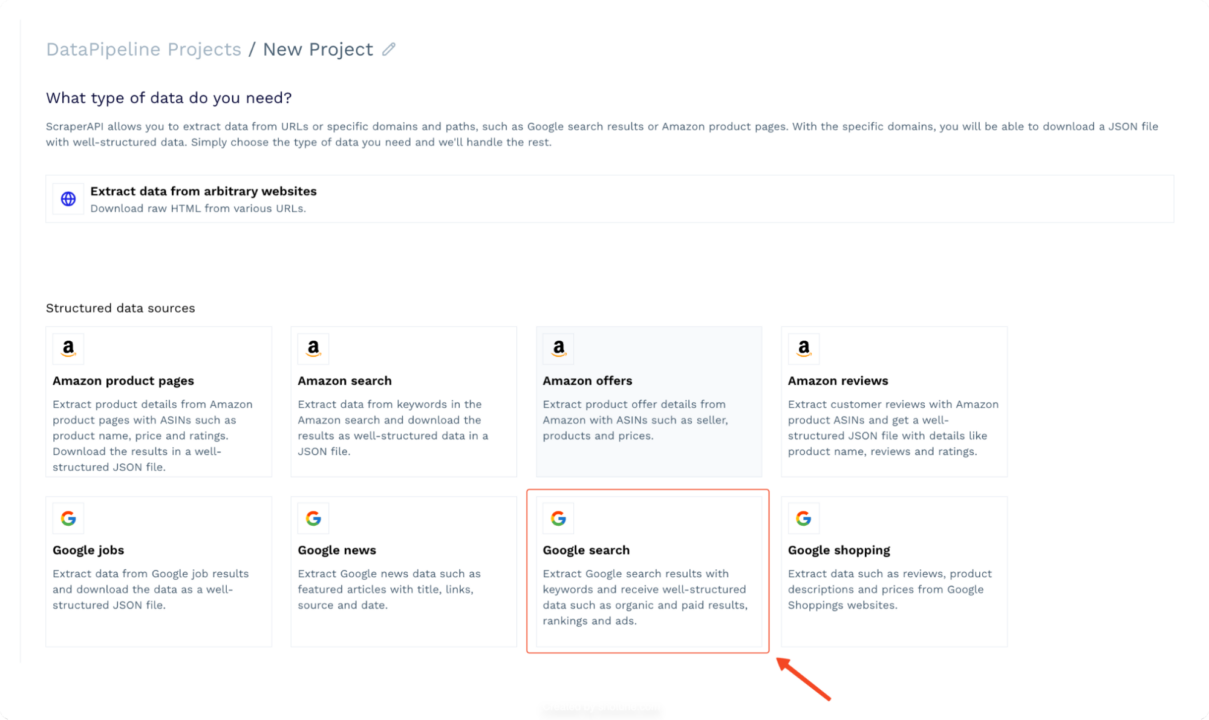
- Wählen Sie „Google-Suche” Extraktor aus der Liste der verfügbaren Extraktoren. Dieser Extraktor wurde speziell zum Scrapen von Google-Suchergebnissen mit Schlüsselwörtern entwickelt.
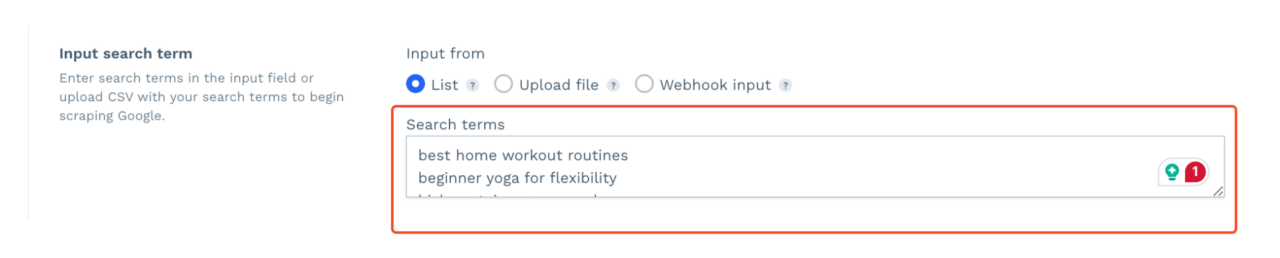
- Geben Sie Ihre Liste der Schlüsselwörter ein, die Sie durchsuchen möchten. Sie können eine CSV-Datei hochladen, eine dynamische Liste über Webhook hinzufügen oder diese manuell eingeben.
- Wählen Sie Ihren Zielort für das Geotargeting, wählen Sie die Domain aus und legen Sie weitere Einstellungen fest.
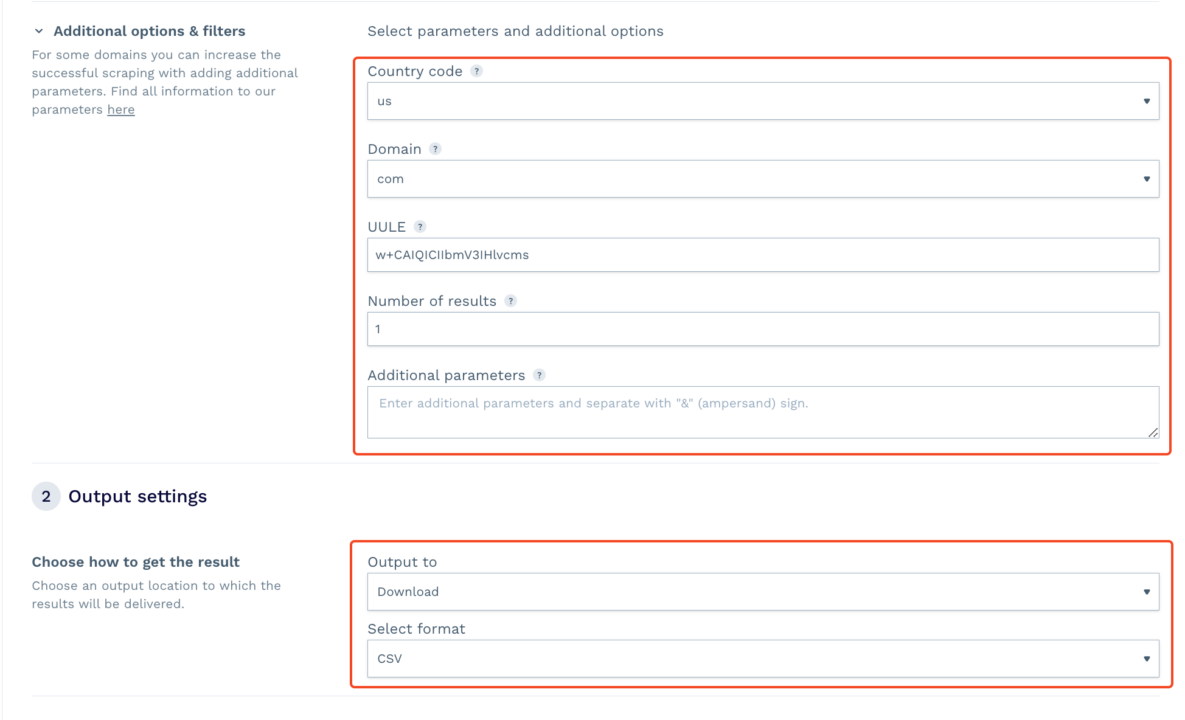
- Starten Sie die Scraping-Aufgabe. Den Rest erledigt DataPipeline. Sobald Sie fertig sind, können Sie die resultierende CSV- oder JSON-Datei herunterladen, die die gecrackten Daten enthält. Wenn Sie einen Webhook hinzufügen, erhalten Sie die Daten direkt in dem von Ihnen angegebenen Ordner oder der angegebenen App.
Profi-Tipp:
Für technisch versiertere Benutzer, die die Planungsfunktionen von DataPipeline nutzen möchten, können Sie über dedizierte Endpunkte auf dieselben Funktionen zugreifen.
Damit können Sie Hunderte von Projekten direkt aus Ihrer Codebasis erstellen und verwalten und so Ihren Arbeitsabläufen eine zusätzliche Automatisierungsebene hinzufügen.
Zusammenfassung
Scraping-APIs sind zu unverzichtbaren Werkzeugen sowohl für globale als auch lokale Unternehmen geworden, die sich auf dem überfüllten Markt von heute einen Wettbewerbsvorteil verschaffen möchten. Durch die Integration dieser Tools in Ihre Arbeitsabläufe können Sie Zeit sparen, den manuellen Aufwand reduzieren und sich darauf konzentrieren, außergewöhnliche Ergebnisse für Ihre Kunden zu liefern.
Benötigen Sie umfangreiche SERP-Daten? Kontaktieren Sie unser Vertriebsteam, um mit einem individuellen Plan zu beginnen, der alle Premium-Funktionen, dedizierte Support-Slack-Kanäle und einen dedizierten Account Manager umfasst.
