
Daten sind im 21. Jahrhundert mittlerweile zu einer Art Währung geworden. Aber wenn Sie an Daten denken, fällt Ihnen dann Web Scraping ein? Wir sind hier, um Ihnen zu sagen, dass es so sein sollte.
Die besten Ideen sind die einfachsten, ähnlich wie beim Web Scraping. Nehmen Sie zum Beispiel einen Lautsprecher.
Äußerlich betrachtet ist ein Lautsprecher ein mysteriöses Objekt, das Musik mit einer Präzision wiedergibt, die selbst echte Konzerte nicht nachahmen können. Technisch gesehen ist es nichts anderes als eine Schwingspule, die um sich herum Magnetfelder erzeugt.
Wenn ein elektrisches Signal die Spule durchläuft, interagiert das von ihr erzeugte Magnetfeld mit dem Permanentmagneten.
Infolgedessen bewegen sich der angeschlossene Kegel und die Schwingspule hin und her, vermischen sich mit der Luft und verursachen Kompressionen und Verdünnungen in den Luftmolekülen.
Diese Druckänderung strahlt als Schallwellen aus.
Was einem Menschen im 17. Jahrhundert wie Zauberei vorkam, ist in Wirklichkeit ein netter Trick.
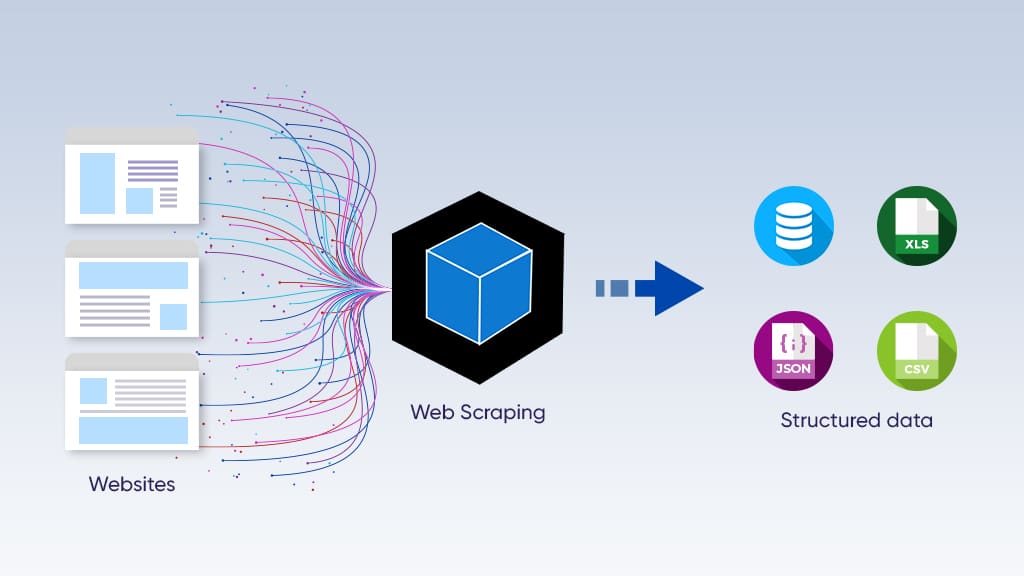
Ebenso ist Web Scraping der Grundpfeiler des einflussreichsten Technologieriesen der Gegenwart – Google. Es sammelt Daten aus der ganzen Welt und präsentiert sie den Menschen, die nach bestimmten Informationen suchen. Ordentlich, nicht wahr? Vielleicht vereinfachen wir hier zu sehr. Oder sind wir es?
Einige der größten Marken der Welt nutzen Webdaten, um Produkte und Dienstleistungen zu entwickeln, die ihnen nicht nur Millionen (wenn nicht Milliarden) Dollar einbringen, sondern auch eine Wirkung erzielen, die nur wenige erreichen.
Ob es darum geht, wirtschaftliche Rezessionen vorherzusagen oder die nächste große kulturelle Sensation zu schaffen, Webdaten sind praktisch. Je mehr Daten Sie haben, desto besser sind Ihre Erfolgschancen.
Jetzt haben Sie zwei Möglichkeiten: Kopieren Sie jeden Datenpunkt und fügen Sie ihn in eine Tabelle ein und geben Sie die Aufgabe als generationsübergreifendes Unterfangen an Ihre Enkelkinder weiter.
Oder Sie können die Datenextraktion mit Web Scraping automatisieren. Holen Sie sich die Daten schnell. Erhalten Sie schneller Erkenntnisse und treffen Sie fundierte Entscheidungen, bevor Ihre Konkurrenten etwas davon mitbekommen. Wir empfehlen Ihnen, mit Bedacht zu wählen.

Unter Web Scraping versteht man den Prozess der automatisierten Datenextraktion aus einer Website. Anschließend umfasst die Datenextraktion die Organisation der Informationen in einem strukturierten, lesbaren Datensatz.
Wenn Sie eine Webseite besuchen, senden Sie eine HTTP-Anfrage an den Server. Im Grunde bitten Sie um Einlass.
Bei der automatisierten Datenextraktion wird ein Computerprogramm namens Crawler mit dem Senden der Anfrage beauftragt. Es ist dafür verantwortlich, das Web zu erkunden, indem es Links folgt und bestimmte Webseiten entdeckt. Wenn der Webserver Zugriff gewährt, speichert der Crawler mehrere Links aus der Antwort. Es fügt diese Links zu einer Liste hinzu, die es als nächsten Besuch anerkennt.
Der Crawler durchläuft diesen Prozess iterativ, bis ein vordefinierter Satz von Kriterien erfüllt ist.
Der Scraper ist jedoch dafür verantwortlich, bestimmte Daten aus den vom Crawler besuchten Links zu extrahieren. Es analysiert den HTML-Code und scrapt die Daten in ein gewünschtes Format, sei es CSV, JSON oder eine einfache Excel-Tabelle.
Bedenken Sie, dass das Schreiben des Crawlers der einfachste Teil der Datenextraktion ist.
Raupenwartung? Nicht sehr viel.
Die meisten Websites ändern ihre Struktur häufig. Da die Datenanforderungen steigen, gewinnt die Crawler-Wartung einen besonderen Platz im Datenprojekt. Es nimmt den Großteil der mit der gesamten Datenextraktion verbundenen Kosten in Anspruch.
Ebenso muss sich die Disposition der Scraper entsprechend der Art der Quellwebsite ändern. Beispielsweise müssen Sie möglicherweise einen anderen Scraper für das Scraping von Google und Amazon schreiben. Wir tun dies, um die semantischen Unterschiede auf den Websites zu berücksichtigen.
Man kann sich den Crawler wie einen Militärgeneral vorstellen, der seine Soldaten (den Scraper) in die Schlacht zieht. Der Crawler erstellt Strategien und identifiziert Ziele, während die Soldaten die Strategie ausführen. Beim Web Scraping extrahiert der Scraper die Daten unter Anleitung des Crawlers.
Lesen Sie hier fünf Gründe, warum Sie einen externen Datenanbieter benötigen.
Web Scraper: bauen oder kaufen
Die DIY-Web-Scraping-Lösung
Websites sind virtuelle Shops im World Wide Web. Wix bietet Website-Entwicklungsdienste an, während Amazon Produkte verkauft.
Aufgrund ihrer unterschiedlichen Ziele werden Informationen so gespeichert, dass sie am besten zum Zweck der Website passen. Wenn Ihr Datenbedarf minimal ist, können Sie ganz einfach selbst einen Web-Scraper programmieren und die Daten durch einen vorhersehbaren Web-Scraping-Prozess sammeln.
Sie können Python-Bibliotheken wie BeautifulSoup und Scrapy zum Web-Scraping verwenden. Pandas und Polars gehören zu einer ähnlichen Art und sind äußerst hilfreich bei der Verarbeitung von Daten, die von Websites stammen.
Wenn Sie kleine Web-Scraper erstellen möchten, sollten Sie die folgenden Anleitungen zur Datenextraktion mit Python und PHP durchgehen.
Ein Wort der Vorsicht: Sie können die Leistung Ihrer Quellwebsites beeinträchtigen, wenn Sie beginnen, Daten in großem Umfang zu sammeln. Das Senden zu vieler Anfragen an den Server kann sich negativ auf dessen Leistung auswirken. Schließlich haben die meisten Websites einen bestimmten Zweck: Sie dienen ihren Lesern und Kunden sowie von Zeit zu Zeit gelegentlichen Browsern.
Darüber hinaus laufen Sie Gefahr, den Großteil der Leistung Ihrer eigenen Computersysteme zu verbrauchen, vor allem Speicher und RAM. Bis zum Abschluss Ihres Datenextraktionsprojekts können Sie andere Anwendungen in Ihrem Programm nicht ordnungsgemäß nutzen.
Nicht alle Menschen bevorzugen den Build-Weg. Wenn Sie keinerlei Erfahrung im Programmieren haben, haben Sie Glück. Schauen Sie sich hier unser kostenloses Web-Scraping-Tool an. Es handelt sich um eine Browsererweiterung, die Sie einfach installieren können. Darüber hinaus bietet das Web-Scraping-Tool eine intuitive Point-and-Click-Oberfläche zur einfachen Datenextraktion.
Nehmen wir an, Sie müssen Tausende von Produktpreisen auf Amazon überwachen. Da sich die Preise recht häufig ändern, ist es notwendig, mit den Preisschwankungen Schritt zu halten.
Fügen Sie weitere E-Commerce-Websites wie eBay, Target und Walmart hinzu, und Sie haben eine Menge Web-Scraping-Chaos vor sich.
Hinzu kommt, dass Websites häufig ihre Strukturen ändern und verschiedene Anti-Bot-Maßnahmen anwenden. Neben der Aktivierung der robots.txt-Datei, die den Web Scraper darüber informiert, auf welche Inhalte er zugreifen kann und auf welche nicht, setzen sie auch fortschrittliche Anti-Bot-Maßnahmen wie IP-Blockierung, Captcha und Honeypot-Traps ein.
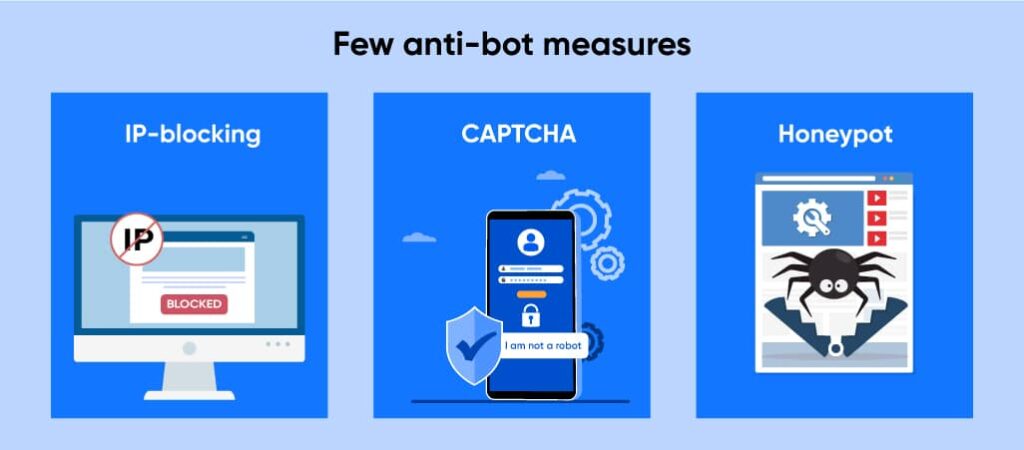
- IP-Blockierung: Der Webhoster überwacht die Besucher, die auf seine Website zugreifen. Sie blockieren IP-Adressen, die zu viele Anfragen stellen.
- Captcha: Websites wenden den vollständig automatisierten öffentlichen Turing-Test zur Unterscheidung von Computern und Menschen an, um Bots den Zugriff auf ihre Inhalte zu blockieren.
- Honeypots: Normalerweise fügen Websites unmerkliche Links auf ihren Webseiten hinzu. Etwas, das ein Mensch unterscheiden könnte.
Und das alles, ohne die Rechtmäßigkeit des Web Scrapings in Frage zu stellen. Als Faustregel gilt: Sie sollten niemals Daten extrahieren, die nicht öffentlich verfügbar sind. Lesen Sie hier mehr über die Rechtmäßigkeit von Web Scraping.
Nachdem wir nun die mit der groß angelegten Datenextraktion verbundenen Probleme geklärt haben, können wir endlich etwas über die Lösung erfahren.
Grepsr ist einer der wenigen und zuverlässigsten Anbieter verwalteter Datenextraktionsdienste für globale Datenanforderungen. Wir bieten eine maßgeschneiderte Lösung ohne Code für die Web-Datenextraktion.
Es handelt sich um einen Concierge-Service, der Benutzer vor den Feinheiten des Web-Scraping-Prozesses schützen soll. Wir setzen auf Qualität und jahrzehntelange Erfahrung.
Die Datenextraktions- und Datenverwaltungsplattform von Grepsr wurde für die Web-Scraping-Anforderungen von Unternehmen entwickelt.
Unsere groß angelegte Datenmanagementplattform zeichnet sich vor allem durch folgende Merkmale aus:
- Web-Scraping-Automatisierung: Implementieren Sie zeitnahe Updates für Web Scraper und verarbeiten Sie jede Stunde Millionen von Seiten.
- Mehrere Lieferoptionen: Liefern Sie Daten in dem für Sie am besten geeigneten Format – Drobox, FTP, Webhooks, Slack, Amazon S3, Google Cloud usw.
- Datenqualität im Maßstab: Stellen Sie qualitativ hochwertige Daten in großem Maßstab bereit, indem Sie sich auf eine Mischung aus Menschen, Prozessen und Technologie verlassen.
- Einfache Automatisierung und Integration: Richten Sie benutzerdefinierte Zeitpläne für die Datenextraktion ein und automatisieren Sie Routine-Scrapings, damit diese wie am Schnürchen ablaufen.
- Verantwortungsvolles Web-Scraping: IP-Rotation rund um die Uhr und automatische Drosselung, um eine Erkennung zu vermeiden und Schäden an den Webquellen zu verhindern.
Letzte Worte
Wenn Sie neu im Web-Scraping sind, vertrauen wir darauf, dass Sie jetzt über alles verfügen, was Sie für den Einstieg benötigen.
Wenn Sie ein erfahrener Fachmann sind, können Sie uns gerne für eine unverbindliche Datenberatung kontaktieren. Vielleicht entdecken wir Aspekte, an die Sie bisher noch nicht gedacht haben.
Was die Anwendungen der Datenextraktion betrifft, haben wir in diesem Artikel noch nicht einmal an der Oberfläche gekratzt. Dennoch können Sie in unserem Branchenbereich erfahren, wie Web Scraping für Ihre Branchennische von Vorteil sein kann.
Vom E-Commerce bis zum Journalismus ist Web Scraping eine effiziente und effektive Möglichkeit, Zugriff auf verwertbare Daten zu erhalten. Aus intuitiver Sicht ist Web Scraping vielleicht nicht das Erste, was Ihnen in den Sinn kommt.
Aber andererseits sind es die einfachen Ideen, die einen oft überraschen.
