
Web Scraping und Crawling sind zwei verschiedene Möglichkeiten, Daten von Websites zu sammeln. Beim Scraping werden bestimmte Daten von einer Website extrahiert, beim Crawlen werden alle Seiten besucht. Webcrawling wird für verschiedene Zwecke eingesetzt, beispielsweise zum Indexieren einer Website durch Suchmaschinen oder zum Erstellen einer Sitemap für ihre Eigentümer. Sie können unseren umfassenden Vergleich lesen, um ihre Unterschiede besser zu verstehen.
Die Vielseitigkeit der Python-Sprache und ihre Community-Unterstützung machen sie zu einer beliebten Wahl für Webanwendungsentwicklungsprojekte, unabhängig davon, ob Sie Anfänger oder erfahrener Entwickler sind. Es vereinfacht den Prozess der Erstellung von Web Scrapern und Crawlern sowie die Arbeit mit den gesammelten Daten und macht es zu einer idealen Sprache für alle, die Daten aus dem Internet abrufen und analysieren möchten.
Python-Webcrawler verstehen
Wie bereits erwähnt, handelt es sich beim Webcrawlen um das Sammeln von Webdaten von allen Seiten einer Website. Beim Crawlen der Seiten werden alle Links auf jeder Webseite erfasst. Anschließend werden die bereits gesammelten Links gecrawlt.
Arten von Webcrawlern
Obwohl alle Webcrawler ähnliche Ziele verfolgen, können sie in verschiedene Typen unterteilt werden:
- Allzweck-Crawler.
- Fokussierte Crawler.
- Inkrementelle Crawler.
- Deep-Web-Crawler.
General Purpose Crawler sind die häufigste Art von Webcrawlern und werden von Suchmaschinen wie Google, Bing und Yahoo verwendet. Ihr Hauptzweck besteht darin, Webseiten im gesamten Internet zu indizieren und sie durchsuchbar zu machen. Gleichzeitig sind fokussierte Crawler darauf ausgelegt, eine bestimmte Teilmenge von Websites oder Webseiten zu indizieren.
Inkrementelle Crawler sind dafür verantwortlich, die indizierten Daten regelmäßig zu aktualisieren, indem sie Websites erneut crawlen, um neue oder aktualisierte Inhalte zu finden und zu indizieren. Suchmaschinen verwenden inkrementelle Crawler, um ihre Suchergebnisse aktuell zu halten.
Der letzte Typ sind Deep-Web-Crawler. Sie dienen dazu, auf Inhalte zuzugreifen und diese zu indizieren, die normalerweise nicht über herkömmliche Suchmaschinen zugänglich sind. Sie können Datenbanken, passwortgeschützte Websites und andere dynamisch generierte Inhalte crawlen.
Wie Python Web Crawler funktioniert
Webcrawler verwenden hauptsächlich zwei Crawling-Methoden: Tiefen-zuerst und Breiten-zuerst. Diese Methoden unterscheiden sich in der Art und Weise, wie sie Links folgen. Wir werden diese Methoden später ausführlicher besprechen. Konzentrieren wir uns zunächst auf die allgemeinen Prinzipien des Web-Crawlings.

Um zu starten, benötigt ein Webcrawler eine Start-URL, von der aus er mit dem Crawlen beginnt. Auf der Startseite werden alle internen Links gefunden und einem Linkpool hinzugefügt. Sobald alle Links auf der Webseite gesammelt wurden, folgt der Webcrawler dem nächsten Link im Pool, der noch nicht gecrawlt wurde. Der Erfassungsprozess wird dann für diesen Link wiederholt. Dieser Vorgang wird fortgesetzt, bis alle Links auf der Website gecrawlt wurden.
Anwendungsfälle für Web-Crawling
Webcrawling hat verschiedene Anwendungen in verschiedenen Branchen und Bereichen, darunter Suchmaschinenindizierung, Data Mining und Inhaltsaggregation.
Webcrawler indizieren Webseiten und bauen Suchmaschinendatenbanken auf, sodass Benutzer online nach Informationen suchen und diese finden können. Sie werden auch verwendet, um Inhalte von verschiedenen Websites zu sammeln und an einem Ort zu präsentieren. Nachrichtenaggregatoren, Blog-Aggregatoren und Content-Syndication-Plattformen nutzen Webcrawler, um Artikel und Informationen aus verschiedenen Quellen zu sammeln.
Forscher und Datenwissenschaftler nutzen Webcrawling, um Webdaten für Analysen und Forschungszwecke zu crawlen. Dies kann eine Stimmungsanalyse von Social-Media-Beiträgen, die Verfolgung der Ausbreitung von Krankheiten anhand von Nachrichtenartikeln oder das Sammeln von Informationen für die akademische Forschung sein. Der Python-Crawler kann Echtzeitdaten wie Börsenkurse, Wetterbedingungen, Sportergebnisse und Live-Streaming-Ereignisse sammeln.
Tiefen-zuerst vs. Breiten-zuerst-Kriechen
Tiefen- und Breitencrawlen sind zwei grundlegende Strategien, die Webcrawler zum Navigieren und Indexieren im Web verwenden. Sie unterscheiden sich darin, wie sie Webseiten priorisieren und durchsuchen.
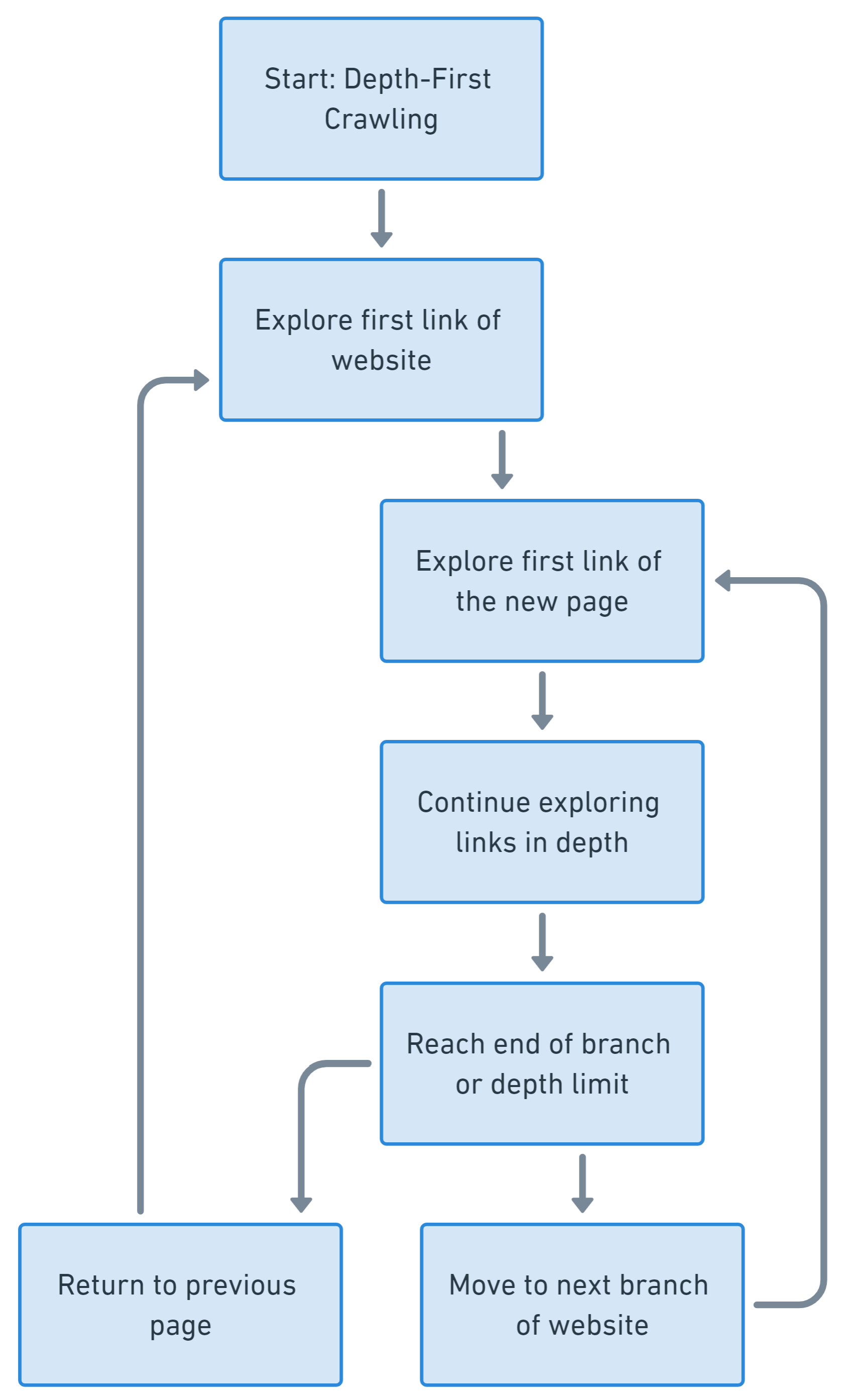
Beim Deep-First-Crawling liegt der Schwerpunkt darauf, einen einzelnen Zweig der Linkstruktur einer Website möglichst gründlich zu erkunden, bevor zu einem anderen Zweig übergegangen wird. Es priorisiert die Abfolge eines Linkpfads vor der Verzweigung.
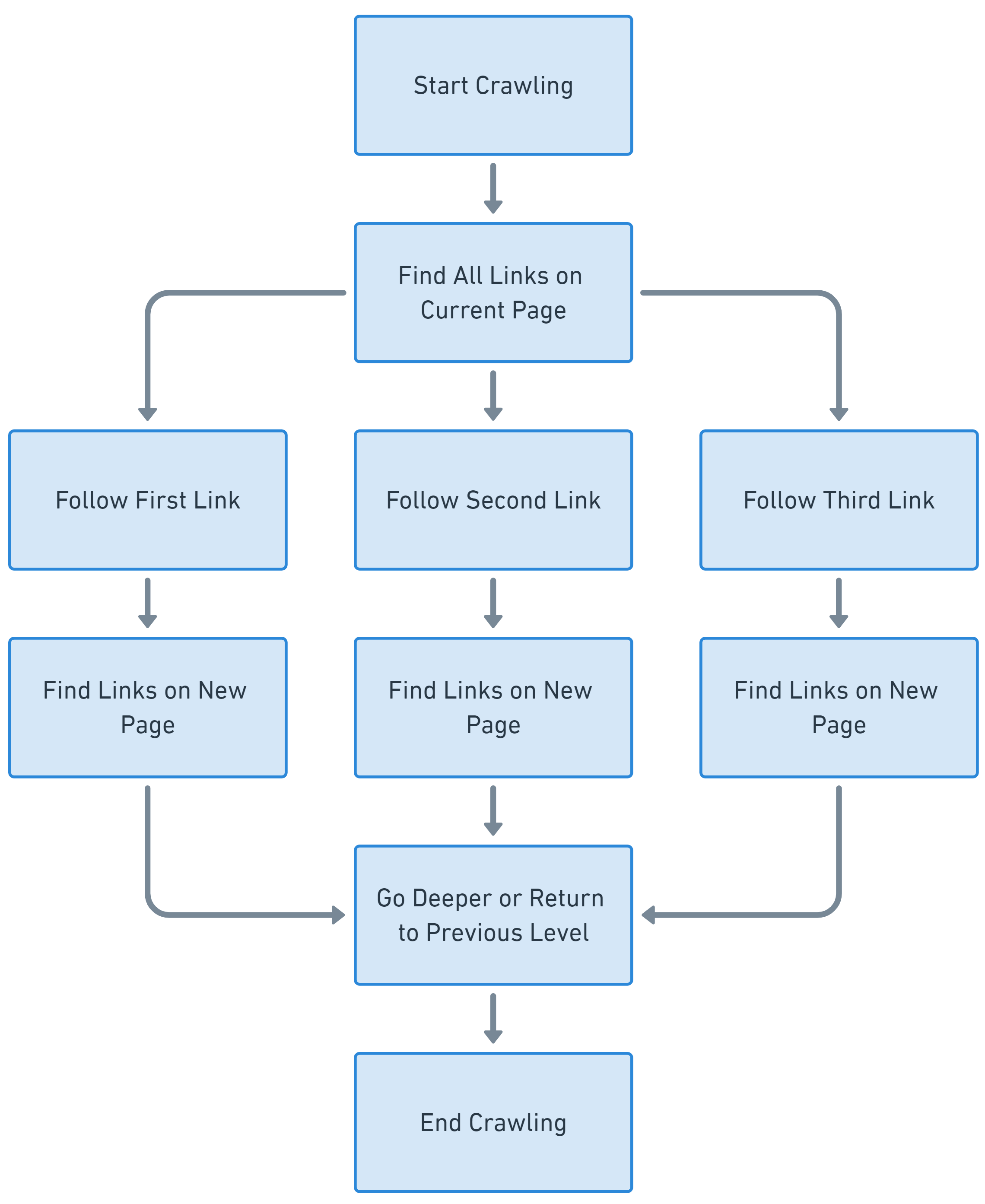
Beim Breiten-First-Crawling hingegen geht es darum, ein breites Spektrum an Webseiten mit der gleichen Tiefe zu erkunden, bevor man tiefer geht. Es gibt der Breite Vorrang vor der Tiefe.
In der Praxis verwenden viele Webcrawler eine Kombination dieser Strategien und implementieren einen hybriden Ansatz, der Tiefe und Breite in Einklang bringt, um die gewünschten Ergebnisse zu erzielen.
Voraussetzungen für das Crawlen von Webseiten
Für das Webcrawlen ist eine einzigartige Bibliothek erforderlich, um verschiedene Links anzufordern und Daten von der Seite zu extrahieren. Zu diesem Zweck eignen sich die Scraping-Bibliotheken, die wir zuvor betrachtet haben. Am häufigsten für diese Zwecke sind jedoch:
- Anfragen mit BeautifulSoup. Dies ist eine gute Wahl zum Schaben, auch wenn Sie Anfänger sind. Allerdings weisen diese Bibliotheken einige Einschränkungen auf, da sie Ihnen nur das Stellen einfacher Anfragen und das Analysieren von Daten ermöglichen. In diesem Fall benötigen wir auch die Bibliothek urllib, um mit verschiedenen Teilen des Links arbeiten zu können.
- Selen. Ermöglicht Ihnen die Verwendung eines Headless-Browsers und erhöht so die Chancen, Blockierungen beim Crawlen von Seiten zu vermeiden. Durch die Verwendung dieser Bibliothek können Sie das Verhalten eines echten Benutzers nachahmen, was bedeutet, dass ihre Verwendung das Risiko einer Blockierung verringert und alle Probleme der ersten Option löst.
- Scrapy. Dies ist keine Bibliothek, sondern ein ganzes Framework zum Scrapen. Es verfügt über eine Reihe von Funktionen, die speziell zur Lösung dieser Aufgabe entwickelt wurden. Im Vergleich zu anderen Bibliotheken kann die Verwendung jedoch recht schwierig erscheinen.
In diesem Artikel betrachten wir alle drei Optionen, damit Sie die für Ihre Bedürfnisse und Aufgaben am besten geeignete Lösung finden. Stellen Sie zunächst sicher, dass Sie Python 3 und einen Texteditor installiert haben, vorzugsweise mit Syntaxhervorhebung (wir empfehlen die Verwendung von Sublime oder Visual Studio Code). Sie benötigen zwar keine vollwertige IDE, um mit Python zu arbeiten, sie können jedoch das Codieren erleichtern. Jetzt installieren wir die benötigten Bibliotheken:
pip install beautifulsoup4
pip install urllib
pip install selenium
pip install scrapyDie Anforderungsbibliothek ist vorinstalliert und Sie benötigen einen Webtreiber, um Selenium verwenden zu können. Anweisungen zur Installation aller Selenium-Komponenten, einschließlich des Webtreibers, finden Sie in unserem vorherigen Artikel.
Web-Crawling mit Requests und BeautifulSoup
Um dieses Beispiel nützlicher und verständlicher zu machen, setzen wir uns ein Ziel. Nehmen wir beispielsweise an, dass wir einen Webcrawler erstellen möchten, mit dem wir Sitemaps erstellen. Erstellen Sie eine Datei mit der Erweiterung .py, in der Sie arbeiten möchten. Als Erstes müssen wir alle Module und Bibliotheken importieren, die wir im Skript verwenden werden.
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoinDefinieren Sie eine Start-URL, von der aus der Web-Crawling-Prozess gestartet wird, einen Satz zum Speichern besuchter URLs, um doppelte URLs zu vermeiden, und eine Liste zum Speichern gesammelter URLs.
start_url="https://example.com"
visited_urls = set()
sitemap = ()Der einfachste Weg, alle Links zu durchlaufen, besteht darin, eine separate Funktion zu erstellen, die wir für jeden gefundenen Link aufrufen.
def crawl(url):Überprüfen Sie zunächst, ob die URL bereits einmal besucht wurde, um Duplikate zu vermeiden:
if url in visited_urls:
returnWenn der Link noch nicht verarbeitet wurde, verarbeiten Sie ihn. Um jedoch unerwartete Fehler und Unterbrechungen zu vermeiden, schließen Sie die Verarbeitung in einen Try/Except-Block ein.
try:
# Here will be URL process
except Exception as e:
print(f'Error crawling URL: {url}')
print(e)Als nächstes fahren wir mit dem Try-Block fort. Folgen Sie dem Link und prüfen Sie, ob der Statuscode 200 zurückgegeben wird. Dies bedeutet, dass die Site eine erfolgreiche Antwort zurückgegeben hat. Wenn die Website einen anderen Statuscode zurückgibt, überspringen wir diesen Link.
response = requests.get(url)
if response.status_code == 200:Wenn der Statuscode erfolgreich ist, analysieren Sie die Webseite mit BeautifulSoup und extrahieren Sie alle Links.
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a')Extrahieren Sie alle URLs aus der Sitemap und speichern Sie sie in einer Liste. Verarbeiten Sie dann jede gefundene URL rekursiv.
for link in links:
href = link.get('href')
if href:
full_url = urljoin(url, href)
sitemap.append(full_url)
crawl(full_url) Markieren Sie am Ende nach dem Try/Except-Block die aktuelle URL als verarbeitet.
visited_urls.add(url)Wir haben nun die Definition der Funktion abgeschlossen. Wir müssen es jedoch noch aufrufen. Wir konnten es nicht aufrufen, bevor wir es definiert haben, da Python eine interpretierte Programmiersprache ist, was bedeutet, dass es Code Zeile für Zeile ausführt und ihn vor der Ausführung nicht kompiliert. Rufen wir also die Funktion für den Startlink auf, die wir zu Beginn deklariert haben.
crawl(start_url)Damit ist der Crawling-Vorgang abgeschlossen. Mit den gesammelten Links können Sie nun alles tun, was Sie brauchen. Speichern wir beispielsweise die generierte Sitemap in einer Textdatei und zeigen Sie auf dem Bildschirm eine Meldung an, dass die Sitemap erfolgreich generiert wurde.
with open('sitemap.txt', 'w') as file:
for url in sitemap:
file.write(url + '\n')
print('Sitemap created and saved to sitemap.txt')Wenn Sie nun das Skript ausführen, wird eine sitemap.txt-Datei generiert, die alle URLs der Website enthält. Diese Sitemap kann für die Suchmaschinenoptimierung (SEO) und die Website-Organisation hilfreich sein.
Web-Crawling mit Scrapy
Scrapy ist ein Open-Source-Web-Crawling- und Scraping-Python-Framework. Es bietet leistungsstarke und flexible Tools zum Extrahieren von Daten aus Websites. Sie können damit benutzerdefinierte Spider definieren, um auf Websites zu navigieren, Daten zu extrahieren und sie in verschiedenen Formaten zu speichern.
Scrapy übernimmt auch die Anforderungsdrosselung, das gleichzeitige Crawlen und andere erweiterte Funktionen. Die Installation und Verwendung von Scrapy haben wir bereits in einem früheren Beitrag behandelt, daher werden wir uns hier nicht wiederholen. Lassen Sie uns einen Crawler erstellen, um mit Scrapy eine Sitemap zu erstellen. Verwenden Sie diesen Befehl, um ein neues Projekt zu erstellen:
scrapy startproject my_sitemapErstellen Sie in Ihrem Scrapy-Projekt einen Spider, der definiert, wie Ihre Website gecrawlt und Links gesammelt werden soll. In Ihrem Spider können Sie die Start-URLs und die Art und Weise definieren, wie Links gefolgt werden sollen:
import scrapy
class SitemapSpider(scrapy.Spider):
name="sitemap"
allowed_domains = ('example.com')
start_urls = ('https://example.com')
def parse(self, response):
for href in response.css('a::attr(href)'):
url = response.urljoin(href.extract())
yield {
'url': url
}Um den Spider auszuführen, verwenden Sie den folgenden Befehl:
scrapy crawl sitemap -o sitemap.jsonAls Ergebnis erhalten Sie eine Ausgabedatei namens sitemap.json, die eine Sitemap enthält.
Verwenden Sie Selenium zum Crawlen dynamischer Websites
Um mit Selenium alle Links auf einer Website zu durchsuchen und für die Sitemap-Generierung zu sammeln, können Sie eine rekursive Funktion erstellen, die wie im ersten Beispiel durch die Website navigiert, Links sammelt und ihnen folgt. Importieren Sie zunächst die Bibliothek und konfigurieren Sie den Headless-Browser:
from selenium import webdriver
DRIVER_PATH = 'C:\chromedriver.exe' #or any other path of webdriver
options = webdriver.ChromeOptions()
options.add_argument("user-agent=Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36")
driver = webdriver.Chrome(executable_path=DRIVER_PATH, options=options)Geben Sie nun die Start-URL an und erstellen Sie einen Satz zum Speichern besuchter URLs, um zu vermeiden, dass dieselbe Seite zweimal gecrawlt wird.
start_url="https://example.com"
visited_urls = set()Erstellen wir eine Funktion zum Verarbeiten von URLs, die mithilfe von Selenium eine rekursive Linkdurchquerung durchführt.
def collect_links(url):
if url in visited_urls:
return
visited_urls.add(url)
driver.get(url)
links = (a.get_attribute('href') for a in driver.find_elements_by_tag_name('a'))
for link in links:
if link and link.startswith('https://example.com'):
collect_links(link)Jetzt müssen Sie nur noch die Funktion aufrufen, um den Linksammlungsprozess zu starten.
collect_links(start_url)Um die Skriptausführung abzuschließen, schließen Sie den Browser:
driver.quit()Selenium ist ein perfektes Tool zum Scrapen dynamischer Websites, erfordert jedoch möglicherweise mehr Code und Ressourcen als herkömmliche Webcrawler. Seine Fähigkeit, mit Webseiten zu interagieren und JavaScript auszuführen, macht es zur ersten Wahl für das Scraping von Inhalten, die auf Echtzeitaktualisierungen und Benutzerinteraktionen angewiesen sind.
Vermeidung von Anti-Bot-Maßnahmen
Web-Scraper und Crawler sind häufig mit Anti-Bot-Maßnahmen konfrontiert, die von Websites implementiert werden, um automatisierte Zugriffe zu verhindern. Diese Maßnahmen werden ergriffen, um die Website vor Missbrauch oder Datendiebstahl zu schützen. Crawler-Betreiber müssen über diese Bot-Schutzmechanismen Bescheid wissen und wissen, wie sie sie umgehen können.
Identifizierung und Umgang mit Anti-Bot-Mechanismen
Websites können Anfragen blockieren, wenn sie verdächtig erscheinen. Um dies zu vermeiden, können Sie einige der Tipps nutzen, die Ihnen helfen können. Sie können beispielsweise einen Benutzeragenten verwenden, der einen typischen Browser nachahmt. Am besten verwenden Sie einen echten Benutzeragenten.
Eine der häufigsten Anti-Bot-Maßnahmen ist das Blockieren von Anfragen von bestimmten IP-Adressen. Um dies zu vermeiden, verwenden Sie Proxyserver oder richten Sie Ihren eigenen Proxy-Pool ein. Um die Auslösung ratenbegrenzender Mechanismen zu vermeiden, kontrollieren Sie die Anzahl der Anfragen über einen bestimmten Zeitraum, indem Sie Verzögerungen zwischen den Anfragen nutzen.
Websites können Sitzungsmarker verwenden, um die Benutzerinteraktion zu verfolgen. Um eine Erkennung zu vermeiden, ahmen Sie das Benutzerverhalten nach und verwalten Sie Sitzungen. Sie können auch Headless-Browser verwenden, um echte Benutzerinteraktionen nachzuahmen. Eine weitere Möglichkeit für Websites ist die Verwendung von Cookies zur Verfolgung von Benutzersitzungen. Um Sitzungen am Leben zu erhalten, verwenden Sie Cookies in Ihrem Web-Crawling-Code.
CAPTCHAs und wie man sie umgeht
CAPTCHA ist ein Challenge-Response-Test, der in der Informatik verwendet wird, um festzustellen, ob der Benutzer ein Mensch ist. Sie sind so konzipiert, dass sie für Menschen leicht zu lösen sind, für Bots jedoch schwierig.
Es gibt verschiedene Möglichkeiten, CAPTCHA zu umgehen. Eine Möglichkeit besteht darin, einen CAPTCHA-Solver-Dienst eines Drittanbieters zu verwenden. Diese Dienste nutzen verschiedene Methoden zur Lösung von CAPTCHAs, darunter Bilderkennung und maschinelles Lernen.
Eine andere Möglichkeit, CAPTCHA zu umgehen, besteht darin, das CAPTCHA manuell zu lösen. Bei großflächigen Schabearbeiten ist dies oft nicht möglich, in manchen Fällen jedoch durchaus machbar.
Websites zeigen CAPTCHAs normalerweise nur an, wenn das Verhalten eines Benutzers verdächtig ist. Indem Sie die Empfehlungen im vorherigen Abschnitt befolgen, können Sie die Wahrscheinlichkeit verringern, dass Ihnen ein CAPTCHA angezeigt wird.
Abschluss
Web-Crawling ist ein wesentliches Werkzeug zum Sammeln von Daten aus dem Internet, und Python bietet eine robuste Umgebung für seine Implementierung. Wenn Sie die Prinzipien, Typen und Methoden des Web-Crawlings verstehen, können Sie dessen Potenzial in verschiedenen Bereichen nutzen, von SEO bis hin zu Forschung und Analyse.
Es ist wichtig, Webcrawler zu verstehen, die Grundlage des Web Scrapings. Webcrawler werden in verschiedene Typen eingeteilt, z. B. Allzweck-Crawler, Spezial-Crawler, inkrementelle Crawler und Deep-Crawler. Jeder Typ führt eine bestimmte Aufgabe aus, von der Indexierung des gesamten Internets bis hin zum Zugriff auf Inhalte, die in Standardsuchmaschinen normalerweise nicht sichtbar sind.
Für das Web-Crawling stehen zahlreiche Bibliotheken und Tools zur Verfügung, darunter Requests mit BeautifulSoup, Selenium und Scrapy. Mit diesen Tools können Entwickler Daten effizient von Websites extrahieren. Die Wahl des Tools hängt von den spezifischen Anforderungen des Projekts ab.
