Verwenden Sie Scraperapi mit Zypressen, um javaScript-hochwertige Websites zu kratzen und End-to-End-Tests durchzuführen. Es ist perfekt für dynamische Seiten, die regelmäßige Kratzwerkzeuge nicht verarbeiten können.
Erste Schritte
Dieser grundlegende Cypress -Test eignet sich gut für statische Websites, lädt jedoch Seiten auf, die Inhalte mit JavaScript laden:
// Basic Cypress Test Without ScraperAPI
describe('Plain Cypress scraping', () => {
it('visits a page', () => {
cy.visit('https://example.com')
cy.get('h1').should('contain.text', 'Example Domain')
})
})
Verwenden Sie beim Kratzen von JavaScript-hochwertigen Seiten mit Scraperapi mit cy.request() und stattdessen Dom Parsen.
Empfohlene Methode: Benutzerdefinierte Befehl + DOM -Injektion + Schaferapi
Scraperapi -Handles Rendering, Proxies, Captchas und Wiederholungen für Sie. Cypress holt die HTML ab, injiziert sie in einen DOM -Knoten und lässt sie leicht abfragen.
Anforderungen
- Zypressen für das Laufen von Scraping -Tests
npmder Paketmanager zur Installation von Zypressen und Abhängigkeitennodejs/nodeZypressen und NPM ausführencypress-dotenvUm Ihre Anmeldeinformationen sicher zu halten- Scraperapi und der angegebene API -Schlüssel zum Kratzen
Schritt 1: Richten Sie Ihr Node.js -Projekt ein
Beginnen Sie, indem Sie zu Ihrem Projektordner wechseln und node.js installieren und npm.
# For Ubuntu
sudo apt update
sudo apt install nodejs npm
# For macOS (includes npm)
brew install node
# For Windows
# Download and install Node.js (which includes npm) from the official website (https://nodejs.org/en/download/) and follow the installer steps.
Initialisieren Sie Ihr Node.js -Projekt und laden Sie Cypress durch Ausführen herunter:
npm init -y
npm install cypress --save-dev
Schritt 2: Fügen Sie einen benutzerdefinierten Befehl hinzu
Erstellen Sie zunächst eine Zypressenordnerstruktur, indem Sie diese in Ihrem Terminal aus der Wurzel Ihres Projekts ausführen:
Wenn Sie dies zum ersten Mal tun, erstellt Cypress seine Standardordnerstruktur.
Jetzt können Sie navigieren cypress/support/commands.js und erstellen Sie einen wiederverwendbaren Cypress-Befehl, der sich in Scraperapi integrieren, um HTML von javaScript-hungrigen Websites zu holen und zu analysieren.
// cypress/support/commands.js
Cypress.Commands.add('scrapeViaScraperAPI', (targetUrl) => {
const scraperUrl = `http://api.scraperapi.com?api_key=${Cypress.env('SCRAPER_API_KEY')}&url=${encodeURIComponent(targetUrl)}&timeout=60000`;
return cy.request(scraperUrl).then((response) => {
return cy.document().then((document) => {
const container = document.createElement('div');
container.innerHTML = response.body;
const titles = Array.from(container.querySelectorAll('.product_pod h3 a')).map(el =>
el.getAttribute('title')
);
return titles;
});
});
});
Verwenden Sie ein Umgebungsvariablen -Setup, um Ihren Schaferapi -Schlüssel zu speichern. Hier können Sie Ihren API -Schlüssel erhalten.
Installieren cypress-dotenverstellen Sie dann a .env Datei in Ihrem Projektstamm:
npm install -D cypress-dotenv
# .env
SCRAPER_API_KEY=your_scraper_api_key
Aktualisieren Sie Ihre cypress.config.js wie folgt:
// cypress.config.js
const { defineConfig } = require("cypress");
require('dotenv').config();
module.exports = defineConfig({
e2e: {
setupNodeEvents(on, config) {
config.env.SCRAPER_API_KEY = process.env.SCRAPER_API_KEY;
return config;
},
supportFile: "cypress/support/commands.js"
}
});
Schritt 3: Verwenden Sie den Befehl in Ihrem Test
In deinem cypress/ Ordner, erstellen Sie einen neuen Ordner e2e und eine Datei scraperapi.cy.js:
mkdir e2e
touch e2e/scraperapi.cy.js
Fügen Sie in der Datei den benutzerdefinierten Befehl in einen Cypress -Test ein, in dem die abgekratzten Daten in einem Browser -DOM angezeigt werden.
// cypress/e2e/scraperapi.cy.js
describe('Scrape Books to Scrape with ScraperAPI + Cypress', () => {
it('gets product titles and displays them', () => {
cy.visit('cypress/fixtures/blank.html'); // Load static HTML file
cy.scrapeViaScraperAPI('http://books.toscrape.com/catalogue/page-1.html').then((titles) => {
cy.document().then((doc) => {
const container = doc.getElementById('results');
const list = doc.createElement('ul');
titles.forEach(title => {
const item = doc.createElement('li');
item.innerText = title;
list.appendChild(item);
});
container.appendChild(list);
});
cy.screenshot('scraped-book-titles'); // Take screenshot after injecting
});
});
});
Schritt 4: Erstellen Sie die leere.html -Datei und führen Sie Ihren Cypress -Test aus
Erstellen Sie in Ihrem Projektordner den Ordner cypress/fixtures Wenn es noch nicht existiert:
mkdir -p cypress/fixtures
Erstellen Sie im Inneren das Blank.html mit dem folgenden Minimalcode (oder ähnlichem!):
Sie können jetzt Ihre Tests aus dem Projekt Root -Ordner ausführen (das, in dem Ihr Paket lebt).
Diese Methode funktioniert, weil:
- Scraperapi behandelt das Proxying und die Geo-Routing
- Cypress injiziert den Inhalt in den Browser -Dom
- Sie erhalten die volle Kontrolle über native DOM -APIs
Alternative: Cy.Request ohne Schaferapi
Sie können anrufen cy.request() Direkt, aber es weder JS oder IPS dreht: IPs:
describe('Simple cy.request test', () => {
it('should load example.com and check the response', () => {
cy.request('https://example.com').then((response) => {
expect(response.status).to.eq(200);
expect(response.body).to.include('Example Domain');
});
});
});
Diese Methode ist nicht ideal, weil:
- Es setzt Ihre IP dem Bot -Schutz aus.
- Es umgeht keine Captchas oder dreht Proxies.
- Es scheitert an Websites, die Geolokalisierung oder JavaScript -Rendering erfordern.
Bevorzugen Sie Scraperapi für alles, was über ein grundlegendes Kratzen hinausgeht.
Scraperapi -Parameter, die wichtig sind
Scraperapi unterstützt Optionen über Abfrageparameter:
const scraperUrl = `http://api.scraperapi.com?api_key=YOUR_KEY&url=https://target.com&render=true&country_code=us&session_number=555`
| Parameter | Was es tut | Wann man es benutzt |
|---|---|---|
render=true |
Fordert Scraperapi an, JavaScript zu laden | Verwenden Sie dies für dynamische Seiten oder Spas |
country_code=us |
Verwendet eine US -IP -Adresse | Ideal für geo-blockierte Inhalte |
premium=true |
Löst CAPTCHAS und RETRIES fehlgeschlagene Anfragen | Benötigt für schwer zu krafthafte Websites |
session_number=555 |
Hält die gleiche Proxy -IP über mehrere Anfragen hinweg bei | Verwenden Sie es, wenn Sie eine Sitzung pflegen müssen |
Diese drei sind alles, was Sie in den meisten Fällen brauchen. Weitere Informationen finden Sie in den Dokumenten.
Test -Wiederholungen
Verbesserung der Stabilität mit Test -Wiederholungen:
// cypress.config.js
export default {
e2e: {
retries: {
runMode: 2,
openMode: 0,
},
},
}
Dies hilft, wenn die Seiten langsam laden oder Fehlern werfen.
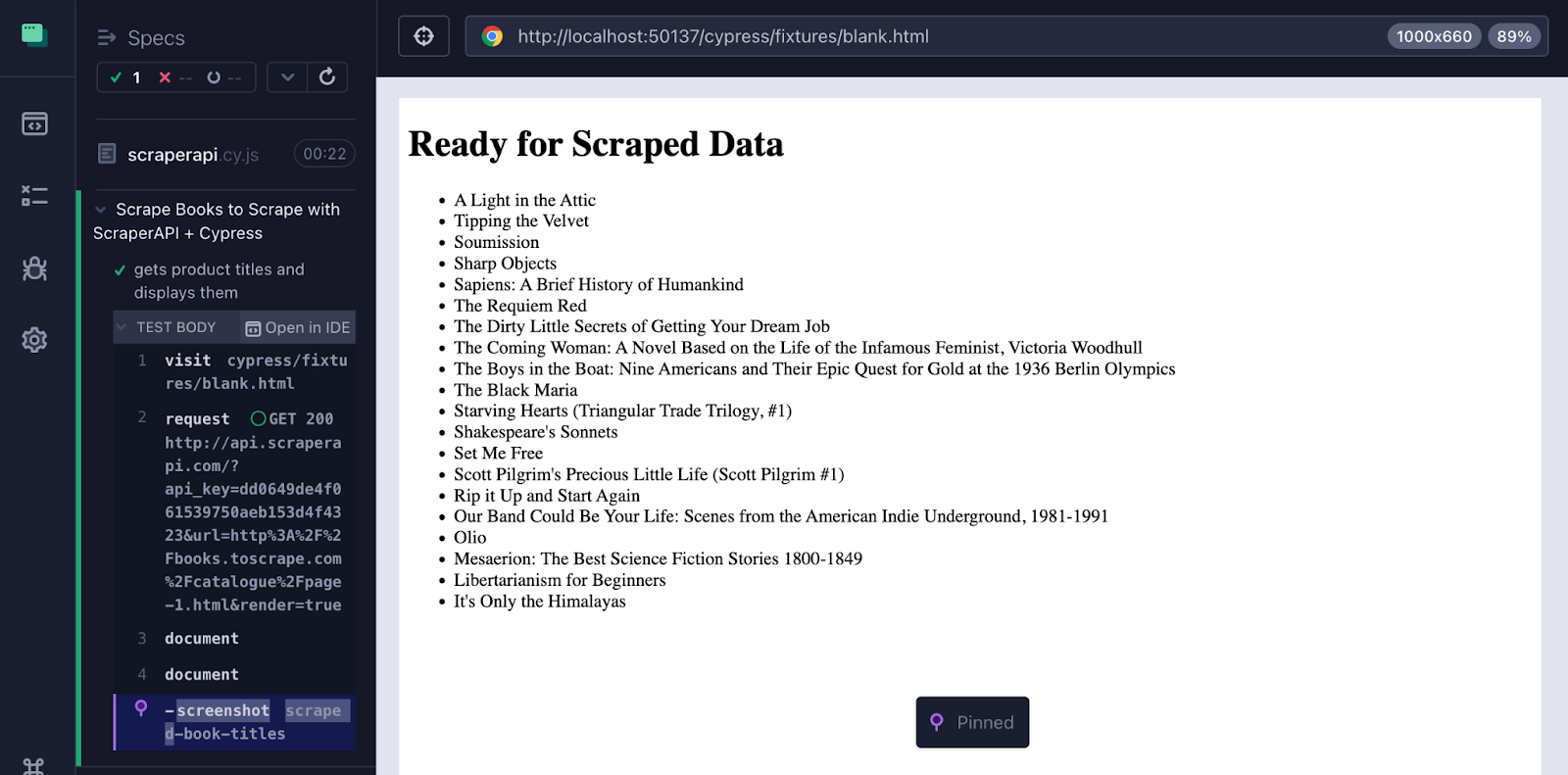
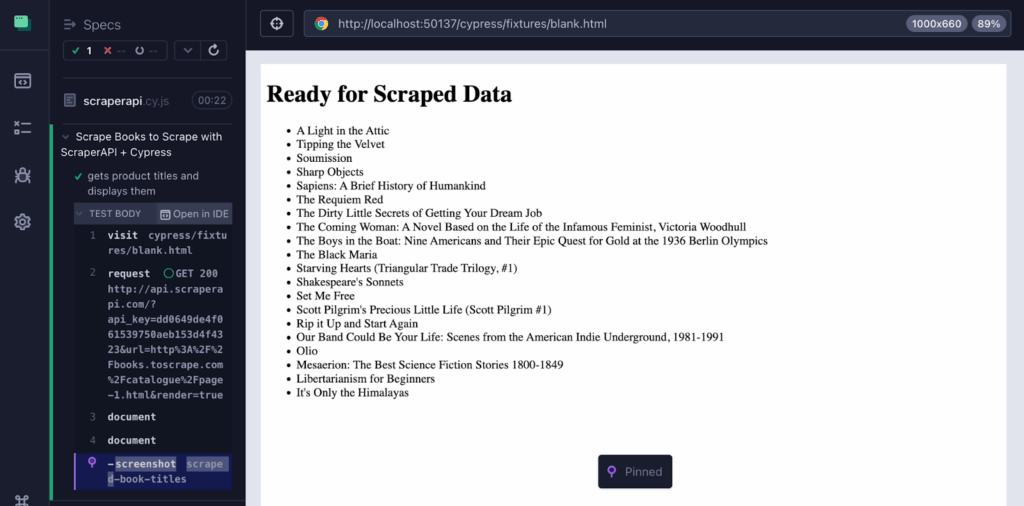
Visualisieren Sie die abgekratzten Daten im DOM
Führen Sie Ihren Test mit den Daten aus:
Dann auswählen scraperapi.cy.js In der Cypress -Benutzeroberfläche. Sie sollten folgende Ergebnisse erzielen:
- Das statische HTML -Seite laden (
Ready for Scraped Data) - Abgekratzte Buchtitel, die dynamisch in den DOM injiziert werden
- Ein Screenshot gespeichert als
scraped-book-titles.png