Scraperapi ist ein leistungsstarkes Scraping -Tool, das automatisch Proxies, Browser und Captchas übernimmt. In dieser Anleitung lernen Sie, wie Sie Scraperapi in htmlunit integrieren, einem schnellen und leichten, kopflosen Browser für Java.
Erste Schritte
Bevor wir Scraperapi integrieren, finden Sie hier ein grundlegendes HTMLunit -Scraping -Beispiel:
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class BasicHtmlUnit {
public static void main(String() args) throws Exception {
WebClient client = new WebClient(BrowserVersion.CHROME);
client.getOptions().setCssEnabled(false);
client.getOptions().setJavaScriptEnabled(false);
HtmlPage page = client.getPage("https://httpbin.org/ip");
System.out.println(page.asNormalizedText());
client.close();
}
}
Dies eignet sich für Basic Scraping, löst jedoch keine Probleme wie IP -Verbote oder Captchas.
Integrationsmethoden
Empfohlen: API -Endpunktmethode
Die beste Möglichkeit, Scraperapi mit HTMLunit zu verwenden, besteht darin, den API -Endpunkt direkt aufzurufen und die Ziel -URL als Abfrageparameter zu übergeben. Dadurch wird Ihre Anforderungswege über das Proxy-Netzwerk von Scraperapi mit integriertem Captcha-Handling gewährleistet.
Erforderliches Setup
1. Installieren Sie Java (wenn nicht bereits installiert)
# Ubuntu
sudo apt-get update
sudo apt-get install default-jdk
# MacOS
brew install openjdk@2
Dann zu Ihrer Shell -Konfiguration (z. B. zu Ihrer Shell -Konfiguration .zshrc oder .bash_profile):
export JAVA_HOME="/Library/Java/JavaVirtualMachines/temurin-21.jdk/Contents/Home"
export PATH="$JAVA_HOME/bin:$PATH"
echo 'export JAVA_HOME="/Library/Java/JavaVirtualMachines/temurin-21.jdk/Contents/Home"' >> ~/.bash_profile
echo 'export PATH="$JAVA_HOME/bin:$PATH"' >> ~/.bash_profile
Laden Sie Ihre Shell neu:
source ~/.zshrc
# or
source ~/.bash_profile
Bestätigen Sie, dass Java installiert ist:
2. Installieren Sie Maven
# Ubuntu
sudo apt update
sudo apt install maven
# MacOS
brew install maven
Überprüfen:
3. Die Projektstruktur einrichten
Erstellen Sie einen Ordner und initialisieren Sie das Maven -Projekt:
mkdir htmlunit-scraperapi && cd htmlunit-scraperapi
Erstellen Sie die Struktur: Erstellen Sie die Struktur:
src/
main/
java/
MarketPrice.java
4. Fügen Sie Abhängigkeiten in pom.xml hinzu
Erstellen Sie im Root Ihres Projektordners eine Datei pom.xml und fügen Sie Folgendes ein:
4.0.0
com.scraperapi
htmlunit-scraperapi
1.0-SNAPSHOT
net.sourceforge.htmlunit
htmlunit
2.70.0
io.github.cdimascio
java-dotenv
5.2.2
org.codehaus.mojo
exec-maven-plugin
3.1.0
MarketPrice
5. Fügen Sie .Env -Datei im Root hinzu
Erstellen Sie im selben Ordner a .env Datei:
SCRAPERAPI_KEY=your_api_key_here
Hier können Sie Ihren Schaferapi -Schlüssel erhalten.
Voller Arbeitscode
Fügen Sie dies hinein MarketPrice.java:
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomNode;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import io.github.cdimascio.dotenv.Dotenv;
import java.io.IOException;
public class MarketPrice {
public static void main(String() args) throws IOException {
// Load ScraperAPI key from .env
Dotenv dotenv = Dotenv.load();
String apiKey = dotenv.get("SCRAPERAPI_KEY");
if (apiKey == null || apiKey.isEmpty()) {
System.err.println("SCRAPERAPI_KEY is missing in your .env file.");
return;
}
// Target a real HTML site
String targetUrl = "https://quotes.toscrape.com";
String scraperApiUrl = String.format("http://api.scraperapi.com?api_key=%s&url=%s",
apiKey, targetUrl);
// Initialize headless browser
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
// Fetch and parse page
HtmlPage page = (HtmlPage) webClient.getPage(scraperApiUrl);
DomNodeList quoteBlocks = page.querySelectorAll(".quote");
System.out.println("\n📌 Scraped Quotes from https://quotes.toscrape.com:\n");
for (DomNode quote : quoteBlocks) {
String text = quote.querySelector(".text").asNormalizedText();
String author = quote.querySelector(".author").asNormalizedText();
DomNodeList tags = quote.querySelectorAll(".tags .tag");
System.out.println("📝 Quote: " + text);
System.out.println("👤 Author: " + author);
System.out.print("🏷️ Tags: ");
for (DomNode tag : tags) {
System.out.print(tag.asNormalizedText() + " ");
}
System.out.println("\n------------------------------------------\n");
}
webClient.close();
}
}
Stellen Sie sicher, dass Sie Ihren API -Schlüssel in der Umgebungsvariablen festlegen SCRAPERAPI_KEY.
Nicht empfohlen: Proxy -Modus
HTMLUnit ermöglicht die Proxy -Konfiguration, aber Scraperapi verwendet die Anfragestöne -Authentifizierung, die nicht mit dem Proxy -Modell von HTMLUNIT funktioniert.
Warum es fehlschlägt
- Scraperapi benötigt die API -Taste in der URL -Abfrage.
- HTMLUNIT Proxy Setup erwartet eine statische IP oder eine grundlegende Authentifizierung.
Fehlerausgabe:
Verwenden Sie stattdessen die API -Endpunktmethode.
Optionale Parameter
Scraperapi unterstützt verschiedene Optionen über Abfrageparameter:
{
Render = true, // Load JavaScript
CountryCode = "us", // Use US IP
Premium = true, // Enable CAPTCHA solving
SessionNumber = 123 // Maintain session across requests
};
| Parameter | Was es tut | Wann man es benutzt |
render=true |
Fordert Scraperapi an, JavaScript auszuführen | Verwendung für Spas und dynamische Inhalte |
country_code=us |
Routenanfragen über US -Proxies | Ideal für geo-blockierte Inhalte |
premium=true |
Ermöglicht CAPTCHA-Lösung und fortgeschrittene Anti-BOT-Maßnahmen | Essentiell für stark geschützte Stellen |
session_number=123 |
Behält die gleiche Proxy -IP über Anfragen hinweg bei | Verwenden Sie, wenn Sie Anmeldesitzungen beibehalten müssen |
Diese Parameter decken die meisten Schablonen -Szenarien ab. Weitere Optionen finden Sie in der Dokumentation der Schaferapi.
Beispiel:
String scraperApiUrl = String.format("http://api.scraperapi.com?api_key=%s&url=%s&render=true&country_code=us", apiKey, java.net.URLEncoder.encode(targetUrl, "UTF-8"));
Best Practices
- Speichern Sie Ihren Schaferapi -Schlüssel immer in einer Umgebungsvariablen
- Verwenden
render=trueBei der Ausrichtung auf javaScript-strenge Websites - Vermeiden Sie die Verwendung von Proxy -Einstellungen in htmlunit
- Implementieren Sie die Wiederholungslogik beim Abkratzen großer Datensätze
- Deaktivieren Sie JavaScript/CSS für eine bessere Leistung auf statischen Seiten
Führen Sie den Schaber aus
Laufen Sie Ihre MarketPrice.java Datei mit:
mvn compile exec:java -Dexec.mainClass=MarketPrice
Erwartete Ausgabe:
Ihr Terminal sollte strukturierte Zitatdaten wie folgt anzeigen:
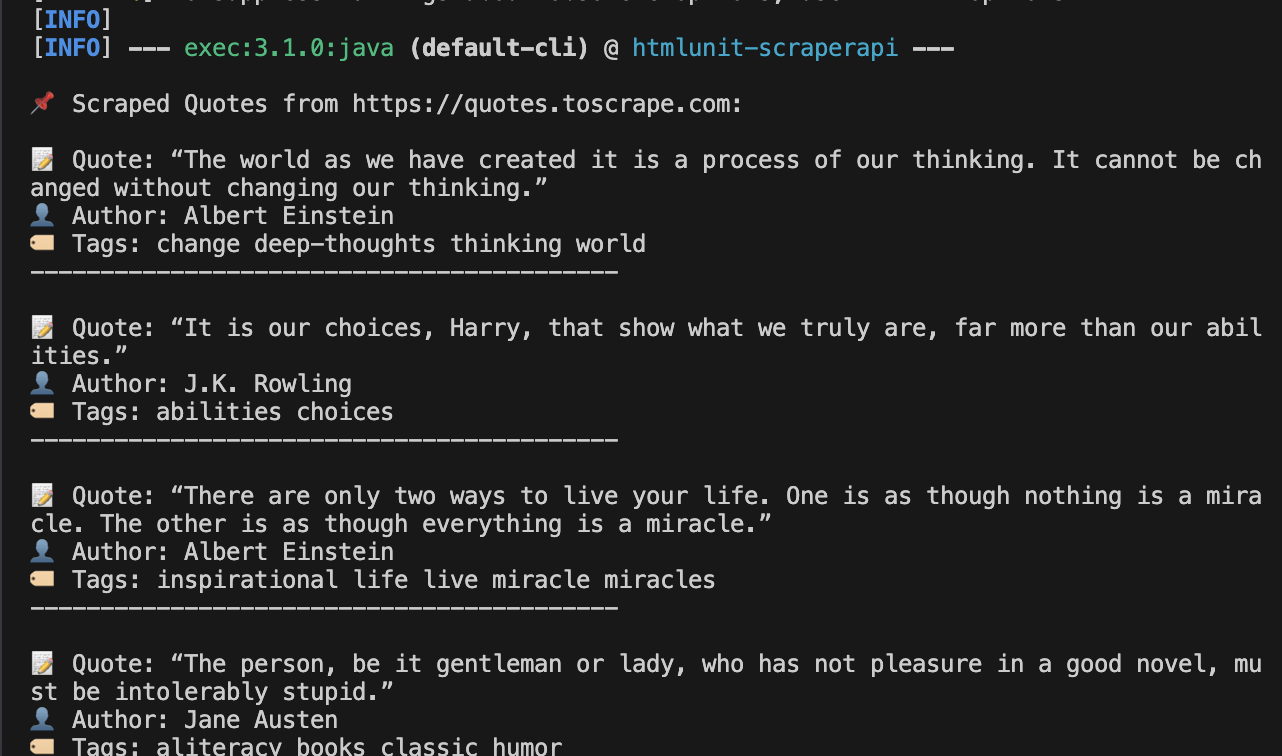
Dies bestätigt, dass Scraperapi die Anfrage bearbeitet und über sein Netzwerk geleitet wird.
