
Scraperapi hilft Ihnen, Websites zu kratzen, ohne blockiert zu werden. Es kümmert sich um Proxys, Captchas und kopflose Browser, sodass Sie sich auf Daten konzentrieren können. In dieser Anleitung zeigen wir Ihnen, wie Sie Scraperapi mit Chromedp, einer Go -Bibliothek für die Kontrolle von Chrom verwenden.
Sie lernen, wie Sie JavaScript-hochwertige Seiten laden, Inhalte rendern und Ihren API-Schlüssel mithilfe von Umgebungsvariablen sicher speichern.
Vor der Integration von Schaferapi ist hier ein einfaches chromedp Skript, das die HTML einer Webseite abruft:
package main
import (
"context"
"fmt"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var res string
err := chromedp.Run(ctx,
chromedp.Navigate("https://example.com"),
chromedp.OuterHTML("html", &res),
)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(res)
}
Dies funktioniert für einfache Websites. Es scheitert jedoch, wenn Websites Captchas, Blöcke oder Anti-Bot-Schutz verwenden. Dort hilft Scraperapi.
Empfohlen: API -Endpunktmethode
Dies ist der beste Weg, um Scraperapi mit zu verwenden chromedp. Sie senden eine reguläre Get -Anfrage an den Schaker -Endpunkt, anstatt sie als Proxy zu verwenden. Scraperapi rendert die Seite und gibt sauberes HTML zurück, in das Sie laden können chromedp bei Bedarf.
Warum das am besten funktioniert
- Vermeidet Proxy -Probleme und Browserflaggen
- Einfach einrichten und debuggen
- Funktioniert gut mit den meisten Websites
Anforderungen
Um diesen Leitfaden auszuführen, benötigen Sie Folgendes:
- Gehen Sie 1.20 oder höher installiert
chromedpgodotenv
Installieren Sie die Abhängigkeiten
In Ihrem Projektordner initialisieren Sie ein GO -Modul:
Führen Sie dann diese Befehle aus, um die Abhängigkeiten zu installieren:
go get -u github.com/chromedp/chromedp
go get -u github.com/joho/godotenv
Richten Sie Ihre .env -Datei einErstellen eine .env Datei im Stamm Ihres Projekts:
SCRAPERAPI_KEY=your_api_key_here
Dein Skript
In einer Datei scraperapi-chromedp.goPaste:
package main
import (
"context"
"fmt"
"io"
"net/http"
"os"
"time"
"github.com/chromedp/chromedp"
"github.com/joho/godotenv"
)
func main() {
err := godotenv.Load()
if err != nil {
fmt.Println("Error loading .env file")
return
}
apiKey := os.Getenv("SCRAPERAPI_KEY")
if apiKey == "" {
fmt.Println("Missing SCRAPERAPI_KEY")
return
}
// Use API instead of proxy
targetURL := "https://httpbin.org/ip"
scraperURL := fmt.Sprintf("http://api.scraperapi.com?api_key=%s&url=%s&render=true", apiKey, targetURL)
// Step 1: Fetch pre-rendered HTML from ScraperAPI
resp, err := http.Get(scraperURL)
if err != nil {
fmt.Println("HTTP request failed:", err)
return
}
defer resp.Body.Close()
bodyBytes, err := io.ReadAll(resp.Body)
if err != nil {
fmt.Println("Failed to read response:", err)
return
}
// Step 2: Load the HTML into a data URL for chromedp to parse
htmlContent := string(bodyBytes)
dataURL := "data:text/html;charset=utf-8," + htmlContent
// Step 3: Use chromedp to parse/extract from the static HTML
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
ctx, cancel = context.WithTimeout(ctx, 20*time.Second)
defer cancel()
var parsed string
err = chromedp.Run(ctx,
chromedp.Navigate(dataURL),
chromedp.Text("body", &parsed),
)
if err != nil {
fmt.Println("Scraping failed:", err)
return
}
fmt.Println("Parsed response:\n", parsed)
}
In diesem obigen Code wird Scraperapi verwendet, um eine Webseite abzurufen und zu rendern, und dann verwendet chromedp Um den HTML -Inhalt in Go zu analysieren.
Nicht empfohlen: Verwenden von Scraperapi als Proxy in Chromedp verwenden
Sie können versuchen, Scraperapi als Proxy in zu verwenden chromedpaber es ist nicht zuverlässig. Wir haben diese Methode getestet und Probleme wie:
net::ERR_INVALID_ARGUMENTnet::ERR_NO_SUPPORTED_PROXIES
Warum sollten Sie es vermeiden
- Proxy -Einstellungen in Chrome sind schwierig zu konfigurieren in Go
- TLS und Authentifizierung scheitern oft lautlos
- Debugging ist schwieriger und weniger konsequent
Diese Methode kann für einige Benutzer funktionieren, aber wir empfehlen sie nicht, es sei denn, Sie wissen, wie Sie mit Chrome -Proxy -Flags im kopflosen Modus umgehen.
Erweiterte Verwendung
SitzungsmanagementSie können sich dafür entscheiden, die gleiche Sitzung über Seiten hinweg zu führen, indem Sie Ihre aktualisieren scraperURL Like SO:
scraperURL := fmt.Sprintf("http://api.scraperapi.com?api_key=%s&session_number=1234&url=%s", apiKey, targetURL)
Land Targeting
IPs aus einem bestimmten Land zu verwenden:
scraperURL := fmt.Sprintf("http://api.scraperapi.com?api_key=%s&url=%s&country_code=us", apiKey, targetURL)
Best Practices
API -Schlüssel sicher speichern
Verwenden Sie a .env Datei und godotenv So laden Sie Ihren Schlüssel, anstatt ihn festzusagen.
Verwenden Sie Zeitüberschreitungen
Vermeiden Sie lange Warten, indem Sie eine Auszeit einstellen:
ctx, cancel := context.WithTimeout(context.Background(), 30*time.Second)
defer cancel()
Logik wiederholen
Einfaches Wiederholungsmuster:
Speichern Sie Ihren Code als scraperapi-chromedp.godann rennen:
go run scraperapi-chromedp.go
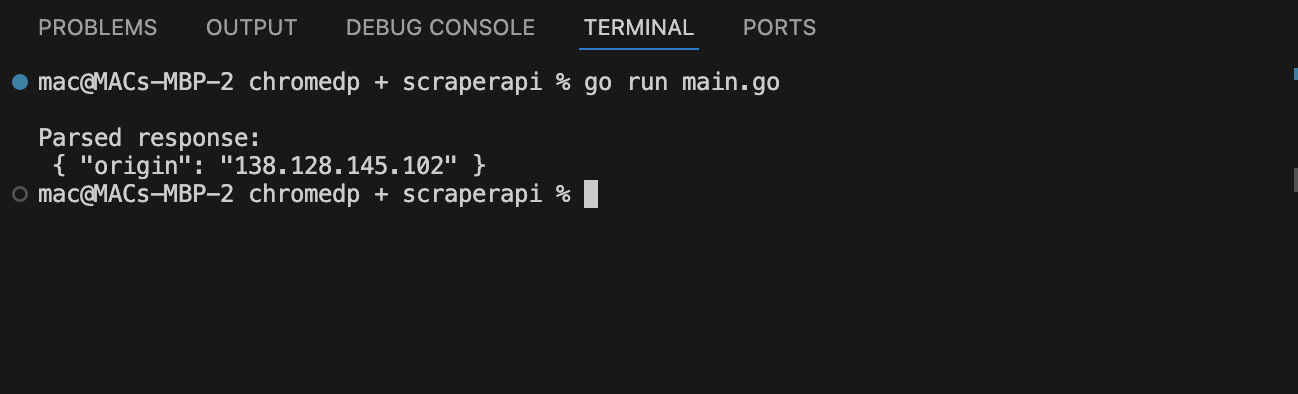
Wenn Sie es mit https://httpbin.org/IP testen, sollte die IP den Proxy -Server von Scraperapi widerspiegeln, den Scraperapi zugewiesen hat.
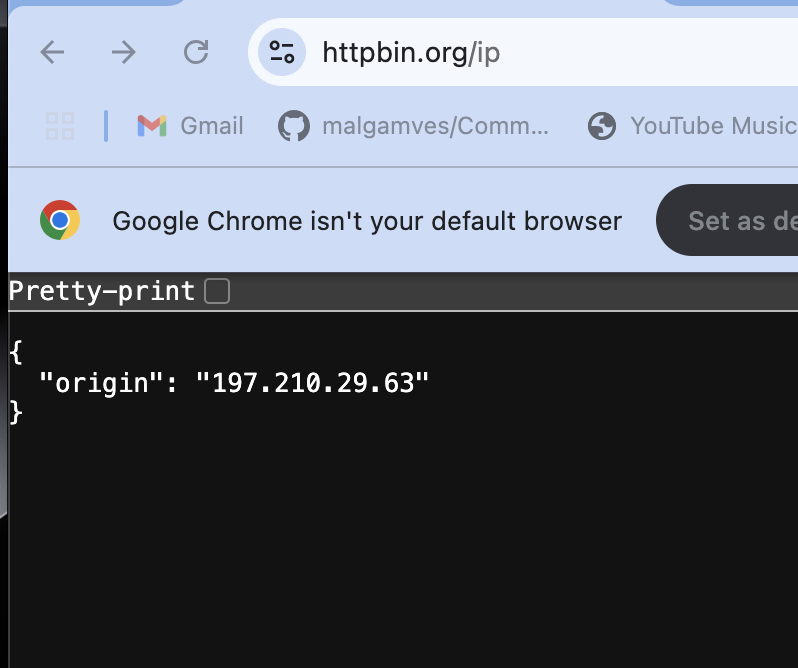
Dies bestätigt, dass Scraperapi die Anfrage bearbeitet.
Weitere Informationen finden Sie unter Scraperapi -Dokumentation
