
Sind Sie bereit, die Leistungsfähigkeit der Browserautomatisierung mit Pyppeteer zu erkunden? Dann legen wir los!
TL;DR: Pyppeteer-Übersicht
Für alle, die sich ein wenig mit Web Scraping oder der Automatisierung von Aufgaben in Python auskennen, ist Pyppeteer ein großartiges Tool zum Verwalten von Webbrowsern, ohne sie sehen zu müssen (Headless-Browser).
So beginnen Sie mit Pyppeteer für das Web Scraping:
- Installieren Sie Pyppeteer:
- Stellen Sie zunächst sicher, dass Python und Pip installiert sind. Sie können dies überprüfen, indem Sie Folgendes ausführen:
python --versionUndpip --version- Verwenden Sie pip, um Pyppeteer zu installieren:
pip install pyppeteer- Richten Sie Ihren Scraper ein:
- Importieren
pyppeteerund andere benötigte Bibliotheken wieBeautifulSoup- Schreiben Sie eine asynchrone Funktion, um einen Browser zu öffnen, eine Website aufzurufen und den Inhalt der Website abzurufen
- Eine Website scrapen:
- Öffnen Sie mit Pyppeteer einen Browser und rufen Sie die Website auf, die Sie scrapen möchten.
- Greifen Sie auf das HTML der Seite zu und verwenden Sie BeautifulSoup, um die benötigten Daten abzurufen, wie den Seitentitel
Hier ist ein einfacher Codeausschnitt, der Pyppeteer und BeautifulSoup verwendet, um den Titel einer Seite zu extrahieren:
import asyncio from pyppeteer import launch from bs4 import BeautifulSoup async def main(): browser = await launch() page = await browser.newPage() await page.goto('https://books.toscrape.com/') html = await page.content() await browser.close() soup = BeautifulSoup(html, 'html.parser') title = soup.find('h1').text print('Title:', title) title = asyncio.get_event_loop().run_until_complete(main())Dieser Code initiiert eine Headless-Browsersitzung, navigiert zu https://books.toscrape.com/ruft den Seiteninhalt ab und extrahiert den Webseitentitel mit BeautifulSoup.
Um diesen Snippet in Ihrem Scraping-Projekt zu verwenden, aktualisieren Sie einfach die URL und die Elemente, die Sie entsprechend Ihren Scraping-Anforderungen extrahieren möchten.
Möchten Sie mehr über das Scraping mit Pyppeteer erfahren? Weiterlesen!
Pyppeteer: Pyppeteer mit Python verwenden
So installieren Sie Pyppeteer
Die Installation von Pyppeteer ist ein unkomplizierter Vorgang, den Sie mit dem Paketmanager von Python in nur wenigen Schritten abschließen können. pip.
Befolgen Sie diese Anweisungen, um Pyppeteer auf Ihrem Computer zum Laufen zu bringen:
-
Stellen Sie sicher, dass Python und Pip installiert sind: Pyppeteer erfordert Python. Sie können überprüfen, ob Python und Pip installiert sind, indem Sie die folgenden Befehle in Ihrem Terminal (Linux oder macOS) oder in der Eingabeaufforderung (Windows) ausführen:
Für Python:
Für Pip:
Wenn diese Befehle keine Versionsnummern zurückgeben, müssen Sie Python installieren, was Sie hier installieren können. Stellen Sie sicher
pipwird zusammen mit Python installiert. -
Installieren Sie Pyppeteer: Führen Sie den folgenden Befehl aus, um Pyppeteer zu installieren:
Dieser Befehl lädt Pyppeteer und alle seine Abhängigkeiten herunter und installiert sie.
Erstellen wir nun ein Skript, das Pyppeteer mit BeautifulSoup kombiniert, um eine Webseite zu öffnen, Inhalte zu scrapen und zu analysieren.
Schritt 1: Erforderliche Bibliotheken importieren
Nach der Installation von pyppeteer importieren wir einige wichtige Bibliotheken in unser Skript. Wir werden Folgendes einbinden: asyncio zur Handhabung asynchroner Aufgaben, pyppeteer für die Browsersteuerung und BeautifulSoup von dem bs4 Paket zum Parsen von HTML-Inhalten.
import asyncio
from pyppeteer import launch
from bs4 import BeautifulSoup
Schritt 2: Definieren Sie die asynchrone Web Scraping-Funktion
Als nächstes definieren wir eine asynchrone Funktion namens main() das wird unser Scraping übernehmen:
async def main():
# Start the browser and open a new page
browser = await launch()
page = await browser.newPage()
await page.goto('https://books.toscrape.com/') # Enter the URL of the website you want to scrape
# Retrieve HTML and close the browser
html = await page.content()
await browser.close()
# Use BeautifulSoup to parse HTML
soup = BeautifulSoup(html, "html.parser")
title = soup.find('h1').text # Extract the text of the first
Lassen Sie uns aufschlüsseln, wie es funktioniert:
Schritt 3: Ausführen der Funktion und Drucken der Ergebnisse
Um das Ergebnis unserer Scraping-Bemühungen zu sehen, führen wir die Hauptfunktion aus mit asyncio's Ereignisschleife, die die Ausführung der asynchronen Funktionen übernimmt:
title = asyncio.get_event_loop().run_until_complete(main())
print('Title:', title)
Notiz: Wenn Sie Pyppeteer zum ersten Mal verwenden, muss möglicherweise Chromium (ca. 150 MB) heruntergeladen werden, falls es nicht bereits auf Ihrem System installiert ist. Diese Ersteinrichtung kann Ihr Skript leicht verzögern.
Um Chromium vorab manuell herunterzuladen und die Wartezeit beim ersten Durchlauf zu vermeiden, führen Sie diese Anweisung in Ihrer Eingabeaufforderung oder Ihrem Terminal aus:
Dieser Befehl stellt sicher, dass Chromium auf Ihrem Computer bereit ist, und erleichtert die Ausführung Ihres Skripts, wenn Sie es ausführen möchten.
Sie können es von hier aus manuell installieren, wenn bei Ihrem Chromium-Download ein Fehler auftritt, direkt mit pyppeteer.
Nach der Installation fügen Sie den Pfad zu Ihrem Chromium.exe wenn Sie den Browser folgendermaßen starten:
browser = await launch(executablePath='/path/to/your/chromium')
Pyppeteer-Spickzettel
In diesem Abschnitt erkunden wir verschiedene Aktionen, die Sie mit Pyppeteer durchführen können, komplett mit gebrauchsfertigen Codeausschnitten, die Ihnen helfen, diese Funktionen reibungslos in Ihre Projekte zu integrieren.
So warten Sie mit Pyppeteer, bis die Seite geladen ist
Für effektives Web Scraping oder Browserautomatisierung mit Pyppeteer muss möglicherweise sichergestellt werden, dass der gesamte Seiteninhalt geladen wurde, bevor Sie fortfahren. Hier sind einige praktische Methoden, um dies zu erreichen:
1. Warten Sie eine bestimmte Zeit
Um Ihr Skript für eine bestimmte Zeit anzuhalten, verwenden Sie die page.waitFor() Funktion. Zum Beispiel das Hinzufügen page.waitFor(5000) lässt das Skript 5 Sekunden warten, bevor es fortfährt.
So verwenden Sie es:
await page.goto('https://books.toscrape.com/')
await page.waitFor(5000) # Wait for 5000 milliseconds (5 seconds)
2. Warten Sie auf einen bestimmten Selektor
Eine andere Methode besteht darin, zu warten, bis ein bestimmtes Seitenelement sichtbar wird, bevor fortgefahren wird.
Dies können Sie tun, indem Sie waitForSelector() Funktion. In diesem Beispiel sagen wir dem Browser, er soll warten, bis ein Element mit dem .thumbnail Klasse erscheint, bevor irgendetwas anderes getan wird.
So können Sie es verwenden:
await page.goto('https://books.toscrape.com/')
await page.waitForSelector('.thumbnail')
So erstellen Sie Screenshots mit Pyppeteer
Das Aufnehmen von Screenshots ist eine leistungsstarke Funktion in Pyppeteer, die zum Debuggen, Archivieren von Snapshots von Webseiten oder Überprüfen von UI-Elementen verwendet werden kann.
Um die gesamte Seitenlänge zu erfassen, wie sie im Ansichtsfenster angezeigt wird, verwenden Sie die screenshot() Methode.
- Navigieren Sie zunächst zu Ihrer Zielwebseite mit dem
goto()Methode - Nachdem Sie die Seite erreicht haben, erstellen Sie einen Screenshot mit dem
screenshot()Funktion und geben Sie den Dateinamen an:
await page.goto('https://books.toscrape.com/')
await page.screenshot({'path': 'example.png'})
Der Screenshot wird in Ihrem Projektordner gespeichert. Er erfasst den sichtbaren Bereich der Seite entsprechend den Standardeinstellungen des Ansichtsfensters.
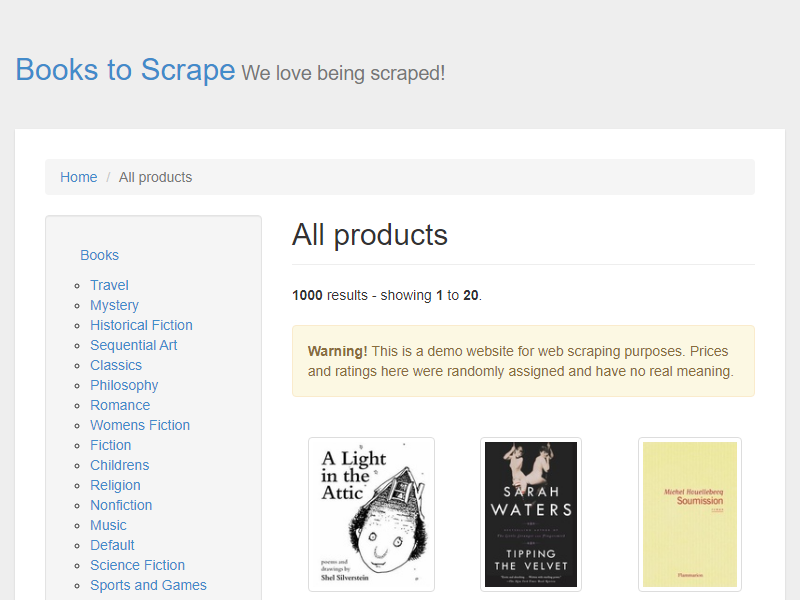
Um einen Screenshot mit bestimmten Abmessungen aufzunehmen, können Sie den Ansichtsbereich festlegen, bevor Sie zur Seite navigieren, indem Sie den setViewport() Methode:
await page.setViewport({"width": 1400, "height": 1200})
await page.goto('https://books.toscrape.com/')
await page.screenshot({'path': 'example.png'})
Der Screenshot wird mit den von Ihnen angegebenen Abmessungen erstellt.
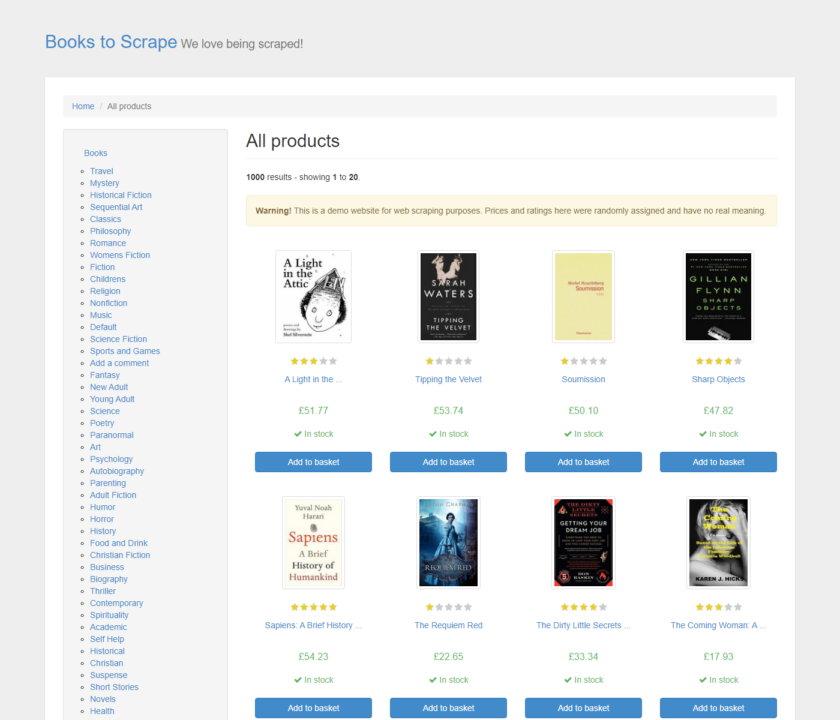
Für einen Screenshot der gesamten Seite, der unabhängig vom aktuellen Ansichtsfenster vom oberen bis zum unteren Rand der Seite erfasst, setzen Sie fullPage auf true, nachdem Sie den Pfad des Bildes im screenshot() Methode:
await page.goto('https://books.toscrape.com/')
await page.screenshot({'path': 'example.png', 'fullPage':True})
So klicken Sie mit Pyppeteer auf Schaltflächen
Mit Pyppeteer ist das Klicken auf eine Schaltfläche oder ein anderes interaktives Element auf einer Webseite unkompliziert.
Zuerst müssen Sie das Element anhand seines Selektors identifizieren und Pyppeteer dann anweisen, darauf zu klicken. In unserem Beispiel möchten wir auf den Link zum Buch „A Light in the Attic“ auf der Website „Books to Scrape“ klicken.
Wir können das genaue Element finden und die href Attribut, das wir mithilfe der Entwicklertools identifizieren müssen.
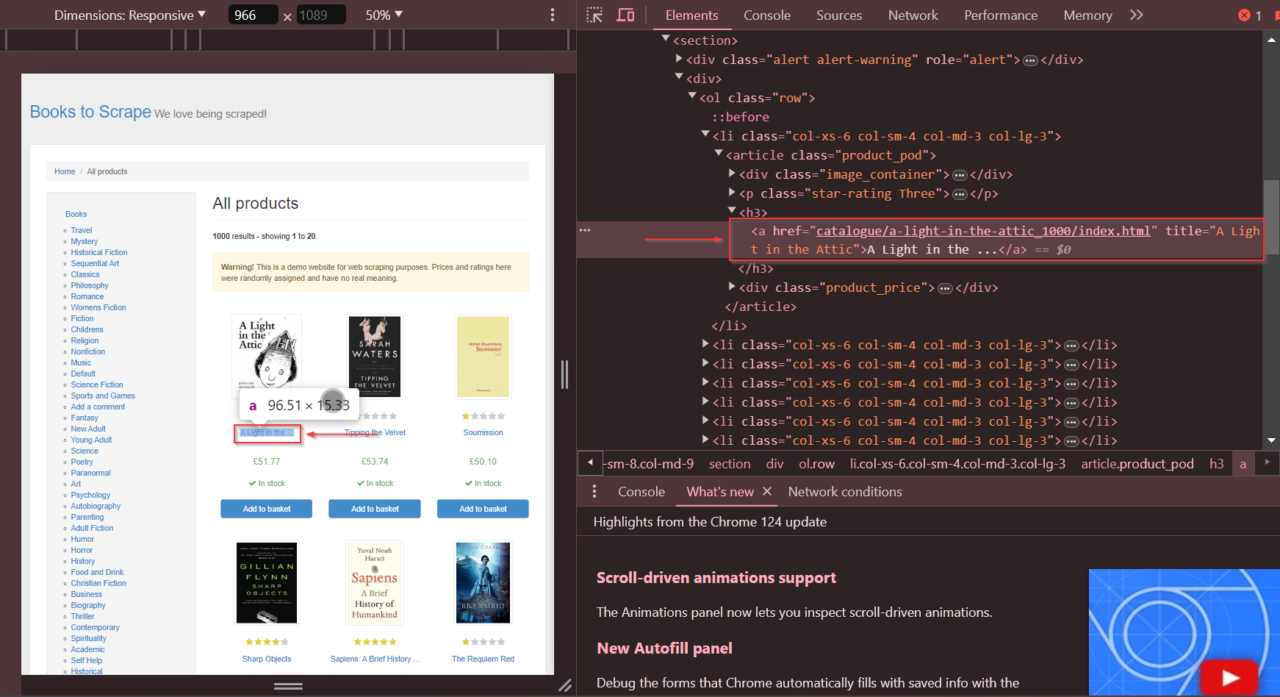
Nachdem wir nun das Element haben, verwenden wir die click() Funktion, um darauf zu klicken und verwenden Sie die waitForSelector() Funktion, um dem Browser mitzuteilen, dass er auf das Element warten soll, bevor wir darauf klicken.
import asyncio
from pyppeteer import launch
async def click_link():
browser = await launch(headless=False) # Launches a visible browser for demonstration
page = await browser.newPage()
# Navigate to the webpage
await page.goto('https://books.toscrape.com/')
# Wait for the link to be clickable and click it
await page.waitForSelector('a(href="catalogue/a-light-in-the-attic_1000/index.html")')
await page.click('a(href="catalogue/a-light-in-the-attic_1000/index.html")')
Nachdem Sie auf den Link geklickt haben, navigiert das Skript zur Detailseite des Buchs.
Um zu bestätigen, dass die Navigation erfolgreich war und der Klick zur richtigen Seite geführt hat, machen wir einen Screenshot der Seite.
# Wait for the page to load fully
await page.waitFor(10000) # Wait for 10 seconds to ensure the page has fully loaded
await page.setViewport({"width": 1400, "height": 1200}) # Set the dimensions for the screenshot
await page.screenshot({'path': 'example.png'}) # Save the screenshot
await browser.close() # Close the browser after the screenshot
asyncio.get_event_loop().run_until_complete(click_link())
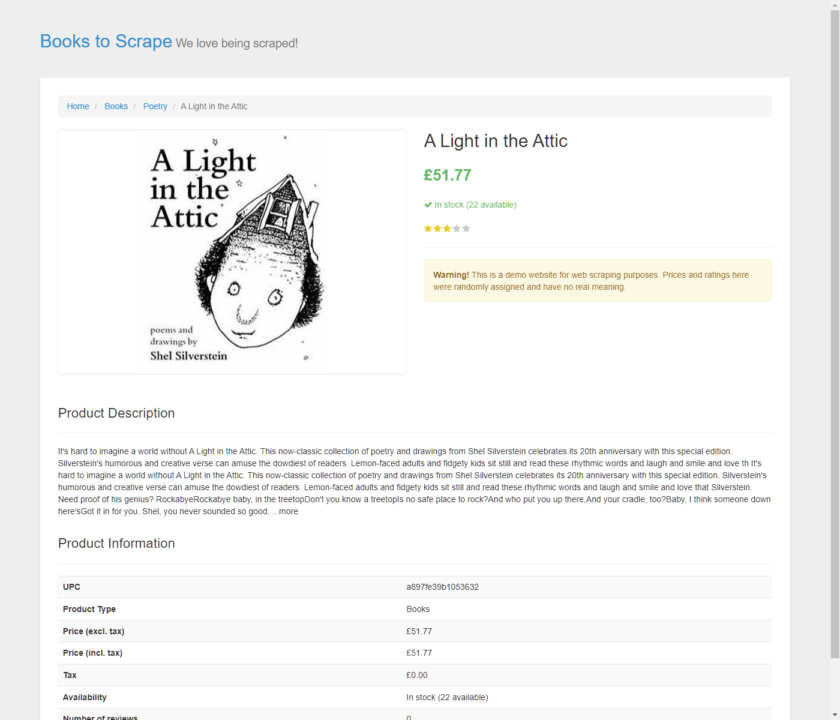
Und es hat funktioniert!
Hier ist der Screenshot gespeichert als beispiel.png. Es zeigt die Detailseite von „A Light in the Attic“ und bestätigt, dass unser Skript erfolgreich ausgeführt wurde.
So scrollen Sie mit Pyppeteer durch eine Webseite
Das automatische Scrollen durch Seiten ist unerlässlich, wenn Sie mit Websites arbeiten, deren Inhalt dynamisch geladen wird, während Sie nach unten scrollen. Pyppeteer macht dies einfach, indem es seine evaluate() Funktion, um Python-Code direkt im Browserkontext auszuführen. Hier ist ein einfaches Beispiel:
import asyncio
from pyppeteer import launch
async def simple_scroll():
browser = await launch(headless=False) # Launches a browser with a visible UI
page = await browser.newPage()
await page.setViewport({'width': 1280, 'height': 720}) # Sets the size of the viewport
await page.goto('https://books.toscrape.com') # Navigate to the website
# Scroll to the bottom of the page
await page.evaluate('window.scrollBy(0, document.body.scrollHeight);')
# Wait for additional content to load
await page.waitFor(5000)
await browser.close()
asyncio.get_event_loop().run_until_complete(simple_scroll())
Dieses Pyppeteer-Skript navigiert zur Webseite und scrollt nach unten mit window.scrollBy()wartet einige Sekunden, um sicherzustellen, dass alle dynamischen Inhalte geladen wurden, und schließt dann den Browser.
So verwenden Sie einen Proxy mit Pyppeteer
Beim Scraping von Websites ist die Verwendung von Proxys unerlässlich, um eine Blockierung durch die Zielseiten zu vermeiden. Wenn Sie regelmäßig eine große Anzahl von Anfragen von derselben IP-Adresse senden, kann dies dazu führen, dass Ihre IP blockiert wird.
Proxys sind Vermittler zwischen Ihrem Scraper und der Website. Sie stellen Ihren Anfragen unterschiedliche IP-Adressen zur Verfügung. Dadurch werden Ihre Scraping-Aktivitäten maskiert, sodass es so aussieht, als kämen sie von mehreren Benutzern und nicht von einer einzigen Quelle.
Ressource: Wenn Sie mehr über Proxys und ihre Funktionsweise erfahren möchten, lesen Sie diesen Artikel zur Verwendung und Rotation von Proxys in Python.
Um einen Proxy mit Pyppeteer zu verwenden, können Sie ihn beim Starten des Browsers angeben.
So können Sie vorgehen und die Authentifizierung durchführen, falls Ihr Proxy dies erfordert:
import asyncio
from pyppeteer import launch
async def use_proxy():
browser = await launch({
'args': ('--proxy-server=your_proxy_address:port')
})
page = await browser.newPage()
await page.authenticate({'username': 'your_username', 'password': 'your_password'})
await page.goto('https://books.toscrape.com')
await browser.close()
asyncio.get_event_loop().run_until_complete(use_proxy())
Wenn Ihr Proxy geschützt ist, verwenden Sie die authenticate() Methode, um die erforderlichen Anmeldeinformationen bereitzustellen.
So integrieren Sie ScraperAPI mit Pyppeteer
Pyppeteer bewältigt die Browserautomatisierung zwar hervorragend, verwaltet jedoch keine Proxys direkt. ScraperAPI füllt diese Lücke, indem es eine robuste Proxyverwaltung bereitstellt, die für die Umgehung von IP-basierten Blockierungen und Ratenbegrenzungen durch Zielwebsites unerlässlich ist.
Darüber hinaus kann ScraperAPI Seiten mit großem JavaScript-Aufwand rendern, wodurch die Komplexität Ihrer Skripte reduziert und die Erfolgsquote beim Scraping dynamischer Inhalte verbessert wird.
Indem Sie die Proxy-Verwaltung und das CAPTCHA-Lösen ScraperAPI überlassen, werden Ihre Scraping-Skripte einfacher und konzentrieren sich mehr auf die Datenextraktionslogik als auf die Navigation durch Anti-Scraping-Maßnahmen.
So können Sie ScraperAPI in Ihre Pyppeteer-Skripte integrieren:
Schritt 1: Einrichten Ihres Browsers mit ScraperAPI
Zuerst müssen wir Pyppeteer so konfigurieren, dass ScraperAPI als Proxy verwendet wird. Dadurch werden nicht nur unsere Verbindungen über verschiedene IPs verwaltet, sondern auch potenzielle Websicherheitsmaßnahmen behandelt, die unser Scraping blockieren oder verlangsamen könnten:
browser = await launch({
'ignoreHTTPSErrors': True,
'args': ('--proxy-server=proxy-server.scraperapi.com:8001'),
})
Dieses Proxy-Setup leitet den gesamten Browserverkehr über ScraperAPI und nutzt dessen Fähigkeit, Site-Einschränkungen und Ratenbegrenzungen zu umgehen. Wir weisen den Browser außerdem an, alle HTTPS-Fehler zu ignorieren, um Unterbrechungen aufgrund von SSL/TLS-Problemen zu vermeiden.
Hinweis: Ausführlichere Informationen finden Sie in der ScraperAPI-Dokumentation.
Schritt 2: Authentifizierung mit ScraperAPI
Authentifizieren Sie sich anschließend mit ScraperAPI, um sicherzustellen, dass Ihre Anfragen richtig erkannt und verwaltet werden:
await page.authenticate({
'username': 'scraperapi',
'password': 'YOUR_SCRAPERAPI_KEY' # Use your actual ScraperAPI key here
})
Notiz: Benötigen Sie einen Scraper-API-Schlüssel? Erstellen Sie ein kostenloses ScraperAPI-Konto, um einen API-Schlüssel und 5.000 API-Credits zu erhalten.
Schritt 3: Navigieren Sie zu Ihrer Zielwebsite
Leiten wir nun unseren Browser zu der Website weiter, von der wir Daten extrahieren möchten:
await page.goto(target_url)
content = await page.content()
print(content)
Hier ist der vollständige Code:
import asyncio
from pyppeteer import launch
async def scrape_with_scraperapi():
target_url = 'https://example.com'
browser = await launch({
'ignoreHTTPSErrors': True,
'args': (
'--proxy-server=proxy-server.scraperapi.com:8001',
)
})
page = await browser.newPage()
await page.authenticate({
'username': 'scraperapi',
'password': 'YOUR_SCRAPERAPI_KEY'
})
await page.goto(target_url)
content = await page.content()
print(content)
await browser.close()
asyncio.get_event_loop().run_until_complete(scrape_with_scraperapi())
Durch die Integration von ScraperAPI in Ihre Pyppeteer-Scraping-Projekte können Sie komplexere Scraping-Aufgaben problemlos bewältigen. Es erweitert die Fähigkeiten Ihrer Skripte, indem es Proxys verwaltet und CAPTCHAs automatisch löst, sodass Sie Ihre Projekte skalieren oder datenintensivere Aufgaben bewältigen können.
Lerne weiter
Herzlichen Glückwunsch, Sie haben gerade Ihren ersten Pyppeteer-Schaber gebaut!
Mit dem, was Sie heute gelernt haben, und dem Proxy-Modus von ScraperAPI können Sie dynamische Websites in großem Umfang und mit hoher Erfolgsquote scrapen und so einen konsistenten Datenstrom erstellen.
Natürlich können Sie auch die JS-Rendering-Funktion von ScraperAPI verwenden, um die Komplexität Ihres Codes zu reduzieren. Auf diese Weise können Sie nachträglich gerenderte HTML-Seiten herunterladen und viel einfacher auf dynamische Inhalte zugreifen.
Möchten Sie mehr über Web Scraping erfahren? Besuchen Sie unseren Blog zum projektbasierten Lernen oder sehen Sie sich hier einige unserer Lieblingsprojekte an:
Bis zum nächsten Mal, viel Spaß beim Scrapen!
