
Beim Web Scraping geht es um mehr als nur das Abrufen von HTML-Code. Sie sollten den Code auch verarbeiten, und Python bietet für diese Aufgabe mehrere Bibliotheken an. Eine der beliebtesten und anfängerfreundlichsten Optionen ist Beautiful Soup.
Die Einfachheit dieser Bibliothek macht sie zu einer beliebten Wahl für Neueinsteiger. Dieser Artikel enthält eine detaillierte Anleitung zur Verwendung für die Seitenanalyse sowie mögliche Herausforderungen und Problemumgehungen.
Erste Schritte mit Beautiful Soup
Bevor Sie beginnen, stellen Sie sicher, dass Sie Python 3.9 oder höher installiert und eine Entwicklungsumgebung eingerichtet haben. Wir empfehlen außerdem die Einrichtung einer virtuellen Umgebung, um einen sicheren Entwicklungsprozess zu gewährleisten.
Wenn Sie neu in der Python-Programmierung sind, auf Installationsprobleme stoßen oder Hilfe beim Einrichten einer virtuellen Umgebung benötigen, finden Sie detaillierte Anweisungen in unserem Einführungsartikel zu Python.
Installieren Sie Beautiful Soup
BeautifulSoup, auch bekannt als bs4, ist eine beliebte Python-Bibliothek für Web-Scraping. Es ermöglicht Ihnen, HTML-Seiten einfach zu analysieren und verschiedene Elemente aus ihrer Struktur zu extrahieren.
Um es zu installieren, verwenden wir den Paketmanager und führen je nach Betriebssystem den folgenden Befehl im Terminal oder in der Befehlszeile aus:
pip install bs4Importieren Sie nach der Installation bs4 in Ihre Python-Skripte und beginnen Sie mit dem Web-Scraping.
Die Grundstruktur von HTML-Seiten
Bevor Sie Daten einer HTML-Seite analysieren, ist es wichtig, deren Grundstruktur zu verstehen. HTML besteht aus Tags, von denen jedes eine bestimmte Rolle hat. Beispielsweise hat jede Seite einen
, der den Seitentitel, Stile und Skripte enthält, und einen , der den sichtbaren Inhalt enthält.Um die Struktur besser zu verstehen, visualisieren wir sie:
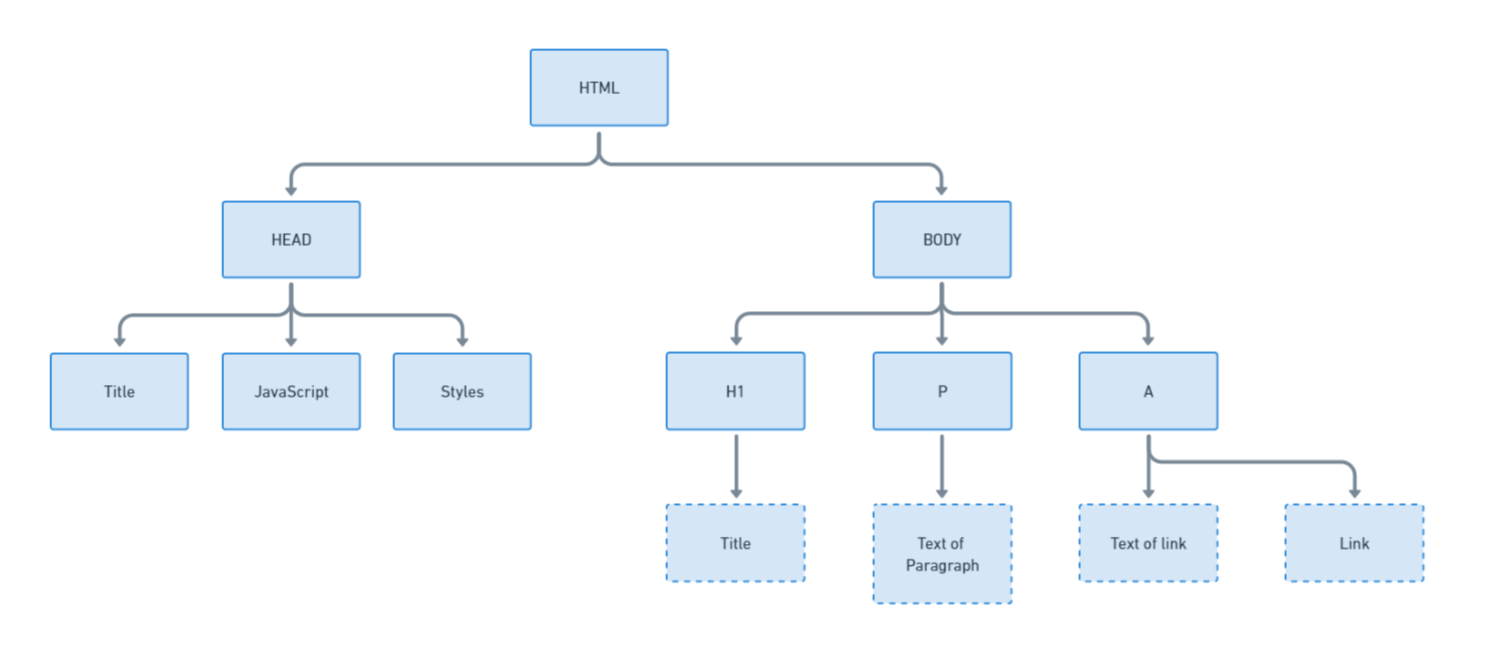
Das Verständnis der Struktur hilft dabei, die Daten zu identifizieren, die Sie extrahieren möchten. Beispielsweise werden Links normalerweise in -Tags gespeichert, während einfacher Text in
-Tags gespeichert wird. Betrachten wir den HTML-Code von example.com, wobei einige Stile der Kürze halber entfernt wurden:
<html><head>
<title>Example Domain</title>
<meta charset="utf-8">
<meta http-equiv="Content-type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
<style>.reset-css {
border: 0;
line-height: 1.5;
margin: 0;
padding: 0;
width: auto;
height: auto;
font-size: 100%;
border-collapse: separate;
border-spacing: 0;
text-align: left;
vertical-align: middle;
}
</style></head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
<div id="wt-sky-root"></div></body></html>Jede Seite ist einzigartig und verfügt über einen eigenen Satz HTML-Tags. Das bedeutet, dass es kein einheitliches Skript zum Parsen von Daten aus HTML-Seiten gibt. Stattdessen müssen Sie die spezifischen Tags auf jeder Seite identifizieren, die Ihre gewünschten Daten enthalten.
Dazu können Sie die DevTools in Ihrem Browser verwenden. Öffnen Sie DevTools, indem Sie F12 drücken oder mit der rechten Maustaste auf die Seite klicken und „Inspizieren“ auswählen. Navigieren Sie dann zur Registerkarte „Elemente“, um den HTML-Code anzuzeigen.
Holen Sie sich einen HTML-Code aus einer Datei oder Website
Wie bereits erwähnt, ist Beautiful Soup eine Python-Bibliothek zum Parsen von HTML-Dokumenten. Es eignet sich nicht zum Web-Scraping oder zum Senden von HTTP-Anfragen, hilft Ihnen jedoch beim Parsen bestimmter HTML-Elemente.
Bevor Sie BeautifulSoup verwenden können, müssen Sie den HTML-Code erhalten, den Sie analysieren möchten. Hier sind zwei gängige Möglichkeiten, dies zu tun: aus einer HTML-Datei und einer Webseite. Nehmen wir an, dass wir im selben Ordner wie unser Skript eine Datei index.html haben, die den HTML-Code einer Seite speichert. Dann können wir den folgenden Code verwenden, um es zu erhalten:
with open('index.html', 'r') as file:
html_code = file.read()Wenn Sie Daten von einer Seite und nicht von einer HTML-Datei erhalten möchten, sollten Sie eine zusätzliche Bibliothek verwenden, die Anfragen stellen kann. Sie können jede Ihnen vertraute Bibliothek verwenden, z. B. „requests“, „urllib“ oder „http.client“. Betrachten wir die Requests-Bibliothek als Beispiel:
import requests
response = requests.get('https://example.com')
html_code = response.textJetzt enthält die Variable html_code den gesamten HTML-Code der Seite und wir können ihn mithilfe der bs4-Bibliothek analysieren.
Analysieren Sie HTML-Code mit Beautiful Soup
Jetzt müssen wir ein Suppenobjekt erstellen, das das HTML-Dokument darstellt, mit dem wir interagieren können. Wir importieren die Bibliothek in unser Projekt und erstellen ein Suppenobjekt mit dem angegebenen Parser. In unserem Fall ist es der HTML-Parser:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_code, 'html.parser')Danach können wir auf dieses Objekt zugreifen, um die erforderlichen Daten zu extrahieren.
Finden Sie HTML-Elemente
Beautiful Soup bietet verschiedene Methoden zum Suchen und Bearbeiten von Elementen in einem HTML-Dokument. Nachfolgend sind die wichtigsten Methoden aufgeführt:
| Methode | Beschreibung |
|---|---|
| find(name, attrs, rekursiv, string, **kwargs) | Suchen Sie das erste Element, das den angegebenen Parametern entspricht. |
| find_all(name, attrs, rekursiv, string, limit, **kwargs) | Finden Sie alle Elemente, die den angegebenen Parametern entsprechen. |
| find_next(name, attrs, string, **kwargs) | Suchen Sie das nächste Element nach dem angegebenen Element. |
| find_all_next(name, attrs, string, limit, **kwargs) | Finden Sie alle Elemente nach dem angegebenen Element. |
| find_ previous(name, attrs, string, **kwargs) | Suchen Sie das vorherige Element vor dem angegebenen Element. |
| find_all_ previous(name, attrs, string, limit, **kwargs) | Findet alle Elemente vor dem angegebenen Element. |
| find_parent(name, attrs, string, **kwargs) | Suchen Sie das übergeordnete Element des angegebenen Elements. |
| find_all_parents(name, attrs, string, limit, **kwargs) | Finden Sie alle übergeordneten Elemente des angegebenen Elements. |
| find_next_sibling(name, attrs, string, **kwargs) | Suchen Sie das nächste gleichgeordnete Element des angegebenen Elements. |
| find_all_next_siblings(name, attrs, string, limit, **kwargs) | Finden Sie alle nächsten gleichgeordneten Elemente des angegebenen Elements. |
| find_ previous_sibling(name, attrs, string, **kwargs) | Suchen Sie das vorherige Geschwisterelement des angegebenen Elements. |
| find_all_ previous_siblings(name, attrs, string, limit, **kwargs) | Finden Sie alle vorherigen Geschwisterelemente des angegebenen Elements. |
| select(selector, recursive=True, limit=None, **kwargs) | Suchen Sie Elemente mithilfe von CSS-Selektoren. |
Die vollständige Liste der Methoden finden Sie in der offiziellen Dokumentation. In diesem Abschnitt werden wir mehrere Beispiele für die Verwendung dieser Methoden zur Suche nach den erforderlichen Elementen anhand verschiedener Parameter diskutieren.
Nach HTML-Tag-Namen
Beautiful Soup erleichtert das Auffinden von Elementen auf einer Seite anhand ihres HTML-Tags. Wenn wir beispielsweise wissen, dass alle Links in -Tags eingeschlossen sind, können wir die Methode find_all() verwenden, um alle -Tags auf einer Seite zu finden:
all_a_tags = soup.find_all('a')Dadurch wird eine Liste aller gefundenen -Tags zurückgegeben. Wir können find() auch verwenden, um nur das erste passende HTML-Tag zu erhalten:
first_a_tags = soup.find('a')Es ist wichtig zu beachten, dass die Suche für den gesamten HTML-Code der Seite durchgeführt wird, nicht nur für den auf dem Bildschirm angezeigten Teil. Das bedeutet, dass sich das erste -Tag normalerweise im -Tag und nicht im -Tag befindet. Es ist wichtig, dies beim Parsen zu berücksichtigen.
Nach Ausweis
Manchmal werden Elementen eindeutige Bezeichner, IDs, zugewiesen, die das Objekt eindeutig identifizieren. Auf einer Seite kann es nur ein Element mit einer solchen ID geben, daher ist die Suche nach ID recht zuverlässig.
element_by_id = soup.find(id='example_id')Die ID wird als Attribut der HTML-Tags angegeben.
Nach Klassennamen
Klassen sind eine weitere praktische Möglichkeit, Elemente zu beschreiben. Sie sind für Website-Entwickler praktisch, da sie für jede Klasse einen eigenen Stilsatz erstellen können, der leicht zugewiesen werden kann. Klassen eignen sich also auch gut zum Parsen.
elements_by_class = soup.find_all(class_='example_class')Manchmal ist die Suche nach Klassen die bequemste und sogar einzige Möglichkeit, Elemente auf einer Seite zu finden.
Verwendung von CSS-Selektoren
Beautiful Soup unterstützt auch die Elementsuche mithilfe von CSS-Selektoren und bietet so einen recht flexiblen Ansatz. Betrachten wir zum Beispiel die Suche nach allen Elementen mit dem Tag , die sich innerhalb eines Elements mit der Klasse „container“ befinden:
selected_elements = soup.select('.container a')Die Verwendung von CSS-Selektoren macht BeautifulSoup zu einem wirklich praktischen Tool. Und wenn Sie sie noch nicht verwendet haben, können Sie in unserem anderen Artikel mehr über CSS-Selektoren und deren Verwendung erfahren.
Die Auswahl des entsprechenden Elements reicht nicht aus, um die erforderlichen Daten zu erhalten. Zunächst müssen Sie feststellen, ob Sie den Text des Elements oder den Inhalt seines Attributs benötigen. Abhängig davon unterscheidet sich die Datenextraktion. In diesem Abschnitt werden wir beide Optionen betrachten.
Wie bereits erwähnt, befindet sich der Text auf einer Seite normalerweise im
-Tag. Extrahieren wir daher als Beispiel den Text aus einem solchen Element:
paragraph_text = soup.find('p').textWenn Sie den Text aus allen Elementen mit dem Tag
extrahieren möchten, müssen Sie bedenken, dass die Methode find_all eine Liste und kein Element zurückgibt. Um den Inhalt des Tags zu extrahieren, müssen Sie daher alle Elemente der Liste durchlaufen und den Text einzeln extrahieren:
all_paragraphs = soup.find_all('p')
all_paragraph_texts = (paragraph.text for paragraph in all_paragraphs)Mit diesem Code können Sie den Inhalt aller Elemente mit dem
-Tag auf der Seite extrahieren.
Ein weiterer häufiger Anwendungsfall ist das Extrahieren von Links. Allerdings werden Links nicht im Tag selbst gespeichert, sondern in einem Attribut des Tags, zum Beispiel:
<a href="https://www.iana.org/domains/example">More information...</a>Wir können jedoch das Attribut angeben, dessen Inhalt wir bei der Suche nach einem Element zurückgeben möchten:
link_href = soup.find('a')('href')Jetzt extrahieren wir alle Links auf der Seite:
all_links = soup.find_all('a')
all_link_hrefs = (link('href') for link in all_links)Auf diese Weise können Sie Informationen aus absolut jedem Tag oder seinem Attribut extrahieren. Das Wichtigste ist, darauf zu achten, ob Sie ein Element oder eine Liste erhalten. Abhängig davon wird sich die Bearbeitung unterscheiden.
Fortgeschrittene Techniken
Zu diesem Zeitpunkt haben wir bereits die wichtigsten Methoden der bs4-Bibliothek behandelt, und sie werden ausreichen, um die meisten Probleme zu lösen. Wir möchten jedoch auch einige zusätzliche Tricks verraten, die bei der Arbeit an bestimmten Projekten nützlich sein können.
Navigieren Sie zwischen Elementen
Manchmal ist es einfacher, ein Element anhand seiner Geschwister oder Eltern zu finden als anhand eines einzelnen Elements. Angenommen, Sie können das benötigte Element nicht direkt finden, können aber sein vorheriges Geschwisterelement leicht identifizieren:
current_element = soup.find(id='example_id')Suchen Sie dann das nächste
-Element nach current_element:
next_element = current_element.find_next_sibling('p')Sie können auch das vorherige Geschwister finden:
prev_element = current_element.find_previous_sibling('p')Sie können ähnliche Methoden verwenden, um übergeordnete und untergeordnete Elemente zu finden.
Umgang mit verschachtelten Elementen
Beautiful Soup bietet jedoch eine prägnantere Möglichkeit, untergeordnete Elemente zu navigieren: die Punktnotation. Dadurch können Sie direkt von einem übergeordneten Element aus auf verschachtelte Elemente zugreifen.
Suchen wir zum Beispiel nach einem übergeordneten div-Element:
outer_div = soup.find('div')Greifen Sie dann direkt auf ein beliebiges untergeordnetes Element zu:
inner_paragraph = outer_div.pDies kann für die Arbeit mit verschachtelten Strukturen praktischer sein.
Filterelemente
Sie können BeautifulSoup verwenden, um Elemente zu finden und zu filtern, wenn Sie bestimmte Daten aus einer Webseite extrahieren. Dies ist nützlich, wenn Sie bestimmte Informationen extrahieren, unerwünschte Elemente entfernen oder die Daten organisieren. Suchen wir zum Beispiel alle
-Tags und filtern sie nach Textinhalt:
filtered_elements = soup.find_all('p', text="desired_text")Nach dem gleichen Prinzip können Sie den Inhalt beliebiger Tags und Elemente filtern.
Während die meisten Textinhalte in
-Tags gespeichert werden, gibt es Fälle, in denen Sie den gesamten Text einer Seite unabhängig vom Container-Tag extrahieren müssen. Dazu können Sie die Methode get_text() für das gesamte BeautifulSoup-Objekt verwenden:
all_text = soup.get_text()Dieser Code gibt den gesamten Text einer beliebigen Seite zurück, unabhängig von der Tag-Struktur.
Machen Sie die HTML-Formatierung hübsch
Obwohl diese Aufgabe selten vorkommt, kann es vorkommen, dass Sie eine Möglichkeit benötigen, Ihren HTML-Code hübsch zu gestalten. Sie können dies mit der folgenden Methode tun:
pretty_html = soup.prettify()Dadurch werden Ihrem HTML-Code die erforderlichen Einrückungen und Zeilenumbrüche hinzugefügt.
Herausforderungen bewältigen
Bei der Verarbeitung von HTML-Code mit der BeautifulSoup-Bibliothek können einige Schwierigkeiten auftreten. In diesem Abschnitt erfahren Sie, wie Sie diese überwinden können.
Fehlender oder defekter HTML-Code
Websites können unvollständiges oder fehlerhaftes HTML enthalten. BeautifulSoup ist für den Umgang mit solch „schmutzigem“ HTML konzipiert und wird sein Bestes tun, um es zu interpretieren und Zugriff auf die Daten zu ermöglichen. Beispielsweise wird der folgende unvollständige HTML-Code korrekt analysiert:
incomplete_html="<p>This is a paragraph"
soup = BeautifulSoup(incomplete_html, 'html.parser')Wie die Praxis zeigt, meistert BeautifulSoup solche Probleme recht gut.
Fehlerbedingungen
Wie jeder Code kann BeautifulSoup bei der Datenverarbeitung Fehler verursachen. Wenn Sie beispielsweise versuchen, ein nicht vorhandenes Element zu finden, gibt BeautifulSoup None zurück. Die weitere Verarbeitung dieses Elements führt zu einer Ausnahme. Um dies zu vermeiden, verwenden Sie try/exclusive-Blöcke oder bedingte Prüfungen, um fehlende Daten zu verarbeiten.
Dynamischer Inhalt
Beautiful Soup analysiert nur HTML und ruft es nicht ab. Sie benötigen ein separates Tool, um den HTML-Code abzurufen und dynamische Webseiten zu verarbeiten. Anschließend können Sie BeautifulSoup oder das ausgewählte Tool verwenden, um die erforderlichen Elemente zu extrahieren.
Beliebte Tools zum Umgang mit dynamischen Seiten sind Selenium und Pyppeteer. Sie können sie verwenden, um den HTML-Code zu erhalten:
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get('https://example.com')
dynamic_content = driver.page_source
soup = BeautifulSoup(dynamic_content, 'html.parser')Da diese Tools jedoch über eigene Parsing-Methoden verfügen, ist die Verwendung von BeautifulSoup möglicherweise überflüssig.
Abschluss
Beautiful Soup ist eine der beliebtesten und benutzerfreundlichsten Web-Scraping-Bibliotheken. Es ist leicht zu erlernen, auch für Benutzer ohne umfassende Webtechnologien oder Programmierkenntnisse. Es bietet eine Vielzahl von Methoden zum Suchen, Navigieren und Extrahieren von Daten aus HTML. Seine flexiblen Filter- und Navigationsfunktionen eignen sich für verschiedene Web-Scraping-Szenarien.
Allerdings weist es, wie jedes andere Tool auch, einige Einschränkungen auf. Es unterstützt keine asynchronen Anforderungen, was bei der Arbeit mit großen Datenmengen oder dynamischen Inhalten ein Nachteil sein kann. Darüber hinaus führt es kein JavaScript aus, sodass für Webseiten, auf denen Inhalte mit JavaScript generiert werden, möglicherweise andere Tools wie Selenium erforderlich sind.
Wie im Artikel erwähnt, wurde diese Bibliothek zum Parsen entwickelt und führt HTTP-Anfragen nicht unabhängig aus. Daher sind zum Herunterladen von Webseiten zusätzliche Bibliotheken wie Requests erforderlich.
Insgesamt ist BS4 ein leistungsstarkes und praktisches Tool zum Web-Scraping. Allerdings hat sie wie jede Technologie ihre eigenen Stärken und Grenzen. Die Wahl der Verwendung hängt von den spezifischen Anforderungen der Aufgabe und den Vorlieben des Entwicklers ab.
