
Was ist PerimeterX (jetzt Human Security)?
PerimeterX ist ein Cybersicherheitsunternehmen, das Tools zum Schutz von Webanwendungen vor automatisierten Angriffen, betrügerischen Aktivitäten und Web Scraping bereitstellt. Mithilfe fortschrittlicher Algorithmen für maschinelles Lernen und Risikobewertungen analysiert PerimeterX Anfragefingerabdrücke und Verhaltenssignale, um Bot-Angriffe in Echtzeit zu erkennen und zu blockieren.
Eine seiner wichtigsten Abwehrmaßnahmen, der HUMAN Bot Defender (ehemals PerimeterX Bot Defender), zielt direkt auf das Scraping von Bots ab. Er sitzt direkt auf einer Website und überwacht und sammelt Informationen aus eingehenden Webanforderungen. Diese Anforderungen werden dann nach vordefinierten Regeln analysiert und später, wenn sie als verdächtig eingestuft werden, entsprechend reagiert.
Zwar lässt PerimeterX die Durchfahrt einiger legitimer Bots, beispielsweise des Googlebot, zu, doch bleibt es eine gewaltige Barriere gegen unbefugtes Web Scraping und andere automatisierte Aktivitäten.
PerimeterX erkennen
Um die Präsenz von PerimeterX auf einer Website zu identifizieren, achten Sie auf diese Merkmale:
Notiz:
Sind Sie frustriert, weil Ihre Web Scraper immer wieder blockiert werden? ScraperAPI kümmert sich für Sie um rotierende Proxys und Headless-Browser. Probieren Sie es KOSTENLOS aus!
Beliebte PerimeterX-Fehler
Wenn PerimeterX feststellt, dass es sich bei einem Besucher um einen automatisierten Scraper oder Bot handelt, wird der Zugriff blockiert und eine 403-Forbidden-Antwort zusammen mit gebrandeten Blockseiten ausgegeben. Diese Antworten stammen vom PerimeterX-Sensor, der in die Infrastruktur der Site integriert ist.
Hier sind einige häufige PerimeterX-Fehlermeldungen, die auftreten können:
| Nachricht oder Code | Bedeutung |
| 403 Verboten | PerimeterX hat Ihre Anfrage als möglicherweise automatisiert gekennzeichnet. |
| „Bitte beweisen Sie, dass Sie ein Mensch sind“ |
Diese Meldung wird angezeigt, wenn der JavaScript-Browsertest fehlschlägt, und fordert den Benutzer auf, zu bestätigen, dass er ein Mensch ist. |
| „Cookies aktivieren“ | Unregelmäßiger oder fehlender Cookie-Header |
| „Versuchen Sie es später noch einmal“ | Vorübergehende Sperrung aufgrund verdächtiger Aktivitätsmuster |
| APTCHA-Herausforderung |
Ausgelöst durch fehlgeschlagene Fingerabdruck- und Verhaltensprüfungen, die eine zusätzliche Überprüfung erfordern, um fortzufahren. |
Denken Sie daran, dass das Blockierungsverhalten von PerimeterX dynamisch ist und sich im Laufe der Zeit ändern kann. Seien Sie immer bereit, Ihre Scraping-Techniken anzupassen, wenn Sie auf neue Arten von Blockierungen oder Herausforderungen stoßen.
Wie erkennt PerimeterX Bots?
Sie erkennen PerimeterX an den Meldungen „Gedrückt halten“ und „Bitte bestätigen Sie, dass Sie ein Mensch sind“, die der Abbildung unten ähneln:
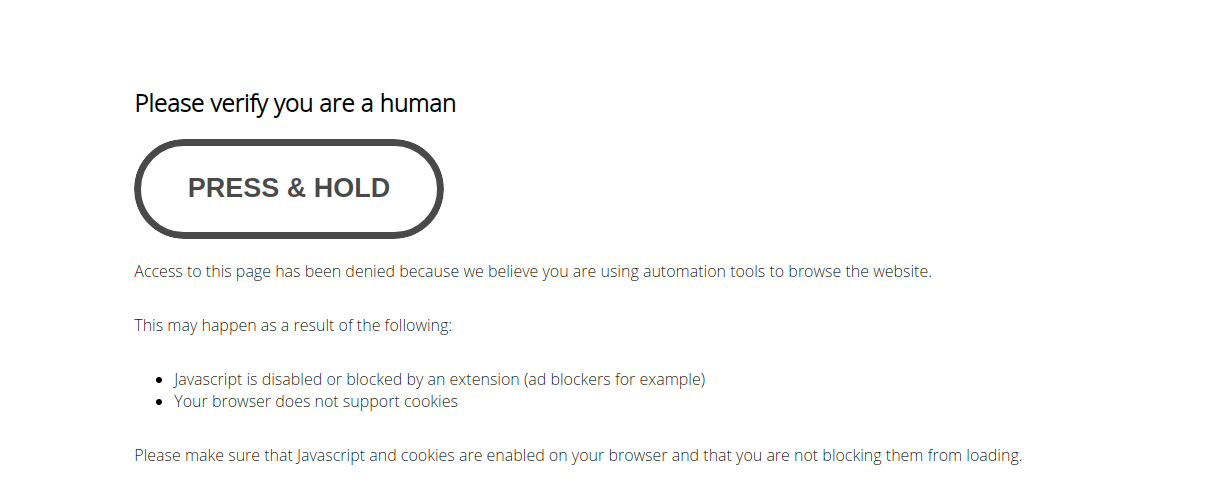
Um Anti-Web-Scraping-Dienste wie PerimeterX zu vermeiden, sollten wir zunächst verstehen, wie sie funktionieren. Im Wesentlichen läuft es auf drei Erkennungskategorien hinaus:
- IP-Adresse
- Javascript-Fingerabdruck
- Anfragedetails
Dienste wie PerimeterX verwenden diese Tools, um für jeden Besucher einen Vertrauenswert zu berechnen. Ein niedriger Wert bedeutet, dass Sie höchstwahrscheinlich ein Bot sind. Sie müssen also entweder eine CAPTCHA-Aufgabe lösen oder der Zugriff wird Ihnen vollständig verweigert. Wie erreichen wir also einen hohen Wert?
IP-Adressen / Proxys
PerimeterX analysiert IP-Adressen, um verdächtige Aktivitäten zu identifizieren. Idealerweise möchten wir unsere Last über Proxys verteilen. Diese Proxys können Datacenter-, Residential- oder Mobile-Proxys sein.
Um einen hohen Vertrauenswert aufrechtzuerhalten, sollte Ihr Scraper einen Pool von Residential- oder mobilen Proxys durchlaufen. Weitere Informationen finden Sie in unserem Blogbeitrag darüber, was Residential-Proxys sind und warum sie zum Scraping verwendet werden sollten.
Javascript-Fingerabdrücke
Dieses Thema ist ziemlich umfangreich, insbesondere für Juniorentwickler, aber hier ist eine kurze Zusammenfassung.
Websites können Javascript verwenden, um den Verbindungsclient (den Scraper) zu fingerprinten, da Javascript Daten über den Client preisgibt, darunter das Betriebssystem, unterstützte Schriftarten, visuelle Rendering-Funktionen usw.
Wenn PerimeterX beispielsweise eine große Anzahl von Linux-Clients erkennt, die sich über Fenster mit einer Auflösung von 1280 x 720 verbinden, kann es daraus einfach schlussfolgern, dass es sich bei dieser Art von Setup wahrscheinlich um einen Bot handelt, und gibt allen Benutzern mit diesen Fingerabdruckdetails niedrige Vertrauenswerte.
Wenn Sie Selenium verwenden, um PerimeterX zu umgehen, müssen Sie viele dieser Lecks patchen, um der Low Trust Zone zu entkommen. Sie können dies tun, indem Sie den Browser so ändern, dass er falsche Fingerabdruckdetails eingibt, oder indem Sie eine gepatchte Version des Headless-Browsers verwenden, wie „Selendraht.”
Weitere Informationen hierzu finden Sie in unserem Blog: 10 Tipps zum Web Scraping, ohne blockiert zu werden.
Anfragedetails
Bei ungewöhnlichen Verbindungsmustern kann uns PerimeterX immer noch niedrige Vertrauenswerte geben, selbst wenn wir über einen großen Pool an IP-Adressen verfügen und unseren Headless-Browser gepatcht haben, um zu verhindern, dass wichtige Fingerabdruckdetails durchsickern.
Es beobachtet verschiedene festgelegte Ereignisse, was darauf schließen lässt, dass es Verhaltensanalysen verwendet. Daher ist es wichtig, beim Scraping dieser Websites vorsichtig zu sein. Um dies zu vermeiden,
Ihr Schaber sollte in nicht offensichtlichen Mustern schaben. Es sollte auch ab und zu eine Verbindung zu Nicht-Zielseiten wie der Homepage der Website herstellen, um menschlicher zu wirken.
Nachdem wir nun wissen, wie unser Scraper erkannt wird, können wir untersuchen, wie wir diese Maßnahmen umgehen können. Selenium, Playwright und Puppeteer haben große Communities, und das Schlüsselwort, nach dem Sie hier suchen müssen, ist „Heimlichkeit.”
Leider ist dies nicht sehr narrensicher, da PerimeterX einfach öffentlich bekannte Patches sammeln und seinen Dienst entsprechend anpassen kann. Sie haben dies wahrscheinlich schon ein paar Mal erlebt, wenn Sie diese Methode manuell ausprobiert haben, was bedeutet, dass Sie viele Dinge selbst herausfinden müssen.
Eine bessere Alternative ist die Verwendung eines Web Scraping API um geschützte Websites einfach zu scrapen.
Umgehen von PerimeterX mit ScraperAPI
ScraperAPI hilft Ihnen, eine Sperrung Ihrer IP-Adresse zu vermeiden, indem es IP-Adressen rotiert, CAPTCHAs verarbeitet und Anforderungslimits verwaltet. Es vereinfacht den gesamten Scraping-Prozess, indem es zuverlässigen Zugriff auf Webseiten bietet und sicherstellt, dass Sie sich auf das Extrahieren und Analysieren von Daten konzentrieren können, anstatt Anti-Scraping-Maßnahmen zu ergreifen.
Die Verwendung von Python und ScraperAPI erleichtert das Scraping großer Datenmengen von PerimeterX-geschützten Websites erheblich.
In dieser Anleitung zeigen wir, wie man Produktinformationen von Neiman Marcus, einem bekannten Kaufhaus mit einer durch PerimeterX geschützten E-Commerce-Website, abruft.
Voraussetzungen
Um dieser Anleitung folgen zu können, stellen Sie sicher, dass Sie die folgenden Voraussetzungen erfüllt haben:
Schritt 1: Richten Sie Ihre Umgebung ein
Lassen Sie uns zunächst eine virtuelle Umgebung einrichten, um Konflikte mit vorhandenen Python-Modulen oder -Bibliotheken zu vermeiden.
Für macOS-Benutzer:
pip install virtualenv
python3 -m virtualenv venv
source venv/bin/activate
Für Windows-Benutzer:
pip install virtualenv
virtualenv venv
srouce venv\Scripts\activate
Sobald Ihre virtuelle Umgebung aktiviert ist, installieren Sie die erforderlichen Bibliotheken:
pip install requests beautifulsoup4 lxml
Schritt 2: Analysieren Sie die Zielwebsite
Unsere Zielwebsite ist Neiman Marcus, ein bekanntes Kaufhaus mit einer E-Commerce-Website, auf der wir versuchen werden, Produktpreise abzukratzen.
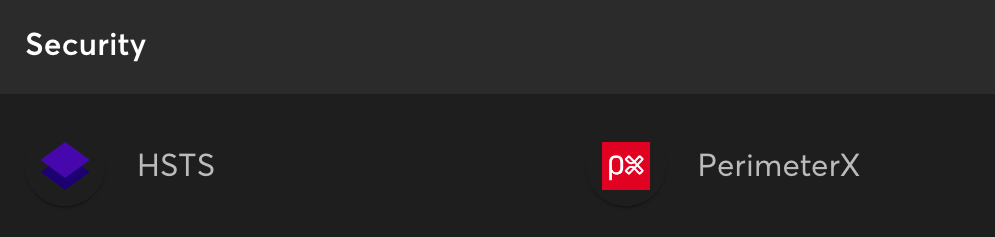
Mit Tools wie Wappalyzer können wir bestätigen, dass PerimeterX Neiman Marcus schützt. Um den Schutz zu umgehen, müssen wir jedoch ScraperAPI verwenden.
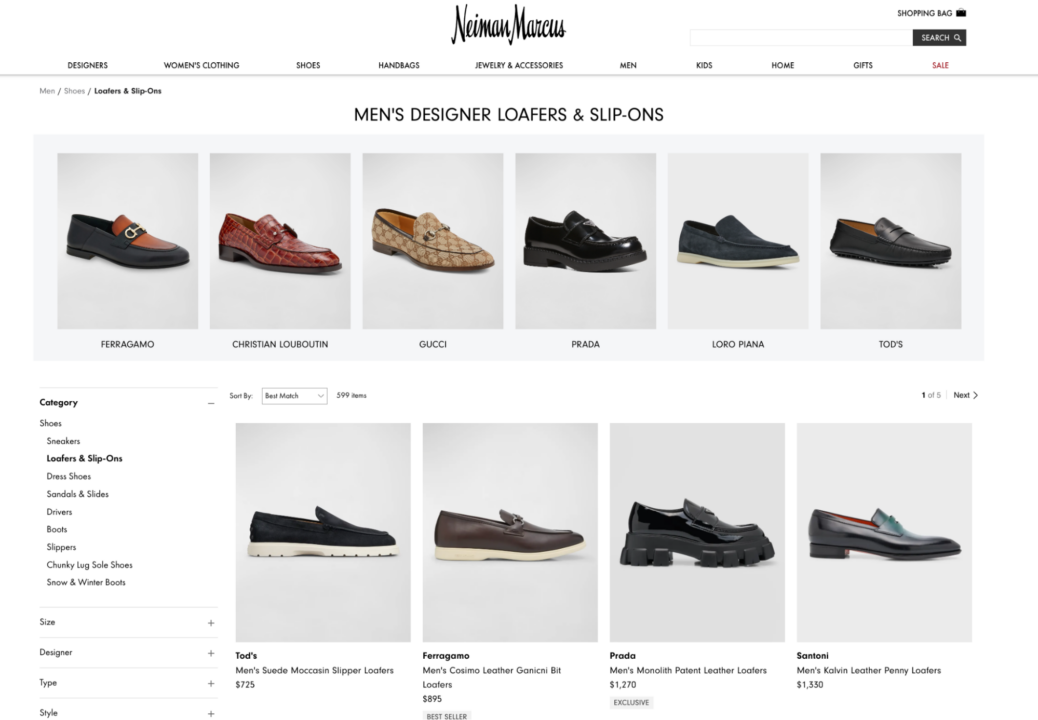
Wir konzentrieren uns auf das Scraping von Produktinformationen von der Kategorieseite für Herren-Loafer.
Schritt 3: ScraperAPI einrichten
Erstellen Sie zunächst ein kostenloses ScraperAPI-Konto und kopieren Sie Ihren API-Schlüssel von Ihrem Dashboard.
Schritt 4: Schreiben Sie das Scraping-Skript
Erstellen wir nun ein Python-Skript, das ScraperAPI verwendet, um PerimeterX zu umgehen und Produktinformationen abzugreifen:
import requests
from bs4 import BeautifulSoup
import json
API_KEY = "YOUR_API_KEY"
url = "https://www.neimanmarcus.com/en-ng/c/shoes-shoes-loafers-slip-ons-cat10580739?navpath=cat000000_cat000470_cat000550_cat10580739"
payload = {"api_key": API_KEY, "url": url, "render": "true"}
def scrape_product_info():
response = requests.get("http://api.scraperapi.com", params=payload)
if response.status_code != 200:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
return ()
soup = BeautifulSoup(response.text, 'lxml')
products = soup.find_all('div', class_='product-thumbnail__details')
product_info = ()
for product in products:
designer = product.find('span', class_='designer')
name = product.find('span', class_='name')
price = product.find('span', class_='price-no-promo')
badge = product.find('div', class_='gift-badge')
info = {
'designer': designer.text.strip() if designer else 'N/A',
'name': name.text.strip() if name else 'N/A',
'price': price.text.strip() if price else 'N/A',
'batch_details': badge.text.strip() if badge else 'N/A'
}
product_info.append(info)
return product_info
def save_to_json(product_info, filename='neiman_marcus_loafers.json'):
with open(filename, 'w', encoding='utf-8') as jsonfile:
json.dump(product_info, jsonfile, ensure_ascii=False, indent=4)
if __name__ == "__main__":
print("Scraping product information...")
product_info = scrape_product_info()
if product_info:
print(f"Found {len(product_info)} products.")
save_to_json(product_info)
print("Product information saved to neiman_marcus_loafers.json")
else:
print("No products found or there was an error scraping the website.")
Notiz: Um dieses Beispiel auszuführen, ersetzen Sie
YOUR_API_KEY mit Ihrem aktuellen API-Schlüssel von Ihrem Dashboard.
Hier stellen wir eine Anfrage an ScraperAPI und übergeben unseren API-Schlüssel und die Ziel-URL. ScraperAPI kümmert sich um die Komplexität der Rotation von IP-Adressen, das Lösen von CAPTCHAs und die Verwaltung anderer Anti-Scraping-Maßnahmen von PerimeterX. Die
render=true Der Parameter innerhalb der Nutzlast weist ScraperAPI an, die Zielwebseite in einem Headless-Browser vollständig zu rendern und so sicherzustellen, dass alle durch PerimeterX geschützten dynamischen Inhalte vollständig geladen und zum Scraping verfügbar sind.
Sobald ScraperAPI den gerenderten HTML-Inhalt zurückgibt, verwenden wir
BeautifulSoup um es zu analysieren. Wir zielen auf bestimmte HTML-Elemente anhand ihrer Klassennamen (product-thumbnail__details,
designer, name, price-no-promo,
gift-badge), um die gewünschten Produktinformationen zu extrahieren.
Schritt 5: Führen Sie das Skript aus
Speichern Sie das Skript unter neiman_marcus_scraper.py und führen Sie es aus:
python neiman_marcus_scraper.py
Dieses Skript kratzt dann Produktinformationen von der Seite für Herren-Loafer von Neiman Marcus und umgeht dabei den PerimeterX-Schutz mithilfe von ScraperAPI. Die gescrapten Daten werden in einer JSON-Datei mit dem Namen gespeichert.
neiman_marcus_loafers.json.
(
{
"designer": "Tod's",
"name": "Men's Suede Moccasin Slipper Loafers",
"price": "$725",
"batch_details": "N/A"
},
{
"designer": "Ferragamo",
"name": "Men's Cosimo Leather Ganicni Bit Loafers",
"price": "$895",
"batch_details": "Best Seller"
},
{
"designer": "Prada",
"name": "Men's Monolith Patent Leather Loafers",
"price": "$1,270",
"batch_details": "Exclusive"
},
{
"designer": "Santoni",
"name": "Men's Kalvin Leather Penny Loafers",
"price": "$1,330",
"batch_details": "N/A"
},
Truncated data,
}
Herzlichen Glückwunsch, wenn Sie bis hierhin mitcodiert haben, haben Sie eine von Human Security geschützte Website erfolgreich umgangen! Dieser Ansatz kann auch angepasst werden, um andere von PerimeterX geschützte Websites zu durchsuchen.
Abschließende Gedanken
Es lässt sich nicht leugnen, dass PerimeterX (jetzt HUMAN Security) ein ausgeklügeltes Anti-Bot-System ist, das eine Reihe von Techniken einsetzt, um Websites vor unerwünschtem Scraping zu schützen. Von der Überwachung von IP-Adressen und der Analyse von Anforderungsheadern bis hin zur Verwendung verschiedener Fingerprinting-Methoden stellt PerimeterX eine gewaltige Herausforderung für Web Scraper dar.
Das Team von ScraperAPI aktualisiert ständig die API-Bypass-Methoden, um Ihre Scraper am Laufen zu halten. Dies macht dies zur besten Möglichkeit, Daten von durch PerimeterX geschützten Sites zu scrapen, ohne blockiert zu werden.
Wenn Sie erfahren möchten, wie Sie andere beliebte Websites scrapen, sehen Sie sich unsere anderen Scraping-Anleitungen an:
