
In diesem Artikel zeigen wir Ihnen eine einfache und effektive Möglichkeit, CAPTCHAs beim Scrapen von Amazon-Produktdaten zu umgehen und sich so einen Wettbewerbsvorteil in Ihrer Branche zu verschaffen.
Aber bevor wir uns mit dem Code befassen, müssen Sie zunächst verstehen, was sie sind.
Was sind CAPTCHAs?
CAPTCHA ist ein Akronym für Cvöllig Aautomatisiert Pöffentlich TWährend des Tests erfahren Sie es CComputer und Humans ATeil. Mit anderen Worten handelt es sich um einen Test, mit dem festgestellt werden soll, ob es sich bei einem Benutzer, der auf eine Website zugreift, um einen Menschen oder einen Bot handelt.
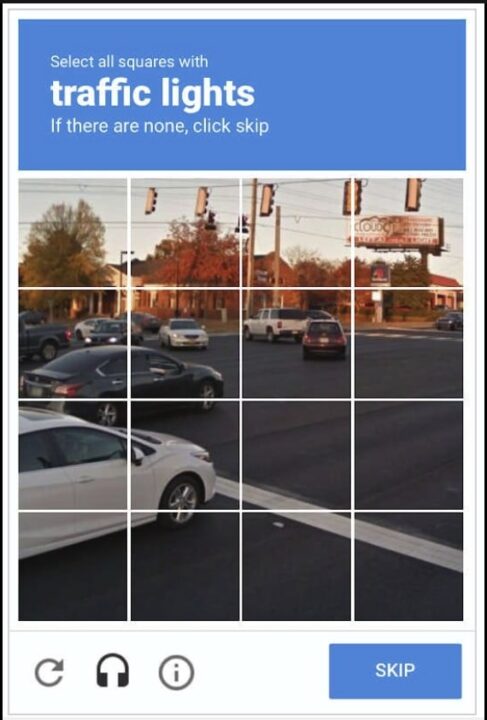
Das CAPTCHA schützt die Website vor Missbrauch, wie zum Beispiel:
- Spammen von Kommentarformularen, Kontaktformularen und Anmeldeseiten, um nur einige zu nennen
- Schädliche, nicht konforme Scraping-Bots
- Automatisierte Bots, die versuchen, gestohlene oder durchgesickerte Benutzernamen und Passwörter zu verwenden
- Automatisierter Warenkauf mithilfe gestohlener Kreditkarteninformationen
Und viele weitere „Blackhat“-Praktiken.
Die Effizienz des CAPTCHA-Tests ergibt sich aus der Tatsache, dass Herausforderungen für Menschen leicht und für Computer schwierig zu lösen sind. Einige Beispiele für CAPTCHA-Tests sind:
- Textbasiertes CAPTCHA: Identifizieren Sie gestreckten Text mit Buchstaben und Zahlen.
- Bildbasiertes CAPTCHA: Identifizieren Sie ähnliche Bilder in einem Bilderraster, indem Sie auf deren Position im Raster klicken.
- Audiobasiertes CAPTCHA: Hören Sie sich den Ton an und transkribieren Sie die Ausgabe in eine Texteingabe. Es ist hilfreich für Benutzer, die Schwierigkeiten mit visuellen Herausforderungen haben.
- Social-Media-Login: Dies kommt seltener vor, sie müssen sich jedoch mit einem ihrer Social-Media-Konten authentifizieren.
Wie CAPTCHAs Web Scraping verhindern
Web Scraping ist eine Datenerfassungstechnik, die darin besteht, automatisch Informationen von einer Website zu extrahieren.
Allerdings sind nicht alle Web Scraper gleich gebaut.
Da alternative Daten immer wertvoller werden, versuchen immer mehr Menschen, durch Automatisierung darauf zuzugreifen.
Das Problem besteht darin, dass Scraper in vielen Fällen nicht richtig konfiguriert sind und dadurch die Zielwebsites schädigen, indem sie beispielsweise den Server überlasten, sodass sie Anfragen von echten Benutzern nicht mehr bedienen können und dadurch das Endbenutzererlebnis beeinträchtigt wird.
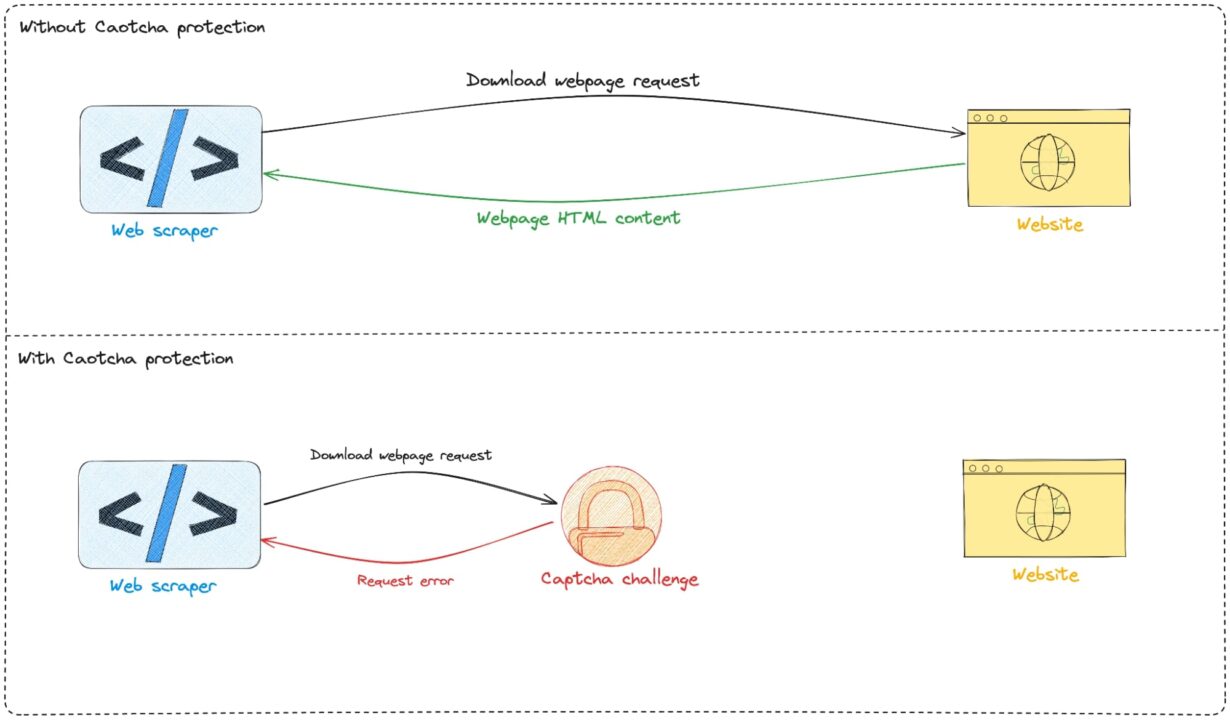
Um sich vor Bot-Missbrauch zu schützen, Viele Websites verlassen sich auf CAPTCHA-Tests, die für die meisten Bots schwer zu lösen sind, da sie eine menschliche Interaktion erfordern. Dies macht es Bots unmöglich, auf die Website zuzugreifen, da sie diese Herausforderungen nicht effektiv interpretieren und lösen können.
Wann werden CAPTCHA-Tests bei Amazon ausgelöst?
Hier sind einige Muster, die einen CAPTCHA-Test auslösen:
- Überdurchschnittlich hohe Klickrate
- Die verwendete IP-Adresse befindet sich in einer Datenbank mit IP-Adressen auf der schwarzen Liste
- Der Client lädt kein CSS, JavaScript oder Bilder
- Der Client lädt dieselben Seiten viele Male, ohne von Zeit zu Zeit zu anderen Seiten zu navigieren
- Der Client unternimmt innerhalb kurzer Zeit mehrere erfolglose Anmeldeversuche
- Hohe Anforderungshäufigkeit oder sehr konsistentes Anforderungsmuster (alle 10 Sekunden eine Anforderung unter Verwendung derselben IP)
Es gibt viele andere Möglichkeiten, wie Amazon feststellen kann, dass ein Bot auf seine Website zugreift – in den meisten Fällen können Sie ohne ordnungsgemäße IP-Rotation nicht einmal die erste erfolgreiche Anfrage erhalten.
Was sollten Sie also tun? Das Codieren eines Verhaltens für jedes potenzielle Szenario ist nicht nur zeitaufwändig, sondern nahezu unmöglich. Es ist nur eine Frage der Zeit, bis Ihre Schaber verstopfen.
Die gute Nachricht ist, dass Sie diese Lösung nicht von Grund auf neu erstellen müssen.
Amazon CAPTCHAs mit ScraperAPI verhindern
Da Amazon die meistbesuchte E-Commerce-Website der Welt ist und über eine große Produktdatenbank verfügt, verwendet es CAPTCHAs, um Bot-Aktivitäten und Daten-Web-Scraping zu verhindern.
Für Web Scraper ist es wichtig, den Amazon CAPTCHA-Test in angemessener Zeit zu lösen.
ScraperAPI hilft, indem es eine einfache, aber leistungsstarke API zur Umgehung von CAPTCHAs mit einer Erfolgsquote von nahezu 100 % bereitstellt und Ihnen in Sekundenschnelle Zugriff auf Daten ermöglicht.
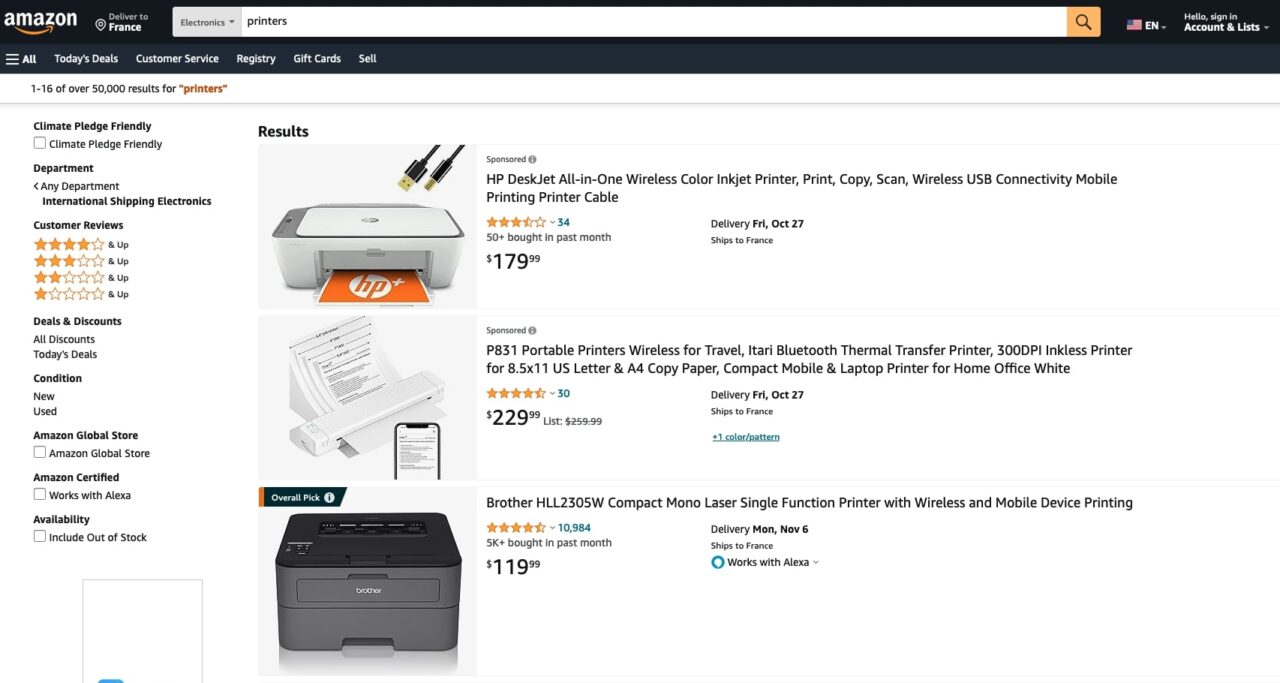
Für dieses Tutorial verwenden wir die Standard-API von ScraperAPI und Node.js, um die Seite unten zu scrapen.
Voraussetzungen
Um diesen Schritt ausführen zu können, müssen diese Tools auf Ihrem Computer installiert sein.
Richten Sie das Projekt ein
Lassen Sie uns den Ordner erstellen und ein neues Node.js-Projekt initialisieren.
mkdir amazon-captcha-bypass
cd amazon-captcha-bypass
npm init -y
touch index.js
Senden Sie Ihre Anfrage über ScraperAPI
Die ScraperAPI-Standard-API ist unter https://api.scraperapi.com zugänglich.
Um die Anfrage an die Standard-API zu senden, verwenden wir Axios, also installieren wir es zuerst:
Öffne das index.js Datei und fügen Sie den folgenden Code hinzu:
const axios = require('axios');
const AMAZON_PAGE_URL = 'https://www.amazon.com/s?crid=2S8Z5MXHF5A2&i=electronics-intl-ship&k=printers&ref=glow_cls&refresh=3&sprefix=printers%2Celectronics-intl-ship%2C174';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '6f18d81b608007cd8226b736c1f6b462' // <--- Enter your API key here
const webScraper = async () => {
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: AMAZON_PAGE_URL,
render: true,
});
try {
const response = await axios.get(`${API_URL}/?${queryParams.toString()}`);
const html = response.data;
console.log(html);
console.log("HTML content length: %d", html.length);
} catch (error) {
console.log(error.response.data)
}
};
void webScraper();
Notiz: Denken Sie daran, Ihren API-Schlüssel hinzuzufügen. Sie finden es in Ihrem ScraperAPI-Dashboard.
Führen Sie den Befehl aus node index.js um den Code auszuführen. Sie erhalten eine ähnliche Ausgabe wie die folgende:
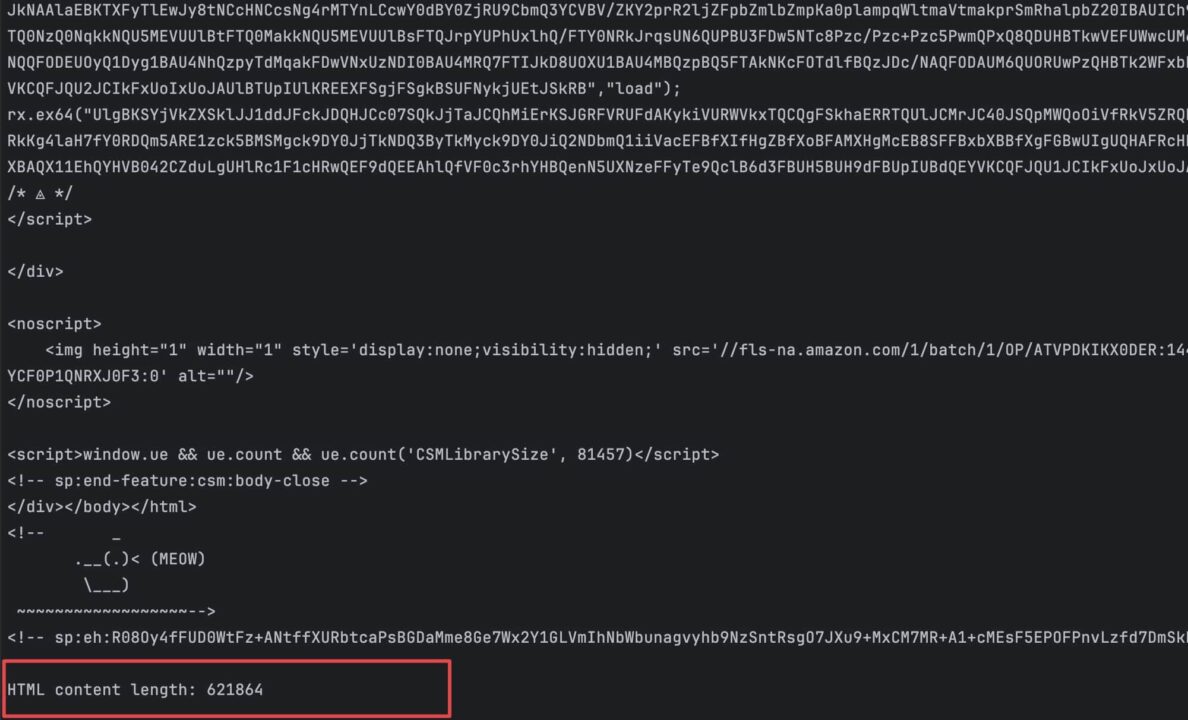
Wenn die API die Anfrage erhält, verwendet sie maschinelles Lernen und statistische Analysen, um die beste Kombination aus IPs und Headern zu ermitteln, um zu verhindern, dass der CAPTCHA-Test von Amazon ausgelöst wird.
Falls das Amazon-Produkt oder die Suchseite den CAPTCHA-Test sendet, generiert ScraperAPI eine neue Kombination aus IP-Adresse und Headern, um eine neue Anfrage zu stellen, und zwar so lange, bis sie erfolgreich ist oder die für die Ausführung festgelegte maximale Zeit erreicht.
