
In diesem Tutorial erstellen wir einen Walmart Web Scraper von Grund auf und zeigen Ihnen, wie Sie seine Anti-Bot-Erkennung einfach umgehen können, ohne seinen Server zu beschädigen.
TL;DR: Vollständiger Walmart Node.js Scraper
Für diejenigen, die es eilig haben, finden Sie hier den vollständigen Code in Node.js.
<pre class="wp-block-syntaxhighlighter-code">
const axios = require('axios');
const cheerio = require('cheerio');
const WALMART_PAGE_URL = 'https://walmart.com/search?q=computer+screen';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '<API_KEY>' // <--- Enter your API key here
const parseProductReview = (inputString) => {
const ratingRegex = /(\d+\.\d+)/;
const reviewCountRegex = /(\d+) reviews/;
const ratingMatch = inputString.match(ratingRegex);
const reviewCountMatch = inputString.match(reviewCountRegex);
const rating = ratingMatch?.length > 0 ? parseFloat(ratingMatch(0)) : null;
const reviewCount = reviewCountMatch?.length > 1 ? parseInt(reviewCountMatch(1)) : null;
return { rating, reviewCount };
};
const webScraper = async () => {
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: WALMART_PAGE_URL,
render: true,
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
const $ = cheerio.load(html);
const productList = ();
$("div(data-testid='list-view')").each((_, el) => {
co
nst link = $(el).prev('a').attr('href');
const price = $(el).find('.f2').text();
const priceCents = $(el).find('.f2 + span.f6').text();
const description = $(el).find("span(data-automation-id='product-title')").text();
const reviews = $(el).find('.w_iUH7').last().text();
const delivery = $(el).find("div(data-automation-id='fulfillment-badge')").find('span.b').last().text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
description,
price: `$${price}.${priceCents}`,
averageRating: rating,
totalReviews: reviewCount,
delivery,
link: `https://www.walmart.com${link}`
});
});
console.log(productList);
} catch (error) {
console.log(error.response.data)
}
};
void webScraper();
</pre>
Bevor Sie diesen Code ausführen, installieren Sie die Abhängigkeiten und legen Sie Ihren API-Schlüssel fest, den Sie im ScraperAPI-Dashboard finden – dies ist wichtig, da ScraperAPI es uns ermöglicht, Walmarts Anti-Bot-Mechanismen zu umgehen und seinen dynamischen Inhalt darzustellen.
Notiz: Die kostenlose Testversion beinhaltet 5.000 API-Credits und Zugriff auf alle ScraperAPI-Tools.
Möchten Sie die Details erfahren? Lasst uns mit dem Tutorial beginnen!
Scraping von Walmart-Produktdaten in Node.js
Um zu demonstrieren, wie man Walmart durchsucht, schreiben wir ein Skript, das Computerbildschirme bei Walmart findet.
Für jeden Computerbildschirm extrahieren wir Folgendes:
- Beschreibung
- Preis
- Durchschnittliche Bewertung
- Gesamtbewertungen
- Liefervoranschlag
- Produktlink
Das Skript exportiert die extrahierten Daten im JSON-Format, um die Verwendung für andere Zwecke zu erleichtern.
Voraussetzungen
Um diesem Tutorial folgen zu können, müssen diese Tools auf Ihrem Computer installiert sein.
Schritt 1: Richten Sie das Projekt ein
Erstellen wir einen Ordner mit dem Quellcode des Walmart-Scraper.
Geben Sie den Ordner ein und initialisieren Sie ein neues Node.js-Projekt
cd walmart-scraper
npm init -y
Der zweite Befehl oben erstellt eine package.json Datei im Ordner.
Als nächstes erstellen Sie eine Datei index.js und fügen Sie darin eine einfache JavaScript-Anweisung hinzu.
touch index.js
echo "console.log('Hello world!');" > index.js
Führen Sie die Datei aus index.js mit der Node.js-Laufzeitumgebung.
Bei dieser Ausführung wird a gedruckt Hello world! Nachricht an das Terminal.
Schritt 2: Installieren Sie die Abhängigkeiten
Um diesen Scraper zu erstellen, benötigen wir diese beiden Node.js-Pakete:
- Axios – um die HTTP-Anfrage zu erstellen (Header, Text, Parameter der Abfragezeichenfolge usw.), sie an die ScraperAPI-Standard-API zu senden und den HTML-Inhalt herunterzuladen
- Cheerio – um die Informationen aus dem HTML zu extrahieren, das von der Axios-Anfrage heruntergeladen wurde
Führen Sie den folgenden Befehl aus, um diese Pakete zu installieren:
npm install axios cheerio
Schritt 3: Identifizieren Sie die DOM-Selektoren, auf die Sie abzielen möchten
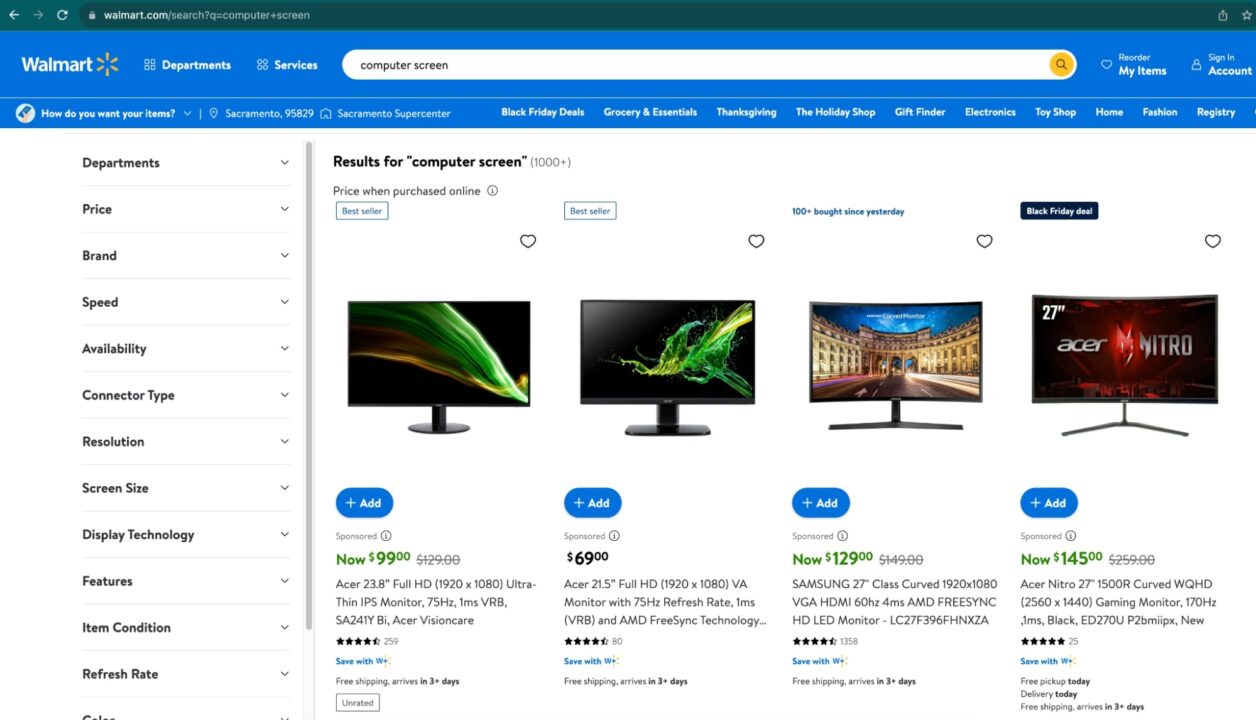
Navigieren Sie zu https://www.walmart.com; Typ „Computer-Bildschirm“ in der Suchleiste ein und drücken Sie die Eingabetaste.
Wenn das Suchergebnis angezeigt wird, überprüfen Sie die Seite, um die HTML-Struktur anzuzeigen und den DOM-Selektor zu identifizieren, der mit dem HTML-Tag verknüpft ist, der die Informationen umschließt, die wir extrahieren möchten.
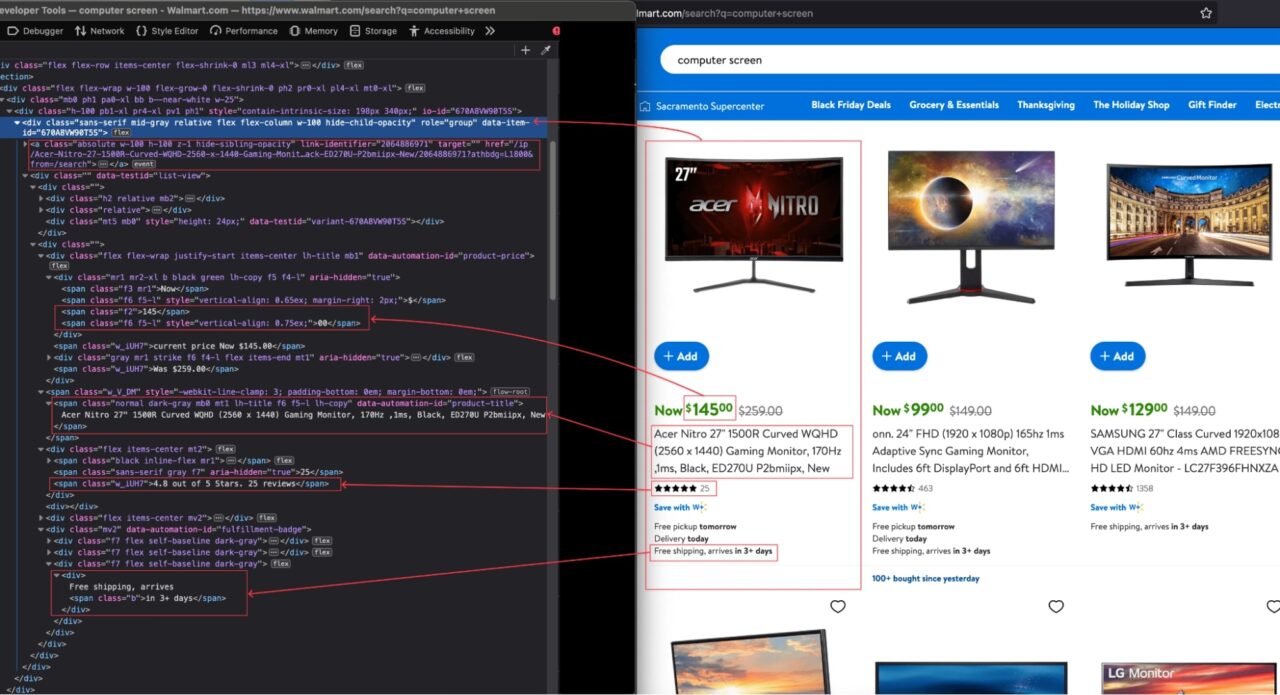
Im obigen Bild sind hier alle DOM-Selektoren aufgeführt, auf die der Web Scraper abzielt, um die Informationen zu extrahieren.
| Information | DOM-Selektor |
| Produktbeschreibung | span(data-automation-id=’product-title‘) |
| Preis | div(data-testid=’list-view‘) .f2 |
| Preis Cent | div(data-testid=’list-view‘) .f2 + span.f6 |
| Durchschnittliche Bewertung | div(data-testid=’list-view‘) span.w_V_DM + div.flex span.w_iUH7 |
| Gesamtbewertungen | div(data-testid=’list-view‘) span.w_V_DM + div.flex span.f7 |
| Liefervoranschlag | div(data-testid=’list-view‘) div(data-automation-id=’fulfillment-badge‘) div.f7:last-child span.b:last-child |
| Walmarts Link | div + a |
Seien Sie beim Schreiben des Selektors vorsichtig, da ein Rechtschreibfehler verhindert, dass das Skript den richtigen Wert abruft.
Notiz: Eine gute Methode, Fehler beim Erstellen Ihrer Selektoren zu vermeiden, besteht darin, sie zuerst mit jQuery auszuprobieren. Geben Sie in der Browserkonsole Ihren Selektor ein $(“span(data-automation-id=’product-title’)”) Wenn das richtige DOM-Element zurückgegeben wird, können Sie loslegen.
Schritt 4: Senden Sie die erste Anfrage an Walmart
Wie bereits erwähnt, verwenden wir die Standard-API von ScraperAPI, um die Anti-Bot-Erkennung von Walmart zu umgehen.
Um die Anfragen zu erstellen, verwenden wir Axios und übergeben die folgenden Parameter an die API:
- Die URL zum Scrapen: Dies ist die URL der Walmart-Produktsuchseite. Sie können es in die Adresszeile Ihres Browsers kopieren (in unserem Fall
https://walmart.com/search?q=computer+screen). - Der API-Schlüssel: um sich bei der Standard-API zu authentifizieren und das Scraping durchzuführen. Sie finden es auf Ihrem ScraperAPI-Dashboard.
- Aktivieren Sie Javascript: Die Website von Walmart basiert auf einem modernen Frontend-Framework, das JavaScript für eine bessere Interaktivität hinzufügt. Um JavaScript beim Scraping zu aktivieren, verwenden wir eine Eigenschaft mit dem Namen
`render`mit dem auf eingestellten Wert`true`.
Notiz: Durch die Aktivierung des JS-Renderings können wir den dynamischen Inhalt von Walmart extrahieren. Ohne sie würden wir eine leere Seite bekommen.
Bearbeiten Sie die index.js um den folgenden Code hinzuzufügen, der die HTTP-Anfrage erstellt, sendet, die Antwort empfängt und sie auf dem Terminal ausgibt.
<pre class="wp-block-syntaxhighlighter-code">
const axios = require('axios');
const WALMART_PAGE_URL = 'https://walmart.com/search?q=computer+screen';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '<API_KEY>' // <--- Enter your API key here
const webScraper = async () => {
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: WALMART_PAGE_URL,
render: true,
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
console.log("HTML content", html);
} catch (error) {
console.log(error.response.data)
}
};
void webScraper();
</pre>
Schritt 5: Informationen aus dem HTML extrahieren
Da wir nun den HTML-Inhalt der Seite haben, müssen wir ihn mit Cheerio analysieren, um darin navigieren und alle gewünschten Informationen extrahieren zu können.
Cheerio bietet Funktionen zum Laden von HTML-Text und zum anschließenden Navigieren durch die Struktur, um mithilfe der DOM-Selektoren Informationen zu extrahieren.
Der folgende Code geht jedes Element durch, extrahiert die Informationen und gibt ein Array zurück, das alle Bildschirme des Computers enthält.
const cheerio = require('cheerio');
const $ = cheerio.load(html);
const productList = ();
const parseProductReview = (inputString) => {
const ratingRegex = /(\d+\.\d+)/;
const reviewCountRegex = /(\d+) reviews/;
const ratingMatch = inputString.match(ratingRegex);
const reviewCountMatch = inputString.match(reviewCountRegex);
const rating = ratingMatch?.length > 0 ? parseFloat(ratingMatch(0)) : null;
const reviewCount = reviewCountMatch?.length > 1 ? parseInt(reviewCountMatch(1)) : null;
return { rating, reviewCount };
};
$("div(data-testid='list-view')").each((_, el) => {
const link = $(el).prev('a').attr('href');
const price = $(el).find('.f2').text();
const priceCents = $(el).find('.f2 + span.f6').text();
const description = $(el).find("span(data-automation-id='product-title')").text();
const reviews = $(el).find('.w_iUH7').last().text();
const delivery = $(el).find("div(data-automation-id='fulfillment-badge')").find('span.b').last().text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
description,
price: `$${price}.${priceCents}`,
averageRating: rating,
totalReviews: reviewCount,
delivery,
link: `https://www.walmart.com${link}`
});
});
console.log(productList);
Die Funktion parseProductionReview() extrahiert die durchschnittliche Bewertung und die Gesamtbewertung der Kunden zum Produkt.
Hier ist der vollständige Code des index.js Datei:
<pre class="wp-block-syntaxhighlighter-code">
const axios = require('axios');
const cheerio = require('cheerio');
const WALMART_PAGE_URL = 'https://walmart.com/search?q=computer+screen';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '<API_KEY>' // <--- Enter your API key here
const parseProductReview = (inputString) => {
const ratingRegex = /(\d+\.\d+)/;
const reviewCountRegex = /(\d+) reviews/;
const ratingMatch = inputString.match(ratingRegex);
const reviewCountMatch = inputString.match(reviewCountRegex);
const rating = ratingMatch?.length > 0 ? parseFloat(ratingMatch(0)) : null;
const reviewCount = reviewCountMatch?.length > 1 ? parseInt(reviewCountMatch(1)) : null;
return { rating, reviewCount };
};
const webScraper = async () => {
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: WALMART_PAGE_URL,
render: true,
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
const $ = cheerio.load(html);
const productList = ();
$("div(data-testid='list-view')").each((_, el) => {
co
nst link = $(el).prev('a').attr('href');
const price = $(el).find('.f2').text();
const priceCents = $(el).find('.f2 + span.f6').text();
const description = $(el).find("span(data-automation-id='product-title')").text();
const reviews = $(el).find('.w_iUH7').last().text();
const delivery = $(el).find("div(data-automation-id='fulfillment-badge')").find('span.b').last().text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
description,
price: `$${price}.${priceCents}`,
averageRating: rating,
totalReviews: reviewCount,
delivery,
link: `https://www.walmart.com${link}`
});
});
console.log(productList);
} catch (error) {
console.log(error.response.data)
}
};
void webScraper();
</pre>
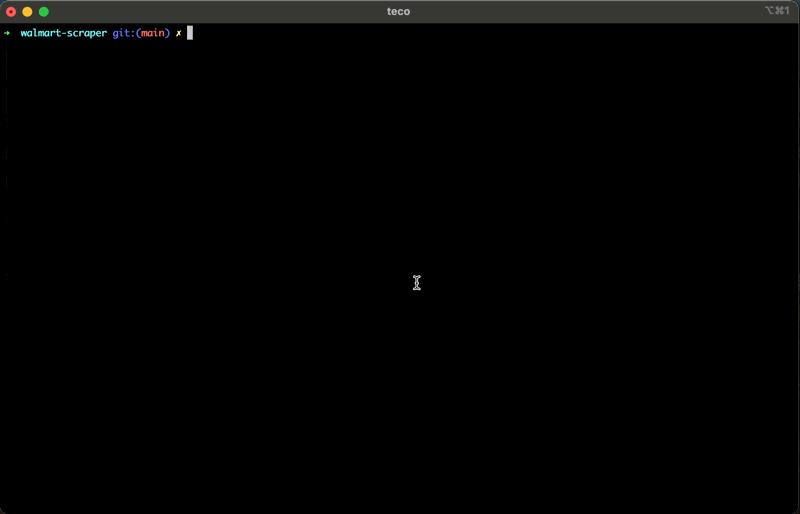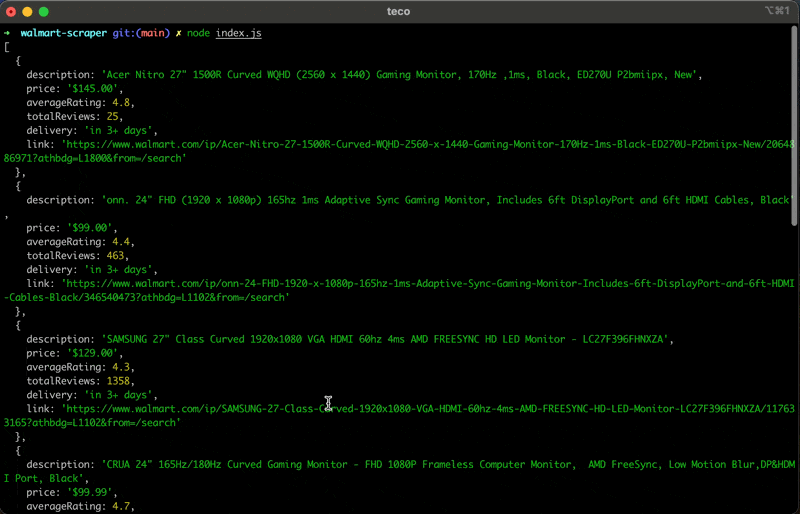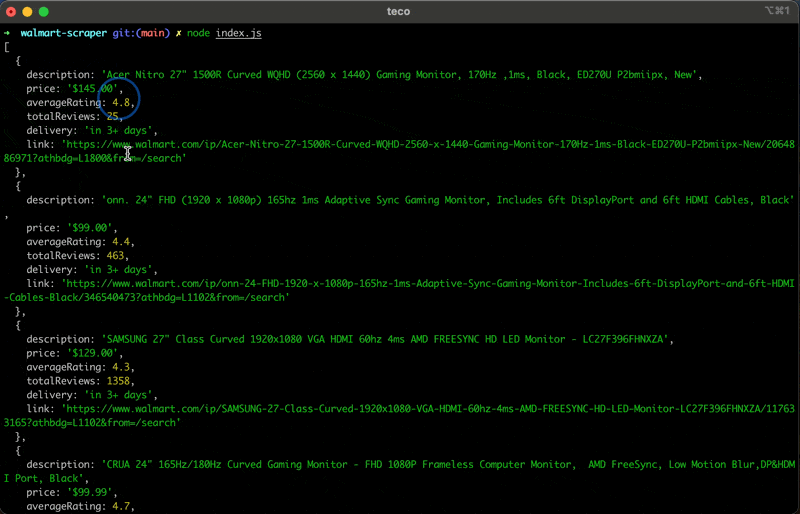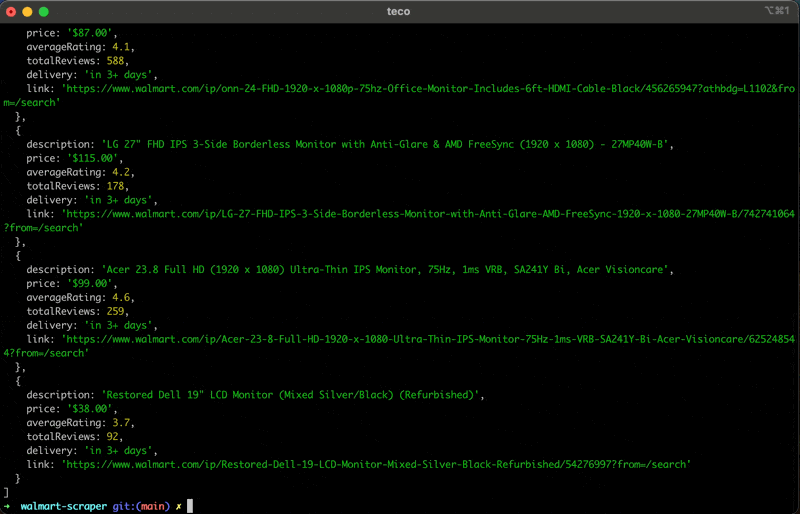
Führen Sie den Code mit dem Befehl aus node index.jsund freuen Sie sich über das Ergebnis:
Zusammenfassung
Der Aufbau eines Web Scrapers für Walmart kann in den folgenden Schritten erfolgen:
- Verwenden Sie Axios, um eine Anfrage an die ScraperAPI mit der Walmart-Seite zu senden, um den gerenderten HTML-Inhalt zu scrapen und herunterzuladen
- Analysieren Sie den HTML-Code mit Cheerio, um die Daten basierend auf DOM-Selektoren zu extrahieren
- Formatieren und transformieren Sie die abgerufenen Daten entsprechend Ihren Anforderungen.
Das Ergebnis ist eine Liste relevanter Informationen zu den auf der Walmart-Website angezeigten Produkten.
Hier sind ein paar Ideen, um mit diesem Walmart Web Scraper weiterzumachen:
- Rufen Sie Daten zu einem Produkt ab, z. B. technische Eigenschaften, Bewertungen usw.
- Machen Sie den Web Scraper dynamisch, indem Sie die direkte Eingabe des Suchbegriffs ermöglichen
- Speichern Sie die Daten in einer Datenbank (RDBMS, JSON-Dateien, CSV-Dateien usw.), um historische Daten zu erstellen und Geschäftsentscheidungen zu treffen
- Verwenden Sie den Async Scraper-Dienst, um Millionen von URLs asynchron zu scrapen
Weitere Informationen finden Sie in der ScraperAPI-Dokumentation für Node.js. Für einen einfachen Zugriff finden Sie hier das GitHub-Repository dieses Projekts.
