
Das Sammeln von Stellendaten aus Jobbörsen ist für Arbeitssuchende und Personalunternehmen von entscheidender Bedeutung. In einem früheren Artikel haben wir besprochen, wie man solche Daten aus dem beruflichen sozialen Netzwerk LinkedIn sammelt. Heute konzentrieren wir uns auf Indeed, eine der größten Plattformen für die Jobsuche.
Indeed ermöglicht es Benutzern, Lebensläufe zu veröffentlichen, Jobbenachrichtigungen zu abonnieren, nach Stellenangeboten zu suchen, diese zu speichern und sich direkt zu bewerben. In diesem Artikel werden verschiedene Methoden zur Automatisierung der Jobdatenerfassung von dieser Plattform aus untersucht, sodass Sie unabhängig von Ihren Programmierkenntnissen die erforderlichen Informationen abrufen können.
Anwendungsfälle für Indeed Job Scraping
Bevor wir uns mit den praktischen Aspekten befassen, wollen wir uns die spezifischen Szenarien ansehen, in denen das Sammeln von Daten von Indeed besonders nützlich sein kann. Kurz gesagt gibt es mehrere wichtige Gründe dafür:
- Analysieren Sie Trends auf dem Arbeitsmarkt und identifizieren Sie gefragte Fähigkeiten. Durch die Analyse von Stellenausschreibungen auf Indeed können Sie wertvolle Einblicke in die aktuelle Arbeitsmarktlandschaft gewinnen, einschließlich der gefragtesten Fähigkeiten und neuen Trends.
- Informieren Sie sich über Gehaltsspannen für bestimmte Berufsbezeichnungen und Standorte. Indeed bietet Gehaltsdaten für eine große Bandbreite an Berufsbezeichnungen und Standorten.
- Sammeln Sie Daten für die Personalbeschaffung und Talentgewinnung. Die Plattform dient als umfangreiche Quelle für Talentdaten und ermöglicht es Ihnen, qualifizierte Kandidaten zu identifizieren, nach bestimmten Kriterien zu filtern und potenzielle neue Mitarbeiter zu erreichen.
- Verfolgen Sie die Einstellungsaktivitäten Ihrer Wettbewerber und identifizieren Sie potenzielle Bewerber. Die Überwachung der Einstellungsaktivitäten Ihrer Konkurrenten auf Indeed kann wertvolle Einblicke in deren Talentbedarf und Strategien liefern.
- Führen Sie Recherchen zur Unternehmenskultur, zu Mitarbeiterbewertungen und zum Arbeitsumfeld durchIndeed bietet Zugriff auf Mitarbeiterbewertungen und Unternehmensinformationen, sodass Sie Einblicke in die Unternehmenskultur, das Arbeitsumfeld und die Mitarbeiterzufriedenheit gewinnen.
Lassen Sie uns auf jeden dieser Bereiche genauer eingehen.
Arbeitsmarktanalyse
Regelmäßige Analysen des Arbeitsmarkts halfen dabei, Veränderungen bei der Einstellung von Mitarbeitern und bei offenen Stellen konsequent zu verfolgen. So konnten wir besser verstehen, welche Fachkräfte derzeit am meisten gefragt sind, Trends in Abhängigkeit von verschiedenen Bedingungen erkennen und Veränderungen bei den Stellenanforderungen und den von den Arbeitgebern gesuchten Fähigkeiten verfolgen.
Dieser Ansatz half Arbeitssuchenden nicht nur dabei, die Anforderungen der Arbeitgeber besser zu verstehen, sondern auch Angebot und Nachfrage für bestimmte Positionen und Berufe einzuschätzen.
Gehaltsrecherche
Ein weiterer Grund für die Datenerfassung von Indeed besteht darin, Gehaltsinformationen aus Stellenausschreibungen zu erhalten. Dies kann Ihnen dabei helfen, Gehälter in verschiedenen Regionen und Branchen sowie für unterschiedliche Erfahrungsstufen und Unternehmensgrößen zu vergleichen.
Dies kann Ihnen dabei helfen, mögliche Benchmarks für Gehaltsverhandlungen bei Vorstellungsgesprächen zu finden. Oder, wenn Sie ein HR-Experte sind, kann es Ihnen dabei helfen, das relevante Gehalt für die von Ihnen benötigten Kriterien zu verstehen, was bei der Einstellung eines neuen Mitarbeiters hilfreich sein kann.
Rekrutierung und Talentakquise
Für Sie als HR-Experte kann Indeed ein wertvolles Tool zur Optimierung Ihres Rekrutierungsprozesses sein. Durch die Nutzung der Automatisierungsfunktionen können Sie potenzielle Kandidaten effizient identifizieren und rekrutieren und so manuelle Aufgaben deutlich reduzieren.
Indeed ermöglicht Ihnen die Erstellung gezielter Kandidatenlisten auf der Grundlage spezifischer Stellenanforderungen und Fähigkeiten. So können Sie sich auf die am besten qualifizierten Personen konzentrieren und sparen Zeit und Aufwand.
Wettbewerbsintelligenz
Durch die Beobachtung von Stellenangeboten können Sie besser verstehen, welche Anforderungen Ihre Mitbewerber an ihre Mitarbeiter stellen. Durch die Verfolgung der Rekrutierungsaktivitäten Ihrer Mitbewerber können Sie neue Stellenangebote und Strategien zur Talentgewinnung identifizieren.
Um Ihren Prozess der Suche nach potenziellen Kandidaten zu verbessern, können Sie versuchen, die Vorgehensweisen Ihrer Konkurrenten zu übernehmen. Analysieren Sie deren Stellenbeschreibungen, um das Profil ihrer idealen Kandidaten zu verstehen, und überlegen Sie, wie dies dazu beitragen könnte, Ihr eigenes Profil zu verbessern.
Überblick über Indeed
Schauen wir uns jetzt Indeed genauer an und sehen wir, welche Daten wir erhalten können. Wenn wir Daten von Arbeitssuchenden sammeln möchten, müssen wir auf die Seite zur Lebenslaufsuche gehen, einen Ort und ein Schlüsselwort festlegen, das eine Fähigkeit oder eine Berufsbezeichnung sein kann, und dann auf die Ergebnisseite gehen.
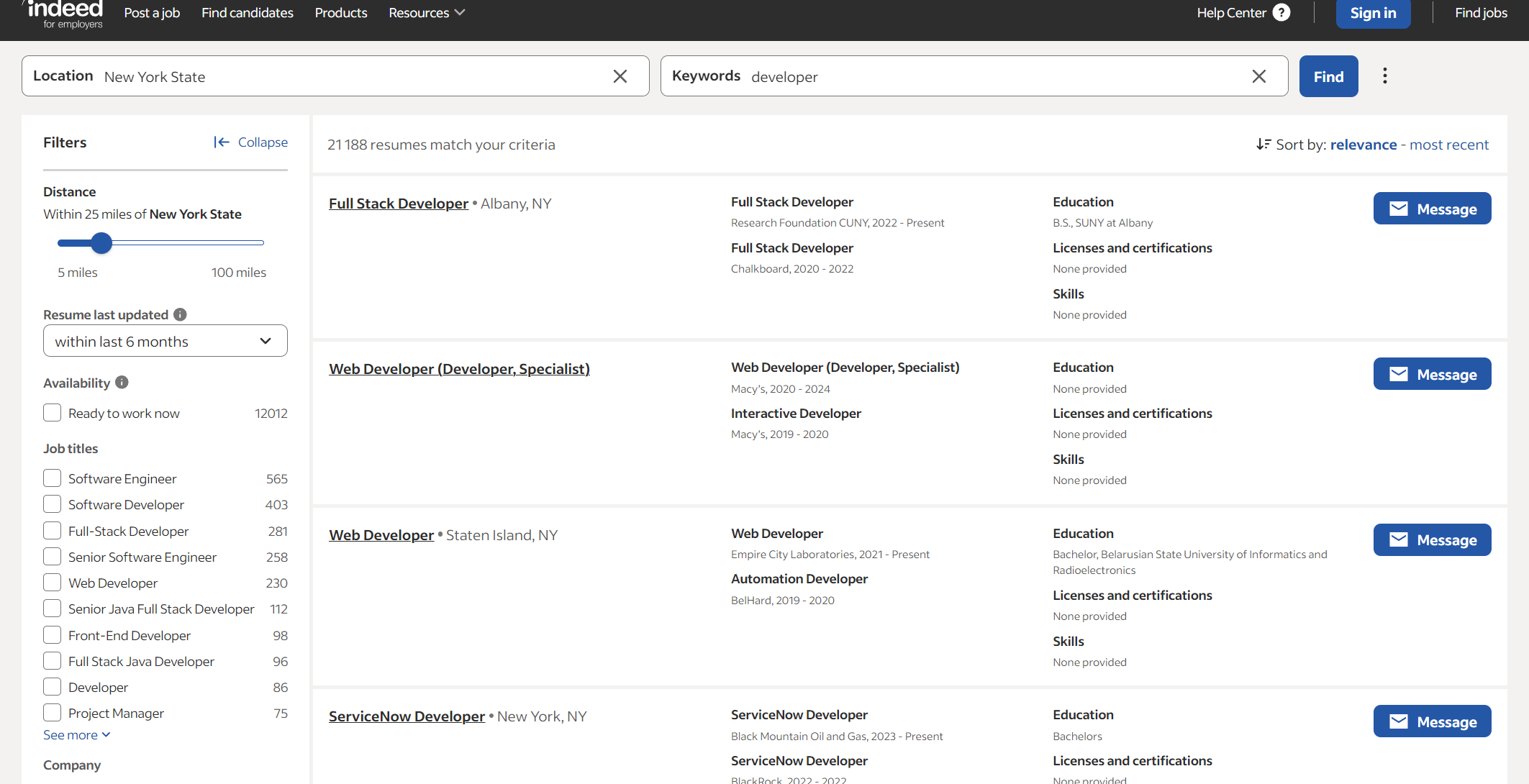
Wie Sie sehen, können Sie ohne Berechtigung keine detaillierten Stelleninformationen einsehen. Die begrenzten Informationen, die Sie erhalten, reichen möglicherweise nicht aus. Aus diesem Grund hören wir nicht auf, Kandidaten zu scrapen.
Fahren wir mit der Jobsuchseite fort und finden Sie alle verfügbaren Entwicklerpositionen.
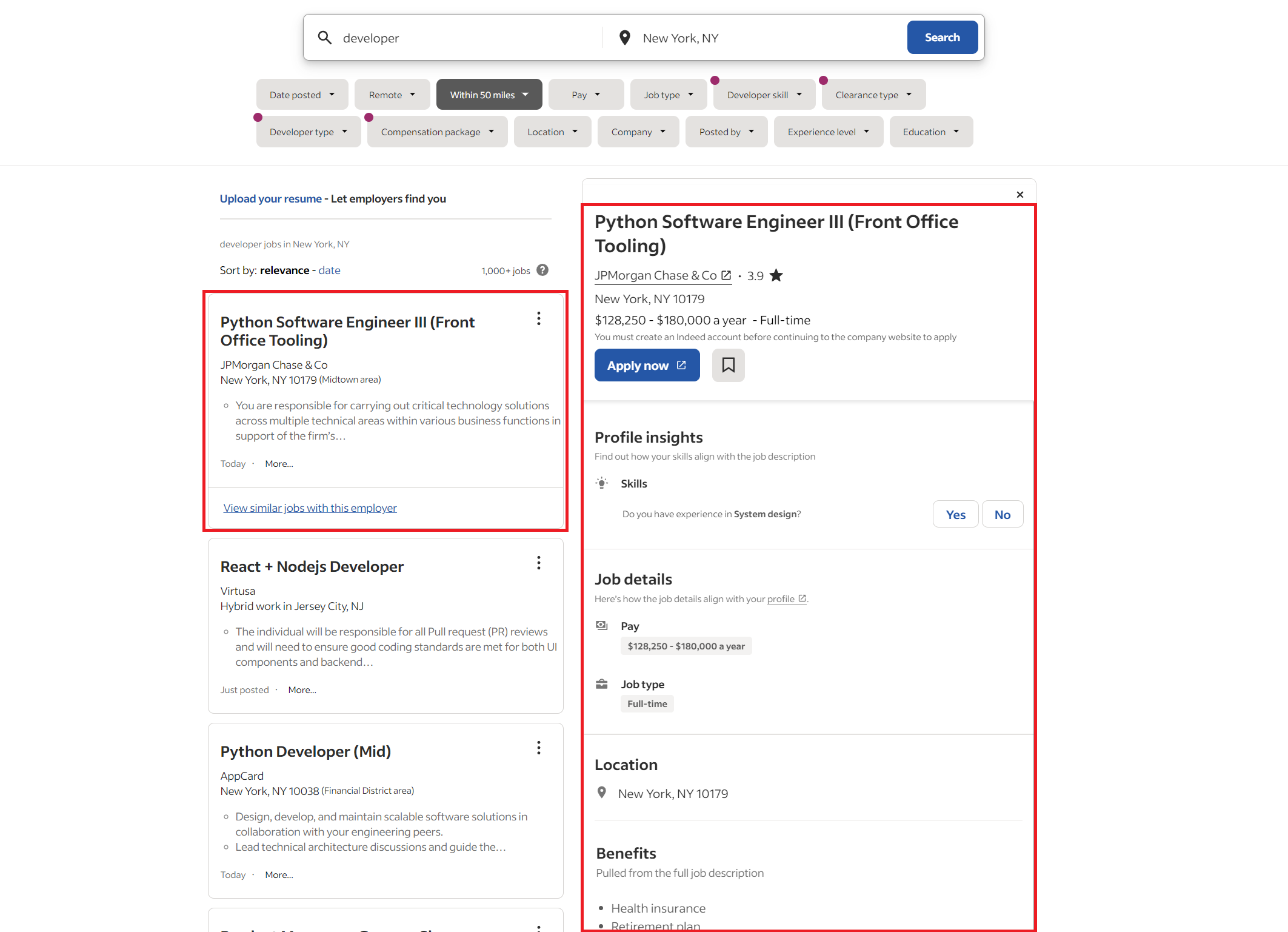
Die hier dargestellte Stellenliste bietet einen umfassenden Überblick über die verfügbaren Positionen. Auf der linken Seite finden Sie eine Übersicht aller offenen Stellen, während die rechte Seite detaillierte Informationen zu den aktuellen Stellen bietet.
Angenommen, Sie müssen Daten zu bestimmten Stellen sammeln. In diesem Fall haben Sie derzeit zwei Möglichkeiten: Sie können manuell zu jeder Stelle navigieren, darauf klicken und detaillierte Informationen einzeln sammeln oder sich auf die Kurzinformationen in der allgemeinen Stellenliste beschränken.
Auswählen einer Scraping-Methode
Welche Methode Sie zum Sammeln von Daten von Indeed wählen, hängt von Ihren spezifischen Anforderungen, Programmierkenntnissen, Datenvolumenanforderungen und der gewünschten Geschwindigkeit der Datenerfassung ab. Hier ist eine Aufschlüsselung der drei Hauptoptionen:
- Manuelle Datenerfassung. Bei dieser Methode werden Daten aus Indeed-Stellenangeboten manuell kopiert und in eine Tabelle oder ein anderes Datenspeicherformat eingefügt. Diese Methode eignet sich für kleine, einmalige Datenerfassungsaufgaben und erfordert keine Programmierkenntnisse. Allerdings ist sie zeitaufwändig, mühsam, fehleranfällig und für große Datensätze nicht skalierbar.
- Verwendung eines vorgefertigten Indeed No-Code Scrapers. Zahlreiche Web Scraping-Dienste bieten vorgefertigte Indeed Scraper an, mit denen Sie Daten ohne Codierung extrahieren können. Diese Scraper bieten eine benutzerfreundliche Oberfläche und liefern strukturierte Datendateien. Es mangelt ihnen jedoch an Flexibilität und Anpassungsoptionen, und Sie sind auf die Daten beschränkt, die der Scraper extrahieren kann.
- Erstellen Sie Ihren eigenen Indeed Scraper. Wenn Sie Ihren eigenen Scraper mit Programmiersprachen wie Python oder Node.js erstellen, haben Sie vollständige Kontrolle und können ihn individuell anpassen. Sie können den Scraper an Ihre spezifischen Datenanforderungen anpassen und ihn ändern, wenn sich die Indeed-Website ändert. Allerdings sind dafür Programmierkenntnisse und laufende Wartung erforderlich.
- Nutzung der Indeed-API. Obwohl die offizielle API von Indeed keine direkte Datenscraping-Funktionalität bietet, können Sie Scraping-APIs von Drittanbietern nutzen, die eine Verbindung zu Indeed herstellen und Daten basierend auf Ihren Kriterien extrahieren. Diese APIs liefern strukturierte Daten im JSON-Format, sodass Sie keinen Scraper programmieren oder warten müssen.
Die beste Methode hängt von Ihren spezifischen Umständen ab. Für eine kleine, einmalige Datenerfassung sind manuelle Datenerfassung oder ein vorgefertigter Scraper geeignete Optionen. Gleichzeitig bietet die Erstellung eines eigenen Scrapers oder die Verwendung einer Drittanbieter-API für häufige Datenerfassung oder spezifische Datenanforderungen mehr Flexibilität und Kontrolle. Für die fortlaufende Datenerfassung als Entwickler sind die Verwendung einer Drittanbieter-API oder die Erstellung eines Scrapers mit Blick auf die Wartung effiziente Optionen.
Methode 1: Indeed-Daten ohne Code scrapen
Beginnen wir mit der einfachsten Methode und erkunden, wie Sie mit dem No-Code-Scraper Indeed von HasData schnell Jobdaten erfassen können. Um dieses Tool zu nutzen, registrieren Sie sich auf unserer Website und navigieren Sie zur Registerkarte „No-Code-Scraper“ Ihres Dashboards. Suchen Sie den „Indeed Scraper“ und klicken Sie darauf.
Schauen wir uns diese Seite genauer an:
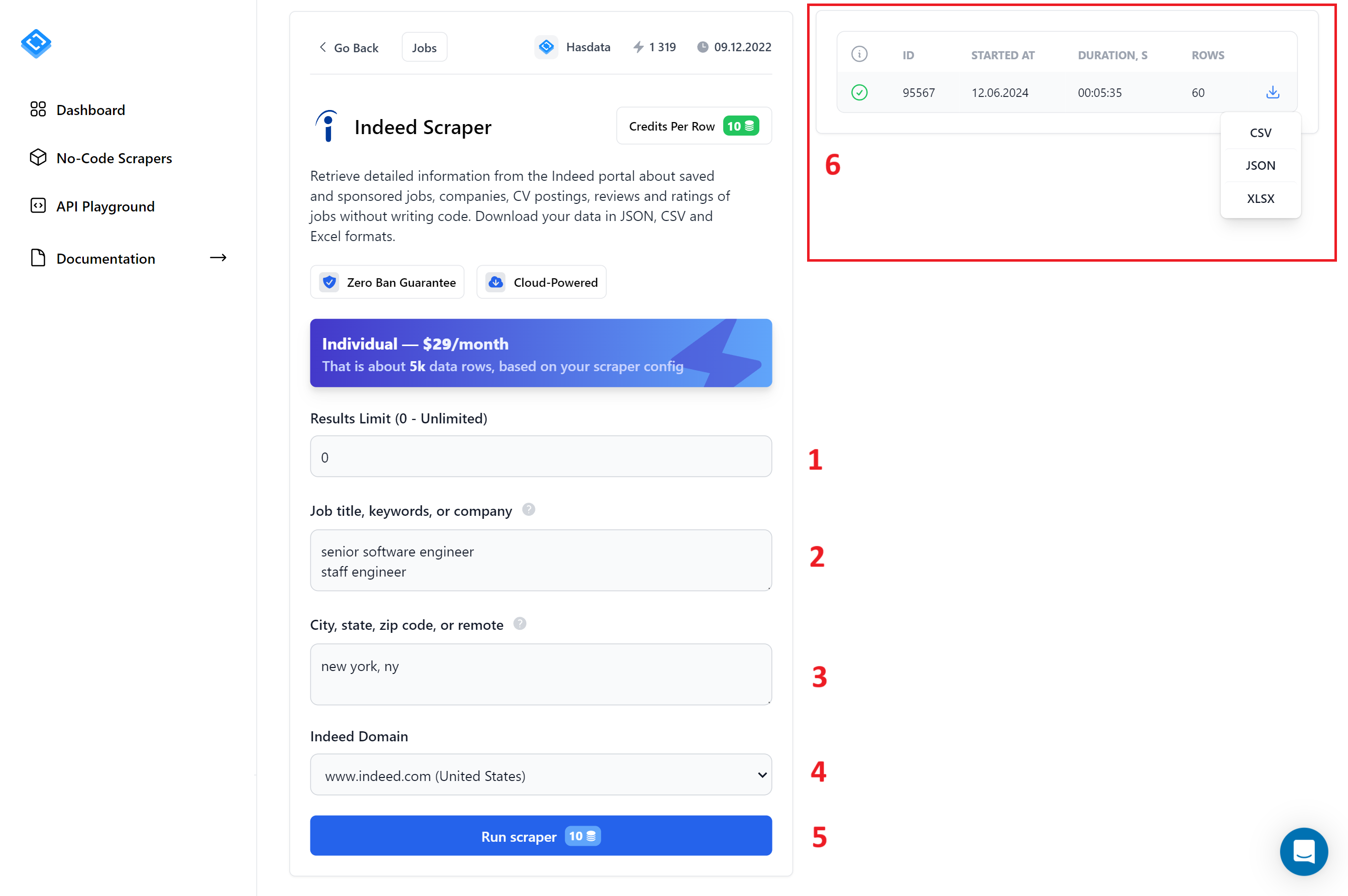
Um den Vorgang zu vereinfachen, haben wir die verschiedenen Felder nummeriert:
- Ergebnisgrenze. Geben Sie hier 0 ein, um die maximale Anzahl an Ergebnissen für jede Abfrage zu erhalten.
- Berufsbezeichnung, Stichworte, Unternehmen. Geben Sie die Schlüsselwörter ein, die Sie für die Jobsuche verwenden möchten. Sie können mehrere Schlüsselwörter eingeben, jedes in einer neuen Zeile.
- StadtBundesstaat
- Postleitzahl. Geben Sie die Stadt ein, in der Sie Jobs finden möchten.
- Indeed-Domain. Wählen Sie die Indeed-Domain für das Land aus, in dem Sie nach Jobs suchen.
- Scraper ausführenKlicken Sie auf diese Schaltfläche, um den Scraping-Vorgang zu starten.
Scraper-Aufgaben
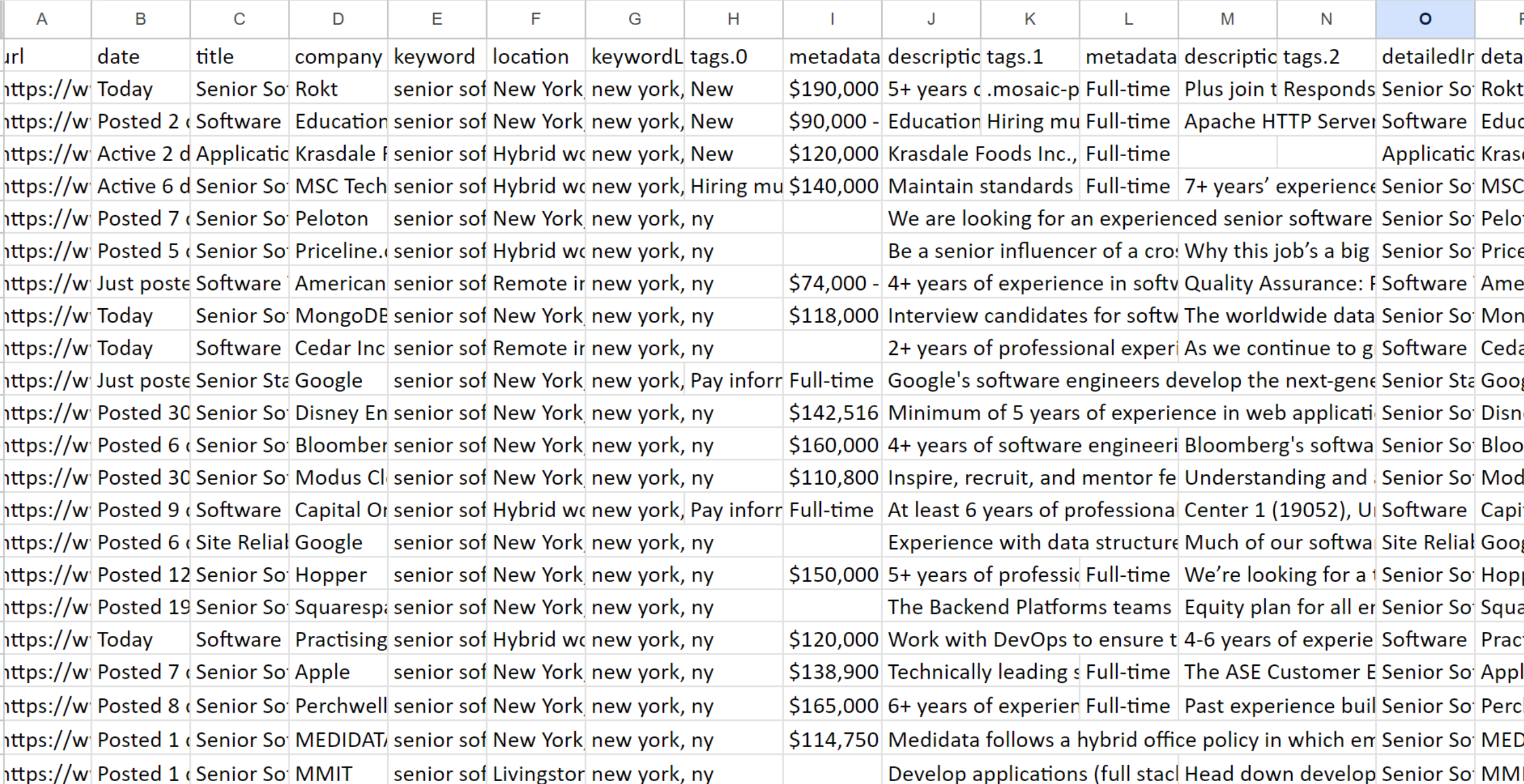
Erforschen Sie die Ergebnisse
Erforschen Sie die Ergebnisse
Da das Bild zu groß ist, zeigt es nur einen Teil. Der No-Code-Scraper sammelt daher alle verfügbaren Informationen zu jeder Stellenausschreibung, einschließlich der vollständigen Beschreibung.
Die Verwendung des No-Code-Scrapers von Indeed eignet sich für alle, die schnell Daten benötigen und kein eigenes Tool schreiben möchten. Da er außerdem alle verfügbaren Informationen für jede Stellenausschreibung sammelt, können Sie den umfassendsten Datensatz erhalten.
Methode 2: Indeed-Eigenschaftsdaten mit Python scrapen
Lassen Sie uns nun ein einfaches Tool mithilfe der Requests-Bibliothek erstellen und mit einem Beispiel mit einem Headless-Browser abschließen. Wir haben Python als Programmiersprache gewählt, da diese für Anfänger einfach genug ist.
Wir werden auch besprechen, wie die Integration einer API die Scraper-Erstellung erheblich vereinfachen kann. Konzentrieren wir uns in der Zwischenzeit auf die Vorbereitung des Daten-Scrapings.
Einrichten Ihrer Entwicklungsumgebung
pip install requests bs4 selenium timeUm loszulegen, müssen Sie einen Interpreter und eine Anwendung installieren, mit der Sie Code bearbeiten können, oder eine vollwertige Entwicklungsumgebung. Wir haben bereits darüber geschrieben, wie das für Python geht.
Sie benötigen Python Version 3.10 oder höher, um den von uns verwendeten Code auszuführen. Lassen Sie uns die Bibliotheken installieren, die wir mit dem Paketmanager verwenden werden:
Wir haben hier alle erforderlichen Bibliotheken aufgelistet, einschließlich der Bibliothek requests, die vorinstalliert ist, wenn Sie eine virtuelle Umgebung verwenden möchten. In diesem Fall müssen Sie alle anderen Bibliotheken installieren.
Um Selenium korrekt auszuführen, benötigen Sie je nach Browser auch einen separaten Webtreiber. Wir haben die Verwendung von Selenium in einem separaten Artikel beschrieben und Links zu allen Webtreibern bereitgestellt (für die neuesten Selenium-Versionen nicht erforderlich).
Daten abrufen mit Anfragen und BS4
Beginnen wir mit einem einfachen Ansatz: Wir verwenden die Bibliothek „requests“, um den HTML-Code der Seite mit den Stellenangeboten abzurufen und ihn dann mit BeautifulSoup zu analysieren. Wir speichern die extrahierten Daten in einer Variablen, damit sie einfach in einer Datei gespeichert werden können.
import requests
from bs4 import BeautifulSoupSie können das vorgefertigte Skript direkt in Google Colaboratory anzeigen und ausführen. Allerdings gibt Indeed bei Anfragen keine Daten zurück, sodass das Sammeln von Daten auf diese Weise nicht möglich ist.
base_url = "https://www.indeed.com/jobs"
query = "developer"
location = "New York, NY"Wenn Sie es dennoch selbst ausprobieren möchten, erstellen Sie eine neue Datei mit der Erweiterung .py und importieren Sie die Bibliotheken:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.5",
"Referer": "https://www.google.com/",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}Definieren Sie als Nächstes Variablen zur Aufnahme dynamischer Parameter wie Berufsbezeichnung, Schlüsselwort und Stadt:
Legen Sie als Nächstes Überschriften fest, um sie menschlicher zu gestalten:
url = f"{base_url}?q={query}&l={location.replace(' ', '+').replace(',', '%2C')}"Den aktuellsten User Agent können Sie unserer regelmäßig aktualisierten Tabelle entnehmen.
response = requests.get(url, headers=headers)
response.raise_for_status()Generieren Sie als Nächstes einen Link basierend auf den angegebenen Parametern.
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://www.indeed.com/jobs?q=developer&l=New+York%2C+NYMachen Sie eine Anfrage und prüfen Sie ihren Status:
Als Ergebnis erhalten Sie eine Fehlermeldung:
Leider kann das Problem nur durch die Verwendung eines Headless-Browsers anstelle der Anforderungsbibliothek oder durch den Einsatz einer vorgefertigten Indeed-Scraping-API gelöst werden.
Umgang mit dynamischem Inhalt mit Selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import timeLassen Sie uns das Problem aus dem vorherigen Beispiel angehen und den Code mithilfe der Selenium-Bibliothek neu schreiben. Das fertige Skript ist auch auf Google Colaboratory verfügbar. Da es jedoch die Ausführung von Headless-Browsern nicht unterstützt, müssen Sie es zum Testen herunterladen und auf Ihrem lokalen Computer ausführen.
base_url = "https://www.indeed.com/jobs"
query = "developer"
location = "New York, NY"
url = f"{base_url}?q={query}&l={location.replace(' ', '+').replace(',', '%2C')}"Erstellen Sie eine neue Datei mit der Endung *.py und importieren Sie die benötigten Module:
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
time.sleep(5)Wir haben auch die Zeitbibliothek importiert, um eine Verzögerung nach dem Starten des Browsers einzuführen. Als nächstes legen wir die Parameter fest und erstellen den Link:
page_source = driver.page_sourceUm mit Webseiten interagieren zu können, müssen Sie zunächst eine Instanz eines Webtreibers erstellen und dessen Einstellungen konfigurieren. Sobald der Webtreiber initialisiert ist, können Sie ihn starten und zur gewünschten URL navigieren:
output_data = ()
job_listings = driver.find_elements(By.CLASS_NAME, 'result')
for job in job_listings:
try:
company_location = job.find_element(By.CLASS_NAME, 'company_location')
company_name = company_location.find_element(By.CSS_SELECTOR, 'span(data-testid="company-name")').text
job_location = company_location.find_element(By.CSS_SELECTOR, 'div(data-testid="text-location")').text
print(f"Company Name: {company_name}")
print(f"Job Location: {job_location}")
job_metadata = job.find_element(By.CLASS_NAME, 'jobMetaDataGroup')
posted_date = job_metadata.find_element(By.CSS_SELECTOR, 'span(data-testid="myJobsStateDate")').text.splitlines()(1).strip()
print(f"Posted Date: {posted_date}")
job_data = {
"Company Name": company_name,
"Job Location": job_location,
"Posted Date": posted_date
}
output_data.append(job_data)
except Exception as e:
print(f"Error extracting job information: {e}")
print("\n" + "-"*100 + "\n")Holen Sie sich die Seitenquelle:
driver.quit()Erstellen Sie nun eine Variable zum Speichern der Daten. Suchen Sie dann den Block mit den Stellenausschreibungen und extrahieren Sie die relevanten Informationen. Zeigen Sie abschließend die extrahierten Daten an und speichern Sie sie in der Variable:
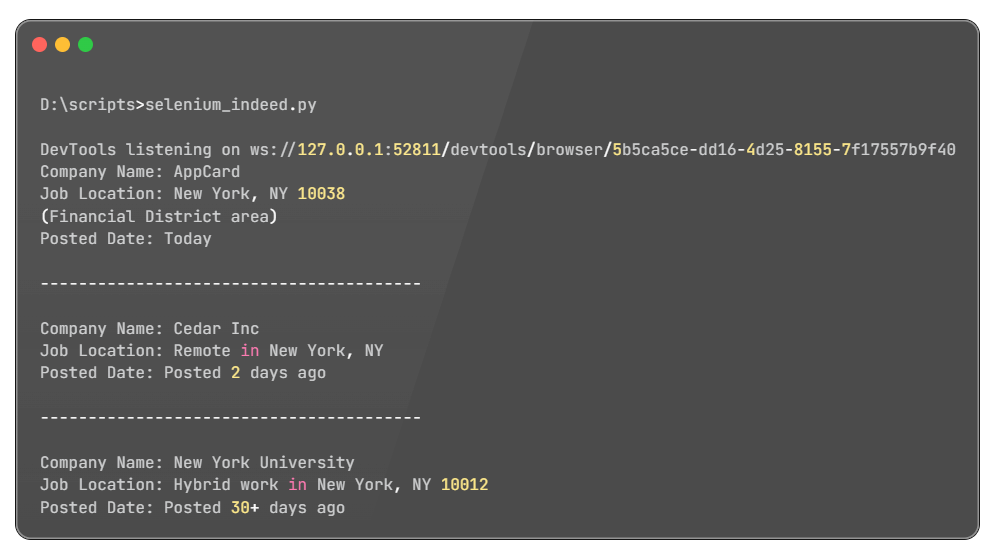
Testen des Skripts
Testen des Skripts
Dieses Skript kann erweitert werden, um effizient detaillierte Informationen aus jeder Stellenausschreibung zu sammeln. Sie können dies erreichen, indem Sie alle verfügbaren Stellenausschreibungen durchlaufen und relevante Daten mithilfe geeigneter Selektoren extrahieren. Darüber hinaus können Sie das Skript anpassen, um sich auf bestimmte Informationen zu konzentrieren, die Ihren Anforderungen entsprechen.
- Methode 3: Indeed mithilfe der API scrapenSehen wir uns nun an, wie Sie Indeed-APIs in Ihre Skripte integrieren können, um die Notwendigkeit von Headless-Browsern und der Analyse von Jobseiten zum Abrufen von Daten zu vermeiden. Wir werden uns zwei Indeed-APIs genauer ansehen:
- Indeed Listing API. Ruft Daten von den Ergebnisseiten der Jobsuche ab. Die Daten sind weniger umfassend, decken aber alle aufgelisteten Jobs ab.
Indeed-Eigenschaften-API
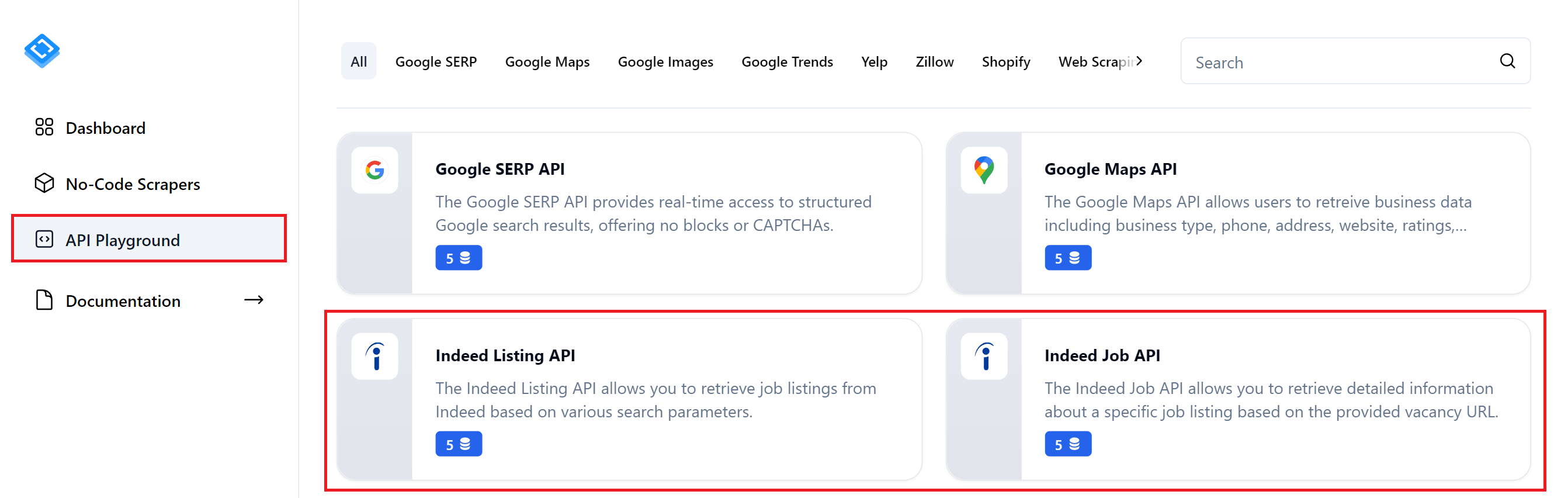
Forschungs-API-Spielplatz
Indeed-APIs finden
Diese APIs erfüllen unterschiedliche Anforderungen an den Datenabruf. Wenn die Indeed Listings API nicht den von Ihnen benötigten Detaillierungsgrad bietet, können Sie die Indeed Properties API nutzen, um detaillierte Daten für bestimmte Stellenangebote zu sammeln.
Einträge mit der Indeed-API scrapen
import requests
import jsonLassen Sie uns zunächst eine Liste mit Stellenangeboten und den dazugehörigen Kurzinformationen abrufen. Sie können ein vorbereitetes Skript in Google Colaboratory überprüfen und ausführen. Denken Sie bei der Verwendung daran, Ihren HasData-API-Schlüssel und die Abfrageparameter für die Jobsuche anzugeben.
base_url = "https://api.hasdata.com/scrape/indeed/listing"
keyword = "software engineer"
location = "New York, NY"
domain = "www.indeed.com"Erstellen Sie eine neue Datei und importieren Sie die erforderlichen Bibliotheken:
url = f"{base_url}?keyword={keyword.replace(' ', '+')}&location={location.replace(' ', '+').replace(',', '%2C')}&domain={domain}"Definieren Sie Variablen und Endpunkt für die Inleed Listing API von HasData:
headers = {
'Content-Type': 'application/json',
'x-api-key': 'PUT-YOUR-API-KEY'
}Verfassen Sie den Link:
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
print(json.dumps(data, indent=2))
else:
print(f"Error: {response.status_code} - {response.text}")Geben Sie die Anforderungsheader an, einschließlich Ihres API-Schlüssels:
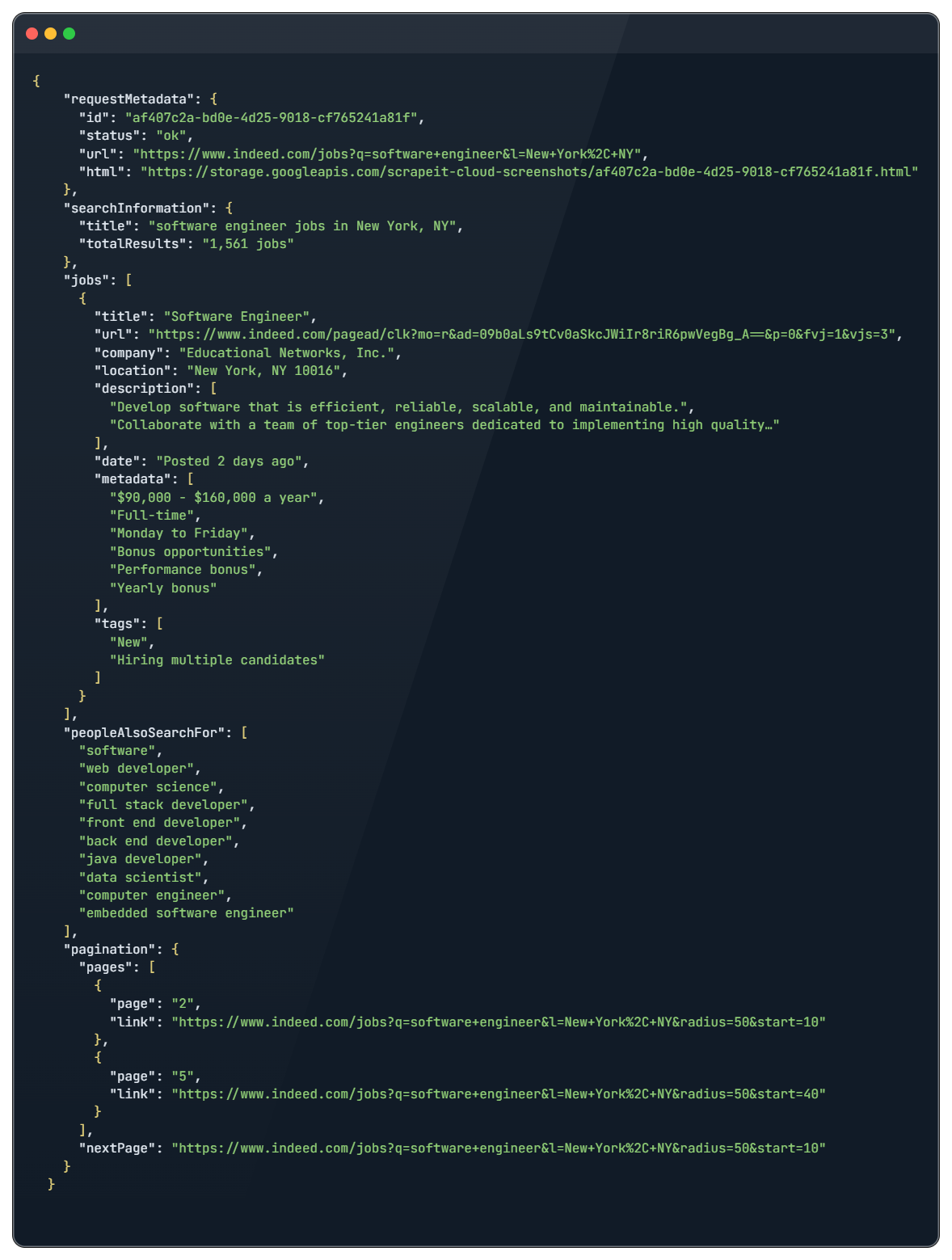
Ein Beispiel für eine JSON-Antwort
Ein Beispiel für eine JSON-Antwort
Diese Daten sollten ausreichen, um einen Überblick über verschiedene Stellenangebote zu erhalten. Wenn Sie jedoch detailliertere Informationen zu einem Stellenangebot benötigen, lesen Sie den folgenden Endpunkt.
Scrapen von Eigenschaften mithilfe der Indeed-API
pip install urllibDieser Endpunkt ist ideal, wenn Sie bereits eine Liste mit Stellenangeboten haben, für die Sie detailliertere Informationen sammeln möchten. Sie finden dieses Skript auch in Google Colaboratory
import requests
import json
import urllib.parseIn diesem Beispiel verwenden wir auch die urllib-Bibliothek, um die URL der Stellenanzeige zu verarbeiten. Wenn Sie sie nicht installiert haben, verwenden Sie den folgenden Befehl:
base_url = "https://api.hasdata.com/scrape/indeed/job"
job_url = "https://www.indeed.com/viewjob?jk=cf56b58ab740db2a"
encoded_job_url = urllib.parse.quote(job_url, safe="")
url = f"{base_url}?url={encoded_job_url}"Importieren Sie zunächst die erforderlichen Bibliotheken in Ihr Skript:
headers = {
'Content-Type': 'application/json',
'x-api-key': 'YOUR-API-KEY'
}Als Nächstes geben wir die URLs für den API-Endpunkt und die gewünschte Stellenausschreibung an und erstellen eine allgemeine URL zum Abrufen der Daten:
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
print(json.dumps(data, indent=2))
else:
print(f"Error: {response.status_code} - {response.text}")Legen Sie Anforderungsheader fest, einschließlich des API-Schlüssels Ihres HasData:
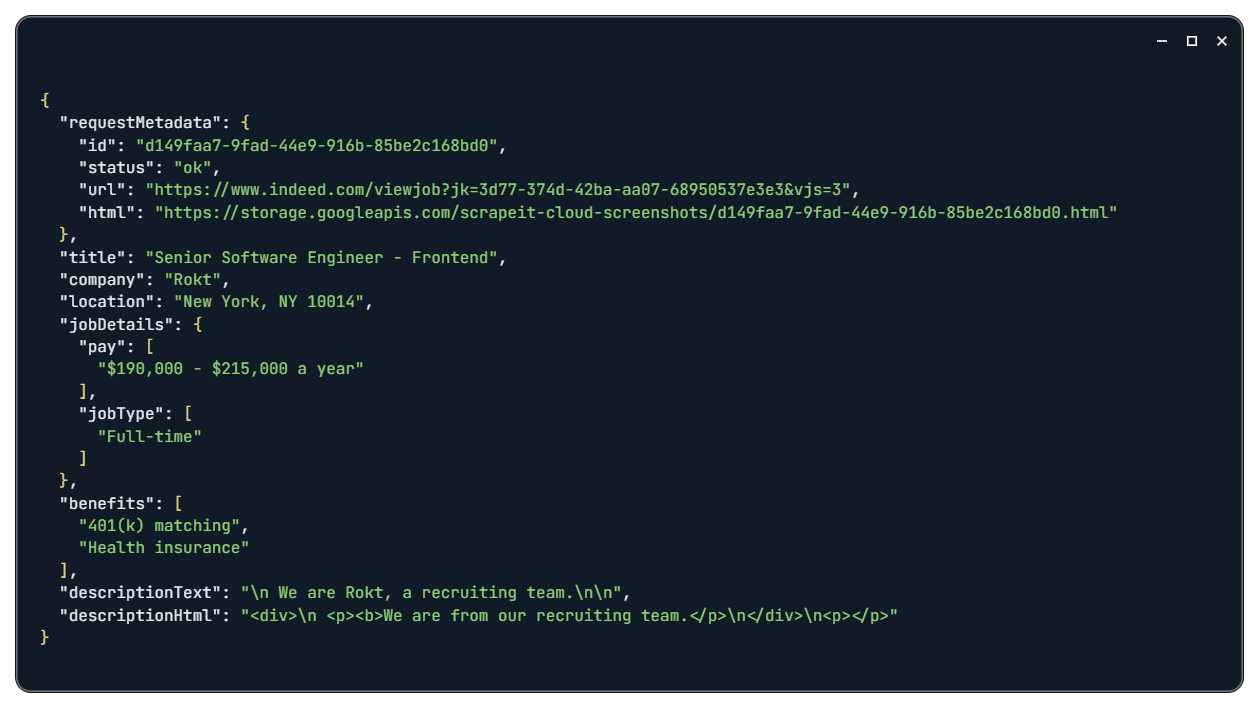
Indeed Job-Ergebnis
Indeed Job-Antwort
Durch Eingabe des vollständigen Stellenbeschreibungstextes können Sie auf alle verfügbaren Informationen zu der jeweiligen Vakanz zugreifen.
pip install json csvDatenverarbeitung und -speicherung
import json
import csvSie benötigen die entsprechenden Bibliotheken, um Daten in Python in Dateien zu speichern. Lassen Sie uns die JSON- und CSV-Bibliotheken mithilfe eines Paketmanagers installieren:
csv_file="jobs_data.csv"
with open(csv_file, 'w', newline="", encoding='utf-8') as csvfile:
fieldnames = ('Company Name', 'Job Location', 'Posted Date')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in output_data:
writer.writerow(job)Importieren Sie als Nächstes die Bibliotheken in Ihr Python-Skript:
json_file="jobs_data.json"
with open(json_file, 'w', encoding='utf-8') as jsonfile:
json.dump(output_data, jsonfile, ensure_ascii=False, indent=4)Fügen Sie nun die Logik zum Speichern von Daten in Dateien hinzu. Verwenden wir eine zuvor erstellte Variable als Datenquelle. So speichern Sie als CSV-Datei:
So speichern Sie als JSON-Datei:
Dadurch werden die zuvor ermittelten Daten in Dateien gespeichert und stehen Ihnen in einem für die weitere Verarbeitung geeigneten Format zur Verfügung.
Abschluss
Das Scraping von Stellendaten von Indeed bietet wertvolle Einblicke in den Arbeitsmarkt, verbessert Rekrutierungsstrategien und sichert einen Wettbewerbsvorteil bei Einstellungsverfahren. Dieser Artikel befasst sich mit den wichtigsten Methoden zum Sammeln von Daten von dieser Plattform. Wir haben eine detaillierte Aufschlüsselung jedes Ansatzes bereitgestellt, von der Verwendung von No-Code-Scrapern bis hin zum Erstellen benutzerdefinierter Scraper von Grund auf.
Zusätzlich haben wir alle in diesem Artikel besprochenen Skripte auf Google Colaboratory verfügbar gemacht. Wenn Sie sich mehr für die Ergebnisse als für die Theorie interessieren, können Sie direkt auf die entsprechenden Seiten zugreifen und die vorgefertigten Skripte ansehen. Links zu diesen Skripten finden Sie am Anfang jedes relevanten Unterabschnitts.Insgesamt hoffen wir, dass dieser Artikel die Vorteile des Scrapings von Indeed verdeutlicht und Ihnen wertvolle Erkenntnisse liefert, die Sie in Ihren eigenen Bemühungen umsetzen können.
