
Nachdem Sie nun Ihr ScraperAPI-Konto haben, können wir zur Sache kommen!!
Schritt 1: Importieren Ihrer Bibliotheken
Damit dies funktioniert, müssen Sie die erforderlichen Python-Bibliotheken importieren json, requestUnd BeautifulSoup.
import json
from datetime import datetime
import requests
from bs4 import BeautifulSoup
Erstellen Sie als Nächstes eine Variable zum Speichern Ihres API-Schlüssels
scraper_api_key = 'ENTER KEY HERE'
Schritt 2: Reddit-Beitrag abrufen
Beginnen wir mit dem Hinzufügen unserer ursprünglichen URL zu reddit_query und dann unsere bauen get() Anfragen über den Standardendpunkt von ScraperAPI.
reddit_query = f"https://www.reddit.com/t/valheim/"
scraper_api_url = f'http://api.scraperapi.com/?api_key={scraper_api_key}&url={reddit_query}'
r = requests.get(scraper_api_url)
Als nächstes analysieren wir den HTML-Code von Reddit (mit BeautifulSoup), ein … Erstellen soup Objekt, mit dem wir nun bestimmte Elemente auf der Seite auswählen können:
soup = BeautifulSoup(r.content, 'html.parser')
articles = soup.find_all('article', class_='m-0')
Konkret suchen wir nach allen article Elemente mit einer CSS-Klasse von m-0 Verwendung der find_all() Methode. Die resultierende Artikelliste wird der Variablen zugewiesen articles die jeden Beitrag enthalten.
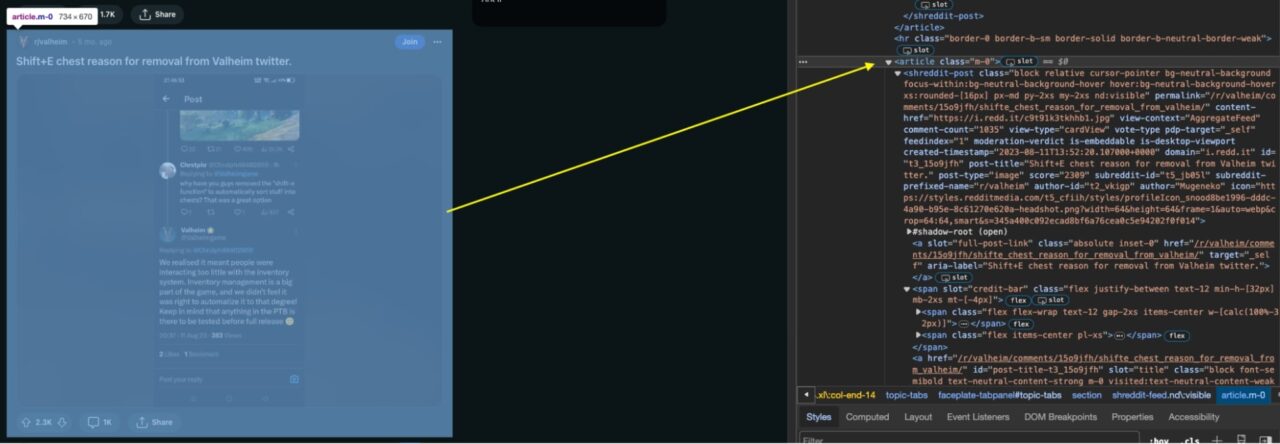
Schritt 3: Extrahieren der Reddit-Post-Informationen
Jetzt, wo Sie das abgekratzt haben article Elemente, die jeden Subreddit-Beitrag auf der Reddit-Seite enthalten, ist es an der Zeit, jeden Beitrag zusammen mit seinen Informationen daraus zu extrahieren
# Initialize a list to store parsed posts
parsed_posts = ()
for article in articles:
post = article.find('shreddit-post')
# Extract post details
post_title = post('post-title')
post_permalink = post('permalink')
content_href = post('content-href')
comment_count = post('comment-count')
score = post('score')
author_id = post.get('author-id', 'N/A')
author_name = post('author')
# Extract subreddit details
subreddit_id = post('subreddit-id')
post_id = post("id")
subreddit_name = post('subreddit-prefixed-name')
# Append the parsed post to the list
parsed_posts.append({
'post_title': post_title,
'post_permalink': post_permalink,
'content_href': content_href,
'comment_count': comment_count,
'score': score,
'author_id': author_id,
'author_name': author_name,
'subreddit_id': subreddit_id,
'post_id': post_id,
'subreddit_name': subreddit_name
})
Im obigen Code haben Sie einzelne Beiträge identifiziert, indem Sie nach Elementen mit der Klasse gesucht haben shreddit-post. Für jeden dieser Beiträge haben Sie dann Details extrahiert wie:
- Titel
- Permalink
- Inhaltslink
- Anzahl Kommentare
- Punktzahl
- Autoren-ID
- Autorenname
Durch Verweis auf bestimmte HTML-Elemente, die jeder Information zugeordnet sind.
Darüber hinaus verwendet der Code beim Umgang mit Subreddit-Beitragsdetails auch Elemente wie shreddit-id, idUnd subreddit-prefixed-name relevante Informationen zu erfassen.
Im Wesentlichen navigiert der Code programmgesteuert durch die HTML-Struktur von Reddit-Beiträgen, sammelt wesentliche Details für jeden Beitrag und speichert sie in einer Liste zur weiteren Verwendung oder Analyse.
Schritt 4: Reddit-Post-Kommentare abrufen
Damit Sie Kommentare aus Beiträgen extrahieren können, müssen Sie eine Anfrage an ScraperAPI senden, sonst riskieren Sie, von den Anti-Scraping-Mechanismen von Reddit gesperrt zu werden.
Erstellen wir zunächst eine fetch_comments_from_post() Funktion zum Senden einer Anfrage an ScraperAPI mit Ihrem API-SCHLÜSSEL (vergessen Sie nicht, ihn zu ersetzen YOUR_SCRAPER_API_KEY mit Ihrem tatsächlichen API-SCHLÜSSEL) und der Beitrags-URL.
def fetch_comments_from_post(post_data):
payload = { 'api_key': 'YOUR_SCRAPER_API_KEY', 'url': 'https://www.reddit.com//r/valheim/comments/15o9jfh/shifte_chest_reason_for_removal_from_valheim/' }
r = requests.get('https://api.scraperapi.com/', params=payload)
soup = BeautifulSoup(r.content, 'html.parser')
Diese Anfrage wird dann zur Analyse an BeautifulSoup weitergeleitet.
Dann können wir alle Kommentare zum SubReddit identifizieren, indem wir nach suchen div Elemente, die eine haben data-type Attribut auf gesetzt comment.
# Find all comment elements
comment_elements = soup.find_all('div', class_='thing', attrs={'data-type': 'comment'})
Nachdem Sie die Kommentare gefunden haben, ist es an der Zeit, sie zu extrahieren.
# Initialize a list to store parsed comments
parsed_comments = ()
for comment_element in comment_elements:
try:
# Extract relevant information from the comment element, handling potential NoneType errors
author = comment_element.find('a', class_='author').text.strip() if comment_element.find('a', class_='author') else None
dislikes = comment_element.find('span', class_='score dislikes').text.strip() if comment_element.find('span', class_='score dislikes') else None
unvoted = comment_element.find('span', class_='score unvoted').text.strip() if comment_element.find('span', class_='score unvoted') else None
likes = comment_element.find('span', class_='score likes').text.strip() if comment_element.find('span', class_='score likes') else None
timestamp = comment_element.find('time')('datetime') if comment_element.find('time') else None
text = comment_element.find('div', class_='md').find('p').text.strip() if comment_element.find('div', class_='md') else None
# Skip comments with missing text
if not text:
continue # Skip to the next comment in the loop
# Append the parsed comment to the list
parsed_comments.append({
'author': author,
'dislikes': dislikes,
'unvoted': unvoted,
'likes': likes,
'timestamp': timestamp,
'text': text
})
except Exception as e:
print(f"Error parsing comment: {e}")
return parsed_comments
Im obigen Code haben wir die aufgerufen parsed_comments Liste zum Speichern der extrahierten Informationen. Der Code durchläuft dann jeden comment_element in einer Sammlung von comment Elemente.
Innerhalb der Schleife haben wir verwendet find() um relevante Details aus jedem Kommentar zu extrahieren, wie zum Beispiel:
- Name des Autors
- Abneigungen
- Zählung ohne Abstimmung
- Likes
- Zeitstempel
- Textinhalt des Kommentars
Um Fälle zu bearbeiten, in denen möglicherweise einige Informationen fehlen (was dazu führt, dass NoneType Fehler), verwenden wir eine bedingte Anweisung. Wenn einem Kommentar der Textinhalt fehlt, wird er übersprungen und die Schleife fährt mit dem nächsten Kommentar fort. Das spart uns Zeit und stoppt das NoneType Fehler.
Die extrahierten Daten werden dann für jeden Kommentar in einem Wörterbuch organisiert und an das angehängt parsed_comments Liste.
Alle Fehler, die während des Analysevorgangs auftreten, werden abgefangen und gedruckt.
Schließlich wird die Liste mit den analysierten Kommentaren zurückgegeben und bietet eine strukturierte Darstellung der wesentlichen Kommentarinformationen zur weiteren Verwendung oder Analyse.
Nachdem die Kommentare für jeden Subreddit-Beitrag extrahiert wurden, können Sie die Kommentare im ersten speichern parsed_post Daten durch Hinzufügen des folgenden Codes.
comments = fetch_comments_from_post(post)
Schritt 5: Konvertieren in JSON
Nachdem Sie nun alle benötigten Daten extrahiert haben, ist es an der Zeit, sie zur einfacheren Verwendung in einer JSON-Datei zu speichern.
# Save the parsed posts to a JSON file
output_file_path = 'parsed_posts.json'
with open(output_file_path, 'w', encoding='utf-8') as json_file:
json.dump(parsed_posts, json_file, ensure_ascii=False, indent=2)
print(f"Data has been saved to {output_file_path}")
Der output_file_path Variable wird auf den Dateinamen gesetzt parsed_posts.json. Der Code öffnet diese Datei dann im Schreibmodus ('w') und verwendet die json.dump() Funktion zum Schreiben des Inhalts der parsed_posts list in die Datei im JSON-Format ein.
Der ensure_ascii=False Das Argument stellt sicher, dass Nicht-ASCII-Zeichen ordnungsgemäß verarbeitet werden indent=2 Fügt Einrückungen zur besseren Lesbarkeit in der JSON-Datei hinzu.
Nach dem Schreiben der Daten wird eine Meldung an die Konsole ausgegeben, die angibt, dass die Daten erfolgreich in der angegebenen JSON-Datei gespeichert wurden (parsed_posts.json).
Testen des Schabers
Das Testen des Scrapers ist ganz einfach: Sie führen einfach Ihren Python-Code aus und alle Datenbeiträge und Kommentare im bereitgestellten Subreddit werden gescrapt und in eine JSON-Datei mit dem Namen konvertiert parsed_post.json.
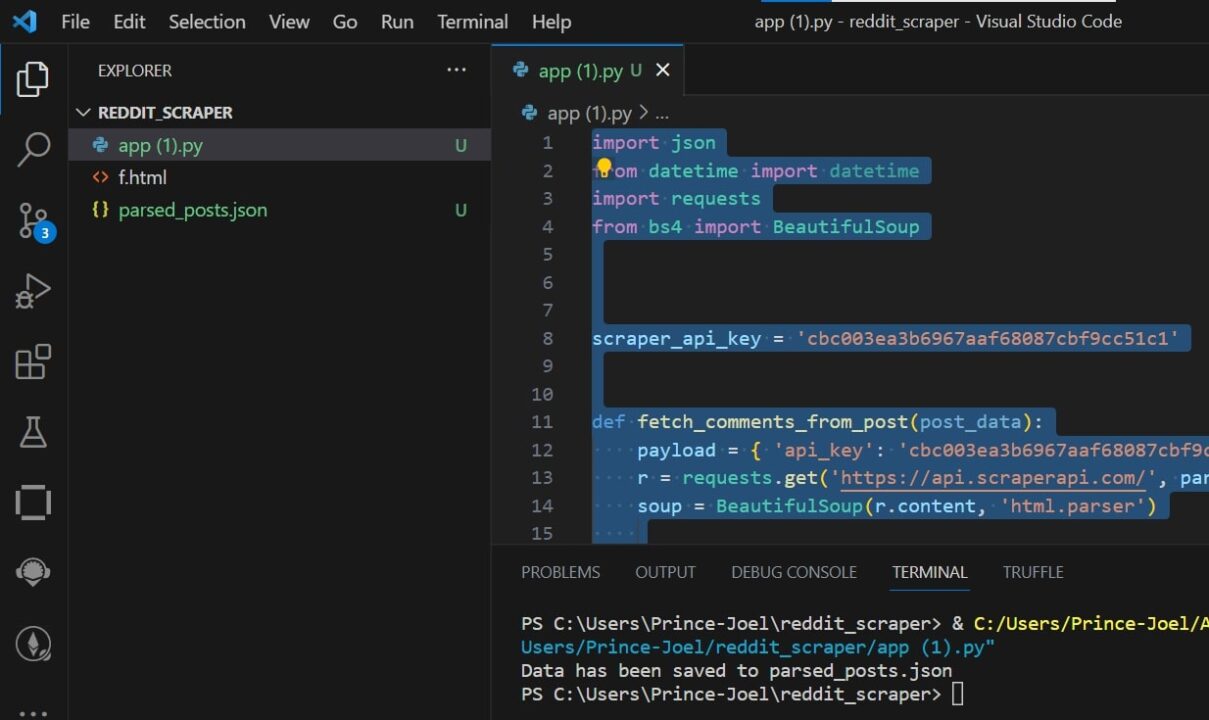
Herzlichen Glückwunsch, Sie haben erfolgreich Daten von Reddit gescrapt und können die Daten nach Belieben verwenden!
Zusammenfassung
Dieses Tutorial stellt einen schrittweisen Ansatz zum Scrapen von Daten aus Reddit vor und zeigt Ihnen, wie das geht
- Sammeln Sie die 25 neuesten Beiträge in einem Subreddit
- Gehen Sie alle Beiträge durch, um Kommentare zu sammeln
- Senden Sie Ihre Anfragen über ScraperAPI, um eine Sperrung zu vermeiden
- Exportieren Sie alle extrahierten Daten in eine strukturierte JSON-Datei
Zum Abschluss dieser aufschlussreichen Reise in die Welt des Reddit-Scrapings hoffen wir, dass Sie wertvolle Einblicke in die Leistungsfähigkeit von Python und ScraperAPI bei der Erschließung des Informationsschatzes von Reddit gewonnen haben.
Bleiben Sie neugierig und denken Sie daran: Mit großartigen Scraping-Fähigkeiten gehen auch große Verantwortungen einher.
Bis zum nächsten Mal, viel Spaß beim Schaben!
