
TL;DR: Produktpreis-Scraper
Wenn Sie bereits mit Web Scraping vertraut sind und nur eine schnelle Lösung suchen, finden Sie hier den Python-Code, den ich zum Scrapen der Produktpreise von Zara mithilfe von Scrapy und Beautifulsoup verwendet habe:
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
def get_scraperapi_url(url):
APIKEY = "YOUR_SCRAPERAPI_KEY"
payload = {'api_key': APIKEY, 'url': url, 'render': True}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
urls = (
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=2',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=3'
)
for url in urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
def parse(self, response):
soup = BeautifulSoup(response.body, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('h2').get_text(strip=True) if product.select_one('h2') else None
price = product.select_one('span.money-amount__main').get_text(strip=True) if product.select_one('span.money-amount__main') else None
yield {
'product_name': product_name,
'price': price,
}
Stellen Sie vor dem Ausführen des Skripts sicher, dass Scrapy installiert ist (pip install scrapy). Erstellen Sie außerdem ein kostenloses ScraperAPI-Konto und ersetzen Sie „YOUR_SCRAPERAPI_KEY“ mit Ihrem tatsächlichen API-Schlüssel – auf diese Weise umgehen wir erfolgreich alle Herausforderungen beim Scraping der Produktpreise von Zara.
Warum Preise scrapen?
Für den Geschäftserfolg ist es entscheidend, die Preisgestaltung der Konkurrenz im Auge zu behalten. Durch die Automatisierung des Prozesses der Erfassung und Analyse von Preisdaten bleiben Sie über die Strategien Ihrer Konkurrenz informiert und können bessere Entscheidungen für Ihr eigenes Unternehmen treffen.
Hier sind drei große Anwendungsfälle für Preisdaten:
- Dynamische Preisgestaltung: Der Zugriff auf Echtzeit-Preisdaten der Konkurrenz ermöglicht Ihnen die Umsetzung dynamischer Preisstrategien. Sie können Ihre Preise basierend auf Marktschwankungen, Nachfragetrends und Aktionen der Konkurrenz anpassen und so Ihre Gewinne maximieren.
- Marktforschung und Erkenntnisse: Beim Price Scraping geht es um mehr als nur die Ermittlung der Preise Ihrer Mitbewerber. Es kann Ihnen dabei helfen, Preistrends in Ihrer Branche zu erkennen, Kostenstrukturen zu verstehen und Einblicke in das Käuferverhalten zu gewinnen.
- Agilität und Anpassungsfähigkeit: Die Marktdynamik kann sich schnell ändern, und Preisänderungen folgen oft diesem Trend. Indem Sie die Preise regelmäßig überprüfen, bleiben Sie über diese Änderungen auf dem Laufenden und können schnell reagieren, sei es durch die Anpassung Ihrer eigenen Preise oder Ihrer Marketingbotschaften.
Natürlich gibt es noch viele weitere Anwendungsfälle für Produktpreisdaten. Sie müssen jedoch zunächst einen Datensatz zur Analyse erstellen, bevor Sie etwas tun können.
Scraping von Produktpreisen mit Python
Für dieses Projekt erstellen wir einen Web Scraper, um Preisdaten aus Zaras Herrenhemdenkollektion zu extrahieren. Wir konzentrieren uns zwar auf Zara, die Konzepte in diesem Leitfaden können jedoch auf jede E-Commerce-Site angewendet werden.
Lass uns anfangen!
Projektanforderungen
Dies sind die Tools und Bibliotheken, die Sie für dieses Projekt benötigen:
Sie können sie mit pip installieren:
pip install scrapy beautifulsoup4
Scrapy ist eine All-in-One-Suite zum Crawlen des Webs, Herunterladen, Verarbeiten und Speichern der resultierenden Daten in einem zugänglichen Format. Es arbeitet mit Spidern, das sind Python-Klassen, die definieren, wie auf einer Website navigiert wird.
BeautifulSoup ist eine Python-Bibliothek, die das Parsen von HTML-Inhalten auf Webseiten vereinfacht. Es ist ein unverzichtbares Tool zum Extrahieren von Daten.
Notiz: Wenn Sie alles von Grund auf neu installieren müssen, folgen Sie unserem Tutorial zu den Grundlagen von Scrapy in Python. Ich werde dasselbe Setup verwenden, also erledigen Sie das und kommen Sie zurück.
Schritt 1: Scrapy einrichten
Lassen Sie uns zunächst Scrapy einrichten. Beginnen Sie mit der Erstellung eines neuen Scrapy-Projekts:
scrapy startproject price_scraper
Dieser Befehl erstellt eine neue Preisscraper Verzeichnis mit den notwendigen Dateien für ein Scrapy-Projekt.
Wenn Sie nun den Inhalt dieses Verzeichnisses auflisten, sollten Sie die folgende Struktur sehen:
$ cd price_scraper
$ tree
.
├── price_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
└── scrapy.cfg
Die Einrichtung unseres Scrapy-Projekts ist abgeschlossen!
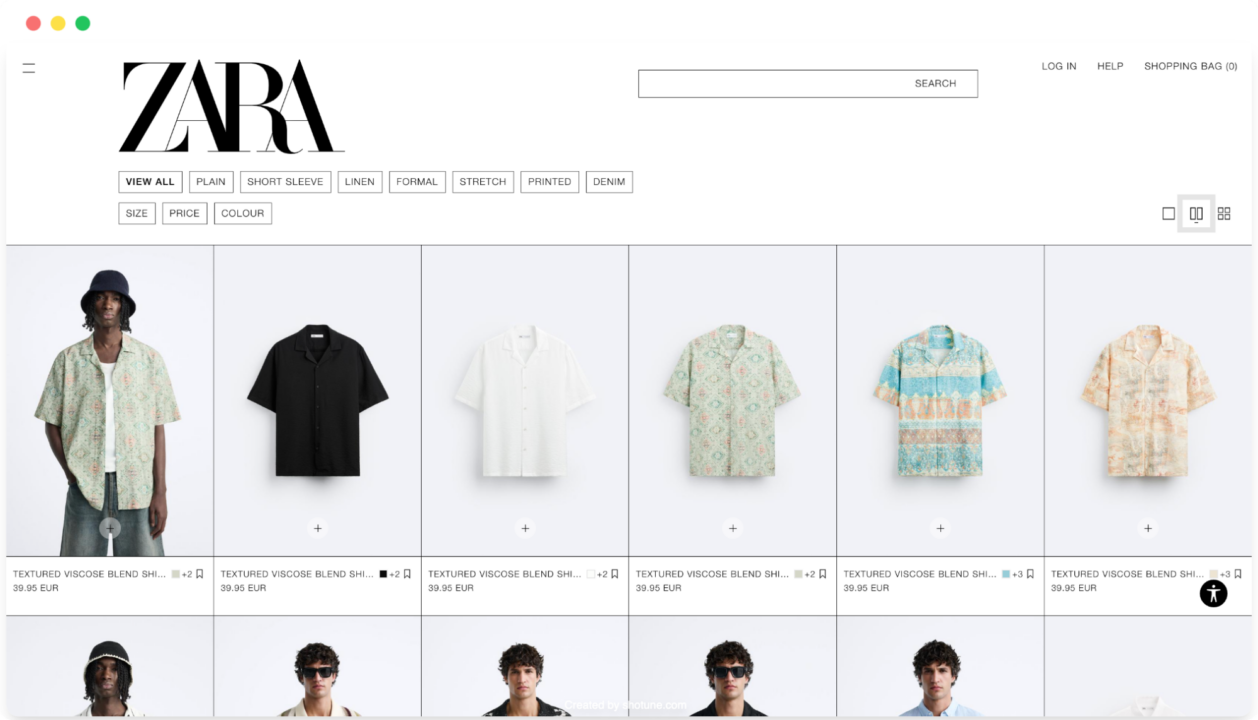
Schritt 2: Überblick über die Website-Struktur von Zara
Bevor Sie mit der Codierung des Spiders beginnen, müssen Sie unbedingt die Struktur der Website verstehen, die Sie scrapen möchten.
Öffnen Sie den Bereich Herrenhemden auf der Website von Zara in Ihrem Browser, klicken Sie mit der rechten Maustaste und wählen Sie „Prüfen“, um die Entwicklertools zu öffnen.
Sehen Sie sich den HTML-Quellcode an, um die erforderlichen HTML-Selektoren zu identifizieren. Suchen Sie insbesondere nach den Elementen, die den Produktnamen und den Preis enthalten.
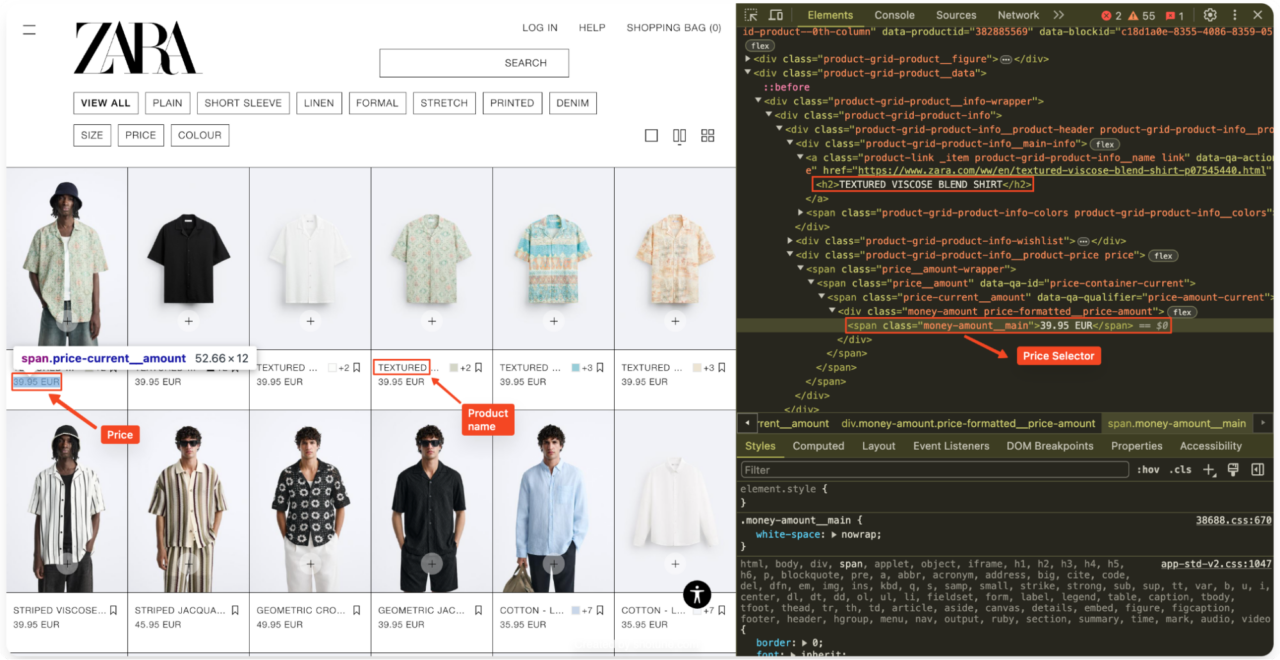
Bei Zara sind die Produktinformationen in der Regel in einem
product-grid-product-infoDer Produktname steht normalerweise innerhalb einer
Tag, und der Preis liegt innerhalb einermoney-amount__main.
Schritt 3: Erstellen der Spinne
Nun navigiere ich zum spiders Verzeichnis in meinem Projekt und erstelle eine neue Datei namens zara_spider.py. Diese Datei enthält die Logik zum Scraping der Zaras-Website.
cd spiders
touch zara_spider.py
Schritt 4: Definieren der ScraperAPI-Methode
Ich werde ScraperAPI verwenden, um mögliche Blockierungs- und JavaScript-Rendering-Probleme zu behandeln. Ich werde meine Anfrage über den Server von ScraperAPI senden, indem ich meine Abfrage-URL an die von ScraperAPI bereitgestellte Proxy-URL anhänge, indem ich
payload Und urlencode.
Oben zara_spider.pyimportieren Sie die erforderlichen Bibliotheken:
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
Hier ist der Code für die ScraperAPI-Integration:
APIKEY = "YOUR_SCRAPERAPI_KEY"
def get_scraperapi_url(url):
payload = {'api_key': APIKEY, 'url': url, 'render': True}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
Das get_scraperapi_url() Die Funktion verwendet eine URL als Eingabe, fügt meinen ScraperAPI-Schlüssel hinzu und gibt eine geänderte URL zurück. Diese geänderte URL leitet unsere Anfragen über ScraperAPI weiter, wodurch das Erkennen und Blockieren unserer Scraping-Aktivitäten für Websites schwieriger wird.
Wichtig: Vergessen Sie nicht, „ zu ersetzen.YOUR_SCRAPERAPI_KEY“ mit Ihrem aktuellen API-Schlüssel von ScraperAPI.
Schritt 5: Schreiben der Haupt-Spider-Klasse
In Scrapy kann ich verschiedene Klassen, sogenannte Spider, erstellen, um bestimmte Seiten oder Sitegruppen zu scrapen. Nachdem ScraperAPI eingerichtet ist, kann ich mit dem Schreiben der Haupt-Spider-Klasse beginnen. Diese Klasse beschreibt, wie unser Scraper mit Zaras Website interagieren wird.
Hier ist der Code für unsere ZaraProductSpider Klasse:
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
urls = (
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=2',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=3'
)
for url in urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
In diesem Code habe ich eine Klasse namens ZaraProductSpiderdas Eigenschaften von Scrapys Basis erbt Spider Klasse. Diese Vererbung macht unsere Klasse zu einer 'Kratzspinne'.
Innerhalb der Klasse, name = "zara_products" definiert den Namen unseres Spiders. Wir werden diesen Namen später verwenden, um den Spider von unserem Terminal aus auszuführen. Der
start_requests Die Methode definiert den Startpunkt des Spiders, indem sie die URLs angibt, die wir scrapen möchten. In diesem Fall ziele ich auf die ersten drei Seiten der Herrenhemden-Abteilung auf der Website von Zara.
Der Code durchläuft dann jede URL im urls Liste und verwendet Scrapys Request-Objekt, um den HTML-Inhalt jeder Seite abzurufen. Die
callback=self.parse Argument weist Scrapy an, den
parse Methode (die wir als nächstes definieren), um den heruntergeladenen Inhalt zu verarbeiten.
Schritt 6: Analysieren der HTML-Antwort
Es ist Zeit zu definieren, parse Methode, die den HTML-Inhalt verarbeitet, den ich von Zara heruntergeladen habe.
def parse(self, response):
soup = BeautifulSoup(response.body, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('h2').get_text(strip=True) if product.select_one('h2') else None
price = product.select_one('span.money-amount__main').get_text(strip=True) if product.select_one('span.money-amount__main') else None
yield {
'product_name': product_name,
'price': price,
}
Die Parse-Methode erhält den heruntergeladenen HTML-Inhalt als Antwortobjekt. Ich erstelle dann ein BeautifulSoup-Objekt namens soup um diese HTML-Antwort zu analysieren.
Der Code durchläuft dann alle
the class
product-grid-product-infodie ich zuvor als Container für Produktinformationen identifiziert habe.
Für jedes Produkt extrahiere ich den Produktnamen aus dem
Tag und der Preis aus dem
Tag mit der Klasse money-amount__main.
ich benutzte get_text(strip=True) um zusätzliche Leerzeichen aus dem extrahierten Text zu entfernen. Wenn ein Tag nicht gefunden wird, setze ich den entsprechenden Wert (Produktname oder Preis) auf None.
Schließlich erstelle ich ein Wörterbuch mit dem extrahierten Produkt
name Und price for each product. Dadurch kann Scrapy die Daten sammeln und weiterverarbeiten, beispielsweise in einer Datei speichern.
Schritt 7: Ausführen der Spinne
Wenn mein Spider vollständig codiert ist, kann ich ihn mit dem folgenden Befehl ausführen:
scrapy crawl zara_products
Dieser Befehl weist Scrapy an, den Spider zara_products auszuführen. Scrapy sendet nun die Anfragen an die Website von Zara, verarbeitet das heruntergeladene HTML, extrahiert die Produktdaten basierend auf meiner definierten Logik und gibt die Daten an die Konsole aus.
Schritt 8: Speichern der Preisdaten
Obwohl das Anzeigen der extrahierten Daten in der Konsole beim Debuggen hilfreich ist, speichere ich die Daten lieber zur späteren Verwendung. Scrapy vereinfacht diesen Prozess durch integrierte Unterstützung für den Export von Daten in verschiedene Formate, einschließlich CSV.
Um meine extrahierten Daten in einer CSV-Datei zu speichern, verwende ich den folgenden Befehl:
scrapy crawl zara_products -o zara_mens_prices.csv
Dieser Befehl führt den zara_products Spider und speichert die extrahierten Daten in einer Datei namens zara_mens_prices.csv. Die
-o Option gibt an, dass ich eine Datei ausgeben möchte. Es erstellt eine neue Datei und fügt die Scraped-Daten darin ein.
Schritt 9: Vollständiger Code und Ergebnisse.
Hier ist der vollständige Code für meine Spinne:
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
def get_scraperapi_url(url):
APIKEY = "YOUR_SCRAPERAPI_KEY"
payload = {'api_key': APIKEY, 'url': url, 'render': True}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
urls = (
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=2',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=3'
)
for url in urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
def parse(self, response):
soup = BeautifulSoup(response.body, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('h2').get_text(strip=True) if product.select_one('h2') else None
price = product.select_one('span.money-amount__main').get_text(strip=True) if product.select_one('span.money-amount__main') else None
yield {
'product_name': product_name,
'price': price,
}
Wichtig: Denken Sie daran, zu ersetzen
YOUR_SCRAPERAPI_KEY mit Ihrem aktuellen API-Schlüssel von Scraper API.
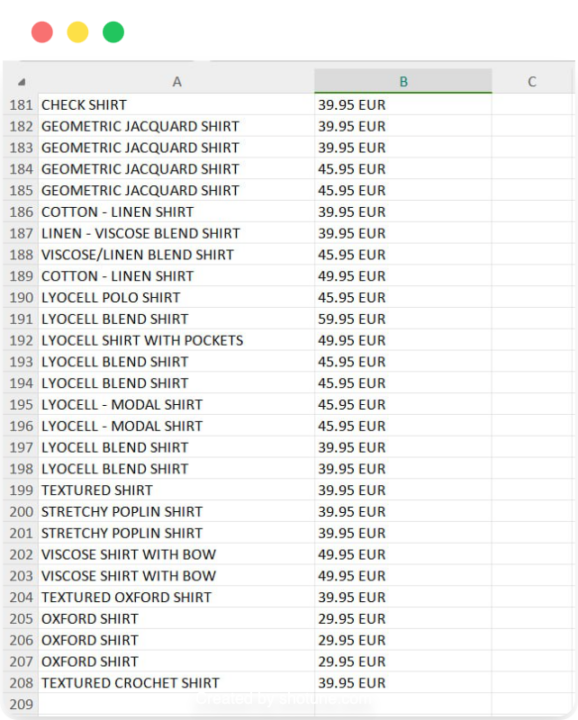
Und da haben Sie es! Sie haben jetzt eine CSV-Datei mit Produktnamen und Preisen aus den ersten drei Seiten der Herrenhemden-Abteilung von Zara, bereit für weitere Analysen oder die Verwendung in anderen Anwendungen.
Scraping von Preisen mit ScraperAPI SDEs
Die Structured Data Endpoints (SDEs) von ScraperAPI vereinfachen den Prozess des Scrapings von Produktpreisen, indem sie strukturierte Daten im JSON-Format bereitstellen. Anstatt sich mit komplizierter HTML-Analyse und Website-Änderungen zu befassen, stellen SDEs strukturierte Daten bereit, oft in einem praktischen JSON- oder CSV-Format, wodurch die Datenextraktion schneller und weniger fehleranfällig wird.
Notiz: Prüfen Sie die SDE-Dokumentation.
Lassen Sie uns untersuchen, wie Sie ScraperAPI SDEs verwenden können, um Produktpreise von großen E-Commerce-Plattformen zu scrapen:
Amazon Produktpreise
Es ist keine Kleinigkeit, Amazons Anti-Bot-Mechanismen zu umgehen, wenn man Produktdaten in großem Umfang ausliest. Zu den Herausforderungen, denen Sie begegnen könnten, gehören IP-Blockierung, CAPTCHAs und häufige Änderungen an den Produktseiten.
Glücklicherweise sind die Amazon SDEs von ScraperAPI darauf ausgelegt, diese Herausforderungen zu bewältigen und saubere Produktdaten bereitzustellen, einschließlich der oft nachgefragten Preise.
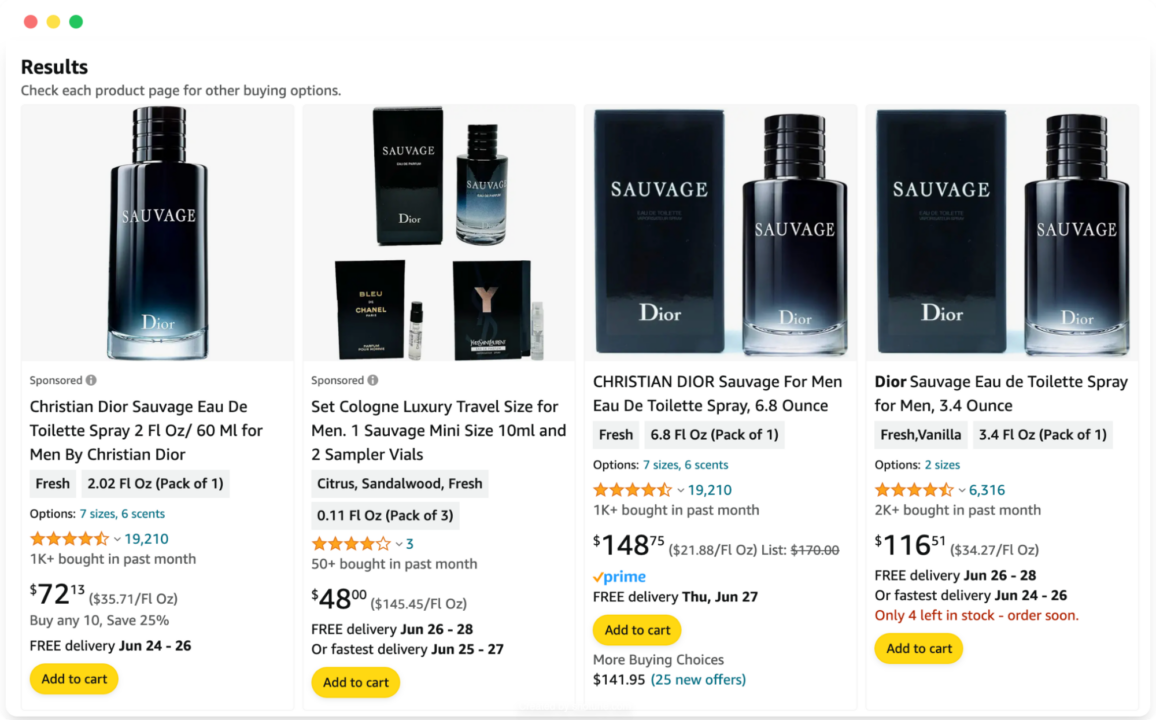
Das Scraping von Produktpreisen von Amazon mithilfe der Amazon-Such-API ist bemerkenswert unkompliziert. Sie können strukturierte Daten im JSON-Format sammeln, indem Sie eine einfache API-Anfrage stellen:
import requests
import json
APIKEY= "YOUR_SCRAPER_API_KEY" # Replace with your ScraperAPI key
QUERY = "Sauvage Dior"
payload = {'api_key': APIKEY, 'query': QUERY, 'country': 'us'}
r = requests.get('https://api.scraperapi.com/structured/amazon/search', params=payload)
# Parse the response text to a JSON object
data = r.json()
with open('amazon_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in amazon_results.json")
In diesem Code definieren wir zunächst unseren API-Schlüssel und die Suchanfrage. Anschließend konstruieren wir die Nutzlast mit dem api_key, queryund optional country_code Parameter.
Notiz: Sie können auch bestimmte TLDs festlegen, um lokalisiertere Daten zu erhalten.
Die Anfrage wird an den ScraperAPI-Endpunkt gesendet und bei Erfolg wird die Antwort in ein JSON-Objekt geparst. Dieses JSON-Objekt enthält alle Produktinformationen, einschließlich der Produktpreise. Schließlich werden die Daten in einer Datei mit dem Namen gespeichert. amazon_results.json.
{
"results": (
{
"type": "search_product",
"position": 1,
"asin": "B014MTG78S",
"name": "Christian Dior Sauvage Eau de Toilette for Men, 2 Ounce",
"image": "https://m.media-amazon.com/images/I/4140FetAgkL.jpg",
"has_prime": true,
"is_best_seller": false,
"is_amazon_choice": false,
"is_limited_deal": false,
"purchase_history_message": "800+ bought in past month",
"stars": 4.6,
"total_reviews": 19210,
"url": "https://www.amazon.com/Sauvage-Christian-Dior-Toilette-Ounce/dp/B014MTG78S/ref=sr_1_1?dib=eyJ2IjoiMSJ9.Fx8LrOyO3CO4VY3zYWkqSe6-HzohovLm08Mkg8Nhgv3folygQwBLui6jDIIPKugSKh4IuQoglcYFl-hTDoa_asMO1TR0AmgUv4w_kLY2WzF8Hf3XuPzIOe97F9kk71M75FofVmcOnoN7U_XYoAw4fddsl9uF8aFAOxfIP0O4Q_GU-BJbRZ7bZrwKqJb_dFHYzNxp-OYwpQBcWStRkJnHiLPgqqG1H4Nh9y8mngo4tnE-5ZWlz3AfcCWueqdASDLKB0ec3OhGATmQ70-yJILtXRjJ6OBuuyChX7HNIEBzEcg.i29lFhcRatBkMJ6pkTgb33fotRSWWjCUhV87WGhB1Wo&dib_tag=se&keywords=Sauvage+Dior&qid=1718868400&sr=8-1",
"availability_quantity": 1,
"spec": {},
"price_string": "$86.86",
"price_symbol": "$",
"price": 86.86,
"original_price": {
"price_string": "$92.99",
"price_symbol": "$",
"price": 92.99
}
}, //TRUNCATED
}
Sie können Ihre Datenerfassung anpassen, indem Sie zusätzliche Parameter in der API-Anfrage verwenden, z. B. indem Sie das Land für die Amazon-Domäne angeben (country), Festlegen des Ausgabeformats (output_format) und die Implementierung der Paginierung (page), um Ergebnisse von mehreren Seiten abzurufen.
Die Amazon-Such-API-Dokumentation bietet eine vollständige Liste der verfügbaren Parameter und erweiterter Anwendungsfälle.
Profi-Tipp
Wenn Sie nur Produktpreise abrufen möchten, können Sie die JSON-Schlüssel verwenden, um bestimmte Werte auszuwählen. Lassen Sie uns für dieses Beispiel den Namen, den Preis, die Währung und die URL für jedes Produkt abrufen:
Erstellen wir zunächst oben in unserer Datei eine leere Liste:
Als nächstes speichern wir alle organischen Produktergebnisse (innerhalb der
resultsSchlüssel) in einenall_productsVariable:all_products = data('results')Jetzt können wir jedes Produkt durchlaufen und die spezifischen Informationen extrahieren, die uns interessieren.
Eine Sache jedoch. Auf der Amazon-Suchergebnisseite haben einige Produkte keine Preise, sodass ScraperAPI die
priceSchlüssel. Um Probleme zu vermeiden, überprüfen wir, ob derpriceDer Schlüssel befindet sich in den Produktinformationen, bevor sein Wert an unsere leere Liste angehängt wird.for product in all_products: product_name = product('name') product_url = product('url') #checking if the product has the price key if 'price' in product: product_price = product('price') product_currency = product('price_symbol') #appeding the product information to our list product_prices.append({ 'name': product_name, 'price': product_price, 'currency': product_currency, 'url': product_url }) else: product_prices.append({ 'name': product_name, 'price': 'not found', 'url': product_url })Durch die Verwendung von JSON-Schlüssel-Wert-Paaren ist es einfach, bestimmte Datenpunkte aus der Antwort zu erhalten. Jetzt müssen wir nur noch
dump()Die
product_pricesListe in eine JSON-Datei, wie wir es zuvor getan haben:with open('amazon_results.json', 'w') as json_file: json.dump(product_prices, json_file, indent=4) print("Results have been stored in amazon_results.json")Sie können für die anderen SDEs ein ähnliches Verfahren verwenden.
Ressource: Erfahren Sie, wie Sie mit Python und ScraperAPI Amazon-Produktdaten scrapen.
Walmart-Produktpreise
Wie Amazon stellt Walmart aufgrund seiner Bot-Erkennungsmaßnahmen und der sich ständig ändernden Website-Struktur eine Herausforderung für herkömmliche Scraping-Methoden dar. Die Walmart-API von ScraperAPI umgeht diese Hindernisse und liefert Ihnen direkt strukturierte Produktdaten, einschließlich Preise.
Hier ist ein einfaches Beispiel, das zeigt, wie man Produktpreise von Walmart abruft:
import requests
import json
APIKEY= "YOUR_SCRAPER_API_KEY" # Replace with your ScraperAPI key
QUERY = "Sauvage Dior"
payload = {'api_key': APIKEY, 'query': QUERY, 'page': '2'}
r = requests.get('https://api.scraperapi.com/structured/walmart/search', params=payload)
data = r.json()
# Write the JSON object to a file
with open('walmart_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in walmart_results.json")
In diesem Code definieren wir unsere api_key und das
query und geben Sie den page Nummer für die Paginierung. Die Anfrage wird an den Walmart Search API-Endpunkt gesendet und bei Erfolg wird die Antwort in ein JSON-Objekt analysiert und gespeichert in
walmart_results.json.
{
"items": (
{
"availability": "In stock",
"id": "52HDEPYCF0WO",
"image": "https://i5.walmartimages.com/seo/Dior-Sauvage-Eau-de-Parfum-300ml_3bb963cb-2769-4c61-b2b7-9bc5fc35e864.119f0ebb7fea31368d709ea899cbe13f.jpeg?odnHeight=180&odnWidth=180&odnBg=FFFFFF",
"sponsored": true,
"name": "Dior Sauvage Eau de Parfum 300ml",
"price": 245.95,
"price_currency": "$",
"rating": {
"average_rating": 0,
"number_of_reviews": 0
},
"seller": "Ultimate Beauty SLU",
"url": "https://www.walmart.com/ip/Dior-Sauvage-Eau-de-Parfum-300ml/2932396976"
}, //TRUNCATED
),
"meta": {
"page": 2,
"pages": 25
}
}
Sie können Ihre Datenextraktion mithilfe von Parametern wie
output_format um CSV- oder JSON-Ausgabe anzugeben. Eine umfassende Liste der Parameter und ihrer Verwendung finden Sie in der Walmart Search API-Dokumentation.
Ressource: Erfahren Sie, wie Sie mit Python und ScraperAPI Walmart-Produktdaten scrapen.
Google Shopping-Produktpreise
Aufgrund der dynamischen Inhaltslade- und Anti-Scraping-Mechanismen kann es schwierig sein, Google Shopping mit herkömmlichen Methoden effektiv zu scrapen. Die Google Shopping API von ScraperAPI vereinfacht diesen Prozess erheblich, indem sie saubere, strukturierte Produktdaten, einschließlich Preisen, liefert.
Hier ist ein einfaches Beispiel, das zeigt, wie Produktdaten aus Google Shopping extrahiert werden:
import requests
import json
APIKEY= "YOUR_SCRAPER_API_KEY" # Replace with your ScraperAPI key
QUERY = "Chop sticks"
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'jp'}
r = requests.get('https://api.scraperapi.com/structured/google/shopping', params=payload)
# Parse the response text to a JSON object
data = r.json()
# Write the JSON object to a file
with open('google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in google_results.json")
Hier definiere ich meinen API-Schlüssel und die Suchanfrage. Nachdem ich meine Nutzlast erstellt habe, wird die Anfrage an die Google Shopping SDE gesendet.
Bei einer erfolgreichen Antwort werden die Daten in ein JSON-Objekt geparst und gespeichert in
google_results.json.
{
"search_information": {},
"ads": (),
"shopping_results": (
{
"position": 1,
"docid": "9651870852817516154",
"link": "https://www.google.co.jp/url?url=https://www.amazon.co.jp/GLAMFIELDS-Fiberglass-Chopsticks-Reusable-Dishwasher/dp/B08346GNS5%3Fsource%3Dps-sl-shoppingads-lpcontext%26ref_%3Dfplfs%26ref_%3Dfplfs%26psc%3D1%26smid%3DA1IXFONC0DTBL5&rct=j&q=&esrc=s&opi=95576897&sa=U&ved=0ahUKEwjjwoXJ2-mGAxXonYQIHebrDoAQ2SkIxQg&usg=AOvVaw0dYnZyMtnWgRJvjmYNuAx0",
"title": "GLAMFIELDS 10 Pairs Fiberglass Chopsticks, Reusable Japanese Chinese Chop Sticks ...",
"source": "Amazon\u516c\u5f0f\u30b5\u30a4\u30c8",
"price": "\uffe52,240",
"extracted_price": 22.4,
"thumbnail": "https://encrypted-tbn0.gstatic.com/shopping?q=tbn:ANd9GcTMdg46wyytkT3p9bvEKBZwtpdyRI97OGHmJBLQIyDjX1JC6Hm3WPEZUrGzJLqnB3Y3tKA6cFbq0gYUJF0XcBlh77VPy7xWVY79HyTtujQdohmytfoKZWnm&usqp=CAE",
"delivery_options": "\u9001\u6599 \uffe5642",
"delivery_options_extracted_price": 6.42
}, //TRUNCATED
}
Eine ausführliche Erläuterung aller verfügbaren Parameter finden Sie in der Google Shopping API-Dokumentation.
