
Immobilienscout24 ist Deutschlands führendes Immobilienportal mit einer riesigen Datenbank an Immobilien. Ähnlich wie beliebte US-Plattformen wie Redfin und Zillow bietet Immobilienscout24 eine benutzerfreundliche Oberfläche zum Suchen und Vergleichen von Wohnungen, Häusern, Gewerbeflächen und Grundstücken. Die umfangreichen Filteroptionen erleichtern das Finden des perfekten Angebots.
Im Gegensatz zu seinen amerikanischen Pendants konzentriert sich Immobilienscout24 speziell auf den deutschen Immobilienmarkt, der für seine Stabilität bekannt ist. Der Zugriff auf diese Daten ist für Analysten, Investoren und Immobilienagenturen von unschätzbarem Wert, was Immobilienscout24.de zu einem attraktiven Ziel für Data Scraping macht.
Einführung zum Immobilienscout24.de Scraping
Wie bereits erwähnt, ist Immobilienscout24.de eine hervorragende Ressource für die Suche nach Immobilien in Deutschland. Leider ist die Site hauptsächlich auf Deutsch. Es gibt zwar Entwicklerbereiche mit Dokumentation für die offizielle API von Immobilienscout24.de, aber darauf werden wir später noch genauer eingehen. Bevor wir uns mit der Datenextraktion von Immobilienscout24.de befassen, machen wir uns mit den wichtigsten Begriffen vertraut, die häufig in Auflistungen verwendet werden. Obwohl die Benutzeroberfläche der Site recht benutzerfreundlich ist, wird das Verständnis dieser Begriffe unsere Fähigkeit erheblich verbessern, die benötigten Informationen genau und effizient zu extrahieren. Zu den wichtigsten Begriffen gehören:
- Miete – Rent. Dies gibt die monatlichen Kosten für die Miete einer Immobilie an.
- Kaufpreis – Purchase price. Hiermit werden die Gesamtkosten für den Kauf einer Immobilie angegeben.
- Nebenkosten – Zusätzliche Kosten. Dabei handelt es sich um zusätzliche Gebühren, die zur Grundmiete oder zum Kaufpreis hinzukommen (z. B. Nebenkosten).
- Wohnfläche. Hiermit ist die Gesamtquadratmeterzahl aller Wohnräume in der Immobilie gemeint.
- ZimmerDie Anzahl der Zimmer ist ein entscheidender Faktor bei der Immobiliensuche.
Wenn Sie diese Begriffe verstehen, können Sie Ihren Datenextraktionsprozess optimieren und die relevantesten Informationen aus den Einträgen extrahieren.
Vorbereitung für Web Scraping
Bevor wir ein Datenextraktionstool erstellen, müssen wir zunächst die spezifischen Daten identifizieren, die wir erfassen möchten. Dazu gehört, dass wir ihren genauen Standort auf der Zielwebsite bestimmen und ihre zugrunde liegende Struktur verstehen. Diese erste Analyse hilft uns bei der Auswahl der am besten geeigneten Datenextraktionstechniken.
Zu Beginn führen wir eine gründliche Untersuchung der Struktur der Website durch. Dies hilft uns dabei, die Seitenelemente zu identifizieren, die die gewünschten Daten enthalten. Sobald wir ein klares Verständnis der Datenorganisation haben, können wir verschiedene Web Scraping-Methoden erkunden und den effektivsten Ansatz für unseren speziellen Anwendungsfall auswählen.
Analyse der Website-Struktur
Gehen wir zur Site und sehen wir, welche Art von Daten wir aus den Feldern abrufen können:
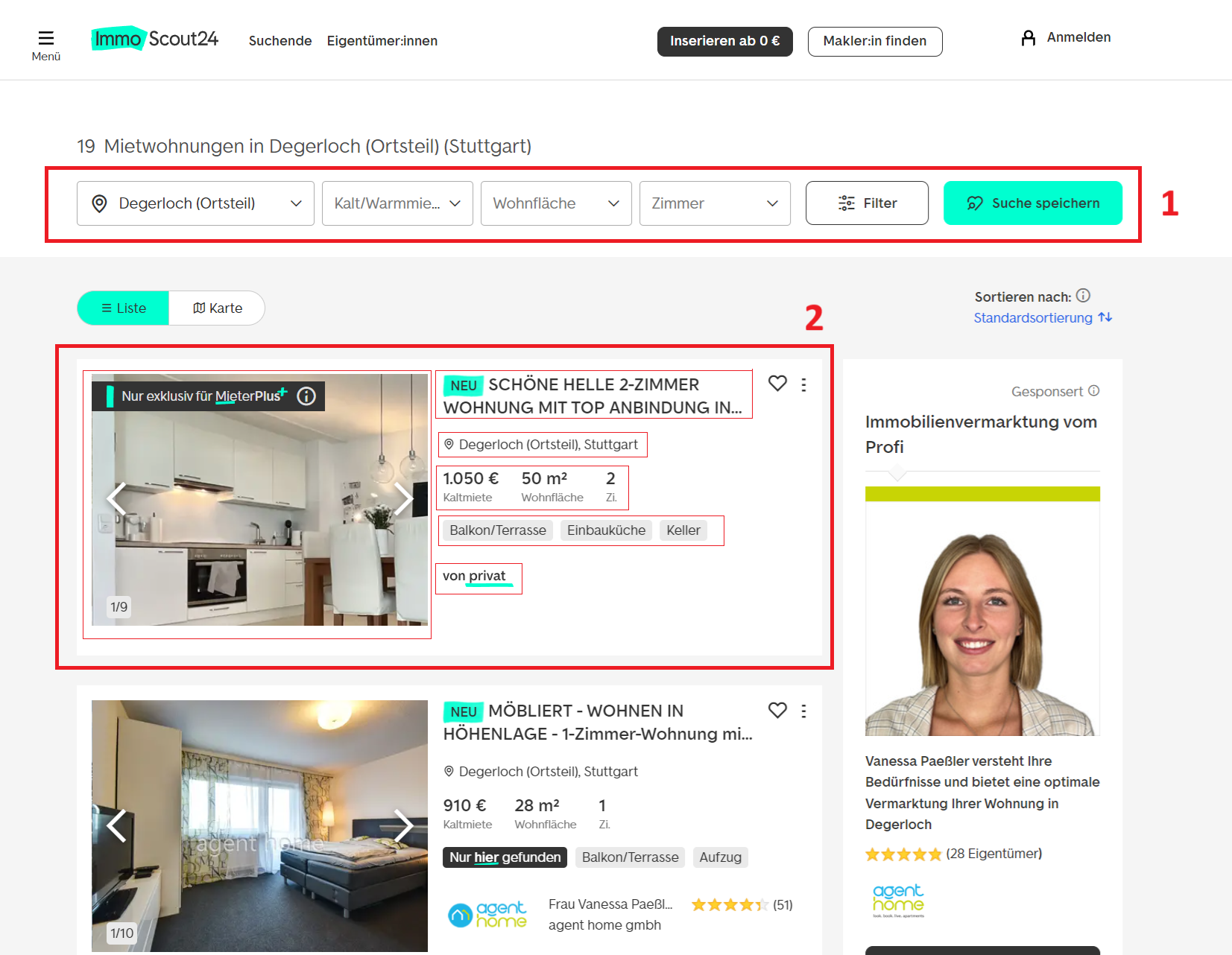
Die für uns wichtigsten Komponenten sind:
- Filter: Diese ermöglichen es uns, unsere Suche zu personalisieren und genau die Daten abzurufen, die wir benötigen.
- Notierung: Jeder Eintrag auf der Seite enthält alle erforderlichen Informationen, vom Titel und der Adresse bis hin zu Einzelheiten zur Agentur, Kosten, Ausstattung und anderen Parametern.
Beginnen wir mit den Filtern auf der Seite. Es stehen tatsächlich viel mehr Filteroptionen zur Verfügung als das, was zunächst oben angezeigt wird. Wenn wir zur speziellen Filterseite navigieren, finden wir eine viel breitere Palette von Kriterien. Mit diesen Filtern können Sie Ihre Suche nach Immobilientyp, Standort, Preisspanne, Anzahl der Zimmer und zusätzlichen Details wie der Erlaubnis von Haustieren, dem Baujahr oder der Art der Heizungsanlage verfeinern.
Zu den erweiterten Optionen gehören der Ausschluss bestimmter Immobilientypen, das Filtern nach Energieeffizienz oder sogar die Angabe einer Mindestinternetgeschwindigkeit. Dank dieser Flexibilität können Sie ganz einfach genau die Daten extrahieren, die Sie für Ihre Analyse benötigen.
Um die Abfrage entsprechend den erforderlichen Filtern zu personalisieren, ist es erforderlich, die Abfrageadresse zu ändern. Standardmäßig sieht die Suchzeichenfolge folgendermaßen aus:
https://www.immobilienscout24.de/Suche/de/Bereiten wir ein Basisskript vor, mit dem wir den erforderlichen Link dynamisch erstellen können. Die meisten Basisfilter werden dabei als Variablen platziert. Als Programmiersprache wählen wir Python, da es sich am besten für die Entwicklung von Scraping-Skripten eignet.
Zu Beginn erstellen wir eine Variable, in der wir die Basis-URL für die Immobiliensuche speichern:
base_url = "https://www.immobilienscout24.de/Suche/de/"Als Nächstes führen wir Variablen ein, um verschiedene Suchfilter darzustellen. Wir werden auch Kommentare hinzufügen, um ihren Zweck zu erklären:
state = "baden-wuerttemberg" # State in Germany
city = "stuttgart" # City
district_1 = "degerloch" # Main district
district_2 = "degerloch" # Sub-district (optional)
property_type = "wohnung" # Property type (e.g., 'wohnung' for apartment)
features = "mit-balkon" # Specific features (e.g., 'mit-balkon' for with balcony)
action = "mieten" # Action (e.g., 'mieten' for rent, 'kaufen' for buy)
price_type = "rentpermonth" # Pricing type (e.g., 'rentpermonth', 'totalprice')
origin = "result_list" # Origin of the search (usually 'result_list' when the search comes from the result list)Am Ende werden wir diese Variablen in einem gemeinsamen Link zusammenfassen:
constructed_url = (
f"{base_url}{state}/{city}/{district_1}/{district_2}/"
f"{property_type}-{features}-{action}?"
f"pricetype={price_type}&enteredFrom={origin}"
)Mit diesem Ansatz können wir unsere Abfragen in Zukunft durch einfaches Ändern von Variablen effektiver anpassen. Dies ist eine bequemere Methode, die den manuellen Arbeitsaufwand reduziert. Bei Bedarf können Sie die endgültige Datenerfassungs-URL jedoch weiterhin manuell eingeben. Wenn die Suchergebnisseite nicht genügend Informationen liefert, können Sie die erforderlichen Daten immer von der jeweiligen Listenseite abrufen. Im Allgemeinen enthält die Seite mit den einzelnen Eigenschaften die folgenden Informationen:
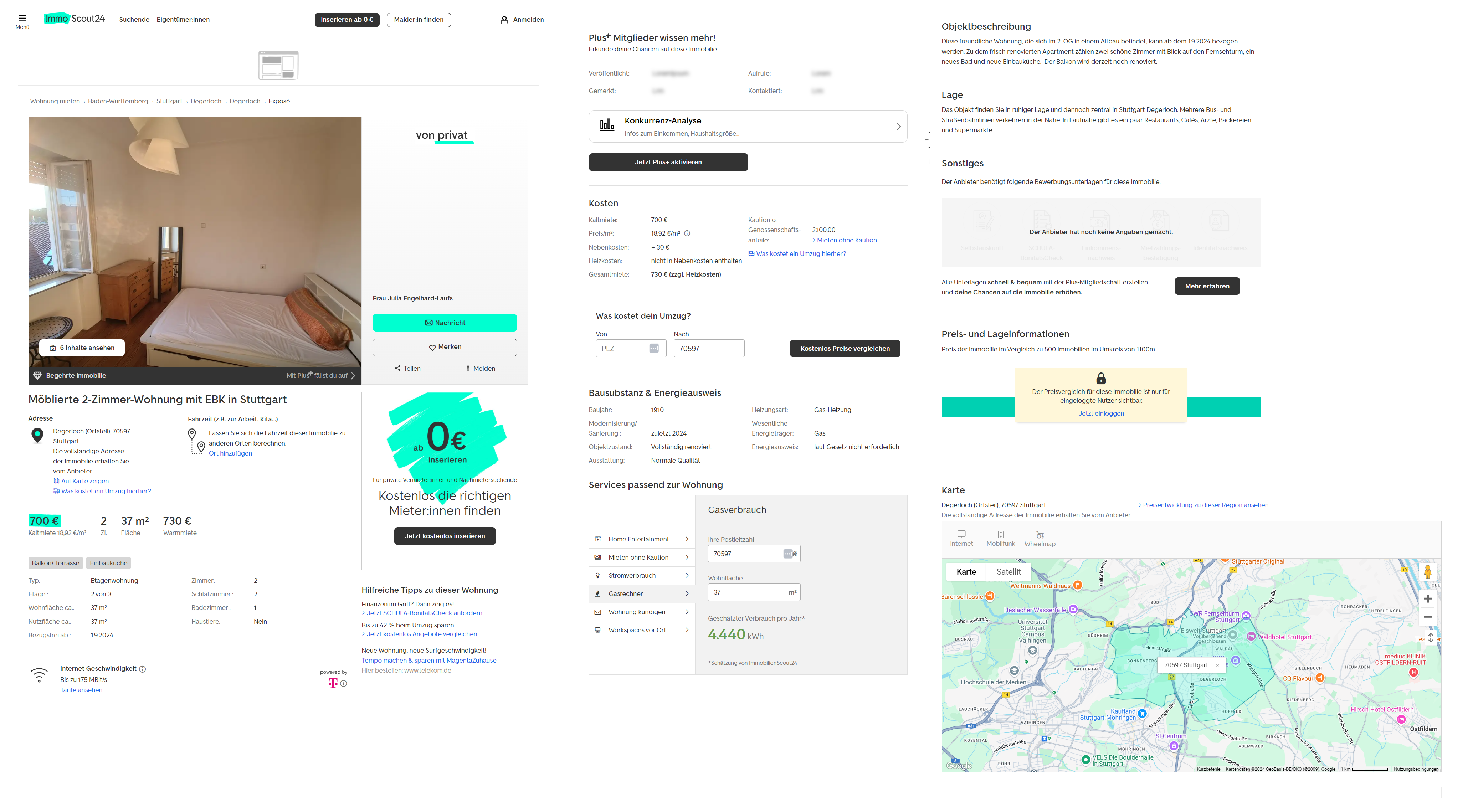
Wie Sie sehen, stehen Ihnen auf der Listing-Seite deutlich mehr Informationen zur Verfügung. Auch ohne die Daten, die nur registrierten Nutzern mit „Plus“-Accounts zur Verfügung stehen, ist der Detailumfang noch wesentlich höher.
In zukünftigen Beispielen werden wir das Scraping sowohl allgemeiner Suchergebnisseiten als auch einzelner Immobilieninserate untersuchen.
Auswählen einer Web Scraping-Methode
Bevor wir uns mit konkreten Beispielen für Data Scraping befassen, wollen wir die verschiedenen verfügbaren Methoden zum Extrahieren der benötigten Informationen skizzieren. Der optimale Ansatz hängt von Ihren technischen Fähigkeiten, der jeweiligen Aufgabe und der Zeit ab, die Sie in die Datenerfassung investieren möchten. Für das Scraping von ImmobilienScout24.de können Sie diese Optionen in Betracht ziehen:
- Manuelle Datenextraktion. Dies ist zwar die am wenigsten effiziente Methode, erfordert aber keine technischen Kenntnisse. Sie eignet sich für die einmalige Datenerfassung in kleinem Maßstab aus einer Handvoll Einträgen.
- Nutzung der ImmoScout24-API. Die Plattform bietet eine Vielzahl von APIs, die eine Interaktion mit ihren Inhalten ermöglichen. Weitere Einzelheiten finden Sie auf der offiziellen Entwicklerseite. Die Verwendung dieser APIs zum Datenscraping kann jedoch bestimmte Herausforderungen mit sich bringen:
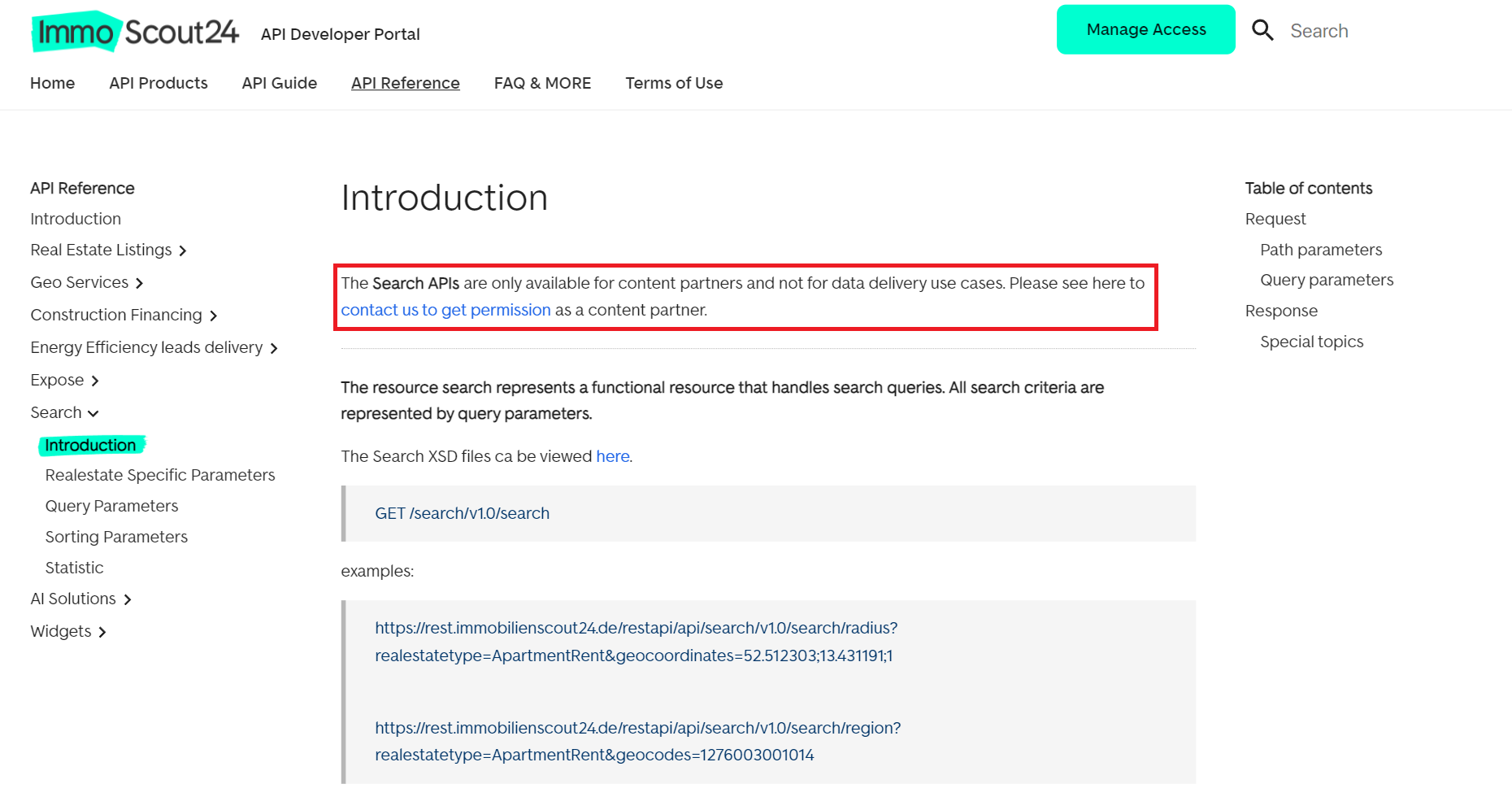
- Nutzung von APIs von Drittanbietern. Erwägen Sie die Verwendung von Tools von Drittanbietern, die für die Extraktion von Immobiliendaten entwickelt wurden. Diese Option ist oft einfacher und weniger restriktiv. Darüber hinaus kann sie helfen, gängige Scraping-Hindernisse zu umgehen.
- Erstellen eines benutzerdefinierten Scrapers. Dabei geht es darum, einen Scraper von Grund auf mit einer Programmiersprache Ihrer Wahl zu entwickeln. Seien Sie darauf vorbereitet, Herausforderungen wie CAPTCHAs zu bewältigen, die ImmoScout24 häufig verwendet, um verdächtige Aktivitäten zu erkennen.
In diesem Artikel untersuchen wir, wie man mit der API von HasData Immobiliendaten von ImmoScout24 scrapt und gehen auf die Erstellung eines benutzerdefinierten Python-Scrapers mit Bibliotheken wie Requests, BeautifulSoup4 und Selenium ein.
Scraping von Daten aus Immobilienangeboten
Beginnen wir unseren Leitfaden mit der Erkundung von Methoden zum Scrapen von Immoscout24-Daten aus Immobilienanzeigen. Um den Prozess der Generierung der erforderlichen URLs zu automatisieren, nutzen wir das zuvor besprochene Skript.
Jede Methode zur Datenextraktion hat ihre Vor- und Nachteile. Es ist wichtig zu beachten, dass die direkte Verwendung von Bibliotheken wie BeautifulSoup und Requests wahrscheinlich keine erfolgreichen Ergebnisse liefert, da Sie häufig auf CAPTCHAs stoßen. Daher liegt unser Hauptaugenmerk auf Web Scraping-APIs und der Selenium-Bibliothek, die menschliches Verhalten simulieren kann.
Verwenden von Requests und BeautifulSoup
Wie bereits erwähnt, ist es aufgrund verschiedener technischer Herausforderungen höchst unwahrscheinlich, dass das Extrahieren von Daten mithilfe von Requests und BeautifulSoup von dieser bestimmten Website erfolgreich sein wird. Lassen Sie uns jedoch zur Veranschaulichung untersuchen, wie dies versucht werden könnte, indem wir unser vorheriges Skript erweitern.
Importieren Sie zuerst die Bibliotheken:
import requests
from bs4 import BeautifulSoupNachdem Sie den Link erstellt haben, legen Sie den User Agent in den Anforderungsheadern fest und rufen Sie ihn auf, um die Seitenquelle oder etwaige Fehlermeldungen anzuzeigen:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
}
response = requests.get(constructed_url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
else:
print(f"Failed to retrieve the page. Status code: {response.status_code}")Anstatt den gesamten Code der Webseite abzurufen, verwenden wir CSS-Selektoren, um nur die genauen Daten zu ermitteln und zu extrahieren, die wir benötigen:
soup = BeautifulSoup(response.text, 'html.parser')
properties = soup.select(".grid-item.result-list-entry__data-container")
for property in properties:
title = property.select_one(".result-list-entry__brand-title").text.strip()
price = property.select_one(".result-list-entry__primary-criterion dd").text.strip()
area = property.select("dl.result-list-entry__primary-criterion dd")(1).text.strip()
rooms = property.select("dl.result-list-entry__primary-criterion dd")(2).text.strip()
location = property.select_one(".result-list-entry__address").text.strip()
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Area: {area}")
print(f"Rooms: {rooms}")
print(f"Location: {location}")
print("-" * 50)Leider führt der Versuch, diesen Code auszuführen, zu einem 401-Fehler. Bei der Überprüfung des Quellcodes der Seite wird eine Aufforderung zur Lösung eines CAPTCHA oder sogar Informationen zur Blockierung angezeigt. Wie wir anfangs warnten, wurde dieser Ansatz rein zu theoretischen Zwecken und aus Neugier hinsichtlich seiner potenziellen Durchführbarkeit untersucht.
Verwenden der Web Scraping API
Die zweite Methode, die wir untersuchen, beinhaltet die Verwendung der Web Scraping API von HasData, mit der Anti-Bot-Maßnahmen wie Blockierungen und CAPTCHAs umgangen werden können. Diese API ist sehr benutzerfreundlich und daher für Programmierer aller Fähigkeitsstufen geeignet.
Insgesamt ist es dem vorherigen Beispiel sehr ähnlich, mit der Ausnahme, dass die Anforderung an die Website über die API erfolgt. Darüber hinaus können Sie mit Google Colaboratory ein vorgefertigtes Skript anzeigen und ausführen.
Importieren wir zunächst die erforderlichen Bibliotheken:
import request
import json
from bs4 import BeautifulSoupAls Nächstes legen wir unseren HasData-API-Schlüssel und die URL der Immobilien-Listing-Seite fest. Sie können den Code aus dem vorherigen Beispiel verwenden, um diese URL zu generieren, aber wir legen sie hier manuell fest, um Wiederholungen zu vermeiden:
api_key = "YOUR-API-KEY"
scout_url = "https://www.immobilienscout24.de/Suche/de/baden-wuerttemberg/stuttgart/degerloch/degerloch/wohnung-mit-balkon-mieten?pricetype=rentpermonth&enteredFrom=result_list"Sie können Ihren HasData API-Schlüssel von Ihrem Konto erhalten, nachdem Sie sich auf unserer Website angemeldet haben.
Legen Sie die Header und den Endpunkt für die Web Scraping-API fest:
api_url = "https://api.hasdata.com/scrape/web"
headers = {
'Content-Type': 'application/json',
'x-api-key': api_key
}Dann legen wir die Parameter für die Anfrage selbst fest. Konkret verwenden wir deutsche Residential Proxies, um das Risiko einer Blockierung zu verringern, und aktivieren die Ausführung von JavaScript auf der Seite:
payload = json.dumps({
"url": scout_url,
"proxyType": "residential",
"proxyCountry": "DE",
"blockResources": False,
"blockAds": False,
"blockUrls": (),
"jsScenario": (),
"screenshot": False,
"jsRendering": True,
"excludeHtml": False,
"extractEmails": False,
"wait": 10
})Jetzt muss nur noch die Anfrage ausgeführt und das HTML der Seite mit BeautifulSoup analysiert werden:
response = requests.post(api_url, headers=headers, data=payload)
if response.status_code == 200:
response_data = response.json()
html_content = response_data.get("content")
if html_content:
soup = BeautifulSoup(html_content, 'html.parser')
properties = soup.select(".grid-item.result-list-entry__data-container")
data = ()
for property in properties:
title = property.select_one(".result-list-entry__brand-title").get_text(strip=True)
price = property.select_one("dl.result-list-entry__primary-criterion dd").get_text(strip=True)
area = property.select("dl.result-list-entry__primary-criterion dd")(1).get_text(strip=True)
rooms = property.select("dl.result-list-entry__primary-criterion dd")(2).get_text(strip=True)
location = property.select_one(".result-list-entry__address").get_text(strip=True)
data.append((title, price, area, rooms, location))
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Area: {area}")
print(f"Rooms: {rooms}")
print(f"Location: {location}")
print("-" * 50)
else:
print("Failed to retrieve HTML content.")
else:
print(f"API request failed: {response.status_code}, error message: {response.text}")Als Ergebnis erhalten wir nach dem Ausführen des Skripts die folgenden Daten:
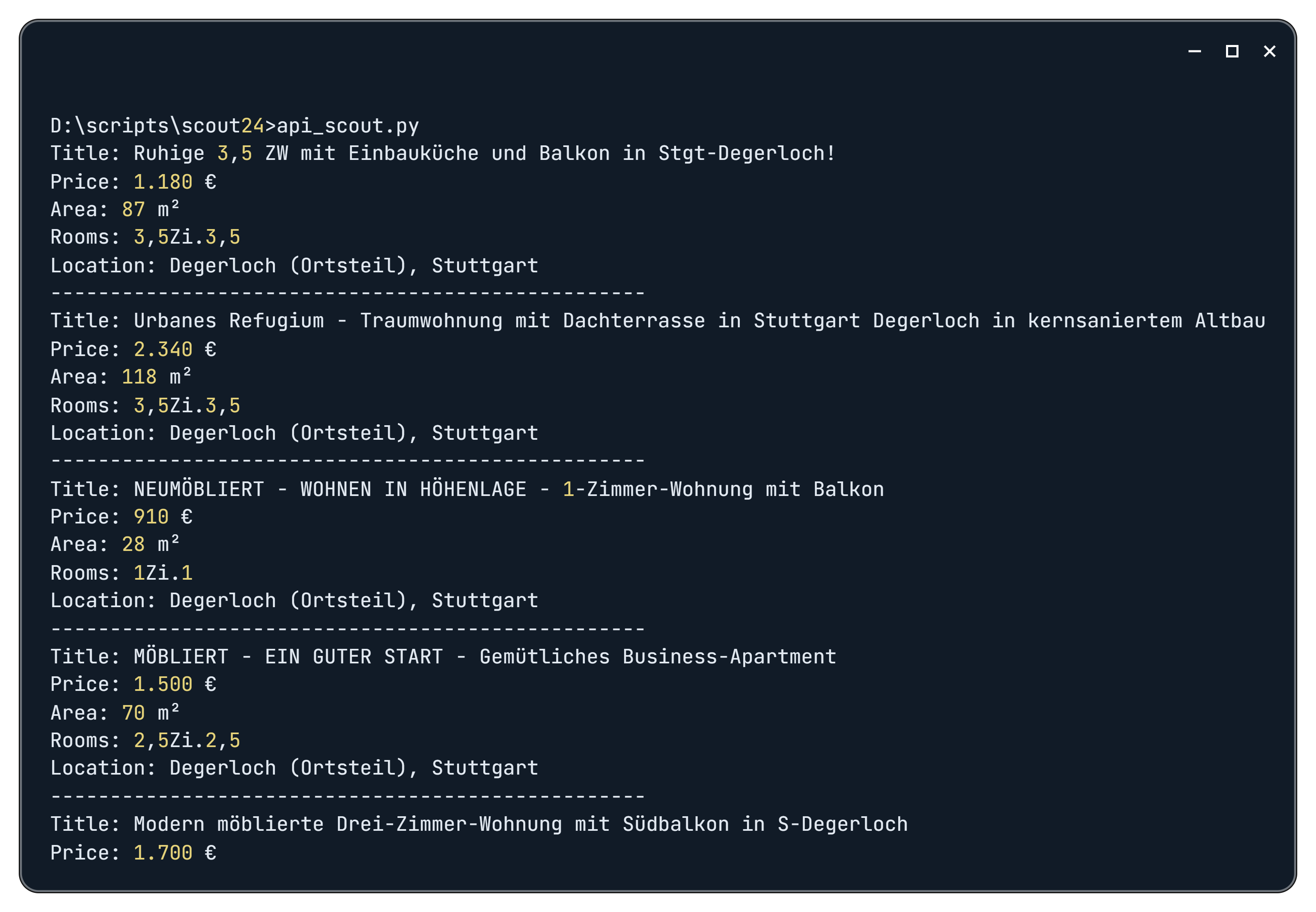
Um Ihre Analyse von Markttrends zu verbessern, sollten Sie Web Scraping in das Skript integrieren. Mit dieser Technik können zusätzliche Daten abgerufen werden, z. B. Informationen von Immobilienmaklern oder andere relevante Details. Um dies umzusetzen, definieren Sie einfach neue Variablen mit den entsprechenden CSS-Selektoren für die gewünschten Elemente.
Verwenden von Selenium für dynamische Inhalte
Die letzte Methode, die wir untersuchen, beinhaltet die Verwendung einer modifizierten Version der Selenium-Bibliothek und Headless-Browsern zum Daten-Scraping. Bevor wir uns in das Skript selbst vertiefen, untersuchen wir, was passiert, wenn wir mit Selenium zu einer Immobiliensuchseite navigieren.
Dazu importieren wir die benötigten Bibliotheken, navigieren zur Webseite und führen eine kurze Verzögerung ein:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)
url = "https://www.immobilienscout24.de/Suche/de/baden-wuerttemberg/stuttgart/degerloch/degerloch/wohnung-mit-balkon-mieten?pricetype=rentpermonth&enteredFrom=result_list"
driver.get(url)
time.sleep(10)
driver.quit()Während der Skriptausführung stoßen wir bei Scout24 auf einen 401-Fehler sowie auf eine Warnung, dass unsere Aktivität verdächtig und roboterhaft erscheint. Im Fehlerfall stellen sie einen Anforderungscode bereit und bitten uns, den Support zu kontaktieren.
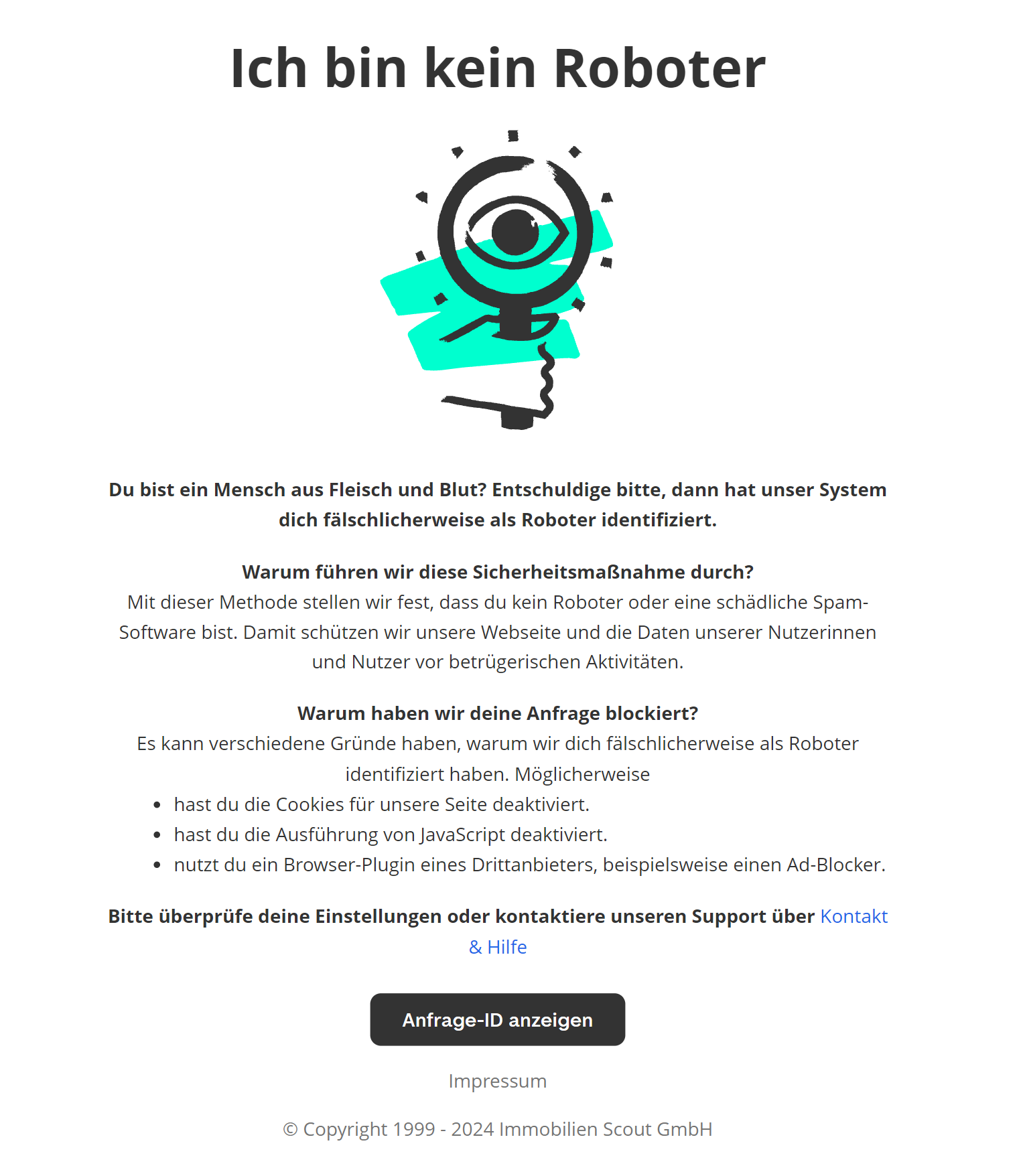
Wie man sieht, wird der Selenium-Webtreiber leider eindeutig als Bot identifiziert und es wird nicht einmal ein CAPTCHA angeboten. Dafür gibt es jedoch eine Lösung. SeleniumBase, eine modifizierte Version von Selenium, kann uns helfen, solche Probleme zu umgehen.
SeleniumBase wird hauptsächlich von Testern verwendet und eignet sich gut zum Durchführen von Tests. Dennoch bietet es Funktionen, mit denen wir die Blockierungsmechanismen von Scout24 umgehen können. Der UC-Modus (Undetected-Chromedriver Mode) von SeleniumBase ermöglicht es Bots, menschliches Verhalten nachzuahmen und so Anti-Bot-Systeme zu umgehen, die versuchen, sie zu blockieren oder CAPTCHAs auszulösen. Dies reicht jedoch möglicherweise nicht aus, da die Website häufig das Lösen eines CAPTCHAs erfordert.
Wir haben mehrere Möglichkeiten:
- Nutzen Sie deutsche Residential Proxies.
- Nutzen Sie Dienste zum Lösen von CAPTCHAs.
- Lösen Sie das CAPTCHA manuell und speichern Sie Cookies, Sitzungsdaten und den lokalen Speicher, um sie später wiederherzustellen.
Wir entscheiden uns für den letzten Ansatz. Zuerst müssen wir die Seite besuchen, das CAPTCHA lösen und die Daten speichern. Dafür verwenden wir ein separates Skript:
from seleniumbase import SB
import pickle
import time
with SB(uc=True) as sb:
sb.open("https://www.immobilienscout24.de/Suche/de/baden-wuerttemberg/stuttgart/degerloch/degerloch/wohnung-mit-balkon-mieten?pricetype=rentpermonth&enteredFrom=result_list")
time.sleep(20)
cookies = sb.get_cookies()
with open('cookies.pkl', 'wb') as file:
pickle.dump(cookies, file)
local_storage = sb.execute_script("return JSON.stringify(window.localStorage);")
with open('local_storage.json', 'w', encoding='utf-8') as file:
file.write(local_storage)
session_storage = sb.execute_script("return JSON.stringify(window.sessionStorage);")
with open('session_storage.json', 'w', encoding='utf-8') as file:
file.write(session_storage)Wir haben eine Verzögerung von 20 Sekunden eingeführt, damit Sie ausreichend Zeit haben, das CAPTCHA zu lösen. Auch wenn Sie kein Deutscher sind, können Sie es ganz einfach lösen, indem Sie das Bild mit den meisten Vorkommen auswählen.
Als nächstes erstellen wir ein neues Skript, in dem wir die zuvor gespeicherten Daten importieren und dann die erforderliche Seite wie in den vorherigen Beispielen analysieren:
from selenium.webdriver.common.by import By
from seleniumbase import SB
import pickle
import csv
import json
with SB(uc=True) as sb:
sb.open("https://www.immobilienscout24.de")
with open('cookies.pkl', 'rb') as file:
cookies = pickle.load(file)
for cookie in cookies:
sb.add_cookie(cookie)
with open('local_storage.json', 'r', encoding='utf-8') as file:
local_storage = file.read()
sb.execute_script(f"var items = JSON.parse(arguments(0)); for (var key in items) {{ window.localStorage.setItem(key, items(key)); }}", local_storage)
with open('session_storage.json', 'r', encoding='utf-8') as file:
session_storage = file.read()
sb.execute_script(f"var items = JSON.parse(arguments(0)); for (var key in items) {{ window.sessionStorage.setItem(key, items(key)); }}", session_storage)
sb.open("https://www.immobilienscout24.de/Suche/de/baden-wuerttemberg/stuttgart/degerloch/degerloch/wohnung-mit-balkon-mieten?pricetype=rentpermonth&enteredFrom=result_list")
properties = sb.find_elements(By.CSS_SELECTOR, ".grid-item.result-list-entry__data-container")
for property in properties:
title = property.find_element(By.CSS_SELECTOR, ".result-list-entry__brand-title").text.strip()
price = property.find_element(By.CSS_SELECTOR, "dl.result-list-entry__primary-criterion dd").text.strip()
area = property.find_elements(By.CSS_SELECTOR, "dl.result-list-entry__primary-criterion dd")(1).text.strip()
rooms = property.find_elements(By.CSS_SELECTOR, "dl.result-list-entry__primary-criterion dd")(2).text.strip()
location = property.find_element(By.CSS_SELECTOR, ".result-list-entry__address").text.strip()
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Area: {area}")
print(f"Rooms: {rooms}")
print(f"Location: {location}")
print("-" * 50)Da die erhaltenen Daten perfekt mit den vorherigen Ergebnissen der HasData-API übereinstimmen, verzichten wir auf eine detaillierte Analyse des Skripts. Bemerkenswerterweise bewältigt dieser Ansatz die meisten Herausforderungen beim Scraping von ImmobillenScout24.de effektiv.
Für maximale Zuverlässigkeit empfiehlt es sich, das Skript mit deutschen Proxys und einem CAPTCHA-Lösungsdienst zu ergänzen. Trotz seiner Wirksamkeit garantiert diese Methode keinen vollständigen Schutz vor Blockaden.
Scraping von Immobiliendaten
Das Scraping von Immobiliendaten weist viele Ähnlichkeiten mit dem Sammeln von Daten aus Immobilienanzeigen auf. Die Hauptunterschiede liegen in den spezifischen Elementen und Links, die gezielt angesprochen werden müssen.
Da wir bereits allgemeine Herausforderungen beim Scraping von Immobilien behandelt haben, wollen wir uns nun mit praktischen Beispielen unter Verwendung der API von HasData und SeleniumBase befassen. Dadurch können wir den grundlegenderen Ansatz mit Requests und BeautifulSoup umgehen.
Verwenden der Web Scraping API
Beginnen wir mit einer einfacheren Methode unter Verwendung der Web Scraping API von HasData. Wie zuvor benötigen Sie einen persönlichen API-Schlüssel, den Sie nach der Registrierung auf unserer Website von Ihrem Konto erhalten.
Sie können das vorgefertigte Skript auch in Colab Research finden, ausführen und damit experimentieren.
Der Großteil des Skripts, das mit der API von HasData interagiert, bleibt unverändert, mit Ausnahme des Seitenlinks:
from bs4 import BeautifulSoup
import requests
import json
import csv
api_key = "YOUR-API-KEY"
scout_url = "https://www.immobilienscout24.de/expose/153073358?referrer=RESULT_LIST_LISTING&searchId=cb9e25ee-fcc3-3365-be73-71e453b7abf5&searchUrl=%2Fde%2Fbaden-wuerttemberg%2Fstuttgart%2Fdegerloch%2Fdegerloch%2Fwohnung-mit-balkon-mieten%3Fpricetype%3Drentpermonth&searchType=district&fairPrice=FAIR_OFFER#/"
api_url = "https://api.hasdata.com/scrape/web"
headers = {
'Content-Type': 'application/json',
'x-api-key': api_key
}
payload = json.dumps({
"url": scout_url,
"proxyType": "residential",
"proxyCountry": "DE",
"blockResources": False,
"blockAds": False,
"blockUrls": (),
"jsScenario": (),
"screenshot": False,
"jsRendering": True,
"excludeHtml": False,
"extractEmails": False,
"wait": 10
})
response = requests.post(api_url, headers=headers, data=payload)
if response.status_code == 200:
response_data = response.json()
html_content = response_data.get("content")
if html_content:
soup = BeautifulSoup(html_content, 'html.parser')
# Here will be another code
else:
print("Failed to retrieve HTML content.")
else:
print(f"API request failed: {response.status_code}, error message: {response.text}")Allerdings müssen die Selektoren für die Daten, die wir extrahieren möchten, geändert werden:
data = {}
title = soup.find('h1', id='expose-title')
data('title') = title.get_text(strip=True) if title else None
address = soup.find('span', class_='zip-region-and-country')
data('address') = address.get_text(strip=True) if address else None
cold_rent = soup.find('div', class_='is24qa-kaltmiete-main is24-value font-semibold')
data('cold_rent') = cold_rent.get_text(strip=True) if cold_rent else None
warm_rent = soup.find('div', class_='is24qa-warmmiete-main is24-value font-semibold')
data('warm_rent') = warm_rent.get_text(strip=True) if warm_rent else None
area = soup.find('div', class_='is24qa-flaeche-main is24-value font-semibold')
data('area') = area.get_text(strip=True) if area else None
rooms = soup.find('div', class_='is24qa-zi-main is24-value font-semibold')
data('rooms') = rooms.get_text(strip=True) if rooms else None
floor = soup.find('dd', class_='is24qa-etage')
data('floor') = floor.get_text(strip=True) if floor else None
availability = soup.find('dd', class_='is24qa-bezugsfrei-ab')
data('availability') = availability.get_text(strip=True) if availability else None
for key, value in data.items():
print(f"{key}: {value}")Als Ergebnis erhalten wir folgende Daten:

Da die Seite eine Menge Daten enthält, können Sie dem Skript alle benötigten Variablen und Selektoren hinzufügen, um alle erforderlichen Informationen zu einer bestimmten Immobilie zu extrahieren.
Verwenden von Selenium für dynamische Inhalte
Wenn wir Selenium oder genauer SeleniumBase verwenden, bleibt der Prozess weitgehend gleich. Wir müssen lediglich die Such-URL ersetzen und die Selektoren aktualisieren. Der Großteil des Skripts bleibt unverändert:
from selenium.webdriver.common.by import By
from seleniumbase import SB
import pickle
import csv
with SB(uc=True) as sb:
sb.open("https://www.immobilienscout24.de")
with open('cookies.pkl', 'rb') as file:
cookies = pickle.load(file)
for cookie in cookies:
sb.add_cookie(cookie)
with open('local_storage.json', 'r', encoding='utf-8') as file:
local_storage = file.read()
sb.execute_script(f"var items = JSON.parse(arguments(0)); for (var key in items) {{ window.localStorage.setItem(key, items(key)); }}", local_storage)
with open('session_storage.json', 'r', encoding='utf-8') as file:
session_storage = file.read()
sb.execute_script(f"var items = JSON.parse(arguments(0)); for (var key in items) {{ window.sessionStorage.setItem(key, items(key)); }}", session_storage)
sb.open("https://www.immobilienscout24.de/expose/153073358?referrer=RESULT_LIST_LISTING&searchId=cb9e25ee-fcc3-3365-be73-71e453b7abf5&searchUrl=%2Fde%2Fbaden-wuerttemberg%2Fstuttgart%2Fdegerloch%2Fdegerloch%2Fwohnung-mit-balkon-mieten%3Fpricetype%3Drentpermonth&searchType=district&fairPrice=FAIR_OFFER#/") Wir ändern nur den Abschnitt, in dem wir die erforderlichen Daten extrahieren:
data = {}
title = sb.get_text("h1#expose-title")
data('title') = title.strip() if title else None
address = sb.get_text("span.zip-region-and-country")
data('address') = address.strip() if address else None
cold_rent = sb.get_text("div.is24qa-kaltmiete-main.is24-value.font-semibold")
data('cold_rent') = cold_rent.strip() if cold_rent else None
warm_rent = sb.get_text("div.is24qa-warmmiete-main.is24-value.font-semibold")
data('warm_rent') = warm_rent.strip() if warm_rent else None
area = sb.get_text("div.is24qa-flaeche-main.is24-value.font-semibold")
data('area') = area.strip() if area else None
rooms = sb.get_text("div.is24qa-zi-main.is24-value.font-semibold")
data('rooms') = rooms.strip() if rooms else None
floor = sb.get_text("dd.is24qa-etage")
data('floor') = floor.strip() if floor else None
availability = sb.get_text("dd.is24qa-bezugsfrei-ab")
data('availability') = availability.strip() if availability else None
for key, value in data.items():
print(f"{key}: {value}")Bevor Sie dieses Skript ausführen, müssen Sie jedoch unbedingt das zuvor erstellte Skript ausführen, das Cookies, Sitzungsdaten und lokalen Speicher speichert. Darüber hinaus empfehlen wir, eine Variable oder Datei zu erstellen, um alle für das Scraping erforderlichen URLs zu speichern. Auf diese Weise können Sie diese URLs in einem einzigen Skript durchlaufen.
Speichern von Scraped-Daten
In den vorherigen Beispielen haben wir einfache Druckanweisungen verwendet, um Daten auf dem Bildschirm anzuzeigen. Dies ist zwar für schnelle Überprüfungen praktisch, für die langfristige Speicherung oder Weitergabe jedoch nicht praktikabel. Sehen wir uns an, wie wir unsere Daten in Dateien speichern.
Zwei gängige Dateiformate zum Speichern strukturierter Daten sind JSON und CSV. Um mit diesen Formaten arbeiten zu können, müssen wir die entsprechenden Python-Bibliotheken importieren: json und csv.
import csv
import jsonEine CSV-Datei (Comma-Separated Values) ist eine reine Textdatei, die tabellarische Daten in einem für Menschen lesbaren Format speichert. Jede Zeile in einer CSV-Datei stellt eine Zeile dar, und jeder Wert innerhalb einer Zeile ist durch ein Komma getrennt:
with open('property_details.csv', mode="w", newline="", encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(data.keys())
writer.writerow(data.values())Die with-Anweisung stellt sicher, dass die Datei auch bei Auftreten einer Ausnahme ordnungsgemäß geschlossen wird. Das csv.writer-Objekt stellt Methoden zum Schreiben von Zeilen in die CSV-Datei bereit.
JSON (JavaScript Object Notation) ist ein einfaches Datenaustauschformat, das für Menschen leicht zu lesen und zu schreiben und für Maschinen leicht zu analysieren und zu generieren ist:
with open('property_details.json', mode="w", encoding='utf-8') as file:
json.dump(data, file, ensure_ascii=False, indent=4)Der json.dump() Funktion konvertiert ein Python-Objekt (in diesem Fall Daten) in einen JSON-String und schreibt ihn in die angegebene Datei. Die ensure_ascii=False Das Argument ermöglicht die korrekte Kodierung von Nicht-ASCII-Zeichen und indent=4 fügt Einrückungen zur besseren Lesbarkeit hinzu.
Fazit und Erkenntnisse
Dieser Artikel befasst sich mit den Herausforderungen und Lösungen im Zusammenhang mit dem Web Scraping von ImmobilienScout24.de. Wir haben eine Reihe von Techniken und Tools untersucht, um Daten effektiv von dieser Plattform zu extrahieren, und bieten praktische Beispiele und Codeausschnitte.
Unsere Ergebnisse zeigen, dass spezialisierte Web Scraping-APIs den robustesten und bequemsten Ansatz bieten. Durch die Nutzung dieser APIs können Entwickler den Datenextraktionsprozess optimieren und müssen sich nicht mehr mit Website-Blockaden, CAPTCHAs und anderen häufigen Hindernissen herumschlagen.
Für diejenigen, die eine genauere Kontrolle über den Scraping-Prozess wünschen, haben wir auch Selenium Base untersucht. Es ist jedoch wichtig zu beachten, dass die Verwendung von Selenium Base häufig zusätzliche Maßnahmen wie Proxyserver und CAPTCHA-Lösungsdienste erfordert, um die Stabilität und Zuverlässigkeit des Skripts sicherzustellen.
