
Python ist eine der besten Programmiersprachen für Web Scraping. Wenn Sie mit dem Scraping beginnen und Ihre Skripte erstellen, hängt die Wahl der Bibliothek häufig von Ihren persönlichen Vorlieben und Fähigkeiten ab. Es ist jedoch wichtig zu überlegen, ob die ausgewählte Bibliothek für die vorliegende Aufgabe geeignet ist.
Dieser Artikel befasst sich mit dem Bereich dynamischer Inhalte, grenzt diese von statischen Inhalten ab und zeigt auf, warum nicht alle Bibliotheken in Ihrem Arsenal zum Scraping dynamischer Websites geeignet sind. Darüber hinaus untersuchen wir Codebeispiele, mit denen Sie Daten von jeder Website sammeln können, sowie verschiedene Techniken und fortgeschrittene Konzepte zur Verfeinerung Ihres Scrapers.
Dynamische Inhalte verstehen
Bevor wir uns mit Beispielen für dynamisches Web Scraping befassen, wollen wir zunächst erklären, was dynamisches Web Scraping ist und worin es sich von statischen Inhalten unterscheidet. Wenn wir diesen Unterschied verstehen, können wir fundiertere Entscheidungen bei der Auswahl des richtigen Scraping-Tools treffen und den Entwicklungsprozess optimieren.
Statischer vs. dynamischer Inhalt
Statische Webseiten haben Inhalte, die für alle Benutzer gleich bleiben, unabhängig von ihren Aktionen oder der Tageszeit. Sie sind normalerweise in HTML, CSS und JavaScript geschrieben und als vorgenerierte Dateien auf dem Webserver gespeichert. Dadurch sind sie einfach zu erstellen und zu verwalten und werden in der Regel schnell geladen. Statische Webseiten können jedoch keine personalisierten Inhalte oder Echtzeitinformationen anzeigen.
Dynamische Webseiten hingegen generieren Inhalte spontan, basierend auf Benutzereingaben oder anderen Faktoren. Sie werden normalerweise in serverseitigen Programmiersprachen wie PHP, Python oder Node.js geschrieben und verwenden eine Datenbank zum Speichern von Daten. Dies macht ihre Entwicklung und Wartung komplexer, bietet jedoch ein breiteres Spektrum an Möglichkeiten, wie personalisierte Inhalte, Echtzeit-Updates und interaktive Elemente.
Gängige Technologien
Wie bereits erwähnt, handelt es sich bei statischem Inhalt auf einer Seite um festen Text, Bilder und andere Elemente, die vorab festgelegt sind und sich nach dem Laden der Seite nicht ändern. Normalerweise wird er mit einfachem HTML, CSS und JavaScript angezeigt.
Dynamische Inhalte hingegen werden basierend auf verschiedenen Faktoren wie Benutzeraktionen, Tageszeit oder externen Daten generiert oder geändert. Sehen wir uns einige gängige Möglichkeiten zur Implementierung dynamischer Inhalte an:
- PHP. Eine serverseitige Skriptsprache, die als Reaktion auf Benutzeranforderungen spontan HTML-Code generiert.
- AJAX. Eine Technik zum Laden von Teilen einer Seite, ohne die gesamte Seite neu zu laden.
- JavaScript. Eine clientseitige Skriptsprache, mit der Sie Seiteninhalte im Browser des Benutzers ändern können.
Trotz der Unterschiede in den für dynamische Inhalte verwendeten Technologien ist das allgemeine Prinzip hinter deren Abruf und Anzeige dasselbe: Daten in Echtzeit ändern und aktualisieren. In den folgenden Abschnitten werden wir uns eingehender mit diesen Prinzipien und ihren Implementierungsmethoden befassen.
Tools und Bibliotheken zum Scraping dynamischer Seiten in Python
Normalerweise kann der Inhalt einer dynamischen Webseite erst abgerufen werden, nachdem sie vollständig geladen wurde. Daher sind die Methoden, mit denen er abgerufen werden kann, auf solche beschränkt, die es ermöglichen, die Webseite vollständig zu laden, bevor ihr Inhalt abgerufen wird.
Betrachten wir die beliebtesten Python-Bibliotheken zum Scrapen und Parsen von Daten und prüfen wir, ob sie das Scrapen einer dynamischen Website ermöglichen. Wenn ja, geben wir Beispiele für ihre Verwendung an.
Schöne Suppe und dynamischer Inhalt
Die erste Bibliothek, die einem in den Sinn kommt, wenn es um Scraping geht, ist BeautifulSoup. Wie wir jedoch in anderen Artikeln erwähnt haben, können Sie mit BS4 nur den HTML-Code einer Seite analysieren und ihn nicht selbst abrufen.
In diesem Fall werden in der Regel einfache Anforderungsbibliotheken wie requests oder urllib verwendet, um den anfänglichen HTML-Code von einer Webseite abzurufen. Leider greift dieser traditionelle Ansatz zu kurz, wenn es um dynamische Inhalte geht, die kontinuierlich über JavaScript- oder AJAX-Anfragen geladen und aktualisiert werden.
Zum Scrapen dynamischer Websites, bei denen Interaktionen und Aktualisierungen nach dem ersten Laden der Seite erfolgen, sind Tools wie Selenium, Pyppeteer oder Playwright unverzichtbar. Diese Bibliotheken ermöglichen das automatisierte Durchsuchen und Interagieren mit Webseiten und ermöglichen das Abrufen von Inhalten, die erst nach Benutzeraktionen oder Echtzeitaktualisierungen angezeigt werden.
Obwohl BeautifulSoup für die statische HTML-Analyse nach wie vor von unschätzbarem Wert ist, ist für das Scraping moderner Webanwendungen, die stark auf dynamische Inhalte angewiesen sind, die Nutzung von Selenium oder ähnlichen Tools erforderlich.
Selenium, Pyppeteer oder Playwright
Wie bereits erwähnt, liegt die Lösung dieses Problems in der Verwendung von Headless-Browser-Bibliotheken wie Selenium, Puppeteer (ein Wrapper für Puppeteer) oder Playwright. Wir haben bereits Python-Bibliotheken für Headless-Browser verglichen und ihre Installation besprochen, daher werden wir hier nicht näher darauf eingehen.
Der allgemeine Prozess zum Scraping dynamischer Inhalte mithilfe von Headless-Browsern ist wie folgt:
- Konfigurieren Sie einen Headless-Browser. Richten Sie die Parameter des Headless-Browsers ein, beispielsweise Fenstergröße und Benutzeragent.
- Zur Zielseite navigieren. Laden Sie die Webseite, die Sie scrapen möchten.
- Warten Sie, bis die Seite geladen ist. Warten Sie, bis die gesamte Webseite vollständig geladen ist, einschließlich aller von JavaScript generierten dynamischen Inhalte.
- Scrapen Sie die Daten. Extrahieren Sie die gewünschten Daten aus der gerenderten Webseite.
- Schließen Sie den Browser. Schließen Sie die Headless-Browserinstanz.
Sobald die Webseite vollständig geladen ist, werden alle erforderlichen Daten geladen und generiert, sodass sie einfach erfasst werden können. Darüber hinaus können Sie mit diesen Bibliotheken die Aktionen eines echten Benutzers auf der Seite vollständig emulieren. Dies gibt Ihnen die Möglichkeit, die erforderlichen Parameter festzulegen und genau die Daten zu erhalten, die Sie benötigen.
Sehen wir uns nun Beispiele an und implementieren den zuvor besprochenen Algorithmus für die drei beliebtesten Bibliotheken, die Headless-Browser unterstützen. Beginnen wir mit Selenium und erstellen hierfür ein neues Skript, importieren alle erforderlichen Module und richten den Headless-Browser ein:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
url = "https://example.com"
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)Navigieren Sie mit der Methode driver.get() zur gewünschten Webseite:
driver.get(url)Beim Scraping dynamischer Webseiten ist es wichtig, zu warten, bis die Zielelemente geladen sind, bevor man versucht, mit ihnen zu interagieren oder Daten daraus zu extrahieren. Selenium bietet verschiedene Methoden zum Implementieren von Wartezeiten, jede mit ihren Vorteilen. Die einfachste Möglichkeit, Wartezeiten hinzuzufügen, besteht darin, time.sleep() festzulegen:
time.sleep(5)Oder Sie können Selenium verwenden, um dasselbe zu erreichen:
wait = WebDriverWait(driver, 10)Die letzte Möglichkeit besteht darin, zu warten, bis ein bestimmtes Element geladen ist. Diese Methode ist besonders nützlich, wenn Sie wissen, welches Element dynamisch generiert wird. Sie können einfach warten, bis es erscheint, und dann mit dem Scraping der Daten fortfahren. Hier ist ein Beispiel, wie dies mit Selenium funktioniert:
paragraphs = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'p')))Als nächstes müssen wir die benötigten Daten aus der Seite extrahieren und sie entweder verarbeiten, speichern oder auf dem Bildschirm anzeigen:
paragraph = driver.find_elements(By.CSS_SELECTOR, 'p').text
print(paragraph)Und schließen Sie abschließend unbedingt den Webbrowser:
driver.quit()Auf diese Weise können Sie mithilfe dieses Algorithmus absolut beliebige Daten von der Seite abrufen, auch wenn dieser Inhalt dynamisch generiert wird.
Lassen Sie uns den gleichen Prozess für die verbleibenden zwei Bibliotheken wiederholen. Jetzt zeigen wir, wie man Pyppeteer verwendet, um dynamische Inhalte von einer Webseite zu sammeln. Pyppeteer ist eine asynchrone Bibliothek, daher benötigen wir die Asyncio-Bibliothek, um den Betrieb zu erleichtern. Wir kapseln den gesamten Datenerfassungsprozess in einer asynchronen Funktion:
import asyncio
from pyppeteer import launch
url = "https://example.com"
async def main():
# Here will be code
asyncio.get_event_loop().run_until_complete(main())Lassen Sie uns die main()-Funktion verfeinern und den Webtreiber einrichten:
async def main():
browser = await launch()
page = await browser.newPage()Rufen Sie als Nächstes die Seite auf und warten Sie, bis sie vollständig geladen ist:
await page.goto(url)
await page.waitForSelector('p')Daten abrufen und verarbeiten:
paragraphs = await page.querySelectorAll('p')
paragraph_texts = ()
for paragraph in paragraphs:
text = await page.evaluate('(element) => element.textContent', paragraph)
paragraph_texts.append(text.strip())Schließen Sie zum Abschluss den Webtreiber:
await browser.close()Die letzte Bibliothek ist Playwright. Sie ist nicht so beliebt wie Selenium oder Puppeteer, die aufgrund unterschiedlicher Ansätze miteinander konkurrieren, wird jedoch auch recht häufig verwendet.
In Bezug auf die Arbeitsweise ist es Selenium sehr ähnlich, obwohl es weniger Funktionalität bietet. Zu Beginn importieren wir die erforderlichen Module und setzen den Link:
from playwright.sync_api import sync_playwright
url = "https://example.com"Importieren Sie die erforderliche Bibliothek und erstellen Sie eine Instanz des Webtreibers. Verwenden Sie dann die goto()-Methode des Webtreibers, um auf die angegebene Webseite zuzugreifen:
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(url)Verwenden wait_for_selector_all() warten, bis das gewünschte Element auf der Seite sichtbar wird. Dadurch wird sichergestellt, dass das Element vollständig geladen und zur Interaktion bereit ist:
paragraphs = page.wait_for_selector_all('p')Verarbeiten Sie die extrahierten Daten:
paragraph_texts = (paragraph.text_content() for paragraph in paragraphs)
print(paragraph_texts)Sobald alle Datenextraktionsaufgaben abgeschlossen sind, rufen Sie die quit()-Methode des Webtreibers auf, um das Browserfenster ordnungsgemäß zu schließen und die zugehörigen Ressourcen freizugeben:
browser.close()Obwohl Playwright weniger Funktionen als Selenium hat, hat es auch seine Anhänger und ist recht erfolgreich beim Sammeln von Daten von dynamischen Websites. Daher hängt die Wahl der Bibliothek nicht so sehr davon ab, welche besser ist, sondern davon, welche für Sie bequemer ist.
Schabracke
Scrapy ist im Gegensatz zu den zuvor besprochenen Optionen nicht nur eine Bibliothek, sondern ein vollwertiges Framework für Web Scraping. Wir haben bereits erläutert, wie Scrapy in Python verwendet wird, aber lassen Sie uns nun tiefer in die Anwendung zum Scraping dynamischer Websites eintauchen.
Zunächst ist es wichtig zu beachten, dass Scrapy keinen Headless-Browser enthält, was bedeutet, dass es keine Webseiten laden kann, bevor es sie verarbeitet. Ein Blick in die offizielle Dokumentation von Scrapy zeigt jedoch einen eigenen Abschnitt zum Scraping dynamischer Webseiten.
Dies mag merkwürdig erscheinen, bis wir die in der Dokumentation vorgeschlagene Methode untersuchen. In Wirklichkeit unterstützt Scrapy, wie Sie vielleicht schon vermutet haben, das Scraping dynamischer Webseiten nicht, da es in erster Linie einfache Anfragen ausführt und kein Browserverhalten emuliert.
Daher empfiehlt die offizielle Scrapy-Website die Verwendung zusätzlicher Bibliotheken, die diese Funktionalität bieten. In diesem speziellen Beispiel wird die zuvor besprochene Bibliothek Playwright als Alternative empfohlen.
Leider führt uns dies zu der Schlussfolgerung, dass das Scrapy-Framework das Scraping dynamischer Seiten nicht erleichtert, im Gegensatz zur BeautifulSoup-Bibliothek.
HasDatas Web Scraping API
Die letzte und einfachste Methode ist die Verwendung einer Web Scraping API, die den dynamischen Inhalt für Sie sammelt und entweder einen vorgefertigten Datensatz oder den HTML-Code der vollständig geladenen Webseite bereitstellt. Als Beispiel verwenden wir die Web Scraping API von HasData.
Um es zu nutzen, registriere dich auf unserer Website und gehe zu deinem Konto. Auf der Registerkarte Dashboard findest du deinen persönlichen API-Schlüssel, den du später benötigst.
Wir können Daten entweder mithilfe der Web Scraping API über den API Playground abrufen oder mithilfe der Dokumentation unser eigenes Python-Skript erstellen. Beginnen wir mit der einfacheren Option und gehen zum API Playground:
Sie können dann eine API für eine bestimmte Website oder die allgemeine Web Scraping API auswählen, mit der Sie Daten von jeder beliebigen Ressource sammeln können. Als Beispiel betrachten wir die vielseitigste Option.
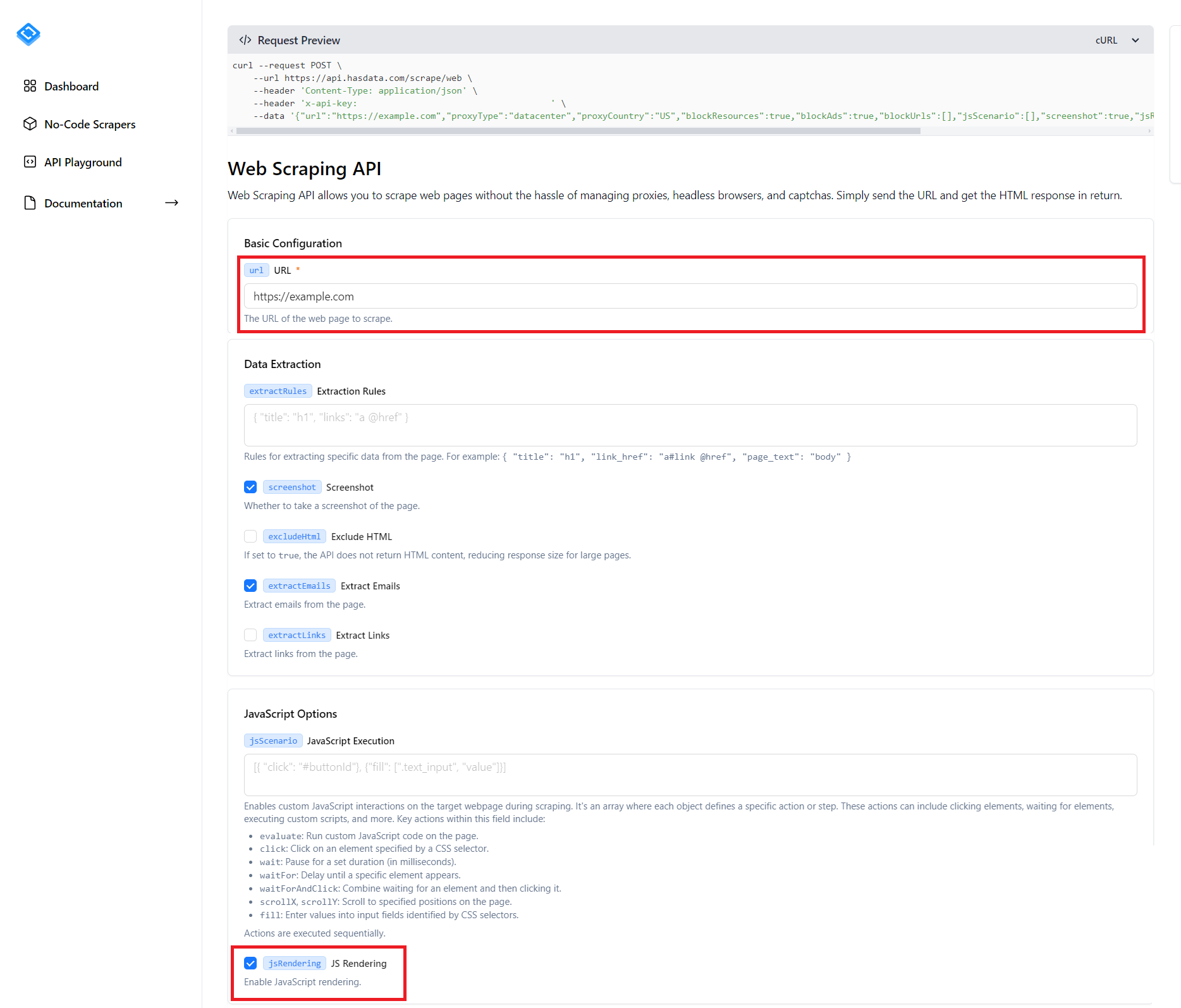
Wie Sie sehen, gibt es auf der Seite viele verschiedene Parameter, die Sie konfigurieren können, und es würde lange dauern, sich mit jedem einzelnen davon zu befassen. Außerdem zeigt der Screenshot nicht alle möglichen Parameter, sondern nur die Hälfte davon. Das Wichtigste, was Sie zum Scrapen einer dynamischen Website benötigen, ist jedoch, die URL der Website anzugeben, von der Sie Daten sammeln möchten, und das Kontrollkästchen neben dem Element „JS-Rendering“ zu aktivieren.
Sie können entweder Ihre Parameter für die restlichen Optionen festlegen, z. B. Standort, Proxy, Extraktionsregeln, E-Mail-Extraktion und vieles mehr, oder Sie können sie unverändert lassen. Anschließend können Sie das Skript entweder ausführen, indem Sie auf die Schaltfläche „Anforderung ausführen“ klicken, den Code in einer der Programmiersprachen kopieren oder die cURL-Anforderung oben auf dem Bildschirm ausführen.
Wir werden ein Skript schreiben, das mit Python Daten von dynamischen Websites sammelt. Erstellen Sie zunächst eine neue *.py-Datei und importieren Sie die Anforderungsbibliothek in Ihr Projekt:
import requestsGeben Sie als Nächstes die Endpunkt-URL der Web-Scraping-API an:
url = "https://api.hasdata.com/scrape/web"Definieren Sie die Parameter, die Sie an die API übergeben möchten. Geben Sie beispielsweise die Website-URL an, aktivieren Sie JS-Rendering, machen Sie einen Screenshot und schließen Sie das E-Mail-Scraping von der Seite ein:
payload = json.dumps({
"url": "https://example.com",
"proxyType": "datacenter",
"proxyCountry": "US",
"blockAds": True,
"screenshot": True,
"jsRendering": True,
"extractEmails": True
})Legen Sie dann die Anforderungsheader fest und fügen Sie Ihren zuvor erhaltenen persönlichen API-Schlüssel ein:
headers = {
'Content-Type': 'application/json',
'x-api-key': 'YOUR-API-KEY'
}Stellen Sie nun die API-Anfrage, um die gewünschten Parameter abzurufen:
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Sie können das Ergebnis beliebig verarbeiten. Denken Sie jedoch daran, dass die API Daten im JSON-Format zurückgibt, wobei eines der Attribute den gesamten Quellcode der Seite enthält.
Fortgeschrittene Techniken
Da Selenium nach wie vor die beliebteste Bibliothek zum Scraping dynamischer Websites ist, werden wir sie für alle Beispiele in diesem Abschnitt verwenden. Die beiden übrigen Bibliotheken unterstützen jedoch ähnliche Funktionen, sodass Sie die besprochenen Beispiele bei Bedarf an Ihr Projekt anpassen können.
Wir bauen auf dem zuvor geschriebenen Skript auf und modifizieren es:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
url = "https://example.com"
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
paragraph = driver.find_elements(By.CSS_SELECTOR, 'p').text
print(paragraph)
driver.quit()Wir besprechen verschiedene zusätzliche Funktionen und Techniken, die beim Sammeln dynamischer Inhalte von Seiten nützlich sein können.
Verwenden des Headless-Modus in Selenium
Um die Leistung Ihres Web Scraping-Skripts zu verbessern, sollten Sie den Headless-Modus verwenden, bei dem Ihr Webbrowser im Hintergrund ausgeführt wird, ohne die grafische Benutzeroberfläche zu rendern. Deaktivieren Sie außerdem die GPU-Nutzung, um die Leistung im Headless-Modus weiter zu optimieren.
Um dies zu erreichen, geben Sie bei der Konfiguration des Webtreibers einfach zusätzliche Optionen an:
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
driver = webdriver.Chrome(options=chrome_options)Abgesehen von diesen Anpassungen bleibt das Skript unverändert, doch diese Änderungen verbessern die Geschwindigkeit und Effizienz Ihres dynamischen Webseiten-Scrapers erheblich.
Handhabung des unendlichen Scrollens
Infinite Scrolling ist eine beliebte Technik, mit der Inhalte schrittweise geladen werden, während Benutzer auf einer Seite nach unten scrollen. Dadurch ist keine Seitennummerierung mehr erforderlich. Dieser Ansatz verbessert das Benutzererlebnis, indem er eine nahtlose und dynamische Interaktion ermöglicht.
Es ist besonders nützlich für die Anzeige großer Datenmengen, wie etwa Social-Media-Feeds oder Suchergebnisse, und für die Anzeige großer Datenmengen, ohne dass eine Seitennummerierung oder ein Neuladen der Seite erforderlich ist. Es verbessert das Benutzererlebnis, indem es ein nahtloses und flüssiges Browsing-Erlebnis bietet.
Um unendliches Scrollen zu implementieren, müssen wir diese Schritte befolgen:
- Identifizieren Sie das Ende der Seite. Bestimmen Sie beim Laden der Seite die Position des Seitenendes.
- Scrollen Sie zum Ende der Seite. Verschieben Sie den Ansichtsbereich an das Ende des Seiteninhalts.
- Prüfen Sie, ob die aktuelle Position am Ende der Seite liegt. Bestimmen Sie, ob die aktuelle Ansichtsfensterposition das Ende der Seite erreicht hat. Wenn nicht, identifizieren Sie das neue Ende der Seite.
- Wiederholen Sie die Schritte 2-3. Scrollen Sie kontinuierlich bis zum Ende der Seite und überprüfen Sie die aktuelle Position, bis das Ansichtsfenster das tatsächliche Ende der Seite erreicht.
Erweitern wir unser ursprüngliches Skript, indem wir den folgenden Python-Code hinzufügen, um das Scrollen nach dem Laden der Seite, aber vor dem Sammeln von Daten von der Seite durchzuführen:
driver.get(url)
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
paragraph = driver.find_elements(By.CSS_SELECTOR, 'p').textDieses erweiterte Skript implementiert den Infinite-Scrolling-Algorithmus effektiv und ist daher auf verschiedene Websites mit ähnlichen Anforderungen anwendbar.
JavaScript auswerten
In Web Scraping-Szenarien ist es häufig erforderlich, JavaScript-Code direkt auf einer Webseite auszuführen, bevor Daten extrahiert werden. Dies ist besonders nützlich, um das dynamische Laden von Webseiten, das Aktivieren von UI-Elementen oder das Ausführen von Datenvorverarbeitungsaufgaben zu handhaben. Darüber hinaus kann JavaScript verwendet werden, um komplexe Aufgaben wie das Lösen von Captchas oder die Interaktion mit Seitenelementen zu automatisieren, die bestimmte Aktionen erfordern.
Selenium bietet die Methode execute_script(), um JavaScript-Code nahtlos innerhalb einer Webseite auszuführen. Übergeben Sie den JavaScript-Code einfach als Zeichenfolge an diese Methode und Selenium führt ihn auf der aktuell geladenen Seite aus:
paragraph_text_js = driver.execute_script("return document.querySelector('p').textContent;")Die Nutzung von JavaScript in Selenium erweitert die Möglichkeiten zum Datenscraping, insbesondere wenn die Standardmethoden von Selenium nicht ausreichen oder sich als ineffizient erweisen. Dieser Ansatz verbessert die Scraping-Flexibilität, ermöglicht die Datenextraktion aus verschiedenen Quellen und umgeht dynamische Website-Einschränkungen.
Abschluss
Zusammenfassend lässt sich sagen, dass das Scraping dynamischer Webseiten ein wichtiges Thema ist, das beträchtliche Aufmerksamkeit erlangt hat. Ziel dieses Artikels war es, den Unterschied zwischen statischen Webseiten und dynamischen Inhalten, die Implementierung dynamischer Inhalte und Methoden zum Sammeln von Daten von dynamischen Webseiten zu beleuchten.
Wir haben uns mit den beliebtesten Tools und Bibliotheken zum Scraping dynamischer Webseiten mit Python beschäftigt, darunter BeautifulSoup, Selenium, Pyppeteer, Playwright und Scrapy. Darüber hinaus haben wir die Prinzipien der Verwendung von Web Scraping-APIs zum Sammeln dynamischer Inhalte untersucht.
Basierend auf der Analyse sind BeautifulSoup und Scrapy aufgrund ihrer funktionalen Einschränkungen nicht zum Scraping dynamischer Websites geeignet. Stattdessen sind Selenium, Pyppeteer oder Web Scraping-APIs geeignetere Optionen.
