
Wenn Suchmaschinen Websites kriechen, versuchen sie ihr Bestes, um so viele Informationen wie möglich von diesen Seiten zu erhalten. Obwohl es an dieser Front massive Entwicklungen gegeben hat, erraten sie im besten Fall die Wahrscheinlichkeiten über die Informationen, die sie extrahieren.
Durch die Bereitstellung von Suchmaschinen mit strukturierten Daten wird es viel einfacher und ermöglicht interessante Anwendungen und Datennutzung.
In diesem Artikel wird angezeigt, wie Sie die Qualität Ihrer Webseiten mithilfe strukturierter Daten und der Hilfe von selbst ausgestatteten Chatgpt-Modellen verbessern können. Wir werden die Wikipedia -Website kratzen und sie verwenden, um den gezielten Webseiten einen Mehrwert zu verleihen.
Automatisierung der strukturierten Datenerstellung für groß angelegte Websites mit LLMs
In vielen Fällen stehen wir mit einer Situation konfrontiert, in der wir zahlreiche Seiten haben, die keine strukturierten Daten enthalten, aber sie müssen durchgeführt werden. Wir können natürlich die manuelle Route übernehmen und unseren Inhalt nacheinander klassifizieren/markieren. Wir können auch die jüngsten Fortschritte untersuchen, die große Sprachmodelle verwendet und sie für die spezifische Aufgabe des Extrahierens bestimmter Daten aus unseren Seiten und das Erstellen des gewünschten zusätzlichen Markups in Form von JSON-LD-Skripten ausbilden. Wir sind jedoch nicht auf dieses Format beschränkt, sobald wir Zugriff auf die Daten haben, können wir es so formatieren, wie wir es wollen.
Hier ist ein kurzer Überblick über das Problem, mit dem wir möglicherweise konfrontiert sind, und die vorgeschlagenen Schritte zur Lösung:
- Wir haben eine große Website mit (Zehn oder Hunderten) von Tausenden von Seiten, die kein strukturiertes Markup haben (zum Beispiel JSON-LD, Twitter, OpenGraph).
- Wir möchten ein strukturiertes Markup für diese Seiten erstellen.
- Wir wollen dies in großem Maßstab tun.
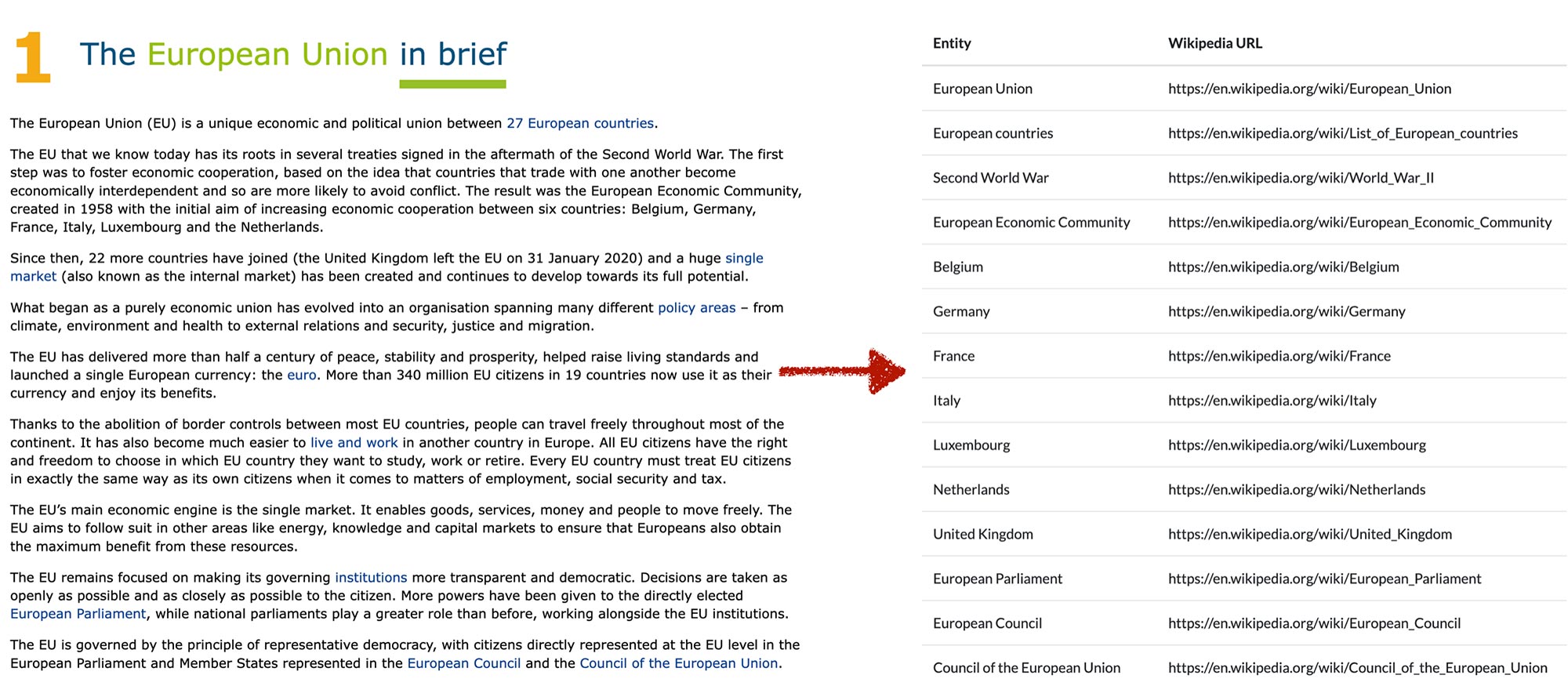
- Wir werden ein LLM ausbilden, um Entitäten aus Artikeln zu extrahieren und einen Link zur Wikipedia -Seite jeder Entität anzubieten.
Um die Dinge klar zu machen, werden wir ChatGPT eine Eingabe wie folgt zur Verfügung stellen. Dies ist der zusammenfassende Teil einer Wikipedia -Seite, „Basketball“ in diesem Fall. Nur die ersten Zeilen werden angezeigt, und wir werden später das vollständige Beispiel durcharbeiten:
Basketball is a team sport in which two teams, most commonly of five players each, opposing one another on a rectangular court, compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter) through the defender’s hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard at each end of the court), while preventing the opposing team from shooting through their own hoop. A field goal is worth two points, unless made from behind the three-point line, when it is worth three…
Und wir wollen wie folgt eine Antwort erhalten:
| IDX | juristische Person | URL |
| 0 | James Naismith | https://en.wikipedia.org/wiki/james_naismith |
| 1 | Springfield, Massachusetts | https://en.wikipedia.org/wiki/springfield,_massachusetts |
| 2 | Nationale Basketballvereinigung | https://en.wikipedia.org/wiki/national_basketball_association |
| 3 | NBA | https://en.wikipedia.org/wiki/national_basketball_association |
| 4 | Euroleague | https://en.wikipedia.org/wiki/euroleague |
| 5 | Basketball Champions League Americas | https://en.wikipedia.org/wiki/Basketball_Champions_league_americas |
| 6 | FIBA -Basketball -Weltmeisterschaft | https://en.wikipedia.org/wiki/fiba_basketball_world_cup |
| 7 | Eurobasket | https://en.wikipedia.org/wiki/eurobasket |
| 8 | Fiba Americup | https://en.wikipedia.org/wiki/fiba_americup |
| 9 | FIBA -Frauenbasketball -Weltmeisterschaft | https://en.wikipedia.org/wiki/fiba_women%27S_BASKETBALL_WORLD_CUP |
| 10 | Wnba | https://en.wikipedia.org/wiki/women%27s_national_basketball_association |
| 11 | NCAA Frauenabteilung I Basketballmeisterschaft | https://en.wikipedia.org/wiki/ncaa_division_i_women%27S_Basketball_Tournament |
| 12 | Euroleague Frauen | https://en.wikipedia.org/wiki/euroleague_women |
Es ist ein ziemlich ehrgeiziges Ziel, den Prozess des Extrahierens von Entitäten zu automatisieren, und nicht nur das, wir werden auch ihre jeweiligen Wikipedia -URLs erhalten.
Sobald wir diese URLs haben, wird es einfacher, weitere Informationen über jede Entität zu erhalten, da wir diese Seite kratzen, Google suchen können und so weiter. Aber wir brauchen zuerst diese erste Startseite. Wir werden in diesem Artikel nicht über diesen Schritt hinausgehen und werden uns bis zu diesem Punkt auf den Prozess konzentrieren.
Normale Aufforderung vs. Feinabstimmung LLMs
Bevor wir mit dem Codieren beginnen, unterscheiden wir zunächst zwischen normalen Aufforderung und fein abgestimmten Modellen. Regelmäßige Eingabeaufforderungen sind einfache Anweisungen oder Fragen, die das Modell anweisen, eine bestimmte Aufgabe zu erledigen, eine Frage zu beantworten oder Inhalte zu erstellen. Ziel ist es, eine universelle Frage/Antwortmaschine zu sein, die als Ihr persönlicher Assistent fungieren kann.
Wenn wir ein Modell dagegen optimieren, trainieren wir das LLM für eine bestimmte Aufgabe, die viel besser abschneidet als eine regelmäßige Eingabeaufforderung, um zu wissen, wie diese Aufgabe nur ausgeführt werden kann. Es ähnelt dem Unterschied zwischen einem normalen Auto (normaler Aufforderung) und einem U-Bahn-Zug (fein abgestimmte Modelle).
Ihr Auto kann für verschiedene Aufgaben verwendet werden und erfüllen fast alle unsere Transportbedürfnisse. Ein U -Bahn -Zug kann nur eine Sache tun, von Punkt A nach Punkt B und zurück gehen. Es ist sehr begrenzt, aber es führt diese Aufgabe sehr gut aus, viel besser als ein Auto und in viel größerem Maßstab. Hier finden Sie einen kurzen Vergleich zwischen diesen beiden Ansätzen:
| Bereich | Normale Aufforderung | Feinabstimmungsmodell |
| Umfang | Allgemein | Spezifisch |
| Schulungsprozess | In der Eingabeaufforderung enthalten | Gemacht, indem viele ähnliche konsistente Beispiele geliefert werden |
| Allgemeinheit | Jack aller Geschäfte | Sehr spezifisches Werkzeug |
Sie haben wahrscheinlich bereits mit normalen Eingabeaufforderungen experimentiert und für die obige Aufgabe etwas wie die folgenden:
"Extract the main entities of the following text, and provide the Wikipedia URL for each, format the response as a table:
FULL TEXT GOES HERE"
Heutzutage stecken Sie hier mit einer paradoxen Situation fest, die sich aus den Einschränkungen der sofortigen Länge ergibt. Wenn Sie eine gute Antwort erhalten möchten, müssen Sie mit Beispielen eine sehr detaillierte Eingabeaufforderung und klare Anweisungen angeben. Je mehr Beispiele und Anweisungen Sie bereitstellen, desto weniger Platz müssen Sie den Inhalt bereitstellen, der verarbeitet werden muss.
Das Gegenteil ist auch wahr. Mit einem feinstimmigen Modell senden Sie nur einen Textstück, der als Eingabeaufforderung fungiert. Unser ausgebildetes Modell wird nicht darüber nachdenken oder etwas anderes ausprobieren als das, wofür es trainiert wurde (die obige Aufgabe).
Lassen Sie uns schnell einen einfachen Prozess des Trainings des LLM mit einem fein abgestimmten Modell durchlaufen:
| prompt | Antwort |
| Blau | Sei |
| Blume | fr |
| Buch | bk |
| Meer | sa |
| Fenster | ww |
| Auto | Cr |
| Tasche | ?? |
Nachdem Sie die obigen Beispiele durchgemacht hatten, war es für Sie wahrscheinlich leicht, herauszufinden, wie Sie die letzte Aufforderungstasche abschließen können, da die Beispiele vor dem konsistenten und klarsten. Jede Antwort enthält nur zwei Buchstaben, und wenn Sie mit ihrer jeweiligen Eingabeaufforderung zusammenhängen, können Sie deutlich erkennen, dass sie im Grunde die ersten und letzten Zeichen dieser Eingabeaufforderung sind. Je mehr Beispiele wir anbieten, desto sicherer wären Sie, dass dies in der Tat das Muster ist, nach dem wir suchen. Der Schlüssel hier ist es dann, zahlreiche, klare und vor allem konsistente Eingabeaufforderung zu liefern: Antwortpaare.
Genau so trainieren wir Chatgpt, um die erforderlichen Einheiten zu extrahieren. Unsere „Eingabeaufforderung“ wird einfach ein Artikel sein und herausfinden, was damit zu tun ist (vorausgesetzt, wir haben in der Trainingsphase gute Arbeit geleistet).
In diesem Sinne werden unsere Aufforderungen extrem einfach sein. Sie würden keine Anweisungen oder Klarstellungen enthalten. Die Schwierigkeit besteht jedoch darin, eine große Anzahl von Beispielen zu liefern, bei denen das LLM das Muster, nach dem wir suchen, eindeutig erhalten können.
Der Trainingsplan
Wir müssen einen Datensatz mit den folgenden Bedingungen bereitstellen:
- Eine große Anzahl von Artikeln (Hunderte)
- Diese Artikel müssen von Menschen von ihnen identifiziert und extrahiert werden
- Wir wollen nicht nur die Entitäten bekommen, wir brauchen auch die Wikipedia -URL jeder Entität
Wo könnten wir einen solchen Datensatz finden? Auf Wikipedia selbst. Es erfüllt all diese Bedingungen. Das war einfach. Jetzt die Implementierung. Glücklicherweise bietet die Wikipedia -API einige bequeme Funktionen, um unsere Arbeit zu erleichtern. Für jeden Artikel können wir den Text zusammen mit verschiedenen interessanten Elementen herunterladen. Wir werden uns auf zwei von ihnen konzentrieren:
- Zusammenfassung: Dies sind die ersten Absätze, die wir zu Beginn jedes Artikels sehen.
- Links: Eine Liste aller Links im Artikel mit
import re import json import advertools as adv import pandas as pd import wikipediaapi pd.options.display.max_columns = None from IPython.display import display_html, display_markdown, IFrame import openai openai.api_key = 'YOUR OPEN AI API KEY'
Erhalten von Daten von der Wikipedia -API
Wir werden zuerst den Prozess Schritt für Schritt für einen Wikipedia-Artikel durchlaufen und dann verallgemeinern.
Wir initiieren zuerst die Wikipedia Objekt und verwenden Sie es dann, um Daten für jede Seite zu erhalten. Um die Seite anzugeben, die wir benötigen, benötigen wir den letzten Ordner des Pfadteils der URL https://en.wikipedia.org/wiki/Article_title „Artikel_Title“ in diesem Fall. Dies ist sehr wichtig, da es nicht immer einfach ist, diesen Teil der URL zu schließen. In einigen Fällen ist es unkompliziert, wie /Pizza oder /Musicaber in vielen Fällen ist es nicht, wie /FIBA_Women's_Basketball_World_Cup
Wir erstellen jetzt eine Variable für die Seite, die wir wollen:
wiki_wiki = wikipediaapi.Wikipedia('en')
page_basketball = wiki_wiki.page('Basketball')
print(page_basketball.summary(:1500))
Basketball is a team sport in which two teams, most commonly of five players each, opposing one another on a rectangular court, compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter) through the defender's hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard at each end of the court), while preventing the opposing team from shooting through their own hoop. A field goal is worth two points, unless made from behind the three-point line, when it is worth three. After a foul, timed play stops and the player fouled or designated to shoot a technical foul is given one, two or three one-point free throws. The team with the most points at the end of the game wins, but if regulation play expires with the score tied, an additional period of play (overtime) is mandated. Players advance the ball by bouncing it while walking or running (dribbling) or by passing it to a teammate, both of which require considerable skill. On offense, players may use a variety of shots – the layup, the jump shot, or a dunk; on defense, they may steal the ball from a dribbler, intercept passes, or block shots; either offense or defense may collect a rebound, that is, a missed shot that bounces from rim or backboard. It is a violation to lift or drag one's pivot foot without dribbling the ball, to carry it, or to hold the ball with both hands then resume dribbling. The five players on each side fall into five playing posi
Wie Sie sehen können, können wir das anfordern summary Attribut dieses Objekts zum Zusammenfassungstext. Oben haben wir den ersten Absatz der Zusammenfassung.
Ein weiteres interessantes Attribut, das wir bekommen können, ist das link Attribut. Dies gibt uns den Text jedes Links sowie zusätzliche Informationen zu jedem Link. Hier sehen wir die ersten Links und drucken auch die Gesamtzahl der Links, um eine Idee zu erhalten.
Erhalten Sie die Links eines Artikels
print(len(page_basketball.links)) list(page_basketball.links.items())(:20)
1309
(('16-inch softball', 16-inch softball (id: ??, ns: 0)),
('1936 Summer Olympics', 1936 Summer Olympics (id: ??, ns: 0)),
('1979 NBL Season', 1979 NBL Season (id: ??, ns: 0)),
('1992 Summer Olympics', 1992 Summer Olympics (id: ??, ns: 0)),
("1992 United States men's Olympic basketball team",
1992 United States men's Olympic basketball team (id: ??, ns: 0)),
('1998 NBL Season', 1998 NBL Season (id: ??, ns: 0)),
('1998–99 NBL season', 1998–99 NBL season (id: ??, ns: 0)),
('1–2–1–1 zone press', 1–2–1–1 zone press (id: ??, ns: 0)),
('1–3–1 defense and offense', 1–3–1 defense and offense (id: ??, ns: 0)),
('2000–01 FIBA SuproLeague', 2000–01 FIBA SuproLeague (id: ??, ns: 0)),
('2004 Summer Olympics', 2004 Summer Olympics (id: ??, ns: 0)),
('2006 FIBA World Championship for Women',
2006 FIBA World Championship for Women (id: ??, ns: 0)),
('2007 Asian Indoor Games', 2007 Asian Indoor Games (id: ??, ns: 0)),
("2008 United States men's Olympic basketball team",
2008 United States men's Olympic basketball team (id: ??, ns: 0)),
('2009 Asian Youth Games', 2009 Asian Youth Games (id: ??, ns: 0)),
('2010 FIBA World Championship',
2010 FIBA World Championship (id: ??, ns: 0)),
('2010 Youth Olympics', 2010 Youth Olympics (id: ??, ns: 0)),
('2011 FIBA 3x3 Youth World Championships',
2011 FIBA 3x3 Youth World Championships (id: ??, ns: 0)),
('2012 FIBA 3x3 World Championships',
2012 FIBA 3x3 World Championships (id: ??, ns: 0)),
('2014 FIBA Basketball World Cup',
2014 FIBA Basketball World Cup (id: ??, ns: 0)))
Diese Links sind überall im Artikel verteilt, und wir wollen jetzt diejenigen, die im Zusammenfassungsteil des Artikels vorhanden sind. Wir können das mit einem einfachen regulären Ausdruck tun.
Erstellen eines regulären Ausdrucks zum Extrahieren von Links
Da wir den Ankertext jedes Links im Artikel haben, ist der Regex einfach eine Verkettung aller Links 'Text, die durch den Rohr „oder“ oder „Operator“ getrennt ist. Das einzige andere, was wir sorgen müssen, ist, unsere Links nach Länge zu sortieren. Hier ist ein einfaches Beispiel, um diesen Punkt zu veranschaulichen. Angenommen, wir möchten jede Instanz des Wortes „gewonnen“ oder „wunderbar“ aus einem Textstück extrahieren. Lassen Sie uns zuerst die Regex testen won|wonderful:
import re
text="I won the game at the wonderful tournament"
re.findall('won|wonderful', text)
('won', 'won')
Was ist gerade passiert?
Die erste Instanz von „Won“, das das zweite Wort im Satz ist, wurde korrekt extrahiert, aber das zweite war nicht. Eigentlich war es es, aber es war nicht das, was wir beabsichtigt hatten. Da wir zum ersten Mal „Won“ angegeben haben, beginnt der Regex -Engine nach diesem Muster zu suchen. Wenn es es nicht findet, sucht er nach der anderen Option. In unserem Fall fand es die zweite Instanz von „Won“ kurz vor „Derful“. Sobald der Regex -Motor den zweiten „Eins“ extrahiert hat, ist er jetzt im „D“ und von dort aus keinen anderen Fällen von „Won“. Probieren wir dieselbe Regex, aber platzieren wir das längere Muster vor dem kürzeren:
re.findall('wonderful|won', text)
('won', 'wonderful')
Es funktioniert jetzt wie beabsichtigt. Aus diesem Grund werden wir unsere Link -Extraktionsregex nach Länge sortiert, um diese Situation zu vermeiden.
Das andere, was wir sicherstellen wollen, ist, dass wir ganze Wörter extrahieren wollen. Angenommen, wir wollen das Muster „Ruhe“ extrahieren. Wenn der Regex -Motor das Wort „Restaurant“ im mitgelieferten Text findet, extrahiert er es als legitime Übereinstimmung für das Muster. Aber das wollen wir nicht. Wir wollen nur „Ruhe“ als vollständiges Wort. Dafür können wir das Wort Grenzmuster in regulären Ausdrücken verwenden \b. Da der Backslack in Regex ein besonderer Charakter ist, entkommen wir ihm, indem wir einen anderen hinzufügen. Unser Regex wird so aussehen:
pattern_1\\b|\\bpattern_2\\b|\\bpattern_3 und so weiter.
Der folgende Code erstellt den gewünschten Regex nach:
- Verkettung aller Ankertexte unserer Links
- Sortieren Sie sie nach Länge in absteigender Reihenfolge (längere Muster vor kürzeren)
- Mit der Pfeife anschließen
|sowie Wort das Wort Grenzcharakter Wort\\bvon beiden Seiten
page_basketball_linksregex = '\\b|\\b'.join(sorted(page_basketball.links.keys(), key=len, reverse=True)) page_basketball_linksregex(:400)
"List of U.S. high school basketball national player of the year awards\\b|\\bList of basketball players who have scored 100 points in a single game\\b|\\bYoung Men's Christian Association Building (Albany, New York)\\b|\\bCategory:Articles with dead external links from February 2021\\b|\\bCategory:Articles with disputed statements from January 2019\\b|\\bCategory:Articles with disputed statements from Janua"
Hier sind die ersten Zeilen aus unserem zusammenfassenden Text, mit dem Ankertext der Entitäten hervorgehoben, sodass Sie eine Vorstellung davon bekommen, wie dies funktionieren wird:
Basketball ist ein Mannschaftssport, in dem zwei Teams, am häufigsten von jeweils fünf Spielern, sich gegenseitig auf einem rechteckigen Hof widersetzen, mit dem Hauptziel konkurrieren, einen Basketball (ca. 9,4 Zoll) im Durchmesser zu schießen, über den Verteidiger des Verteidigers (ca. 9,4 Zoll) zu schießen. Ein Korb mit einem Durchmesser von 18 Zoll mit einem Durchmesser von 10 Fuß (3,048 m) hoch zu einem Rückenbrett an jedem Ende des Platzes) und verhindern, dass das gegnerische Team durch ihren eigenen Reifen schießt.
Ein Feldtor ist zwei Punkte wert, es sei denn, hinter der Drei-Punkte-Linie, wenn es drei wert ist. Nach einem Foul, zeitgesteuerte Spielstopps, und der Spieler verschmutzte oder bezeichnet, um ein technisches Foul zu schießen, erhält ein, zwei oder drei Freiwürfe. Das Team mit den meisten Punkten am Ende des Spiels gewinnt gewinnt, aber wenn das Spielspiel mit der Partitur abgibt, wird eine zusätzliche Spielzeit (Überstunden) vorgeschrieben.
Die Spieler fördern den Ball, indem sie ihn beim Gehen oder Laufen (Dribbling) oder an einen Teamkollegen abgeben, die beide beträchtliche Fähigkeiten erfordern. In der Offensive können die Spieler eine Vielzahl von Schüssen verwenden – das Layup, den Sprungschuss oder einen Dunk; In der Verteidigung können sie den Ball von einem Dribbler, Abfangpässen oder Blockschüssen stehlen; Entweder Straftat oder Verteidigung kann einen Abpraller sammeln, dh einen verpassten Schuss, der von Rand oder Backboard abprallt. Es ist eine Verletzung, den Drehfuß zu heben oder zu ziehen, ohne den Ball zu dribbeln, ihn zu tragen oder den Ball mit beiden Händen zu halten und dann das Dribbeln wieder aufzunehmen.
Die fünf Spieler auf jeder Seite fallen in fünf Spielpositionen. The tallest player is usually the center, the second-tallest and strongest is the power forward, a slightly shorter but more agile player is the small forward, and the shortest players or the best ball handlers are the shooting guard and the point guard, who Implementiert den Spielplan des Trainers, indem es die Ausführung von offensiven und defensiven Spielen (Spielerpositionierung) verwaltet. Informell können Spieler drei gegen drei, zwei gegen zwei und eins zu eins spielen.
1891 von kanadisch-amerikanischer Fitnesslehrer erfunden James Naismith In Springfield, MassachusettsIn den Vereinigten Staaten hat sich der Basketball zu einem der beliebtesten und am häufigsten angesehenen Sportarten der Welt entwickelt. Der Nationale Basketballvereinigung (NBA) ist die wichtigste professionelle Basketballliga der Welt in Bezug auf Popularität, Gehälter, Talent und Wettbewerbsniveau (die den größten Teil seines Talents von US -College -Basketball ziehen). Außerhalb Nordamerikas qualifizieren sich die Top -Clubs aus nationalen Ligen für Kontinentalmeisterschaften wie die Euroleague und die Basketball Champions League Americas. Der FIBA -Basketball -Weltmeisterschaft Und das olympische Basketballturnier der Männer sind die wichtigsten internationalen Ereignisse des Sports und ziehen Top -Nationalmannschaften aus der ganzen Welt an. Jeder Kontinent veranstaltet regionale Wettbewerbe für Nationalmannschaften wie Eurobasket Und Fiba Americup.
Der FIBA -Frauenbasketball -Weltmeisterschaft Das olympische Basketballturnier für Frauen verfügt über Top -Nationalmannschaften aus Kontinentalmeisterschaften. Die wichtigste nordamerikanische Liga ist die wNBA (NCAA Frauenabteilung I Basketballmeisterschaft ist ebenfalls beliebt), während die stärksten europäischen Vereine an der beteiligt sind Euroleague Frauen.
Wir möchten jetzt den Link -Text erhalten, der in der Zusammenfassung unseres Artikels übereinstimmt, und sie in ein einfaches Wörterbuch einfügen. Die Schlüssel sind der übereinstimmende Ankertext. Die Werte werden die Anforderungsseite von Wikipedia (mit allen relevanten Daten enthalten).
Beim Einstellen der Werte senden wir eine Anfrage an Wikipedia, um neue Daten über die übereinstimmende Seite zu erhalten. Das Endergebnis, das ist das links_wikis Das Wörterbuch enthält die vollständigen Informationen zu jeder extrahierten Übereinstimmung. Wir interessieren uns hauptsächlich für den Namen der Entität und der URL, sodass wir einen einfachen Datenrahmen erstellen können, um das Endergebnis anzuzeigen, das wir suchen.
links_wikis = {}
for match in re.finditer(page_basketball_linksregex, page_basketball.summary):
links_wikis(match.group()) = wiki_wiki.page(match.group())
Strukturieren Sie die Einrichtungen und ihre Verbindungen (extrahiert aus der Zusammenfassung des Aritcle)
ent_link = pd.DataFrame({
'entity': links_wikis.keys(),
'url': (link.fullurl for link in links_wikis.values())})
ent_link.style.set_caption('
Einheiten im Zusammenfassungsabschnitt der /Basketball Wiki
'))
Einheiten im Zusammenfassungsabschnitt der /Basketball Wiki
| juristische Person | URL | |
| 0 | James Naismith | https://en.wikipedia.org/wiki/james_naismith |
| 1 | Springfield, Massachusetts | https://en.wikipedia.org/wiki/springfield,_massachusetts |
| 2 | Nationale Basketballvereinigung | https://en.wikipedia.org/wiki/national_basketball_association |
| 3 | NBA | https://en.wikipedia.org/wiki/national_basketball_association |
| 4 | Euroleague | https://en.wikipedia.org/wiki/euroleague |
| 5 | Basketball Champions League Americas | https://en.wikipedia.org/wiki/Basketball_Champions_league_americas |
| 6 | FIBA -Basketball -Weltmeisterschaft | https://en.wikipedia.org/wiki/fiba_basketball_world_cup |
| 7 | Eurobasket | https://en.wikipedia.org/wiki/eurobasket |
| 8 | Fiba Americup | https://en.wikipedia.org/wiki/fiba_americup |
| 9 | FIBA -Frauenbasketball -Weltmeisterschaft | https://en.wikipedia.org/wiki/fiba_women%27S_BASKETBALL_WORLD_CUP |
| 10 | Wnba | https://en.wikipedia.org/wiki/women%27s_national_basketball_association |
| 11 | NCAA Frauenabteilung I Basketballmeisterschaft | https://en.wikipedia.org/wiki/ncaa_division_i_women%27S_Basketball_Tournament |
| 12 | Euroleague Frauen | https://en.wikipedia.org/wiki/euroleague_women |
Angesichts der Seite „Basketball“ haben wir einen Datenrahmen, der Entitäten in ihrem zusammenfassenden Teil enthält, zusammen mit jeder URL, die zu jeder Entität gehört, enthält.
Der nächste Schritt besteht darin, diese Antwort konsistent zu formatieren, damit Chatgpt genau wissen kann, wie die Antworten für uns formatiert werden können. Das Format wird wie folgt sein.
Formatieren Sie die GPT -Fertigstellung klar und konsequent
Entity_1: https://en.wikipedia.org/wiki/Entity_1 Entity_2: https://en.wikipedia.org/wiki/Entity_2 Entity_3: https://en.wikipedia.org/wiki/Entity_3 ...
completion = '@@'.join((': '.join(entity) for entity in ent_link.values))
print(*completion.split('@@'), sep='\n')
James Naismith: https://en.wikipedia.org/wiki/James_Naismith Springfield, Massachusetts: https://en.wikipedia.org/wiki/Springfield,_Massachusetts National Basketball Association: https://en.wikipedia.org/wiki/National_Basketball_Association NBA: https://en.wikipedia.org/wiki/National_Basketball_Association EuroLeague: https://en.wikipedia.org/wiki/EuroLeague Basketball Champions League Americas: https://en.wikipedia.org/wiki/Basketball_Champions_League_Americas FIBA Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Basketball_World_Cup EuroBasket: https://en.wikipedia.org/wiki/EuroBasket FIBA AmeriCup: https://en.wikipedia.org/wiki/FIBA_AmeriCup FIBA Women's Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Women%27s_Basketball_World_Cup WNBA: https://en.wikipedia.org/wiki/Women%27s_National_Basketball_Association NCAA Women's Division I Basketball Championship: https://en.wikipedia.org/wiki/NCAA_Division_I_women%27s_basketball_tournament EuroLeague Women: https://en.wikipedia.org/wiki/EuroLeague_Women
Wir möchten jetzt das Eingabeaufforderung/Fertigstellungspaar im Standard -JSON -Format, das ChatGPT benötigt, platzieren, nämlich
{"prompt": "prompt text goes here", "completion": "completion text goes here"}
Kombinieren Sie Eingabeaufforderungen und ihre Abschlüsse in einem JSON -Format, das in einer JSONLINES -Datei gespeichert ist (dies ist unser „Training“)
print(json.dumps({"prompt":page_basketball.summary,"completion":completion}))
{"prompt": "Basketball is a team sport in which two teams, most commonly of five players each, opposing one another on a rectangular court, compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter) through the defender's hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard at each end of the court), while preventing the opposing team from shooting through their own hoop. A field goal is worth two points, unless made from behind the three-point line, when it is worth three. After a foul, timed play stops and the player fouled or designated to shoot a technical foul is given one, two or three one-point free throws. The team with the most points at the end of the game wins, but if regulation play expires with the score tied, an additional period of play (overtime) is mandated.\nPlayers advance the ball by bouncing it while walking or running (dribbling) or by passing it to a teammate, both of which require considerable skill. On offense, players may use a variety of shots \u2013 the layup, the jump shot, or a dunk; on defense, they may steal the ball from a dribbler, intercept passes, or block shots; either offense or defense may collect a rebound, that is, a missed shot that bounces from rim or backboard. It is a violation to lift or drag one's pivot foot without dribbling the ball, to carry it, or to hold the ball with both hands then resume dribbling.\nThe five players on each side fall into five playing positions. The tallest player is usually the center, the second-tallest and strongest is the power forward, a slightly shorter but more agile player is the small forward, and the shortest players or the best ball handlers are the shooting guard and the point guard, who implements the coach's game plan by managing the execution of offensive and defensive plays (player positioning). Informally, players may play three-on-three, two-on-two, and one-on-one.\nInvented in 1891 by Canadian-American gym teacher James Naismith in Springfield, Massachusetts, in the United States, basketball has evolved to become one of the world's most popular and widely viewed sports. The National Basketball Association (NBA) is the most significant professional basketball league in the world in terms of popularity, salaries, talent, and level of competition (drawing most of its talent from U.S. college basketball). Outside North America, the top clubs from national leagues qualify to continental championships such as the EuroLeague and the Basketball Champions League Americas. The FIBA Basketball World Cup and Men's Olympic Basketball Tournament are the major international events of the sport and attract top national teams from around the world. Each continent hosts regional competitions for national teams, like EuroBasket and FIBA AmeriCup.\nThe FIBA Women's Basketball World Cup and Women's Olympic Basketball Tournament feature top national teams from continental championships. The main North American league is the WNBA (NCAA Women's Division I Basketball Championship is also popular), whereas the strongest European clubs participate in the EuroLeague Women.", "completion": "James Naismith: https://en.wikipedia.org/wiki/James_Naismith@@Springfield, Massachusetts: https://en.wikipedia.org/wiki/Springfield,_Massachusetts@@National Basketball Association: https://en.wikipedia.org/wiki/National_Basketball_Association@@NBA: https://en.wikipedia.org/wiki/National_Basketball_Association@@EuroLeague: https://en.wikipedia.org/wiki/EuroLeague@@Basketball Champions League Americas: https://en.wikipedia.org/wiki/Basketball_Champions_League_Americas@@FIBA Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Basketball_World_Cup@@EuroBasket: https://en.wikipedia.org/wiki/EuroBasket@@FIBA AmeriCup: https://en.wikipedia.org/wiki/FIBA_AmeriCup@@FIBA Women's Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Women%27s_Basketball_World_Cup@@WNBA: https://en.wikipedia.org/wiki/Women%27s_National_Basketball_Association@@NCAA Women's Division I Basketball Championship: https://en.wikipedia.org/wiki/NCAA_Division_I_women%27s_basketball_tournament@@EuroLeague Women: https://en.wikipedia.org/wiki/EuroLeague_Women"}
# for link, name in links_wikis.items():
# display_markdown(f'### {link}', raw=True)
# display_markdown(name.summary, raw=True)
# print()
Nachdem wir dies für eine Wikipedia -Seite getan haben, sind wir bereit, all diese Schritte in einer Funktion zu kombinieren. Diese Funktion nimmt eine Wikipedia -Seite als Eingabe an und gibt das JSON -Objekt wie im letzten Schritt zurück.
Wichtiger Hinweis zu Formatierungsaufforderungen und Antworten: Es muss ein klarer Hinweis darauf geben, wo die Eingabeaufforderung endet und wo die Fertigstellung endet. Es kann alles sein, und ein sehr unwahrscheinliches Textmuster ist eine gute Wahl, zum Beispiel zwei Newlin -Charaktere, die nach einer Reihe von Dollar -Schildern folgen.
Erstellen Sie eine Funktion, die eine Wikipedia -Slug übernimmt, z. /Basketball und gibt die gewünschte JSON -String zurück
Dies kombiniert alle bisher unternommenen Schritte. In der Funktion steht „Ner“ für „genannte Entitätserkennung“.
prompt_end = '\n\n%%%%%\n'
completion_end = '\n\n^^^^^\n'
def wikipedia_ner(page):
wikipage = wiki_wiki.page(page)
page_links_regex = '\\b|\\b'.join(sorted(wikipage.links.keys(), key=len, reverse=True))
links_wikis = {}
for match in re.finditer(page_links_regex, wikipage.summary):
links_wikis(match.group()) = wiki_wiki.page(match.group())
ent_link = pd.DataFrame({
'entity': links_wikis.keys(),
'url': (link.fullurl for link in links_wikis.values())})
completion = ' ' + '@@'.join((': '.join(entity) for entity in ent_link.values))
training_dict = {
'prompt': wikipage.summary + prompt_end,
'completion': completion + completion_end}
return json.dumps(training_dict)
Testen Sie es erneut mit /Basketball
Nachdem wir alle Schritte in einen Befehl abstrahiert haben, lassen Sie uns sehen, wie es mit derselben Seite funktioniert, mit der wir begonnen haben.
basketball = wikipedia_ner('Basketball')
print(json.loads(basketball)('prompt'))
Basketball is a team sport in which two teams, most commonly of five players each, opposing one another on a rectangular court, compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter) through the defender's hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard at each end of the court), while preventing the opposing team from shooting through their own hoop. A field goal is worth two points, unless made from behind the three-point line, when it is worth three. After a foul, timed play stops and the player fouled or designated to shoot a technical foul is given one, two or three one-point free throws. The team with the most points at the end of the game wins, but if regulation play expires with the score tied, an additional period of play (overtime) is mandated. Players advance the ball by bouncing it while walking or running (dribbling) or by passing it to a teammate, both of which require considerable skill. On offense, players may use a variety of shots – the layup, the jump shot, or a dunk; on defense, they may steal the ball from a dribbler, intercept passes, or block shots; either offense or defense may collect a rebound, that is, a missed shot that bounces from rim or backboard. It is a violation to lift or drag one's pivot foot without dribbling the ball, to carry it, or to hold the ball with both hands then resume dribbling. The five players on each side fall into five playing positions. The tallest player is usually the center, the second-tallest and strongest is the power forward, a slightly shorter but more agile player is the small forward, and the shortest players or the best ball handlers are the shooting guard and the point guard, who implements the coach's game plan by managing the execution of offensive and defensive plays (player positioning). Informally, players may play three-on-three, two-on-two, and one-on-one. Invented in 1891 by Canadian-American gym teacher James Naismith in Springfield, Massachusetts, in the United States, basketball has evolved to become one of the world's most popular and widely viewed sports. The National Basketball Association (NBA) is the most significant professional basketball league in the world in terms of popularity, salaries, talent, and level of competition (drawing most of its talent from U.S. college basketball). Outside North America, the top clubs from national leagues qualify to continental championships such as the EuroLeague and the Basketball Champions League Americas. The FIBA Basketball World Cup and Men's Olympic Basketball Tournament are the major international events of the sport and attract top national teams from around the world. Each continent hosts regional competitions for national teams, like EuroBasket and FIBA AmeriCup. The FIBA Women's Basketball World Cup and Women's Olympic Basketball Tournament feature top national teams from continental championships. The main North American league is the WNBA (NCAA Women's Division I Basketball Championship is also popular), whereas the strongest European clubs participate in the EuroLeague Women. %%%%%
print(*json.loads(basketball)('completion').split('@@'), sep='\n')
James Naismith: https://en.wikipedia.org/wiki/James_Naismith Springfield, Massachusetts: https://en.wikipedia.org/wiki/Springfield,_Massachusetts National Basketball Association: https://en.wikipedia.org/wiki/National_Basketball_Association NBA: https://en.wikipedia.org/wiki/National_Basketball_Association EuroLeague: https://en.wikipedia.org/wiki/EuroLeague Basketball Champions League Americas: https://en.wikipedia.org/wiki/Basketball_Champions_League_Americas FIBA Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Basketball_World_Cup EuroBasket: https://en.wikipedia.org/wiki/EuroBasket FIBA AmeriCup: https://en.wikipedia.org/wiki/FIBA_AmeriCup FIBA Women's Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Women%27s_Basketball_World_Cup WNBA: https://en.wikipedia.org/wiki/Women%27s_National_Basketball_Association NCAA Women's Division I Basketball Championship: https://en.wikipedia.org/wiki/NCAA_Division_I_women%27s_basketball_tournament EuroLeague Women: https://en.wikipedia.org/wiki/EuroLeague_Women ^^^^^
Lassen Sie uns dies nun in großem Maßstab tun.
Holen Sie sich tausend Wikipedia -URLs/Schnecken von populären Seiten, Extrahieren von Entitäten und Links
Wir möchten eine zufällige Liste von Wikipedia -URLs finden und ihren zusammenfassenden Text zusammen mit den extrahierten Einheiten (und ihren URLs) erhalten. Dazu werden wir Werbung verwenden, ein Python -Paket, das unter anderem einen SEO -Crawler hat.
Wir werden es vorziehen, die Daten für beliebte Wikipedia -Seiten zu erhalten. Der Grund dafür ist, dass je mehr Menschen eine populärere Seite sind, desto mehr Menschen werden daran arbeiten, sie zu bearbeiten, und daher wird die Qualität der extrahierten Einheiten besser sein. Der folgende Code beginnt mit der Auflistung der am meisten angesehenen Wikipedia -Seiten und folgt den Links von dort. Ich habe Kommentare zu jeder Zeile aufgenommen, die ein bisschen mehr darüber erklären, was es tut.
adv.crawl(
url_list="https://en.wikipedia.org/wiki/Wikipedia:Top_25_Report",
output_file="wiki_crawl.jl",
# for each crawled page, should the crawler follow discovered links?
# this is also known as "spider mode" as opposed to "list mode" where
# only the given URLs are crawled
follow_links=True,
# out of the disovered links, which ones should the crawler follow?
# follow links that match the following regex:
include_url_regex='https://en.wikipedia.org/wiki/(A-Z).+',
# same as the previous parameter, but for exclusion, this is to prevent
# following fragments
exclude_url_regex='#',
# further customization of the crawling process
custom_settings={
# stop crawling after a certain number of pages
'CLOSESPIDER_PAGECOUNT': 1500,
# save the logs of the crawl process in this file (good for debugging)
'LOG_FILE': 'wiki_crawl.jl',
# save the details of the current crawl job to a folder, so we can
# pause/resume the crawl without having to re-crawl the same pages again
'JOBDIR': 'wikicrawl_job'
})
Kriechendatensatzübersicht:
wiki_crawl = pd.read_json('wiki_crawl.jl', lines=True)
wiki_crawl.head(3)
| URL | Titel | Ansichtsfenster | Charset | H1 | H2 | H3 | kanonisch | ALT_HREF | OG: Titel | … | JSONLD_1_AUTHOR.NAME | jsonld_1_publisher.@type | jsonld_1_publisher.name | jsonld_1_publisher.logo.@type | jsonld_1_publisher.logo.url | resp_Headers_set-Cookie | Request_HeaDers_Referer | H4 | IMG_USEMAP | H5 | |
| 0 | https://en.wikipedia.org/wiki/wikipedia:top_25_report | Wikipedia: Top 25 Bericht – Wikipedia | Breite = 1000 | UTF-8 | Wikipedia: Top 25 Bericht | Die beliebtesten Wikipedia -Artikel der Woche (16. bis 22. April 2023) (Bearbeiten) | Ausschlüsse (Bearbeiten) | https://en.wikipedia.org/wiki/wikipedia:top_25_report | //en.m.wikipedia.org/wiki/wikipedia:top_25_report@/w/index.php?title=wikipedia:top_25_report&action=edit@@/w/index…. | Wikipedia: Top 25 Bericht – Wikipedia | … | Nan | Nan | Nan | Nan | Nan | Nan | Nan | Nan | Nan | Nan |
| 1 | https://en.wikipedia.org/wiki/chatgpt | Chatgpt – Wikipedia | Breite = 1000 | UTF-8 | Chatgpt | Contents @@ Training @@ Funktionen und Einschränkungen @@ Service @@ reception @@ Implications @@ Ethical Bedenken @@ Cultural Impact @@ C… | Features @@ limitations @@ Basic Service @@ Premium Service @@ Software Developer Support @@ März 2023 Sicherheitsverstoß @@ Other… | https://en.wikipedia.org/wiki/chatgpt | //en.m.wikipedia.org/wiki/chatgpt@@/w/index.php?title=special:Recentchanges&feed=atom | Chatgpt – Wikipedia | … | Mitwirkende zu Wikimedia -Projekten | Organisation | Wikimedia Foundation, Inc. | ImageObject | https://www.wikimedia.org/static/images/wmf-hor-googpub.png | WMF-DP = 46F; Path =/; | https://en.wikipedia.org/wiki/wikipedia:top_25_report | Nan | Nan | Nan |
| 2 | https://en.wikipedia.org/wiki/wikipedia:Humor | Wikipedia: Humor – Wikipedia | Breite = 1000 | UTF-8 | Wikipedia: Humor | Inhalt @@ Humor braucht Indikatoren (bearbeiten) @@ Warum verantwortungsbewusstes Humor wichtig ist (bearbeiten) @@ Humor in Artikeln (bearbeiten) @@ humor out… | Wie Humor aufgenommen werden kann (bearbeiten) | https://en.wikipedia.org/wiki/wikipedia:Humor | //en.m.wikipedia.org/wiki/wikipedia:humor@/w/index.php?title=wikipedia | Wikipedia: Humor – Wikipedia | … | Nan | Nan | Nan | Nan | Nan | Nan | https://en.wikipedia.org/wiki/wikipedia:top_25_report | Nan | Nan | Nan |
3 Zeilen × 107 Spalten
Extrahieren Sie URL -Schnecken von krabbenden Seiten.
wikipedia_slugs = wiki_crawl(~wiki_crawl('url').str.contains('(a-zA-Z):(a-zA-Z)'))('url').str.rsplit('/').str(-1).tolist()
wikipedia_slugs(:30)
('ChatGPT',
'Mario',
'Netflix',
'GPT-3',
'Language_models',
'LLaMA',
'Meta_AI',
'Bard_(chatbot)',
'Ambedkar_Jayanti',
'The_Greatest_Indian',
'The_Matrix',
'Dalai_Lama',
'Academic_plagiarism',
'Hyderabad',
'B._R._Ambedkar',
'Bon_Jovi',
'Mahatma_Gandhi',
'Mario_Bros.',
'Satoru_Iwata',
'San_Diego_Comic-Con',
'A_Perfect_Crime_(TV_series)',
'If',
'V_Wars',
'When_They_See_Us',
'AJ_and_the_Queen',
'Unbelievable_(miniseries)',
'Trinkets_(TV_series)',
'Trailer_Park_Boys:_The_Animated_Series',
'Twelve_Forever',
'Turn_Up_Charlie')
Gehen Sie durch die Schnecken und extrahieren Sie Entitäten und Links
entity_responses = ()
errors = ()
for i, slug in enumerate(wikipedia_slugs):
try:
print(f'{i:>4}Getting: /{slug}', end='\r')
wikipage = wikipedia_ner(slug)
entity_responses.append(wikipage)
except Exception as e:
err = (slug, str(e))
errors.append(err)
print('Error: ', err)
Erstellen Sie die Trainingsdatei
with open('training_data_wikipedia_ner.jsonl', 'w') as file:
for resp in entity_responses:
prompt = json.loads(resp)('prompt')
completion = json.loads(resp)('completion')
if prompt:
print(json.dumps({'prompt': prompt, 'completion': completion}), file=file)
Damit ist unser Trainingsmodell bereit, ein einfaches Satz von Eingabeaufforderungen/Fertigstellungspaaren, die mit ChatGPT hochgeladen und verwendet werden können.
Sie können es in dieser Live -Entität -Extraktions -App testen und sehen, wie sie funktioniert.
(Tagstotranslate) CHATGPT (T) Structured Data (T) Web Scraping
