
LinkedIn, die weltweit größte professionelle Social-Networking-Site mit 1 Milliarde Mitgliedern in mehr als 200 Ländern und Territorien weltweit. Es ist eine wertvolle Ressource sowohl für Unternehmen als auch für Privatpersonen, da es eine Plattform zum Networking, zur Jobsuche und zum Kennenlernen neuer Branchen bietet.
In diesem Artikel befassen wir uns mit dem Scraping von LinkedIn-Daten und untersuchen die Methoden und Tools zum Extrahieren dieser wertvollen Informationen. Wir stellen Schritt-für-Schritt-Anleitungen und gebrauchsfertige Tools in Google Colaboratory bereit, die es Ihnen ermöglichen, die Leistungsfähigkeit von LinkedIn-Daten für Ihre spezifischen Anforderungen zu nutzen.
LinkedIn-Struktur und Datenobjekte
Wie bereits erwähnt, ist LinkedIn eine professionelle Networking-Plattform, auf der Einzelpersonen Profile erstellen können, die ihre Fähigkeiten, Erfahrungen und beruflichen Erfolge präsentieren. Es wird häufig von Arbeitssuchenden, Personalvermittlern und Fachleuten genutzt, die mit anderen in ihrem Bereich in Kontakt treten möchten.
Bevor wir uns mit dem Datenerfassungsprozess befassen, werfen wir einen genaueren Blick auf LinkedIn und ermitteln die Informationen, die wir extrahieren können. Hier sind einige der wichtigsten Datenpunkte, die auf LinkedIn verfügbar sind:
- Benutzerprofil: Diese Profile bieten umfassende Informationen über Benutzer, einschließlich Name, Standort, aktuelle und frühere Arbeitserfahrungen, Bildungshintergrund, Fähigkeiten und Empfehlungen.
- Stellenangebote: Die Jobsuchfunktion von LinkedIn bietet erweiterte Filter, um die Ergebnisse auf die relevantesten Stellen einzugrenzen. Zu den aus Stellenangeboten extrahierbaren Daten gehören Unternehmensdetails, Standort, Stellenbeschreibungen und spezifische Anforderungen an Kandidaten.
- LinkedIn-Lernen: Diese Plattform bietet viele Online-Kurse und Video-Tutorials. Zu den extrahierbaren Daten gehören Kurstitel, Beschreibungen, Dozenten und Links zu Kursmaterialien.
- LinkedIn-Artikel: Der Abschnitt „Gemeinsame Artikel“ enthält von Benutzern und Experten verfasste Artikel, kategorisiert nach Thema oder Autor. Durch die Datenextraktion können Artikeltitel, Autoren, Inhaltszusammenfassungen und Veröffentlichungsdaten erfasst werden.
Das Scraping verschiedener Plattformelemente ermöglicht einen schnellen Zugriff auf wertvolle Daten über Benutzer und Unternehmen. Benutzerdaten können dabei helfen, qualifizierte und erfahrene Fachkräfte für Rekrutierungszwecke zu identifizieren, und Unternehmensdaten können dabei helfen, potenzielle Kunden, Partner oder zukünftige Beschäftigungsmöglichkeiten zu finden.
Arten von LinkedIn-Scrapern
Vor dem Scrapen von Daten ist es wichtig, die geeignete Methode zur Datenerfassung zu bestimmen. Basierend auf dem gewählten Ansatz gibt es zwei Haupttypen von LinkedIn-Scrapern:
- Proxy-basierte LinkedIn-Scraper. Diese Scraper nutzen einen Pool von Proxys, um Ihre IP-Adresse zu maskieren und eine Erkennung durch LinkedIn zu verhindern. Diese Methode ermöglicht eine groß angelegte Datenextraktion, ohne dass das Risiko einer Kontosperrung besteht. Aufgrund von LinkedIn-Einschränkungen ist der Zugriff auf bestimmte Daten jedoch möglicherweise nicht möglich.
- Cookie-basierte LinkedIn-Scraper. Diese Scraper nutzen Ihre vorhandenen LinkedIn-Sitzungscookies, um Ihre Browsing-Aktivitäten nachzuahmen. Diese Methode bietet eine gezielte Datenerfassung und Zugriff auf personalisierte Informationen. Es ist jedoch auf Ihr Konto angewiesen, was zu einer Kontosperrung führen kann, wenn LinkedIn verdächtige Aktivitäten erkennt.
In diesem Artikel gehen wir näher auf die einzelnen Methoden ein und stellen Codebeispiele zur Veranschaulichung ihrer Implementierung bereit. Wir besprechen auch die Vorteile und Grenzen jedes Ansatzes, um Ihnen bei der Auswahl des für Ihre spezifischen Schabeanforderungen am besten geeigneten Ansatzes zu helfen.
Voraussetzungen
Um die Beispiele in diesem Artikel verwenden zu können, benötigen Sie Python 3.10 oder höher, ausgenommen ein LinkedIn-Konto. Für ein optimiertes Erlebnis wird eine Python-IDE empfohlen, aber jeder Code-Editor mit Syntaxhervorhebung und installiertem Python reicht aus.
Eine virtuelle Umgebung ist optional, wenn Sie die Sicherheit Ihres Scrapings nicht erhöhen möchten. Wie man es einrichtet und verwendet, haben wir bereits im Python-Scraping-Artikel behandelt.
In diesem Artikel werden wir mehrere Bibliotheken verwenden. Installieren Sie sie mit dem Paketmanager:
pip install beautifulsoup4 requests selenium requests_oauthlib jsonMöglicherweise benötigen Sie auch einen Webtreiber, um Selenium verwenden zu können. Der Artikel zum Selen-Scraping enthält Anweisungen dazu, wo man es findet und verwendet.
Lassen Sie uns die verschiedenen Methoden zum Extrahieren von Daten aus LinkedIn erkunden. Unabhängig von der gewählten Methode bleibt der Scraping-Prozess bis auf die Verwendung der LinkedIn-API unverändert. Der einzige Unterschied besteht im ursprünglichen Skript zum Abrufen des Quellcodes der Seite.
Verwendung der LinkedIn-API
Wie viele andere Plattformen mit großen Datenmengen bietet LinkedIn seine API für den Datenzugriff an. Diese Methode hat jedoch sowohl Vor- als auch Nachteile.
Beispielsweise garantiert die Nutzung von LinkedIn einen einfachen und schnellen Zugriff auf alle benötigten Daten in einem praktischen Format. Allerdings kann die Arbeit mit der LinkedIn-API schwieriger sein als zunächst angenommen. Die erste Hürde besteht darin, einen Server zur Generierung eines Tokens einzurichten, was ohne das erforderliche Fachwissen recht kompliziert sein kann.
Darüber hinaus legt LinkedIn tägliche Anforderungslimits für API-Aufrufe fest. Dies kann zu Skalierbarkeitsproblemen für Anwendungen führen, die häufig auf die API zugreifen.
Was die über die API abrufbaren Daten angeht, sind nicht alle LinkedIn-Daten über die API extrahierbar. Beispielsweise ist der Zugriff auf die Liste der verfügbaren Stellenangebote nicht gestattet. Darüber hinaus müssen Sie als einzelner Entwickler bei der App-Erstellung ein Testunternehmen angeben, und die Verwendung eines solchen Unternehmens schränkt den Zugriff auf bestimmte Endpunkte ein.
Wenn Sie sich dennoch dazu entschließen, diese Methode auszuprobieren, gehen Sie zur Entwicklerseite und erstellen Sie Ihre Anwendung. Um die erforderlichen Schlüssel zu erhalten, müssen Sie ein Formular ausfüllen. Anschließend finden Sie im Abschnitt „Auth“ Ihre persönliche „Client-ID“ und Ihr „Client-Geheimnis“.
Erstellen Sie ein neues Python-Projekt, importieren Sie die erforderlichen Bibliotheken und geben Sie die erhaltenen Anmeldeinformationen ein:
from requests_oauthlib import OAuth2Session
cl_id = 'PUT-YOUR-CLIENT-ID'
cl_secret="PUT-YOUR-CLIENT-SECRET"Anschließend erstellen wir Variablen, um die notwendigen Links zum Erhalt von Tokens und zur Autorisierung zu speichern:
redirect_url="http://localhost:8080/callback"
base_url="https://www.linkedin.com/oauth/v2/authorization"
token_url="https://www.linkedin.com/oauth/v2/accessToken"Öffnen Sie die Sitzung:
linkedin = OAuth2Session(cl_id, redirect_uri=redirect_url)Generieren Sie einen Autorisierungslink und zeigen Sie ihn auf dem Bildschirm an:
authorization_url, state = linkedin.authorization_url(base_url)
print('Go to:', authorization_url)Als nächstes müssen Sie dem Link in Ihrem Browser manuell folgen. Alternativ können Sie Selenium integrieren, um den Token-Abrufprozess zu automatisieren. Sobald Sie das Token haben, geben Sie den vollständigen Link zum Skript zurück:
response = input('Put full URL: ')Dann holen Sie sich den Token:
linkedin.fetch_token(token_url, client_secret=cl_secret, authorization_response=response)Mit dem erhaltenen Token können Sie nun über die LinkedIn-API auf die benötigten Daten zugreifen. Die umfassende LinkedIn-API-Dokumentation bietet detaillierte Informationen zu den verschiedenen verfügbaren Endpunkten.
Verwendung von Requests und BeautifulSoup
Eine weitere Möglichkeit, Daten zu erhalten, besteht darin, eine reguläre Anforderungsbibliothek und Proxys oder Cookies zu verwenden. Wie wir bereits erwähnt haben, können Sie ohne Genehmigung auf alle öffentlich zugänglichen Daten zugreifen, solange LinkedIn Ihre Aktivitäten nicht verdächtig findet. Allerdings ist in diesem Fall die Gefahr einer Blockierung hoch.
Andererseits können Sie die Proxys ständig wechseln, um eine Blockierung Ihrer echten IP-Adresse zu vermeiden. Oder Sie können Ihre echten Cookies und Header verwenden, um Ihre Anfragen weniger verdächtig zu machen. Betrachten wir beide Optionen und beginnen wir mit der Verwendung von Proxys.
Wir haben bereits ausführlich über die Verwendung von Proxys mit der Requests-Bibliothek in Python geschrieben, daher werden wir nicht näher darauf eingehen und Ihnen ein vorgefertigtes Beispiel für die Ausführung einer Anfrage mit einem Proxy geben:
import requests
url ="https://www.linkedin.com/jobs/search?position=1&pageNum=0"
proxies = {
'http': 'http://45.95.147.106:8080',
'https': 'https://37.187.17.89:3128'
}
response = requests.get(url, proxies=proxies)Sie können die Proxy-Rotation selbst einrichten oder einen Proxy-Server verwenden. Eine Liste zuverlässiger Proxy-Anbieter finden Sie in unseren Top 10 Proxy-Anbietern für Privathaushalte.
Wenn Sie Ihre tatsächlichen Cookies verwenden möchten, gehen Sie zur LinkedIn-Seite, melden Sie sich an und gehen Sie zu DevTools (F12 oder Rechtsklick und Prüfen). Gehen Sie dann zur Registerkarte Netzwerk und suchen Sie das gewünschte Feld:
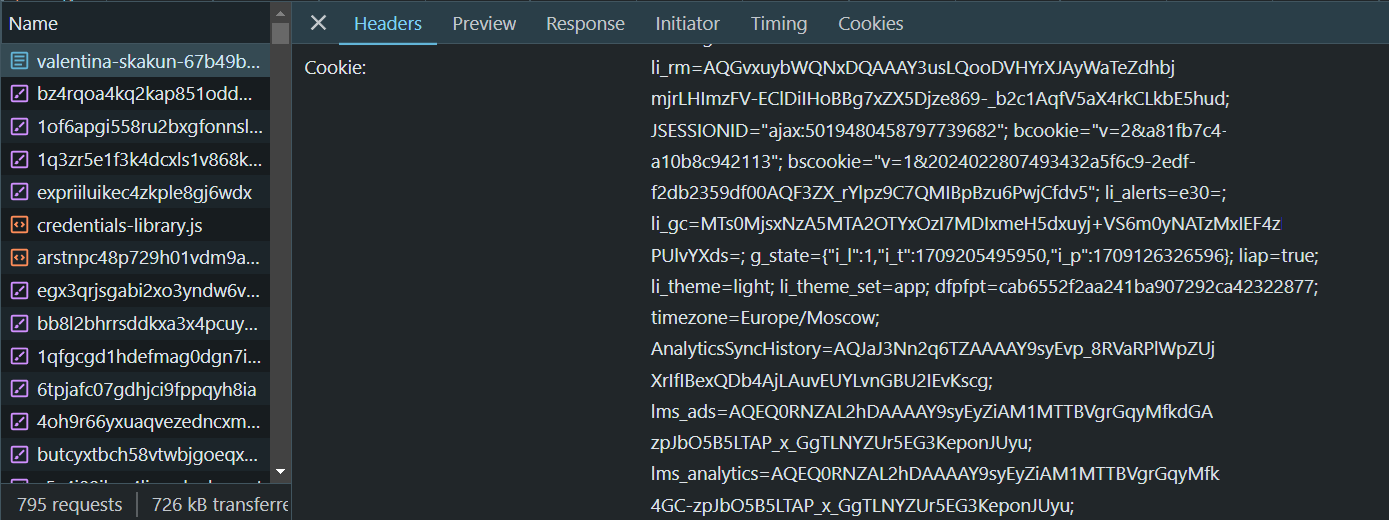
Zusätzlich zu den oben genannten Headern sollten Sie einige andere Header einfügen, einschließlich einer gültigen User-Agent-Zeichenfolge. Sie können unser Beispiel verwenden, aber Sie sollten die Platzhalterwerte durch Ihre Cookies und die neueste User-Agent-Zeichenfolge ersetzen, bevor Sie es verwenden.
cookies = "YOUR-COOKIES"
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Connection':'keep-alive',
'accept-encoding': 'gzip, deflate, br',
'Referer':'http://www.linkedin.com/',
'accept-language': 'en-US,en;q=0.9',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',
'Cookie': cookies
}Geben Sie bei einer Anfrage unbedingt die folgenden Header an:
response = requests.get(url, headers=headers)Es steht Ihnen frei, eine der in Betracht gezogenen Optionen zu wählen, da beide die erforderlichen Daten erhalten.
Verwenden von Profilen in Selenium
Eine weitere Möglichkeit ist die Verwendung von Selenium-Profilen. Sie können ein vorhandenes Browserprofil verwenden, in dem Sie bei LinkedIn angemeldet sind, oder ein neues Profil erstellen und den Anmeldevorgang mithilfe der Selenium-Bibliotheksfunktion automatisieren.
Sie können sich auch einfach mit Selenium anmelden, ohne Profile zu verwenden. In diesem Fall müssen Sie dies jedoch jedes Mal tun, wenn Sie Ihr Skript ausführen.
Daher ist es einfacher, sich einmal bei einem bestimmten Profil anzumelden und dann einfach Daten zu sammeln. In diesem Fall wird die Autorisierung nach einem Neustart des Skripts gespeichert. Außerdem können Sie sich manuell über Google bei Ihrem Konto anmelden und dann das Profil mit der abgeschlossenen Autorisierung verwenden.
Importieren Sie dazu die Bibliothek:
from selenium import webdriverGeben Sie den Profilpfad an und legen Sie Webtreiberoptionen fest:
profile_path = r'C:\Users\Admin\AppData\Local\Google\Chrome\User Data\Profile 1'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument(f'--user-data-dir={profile_path}')Nachdem die notwendigen Bibliotheken importiert und der Browsertreiber initialisiert wurden, können Sie das WebDriver-Objekt erstellen:
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://www.linkedin.com/jobs/search?position=1&pageNum=0')Diese Option eignet sich, wenn Sie ein Profil verwenden möchten, in dem Sie bereits auf LinkedIn angemeldet sind. Wenn Sie sich über ein Skript anmelden möchten, müssen Sie eine andere Seite aufrufen:
driver.get("https://linkedin.com/uas/login")Um den Benutzernamen und das Passwort einzugeben, identifizieren wir die Eingabefelder:
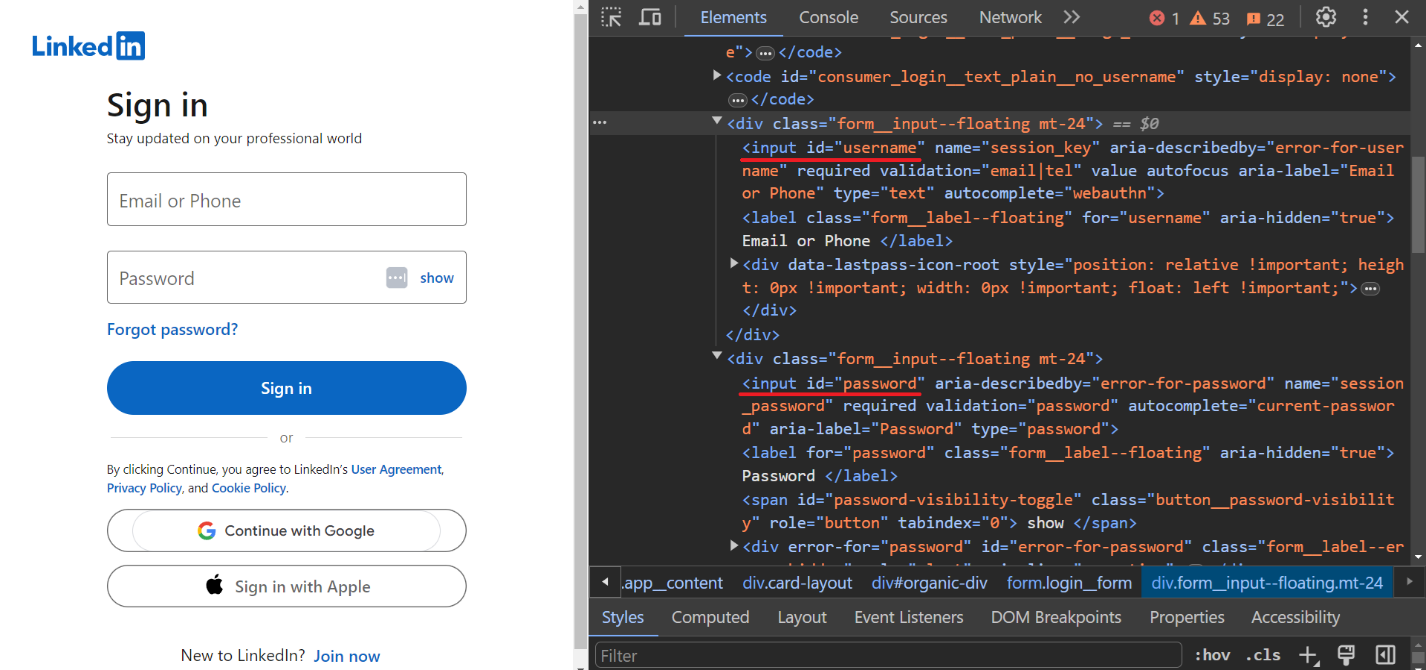
Geben Sie die Anmelde- und Kennwortanmeldeinformationen des Benutzers ein:
username = driver.find_element(By.ID, "username")
username.send_keys("PUT-YOUR-LOGIN")
password = driver.find_element(By.ID, "password")
password.send_keys("PUT-YOUR-PASSWORD") Bestätigen Sie die Daten:
driver.find_element(By.XPATH, "//button(@type="submit")").click()Diese Autorisierung wird in Ihrem aktuellen Profil gespeichert und Sie können ohne diesen Schritt scrapen.
Verwenden Sie die Web Scraping API
Der einfachste und sicherste Weg, Daten von LinkedIn zu extrahieren, ist die Verwendung einer Web-Scraping-API. Dadurch werden die notwendigen Daten erfasst und nur die endgültigen Ergebnisse bereitgestellt. Dadurch können Sie die Verwendung von Proxys und die Sorge um Blockierungsprobleme vermeiden, da Anfragen an LinkedIn nicht auf der Clientseite, sondern auf der Seite des API-Dienstes erfolgen.
Betrachten wir diese Option am Beispiel der Web-Scraping-API von HasData. Um es zu nutzen, melden Sie sich auf unserer Website an und kopieren Sie Ihren persönlichen API-Schlüssel, den Sie in Ihrem Konto finden.
Als nächstes erstellen wir ein neues Projekt und importieren die notwendigen Bibliotheken:
import requests
import jsonGeben Sie einen Link zur Stellenanzeige und den kürzlich kopierten API-Schlüssel an:
ln_url = "https://www.linkedin.com/jobs/search?position=1&pageNum=0"
api_key = "PUT-YOUR-API-KEY"Definieren Sie einen API-Endpunkt und Anforderungsparameter, einschließlich der Art der zu verwendenden Proxys:
url = "https://api.hasdata.com/scrape/web"
payload = json.dumps({
"url": ln_url,
"proxyCountry": "US",
"proxyType": "datacenter",
"blockResources": True,
"blockAds": True,
"screenshot": True,
"jsRendering": True,
"extractEmails": True
})
headers = {
'Content-Type': 'application/json',
'x-api-key': api_key
}Stellen Sie die Anfrage:
response = requests.request("POST", url, headers=headers, data=payload)Als Ergebnis gibt die Web-Scraping-API von HasData alle Daten zurück, einschließlich Header, Inhalt und einen Screenshot der Seite.
Scrapen Sie Daten von LinkedIn
Lassen Sie uns anhand von Beispielen den Prozess des Scrapens verschiedener LinkedIn-Seiten untersuchen. Der allgemeine Ansatz bleibt derselbe, mit Ausnahme der Seiten-URLs und der Struktur.
Wir nutzen die Web-Scraping-API von HasData, um Seiten abzurufen, wodurch die Notwendigkeit von Proxys entfällt und Blockierungsprobleme vermieden werden. Darüber hinaus verwenden wir die BeautifulSoup-Bibliothek, um den extrahierten Seitencode zu analysieren. Sie können alle zuvor besprochenen Methoden verwenden, um den HTML-Code der Seite abzurufen. Die Verarbeitungs- und Analyseschritte bleiben jedoch dieselben.
Scraping von LinkedIn-Stellenangeboten
Beginnen wir damit, Daten aus den Stellenangeboten zu extrahieren. Ein fertiges Scraper-Skript finden Sie in Google Colaboratory. Gehen wir zur Jobsuchseite und sehen, welche Daten wir extrahieren können.
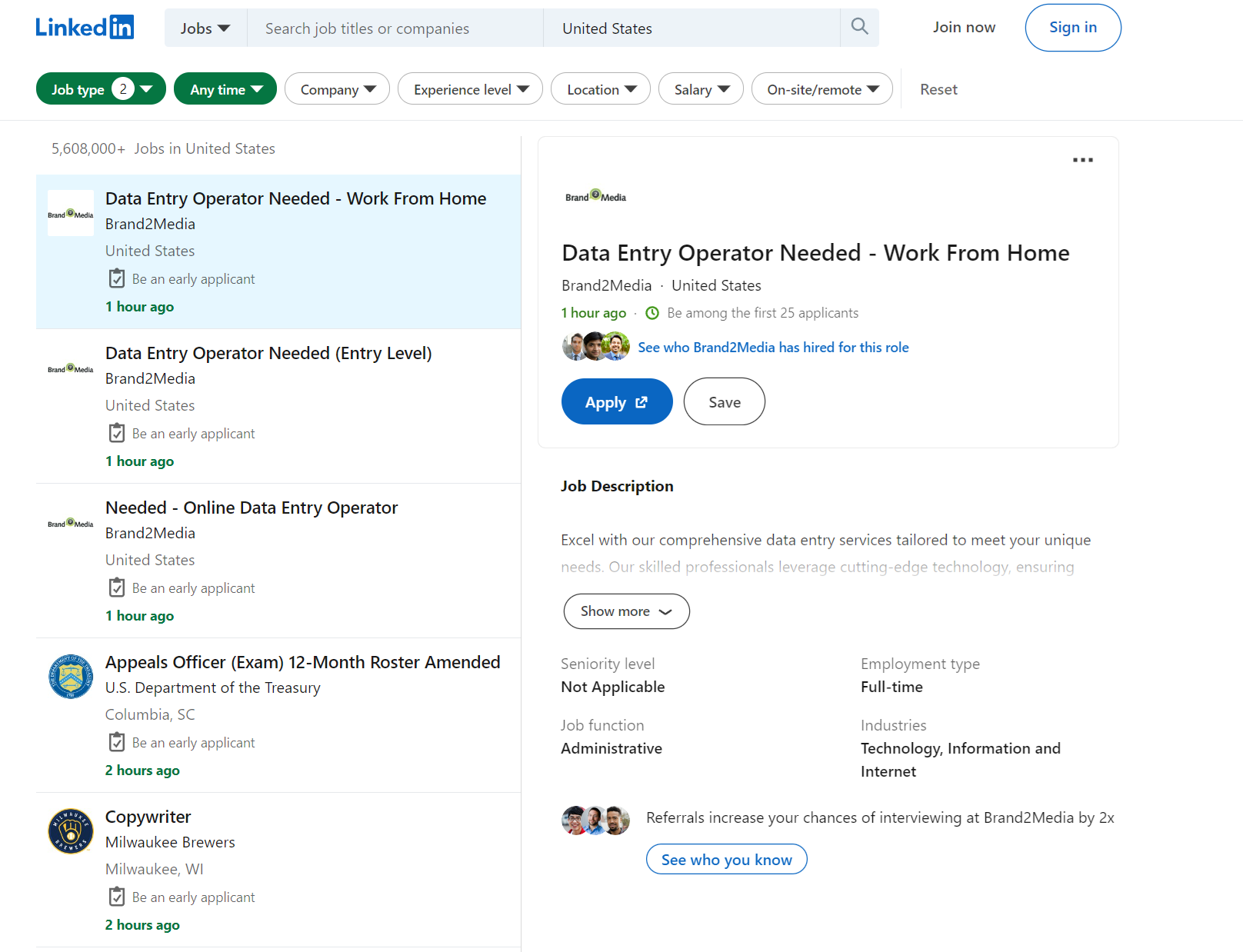
Lassen Sie uns die Filter aufschlüsseln, die wir verwenden können:
f_SB2: Gehaltsstufe von 1 bis 5, beginnend bei 40.000 $ mit einer Erhöhung um 20.000 $.f_E: Bildungsniveau von 1 bis 5, Mehrfachauswahl möglich.f_TPR: Zeitraum. Wenn leer, werden offene Stellen für alle Zeit angezeigt.location: Standort. Land oder Stadt können angegeben werden.keywords: Schlüsselwörter für die Suche nach offenen Stellen.f_JT: Auftragstyp. Der erste Buchstabe wird als Parameter verwendet, z. B. Vollzeit als F oder Teilzeit als P. Es können mehrere Optionen angegeben werden.position: Positionsnummer der offenen Stelle, zu der Details angezeigt werden.pageNum: Seitenzahl suchen.
Durch das Extrahieren von Daten aus einer einzigen Seite für alle verfügbaren Stellenangebote, ohne durch jede Seite navigieren zu müssen, können wir nur Daten zum Unternehmen, zum Stellentitel, zum Standort und zur Anzahl der Antworten extrahieren.
Erstellen Sie ein neues Skript und rufen Sie diese Daten ab. Zunächst importieren wir die erforderlichen Bibliotheken:
import requests
import json
from bs4 import BeautifulSoup
import csvLegen Sie dann die Jobeinstellungen fest und generieren Sie den Link:
f_SB2 = 1 # Salary level from 40k to $120k
f_E = 1 # Expirience level 1 (e.g., Internship)
f_TPR = "" # Vacancies displayed for all time periods
location = "United States" # Country or city
keywords = "Data Scientist" # Keywords for search
f_JT = "F" # Employment type - Full-time
position = 1 # Job position number for details
pageNum = 0 # Page number of search results
# Constructing the URL
ln_url = f"https://www.linkedin.com/jobs/search?f_SB2={f_SB2}&f_E={f_E}&f_TPR={f_TPR}&location={location}&keywords={keywords}&f_JT={f_JT}&position={position}&pageNum={pageNum}"Legen Sie den API-Schlüssel Ihres HasData fest:
api_key = "PUT-YOUR-API-KEY"Erhalten Sie LinkedIn-Stellenlistendaten mithilfe der Web-Scraping-API:
url = "https://api.hasdata.com/scrape/web"
payload = json.dumps({
"url": ln_url,
"proxyCountry": "US",
"proxyType": "datacenter",
"blockResources": True,
"blockAds": True,
"screenshot": True,
"jsRendering": True,
"extractEmails": True
})
headers = {
'Content-Type': 'application/json',
'x-api-key': api_key
}
response = requests.request("POST", url, headers=headers, data=payload)
job_content = response.json()('content')Analysieren Sie den HTML-Code der Seite:
soup = BeautifulSoup(job_content, 'html.parser')Erhalten Sie Daten für jeden Auftrag:
job_list = soup.find('ul', class_='jobs-search__results-list')
if job_list:
jobs = job_list.find_all('li')
job_data = ()
for job in jobs:
print(job)
job_title = job.find('h3', class_='base-search-card__title').get_text(strip=True) if job.find('h3', class_='base-search-card__title') else '-'
company = job.find('h4', class_='base-search-card__subtitle').get_text(strip=True) if job.find('h4', class_='base-search-card__subtitle') else '-'
location = job.find('span', class_='job-search-card__location').get_text(strip=True) if job.find('span', class_='job-search-card__location') else '-'
job_link = job.find('a')('href') if job.find('a') else '-'
posted_date = job.find('time', class_='job-search-card__listdate')('datetime') if job.find('time', class_='job-search-card__listdate') else '-'
job_info = {
'job_title': job_title,
'company': company,
'location': location,
'job_link': job_link,
'posted_date': posted_date
}
job_data.append(job_info)Drucken Sie das Ergebnis auf dem Bildschirm aus:
if job_data:
for job in job_data:
print("Job Title:", job('job_title'))
print("Company:", job('company'))
print("Location:", job('location'))
print("Job Link:", job('job_link'))
print("Posted Date:", job('posted_date'))
print("-" * 50)Oder speichern Sie diese Daten im CSV-Format:
with open("job_data.csv", 'w', newline="", encoding='utf-8') as csvfile:
fieldnames = ('job_title', 'company', 'location', 'job_link', 'posted_date')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in job_data:
writer.writerow(job)Als Ergebnis erhalten wir:
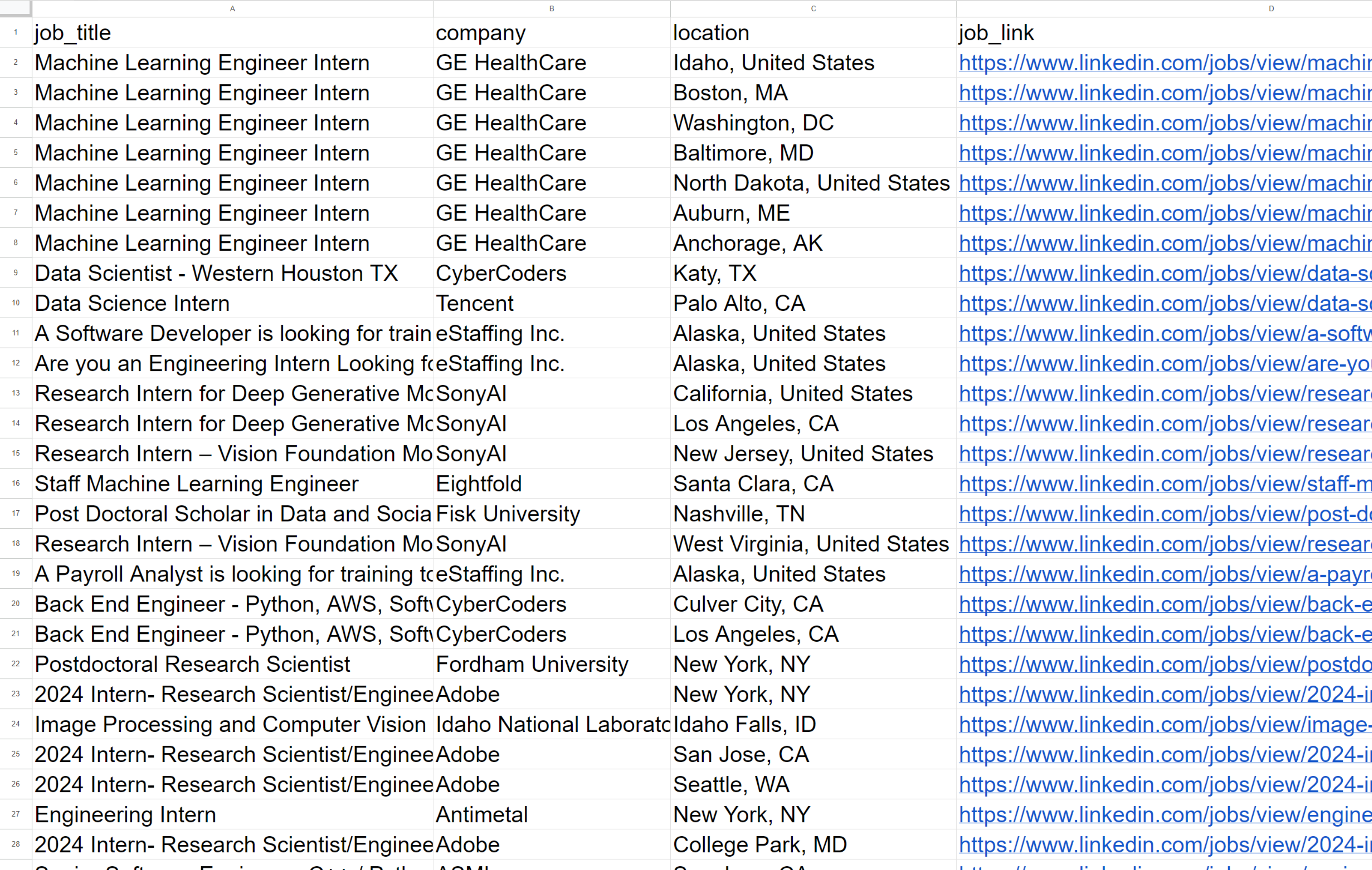
Wie Sie sehen, erhalten wir nach der Ausführung des Skripts Daten zu 60 offenen Stellen, die in einem praktischen Format zurückgegeben werden. Um detaillierte Daten zu den einzelnen Stellenangeboten zu erhalten, müssen Sie leider jede einzelne durchgehen, was umständlich sein kann, da viele Anfragen erforderlich sind.
Scrapen Sie LinkedIn Learning
LinkedIn Learning bietet umfangreiche Kurse und Video-Tutorials zu verschiedenen Themen. Darüber hinaus steht in Google Colaboratory ein gebrauchsfertiges Skript zur Verfügung.
Lassen Sie uns durch die LinkedIn Learning-Seite navigieren und die verfügbaren Filter und Datenextraktionsmöglichkeiten erkunden.
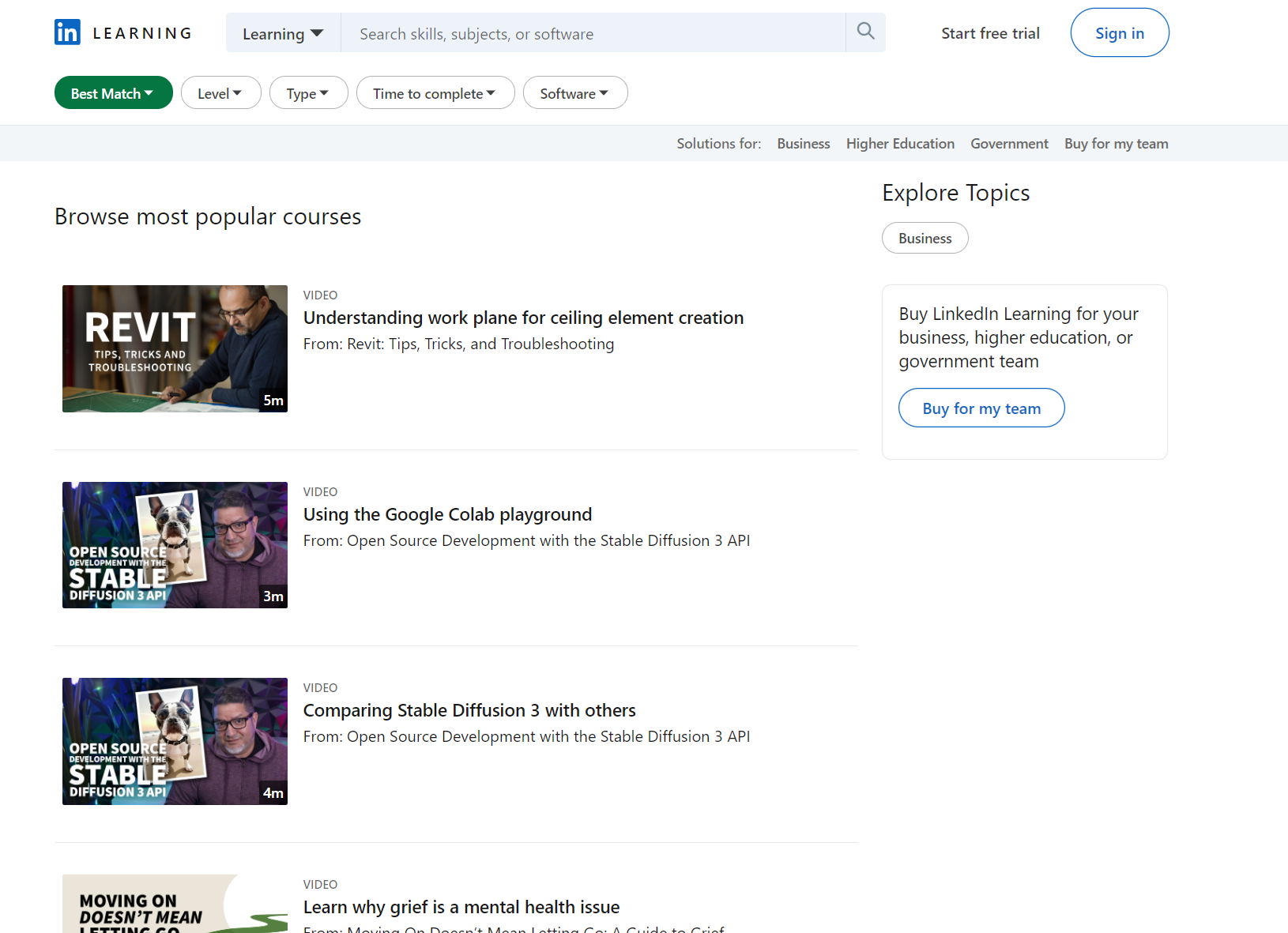
Diese Seite hat weniger Filter. Schauen wir sie uns genauer an:
sortBy: Die Methode zum Sortieren der Ergebnisse. Zum Beispiel „RELEVANCE“ zum Sortieren nach Relevanz.difficultyLevel: Der Schwierigkeitsgrad des Kurses. Zum Beispiel „BEGINNER“ für Anfängerniveau.entityType: Der Entitätstyp, der in den Suchergebnissen zurückgegeben wird. In diesem Fall ist dies „COURSE“ für Kurse.durationV2: Die Dauer des Kurses. Beispiel: „BETWEEN_0_TO_10_MIN“ für Kurse mit einer Dauer von 0 bis 10 Minuten.softwareNames: Die Namen der Software, auf die sich die Kurse beziehen. Beispielsweise „Power+Platform“ für Kurse rund um Power Platform.
Auf dieser Seite können wir den Titel und den Link zum Kurs, seinen Autor und die Art des Lernmaterials extrahieren. Nehmen wir unseren bisherigen Code als Grundlage und ersetzen wir die Parameter zur Generierung des Links:
sortBy = "RELEVANCE"
difficultyLevel = "BEGINNER"
entityType = "COURSE"
durationV2 = ""
softwareNames = ""
# Constructing the URL
ln_url = f"https://www.linkedin.com/learning/search?trk=content-hub-home-page_guest_nav_menu_learning&sortBy={sortBy}&difficultyLevel={difficultyLevel}&entityType={entityType}&durationV2={durationV2}&softwareNames={softwareNames}"Und Selektoren zum Parsen der Seite:
learn_list = soup.find('ul', class_='results-list')
if learn_list:
learns = learn_list.find_all('li')
learn_data = ()
for learn in learns:
title = learn.find('h3', class_='base-search-card__title').text.strip() if learn.find('h3', class_='base-search-card__title') else '-'
subtitle = learn.find('h4', class_='base-search-card__subtitle').text.strip() if learn.find('h4', class_='base-search-card__subtitle') else '-'
identifier = learn.find('p', class_='base-search-card__identifier').text.strip() if learn.find('p', class_='base-search-card__identifier') else '-'
learn_link = learn.find('a')('href') if learn.find('a') else '-'
job_info = {
'title': title,
'subtitle': subtitle,
'identifier': identifier,
'learn_link': learn_link,
}
learn_data.append(job_info)Der restliche Code bleibt gleich. Dadurch wird eine Datei mit einer Liste der verfügbaren Kurse erstellt:
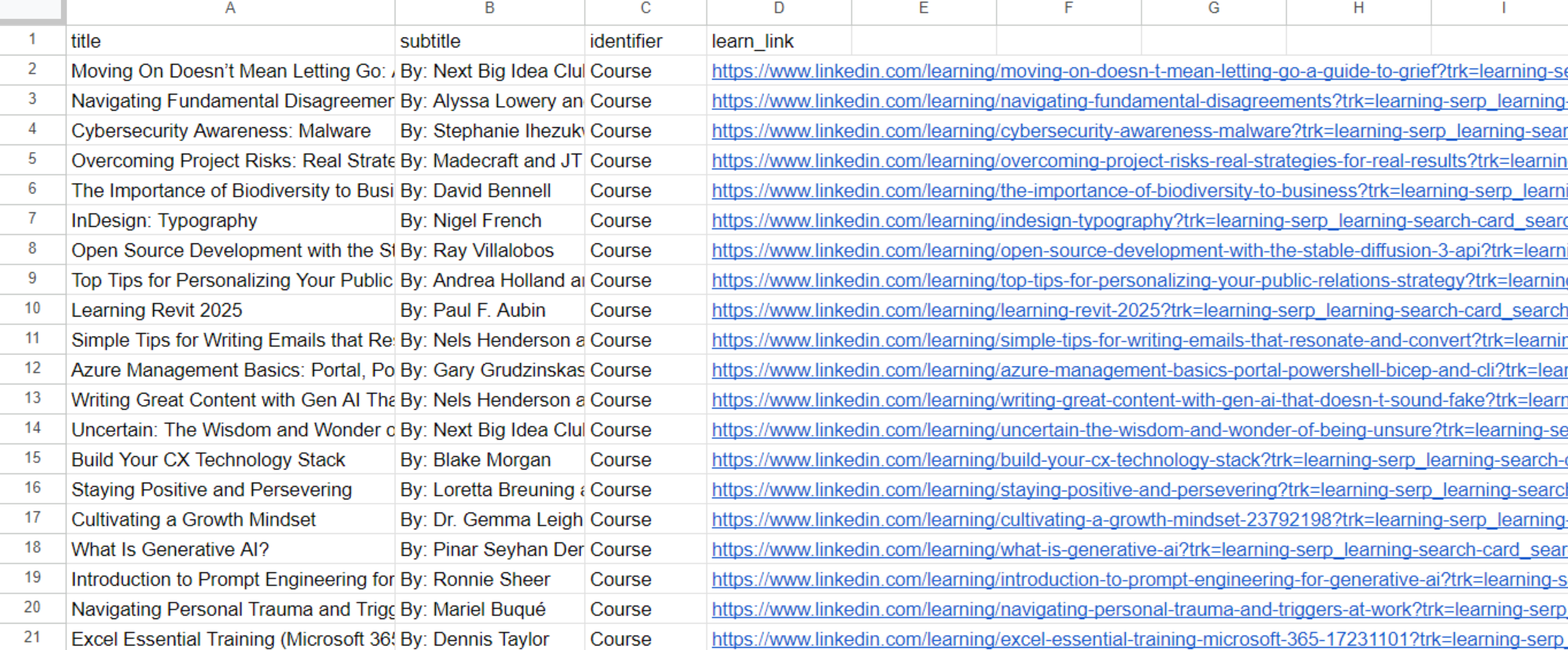
Wir haben eine Datei mit 50 anfängerfreundlichen Lernmaterialien erhalten, darunter Kurse und Video-Tutorials mit einer Länge von 0 bis 10 Minuten.
Scrapen Sie LinkedIn-Artikel
Ein weiterer Abschnitt, der möglicherweise schnell gelöscht werden muss, sind LinkedIn-Artikel. Ein fertiges Skript finden Sie auf Google Colaboratory.
Gehen wir zur Seite „LinkedIn-Artikel“ und schauen wir uns diese genauer an:
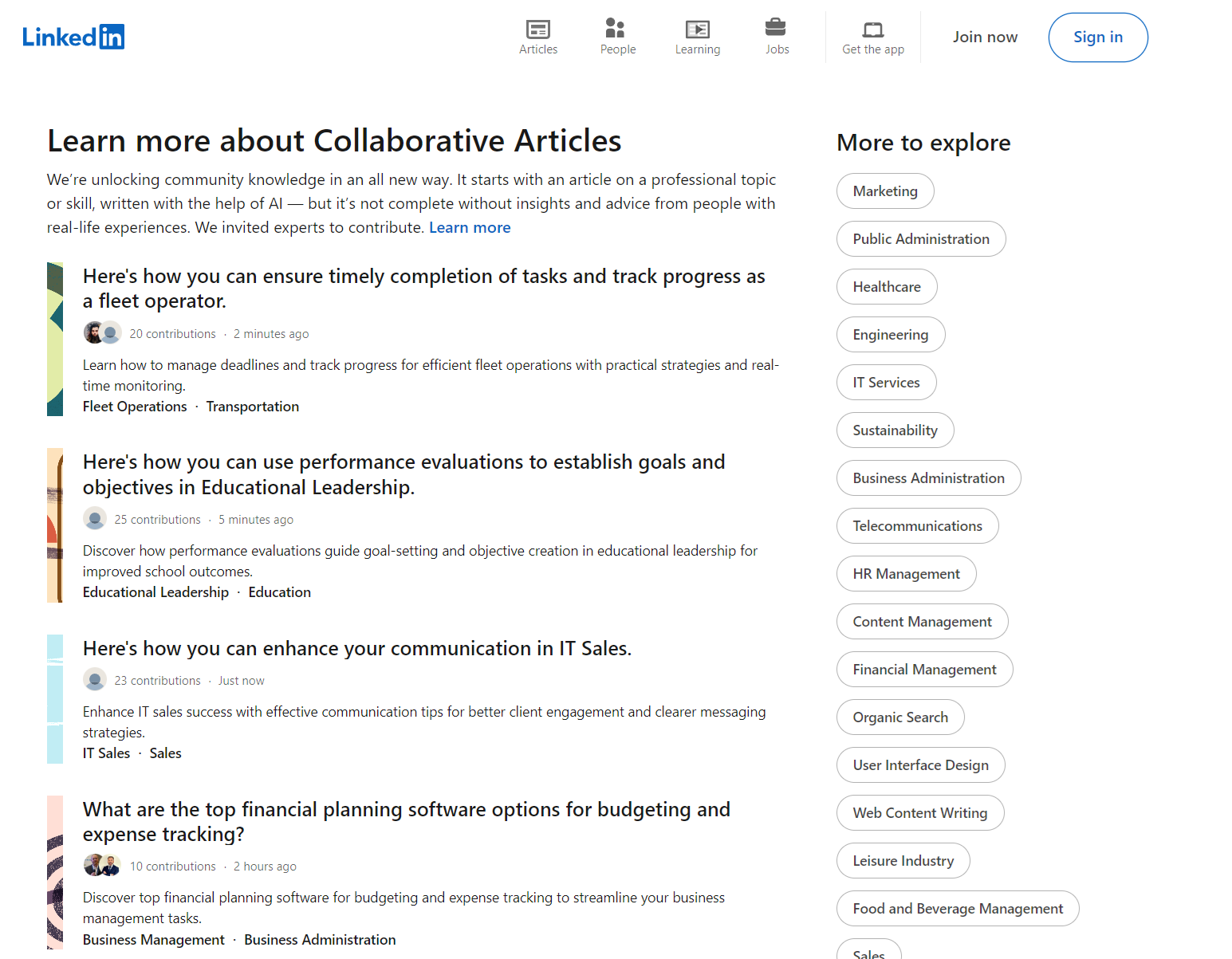
Im Gegensatz zu den vorherigen Beispielen gibt es hier keine anpassbaren Filter. Sie können jedoch rechts eine beliebige Kategorie oder Unterkategorie auswählen. Als Beispiel verwenden wir einen Link zum Root-Bereich:
ln_url = f"https://www.linkedin.com/pulse/topics/home/"Und Selektoren ändern:
article_list = soup.find('div', class_='content-hub-home-core-rail')
if article_list:
articles = article_list.find_all('div', class_='content-hub-entity-card-redesign')
article_data = ()
for article in articles:
title = article.find('h2').text.strip() if article.find('h2') else '-'
description = article.find('p', class_='content-description').text.strip() if article.find('p', class_='content-description') else '-'
contributions = article.find('span').text.strip() if article.find('span') else '-'
timestamp = article.find_all('span')(-1).text.strip() if article.find('span') else '-'
article_link = article.find('a')('href') if article.find('a') else '-'
article_info = {
'title': title,
'description': description,
'contributions': contributions,
'timestamp': timestamp,
'article_link': article_link,
}
article_data.append(article_info)Andere Teile des Skripts bleiben dieselben wie in den vorherigen Beispielen und erzeugen die folgende CSV-Datei:

Insgesamt haben wir 100 Artikellinks zum angegebenen Thema erhalten. Bei Bedarf kann das Skript verfeinert werden, um detailliertere Daten zu sammeln, indem alle Links in einer Warteschlange durchsucht werden. Dadurch können wir Artikelinhalte, Autoreninformationen, Links zu ihren Profilen und Diskussionsteilnehmern abrufen.
Abschluss
In diesem Artikel haben wir verschiedene Methoden für den Zugriff auf Daten auf LinkedIn untersucht und verschiedene Ansätze zur Implementierung von Scrapern untersucht. Darüber hinaus haben wir gebrauchsfertige Codebeispiele bereitgestellt und diese für einen bequemen Zugriff und eine cloudbasierte Ausführung auf Google Colaboratory hochgeladen.
Aus diesem Grund haben wir mehrere praktische Tools entwickelt, die das Extrahieren personalisierter Daten aus LinkedIn erleichtern, unabhängig davon, ob die Daten von einer Kursseite oder einer Seite mit Stellenangeboten abgerufen werden. Um die Datenerfassung zu veranschaulichen und zu vereinfachen, haben wir die API von HasData genutzt, die eine Datenerfassung ermöglicht, ohne dass das Risiko einer Blockierung durch LinkedIn besteht und ohne dass man sich bei seinem Profil anmelden muss.
