
Web Scraping ist eine der beliebtesten Methoden zur Datenerfassung. Es ist ein hervorragender Ersatz für die manuelle Datenerfassung, da es die Möglichkeit von Fehlern ausschließt, den Zeitaufwand reduziert und große Datenmengen schnell bereitstellt.
Wir haben bereits viel darüber gesprochen, wie man Daten von Online-Shops sammelt, um Konkurrenten zu verfolgen, und wie man Google-Dienste wie Maps und SERP (Suchmaschinen-Ergebnisseite) auswertet. Heute besprechen wir, wie Sie mithilfe von Web Scraping schnell und effizient Bilder sammeln können.
Vorteile von Image Scraping
Obwohl das Scraping von Google-Bildern nicht so gefragt ist wie das Scraping anderer Google-Dienste, kann es in einigen Geschäftsbereichen dennoch eine Notwendigkeit sein. Sie können beispielsweise gescrapte Bilder verwenden, um die Qualität visueller Inhalte und die Benutzerinteraktion zu verbessern. Es ist auch hilfreich, trendige und relevante Bilder zu finden. Und natürlich ist es eine großartige Möglichkeit, große Mengen an Bildern zu sammeln, wenn Sie verschiedene Bildergalerien für Websites oder sogar für maschinelles Lernen erstellen möchten.
Wenn wir über Image-Scraping-Methoden sprechen, können wir sie in zwei Teile unterteilen: manuell und automatisiert. Da es sich beim manuellen Scraping um das manuelle Herunterladen von Bildern handelt, was viel Zeit und Mühe erfordert, werden wir uns nicht näher mit dieser Methode befassen.
Schauen wir uns stattdessen Möglichkeiten an, das Scraping von Google-Bildern zu automatisieren.
Erstellen eines benutzerdefinierten Web Scrapers
Sie können versuchen, Ihren Image Scraper zu erstellen, wenn Sie über grundlegende Programmierkenntnisse verfügen. Zu diesem Zweck können Sie nahezu jede Programmiersprache verwenden. Wenn Sie erfahren möchten, welche Bibliotheken Sie verwenden sollten, und grundlegende Kenntnisse erwerben möchten, können Sie unsere Artikel zum Web Scraping mit Python, NodeJS, PHP, Ruby, R oder C# lesen. Sie können beispielsweise ganz einfach Daten in Python mit der Beautiful Soup® UrlLib oder der Selenium-Bibliothek mit Webdriver sammeln. Wir haben bereits darüber geschrieben, wie man Google-Suchergebnisse mit diesen Bibliotheken und CSS-Selektoren scrapt, und das Scraping von Bildern ist nicht viel anders.
Obwohl dies zunächst schwierig erscheinen mag und Sie auf einige Herausforderungen stoßen werden, gibt es eine Möglichkeit, diese zu meistern. Sie können beispielsweise eine Web-Scraping-API verwenden, um den Scraping-Prozess zu vereinfachen und das Risiko einer Blockierung zu verringern.
Nutzung von Online-Diensten
Die zweite Möglichkeit, den Scraping-Prozess von Google Images zu automatisieren, besteht darin, spezielle Web-Scraping-Dienste zum Sammeln der Daten zu nutzen. Hier benötigen Sie keine Programmierkenntnisse, sondern können nur die Daten sammeln, die der Dienst bereitstellt. Das bedeutet, dass dieser Dienst nicht für Sie geeignet ist, wenn Sie unter den bereitgestellten Daten nicht über die benötigten Daten verfügen.
Neben speziellen Diensten gibt es auch verschiedene Plug-Ins für Browser. Allerdings verfügen sie entweder über keine Flexibilität oder erfordern eine individuelle Anpassung, was Programmierkenntnisse erfordert.
Vor diesem Hintergrund möchten wir den Bedarf an Programmierkenntnissen minimieren und dennoch die vielseitigste Lösung mit einem breiten Funktionsumfang erhalten. Daher verwenden wir den Request Builder für die Web Scraping API. Auf diese Weise konfigurieren wir alle Parameter, einschließlich der Lokalisierung, und führen Anfragen auf der Site aus.
Erhalten Sie Bilddaten mit Scrape-It.Cloud Request Builder
Wir werden uns später mit dem Scraping von Bildern auf Python mithilfe der Scrape-It.Cloud-API befassen. Wir möchten jedoch zeigen, wie man ohne Programmierung Links zu Bildern erhält. Der Einfachheit halber haben wir diesen Prozess in Schritte unterteilt.
Schritt 1: Besorgen Sie sich einen API-Schlüssel
Melden Sie sich auf der Website an, um Zugriff auf die Google SERP API und ein persönliches Konto zu erhalten, über das Sie Anfragen beantworten können. Sie erhalten außerdem kostenlose Credits, sodass Sie die Funktionalität auch ohne Bezahlung ausprobieren können.
Ein API-Schlüssel befindet sich auf der Registerkarte „Dashboard“.
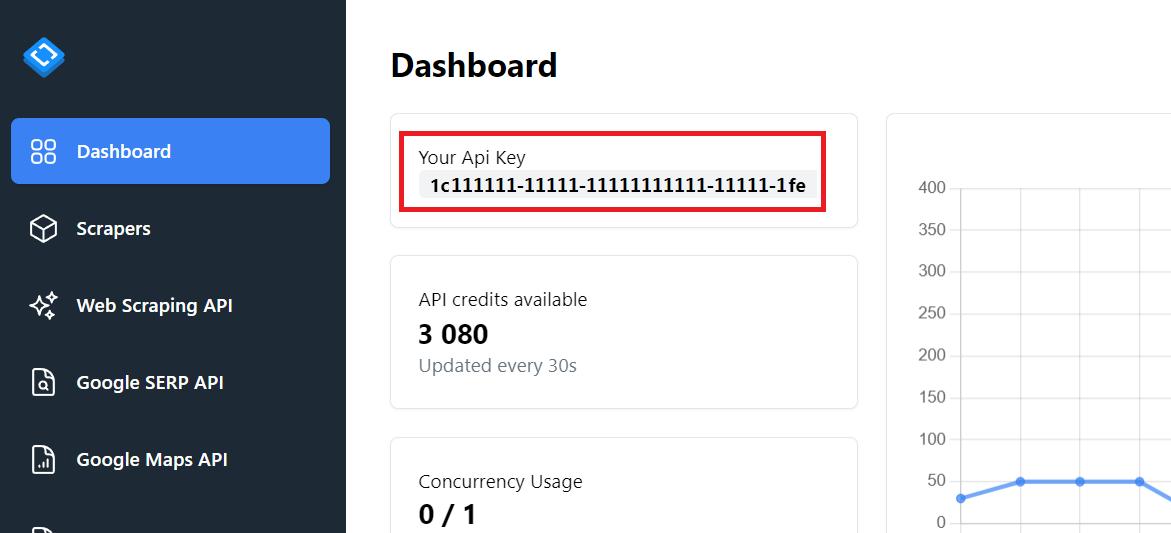
Diesen API-Schlüssel benötigen wir im folgenden Beispiel.
Schritt 2: Gehen Sie zur Registerkarte Google SERP API
Um Bilder zu sammeln, klicken Sie in Ihrem Konto auf die Registerkarte „Google SERP“.
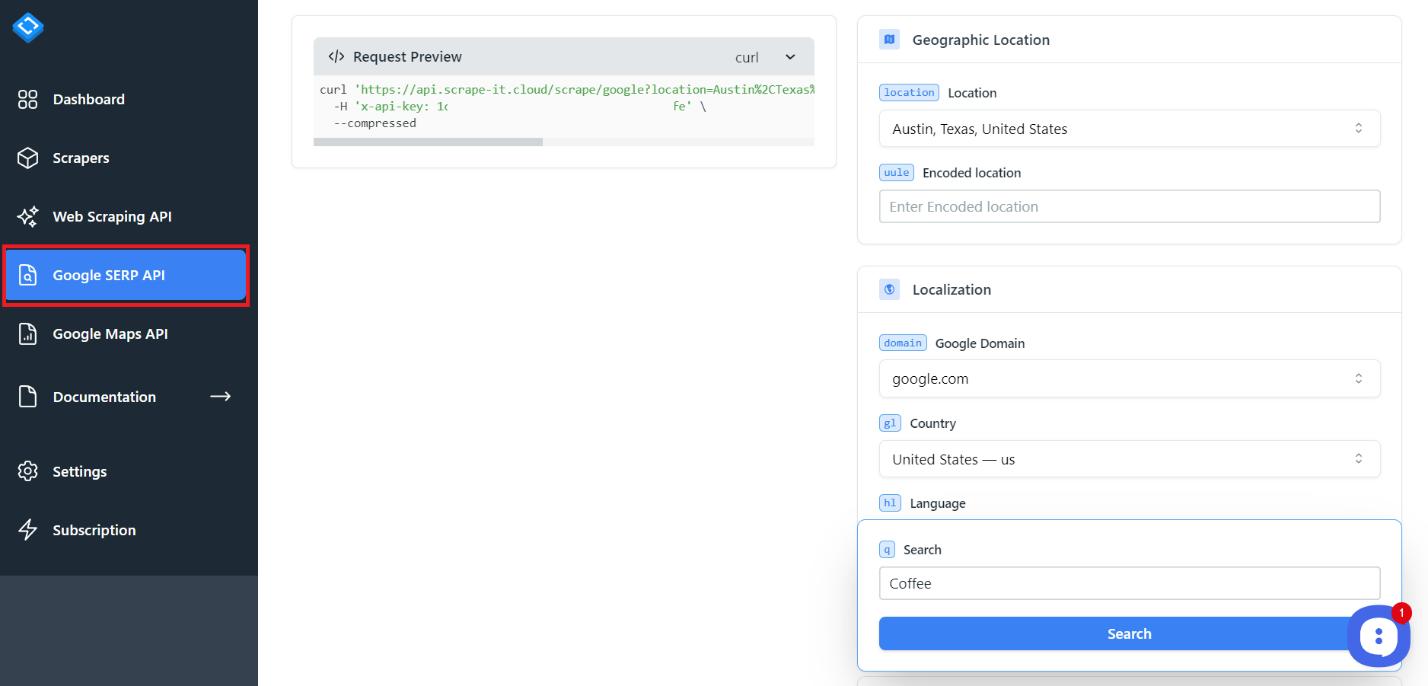
Mit diesem Tool können Sie Daten aus Suchergebnissen, Bildern, Nachrichten, Einheimischen und Einkäufen sammeln.
Schritt 3: Abfrageparameter für die Suche hinzufügen
Sehen Sie sich nun die primären Felder an, die Sie einrichten können, um Ihre Abfrage anzupassen. Und als Erstes muss der geografische Standort festgelegt werden.
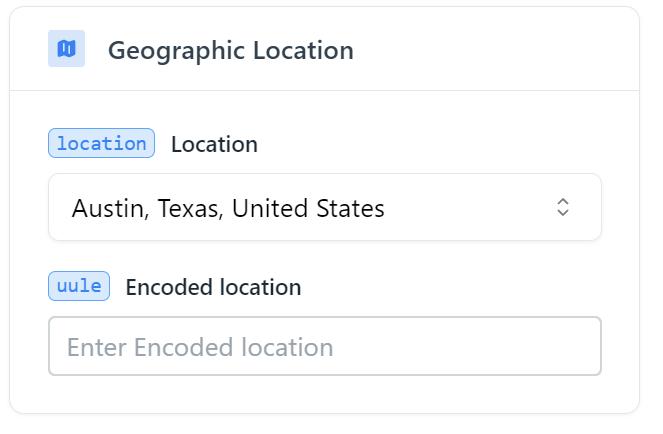
Sie müssen die Stadt oder das Land auswählen, von der/dem Sie Ergebnisse erhalten möchten. Sie können anstelle eines Ortsnamens auch einen Regionalcode angeben. Abhängig von Ihren Einstellungen werden die Ergebnisse unterschiedlich ausfallen.
Passen Sie dann die Lokalisierung an. Wenn Sie mit den Standardeinstellungen zufrieden sind, müssen Sie nichts ändern.
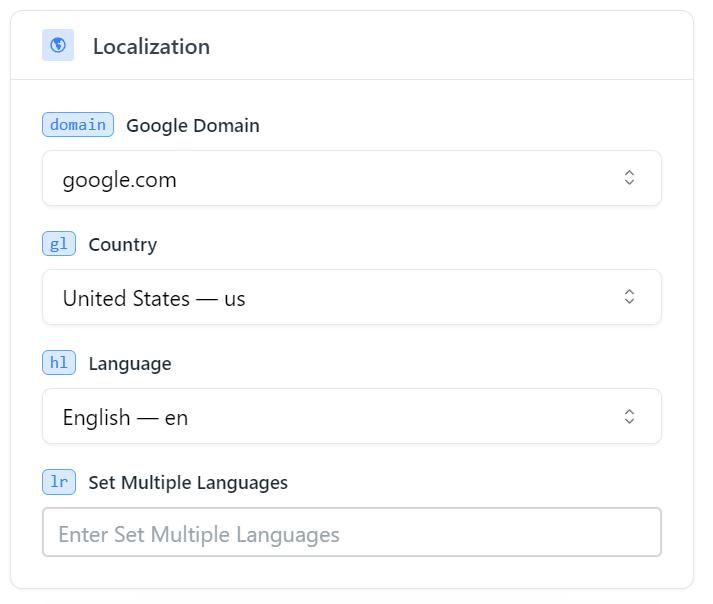
Die Hauptparameter sind hier Domain, Land und Sprache, sodass Sie nur diese angeben können. Dann kommt ein Block mit erweiterten Parametern. Sie können sich mit ihnen vertraut machen und sie bei Bedarf verwenden, wir möchten jedoch noch einen Schritt weiter gehen und den folgenden notwendigen Parameter berücksichtigen.
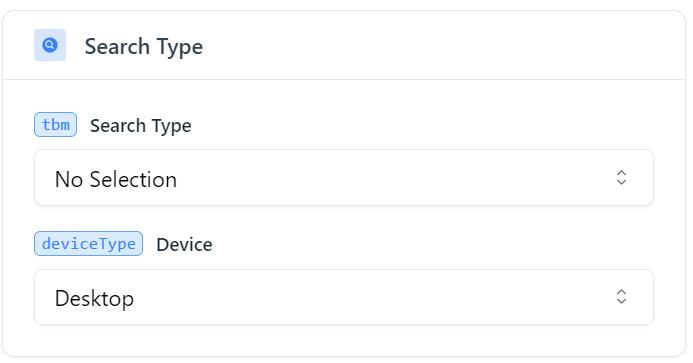
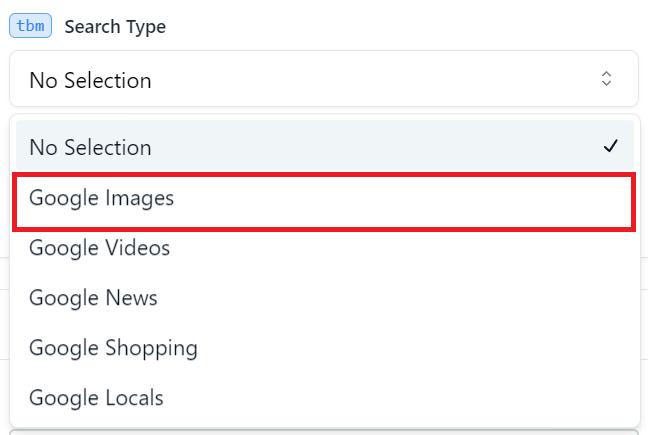
Um Google Bilder zu durchsuchen, sollten Sie den entsprechenden Suchtyp (tbm) als Google Bilder (isch) angeben.
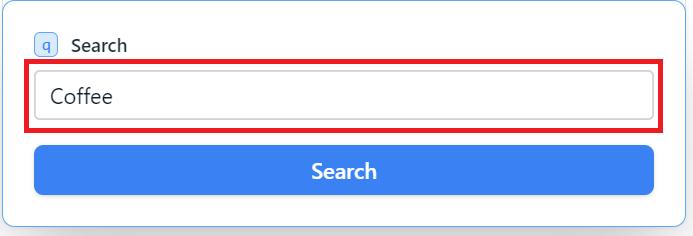
Und der letzte anzugebende Parameter ist das Schlüsselwort, für das Sie Bilder erhalten möchten.
Auch die anderen Parameter sind sehr hilfreich. Ihr Zweck ist jedoch intuitiv, sodass Sie sich bei Bedarf mit ihnen vertraut machen können. Mit ihnen können Sie beispielsweise die Anzahl der Bilder angeben, die Sie erhalten möchten.
Schritt 4: Senden Sie die API-Anfrage
Nachdem nun alle Parameter angegeben wurden, führen Sie die Abfrage aus.

Das Ausführen einer solchen Anfrage kostet fünf Credits. Wenn Sie sich anmelden, erhalten Sie 1000 Credits kostenlos, was 200 solcher Anfragen entspricht. Durch die Verwendung unserer API können Sie flexible Einstellungen verwenden, um Ihre Anfrage anzupassen. Darüber hinaus werden Proxys verwendet, Captchas werden vermieden und JS-Rendering wird verwendet, um das Risiko einer Blockierung zu verringern.
Schritt 5: Speichern Sie die URLs der Scraped-Bilder
Das Ergebnis ist eine JSON-Antwort mit allen verfügbaren Inhalten, einschließlich Titel und Bildlink. Sie können die gesamte JSON-Antwort oder nur den erforderlichen Teil kopieren.
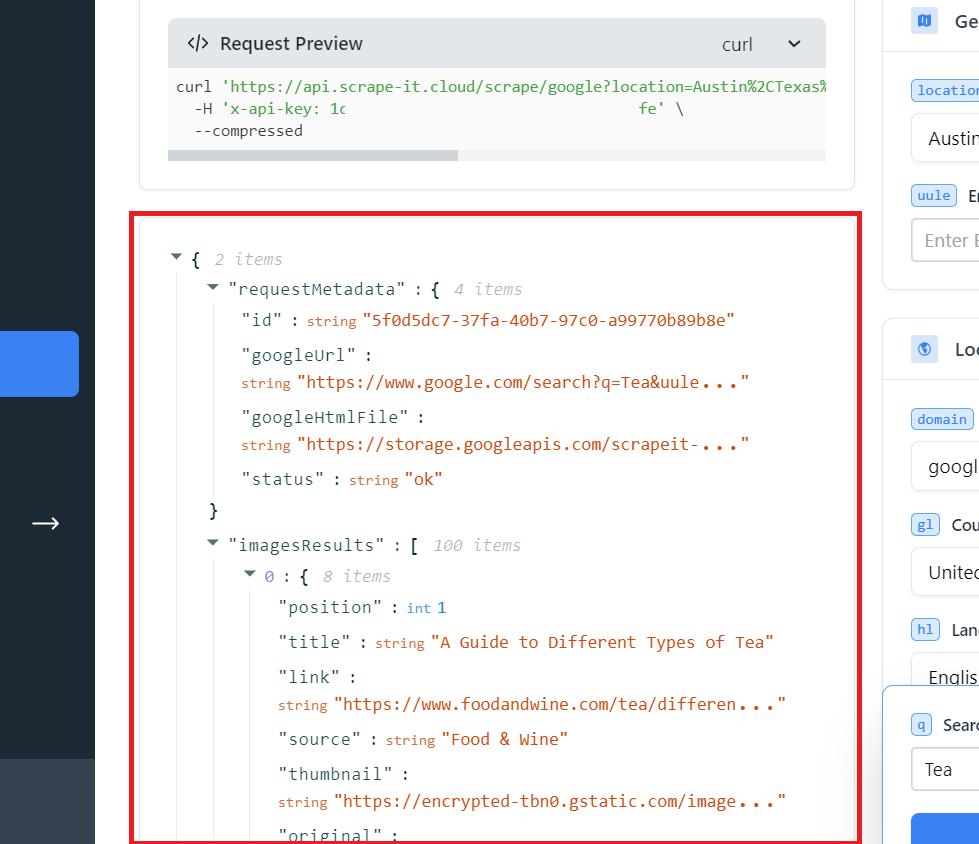
Um diese Daten als Excel-Datei zu speichern, können Sie den integrierten Datenimport nutzen oder JSON mit speziellen Diensten in XLSX konvertieren. Als Ergebnis erhalten Sie die Daten in folgender Form:
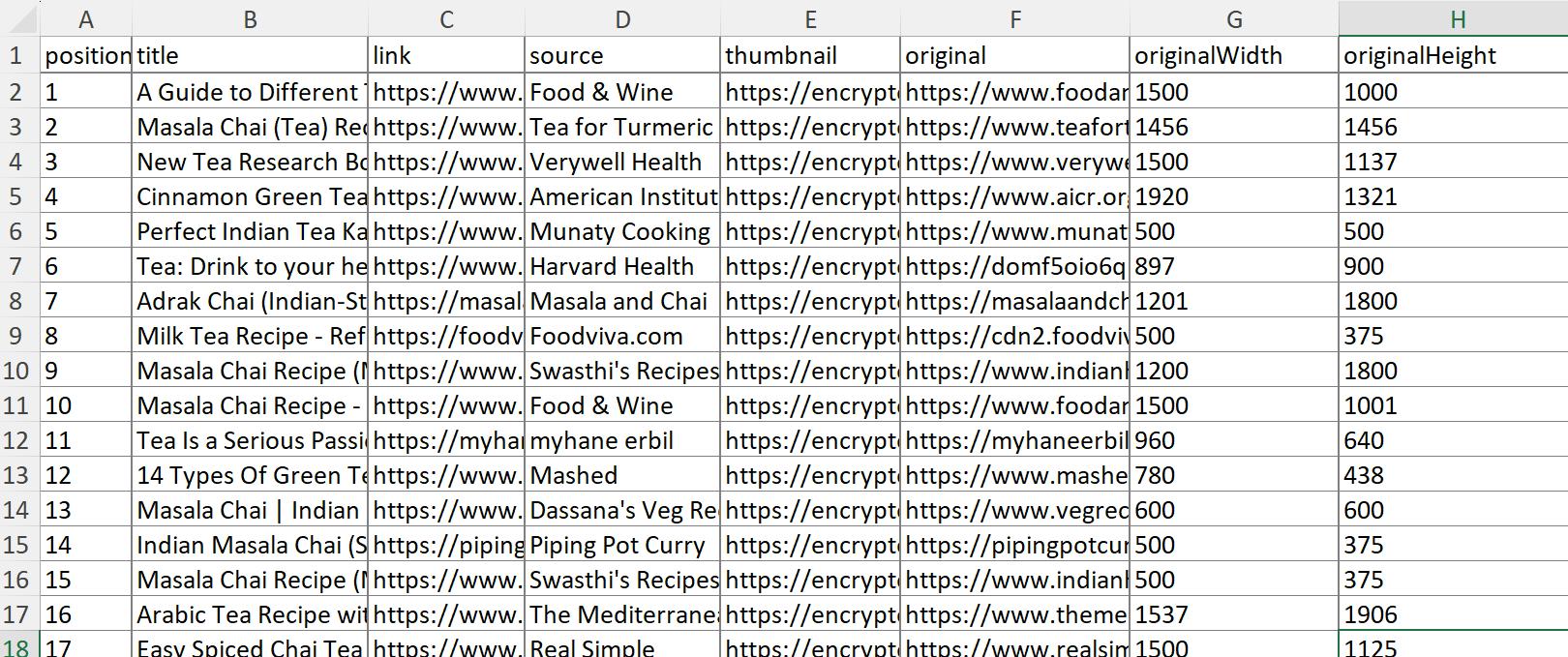
Wie Sie der Tabelle entnehmen können, erhalten Sie Bildposition, Titel, Quelle, Miniaturansicht, Link und sogar Abmessungen.
Einfacher Google Images Scraper auf Python mit API
Schauen wir uns an, wie man Bilder mit Python kratzt. Wir werden Python 3 verwenden. Wenn Sie nicht wissen, wie Sie die Umgebung vorbereiten und alles konfigurieren, was Sie benötigen, können Sie unseren Artikel lesen: „Web Scraping mit Python: Von den Grundlagen zur Praxis“.
Schritt 1: Erforderliche Bibliotheken installieren
Zuerst müssen wir die Bibliotheken installieren. Wir benötigen lediglich die Requests-Bibliothek, um Daten aus der Google-Bildersuche zu extrahieren. Um die Requests-Bibliothek zu installieren, können Sie sie in die Eingabeaufforderung eingeben:
pip install requestsKommen wir nun zur Erstellung des Skripts.
Schritt 2: Erforderliche Module importieren
Erstellen Sie eine neue Datei mit der Erweiterung *.py, in die wir das Skript schreiben. Importieren Sie die darin enthaltene Anforderungsbibliothek:
import requestsWir benötigen die Requests-Bibliothek, um eine Anfrage an die Scrape-It.Cloud-API auszuführen und eine Antwort von der API zu erhalten.
Schritt 3: API-Schlüssel und Parameter einrichten
Passen wir die Parameter an, die wir verwenden werden. Wenn es möglich ist, Daten in Variablen einzufügen, ist es besser, dies zu tun, wenn wir sie an mehreren Stellen verwenden. Beginnen wir also mit der Erstellung von Variablen, in die wir den API-Endpunkt und das Schlüsselwort einfügen.
keyword = 'Coffee'
api_url="https://api.scrape-it.cloud/scrape/google"Jetzt erstellen wir einen Anforderungsheader und geben den API-Schlüssel ein, den wir im letzten Beispiel erhalten haben.
headers = {'x-api-key': 'YOUR-API-KEY'}Der letzte Schritt besteht darin, den Hauptteil der Anfrage zu erstellen und die erforderlichen Parameter einzugeben. Im Parameter „q“ fügen wir das zuvor gespeicherte Schlüsselwort in die Variable ein. Geben Sie als Nächstes die Google-Domain an, in der die Suche durchgeführt werden soll. Und der letzte Parameter, „tbm“, sollte den Wert „isch“ haben, um nach Bildern zu suchen.
params = {
'q': keyword,
'domain': 'google.com',
'tbm': 'isch'
}Wie wir im letzten Beispiel gesagt haben, sind die Parameter viel wichtiger. Sie finden sie alle in unserer Dokumentation.
Schritt 4: API-Anfrage erstellen und senden
Jetzt müssen wir nur noch alle oben genannten Daten in einer Abfrage zusammenfassen und ausführen. Verwenden Sie den Block try..exclusive, wenn die Abfrage mit einem Fehler ausgeführt wird.
try:
response = requests.get(api_url, params=params, headers=headers)
# Here will be the future code
except Exception as e:
print("Failed to make the API request:", e)Dieser Ansatz ermöglicht es Ihnen, die Codeausführung trotz eines Fehlers fortzusetzen. Andernfalls wird die Programmausführung abgebrochen.
Schritt 5: API-Antwort analysieren und verarbeiten
Es ist auch einfach, eine Antwort zu erhalten und zu verarbeiten. Stellen Sie dazu sicher, dass die Anfrage eine positive Antwort zurückgegeben hat. Und fügen Sie dann die Daten im JSON-Format in eine Variable ein.
if response.status_code == 200:
# Parse the JSON response
data = response.json()Sie können Ihre Aktionen zuweisen, die ausgeführt werden, wenn die Anfrage nicht erfolgreich ist, z. B. die Ausgabe des Antwortcodes. Oder Sie können nichts hinzufügen, dann wird der Code nur im Falle einer positiven Antwort ausgeführt.
Schritt 6: Bild-URLs und Daten extrahieren
Stellen Sie nun sicher, dass das Skript ordnungsgemäß funktioniert. Holen Sie sich eine Liste mit Bildnamen und Links dazu und zeigen Sie sie dann an.
images_results = data('imagesResults')
for image in images_results:
print(image('title'),str(": "), image('original'))Da die Antwort im JSON-Format zurückgegeben wird, ist die Arbeit damit relativ einfach. Führen Sie das Skript aus und stellen Sie sicher, dass alles korrekt ist.
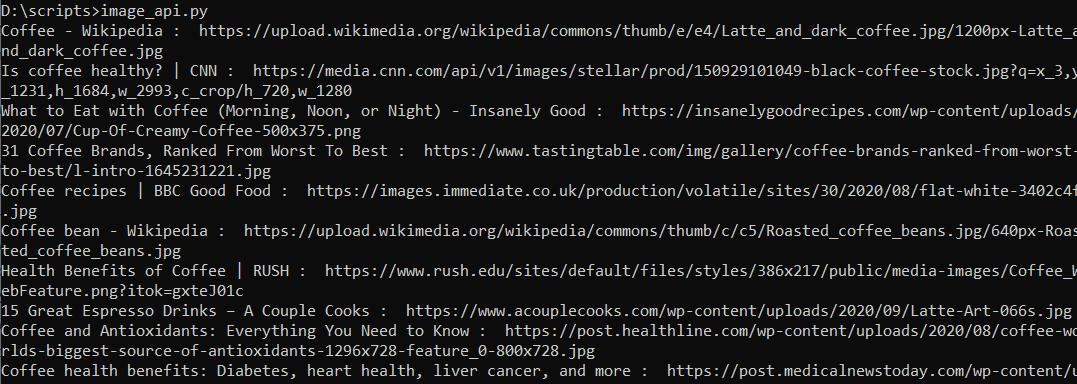
Wir verfügen über alle Daten, die wir zum Sammeln der Bilder benötigen. Fahren wir mit dem nächsten Schritt fort und speichern die gewonnenen Bilder.
Schritt 7: Bilder herunterladen
Es gibt viele Möglichkeiten, ein Bild zu speichern, aber wir werden nicht näher darauf eingehen. Lassen Sie uns die bereits verbundene Requests-Bibliothek verwenden, um die Daten zu speichern. Lassen Sie uns zunächst einen Algorithmus für das erstellen, was wir tun müssen:
- Erstellen Sie einen Ordner, in dem die Bilder gespeichert werden. Wir können dies nicht tun, aber dann befinden sich alle Bilder in einem freigegebenen Ordner, was unpraktisch ist. Wir erstellen also einen Ordner, der mit dem Schlüsselwort identisch ist.
- Holen Sie sich die Erweiterung des Bildes. Leider verlangt die Requests-Bibliothek, dass wir das zu speichernde Dateiformat angeben. Holen wir es uns aus dem Feld „Original“.
- Legen Sie den Dateinamen fest. Dazu verwenden wir den Titel und die Dateierweiterung.
- Speichern Sie alle Dateien einzeln.
Um diese Aufgaben zu erfüllen, benötigen wir zwei zusätzliche Bibliotheken: re (um reguläre Ausdrücke zu verwenden) und os (um Systemoperationen wie das Erstellen von Ordnern abzuwickeln). Sie sind vorinstalliert, sodass wir sie sofort in das Skript einbinden können.
import os
import reFolgen wir dem Algorithmus und erstellen wir einen Ordner. Um Fehler zu vermeiden, entfernen Sie mögliche Leerzeichen und andere Zeichen:
folder_name = re.sub(r'(^\w\-)+', '_', keyword)
os.makedirs(folder_name, exist_ok=True)Rufen Sie die Erweiterungsdaten ab und entfernen Sie unnötige Zeichen aus dem Titel in jedem Bild:
images_results = data('imagesResults')
for image in images_results:
image_title = re.sub(r'(^\w\-)+', '_', image('title'))
image_url = image('original')
image_extension = image_url.split('.')(-1)Legen Sie den Dateinamen und den Pfad fest:
image_file_name = f"{image_title}.{image_extension}"
image_path = os.path.join(folder_name, image_file_name)Jetzt laden wir das Bild und speichern es als Datei. Wir zeigen auch eine Meldung darüber an, ob es erfolgreich war:
with open(image_path, "wb") as file:
image_response = requests.get(image_url)
if image_response.status_code == 200:
file.write(image_response.content)
print(f"Image '{image_title}' downloaded successfully.")
else:
print(f"Failed to download the image '{image_title}'. Status code:", image_response.status_code)Führen Sie das Skript aus und prüfen Sie, ob alles ordnungsgemäß funktioniert:
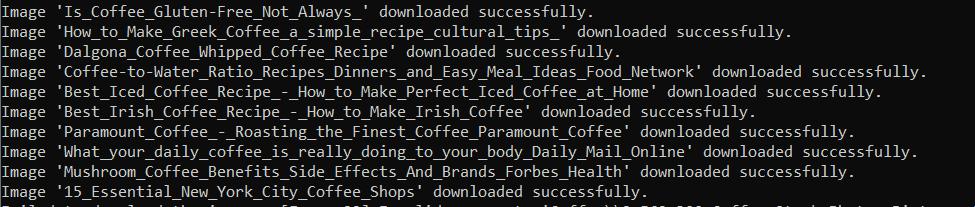
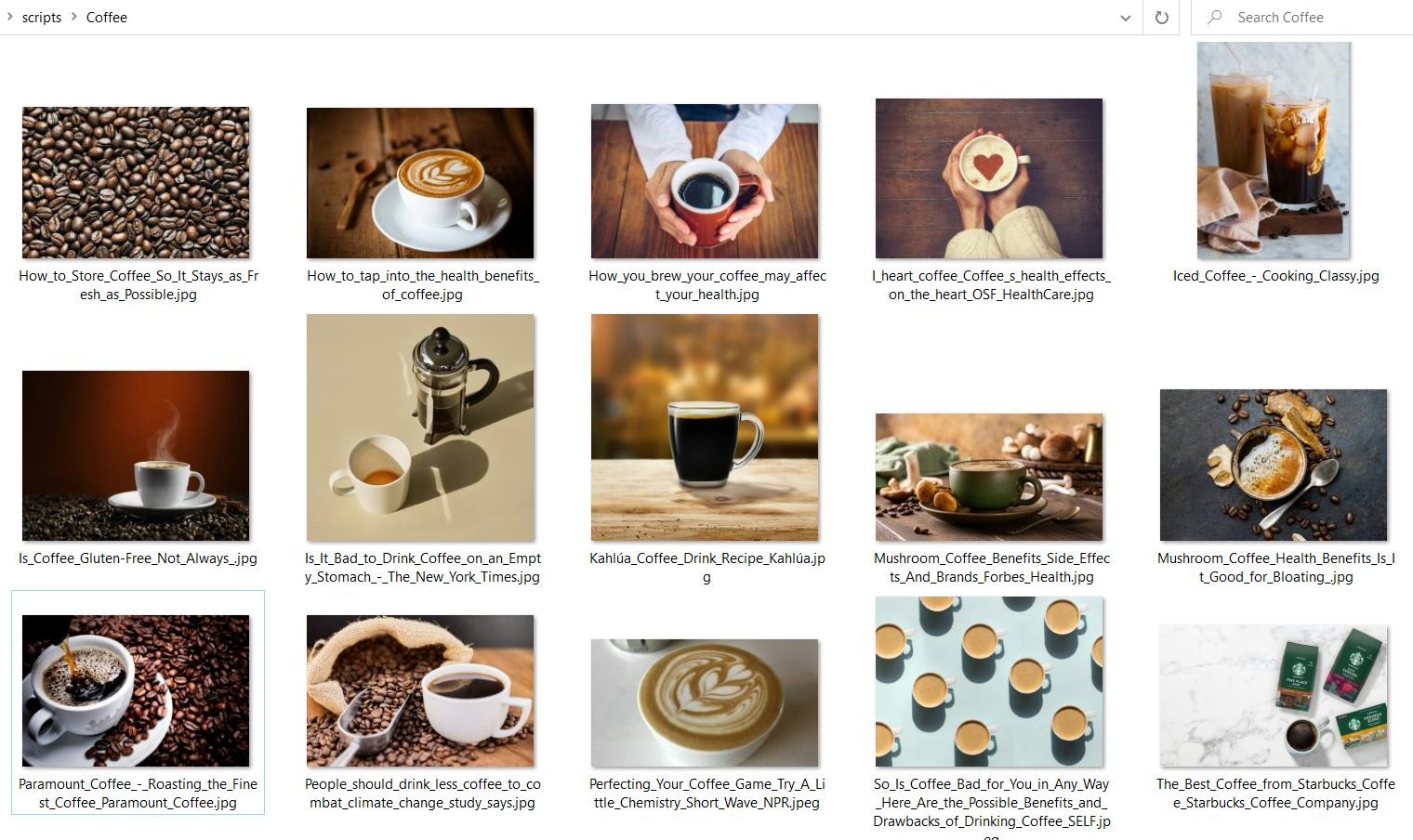
Als Ergebnis der Ausführung erhielten wir einen Coffee-Ordner mit allen resultierenden Bildern:
Vollständiger Code:
import requests
import os
import re
keyword = 'Coffee'
api_url="https://api.scrape-it.cloud/scrape/google"
headers = {'x-api-key': 'YOUR-API-KEY'}
params = {
'q': keyword,
'domain': 'google.com',
'tbm': 'isch'
}
try:
response = requests.get(api_url, params=params, headers=headers)
if response.status_code == 200:
# Parse the JSON response
data = response.json()
# Create a folder with the keyword name
folder_name = re.sub(r'(^\w\-)+', '_', keyword)
os.makedirs(folder_name, exist_ok=True)
# Save the images to the folder
images_results = data('imagesResults')
for image in images_results:
print(image('title'),str(": "), image('original'))
try:
image_title = re.sub(r'(^\w\-)+', '_', image('title'))
image_url = image('original')
image_extension = image_url.split('.')(-1)
image_file_name = f"{image_title}.{image_extension}"
image_path = os.path.join(folder_name, image_file_name)
with open(image_path, "wb") as file:
image_response = requests.get(image_url)
if image_response.status_code == 200:
file.write(image_response.content)
print(f"Image '{image_title}' downloaded successfully.")
else:
print(f"Failed to download the image '{image_title}'. Status code:", image_response.status_code)
except Exception as e:
print("Failed to download the image: ", e)
else:
print("Failed to get the API response. Status code:", response.status_code)
except Exception as e:
print("Failed to make the API request:", e)Mithilfe der API können Sie schnell und einfach große Bildbeispiele abrufen und sich um die Aufgaben der Captcha-Vermeidung, Proxy-Nutzung und Blockierungsvermeidung kümmern.
So scrapen Sie Google-Bilder auf Python mit BeautifulSoup
Sehen wir uns nun an, wie man Bilder ohne Verwendung der API scrapt. Wir können hierfür jede Scraping-Bibliothek verwenden. Schauen wir uns also die einfachste Option an: Verwenden Sie die bereits bekannte Requests-Bibliothek und die BeautifulSoup-Bibliothek zum Parsen von Seitendaten.
Mit dieser Option können wir keinen Seitenwechsel implementieren oder das Benutzerverhalten simulieren, aber die BeautifulSoup-Bibliothek eignet sich hervorragend für Anfänger und ist leicht zu erlernen. Wenn Sie einen Browser emulieren möchten, schauen Sie sich die Selenium-Bibliothek an. Es verwendet einen Webtreiber, zum Beispiel Chromedriver, und ermöglicht die Steuerung eines Headless-Browsers.
Schritt 1: Recherchieren Sie die Google-Bilderseite
Bevor wir mit der Erstellung des Skripts fortfahren, müssen wir die Seite untersuchen. In den vorherigen Beispielen war dies nicht erforderlich, da wir die API verwendet haben und ein fertiges und gut strukturiertes Ergebnis erhalten haben.
Gehen Sie zu Google Bilder und suchen Sie nach Bildern für die Suchanfrage „Kaffee“. Achten Sie auf die Linkstruktur. Es ist hilfreich, Daten nicht für ein einzelnes Schlüsselwort, sondern für die gesamte Liste zu erhalten.
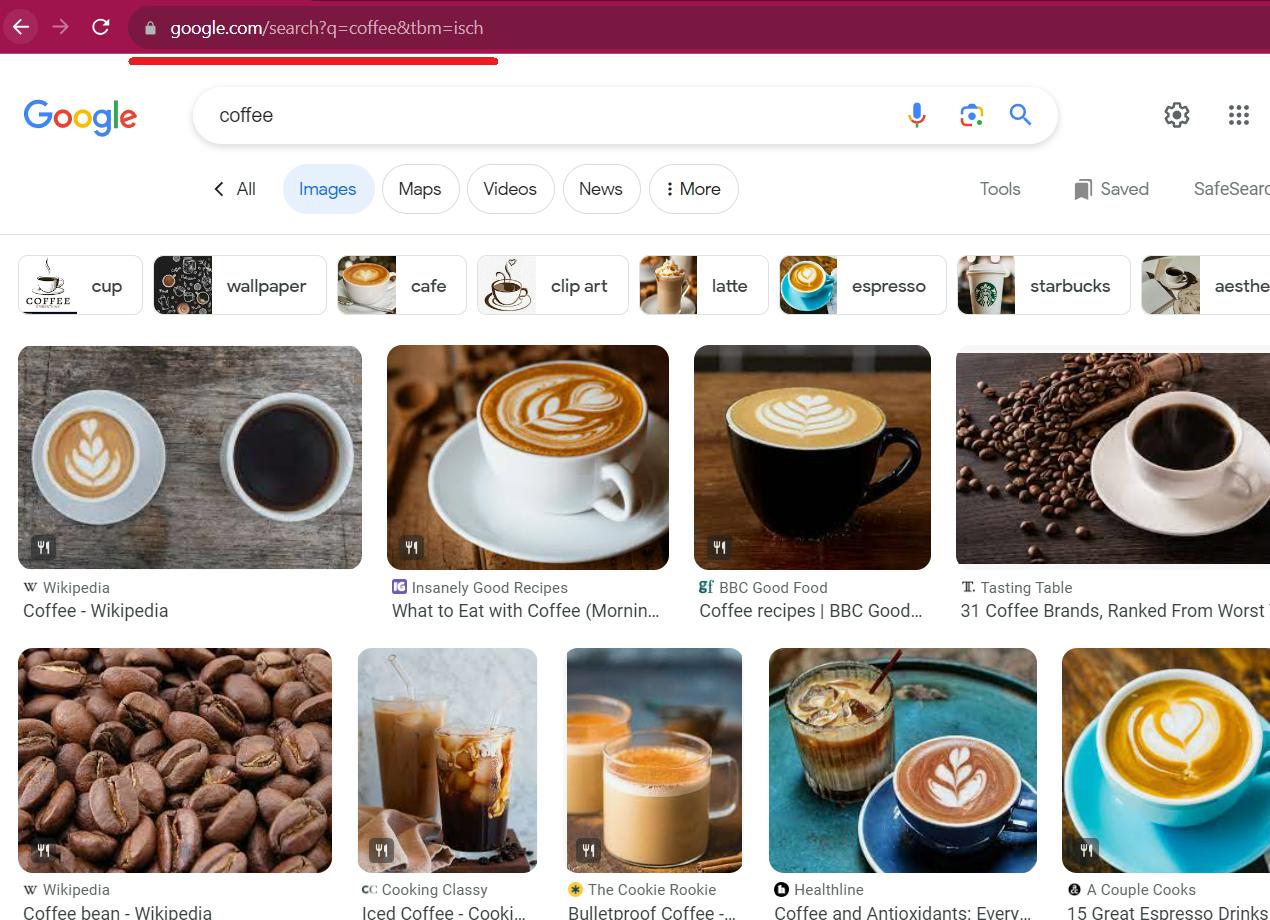
Wir können Variablen verwenden, um die notwendige Suchabfrage zu erstellen:
https://www.google.com/search?q={KEYWORD}&tbm=ischGehen Sie zu DevTools (F12 oder klicken Sie mit der rechten Maustaste auf die Seite und gehen Sie zu „Inspizieren“) und suchen Sie den Code, der zum Bild passt. Verwenden Sie das Tool, um auf der Seite nach einem Element zu suchen.
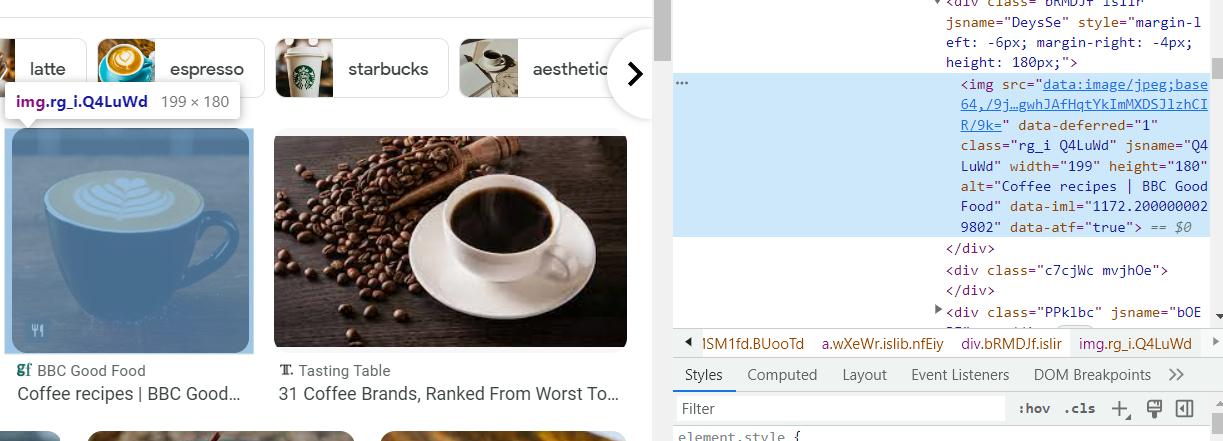
Hier können wir uns den Code jedes Elements ansehen und die benötigten Daten finden. Wenn wir die im img-Tag gespeicherten Daten direkt verwenden, erhalten wir Bildvorschauen. Um das Originalbild zu erhalten, extrahieren Sie den Javascript-Code, führen ihn aus und analysieren das Ergebnis. Da es sich um ein einfaches Beispiel handelt, werden wir Bildvorschauen abrufen.
Schritt 2: Erforderliche Bibliotheken installieren
Wie bereits erwähnt, benötigen wir die BeautifulSoup-Bibliothek. Sie können es mit diesem Befehl installieren:
pip install requests bs4Fahren wir mit der Erstellung des Skripts fort.
Schritt 3: Navigieren Sie zu Google Bilder
Schließen Sie alle erforderlichen Bibliotheken an und legen Sie die Variablen fest. Hier verwenden wir User-Agent in den Headern, um das Risiko einer Blockierung zu verringern. Sie können zu Ihrem Browser gehen und Ihren eigenen finden oder unseren verwenden.
import requests, re, os
from bs4 import BeautifulSoup
keyword = "coffee"
url = f"https://www.google.com/search?q={keyword}&tbm=isch"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}Dann erstellen wir einen try…catch-Block und führen darin die Abfrage aus:
try:
response = requests.get(url, headers=headers)
#Here will be code
except Exception as e:
print("Failed to make the request:", e)Stellen Sie nun sicher, dass die Anfrage erfolgreich ist, und erstellen Sie den erforderlichen Ordner. Wir übernehmen diesen Block aus dem vorherigen Beispiel und fügen ihn daher nicht noch einmal ein.
Schritt 4: HTML-Antwort mit BeautifulSoup analysieren
Um bestimmte Elemente von der HTML-Seite abzurufen, verwenden wir CSS-Selektoren und die schöne Suppenbibliothek:
images = soup.find_all('img')
img_src_list = (img('src') for img in images if 'src' in img.attrs)Wir haben eine Liste mit Links zu Bildvorschauen und können mit dem nächsten Schritt fortfahren.
Schritt 5: Bilder herunterladen
Lassen Sie uns eine Zählervariable festlegen, um die gespeicherten Bilder zu nummerieren. Gehen Sie dann die gesamte Liste der Bilder der Reihe nach durch und speichern Sie sie. Der Speichervorgang ist identisch mit dem vorherigen Beispiel.
сount = 0
for img in img_src_list:
count=count+1
image_path = os.path.join(folder_name, f"{str(count)}_{folder_name}.jpg")Als Ergebnis der Ausführung des Skripts haben wir einen Ordner mit Vorschaubildern erhalten.
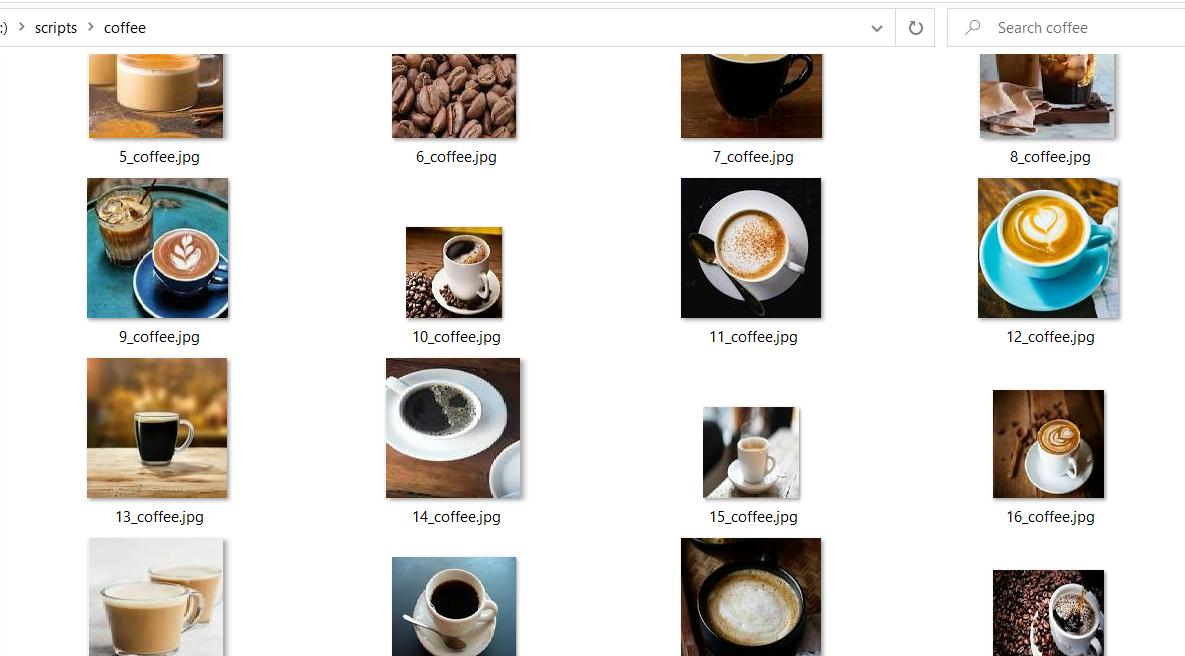
Hier ist der vollständige Code, falls Sie Probleme haben:
import requests, re, os
from bs4 import BeautifulSoup
keyword = "coffee"
url = f"https://www.google.com/search?q={keyword}&tbm=isch"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
count = 0
folder_name = re.sub(r'(^\w\-)+', '_', keyword)
os.makedirs(folder_name, exist_ok=True)
soup = BeautifulSoup(response.content, 'html.parser')
images = soup.find_all('img')
img_src_list = (img('src') for img in images if 'src' in img.attrs)
for img in img_src_list:
count=count+1
image_path = os.path.join(folder_name, f"{str(count)}_{folder_name}.jpg")
with open(image_path, "wb") as file:
try:
image_response = requests.get(img)
if image_response.status_code == 200:
file.write(image_response.content)
print(f"Image '{img}' downloaded successfully.")
else:
print(f"Failed to download the image '{img}'. Status code:", image_response.status_code)
except Exception as e:
print("Oops!")
else:
print("Failed to fetch the webpage. Status code:", response.status_code)
except Exception as e:
print("Failed to make the request:", e)Nachdem wir das Skript ausgeführt hatten, erhielten wir nur 20 Bilder. Leider können wir mit dieser Bibliothek nicht mehr Bilder abrufen. Um mehr als 20 Bilder zu erhalten, verwenden Sie die Selenium-Bibliothek. Mit seiner Hilfe können Sie das Scrollen anpassen, sodass Sie nicht auf die Anzahl der herunterzuladenden Bilder beschränkt sind.
Fazit und Erkenntnisse
Zum Scraping von Google-Bildern können Sie entweder eine API oder Scraping-Bibliotheken verwenden. Ihre Wahl sollte auf Ihren Fähigkeiten, Zielen und Aufgaben basieren. Die Verwendung einer API zum Scraping ist viel einfacher. Außerdem müssen Sie sich keine Gedanken über Blöcke, CAPTCHA oder die Verwendung von Proxys machen. Wenn Sie hingegen gut im Programmieren sind, können Sie ein Tool erstellen, das Ihre Aufgaben vollständig erfüllt.
Mithilfe dieser Schritt-für-Schritt-Anleitung können Sie die Grundlagen des Scrapings von Google-Bildern ausprobieren, ein Tool auswählen und Ihre ersten Schritte beim Sammeln von Bildern unternehmen. Wir haben einfache Beispiele verwendet, damit Sie die Grundlagen verstehen und lernen können.
