
Das Scraping von Zillow mit Python kann aus verschiedenen Gründen nützlich sein. Es kann Immobilienmaklern und Investoren helfen, mit aktuellen Markttrends Schritt zu halten, potenzielle Immobilien schnell zu identifizieren, Daten aus Angeboten zu analysieren und über lokale Angebotsaktivitäten auf dem Laufenden zu bleiben. Darüber hinaus ist Scraping eine effiziente Möglichkeit, vergünstigte oder unterbewertete Immobilien zu finden, die für diejenigen, die für sich selbst oder ein Unternehmen danach suchen, große Chancen darstellen können.
Unser Artikel behandelt die Grundlagen dessen, was zum Scrapen von Daten von der Website erforderlich ist, einschließlich der Verwendung von Paketen wie BeautifulSoup und Selenium, um die benötigten Daten zu erhalten. Abschließend werden in dem Artikel einige Tipps erläutert, wie Sie Zillow effektiver entfernen können, indem Sie die Erkennung oder Blockierung aufgrund übermäßiger Anfragen vermeiden.
So kratzen Sie Zillow-Eigenschaftsdaten
Es gibt mehrere Möglichkeiten, Immobiliendaten von Zillow zu erhalten. Wir geben sowohl No-Code-Optionen als auch ein Beispiel für das Schreiben Ihres eigenen Scrapers. Erwähnenswert ist auch, dass Zillow über eine eigene API zur Datenextraktion verfügt.
Verwendung der Zillow-API
Zillow bietet derzeit 22 verschiedene Anwendungsprogrammierschnittstellen (APIs) an. Diese werden entwickelt, um eine Reihe von Daten zusammenzustellen: einschließlich Auflistungen und Bewertungen, Immobilien-, Miet- und Zwangsvollstreckungsschätzungen.
Der Zugriff auf einige über die API bereitgestellte Dienste ist je nach Nutzungsgrad kostenpflichtig. Darüber hinaus verlagerte Zillow seinen Datenbetrieb zu Bridge Interactive, einem Unternehmen, das sich auf MLS-Informationen und -Vermittlung konzentriert. Um Bridge nutzen zu können, müssen Benutzer die Zustimmung des Systems einholen, bevor sie dessen Endpunkte verwenden – auch Personen, die zuvor die API von Zillow verwendet haben.
Um mehr zu erfahren und die Zillow-API auszuprobieren, besuchen Sie die offizielle API-Website für Entwickler.
Verwendung eines Zillow-Scraper ohne Code
Am bequemsten ist es, einen vorgefertigten No-Code-Scraper zu verwenden, der speziell für Zillow geschrieben wurde.
Um es zu nutzen, melden Sie sich bei Scrape-It.Cloud an und gehen Sie zur No-Code-Scraper-Seite. Hier finden Sie in der Kategorie „Immobilien“ einen fertigen Zillow-Schaber.
Hier können Sie alle Aspekte Ihrer Immobiliensuche anpassen: Anzahl der Zeilen, Region und Typ (zu verkaufen, zur Miete, verkauft). Außerdem können Sie detaillierte Immobilienangebote erhalten, die den URL-Link zu jedem Angebot, ein Bild (falls verfügbar), ein Preisschild, eine Beschreibung des zuständigen Maklers oder Maklers, den Namen und die Kontaktinformationen des Maklers oder Maklers enthalten Agentur, mit der sie verbunden sind usw.
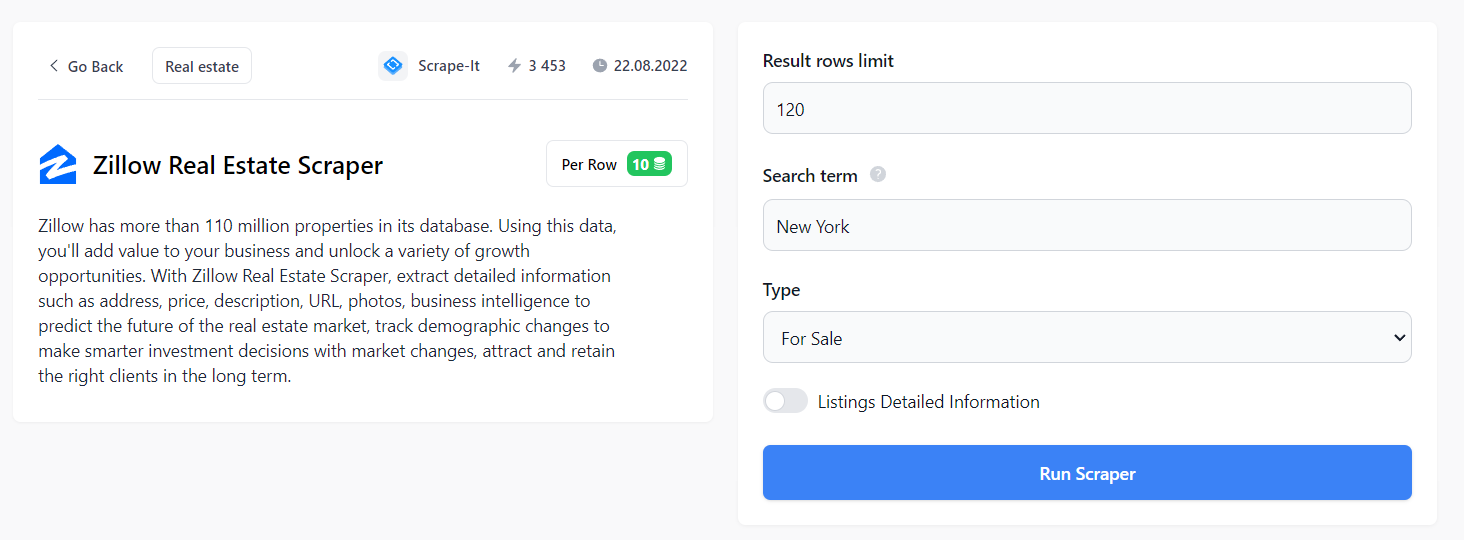
Die resultierenden Daten können in den Formaten CSV, JSON oder XSLX geladen werden.

Die resultierenden Daten lassen sich einfach verarbeiten und es sind keine Programmiersprachenkenntnisse erforderlich, um den Scraper zu verwenden. Darüber hinaus müssen Sie sich keine Gedanken über Möglichkeiten zur Vermeidung von Blockaden machen.
Erstellen Sie Ihr eigenes Zillow Web-Scraping-Tool
Das Scrapen von Daten aus Zillow kann mit einer Vielzahl von Programmiersprachen erfolgen. Beliebte Optionen zum Scrapen von Webseiten sind Python und NodeJS. Abhängig von der Komplexität der Aufgaben, die für den Zugriff auf die gewünschten Informationen erforderlich sind, kann jede Sprache Vor- oder Nachteile hinsichtlich Geschwindigkeit, Genauigkeit, Skalierbarkeit und Analysefunktionen haben.
Die Wahl der Programmiersprache beim Zillow Web Scraping hängt weitgehend von den spezifischen Bedürfnissen und Vorlieben des Benutzers ab. Beide Sprachen haben ihre eigenen Vor- und Nachteile, je nachdem, welche Aufgaben während der Extraktionszeit erfüllt werden müssen.
NodeJS bietet eine asynchrone Umgebung, in der Webseiten mithilfe von JavaScript-Code gescrapt werden können. NodeJS bietet aufgrund seiner ereignisgesteuerten Architektur eine hervorragende Skalierbarkeit und ermöglicht mehrere Anfragen gleichzeitig bei gleichzeitig niedriger CPU-Auslastung.
Andererseits ist Python eine leistungsstarke Programmiersprache, die seit Jahren für Web Scraping verwendet wird. Es ist leicht zu erlernen und bietet eine breite Palette an Bibliotheken und Frameworks, die zur Datenanalyse, Visualisierung und Analyse verwendet werden können. Aufgrund der Flexibilität von Python kann es zuverlässig strukturierte Informationen aus den meisten Webseiten extrahieren.
Scraping von Zillow mit Python
Schauen wir uns Schritt für Schritt an, wie man einen Zillow-Scraper in Python schreibt. Am Ende des Artikels geben wir außerdem zusätzliche Empfehlungen, um Blockierungen zu vermeiden und das Scraping sicherer zu machen.
Installieren der Bibliotheken
Wählen wir zunächst die Bibliothek aus. Es gibt zwei Möglichkeiten:
- Verwendung einer Abfragebibliothek (Requests, UrlLib oder andere) und einer Analysebibliothek (BeautifulSoup, Lxml).
- Verwendung einer vollständigen Bibliothek oder eines Scraping-Frameworks (Scrapy, Selenium, Pyppeteer).
Die erste Option ist für Anfänger einfacher, die zweite jedoch sicherer. Beginnen wir also damit, einen einfachen Scraper zu schreiben, der die Bibliotheken Requests und BeautifulSoup verwendet, um Daten abzurufen und zu analysieren. Anschließend geben wir ein Beispiel für einen Schaber, der Selen verwendet.
Installieren Sie zunächst den Python-Interpreter. Um zu überprüfen oder sicherzustellen, dass es bereits installiert ist, geben Sie es in die Befehlszeile ein:
python -VWenn bereits ein Interpreter installiert ist, wird dessen Version angezeigt. Um die Bibliotheken zu installieren, geben Sie in der Befehlszeile Folgendes ein:
pip install requests
pip install beautifulsoup4
pip install seleniumSelenium erfordert außerdem einen Webtreiber und einen Chrome-Browser derselben Version.
Zillow-Seitenanalyse
Lassen Sie uns die Seite analysieren, um Tags zu finden, die die erforderlichen Daten enthalten. Gehen wir zur Zillow-Website zum Kaufbereich. In diesem Tutorial sammeln wir Daten über Immobilien in Portland.
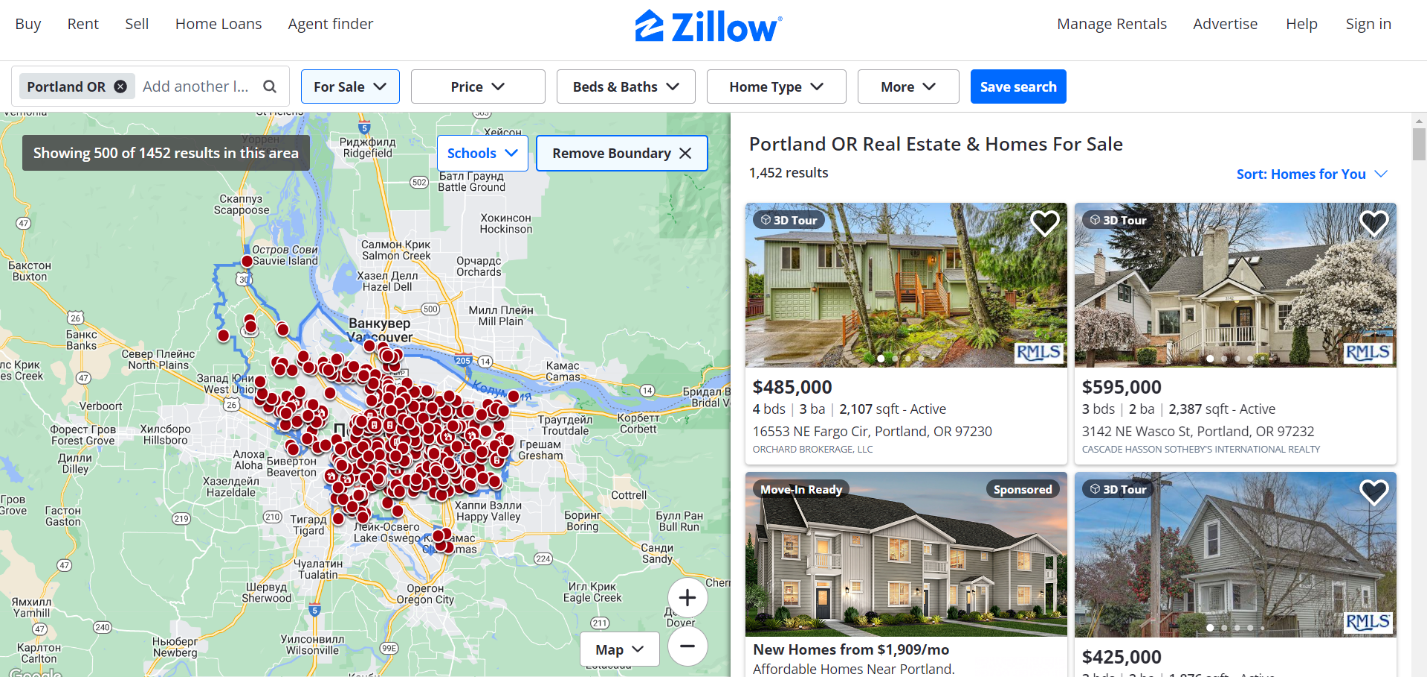
Sehen wir uns nun den HTML-Code der Seite an, um die Elemente zu bestimmen, die wir entfernen möchten.
Um den HTML-Seitencode zu öffnen, gehen Sie zu DevTools (drücken Sie F12 oder klicken Sie mit der rechten Maustaste auf eine leere Stelle auf der Seite und gehen Sie zu „Inspizieren“).
Definieren wir die zu kratzenden Elemente:
1. Adresse. Die Daten liegen im <address data-test="property-card-addr">...</address> Etikett.
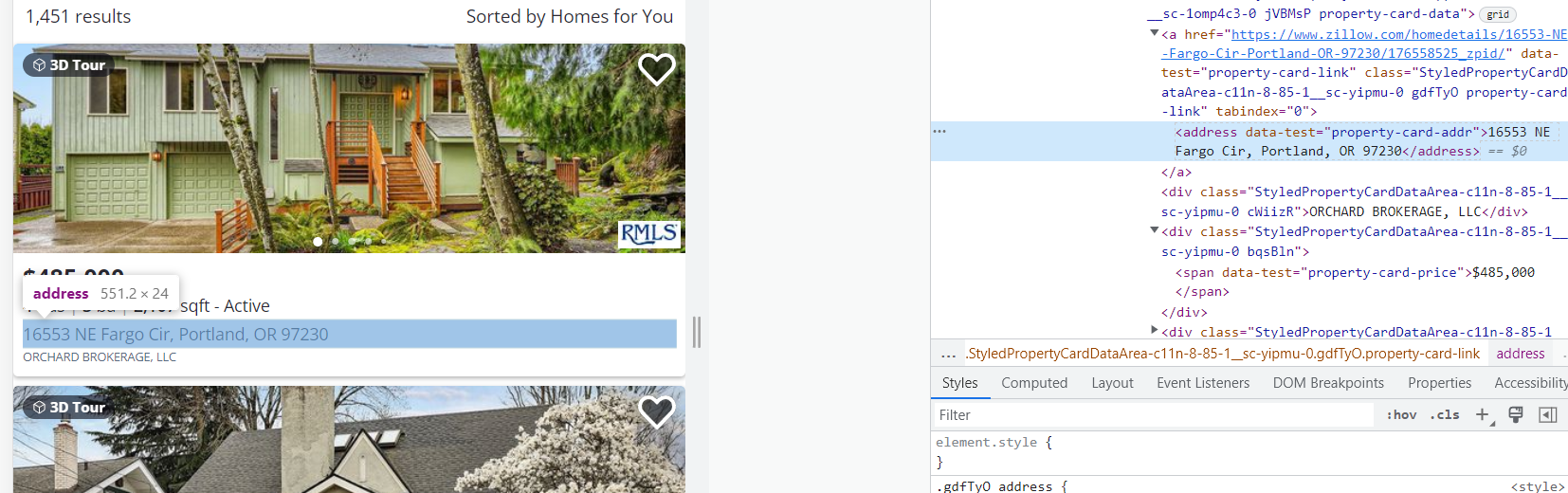
2. Preis. Daten sind da <span data-test="property-card-price">…</span> Etikett.

3. Verkäufer oder Makler. Die Daten liegen im <div class= "cWiizR">…</div> Etikett.

Bei allen anderen Karten sind die Tags ähnlich.
Beginnen wir nun mit dem Schreiben eines Scrapers, basierend auf den Informationen, die wir gesammelt haben.
Einen Web-Scraper erstellen
Erstellen Sie eine Datei mit der Erweiterung *.py und fügen Sie die erforderlichen Bibliotheken hinzu:
import requests
from bs4 import BeautifulSoupLassen Sie uns eine Anfrage stellen und den Code der gesamten Seite in einer Variablen speichern.
data = requests.get('https://www.zillow.com/portland-or/')Verarbeiten Sie die Daten mit der BS4-Bibliothek.
soup = BeautifulSoup(data.text, "lxml")Erstellen Sie Variablen Adresse, Preis, Und Verkäuferin dem wir die ausgeführten Daten anhand der zuvor gesammelten Informationen eingeben.
address = soup.find_all('address', {'data-test':'property-card-addr'})
price = soup.find_all('span', {'data-test':'property-card-price'})
seller = soup.find_all('div', {'class':'cWiizR'})Wenn wir versuchen, den Inhalt dieser Variablen anzuzeigen, erhalten wir leider eine Fehlermeldung, da Zillow das Captcha und nicht den Seitencode zurückgegeben hat.
Um dies zu vermeiden, fügen Sie Header zum Hauptteil der Anfrage hinzu:
header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'referer':'https://www.zillow.com/homes/Missoula,-MT_rb/'}
data = requests.get('https://www.zillow.com/portland-or/', headers=header)Versuchen wir nun, das Ergebnis auf dem Bildschirm anzuzeigen:
print(address)
print(price)
print(seller)Das Ergebnis eines solchen Skripts wäre das Folgende:
(<address data-test="property-card-addr">3142 NE Wasco St, Portland, OR 97232</address>, <address data-test="property-card-addr">4801 SW Caldew St, Portland, OR 97219</address>, <address data-test="property-card-addr">16553 NE Fargo Cir, Portland, OR 97230</address>, <address data-test="property-card-addr">3064 NW 132nd Ave, Portland, OR 97229</address>, <address data-test="property-card-addr">3739 SW Pomona St, Portland, OR 97219</address>, <address data-test="property-card-addr">1440 NW Jenne Ave, Portland, OR 97229</address>, <address data-test="property-card-addr">3435 SW 11th Ave, Portland, OR 97239</address>, <address data-test="property-card-addr">8023 N Princeton St, Portland, OR 97203</address>, <address data-test="property-card-addr">2456 NW Raleigh St, Portland, OR 97210</address>)
(<span data-test="property-card-price">$595,000</span>, <span data-test="property-card-price">$395,000</span>, <spanspan data-test="property-card-price">$485,000</span>, <span data-test="property-card-price">$1,185,000</span>, <span data-test="property-card-price">$349,900</span>, <span data-test="property-card-price">$599,900</span>, <span data-test="property-card-price">$575,000<span/span>, <span data-test="property-card-price">$425,000</span>, <span data-test="property-card-price">$1,195,000</span>)
(<div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">CASCADE HASSON SOTHEBY'S INTERNATIONAL REALTY</div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">PORTLAND CREATIVE REALTORS</div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">ORCHARD BROKERAGE, LLC</div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">ELEETE REAL ESTATE</div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">URBAN NEST REALTY</div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">KELLER WILLIAMS REALTY PROFESSIONALS<div/div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">KELLER WILLIAMS PDX CENTRAL<div/div>, <div class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">EXP REALTY, LLC</div>, <divdiv class="StyledPropertyCardDataArea-c11n-8-85-1__sc-yipmu-0 cWiizR">CASCADE HASSON SOTHEBY'S INTERNATIONAL REALTY</div>)Lassen Sie uns zusätzliche Variablen erstellen und nur den Immobilienlistentext aus den empfangenen Daten in sie einfügen:
adr=()
pr=()
sl=()
for result in address:
adr.append(result.text)
for result in price:
pr.append(result.text)
for results in seller:
sl.append(result.text)
print(adr)
print(pr)
print(sl)Das Ergebnis:
('16553 NE Fargo Cir, Portland, OR 97230', '3142 NE Wasco St, Portland, OR 97232', '8023 N Princeton St, Portland, OR 97203', '3064 NW 132nd Ave, Portland, OR 97229', '1440 NW Jenne Ave, Portland, OR 97229', '10223 NW Alder Grove Ln, Portland, OR 97229', '5302 SW 53rd Ct, Portland, OR 97221', '3435 SW 11th Ave, Portland, OR 97239', '3739 SW Pomona St, Portland, OR 97219')
('$485,000', '$595,000', '$425,000', '$1,185,000', '$599,900', '$425,000', '$499,000', '$575,000', '$349,900')
('ORCHARD BROKERAGE, LLC', 'CASCADE HASSON SOTHEBY'S INTERNATIONAL REALTY', 'EXP REALTY, LLC', 'ELEETE REAL ESTATE', 'KELLER WILLIAMS REALTY PROFESSIONALS', 'ELEETE REAL ESTATE', 'REDFIN', 'KELLER WILLIAMS PDX CENTRAL', 'URBAN NEST REALTY')Vollständiger Skriptcode:
import requests
from bs4 import BeautifulSoup
header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'referer':'https://www.zillow.com/homes/Missoula,-MT_rb/'}
data = requests.get('https://www.zillow.com/portland-or/', headers=header)
soup = BeautifulSoup(data.text, 'lxml')
address = soup.find_all('address', {'data-test':'property-card-addr'})
price = soup.find_all('span', {'data-test':'property-card-price'})
seller =soup.find_all('div', {'class':'cWiizR'})
adr=()
pr=()
sl=()
for result in address:
adr.append(result.text)
for result in price:
pr.append(result.text)
for results in seller:
sl.append(result.text)
print(adr)
print(pr)
print(sl)Jetzt liegen die Daten in einem praktischen Format vor und Sie können weiter damit arbeiten.
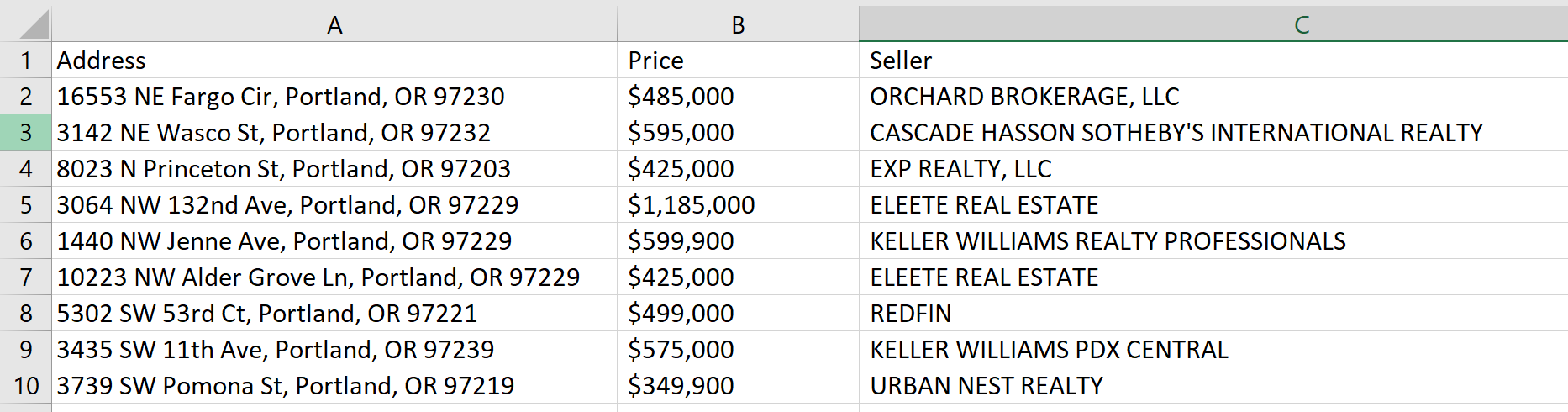
Daten speichern
Damit wir die Daten nicht selbst in die Datei kopieren müssen, speichern wir sie in einer CSV-Datei. Dazu erstellen wir eine Datei und geben darin die Namen der Spalten ein:
with open("zillow.csv", "w") as f:
f.write("Address; Price; Seller\n")Der Buchstabe „w“ gibt an, dass eine Datei mit dem Namen zillow.csv erstellt wird, wenn sie nicht existiert. Falls eine solche Datei vorhanden ist, wird sie gelöscht und neu erstellt. Sie können die Option “ verwenden.a„-Attribut, um zu vermeiden, dass der Inhalt jedes Mal überschrieben wird, wenn Sie das Skript ausführen.
Gehen Sie die Elemente durch und tragen Sie sie in die Tabelle ein:
for i in range(len(adr)):
with open("zillow.csv", "a") as f:
f.write(str(adr(i))+"; "+str(pr(i))+"; "+str(sl(i))+"\n")Als Ergebnis haben wir die folgende Tabelle erhalten:
Vollständiger Skriptcode:
import requests
from bs4 import BeautifulSoup
header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'referer':'https://www.zillow.com/homes/Missoula,-MT_rb/'}
data = requests.get('https://www.zillow.com/portland-or/', headers=header)
soup = BeautifulSoup(data.text, 'lxml')
address = soup.find_all('address', {'data-test':'property-card-addr'})
price = soup.find_all('span', {'data-test':'property-card-price'})
seller =soup.find_all('div', {'class':'cWiizR'})
adr=()
pr=()
sl=()
for result in address:
adr.append(result.text)
for result in price:
pr.append(result.text)
for results in seller:
sl.append(result.text)
with open("zillow.csv", "w") as f:
f.write("Address; Price; Seller\n")
for i in range(len(adr)):
with open("zillow.csv", "a") as f:
f.write(str(adr(i))+"; "+str(pr(i))+"; "+str(sl(i))+"\n")Daher haben wir einen einfachen Zillow-Scraper in Python erstellt.
So kratzen Sie Zillow, ohne blockiert zu werden
Zillow verbietet strengstens den Einsatz von Scrapern und Bots zur Datenerfassung auf seiner Website. Sie überwachen alle Versuche, mit diesen Methoden Daten zu sammeln, genau und gehen dagegen vor.
Werfen wir einen kurzen Blick darauf, wie wir den resultierenden Code ändern oder verbessern können, um das Risiko einer Blockierung zu verringern.
Verwendung von Proxys
Der einfachste Weg ist die Verwendung von Proxys. Wir haben bereits über Proxys geschrieben und wo Sie kostenlose Proxys erhalten können.
Lassen Sie uns eine Proxy-Datei erstellen und einige funktionierende Proxys darin einfügen. Verbinden Sie dann die Proxy-Datei mit dem Scraper:
with open('proxies.txt', 'r') as f:
proxies = f.read().splitlines()Um Proxys zufällig auszuwählen, verbinden wir die zufällig Bibliothek zum Projekt:
import randomSchreiben Sie nun einen zufälligen Wert aus der Proxy-Liste in die Proxy-Variable und fügen Sie einen Proxy zum Anfragetext hinzu:
proxy = random.choice(proxies)
data = requests.get('https://www.zillow.com/portland-or/', headers=header, proxies={"http": proxy})Dies verringert die Fehleranzahl und hilft, Blockaden zu vermeiden.
Verwendung des Headless-Browsers
Eine weitere Möglichkeit, das Blockieren zu vermeiden, ist die Verwendung eines Headless-Browsers. Die bequemste Bibliothek hierfür ist Selenium.
Erstellen Sie eine neue Datei mit der Erweiterung *.py, importieren Sie die Bibliothek und die erforderlichen Module sowie den Webtreiber:
from selenium import webdriver
from selenium.webdriver.common.by import By
DRIVER_PATH = 'C:\chromedriver.exe'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)Um das Beispiel vollständiger zu machen, verwenden wir XPath, um die erforderlichen Daten auszuführen:
address = driver.find_elements(By.XPATH,'//address')
price = driver.find_elements(By.XPATH,'//article/div/div/div(2)/span')
seller = driver.find_elements(By.XPATH,'//div(contains(@class, "cWiizR"))')Verwenden Sie nun einen Teil des Codes aus dem letzten Beispiel und fügen Sie Speicherdaten zu einer Datei hinzu:
adr=()
pr=()
sl=()
for result in address:
adr.append(result.text)
for result in price:
pr.append(result.text)
for results in seller:
sl.append(result.text)
with open("zillow.csv", "w") as f:
f.write("Address; Price; Seller\n")
for i in range(len(adr)):
with open("zillow.csv", "a") as f:
f.write(str(adr(i))+"; "+str(pr(i))+"; "+str(sl(i))+"\n")Schließen Sie abschließend den Webdriver:
driver.quit()Vollständiger Code:
from selenium import webdriver
from selenium.webdriver.common.by import By
DRIVER_PATH = 'C:\chromedriver.exe'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
driver.get('https://www.zillow.com/portland-or/')
address = driver.find_elements(By.XPATH,'//address')
price = driver.find_elements(By.XPATH,'//article/div/div/div(2)/span')
seller = driver.find_elements(By.XPATH,'//div(contains(@class, "cWiizR"))')
adr=()
pr=()
sl=()
for result in address:
adr.append(result.text)
for result in price:
pr.append(result.text)
for results in seller:
sl.append(result.text)
with open("zillow.csv", "w") as f:
f.write("Address; Price; Seller\n")
for i in range(len(adr)):
with open("zillow.csv", "a") as f:
f.write(str(adr(i))+"; "+str(pr(i))+"; "+str(sl(i))+"\n")
driver.quit()Nach dem Start öffnet sich Chromium mit der von uns angegebenen Seite. Wenn die Seite vollständig geladen ist, werden die erforderlichen Daten gesammelt und in einer Datei gespeichert. Anschließend wird der Webtreiber geschlossen.
Dateiinhalt:
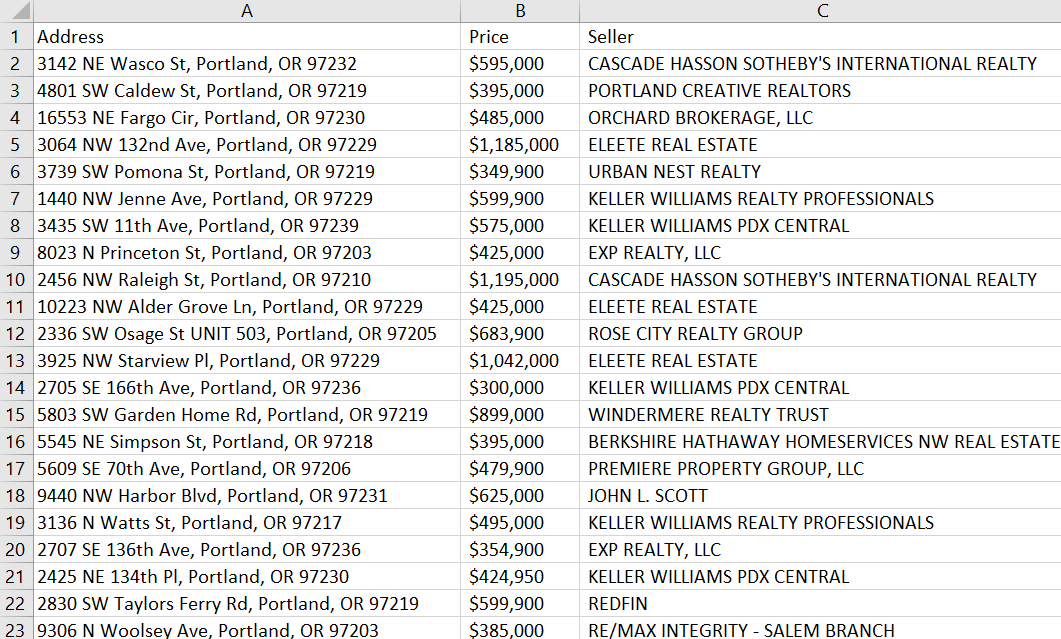
Damit haben wir ganz einfach die Sicherheit unseres Schabers erhöht.
Verwendung der Web-Scraping-API
Die Verwendung der Web-Scraping-API ist die beste Wahl, da sie die Verwendung eines Headless-Browsers, automatische Proxy-Rotation und andere Möglichkeiten zur Umgehung von Blockierungen kombiniert.
Für diese Aufgaben verwenden wir Scrape-It.Cloud. Melden Sie sich an und bestätigen Sie Ihre E-Mail-Adresse, um 1000 kostenlose Credits zu erhalten. Gehen Sie dann zur Web Scraping API-Seite und geben Sie den Link ein, von dem Sie Daten extrahieren möchten. Sie können eine Programmiersprache auswählen und die Anfrage anpassen.
Lassen Sie uns Extraktionsregeln verwenden, um nur die Adresse, den Preis und den Verkäufer zu erhalten:
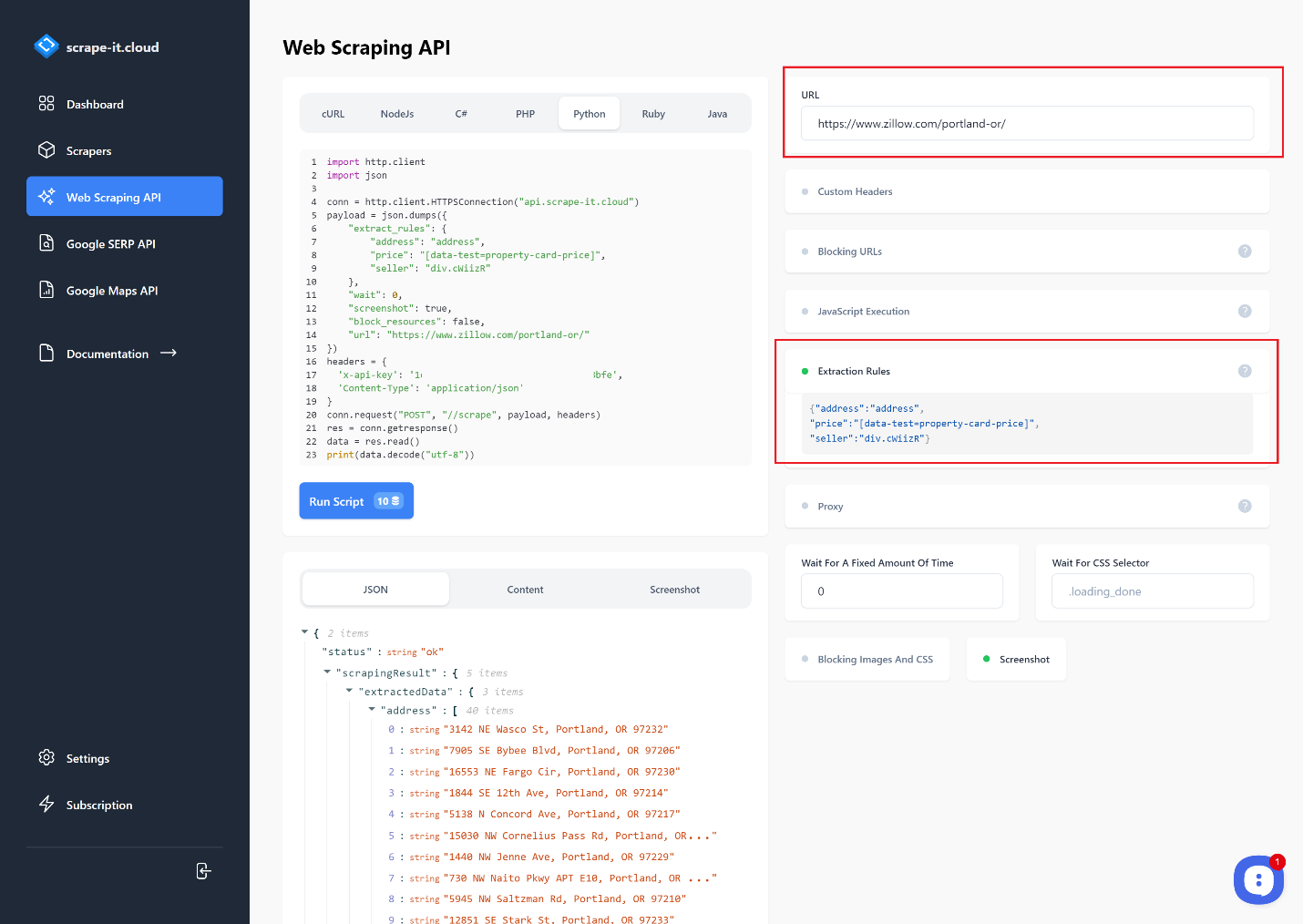
Je nach Verwendungszweck können die anfallenden Daten kopiert und weiterverarbeitet oder sofort genutzt werden. Der Einfachheit halber erstellen wir ein Skript und erstellen auf der Grundlage der resultierenden Anfrage einen Scraper, der eine Funktion zum Speichern von Daten in einer CSV-Datei enthält. Um das Beispiel vollständiger zu machen, verwenden wir die Anfragen Bibliothek und schreiben Sie die Anfrage neu:
import requests
import json
url = "https://api.scrape-it.cloud/scrape"
payload = json.dumps({
"extract_rules": {
"address": "address",
"price": "(data-test=property-card-price)",
"seller": "div.cWiizR"
},
"wait": 0,
"screenshot": True,
"block_resources": False,
"url": "https://www.zillow.com/portland-or/"
})
headers = {
'x-api-key': 'YOUR-API-KEY',
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)Lassen Sie uns nun die Antwort in die Form umwandeln, in der es bequemer ist, mit der Struktur zu arbeiten:
data = json.loads(response.text)Erstellen Sie Variablen Adresse, Preis, Und Verkäuferin dem wir die Daten aus der Abfrage einfügen:
address = ()
price = ()
seller = ()
for item in data("scrapingResult")("extractedData")("address"):
address.append(item)
for item in data("scrapingResult")("extractedData")("price"):
price.append(item)
for item in data("scrapingResult")("extractedData")("seller"):
seller.append(item)Jetzt speichern wir die Daten in einer Datei:
with open("result.csv", "w") as f:
f.write("Address; Price; Seller\n")
for i in range(len(address)):
with open("result.csv", "a") as f:
f.write(str(address(i))+"; "+str(price(i))+"; "+str(seller(i))+"\n")Als Ergebnis erhielten wir dieselbe *.csv-Datei wie zuvor, aber jetzt müssen wir keinen Headless-Browser, Proxy oder Verbindungsdienst verwenden, um das Captcha zu lösen. Alle diese Funktionen werden bereits auf der Scrape-It.Cloud-Seite ausgeführt.
Lesen Sie auch darüber cURL-Python
Fazit und Erkenntnisse
Das Scraping von Zillow mit Python bietet großes Potenzial, wertvolle Erkenntnisse über den Immobilienmarkt zu gewinnen. Es ist eine effiziente Möglichkeit, Daten zu Angeboten, Preisen, Stadtteilen und vielem mehr zu sammeln. Mit gut gestalteten Anfragen und Code, der die Python-Bibliotheken wie Beautiful Soup oder Selenium nutzt, kann jeder die Website von Zillow nutzen, um auf diese Daten zuzugreifen und seinen lokalen oder regionalen Markttrend zu analysieren.
Bedenken Sie jedoch, dass die Struktur oder die Namen von Klassen auf der Website geändert werden können. Bevor Sie unsere Beispiele verwenden, sollten Sie daher sicherstellen, dass die Daten noch aktuell sind.
Wenn Ihnen das Schreiben des Scrapers selbst immer noch recht schwer fällt, versuchen Sie es mit einem No-Code-Scraper. Unser No-Code-Scraper lässt sich ohne Programmiererfahrung oder -kenntnisse relativ schnell und einfach einrichten.
