
S.
for job in jobs:
job_title = job.find('h3', class_='base-search-card__title').text.strip()
job_company = job.find('h4', class_='base-search-card__subtitle').text.strip()
job_location = job.find('span', class_='job-search-card__location').text.strip()
job_link = job.find('a', class_='base-card__full-link')('href')
Notiz: Wenn Sie das Gefühl haben, dass wir zu schnell vorankommen, empfehlen wir Ihnen, unser Python-Web-Scraping-Tutorial für Anfänger zu lesen. Auf diesen Vorgang wird näher eingegangen.
9. LinkedIn-Jobs in eine CSV-Datei importieren
Außerhalb unserer Hauptfunktion öffnen wir eine neue Datei, erstellen einen neuen Writer und weisen ihn an, unsere Überschriftenzeile mithilfe der Methode .writerow() zu erstellen:
file = open('linkedin-jobs.csv', 'a')
writer = csv.writer(file)
writer.writerow(('Title', 'Company', 'Location', 'Apply'))
Wenn Sie eine Datei öffnen, zu der Sie ständig neue Zeilen hinzufügen möchten, müssen Sie sie in öffnen Anhängemodus, daher warum die a als zweites Argument in der open() Funktion.
Um eine neue Zeile mit den vom Parser extrahierten Daten zu erstellen, fügen Sie diesen Codeausschnitt am Ende der for-Schleife hinzu:
writer.writerow((
job_title.encode('utf-8'),
job_company.encode('utf-8'),
job_location.encode('utf-8'),
job_link.encode('utf-8')
))
Am Ende jeder Iteration durch die Jobliste fügt unser Scraper alle Daten in eine neue Zeile ein.
Notiz: Es ist wichtig sicherzustellen, dass die Reihenfolge, in der wir die neuen Daten hinzufügen, mit der Reihenfolge unserer Überschriften übereinstimmt.
Um diesen Schritt abzuschließen, fügen wir eine hinzu else Anweisung, um die Datei zu schließen, sobald die Schleife unterbrochen wird.
else:
file.close()
print('File closed')
10. Umgehen der Anti-Bot-Erkennung von LinkedIn mit ScraperAPI
Unser letzter Schritt ist optional, kann Ihnen aber auf lange Sicht Stunden an Arbeit ersparen. Schließlich geht es uns nicht darum, nur eine oder zwei Seiten abzukratzen.
Um Ihr Projekt zu skalieren, müssen Sie Folgendes tun:
- Behandeln Sie IP-Rotationen
- Verwalten Sie einen Pool von Proxys
- Behandeln Sie CAPTCHAs
- Senden Sie die richtigen Header
und mehr, um nicht gesperrt oder sogar lebenslang gesperrt zu werden.
ScraperAPI kann diese und weitere Herausforderungen mit nur wenigen Änderungen an der Basis-URL, die wir gerade verwenden, bewältigen.
Erstellen Sie zunächst ein neues kostenloses ScraperAPI-Konto, um Zugriff auf unseren API-Schlüssel zu erhalten.
Von dort aus müssen Sie nur noch diese Zeichenfolge am Anfang der URL hinzufügen:
http://api.scraperapi.com?api_key={YOUR_API_KEY}&url=
Daraus ergibt sich folgender Funktionsaufruf:
linkedin_scraper('http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Product%20Management&location=San%20Francisco%20Bay%20Area&geoId=90000084&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0&start=', 0)
Auf diese Weise wird die HTTP-Anfrage vom ScraperAPI-Server verarbeitet. Es rotiert IPs nach jeder Anfrage (oder nach Bedarf) und wählt die richtigen Header basierend auf jahrelanger statistischer Analyse und maschinellem Lernen aus.
Darüber hinaus verfügt ScraperAPI über Ultra-Premium-Proxys, die speziell für den Umgang mit wirklich schwierigen Websites wie LinkedIn ausgewählt wurden. Um sie zu verwenden, aktivieren Sie die ultra_premium=true Parameter in der Anfrage.
LinkedIn Web Scraper: Der vollständige Code
Herzlichen Glückwunsch, Sie haben gerade Ihren ersten LinkedIn-Scraper erstellt!
Wenn Sie mitgemacht haben, sollte Ihre Codebasis wie folgt aussehen:
import csv
import requests
from bs4 import BeautifulSoup
file = open('linkedin-jobs.csv', 'a')
writer = csv.writer(file)
writer.writerow(('Title', 'Company', 'Location', 'Apply'))
def linkedin_scraper(webpage, page_number):
next_page = webpage + str(page_number)
print(str(next_page))
response = requests.get(str(next_page))
soup = BeautifulSoup(response.content,'html.parser')
jobs = soup.find_all('div', class_='base-card relative w-full hover:no-underline focus:no-underline base-card--link base-search-card base-search-card--link job-search-card')
for job in jobs:
job_title = job.find('h3', class_='base-search-card__title').text.strip()
job_company = job.find('h4', class_='base-search-card__subtitle').text.strip()
job_location = job.find('span', class_='job-search-card__location').text.strip()
job_link = job.find('a', class_='base-card__full-link')('href')
writer.writerow((
job_title.encode('utf-8'),
job_company.encode('utf-8'),
job_location.encode('utf-8'),
job_link.encode('utf-8')
))
print('Data updated')
if page_number
Wir haben ein paar hinzugefügt print() Aussagen als visuelles Feedback.
Nach der Ausführung des Codes erstellt das Skript eine CSV-Datei mit den extrahierten Daten:

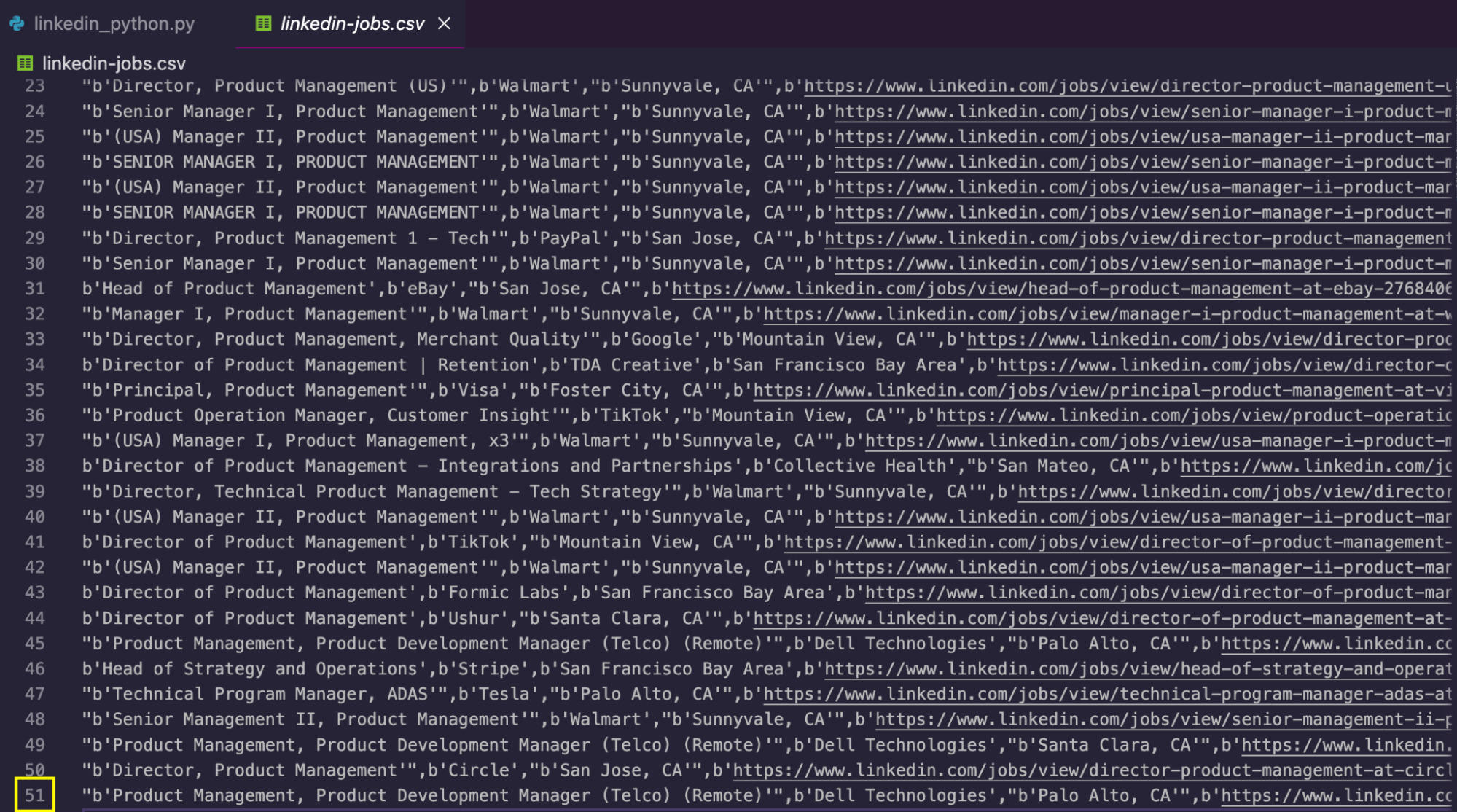
Um noch mehr Daten zu erhalten, können Sie das Limit im erhöhen if Bedingung, um mehr Seiten zu kratzen, behandeln Sie die keywords Parameter, um verschiedene Abfragen zu durchlaufen und/oder zu ändern location Parameter, um die gleiche Berufsbezeichnung in verschiedenen Städten und Ländern zu erhalten.
Scraping von LinkedIn-Profilen basierend auf der Berufsbezeichnung mit Selenium
Notiz: Bevor Sie fortfahren, denken Sie daran, dass das Scrapen von Daten hinter Login-Walls rechtliche Konsequenzen haben und möglicherweise gegen die Nutzungsbedingungen von LinkedIn verstoßen kann. Wir raten dringend davon ab, diese Technik ohne Genehmigung zu verwenden. Für dieses Tutorial verwenden wir ein Brennerkonto und einen Proxyserver, um das Risiko einer Blockierung zu minimieren.
Während unsere bisherige Methode Stellenangebote effektiv aussortierte, liefert sie nicht die detaillierten Profilinformationen, die wir für die Kandidatenrecherche benötigen. Um auf diese Daten zuzugreifen, müssen wir einzelne Profile durchsuchen.
Sehen wir uns an, wie man mit Selenium einen Web-Scraper erstellt, um Daten aus LinkedIn-Profilen basierend auf einer bestimmten Berufsbezeichnung zu sammeln unentdeckter Chrome-Treiber. In diesem Abschnitt wird davon ausgegangen, dass Sie bereits über ein grundlegendes Verständnis der Funktionsweise von Selenium verfügen.
Diese Methode kann jedoch für den Aufbau einer Kandidatendatenbank wertvoll sein, insbesondere wenn Sie über mehrere Standorte hinweg suchen möchten. Für jeden Kandidaten erfassen wir die folgenden Informationen:
- Name des Kandidaten
- LinkedIn-Profil-URL
- Berufsbezeichnung
- Standort
- Aktuelle Rolle, falls verfügbar
Einrichten der Umgebung
Zum Scrapen von LinkedIn-Profilen verwenden wir die folgenden Python-Bibliotheken:
- Selen: Automatisiert die Browserinteraktion.
- Selendraht: Erweitert die Selenfähigkeiten.
- Unerkannter Chrome-Treiber: Hilft, die Anti-Bot-Erkennung zu umgehen.
- Wunderschöne Suppe: Analysiert HTML-Inhalte.
- Lxml: Leistungsstarker XML- und HTML-Parser
- CSV: Verarbeitet CSV-Dateivorgänge.
Fahren Sie mit der Installation der erforderlichen Bibliotheken mit pip fort:
pip install selenium selenium-wire undetected-chromedriver beautifulsoup4 lxml webdriver-manager setuptools
Bibliotheken importieren
Als nächstes importieren Sie die erforderlichen Bibliotheken und richten den Selenium WebDriver mit den entsprechenden Optionen ein.
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
import undetected_chromedriver as uc
from bs4 import BeautifulSoup
import csv
Proxy-Einstellungen konfigurieren
Anschließend richten wir unsere Proxy-Konfiguration ein. Die Verwendung eines Proxys hilft, Anfragen zu verteilen und das Risiko einer IP-basierten Blockierung zu verringern:
proxy_host="your_proxy_host"
proxy_port="your_proxy_port"
proxy_username="your_username"
proxy_password = 'your_password'
proxy_url = f'http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}'
Notiz: Ersetzen „your_proxy_host„, „your_proxy_port “, „Ihr_Benutzername„, Und „Ihr_Passwort” mit Ihren tatsächlichen Proxy-Anmeldeinformationen.
Die Proxy-Konfiguration wird dann mithilfe der Selenium Wire-Optionen eingerichtet:
seleniumwire_options = {
'proxy': {
'http': proxy_url,
'https': proxy_url,
},
'verify_ssl': False,
}
Navigieren Sie zu LinkedIn
Für dieses Beispiel suchen wir nach „Junior-Webentwickler” in den Vereinigten Staaten und Indien.
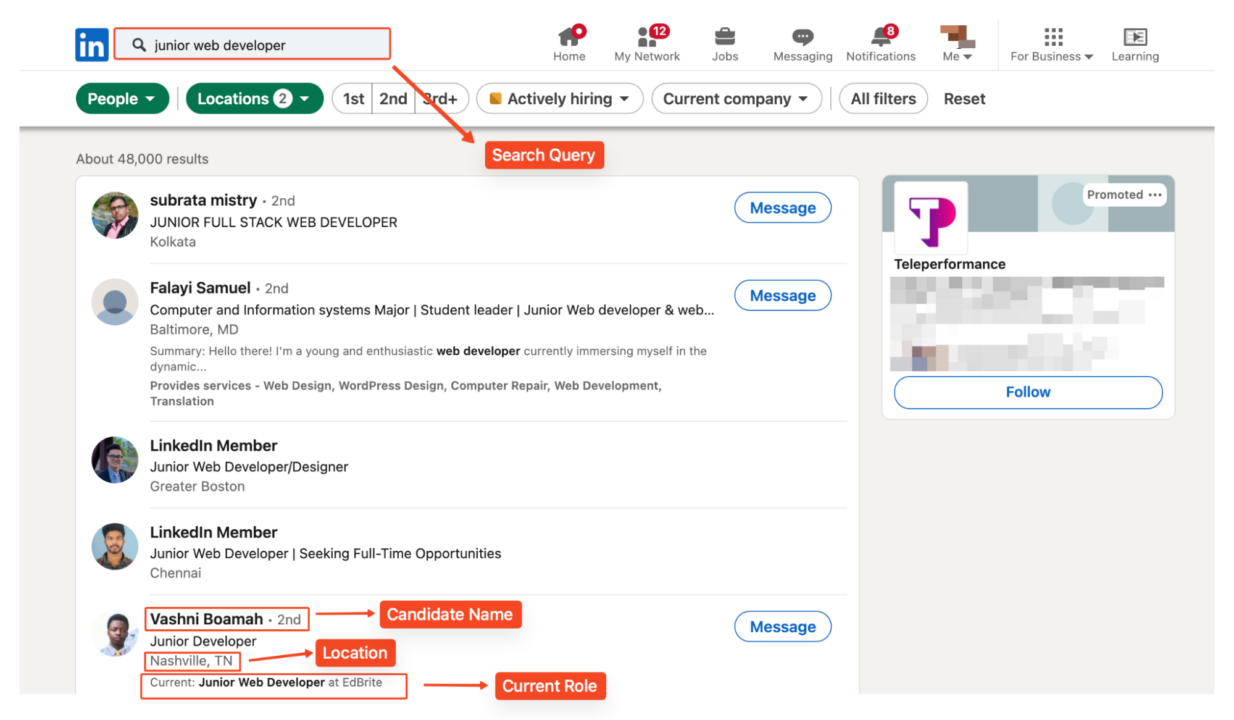
Die URL enthält Standortparameter für die gezielte Suche:
linkedin_url="https://www.linkedin.com/search/results/people/?geoUrn=%5B%22103644278%22%2C%22102713980%22%5D&keywords=junior%20web%20developer&origin=FACETED_SEARCH"
Benutzen Sie die „driver.get()”-Methode, um zur LinkedIn-Zielseite zu navigieren.
# Initialize the undetected Chrome driver with proxy settings
driver = uc.Chrome(options=options, seleniumwire_options=seleniumwire_options)
# Go to the LinkedIn page
driver.get(linkedin_url)
Wir konfigurieren Chrome-Optionen, um die Erkennung zu minimieren:
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--headless=new")
Anmelden bei LinkedIn
Um auf Profildaten zugreifen zu können, müssen wir uns bei LinkedIn anmelden. Wir empfehlen dringend, ein Dummy-Konto zu verwenden, um Ihr persönliches Profil nicht zu gefährden. Wir suchen die E-Mail- und Passwort-Eingabefelder anhand ihrer HTML-IDs und verwenden dann die send_keys() Methode zur Eingabe Ihrer Anmeldeinformationen.
# Wait for the username and password fields to load and enter credentials
username_field = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.ID, 'username')))
username_field.send_keys('Linkedin_username')
password_field = driver.find_element(By.ID, 'password')
password_field.send_keys(‘Linkedin_password’)
login_button = driver.find_element(By.CSS_SELECTOR, '.login__form_action_container button')
login_button.click()
print("Sign In Successful...\n")
# Allow some time to bypass CAPTCHA if needed
sleep(10)
Notiz: Ersetzen „Linkedin_Benutzername“ Und „LinkedIn_Passwort” mit Ihren tatsächlichen LinkedIn-Anmeldedaten.
Scraping von Profildaten mit Selen
Nach dem Anmelden erstellen wir eine CSV-Datei zum Speichern unserer Scraped-Daten:
with open('linkedin_profiles.csv', 'w', newline="", encoding='utf-8') as csvfile:
fieldnames = ('Name', 'Profile Link', 'Job Title', 'Location', 'Current Role')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
Der Scraper durchläuft die ersten fünf (5) Suchergebnisseiten und extrahiert wichtige Informationen aus jedem Profil.
Wir können mehr Seiten scrapen, indem wir einfach die Anzahl der zu scrapenden Seiten anpassen:
for page_number in range(1, 6):
page_url = linkedin_url + f"&page={page_number}"
driver.get(page_url)
print(f"Scraping page {page_number}...\n")
Für jedes Profil suchen und analysieren wir die Benutzerdaten mit BeautifulSoup. Lassen Sie uns jedes Element aufschlüsseln, das wir aus den LinkedIn-Profilen extrahieren:
Suchen von Profilcontainern
Zuerst müssen wir alle Profilcontainer auf der Seite finden. Wir werden BeautifulSoup's verwenden find_all() Methode, um alle diese Container zu erhalten:
profiles = soup.find_all('li', class_='reusable-search__result-container')
Namensextraktion
Um den Namen des Benutzers zu extrahieren, befindet er sich in a Tag mit dem Attribut aria-hidden='true'. Wir verwenden die Suchmethode, um dieses Tag in jedem Profil zu finden. Einige Profile sind möglicherweise ausgeblendet oder eingeschränkt, daher bieten wir eine Alternative zu „LinkedIn Member„:
name_tag = profile.find('span', {'aria-hidden': 'true'})
name = name_tag.get_text(strip=True) if name_tag else "LinkedIn Member"
Als Nächstes extrahieren wir die URL zum LinkedIn-Profil des Benutzers:
profile_link_tag = profile.find('a', class_='app-aware-link', href=True)
profile_link = profile_link_tag('href') if profile_link_tag else "N/A"
Berufsbezeichnung
Die Berufsbezeichnung des Benutzers befindet sich in a div Element mit dem 'entity-result__primary-subtitle' Klasse:
job_title_tag = profile.find('div', class_='entity-result__primary-subtitle')
job_title = job_title_tag.get_text(strip=True) if job_title_tag else "N/A"
Wenn die Berufsbezeichnung nicht verfügbar ist, weisen wir ihr „N/A“ zu job_title Variable.
Standortinformationen
Standortdaten werden in einem gespeichert div mit dem 'entity-result__secondary-subtitle' Klasse:
location_tag = profile.find('div', class_='entity-result__secondary-subtitle')
location = location_tag.get_text(strip=True) if location_tag else "N/A"
Aktuelle Rolle
Um die aktuelle Rolle oder Position zu extrahieren, suchen wir nach einem Tag mit der Klasse entity-result__summary. Wir prüfen, ob der Text mit „beginnt“Current:” und extrahieren Sie die relevanten Informationen:
current_role = "N/A"
summary_p = profile.find('p', class_='entity-result__summary')
if summary_p:
summary_text = summary_p.get_text(strip=True)
if summary_text.startswith("Current:"):
current_role = summary_text.replace("Current:", "").strip()
Schreiben der extrahierten Daten in die CSV-Datei
Nachdem wir alle notwendigen Informationen extrahiert haben, schreiben wir die Daten mithilfe von in unsere CSV-Datei writer.writerow() Verfahren:
writer.writerow({
'Name': name,
'Profile Link': profile_link,
'Job Title': job_title,
'Location': location,
'Current Role': current_role
})
Wir drucken außerdem eine Bestätigungsnachricht aus, um anzuzeigen, dass das Profil gespeichert wurde:
print(f"Saved profile: {name}")
Schließen des Browsers
Schließen Sie nach dem Scraping den Browser, um Systemressourcen freizugeben.
# Close the browser
driver.quit()
Anzeigen der gesammelten Daten
Nachdem Sie das Skript ausgeführt haben, erhalten Sie eine CSV-Datei mit dem Namen linkedin_profiles.csv enthält die geschabten Daten:
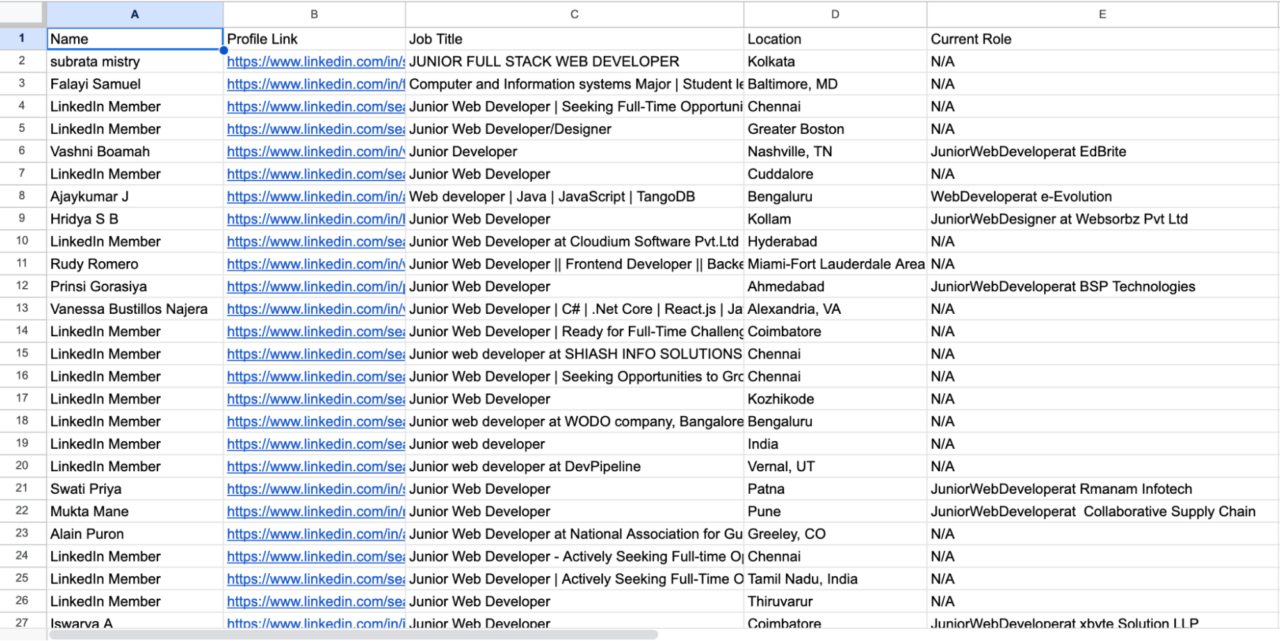
Vollständiger Code: Schabeprofile mit Selen
Dieser vollständige Code integriert alle Techniken, die wir in diesem Abschnitt verwendet haben.
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
import undetected_chromedriver as uc
from bs4 import BeautifulSoup
import csv
proxy_host="your_proxy_host"
proxy_port="your_proxy_port"
proxy_username="your_linkedin_email"
proxy_password = 'your_password'
# Construct the proxy URL
proxy_url = f'http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}'
# LinkedIn URL and credentials
linkedin_url="https://www.linkedin.com/search/results/people/?geoUrn=%5B%22103644278%22%2C%22102713980%22%5D&keywords=junior%20web%20developer&origin=FACETED_SEARCH"
username = "Your_linkedin_username"
password = "Your_linkedin_password"
# Setting Chrome options and proxy configuration for undetected_chromedriver
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--headless=new")
seleniumwire_options = {
'proxy': {
'http': proxy_url,
'https': proxy_url,
},
'verify_ssl': False,
}
# Initialize the undetected Chrome driver with proxy settings
driver = uc.Chrome(options=options, seleniumwire_options=seleniumwire_options)
# Go to the LinkedIn page
driver.get(linkedin_url)
# Wait for the username and password fields to load and enter credentials
username_field = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.ID, 'username')))
username_field.send_keys(username)
password_field = driver.find_element(By.ID, 'password')
password_field.send_keys(password)
login_button = driver.find_element(By.CSS_SELECTOR, '.login__form_action_container button')
login_button.click()
print("Sign In Successful...\n")
sleep(10)
# Open a CSV file to write the data
with open('linkedin_profiles.csv', 'w', newline="", encoding='utf-8') as csvfile:
fieldnames = ('Name', 'Profile Link', 'Job Title', 'Location', 'Current Role')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader() # Write the header row
# Loop through the first 5 pages
for page_number in range(1, 6):
page_url = linkedin_url + f"&page={page_number}"
driver.get(page_url)
print(f"Scraping page {page_number}...\n")
# Wait for the search results to load
sleep(5)
# Locate and parse the profile details
try:
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'lxml')
profiles = soup.find_all('li', class_='reusable-search__result-container')
for profile in profiles:
# name
name_tag = profile.find('span', {'aria-hidden': 'true'})
name = name_tag.get_text(strip=True) if name_tag else "LinkedIn Member"
# profile link
profile_link_tag = profile.find('a', class_='app-aware-link', href=True)
profile_link = profile_link_tag('href') if profile_link_tag else "N/A"
# job title
job_title_tag = profile.find('div', class_='entity-result__primary-subtitle')
job_title = job_title_tag.get_text(strip=True) if job_title_tag else "N/A"
# location
location_tag = profile.find('div', class_='entity-result__secondary-subtitle')
location = location_tag.get_text(strip=True) if location_tag else "N/A"
# current (if any)
current_role = "N/A"
summary_p = profile.find('p', class_='entity-result__summary')
if summary_p:
summary_text = summary_p.get_text(strip=True)
if summary_text.startswith("Current:"):
current_role = summary_text.replace("Current:", "").strip()
# Write the extracted data to the CSV file
writer.writerow({
'Name': name,
'Profile Link': profile_link,
'Job Title': job_title,
'Location': location,
'Current Role': current_role
})
print(f"Saved profile: {name}")
except Exception as e:
print(f"An error occurred on page {page_number}: {e}")
# Close the browser
driver.quit()
So extrahieren Sie Unternehmensdaten von LinkedIn
Um LinkedIn-Unternehmensdaten zu extrahieren, können wir auf unserer Benutzerprofil-Scaping-Technik aufbauen und unseren Code an LinkedIn-Unternehmen anpassen. Zur Sicherheit durchsuchen wir Technologieunternehmen in den USA mit 11–50 Mitarbeitern, um Informationen wie deren Namen, LinkedIn-Profile, Followerzahl, Websites, Branche und Hauptsitz zu sammeln.
Wir werden die gleichen Bibliotheken und das gleiche Setup wie zuvor verwenden. Navigieren Sie zunächst zur Suchergebnisseite des Unternehmens:
linkedin_url="https://www.linkedin.com/search/results/companies/?companyHqGeo=%5B%22103644278%22%5D&companySize=%5B%22C%22%5D&industryCompanyVertical=%5B%221594%22%5D&origin=FACETED_SEARCH&sid=G4U"
Unser Fokus liegt jedoch ausschließlich auf dem Scraping der unten aufgeführten unternehmensspezifischen Daten:
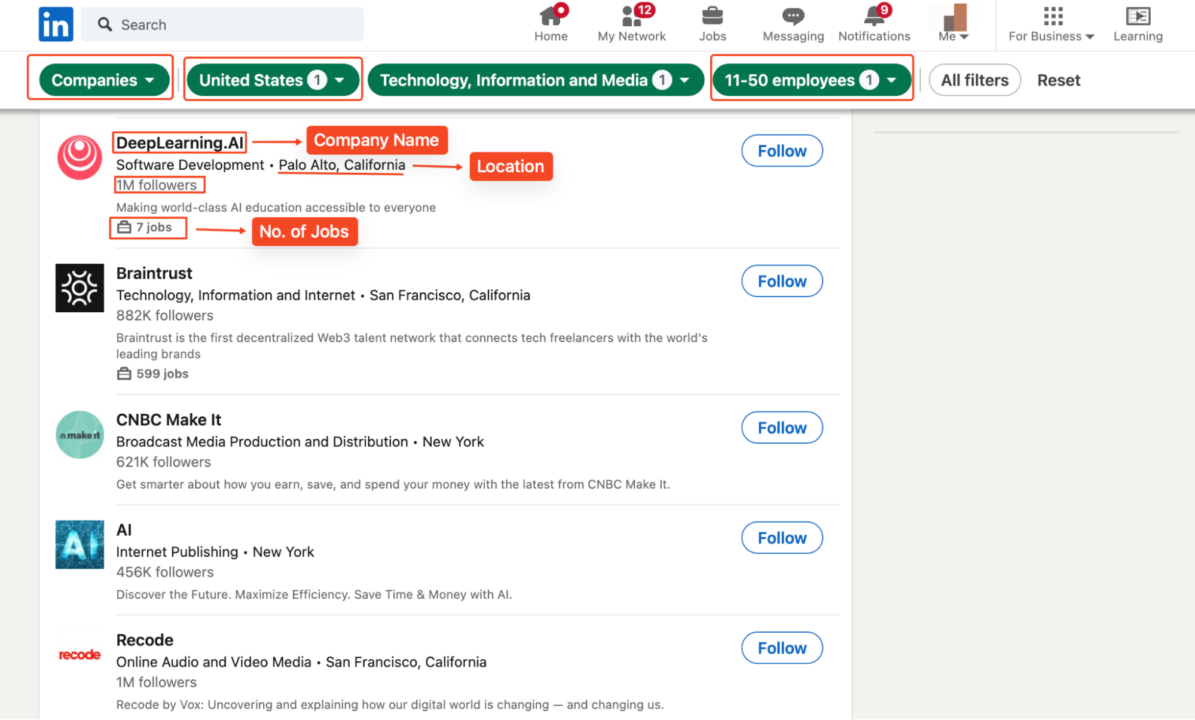
Durchblättern von Seiten und Extrahieren von Unternehmensdaten
Nach der Anmeldung durchgehen wir die ersten fünf Seiten der Suchergebnisse, um Daten von mehreren Unternehmen zu sammeln. Wir erstellen die URL für jede Seite, indem wir die Seitennummer anhängen und zu dieser navigieren. Anschließend warten wir einige Sekunden, bis die Seite geladen ist.
for page_number in range(1, 6):
page_url = linkedin_url + f"&page={page_number}"
driver.get(page_url)
print(f"Scraping page {page_number}...\n")
sleep(5) # Adjust sleep time if necessary
Parsen der Seitenquelle
Wir analysieren die Seitenquelle mit BeautifulSoup, um alle Firmeneinträge auf der aktuellen Seite abzurufen:
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'lxml')
company_listings = soup.find_all('li', class_='reusable-search__result-container')
Firmennamen extrahieren
Wir extrahieren den Firmennamen aus dem Tag mit der Klasse entity-result__title-text. Wenn das Namensschild nicht gefunden wird, verwenden wir standardmäßig „N/A“.
name_tag = company_li.find('span', class_='entity-result__title-text')
company_name = name_tag.get_text(strip=True) if name_tag else "N/A"
Extrahieren der Unternehmensprofil-URL
Der Link zum Unternehmensprofil befindet sich innerhalb von a Tag mit der Klasse app-aware-link. Wir extrahieren die href Attribut, um die URL zu erhalten:
profile_link_tag = company_li.find('a', class_='app-aware-link', href=True)
company_profile_url = profile_link_tag('href') if profile_link_tag else "N/A"
Extrahieren von Branche, Standort und Anzahl der Follower
Die Branche und der Standort liegen im Umkreis von a
entity-result__primary-subtitle. Sie werden normalerweise durch ein „•“ getrennt:
primary_subtitle_tag = company_li.find('div', class_='entity-result__primary-subtitle')
primary_subtitle = primary_subtitle_tag.get_text(strip=True) if primary_subtitle_tag else "N/A"
if '•' in primary_subtitle:
industry, location = (text.strip() for text in primary_subtitle.split('•', 1))
else:
industry, location = primary_subtitle, "N/A"
Dann ermitteln wir die Anzahl der Follower von a
entity-result__secondary-subtitle:
secondary_subtitle_tag = company_li.find('div', class_='entity-result__secondary-subtitle')
num_followers = secondary_subtitle_tag.get_text(strip=True) if secondary_subtitle_tag else "N/A"
Anzahl der Jobs extrahieren
Anschließend suchen wir nach der Anzahl der Arbeitsplätze im Unternehmen
reusable-search-simple-insight__text-container:
num_jobs = "N/A"
insight_tags = company_li.find_all('div', class_='reusable-search-simple-insight__text-container')
for insight_tag in insight_tags:
insight_text = insight_tag.get_text(strip=True)
if 'jobs' in insight_text:
num_jobs = insight_text
break
Daten in die CSV-Datei schreiben
Nachdem wir alle erforderlichen Informationen extrahiert haben, schreiben wir die Daten in unsere CSV-Datei. Dadurch wird der CSV-Datei für jedes Unternehmen eine neue Zeile hinzugefügt:
writer.writerow({
'Company Name': company_name,
'Profile URL': company_profile_url,
'Industry': industry,
'Location': location,
'Number of Followers': num_followers,
'Number of Jobs': num_jobs
})
print(f"Saved company: {company_name}")
Schließen des Browsers
Nachdem das Scraping abgeschlossen ist, schließen wir den Browser und drucken eine Bestätigungsmeldung. Dadurch werden Systemressourcen freigegeben und das Ende des Skripts signalisiert:
driver.quit()
print("Scraping complete.")
Vollständiger Code und Anzeigen der gesammelten Daten
Dies ist der vollständige Code, den wir verwendet haben, um Unternehmensdaten von LinkedIn zu entfernen.
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
import undetected_chromedriver as uc
from bs4 import BeautifulSoup
import csv
# Proxy credentials and LinkedIn credentials
proxy_host="your_proxy_host"
proxy_port="your_proxy_port"
proxy_username="your_proxy_username"
proxy_password = 'your_proxy_password'
proxy_url = f'http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}'
linkedin_url="https://www.linkedin.com/search/results/companies/?companyHqGeo=%5B%22103644278%22%5D&industryCompanyVertical=%5B%221594%22%5D&origin=FACETED_SEARCH&sid=G4U"
username = "your_linkedin_email"
password = "your_password"
# Set Chrome options
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--headless=new")
# Initialize the undetected Chrome driver with proxy settings
driver = uc.Chrome(options=options, seleniumwire_options={
'proxy': {'http': proxy_url, 'https': proxy_url},
'verify_ssl': False
})
# Log into LinkedIn
driver.get(linkedin_url)
username_field = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.ID, 'username'))
)
username_field.send_keys(username)
driver.find_element(By.ID, 'password').send_keys(password)
driver.find_element(By.CSS_SELECTOR, "button(type="submit")").click()
print("Sign In Successful...\n")
sleep(10) # Wait for the login process to complete
# Open a CSV file to write the company data
with open('linkedin_companies.csv', 'w', newline="", encoding='utf-8') as csvfile:
fieldnames = ('Company Name', 'Profile URL', 'Industry', 'Location', 'Number of Followers', 'Number of Jobs')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# Loop through the first 5 pages
for page_number in range(1, 6):
page_url = linkedin_url + f"&page={page_number}"
driver.get(page_url)
print(f"Scraping page {page_number}...\n")
sleep(5)
# Parse page source and extract company data
try:
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'lxml')
company_listings = soup.find_all('li', class_='reusable-search__result-container')
for company_li in company_listings:
# company name
name_tag = company_li.find('span', class_='entity-result__title-text')
company_name = name_tag.get_text(strip=True) if name_tag else "N/A"
# company profile link
profile_link_tag = company_li.find('a', class_='app-aware-link', href=True)
company_profile_url = profile_link_tag('href') if profile_link_tag else "N/A"
# industry and location
primary_subtitle_tag = company_li.find('div', class_='entity-result__primary-subtitle')
primary_subtitle = primary_subtitle_tag.get_text(strip=True) if primary_subtitle_tag else "N/A"
if '•' in primary_subtitle:
industry, location = (text.strip() for text in primary_subtitle.split('•', 1))
else:
industry, location = primary_subtitle, "N/A"
# number of followers
secondary_subtitle_tag = company_li.find('div', class_='entity-result__secondary-subtitle')
num_followers = secondary_subtitle_tag.get_text(strip=True) if secondary_subtitle_tag else "N/A"
# number of jobs (if any)
num_jobs = "N/A"
insight_tags = company_li.find_all('div', class_='reusable-search-simple-insight__text-container')
for insight_tag in insight_tags:
insight_text = insight_tag.get_text(strip=True)
if 'jobs' in insight_text:
num_jobs = insight_text
break
# Write company data to the CSV file
writer.writerow({
'Company Name': company_name,
'Profile URL': company_profile_url,
'Industry': industry,
'Location': location,
'Number of Followers': num_followers,
'Number of Jobs': num_jobs
})
print(f"Saved company: {company_name}")
except Exception as e:
print(f"An error occurred on page {page_number}: {e}")
# Close the browser
driver.quit()
print("Scraping complete.")
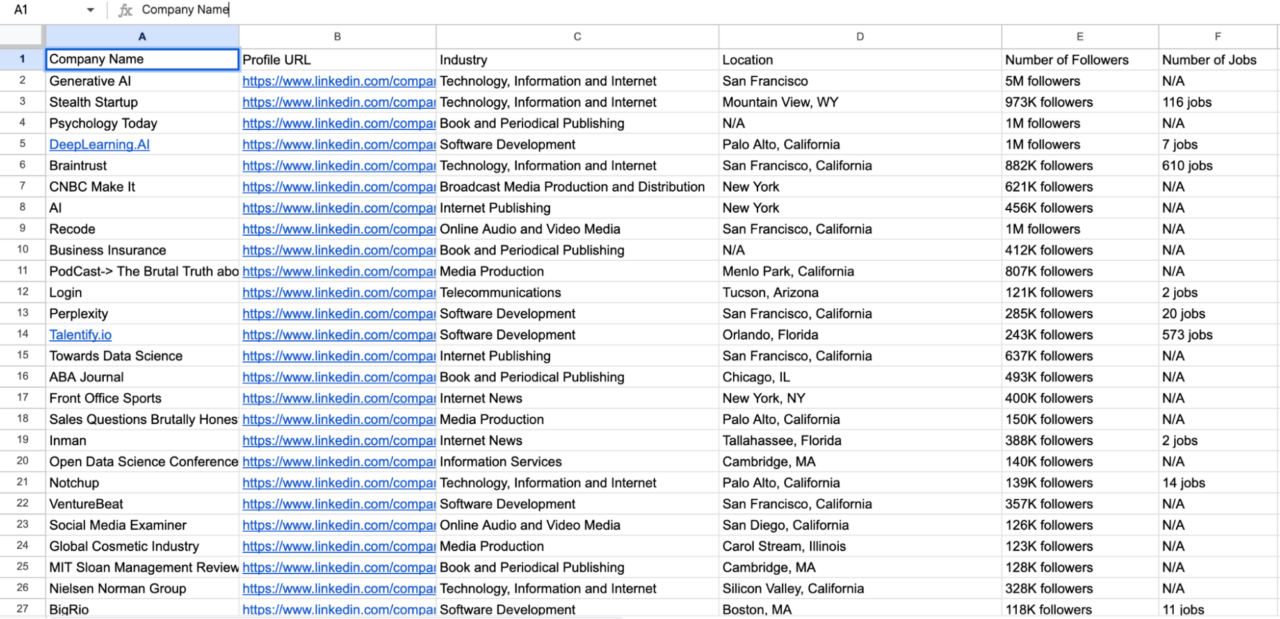
Wenn Sie diesen Code ausführen, wird eine CSV-Datei mit dem Namen generiert linkedin_companies.csv enthält die gekratzten Unternehmensdaten.
Holen Sie sich mit ScraperAPI die gewünschten LinkedIn-Daten
Der Aufbau eines LinkedIn-Scrapers kann entmutigend sein, insbesondere wenn das Risiko besteht, blockiert zu werden. Wenn Sie jedoch dieser LinkedIn-Web-Scraping-Anleitung folgen, garantieren wir, dass Sie LinkedIn-Daten in großen Mengen ohne Probleme extrahieren und exportieren können.
Denken Sie daran: Wenn das Projekt mehr als nur ein paar Seiten umfasst, können Sie mithilfe der ScraperAPI-Integration Hindernisse vermeiden und Ihr geistiges Eigentum vor Anti-Scraping-Systemen schützen.
Sie wissen nicht, wo Sie anfangen sollen? Kontaktieren Sie unser Vertriebsteam und lassen Sie unsere Experten den perfekten Plan für Ihren Anwendungsfall erstellen!
Bis zum nächsten Mal, viel Spaß beim Schaben!
