
Stellen Sie sich ein riesiges Einkaufszentrum mit Produkten aus aller Welt vor, das unzählige Angebote präsentiert, von den neuesten Gadgets bis hin zu Modeartikeln. So könnte man Google Shopping beschreiben.
Mit Scraping können Sie die Informationen in jeder Produktliste extrahieren, analysieren und nutzen und Erkenntnisse gewinnen, um intelligentere Geschäftsentscheidungen zu treffen, innovative Marketingstrategien anzuwenden und Verbraucher zu stärken.
In diesem Artikel befassen wir uns mit den Vorteilen des Scrapings des Gegebenen mit Google Shopping und mit den Tools, die Sie zum Scrapen der benötigten Daten verwenden können.
Das Auslesen von Daten aus Google Shopping kann aus verschiedenen Gründen notwendig sein, von der Analyse des Marktes eines Unternehmens bis hin zur Erweiterung seiner Möglichkeiten. Mithilfe dieser Daten können Sie Markttrends schnell verfolgen und mehr über die Aktionen der Wettbewerber erfahren. Das Scrapen von Google-Produktinformationen kann auch für die Marktforschung oder Preisüberwachung hilfreich sein.
Mit Google Shopping Scraping verfolgen und analysieren Sie Verbraucherpreise und entwickeln auf der Grundlage der Daten neue Marketingstrategien. Auf diese Weise verbessern Sie nicht nur die Preisgestaltung, sondern können auch Trends rechtzeitig erkennen.
Die Google Shopping-Seite verstehen
Um Daten aus Google Shopping zu extrahieren, müssen wir die Seite recherchieren und herausfinden, welche Elemente wir durchsuchen müssen. Recherchieren Sie dazu die HTML-Struktur der gewünschten Seite und schließen Sie die notwendigen CSS-Selektoren ab.
Beginnen wir mit der Google Shopping-Seite und gehen dann zur Produktseite, um die verfügbaren Daten zu überprüfen. Achten Sie auf diese Seite:
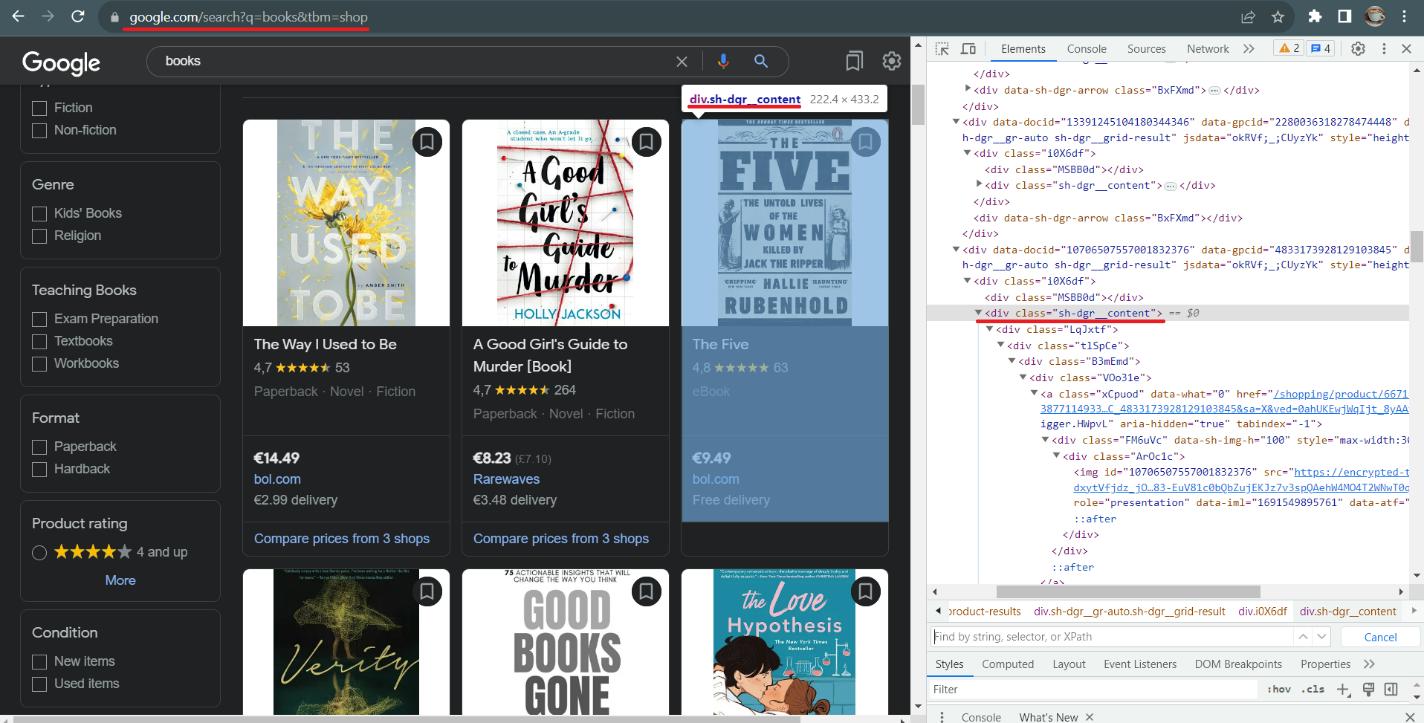
Das erste, was Sie sich ansehen sollten, ist der Link. Dank seiner Struktur ist das Verfassen von Links direkt in der Abfrage möglich. Sie müssen lediglich das Schlüsselwort ersetzen. Google unterstützt mehrere Parameter, die über den Link übergeben werden können, es sind jedoch nur zwei erforderlich: das Keyword und der Shop-Parameter, der zeigt, dass wir im Shopping-Bereich nach Daten suchen.
Gehen Sie als Nächstes zu DevTools (F12 oder klicken Sie mit der rechten Maustaste auf die Seite und wählen Sie „Inspizieren“) und erkunden Sie die Seite. In diesem Fall können wir sehen, dass alle Produkte die Klasse „sh-dgr__content“ haben. Wir können die Daten zu jedem Produkt abrufen, indem wir mit einem CSS-Selektor darauf zugreifen. Sehen Sie anhand eines Beispiels für ein Produkt, in welchen Tags sich die Informationen befinden.
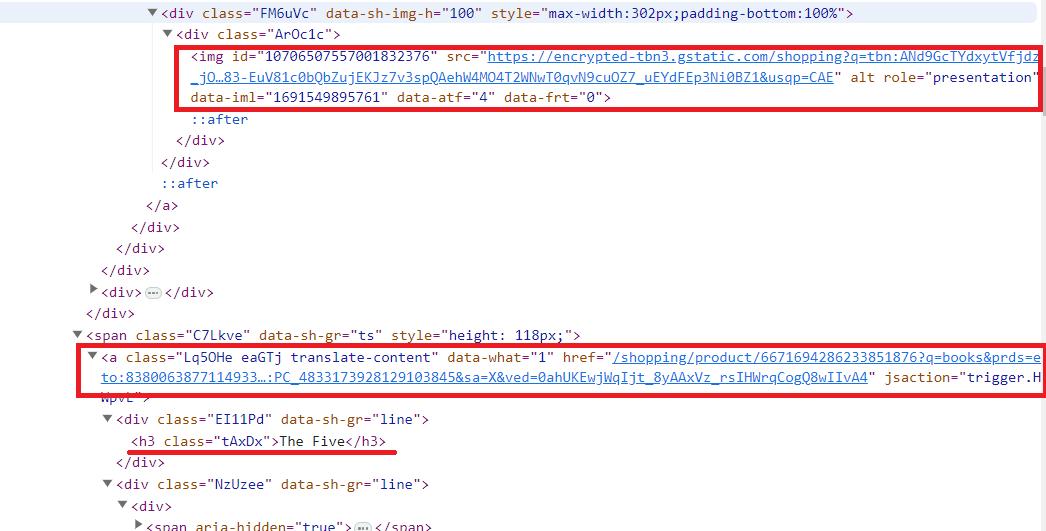
Die am einfachsten zu extrahierenden Daten sind das Bild (img-Tag-src-Parameter), der Titel (h3-Tag) und der Link zur Produktseite (ein Tag, href-Parameter). Nachdem die Seite aktualisiert wurde, verfügen die restlichen Daten über ein div-Tag und eine automatisch generierte Klasse mit einem anderen Namen. Den Rest der Daten können wir mithilfe von CSS-Selektoren für das untergeordnete Element oder benachbarte Elemente extrahieren.
Gehen Sie nun zu einer Produktseite und erkunden Sie sie auf die gleiche Weise wie die Seite zuvor.
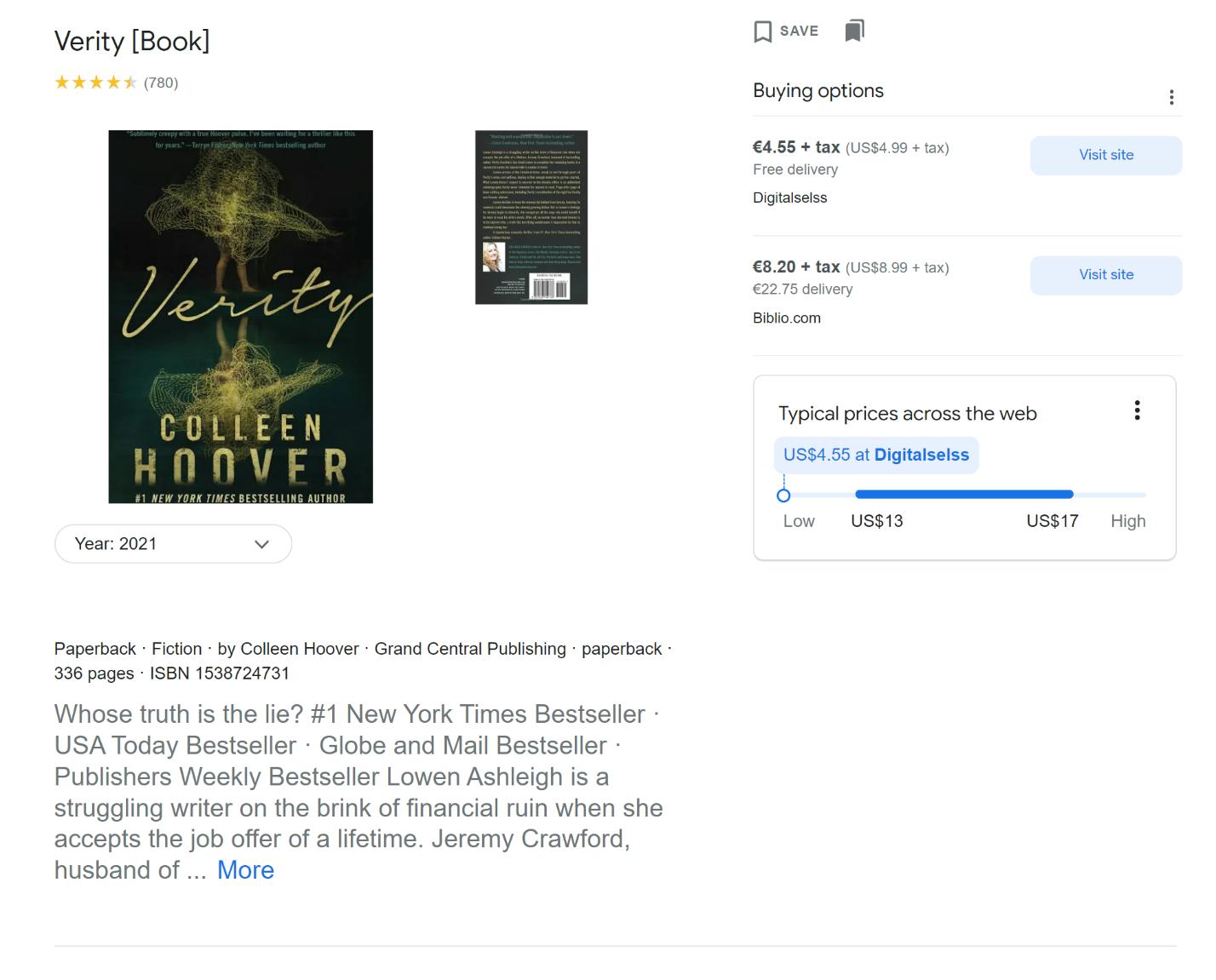
Auf dieser Seite können wir detailliertere Informationen zum Produkt erhalten:
- Produktname.
- Bewertung und Anzahl der Rezensionen.
- Preise in verschiedenen Geschäften.
- Beschreibung.
- Zusätzliche Produktdetails (in unserem Fall Genre, ISBN, Autor und Seitenzahl).
- Rezensionen.
- Verwandte Produkte.
Typischerweise reicht auch die Google Shopping-Seite aus, um Produktinformationen abzurufen. Wenn Sie jedoch alles über ein Produkt wissen möchten, können Sie diese Informationen auf der Produktseite abrufen.
Erhalten Sie Daten mit Scrape-It.Cloud Request Builder
Bevor wir Daten in Python mithilfe von APIs oder Bibliotheken extrahieren, möchten wir Ihnen zeigen, wie Sie mit nur wenigen Klicks schnell und einfach JSON mit den erforderlichen Daten erhalten.
Melden Sie sich bei scrape-it.cloud an und gehen Sie zum Abschnitt Google SERP API. Wenn Sie sich anmelden, erhalten Sie 1000 kostenlose Credits, sodass Sie das Tool ausprobieren und entscheiden können, ob es das Richtige für Sie ist.
Auf der Google SERP API-Seite finden Sie Einstellungen, die Ihnen dabei helfen können, Ihre Abfrage genauer zu gestalten. Hier gibt es auch einen Code-Viewer, mit dem Sie den Code kopieren können, um die generierte Abfrage in einer der gängigen Programmiersprachen auszuführen.
Versuchen Sie, Ihre erste Abfrage zu erstellen. Passen Sie dazu den Standort und die Lokalisierung an.
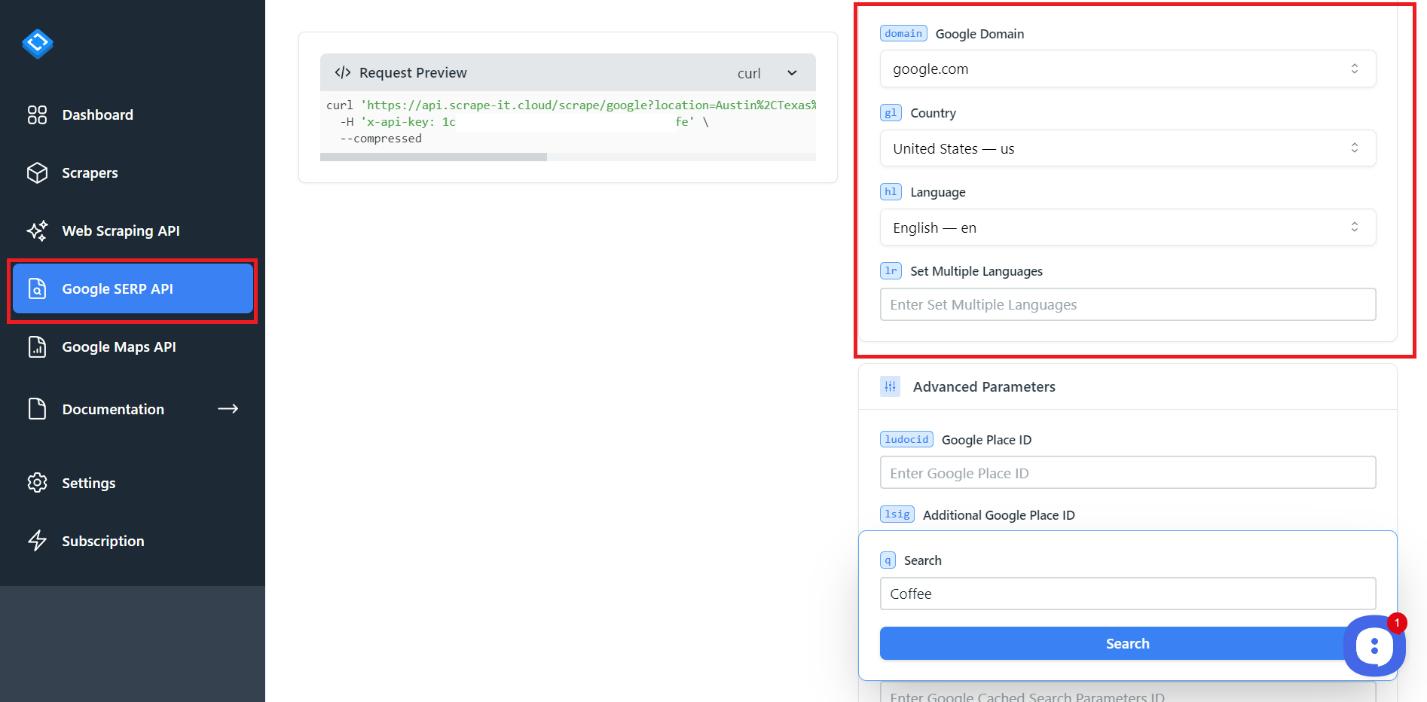
Wählen Sie dann Ihren Abfragetyp, Google Shopping, aus, um von dort Daten zu sammeln. Sie können auch Daten von Google Bildern, Nachrichten, SERP (Suchmaschinenseitenergebnissen), Videos und Lokalen sammeln. Passen Sie zusätzliche Einstellungen nach Bedarf an. Sie haben intuitive Namen, sodass Sie sie bei Bedarf selbst anpassen können. Wenn Sie Fragen zu Parametern haben, beschreiben wir diese auf der Dokumentationsseite.
Wenn alle Parameter ausgefüllt sind, geben Sie das Schlüsselwort ein und klicken Sie auf die Schaltfläche „Suchen“.
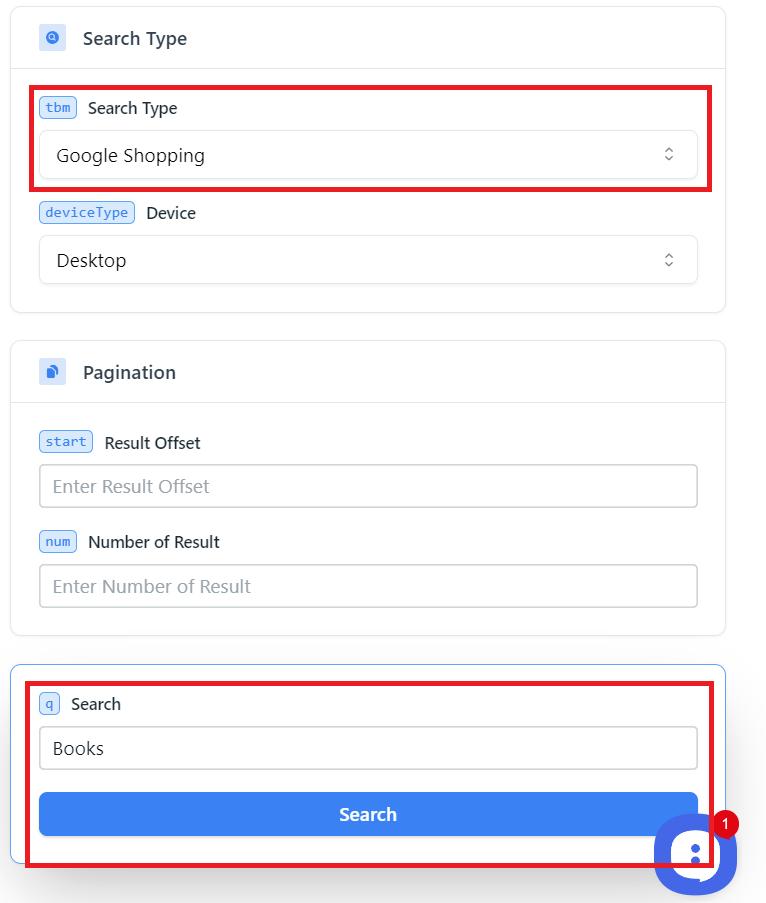
Das Ergebnis ist eine JSON-Antwort, die Sie verwenden, in ein praktisches Format konvertieren oder in Excel importieren können.

Auf diese Weise erhalten Sie die benötigten Produktdaten, ohne eine einzige Codezeile schreiben zu müssen, und das in kürzester Zeit.
Lassen Sie uns nun die Google Shopping API von scrape-it.cloud verwenden, die erforderlichen Daten in ein Python-Skript übertragen und sie dann im *.xlsx-Format speichern.
Holen Sie sich Ihren API-Schlüssel
Gehen Sie dazu zurück zu scrape-it.cloud und gehen Sie in Ihrem Konto auf die Registerkarte „Dashboard“.
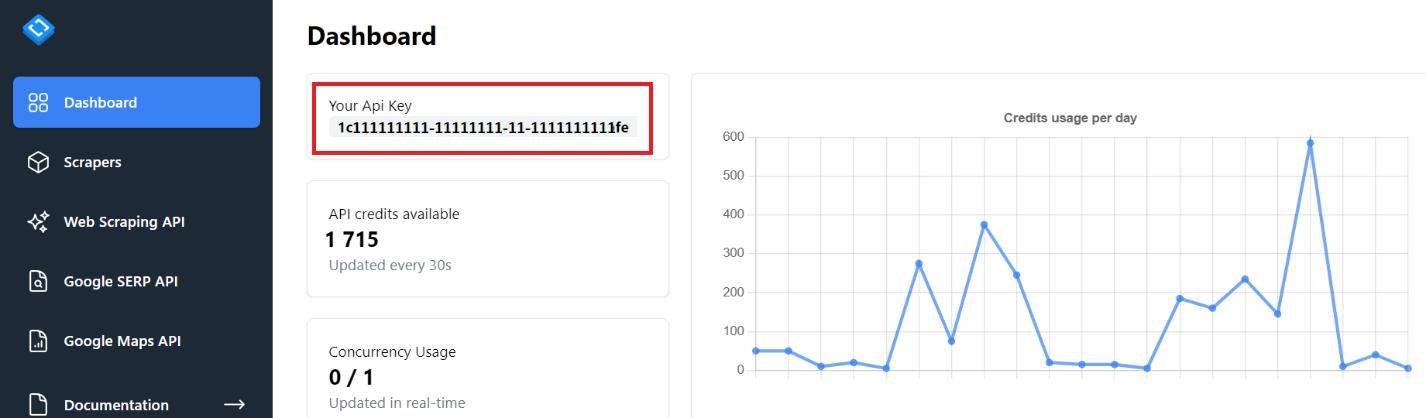
Sie können auch Ihre Kreditauslastungsstatistik, eine Liste der zuletzt verwendeten No-Code-Scrapper und Ihren Kreditsaldo einsehen.
Verwenden Sie die API in Ihrem Skript
Erstellen Sie eine neue Datei mit der Erweiterung *.py. Wir werden die Anforderungsbibliothek verwenden, um Anforderungen von der API und der Pandas-Bibliothek auszuführen und sie einfach im *.xlsx- oder *.csv-Dateiformat zu speichern. Um sie zu installieren, führen Sie diese Befehle in der Eingabeaufforderung aus:
pip install requests
pip install pandasImportieren Sie dann diese Bibliotheken in Ihre Datei:
import requests
import pandas as pdGeben Sie die Variablen an, die Sie verwenden möchten. Dies ist notwendig, wenn Sie mit demselben Skript Daten sammeln möchten, beispielsweise für mehrere Schlüsselwörter.
keyword = 'Books'
api_url="https://api.scrape-it.cloud/scrape/google"Legen Sie nun den Header mit Ihrem API-Schlüssel fest und bilden Sie den Hauptteil der Anfrage. Sie können diese Google Shopping-Parameter verwenden:
|
Kategorie |
Parameter |
Beschreibung |
Beispiel |
|---|---|---|---|
|
Suchanfrage |
Q |
Erforderlich. Abfrage, nach der Sie suchen möchten. |
q=Kaffee |
|
Geographische Lage |
Standort |
Optional. Kanonischer Google-Standort. |
Standort=New York, USA |
|
uule |
Optional. Verschlüsselter Ort für die Suche. |
uule=SomeEncodedLocation |
|
|
Lokalisierung |
google_domain |
Optional. Zu verwendende Google-Domain. |
google_domain=google.co.uk |
|
gl |
Optional. Land für die Suche. |
gl=uns |
|
|
hl |
Optional. Sprache für die Suche. |
hl=en |
|
|
lr |
Optional. Beschränken Sie die Suche auf eine bestimmte Sprache. |
lr=lang_fr |
|
|
Erweiterte Google-Parameter |
ludocid |
Optional. Google My Business-Eintrags-ID. |
ludocid=SomeID |
|
lsig |
Optional. ID der Kartenansicht des Wissensdiagramms. |
lsig=SomeID |
|
|
kgmid |
Optional. ID des Google Knowledge Graph-Eintrags |
kgmid=SomeID |
|
|
si |
Optional. ID der zwischengespeicherten Suchparameter. |
si=SomeID |
|
|
Erweiterte Filter |
tbs |
Optional. Erweiterte Suchparameter. |
tbs=SomeParameters |
|
sicher |
Optional. Filterstufe für Inhalte für Erwachsene |
sicher=aktiv |
|
|
nfpr |
Optional. Automatisch korrigierte Ergebnisse ausschließen. |
nfpr=1 |
|
|
Filter |
Optional. Filter aktivieren/deaktivieren. |
Filter=0 |
|
|
Suchtyp |
tbm |
Optional. Art der Suche. |
tbm=shop |
|
Seitennummerierung |
Start |
Optional. Ergebnis-Offset. |
Start=10 |
|
Num |
Optional. Maximale Anzahl an Ergebnissen. |
Anzahl=20 |
Sie können bei Bedarf noch viele weitere Parameter angeben, wir verwenden nur einige wenige:
headers = {'x-api-key': 'PUT-YOUR-API-KEY'}
params = {
'q': keyword,
'domain': 'google.com',
'tbm': 'shop'
}Führen Sie nun die Abfrage aus, indem Sie alle Daten zusammen sammeln. Um eine Unterbrechung des Skripts aufgrund von Fehlern zu vermeiden, verwenden Sie den try..exclusive-Block:
try:
response = requests.get(api_url, params=params, headers=headers)
if response.status_code == 200:
# Here will be your Code
except Exception as e:
print('Error:', e)Extrahieren wir innerhalb der obigen Bedingung die erforderlichen Daten im JSON-Format. Wenn Sie sich den Screenshot der JSON-Antwort im vorherigen Beispiel ansehen, gibt die API die erforderlichen Daten im Parameter „shoppingResults“ zurück.
data = response.json()
shopping = data('shoppingResults')Abschließend verwenden wir Pandas, um die Daten in der gewünschten Form zu speichern.
df = pd.DataFrame(shopping)
df.to_excel("shopping_result.xlsx", index=False)Als Ergebnis erhalten wir diese Datei, die automatisch Spaltenüberschriften erstellt und die Daten speichert. Auch wenn sich der Inhalt von shoppingResults in Zukunft ändert, erhalten wir weiterhin die Daten mit den Headern in den JSON-Parametern. Hier erhalten wir die Produktposition, den Titel, den Link, die Bewertung, Rezensionen und andere Produktinformationen.

Vollständiger Code:
import requests
import pandas as pd
keyword = 'Books'
api_url="https://api.scrape-it.cloud/scrape/google"
headers = {'x-api-key': 'YOUR-API-KEY'}
params = {
'q': keyword,
'domain': 'google.com',
'tbm': 'shop'
}
try:
response = requests.get(api_url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
shopping = data('shoppingResults')
df = pd.DataFrame(shopping)
df.to_excel("shopping_result.xlsx", index=False)
except Exception as e:
print('Error:', e)Wenn Sie keine Pandas verwenden möchten, können Sie die Datei erstellen, die Spalten benennen und die Daten Zeile für Zeile speichern.
Die Verwendung einer API vereinfacht den Scraping-Prozess erheblich, da der schwierigste Teil auf der Seite der Ressource erledigt wird, die die API bereitstellt. Es löst Probleme beim JS-Rendering, beim Umgehen von Sperren und Captchas und vielem mehr. Dem Benutzer werden gut strukturierte Daten in einem praktischen Format zurückgegeben.
Die Verwendung einer API zum Scrapen von Daten mag teuer erscheinen, kann Ihnen aber auf lange Sicht Zeit und Geld sparen. Der Aufbau eines benutzerdefinierten Scrapers scheint zunächst Kosten zu sparen, doch die Verwaltung der Proxy-Rotation, des HTML-Parsings und der konsistenten Extraktion kann schwierig sein. Darüber hinaus könnten zusätzliche Herausforderungen wie Captchas und Blockaden am Ende zu viele Ressourcen beanspruchen, die die anfänglichen Kosteneinsparungen durch die Verwendung Ihres eigenen Scrapers zunichtemachen. In diesen Fällen ist die Nutzung eines speziellen Scraping-Dienstes letztendlich oft effizienter und insgesamt weniger aufwändig.
Lassen Sie uns einen Google Shopping-Daten-Scraper in Python mit den Bibliotheken BeautifulSoup oder Selenium erstellen.
Scrapen Sie Google Shopping mit BeautifulSoup auf Python
In diesem Beispiel verwenden wir die BeautifulSoup-Bibliothek, um eine Seite zu analysieren. Es ist ziemlich einfach und eignet sich auch für Anfänger. Es verfügt jedoch nicht über Funktionen wie einen Headless-Browser oder eine Simulation des Benutzerverhaltens, etwa das Navigieren zu einer neuen Seite oder das Ausfüllen von Feldern.
Installieren Sie zunächst die BeautifulSoup-Bibliothek. Außerdem werden wir die zuvor installierte Requests-Bibliothek verwenden, um Abfragen auszuführen.
pip install bs4Erstellen Sie nun eine neue Datei mit der Erweiterung *.py und korrumpieren Sie die darin enthaltenen Bibliotheken:
from bs4 import BeautifulSoup
import requestsFügen Sie einen Link auf Ihrer Google Shopping-Seite ein:
url="https://www.google.com/search?q=books&tbm=shop"Sie können Variablen verwenden, um die benötigten Links zu erstellen. In diesem Fall müssen Sie eine Datei mit Schlüsselwörtern angeben oder diese in eine Variable einfügen und dann alle Schlüsselwörter einzeln durchgehen.
Geben Sie nun Header an, um das Risiko einer Blockierung zu verringern. Gehen Sie am besten zu Ihrem eigenen Browser und verwenden Sie Ihren User Agent.
headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1',
'Accept-Language': 'en-US,en;q=0.5'
}Jetzt müssen Sie nur noch die Abfrage ausführen und die resultierenden Daten verarbeiten. Um den HTML-Code der Seite zu erhalten, verwenden wir die Get-Anfrage:
response = requests.get(url, headers=headers)Wenn die Anfrage nun erfolgreich ist, erstellen wir ein BeautifulSoup-Objekt und analysieren die Seite:
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')Um alle Elemente einzeln durchzugehen, suchen wir zunächst alle.
content_elements = soup.find_all('div', class_='sh-dgr__content')Nun verwenden wir for, um alle gefundenen Elemente durchzugehen:
for content_element in content_elements:Geben wir in der Schleife die CSS-Selektoren der Elemente an, die wir für jedes Produkt finden müssen. Beginnen wir mit dem Link zum Produkt:
link = content_element.find('a')('href')
print("Link:", link)Jetzt holen wir uns alle Header und zeigen sie auch auf dem Bildschirm an:
title = content_element.find('h3').get_text()
print("Title:", title)Jetzt bekommen wir die Bewertungen. Da wir jedoch nicht die Klassennamen verwenden können, verwenden wir die Ordnungszahl des erforderlichen Elements:
rating_element = content_element.find_all('span')(1)
rating = rating_element.get_text()
print("Rating:", rating)Abschließend erhalten wir eine Beschreibung des Produkts. Es ist die nächste Spanne nach der Bewertung. Das heißt, es ist sein Geschwister.
description_element = rating_element.find_next_sibling('span')
description = description_element.get_text()
print("Description:", description)Wenn Sie mehr über CSS-Selektoren erfahren möchten, können Sie unseren Spickzettel nutzen und etwas Neues über deren Verwendung erfahren.
Vollständiger Code:
from bs4 import BeautifulSoup
import requests
url="https://www.google.com/search?q=books&tbm=shop"
headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1',
'Accept-Language': 'en-US,en;q=0.5'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
content_elements = soup.find_all('div', class_='sh-dgr__content')
for content_element in content_elements:
link = content_element.find('a')('href')
print("Link:", link)
title = content_element.find('h3').get_text()
print("Title:", title)
rating_element = content_element.find_all('span')(1)
rating = rating_element.get_text()
print("Rating:", rating)
description_element = rating_element.find_next_sibling('span')
description = description_element.get_text()
print("Description:", description)
print("\n")Wenn Sie mit der Möglichkeit der Datenausgabe an die Konsole nicht zufrieden sind, können Sie Pandas oder andere Tools verwenden, um die Daten im benötigten Format zu speichern.
Scrapen Sie die Google Shopping-Ergebnisse mit Selenium
Das letzte Tool in diesem Artikel ist die Selenium-Bibliothek. Es gibt Analoga in fast allen Programmiersprachen. Darüber hinaus verfügt es über eine sehr aktive Community und eine umfangreiche Dokumentation. Selenium verwendet einen Webtreiber, um Benutzerverhalten zu simulieren und Headless-Browser zu steuern.
Zuvor haben wir darüber geschrieben, wie man Selenium installiert und was Sie sonst noch verwenden müssen. Wir haben auch Beispiele für Scraping in Python mit Selenium gegeben: „Web Scraping mit Selenium Python“.
Um das folgende Skript auszuführen, benötigen wir einen Webdriver. Wir werden Chrome verwenden. Es ist unbedingt darauf zu achten, dass die Version des Webtreibers mit der Version des installierten Browsers übereinstimmt.
Jetzt erstellen wir eine neue *.py-Datei und importieren die notwendigen Pakete:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import ByGeben Sie nun den Pfad zum zuvor heruntergeladenen Webdriver und einen Link zur Google Shopping-Seite an:
chromedriver_path="C://chromedriver.exe"
url="https://www.google.com/search?q=books&tbm=shop"Erstellen Sie einen Webdriver-Handler:
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service)Schließlich können wir den Webbrowser starten und zur Zielseite navigieren.
driver.get(url)Führen Sie die Seitenanalyse mit dem By-Modul und seinen verschiedenen Elementen durch. Wir verwenden dieselben Tags wie beim letzten Mal, verwenden jedoch andere Funktionen des Moduls, um Daten zu sammeln:
content_elements = driver.find_elements(By.CLASS_NAME, 'sh-dgr__content')
for content_element in content_elements:
link_element = content_element.find_element(By.TAG_NAME, 'a')
link = link_element.get_attribute('href')
print("Link:", link)
title_element = content_element.find_element(By.TAG_NAME, 'h3')
title = title_element.text
print("Title:", title)
rating_element = content_element.find_elements(By.TAG_NAME, 'span')(1)
rating = rating_element.text
print("Rating:", rating)
description_element = rating_element.find_element(By.XPATH, './following-sibling::span')
description = description_element.text
print("Description:", description)
print("\n")Schließen Sie am Ende den Webdriver, um die Ausführung des Skripts abzuschließen.
driver.quit()Vollständiger Code:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
chromedriver_path="C://chromedriver.exe"
url="https://www.google.com/search?q=books&tbm=shop"
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service)
driver.get(url)
content_elements = driver.find_elements(By.CLASS_NAME, 'sh-dgr__content')
for content_element in content_elements:
link_element = content_element.find_element(By.TAG_NAME, 'a')
link = link_element.get_attribute('href')
print("Link:", link)
title_element = content_element.find_element(By.TAG_NAME, 'h3')
title = title_element.text
print("Title:", title)
rating_element = content_element.find_elements(By.TAG_NAME, 'span')(1)
rating = rating_element.text
print("Rating:", rating)
description_element = rating_element.find_element(By.XPATH, './following-sibling::span')
description = description_element.text
print("Description:", description)
print("\n")
driver.quit()
Wie Sie sehen, ist die Verwendung von Selenium zum Scrapen der Google Shopping-Seite einfach. Gleichzeitig können Sie mit Selenium das Verhalten eines echten Benutzers nachahmen, verschiedene Elemente auf der Seite steuern und JavaScript laden.
Fazit und Erkenntnisse
In diesem Tutorial haben wir uns verschiedene Möglichkeiten zum Scraping von Google Shopping-Suchergebnissen angesehen, die beide Programmierkenntnisse erfordern und auch nicht. Wenn Sie mit Programmierung vertraut sind, aber nicht bereit sind, komplexe Website-Strukturen zu analysieren oder Möglichkeiten zu entwickeln, sich vor Captchas oder Blockierungen zu schützen, ist die Verwendung der Google Shopping API möglicherweise besser geeignet.
