TL;DR: Google Maps Python Scraper
Für diejenigen, die es eilig haben, finden Sie hier den vollständigen Code für den Scraper, den wir in diesem Artikel erstellen werden. Dieser Code verwendet Selenium mit ScraperAPI im Proxy-Modus, um Geschäftsdaten aus den Suchergebnissen von Google Maps zu extrahieren:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
import csv
# Selenium Wire configuration to use a proxy
api_key = 'YOUR_SCRAPERAPI_KEY'
seleniumwire_options = {
'proxy': {
'http': f'http://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001',
'verify_ssl': False,
},
}
chrome_options = Options()
chrome_options.add_argument("--headless=new")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options, seleniumwire_options=seleniumwire_options)
# URL of the web page
url = "https://www.google.com/maps/search/pizza+in+new+york"
# Open the web page
driver.get(url)
try:
button = driver.find_element(By.XPATH,'//*(@id="yDmH0d")/c-wiz/div/div/div/div(2)/div(1)/div(3)/div(1)/div(1)/form(2)/div/div/button/div(3)')
button.click()
print("Accepted cookies.")
except:
print("No cookies consent required.")
# Set an implicit wait time to wait for JavaScript to render
driver.implicitly_wait(30) # Wait for max 30 seconds
# Scrolls within a specific panel by simulating Page Down key presses.
def scroll_panel_down(driver, panel_xpath, presses, pause_time):
# Find the panel element
panel_element = driver.find_element(By.XPATH, panel_xpath)
# Ensure the panel is in focus by clicking on it
actions = ActionChains(driver)
actions.move_to_element(panel_element).click().perform()
# Send the Page Down key to the panel element
for _ in range(presses):
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(pause_time)
panel_xpath = '//*(@id="QA0Szd")/div/div/div(1)/div(2)/div'
scroll_panel_down(driver, panel_xpath, presses=5, pause_time=1)
# Get the page HTML source
page_source = driver.page_source
# Parse the HTML using BeautifulSoup
soup = BeautifulSoup(page_source, "lxml")
# Find all elements using its class
titles = soup.find_all(class_="hfpxzc")
ratings = soup.find_all(class_='MW4etd')
reviews = soup.find_all(class_='UY7F9')
services = soup.find_all(class_='Ahnjwc')
# Print the number of places found
elements_count = len(titles)
print(f"Number of places found: {elements_count}")
# Specify the CSV file path
csv_file_path = 'maps_pizza_places.csv'
# Open a CSV file in write mode
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
# Create a CSV writer object
csv_writer = csv.writer(csv_file)
# Write the header row (optional, adjust according to your data)
csv_writer.writerow(('Place', 'Rating', 'Reviews', 'Service options'))
# Write the extracted data
for i, title in enumerate(titles):
title = title.get('aria-label')
rating = (ratings(i).text + "/5") if i
Notiz: Ersetzen 'YOUR_SCRAPERAPI_KEY' mit Ihrem eindeutigen API-Schlüssel aus Ihrem ScraperAPI-Dashboard. Sie haben noch kein Konto? Melden Sie sich noch heute an und erhalten Sie 5.000 kostenlose Scraping-Credits, um in wenigen Minuten mit dem Scraping von Daten zu beginnen!
Dieser Code entfernt Firmennamen, Bewertungen, Bewertungszahlen und Serviceoptionen für Pizzerien in New York aus Google Maps und speichert die Daten in einer CSV-Datei.
Scraping von Google Maps mit Python und Selenium (Headless-Ansatz)
Eine Möglichkeit, Google Maps-Daten abzurufen, ist die offizielle API, diese Methode hat jedoch mehrere Nachteile. Das Erhalten des API-Schlüssels ist komplex, da Sie ein Google Cloud-Projekt einrichten müssen. Zu den Einschränkungen gehören Datenzugriffsbeschränkungen, Abfragebeschränkungen und potenzielle Kosten im Zusammenhang mit der Nutzung bei hohem Datenvolumen.
Die Entwicklung eines eigenen Google Maps-Scraping-Tools könnte eine große Herausforderung sein, wenn Sie nicht über ein paar Jahre Erfahrung verfügen. Sie müssen auf zahlreiche Herausforderungen von Google vorbereitet sein, darunter IP-Schutz (Proxys), Cookies und Sitzungen, Browseremulation, Website-Updates usw.
Glücklicherweise gibt es einige gute Tools von Drittanbietern, die wir verwenden können. Wir verwenden Selenium, um wie ein echter Benutzer mit Google Maps zu interagieren. Unser Ziel sind Google Maps-Ergebnisse für Restaurants in New York, die Pizza servieren. Um die Proxy-Verwaltung und das JavaScript-Rendering zu übernehmen und die Anti-Scraping-Mechanismen von Google Maps zu umgehen, integrieren wir ScraperAPI in unser Setup.
Anforderungen
Um diesem Tutorial zu folgen, stellen Sie sicher, dass die folgenden Tools auf Ihrem Computer installiert sind:
- Python: Laden Sie die neueste Version von Python von der offiziellen Website herunter und installieren Sie sie.
- Google Chrome-Browser.
- Bibliotheken: Installieren Sie die erforderlichen Python-Bibliotheken mit pip:
pip install selenium selenium-wire webdriver-manager beautifulsoup4 lxml
Dies installiert:
- Selenium: Wird zur Automatisierung der Webbrowser-Interaktion mit Python verwendet
- Selenium Wire: Eine leistungsstarke Erweiterung für Python Selenium, die Ihnen Zugriff auf die zugrunde liegenden Anforderungen Ihres Selenium-Browsers ermöglicht. Nützlich für die Proxy-Integration.
- Webdriver Manager: Vereinfacht die Verwaltung von Binärtreibern für verschiedene Browser.
- BeautifulSoup: Analysiert HTML- und XML-Daten.
- LXML: Eine XML-Parsing-Bibliothek, die häufig zusammen mit BeautifulSoup verwendet wird, um Geschwindigkeit und Leistung zu verbessern.
Sie benötigen außerdem ein ScraperAPI-Konto. Wenn Sie noch keinen haben, können Sie sich hier anmelden, um einen API-Schlüssel zur Authentifizierung Ihrer Anfragen zu erhalten.
Übersicht über das Google Maps-Layout
Bevor wir mit dem Scraping beginnen, müssen wir verstehen, wo und in welcher Form die Daten vorliegen. In diesem Artikel werden wir versuchen, nach „Pizza in New York“ zu suchen.
Wenn Sie auf einen Eintrag oder die Karte klicken, gelangen Sie zur Hauptoberfläche von Google Maps. Hier sehen Sie, dass alle Suchergebnisse im linken Bereich aufgelistet sind und auf der rechten Seite detailliertere Karteninformationen angezeigt werden.
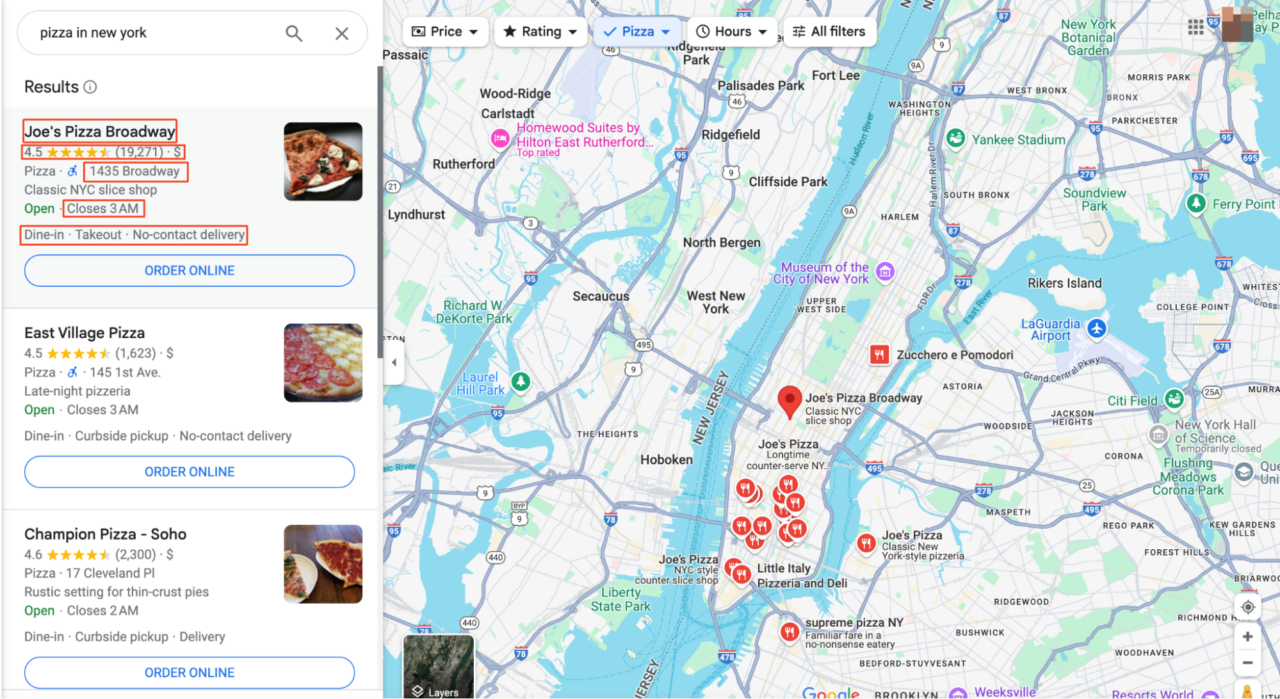
Um herauszufinden, welche Teile der Seite die von uns benötigten Informationen enthalten, öffnen Sie DevTools (F12oder klicken Sie mit der rechten Maustaste auf die Seite und wählen Sie „Überprüfen“). Mit den DevTools können Sie mit der Maus über verschiedene Teile der Webseite fahren, um die entsprechenden HTML-Elemente anzuzeigen.
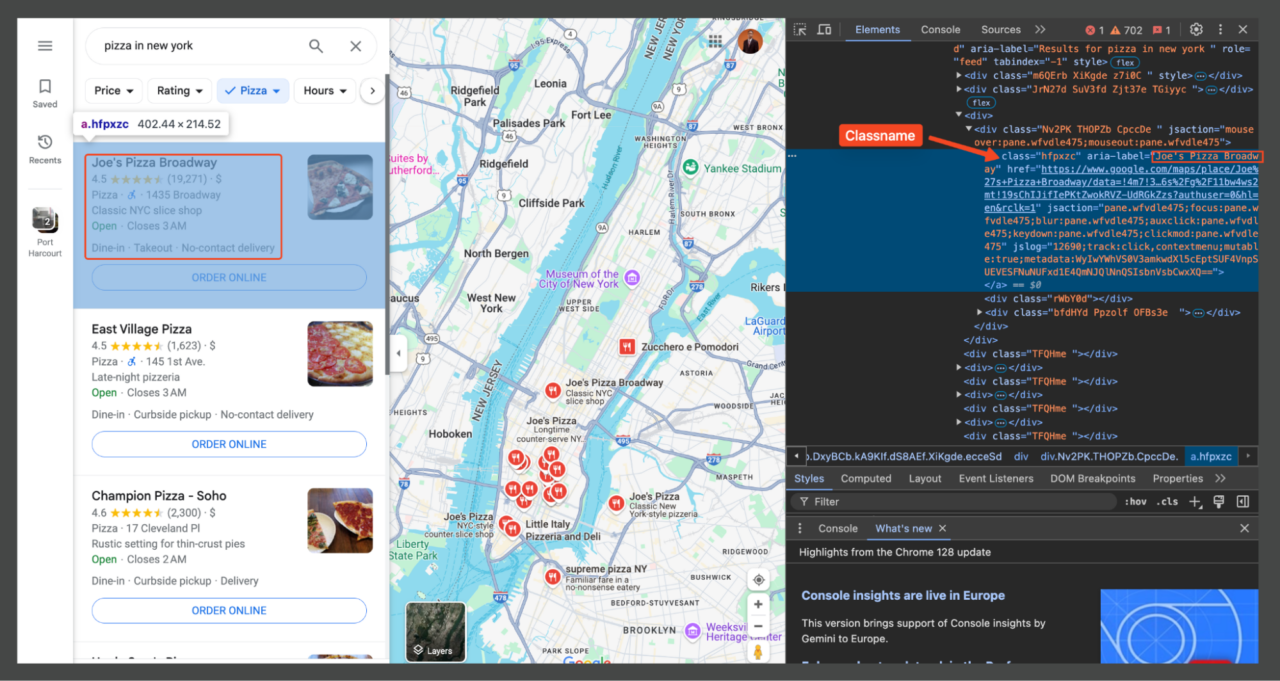
Jedes Element auf der Seite kann mithilfe von CSS-Selektoren gezielt angesprochen werden. Beispielsweise werden die Ortstitel (z. B. „Joe's Pizza“) normalerweise in ein Element mit einer bestimmten Klasse eingeschlossen (hfpxzc). Anschließend verwenden wir Beautiful Soup, um alle Elemente dieser Klasse zu finden.
Darüber hinaus verwendet Google Maps keine herkömmliche Paginierung. Stattdessen werden kontinuierlich weitere Ergebnisse geladen, wenn Sie in der Liste nach unten scrollen. Nachdem wir dieses Layout und die relevanten Selektoren verstanden haben, können wir nun mit dem Schreiben unseres Scraping-Skripts fortfahren, das auf diese spezifischen Elemente abzielt, um die benötigten Informationen zu extrahieren.
Schritt 1: Einrichten Ihrer Umgebung
Zunächst bereiten wir unsere Python-Umgebung mit den notwendigen Bibliotheken für das Web-Scraping von Google Maps vor. Öffnen Sie die Projektdatei in Ihrem jeweiligen Code-Editor und importieren Sie die oben installierten Bibliotheken.
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
import csv
Hier verwenden wir:
seleniumwireanstelle von regulärem Selenium, um eine einfache Proxy-Integration zu ermöglichen- Der
webdriver_managerDas Paket lädt automatisch die entsprechende ChromeDriver-Version herunter und verwaltet sie für uns - Der
By,ActionChainsUndKeysImporte aus Selenium helfen uns bei der Interaktion mit der Seite, z. B. beim Scrollen und Klicken auf Elemente - Zum Schluss importieren wir
timezum Hinzufügen von Verzögerungen undcsvzum Speichern unserer Scraped-Daten.
Schritt 2: Selenium und ScraperAPI konfigurieren
Als Nächstes konfigurieren wir Selenium für die Zusammenarbeit mit ScraperAPI, einem leistungsstarken Web-Scraping-Dienst, der uns hilft, die strengen Anti-Scraping-Mechanismen von Google zu umgehen, indem er Proxys rotiert, CAPTCHAs verarbeitet, passende Header und Cookies generiert und mehr.
api_key = 'YOUR_SCRAPERAPI_KEY'
seleniumwire_options = {
'proxy': {
'http': f'http://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001',
'verify_ssl': False,
},
}
chrome_options = Options()
chrome_options.add_argument("--headless=new")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options, seleniumwire_options=seleniumwire_options)
Notiz: Erstellen Sie ein kostenloses ScraperAPI-Konto und ersetzen Sie es 'YOUR_SCRAPERAPI_KEY' mit Ihrem API-Schlüssel.
Hier bauen wir auf selenium-wire um ScraperAPI als unseren Proxy zu verwenden. Um Selenium mit ScraperAPI korrekt zu verwenden, sollten Sie unseren Proxy-Modus wie jeden anderen Proxy verwenden. Der username denn der Proxy ist scraperapi und der password ist Ihr API-Schlüssel.
Um zusätzliche Funktionen bei der Verwendung der API im Proxy-Modus zu ermöglichen, können Sie Parameter an die API übergeben, indem Sie sie durch Punkte getrennt zum Benutzernamen hinzufügen. Die Proxy-URL enthält Parameter wie render=truewodurch sichergestellt wird, dass JavaScript ausgeführt wird, und country_code=us um unsere Anfragen geografisch auf die Vereinigten Staaten auszurichten.
Der Headless-Modus ermöglicht die Ausführung unseres Skripts, ohne ein sichtbares Browserfenster zu öffnen, wodurch die Leistung verbessert und der Ressourcenverbrauch reduziert wird. Wir verwenden ChromeDriverManager auch, um Chrome-Treiberinstallationen und -Updates automatisch zu verwalten.
Ressource: Weitere Informationen finden Sie in unserer Proxy-Port-Dokumentation.
Schritt 3: Zugriff auf Google Maps
Jetzt weisen wir unseren Browser an, zur Google Maps-Seite für unseren gewünschten Suchbegriff zu navigieren, in diesem Beispiel „Pizza in New York“. Diese Aktion lädt die Seite, als ob ein Benutzer die Suchanfrage manuell in die Google-Suchleiste eingegeben hätte.
url = "https://www.google.com/maps/search/pizza+in+new+york"
driver.get(url)
Schritt 4: Umgehen des Cookies-Popups
Google Maps zeigt möglicherweise ein Popup-Fenster mit der Zustimmung zu Cookies an, wenn Selenium versucht, den Link zu öffnen.
Um dies zu umgehen, müssen wir dieses Popup programmgesteuert akzeptieren.
try:
button = driver.find_element(By.XPATH, '//*(@id="yDmH0d")/c-wiz/div/div/div/div(2)/div(1)/div(3)/div(1)/div(1)/form(2)/div/div/button/div(3)')
button.click()
print("Accepted cookies.")
except:
print("No cookies consent required.")
Wir werden versuchen, das „Akzeptiere alles”-Schaltfläche im Cookie-Zustimmungs-Popup. Wir verwenden einen Try-Except-Block, da das Popup möglicherweise nicht immer angezeigt wird. Innerhalb des Try-Blocks driver.find_element(By.XPATH, '...') sucht mithilfe seines XPath nach dem Schaltflächenelement. Wenn gefunden, button.click() simuliert einen Klick auf die Schaltfläche. Wenn das Element nicht gefunden wird (was bedeutet, dass das Popup nicht vorhanden ist), wird der Ausnahmeblock ausgeführt und eine Meldung an die Konsole ausgegeben.
Notiz: Die Verwendung von ScraperAPI sollte verhindern, dass CAPTCHAs-Herausforderungen angezeigt werden. Es empfiehlt sich jedoch, dies für alle Fälle vorzusehen.
Schritt 5: Scrollen und weitere Ergebnisse laden
Google Maps lädt dynamisch weitere Ergebnisse, wenn Sie auf der Seite nach unten scrollen. Wir simulieren dieses Scrollverhalten, um mehr Daten zu laden.
def scroll_panel_down(driver, panel_xpath, presses, pause_time):
panel_element = driver.find_element(By.XPATH, panel_xpath)
actions = ActionChains(driver)
actions.move_to_element(panel_element).click().perform()
for _ in range(presses):
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(pause_time)
panel_xpath = '//*(@id="QA0Szd")/div/div/div(1)/div(2)/div'
scroll_panel_down(driver, panel_xpath, presses=5, pause_time=1)
Hier, panel_xpath identifiziert den Bereich, der die Suchergebnisse enthält. Der scroll_panel_down() Die Funktion ist so definiert, dass eine Reihe von Bild-nach-unten-Tastendrücken an dieses Bedienfeld gesendet wird, wodurch es gezwungen wird, zusätzliche Ergebnisse zu laden. Die Parameter presses=5 Und pause_time=1 Geben Sie an, wie oft die Taste gedrückt werden soll und wie lange zwischen jedem Drücken gewartet werden soll. Diese Methode stellt sicher, dass wir auf alle verfügbaren Daten zugreifen können, indem wir die Scroll-Aktion eines Benutzers simulieren.
Schritt 6: Daten mit BeautifulSoup analysieren
Nachdem die Ergebnisse geladen sind, besteht der nächste Schritt darin, den HTML-Code zu analysieren und relevante Informationen wie Firmennamen, Bewertungen, Rezensionen und Serviceoptionen mit BeautifulSoup zu extrahieren.
page_source = driver.page_source
soup = BeautifulSoup(page_source, "lxml")
titles = soup.find_all(class_="hfpxzc")
ratings = soup.find_all(class_='MW4etd')
reviews = soup.find_all(class_='UY7F9')
services = soup.find_all(class_='Ahnjwc')
Wir holen uns zunächst die gesamte Seitenquelle driver.page_source. Dadurch erhalten wir den HTML-Inhalt der Seite, nachdem alle unsere Interaktionen (Scrollen usw.) durchgeführt wurden. Anschließend erstellen wir ein BeautifulSoup-Objekt, übergeben die Seitenquelle und geben „lxml” um den Inhalt zu analysieren.
Als nächstes verwenden wir BeautifulSoup's find_all Methode, um alle Elemente mit bestimmten Klassennamen zu finden, die den Daten entsprechen, die wir extrahieren möchten.
Schritt 7: Daten in einer CSV-Datei speichern
Schließlich speichern wir die extrahierten Daten mithilfe der Dateiverarbeitungsfunktionen von Python in einer CSV-Datei.
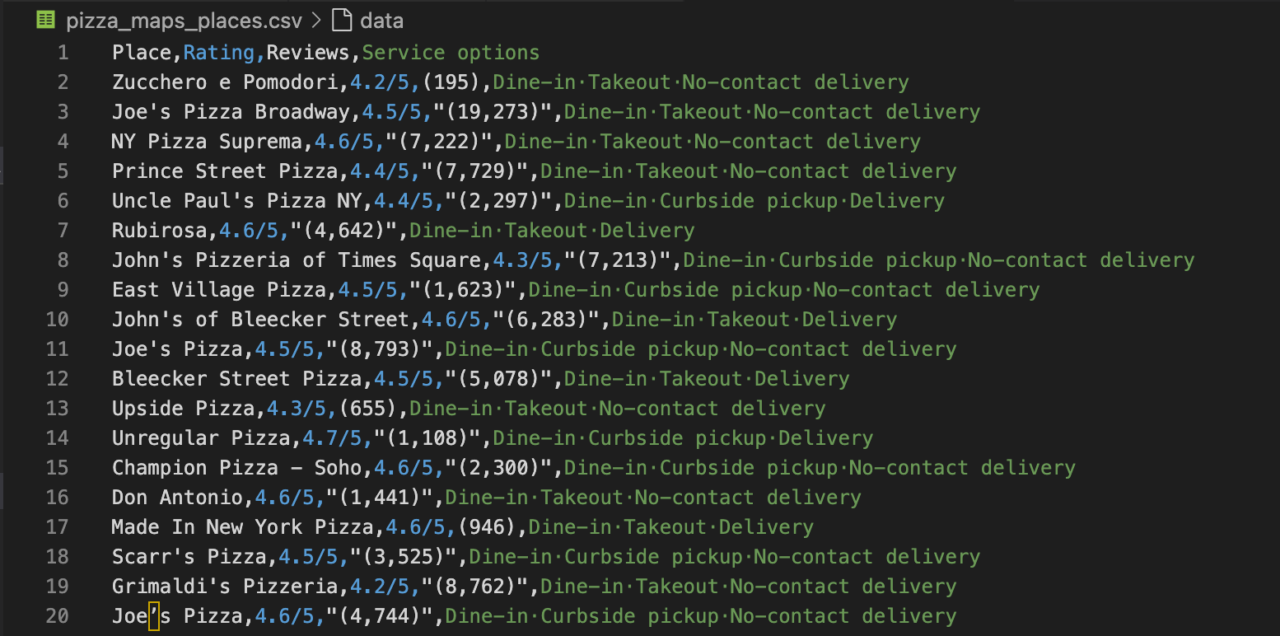
csv_file_path = 'pizza_maps_places.csv'
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(('Place', 'Rating', 'Reviews', 'Service options'))
for i, title in enumerate(titles):
title = title.get('aria-label')
rating = (ratings(i).text + "/5") if i
In dieser Phase geht es in der Regel darum, die Daten zu speichern und eine Datenbereinigung durchzuführen. Dies kann beispielsweise das Entfernen unnötiger Zeichen, das Korrigieren von Datenfehlern oder das Eliminieren leerer Zeichenfolgen umfassen.
- Wir öffnen eine Datei mit dem Namen '
pizza_maps_places.csv' im Schreibmodus, um sicherzustellen, dass wir verwendenutf-8Codierung zur Verarbeitung von Sonderzeichen. - Dann durchlaufen wir unsere Scraped-Daten. Für jedes Restaurant extrahieren wir den Titel aus dem „
aria-label' Attribut des Titelelements. - Wir erhalten den Bewertungstext und hängen „
/5” dazu oder verwenden Sie 'N/A', wenn keine Bewertung gefunden wird. - In ähnlicher Weise extrahieren wir die Anzahl der Bewertungen und die Serviceoptionen, indem wir „
N/A' als Ersatz, wenn die Daten fehlen. - Anschließend schreiben wir die Daten jedes Restaurants als Zeile in unsere CSV-Datei.
- Nach der Schleife drucken wir eine Bestätigungsmeldung mit dem Dateipfad.
- Zum Schluss rufen wir an
driver.quit()um den Browser zu schließen und die Selenium-Sitzung zu beenden, wodurch Systemressourcen freigegeben werden.
Vollständiger Google Maps Scraper mit Selenium
Hier ist unser vollständiges Skript zum Durchsuchen von Google Maps, um Pizzerien in New York zu finden.
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
import csv
# Selenium Wire configuration to use a proxy
api_key = 'YOUR_SCRAPERAPI_KEY'
seleniumwire_options = {
'proxy': {
'http': f'http://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001',
'verify_ssl': False,
},
}
chrome_options = Options()
chrome_options.add_argument("--headless=new")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options, seleniumwire_options=seleniumwire_options)
# URL of the web page
url = "https://www.google.com/maps/search/pizza+in+new+york"
# Open the web page
driver.get(url)
try:
button = driver.find_element(By.XPATH,'//*(@id="yDmH0d")/c-wiz/div/div/div/div(2)/div(1)/div(3)/div(1)/div(1)/form(2)/div/div/button/div(3)')
button.click()
print("Accepted cookies.")
except:
print("No cookies consent required.")
# Set an implicit wait time to wait for JavaScript to render
driver.implicitly_wait(30) # Wait for max 30 seconds
# Scrolls within a specific panel by simulating Page Down key presses.
def scroll_panel_down(driver, panel_xpath, presses, pause_time):
# Find the panel element
panel_element = driver.find_element(By.XPATH, panel_xpath)
# Ensure the panel is in focus by clicking on it
actions = ActionChains(driver)
actions.move_to_element(panel_element).click().perform()
# Send the Page Down key to the panel element
for _ in range(presses):
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(pause_time)
panel_xpath = '//*(@id="QA0Szd")/div/div/div(1)/div(2)/div'
scroll_panel_down(driver, panel_xpath, presses=5, pause_time=1)
# Get the page HTML source
page_source = driver.page_source
# Parse the HTML using BeautifulSoup
soup = BeautifulSoup(page_source, "lxml")
# Find all elements using its class
titles = soup.find_all(class_="hfpxzc")
ratings = soup.find_all(class_='MW4etd')
reviews = soup.find_all(class_='UY7F9')
services = soup.find_all(class_='Ahnjwc')
# Print the number of places found
elements_count = len(titles)
print(f"Number of places found: {elements_count}")
# Specify the CSV file path
csv_file_path = 'maps_pizza_places.csv'
# Open a CSV file in write mode
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
# Create a CSV writer object
csv_writer = csv.writer(csv_file)
# Write the header row (optional, adjust according to your data)
csv_writer.writerow(('Place', 'Rating', 'Reviews', 'Service options'))
# Write the extracted data
for i, title in enumerate(titles):
title = title.get('aria-label')
rating = (ratings(i).text + "/5") if i
Nachdem Sie dieses Skript ausgeführt haben, zeigt Ihnen das Terminal an, ob es Cookies akzeptieren musste, wie viele Orte extrahiert wurden und wo die CSV-Datei mit allen extrahierten Informationen gespeichert wurde.
Möchten Sie dies mit Javascript tun? Sehen Sie sich unsere umfassende Anleitung zum Erstellen eines Google Maps Scrapers (in Javascript) an.
Scraping von Google Maps mit den Renderanweisungen von ScraperAPI (API-Ansatz)
In den vorherigen Abschnitten haben wir Selenium verwendet, um Daten aus Google Maps zu extrahieren. Obwohl diese Methode effektiv ist, erfordert sie die direkte Handhabung der Browser-Automatisierung, was komplex und ressourcenintensiv sein kann.
ScraperAPI bietet einen einfacheren Ansatz durch die Verwendung seines Render-Befehlssatzes. Dadurch können wir ähnliche Automatisierungsaufgaben wie das Scrollen durch eine endlos ladende Seite oder das Klicken auf Schaltflächen mit weniger Code und Aufwand ausführen.
So verwenden Sie die Renderanweisungen von ScraperAPI
Mit dem Render-Anweisungssatz können Sie über ScraperAPI Anweisungen an einen Headless-Browser senden und ihn anleiten, welche Aktionen beim Rendern der Seite ausgeführt werden sollen. Diese Anweisungen werden als JSON-Objekt in den API-Anfrageheadern gesendet.
So können wir ScraperAPI verwenden, um Google Maps nach Pizzerien in New York zu durchsuchen und so das zu reproduzieren, was wir mit Selenium erreicht haben, jedoch auf effizientere Weise
import requests
from bs4 import BeautifulSoup
import csv
api_key = 'YOUR_SCRAPERAPI_KEY'
url = 'https://api.scraperapi.com/'
# Define the target Google Maps URL
target_url = 'https://www.google.com/maps/search/pizza+in+new+york'
# div.VfPpkd-RLmnJb
# Construct the instruction set for Scraper API
headers = {
'x-sapi-api_key': api_key,
'x-sapi-render': 'true',
'x-sapi-instruction_set': '({"type": "loop", "for": 5, "instructions": ({"type": "scroll", "direction": "y", "value": "bottom" }, {"type": "click", "selector": {"type": "css", "value": "div.VfPpkd-RLmnJb"}}, { "type": "wait", "value": 5 }) })'
}
payload = {'url': target_url, 'country_code': 'us'}
response = requests.get(url, params=payload, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
# Find all listing elements using the class "Nv2PK"
listings = soup.find_all("div", class_="Nv2PK")
# Print the number of places found
elements_count = len(listings)
print(f"Number of places found: {elements_count}")
# Specify the CSV file path
csv_file_path = 'render_map_results.csv'
# Open a CSV file in write mode
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
# Create a CSV writer object
csv_writer = csv.writer(csv_file)
# Write the header row (optional, adjust according to your data)
csv_writer.writerow(('Place', 'Rating', 'Reviews', 'Service options'))
# Iterate through each listing and extract information
for listing in listings:
title_tag = listing.find("a", class_="hfpxzc")
rating_tag = listing.find("span", class_="MW4etd")
review_tag = listing.find("span", class_="UY7F9")
service_tags = listing.find_all("div", class_="Ahnjwc")
title = title_tag.get('aria-label') if title_tag else 'N/A'
rating = rating_tag.text if rating_tag else 'N/A'
reviews = review_tag.text if review_tag else 'N/A'
service_options = ', '.join((service.text for service in service_tags)) if service_tags else 'N/A'
# Write a row to the CSV file
csv_writer.writerow((title, rating, reviews, service_options))
print(f"Data has been saved to '{csv_file_path}'")
Notiz: Weitere Informationen zur Verwendung des Render-Befehlssatzes und weitere Beispiele finden Sie in der ScraperAPI-Dokumentation.
Der wichtigste Teil dieses Setups ist das Header-Wörterbuch, das Folgendes umfasst:
- Der
x-sapi-api_keyzur Authentifizierung mit ScraperAPI x-sapi-renderauf „true“ setzen, um das JavaScript-Rendering zu aktivieren, undx-sapi-instruction_setwelches die Anweisungen für den Browser enthält.
In unserem Befehlssatz klicken wir auf alle Elemente, die zum Selektor passen div.VfPpkd-RLmnJb wenn es existiert. Wir tun dies, um das Cookie-Popup zu umgehen. Anschließend scrollen wir mit einer Schleife fünfmal durch die Seite und warten zwischen den einzelnen Aktionen fünf Sekunden. Dieser Ansatz lädt effektiv mehr Ergebnisse dynamisch, ähnlich dem Scrollverhalten.
Fazit: Was können Sie mit Google Maps-Daten machen?
Dieser Artikel hat Sie durch das Scrapen von Daten aus Google Maps geführt und gezeigt, wie Sie wertvolle Informationen wie Firmennamen, Bewertungen, Rezensionen und Serviceoptionen sammeln können. Hier sind einige mögliche Anwendungen für Ihre neu erfassten Daten:
- Marktforschung
- Konkurrenzanalyse
- Analyse der Kundenstimmung
- Standortbasierte Serviceoptimierung
- Trenderkennung
Sind Sie es leid, ständig von Google blockiert zu werden? Testen Sie ScraperAPI kostenlos und erleben Sie müheloses und skalierbares Scraping in wenigen Minuten!
Weitere Informationen finden Sie in den folgenden Ressourcen:
