
In diesem Handbuch erfahren Sie, wie Sie:
- Einrichten und Installieren von Selenium für Web Scraping
- Führen Sie Aufgaben wie das Aufnehmen von Screenshots, Scrollen und Klicken auf Elemente aus.
- Verwenden Sie Selenium in Verbindung mit BeautifulSoup für eine effizientere Datenextraktion
- Bewältigen Sie das dynamische Laden von Inhalten und unendliches Scrollen
- Identifizieren und umgehen Sie Honeypots und andere Scraping-Hindernisse
- Implementieren Sie Proxys, um IP-Sperren zu vermeiden und die Scraping-Leistung zu verbessern
- Rendern Sie JavaScript-lastige Websites, ohne sich ausschließlich auf Selenium zu verlassen
Tauchen wir jetzt in das Selenium-Web-Scraping ein und schöpfen das volle Potenzial der automatisierten Datenerfassung aus!
Projektanforderungen
Bevor Sie mit Selenium Web Scraping beginnen, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Auf Ihrem Computer muss Python installiert sein (Version 3.10 oder neuer)
pip(Python-Paketinstallationsprogramm)- Ein Webtreiber für den von Ihnen gewählten Browser (z. B. ChromeDriver für Google Chrome)
Installation
Zuerst müssen Sie Selenium installieren. Sie können dies mit pip tun:
Laden Sie als Nächstes den Webtreiber für Ihren Browser herunter. Laden Sie beispielsweise ChromeDriver für Google Chrome herunter und stellen Sie sicher, dass er über den PATH Ihres Systems zugänglich ist.
Selenium importieren
Beginnen Sie mit dem Importieren der erforderlichen Module:
-
Webtreiber: Dies ist das Hauptmodul von Selenium, das alle WebDriver-Implementierungen bereitstellt. Es ermöglicht Ihnen, eine Browserinstanz zu initiieren und ihr Verhalten programmgesteuert zu steuern.
from selenium import webdriver -
Von: Der
ByMit der Klasse wird der Mechanismus zum Auffinden von Elementen innerhalb einer Webseite angegeben. Sie bietet verschiedene Methoden wie ID, Name, Klassenname, CSS-Selektor, XPath usw., die zum Auffinden von Elementen auf einer Webseite entscheidend sind.from selenium.webdriver.common.by import By -
Schlüssel: Der
KeysDie Klasse stellt spezielle Tasten bereit, die an Elemente gesendet werden können, wie etwa die Eingabetaste, Pfeiltasten, Escape usw. Sie ist nützlich für die Simulation von Tastaturinteraktionen in automatisierten Tests oder beim Web Scraping.from selenium.webdriver.common.keys import Keys -
WebDriverWait: Diese Klasse ist Teil des Support-UI-Moduls von Selenium (
selenium.webdriver.support.ui) und ermöglicht es Ihnen, auf das Eintreten einer bestimmten Bedingung zu warten, bevor Sie mit dem Code fortfahren. Es hilft beim Umgang mit dynamischen Webelementen, deren Laden möglicherweise einige Zeit in Anspruch nimmt.from selenium.webdriver.support.ui import WebDriverWait -
erwartete_Bedingungen als EC: Der
expected_conditionsModul innerhalb von Selenium bietet eine Reihe vordefinierter Bedingungen, dieWebDriverWaitverwenden können. Zu diesen Bedingungen gehört die Überprüfung der Anwesenheit, Sichtbarkeit, des anklickbaren Status usw. eines Elements.from selenium.webdriver.support import expected_conditions as EC
Diese Importe sind für die Einrichtung eines Selenium-Automatisierungsskripts unerlässlich. Sie bieten Zugriff auf die erforderlichen Klassen und Methoden, um mit Webelementen zu interagieren, auf Bedingungen zu warten und Benutzeraktionen auf Webseiten effektiv zu simulieren.
Einrichten des Web-Treibers
Initialisieren Sie den Webtreiber für Ihren Browser und konfigurieren Sie bei Bedarf Optionen:
chrome_options = webdriver.ChromeOptions()
# Add any desired options here, for example, headless mode:
# chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
Mit diesem Setup können Sie das Verhalten des Chrome-Browsers anpassen durch chrome_options.
Sie können den Browser beispielsweise im Headless-Modus ausführen, indem Sie die --headless Option. Das bedeutet, dass alles im Hintergrund geschieht und Sie das Browserfenster nicht aufpoppen sehen.
Und nun fangen wir mit dem Schaben an!
TL;DR: Grundlagen des Selenium Scraping
Hier ist ein kurzer Spickzettel, der Ihnen den Einstieg in das Selenium-Web-Scraping erleichtert. Hier finden Sie wichtige Schritte und Codeausschnitte für gängige Aufgaben, sodass Sie ganz einfach direkt mit dem Scraping beginnen können.
Besuch einer Site
Um eine Website zu öffnen, verwenden Sie das get() Funktion:
driver.get("https://www.google.com")
Einen Screenshot machen
Um einen Screenshot der aktuellen Seite zu erstellen, verwenden Sie das save_screenshot() Funktion:
driver.save_screenshot('screenshot.png')
Scrollen auf der Seite
Um auf der Seite nach unten zu scrollen, verwenden Sie die execute_script() Funktion zum Herunterscrollen auf die gesamte Seitenhöhe:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
Klicken auf ein Element
Um auf ein Element (z. B. eine Schaltfläche) zu klicken, verwenden Sie die find_element() Funktion, um das Element zu lokalisieren, und rufen Sie dann die click() Funktion auf dem Element:
button = driver.find_element(By.ID, "button_id")
button.click()
Warten auf ein Element
So warten Sie, bis ein Element sichtbar wird:
element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.ID, "element_id"))
)
Umgang mit unendlichem Scrollen
Um mit unendlichem Scrollen umzugehen, können Sie wiederholt zum Ende der Seite scrollen, bis kein neuer Inhalt mehr geladen wird:
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # Wait for new content to load
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
Kombination von Selenium mit BeautifulSoup
Für eine effizientere Datenextraktion können Sie BeautifulSoup zusammen mit Selenium verwenden:
from bs4 import BeautifulSoup
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Now you can use BeautifulSoup to parse the HTML content like normal
Wenn Sie diese Schritte befolgen, können Sie die meisten gängigen Web-Scraping-Aufgaben mit Selenium erledigen.
Wenn Sie tiefer in das Web Scraping mit Selenium eintauchen möchten, lesen Sie weiter!
So verwenden Sie Selenium für Web Scraping
Schritt 1: ChromeOptions konfigurieren
Um die Interaktion von Selenium mit dem Chrome-Browser anzupassen, konfigurieren Sie zunächst ChromeOptions:
chrome_options = webdriver.ChromeOptions()
Dies richtet chrome_options mit webdriver.ChromeOptions()sodass wir das Verhalten von Chrome anpassen können, wenn es von Selenium gesteuert wird.
Optional: ChromeOptions anpassen
Sie können ChromeOptions weiter anpassen. Fügen Sie beispielsweise die folgende Zeile hinzu, um den Headless-Modus zu aktivieren:
chrome_options.add_argument("--headless")
Headless-Modus aktivieren (--headless) führt Chrome ohne sichtbare Benutzeroberfläche aus, was perfekt für automatisierte Aufgaben ist, bei denen Sie den Browser nicht sehen müssen.
Schritt 2: WebDriver mit ChromeOptions initialisieren
Als nächstes initialisieren Sie den Chrome WebDriver mit dem konfigurierten ChromeOptions:
driver = webdriver.Chrome(options=chrome_options)
Diese Zeile bereitet Selenium darauf vor, Chrome basierend auf den angegebenen Optionen zu steuern und schafft so die Voraussetzung für automatisierte Interaktionen mit Webseiten.
Schritt 3: Zu einer Website navigieren
Um den WebDriver zur gewünschten URL umzuleiten, verwenden Sie den get() Funktion. Dieser Befehl weist Selenium an, die Webseite zu öffnen und zu laden, sodass Sie mit der Site interagieren können.
driver.get("https://google.com/")
Wenn Sie mit Ihren Interaktionen fertig sind, verwenden Sie die quit() Methode, um den Browser zu schließen und die WebDriver-Sitzung zu beenden.
In Summe, get() lädt die angegebene Webseite, während quit() schließt den Browser und beendet die Sitzung, wodurch ein sauberer Abschluss Ihrer Scraping-Aufgaben gewährleistet wird.
Schritt 4: Einen Screenshot machen
Um einen Screenshot der aktuellen Seite zu erstellen, verwenden Sie das save_screenshot() Funktion. Dies kann zum Debuggen oder zum Speichern des Status einer Seite nützlich sein.
driver.save_screenshot('screenshot.png')
Dadurch wird ein Screenshot der Seite erstellt und in einem Bild namens Screenshot.png.
Schritt 5: Scrollen der Seite
Scrollen ist wichtig für die Interaktion mit dynamischen Websites, die beim Scrollen zusätzliche Inhalte laden. Selenium bietet die execute_script() Funktion zum Ausführen von JavaScript-Code im Browserkontext, sodass Sie das Bildlaufverhalten der Seite steuern können.
Zum Ende der Seite scrollen
Um bis zum Ende der Seite zu scrollen, können Sie das folgende Skript verwenden. Dies ist insbesondere zum Laden zusätzlicher Inhalte auf dynamischen Websites nützlich.
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
Dieser JavaScript-Code scrollt das Browserfenster auf die Höhe des Dokumenttexts und bewegt es effektiv zum unteren Seitenende.
Zu einem bestimmten Element scrollen
Wenn Sie zu einem bestimmten Element auf der Seite scrollen möchten, können Sie das scrollIntoView() Methode. Dies ist nützlich bei der Interaktion mit Elementen, die im aktuellen Ansichtsfenster nicht sichtbar sind.
element = driver.find_element(By.ID, "element_id")
driver.execute_script("arguments(0).scrollIntoView(true);", element)
Dieser Code findet ein Element anhand seiner ID und scrollt die Seite, bis das Element angezeigt wird.
Umgang mit unendlichem Scrollen
Für Seiten, die beim Scrollen kontinuierlich Inhalte laden, können Sie eine Schleife implementieren, um wiederholt nach unten zu scrollen, bis keine neuen Inhalte mehr geladen werden. Hier ist ein Beispiel für den Umgang mit unendlichem Scrollen:
import time
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # Wait for new content to load
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
Diese Schleife scrollt zum unteren Ende der Seite, wartet, bis neuer Inhalt geladen wird, und prüft, ob die Scrollhöhe zugenommen hat. Wenn die Höhe gleich bleibt, wird die Schleife beendet, was bedeutet, dass kein weiterer Inhalt geladen wird.
Horizontales Scrollen
In manchen Fällen müssen Sie möglicherweise horizontal scrollen, beispielsweise um mit Elementen in einer breiten Tabelle zu interagieren. Verwenden Sie das folgende Skript, um horizontal zu scrollen:
driver.execute_script("window.scrollBy(1000, 0);")
Dieser Code scrollt die Seite 1000 Pixel nach rechts. Passen Sie den Wert je nach Anwendungsfall an.
Diese Scroll-Techniken mit Selenium stellen sicher, dass alle erforderlichen Inhalte geladen und für die Interaktion oder das Scraping zugänglich sind. Diese Methoden sind für die effektive Navigation und das Extrahieren von Daten aus dynamischen Websites unerlässlich.
Schritt 6: Mit Elementen interagieren
Die Interaktion mit Webseitenelementen beinhaltet häufig das Klicken auf Schaltflächen oder Links und das Eingeben von Text in Felder, bevor deren Inhalt ausgelesen wird.
Selenium bietet verschiedene Strategien zum Auffinden von Elementen auf einer Seite mithilfe der By Klasse und die find_element() Und find_elements() Methoden.
So können Sie diese Locator-Strategien zur Interaktion mit Elementen verwenden:
Lokalisierungselemente
Selenium bietet mehrere Möglichkeiten zum Auffinden von Elementen auf einer Webseite mithilfe von find_element() Methode für ein einzelnes Element und die find_elements() Methode für verschiedene Elemente:
-
Nach ID: Suchen Sie ein Element anhand seines eindeutigen ID-Attributs.
driver.find_element(By.ID, "element_id") -
Namentlich: Suchen Sie ein Element anhand seines Namensattributs.
driver.find_element(By.NAME, "element_name") -
Nach Klassenname: Suchen Sie Elemente anhand ihres CSS-Klassennamens.
driver.find_element(By.CLASS_NAME, "element_class") -
Nach Tag-Name: Suchen Sie Elemente anhand ihres HTML-Tagnamens.
driver.find_element(By.TAG_NAME, "element_tag") -
Nach Linktext: Finden Sie Hyperlinks anhand ihres genauen sichtbaren Textes.
driver.find_element(By.LINK_TEXT, "visible_text") -
Nach teilweisem Linktext: Suchen Sie Hyperlinks anhand einer teilweisen Übereinstimmung ihres sichtbaren Textes.
driver.find_element(By.PARTIAL_LINK_TEXT, "partial_text") -
Per CSS-Selektor: Verwenden Sie CSS-Selektoren, um Elemente basierend auf CSS-Regeln zu lokalisieren.
driver.find_element(By.CSS_SELECTOR, "css_selector") -
Per XPath: Suchen Sie Elemente mithilfe ihres XPATH. XPath ist eine leistungsstarke Möglichkeit, Elemente mithilfe von Pfadausdrücken zu suchen.
driver.find_element(By.XPATH, "xpath_expression")
Klicken auf ein Element
Um auf ein Element zu klicken, suchen Sie es mit einer der oben genannten Strategien und verwenden Sie dann die click() Methode.
# Example: Clicking a button by ID
button = driver.find_element(By.ID, "button_id")
button.click()
# Example: Clicking a link by Link Text
link = driver.find_element(By.LINK_TEXT, "Click Here")
link.click()
In ein Textfeld tippen
Um Text in ein Feld einzugeben, suchen Sie das Element und verwenden Sie die send_keys() Methode.
# Example: Typing into a textbox by Name
textbox = driver.find_element(By.NAME, "username")
textbox.send_keys("your_username")
# Example: Typing into a textbox by XPath
textbox = driver.find_element(By.XPATH, "//input(@name='username')")
textbox.send_keys("your_username")
Abrufen von Text aus einem Element
Suchen Sie den Textinhalt des Elements und verwenden Sie die text Attribut, um den Textinhalt zu erhalten.
# Example: Retrieving text by Class Name
element = driver.find_element(By.CLASS_NAME, "content")
print(element.text)
# Example: Retrieving text by Tag Name
element = driver.find_element(By.TAG_NAME, "p")
print(element.text)
Abrufen von Attributwerten
Nachdem Sie das Element lokalisiert haben, verwenden Sie die get_attribute() Methode zum Abrufen von Attributwerten, wie z. B. URLs, aus Anker-Tags.
# Example: Getting the href attribute from a link by Tag Name
link = driver.find_element(By.TAG_NAME, "a")
print(link.get_attribute("href"))
# Example: Getting src attribute from an image by CSS Selector
img = driver.find_element(By.CSS_SELECTOR, "img")
print(img.get_attribute("src"))
Sie können effektiv mit verschiedenen Elementen auf einer Webseite interagieren, indem Sie diese Locator-Strategien von Selenium verwenden. By Klasse. Egal, ob Sie auf eine Schaltfläche klicken, Text in ein Formular eingeben, Text abrufen oder Attributwerte abrufen müssen, diese Methoden helfen Ihnen dabei, Ihre Web Scraping-Aufgaben effizient zu automatisieren.
Schritt 7: Honeypots identifizieren
Honeypots sind Elemente, die vor normalen Benutzern absichtlich verborgen, für Bots jedoch sichtbar sind. Sie sind darauf ausgelegt, automatisierte Aktivitäten wie Web Scraping zu erkennen und zu blockieren. Mit Selenium können Sie diese Elemente effektiv erkennen und die Interaktion mit ihnen vermeiden.
Sie können CSS-Selektoren verwenden, um Elemente zu identifizieren, die mit Stilen wie diesen ausgeblendet sind display: none; oder visibility: hidden;. Seleniums find_elements Methode mit By.CSS_SELECTOR ist für diesen Zweck praktisch:
elements = driver.find_elements(By.CSS_SELECTOR, '(style*="display:none"), (style*="visibility:hidden")')
for element in elements:
if not element.is_displayed():
continue # Skip interacting with honeypot elements
Hier prüfen wir, ob das Element auf der Webseite nicht angezeigt wird, indem wir is_displayed() Methode. Dadurch wird sichergestellt, dass Interaktionen nur mit Elementen durchgeführt werden, die für die Benutzerinteraktion vorgesehen sind, und so potenzielle Honeypots umgangen werden.
Eine häufige Form eines Honeypots ist ein getarntes Button-Element. Diese Buttons sind für Benutzer optisch verborgen, existieren aber innerhalb der HTML-Struktur der Seite:
In diesem Szenario ist die Schaltfläche absichtlich versteckt. Ein automatisierter Bot, der so programmiert ist, dass er alle Schaltflächen auf einer Seite anklickt, könnte mit dieser versteckten Schaltfläche interagieren und Sicherheitsmaßnahmen auf der Website auslösen. Legitime Benutzer würden jedoch niemals auf solche versteckten Elemente stoßen oder mit ihnen interagieren.
Mit Selenium können Sie diese Fallen effektiv umgehen, indem Sie die Sichtbarkeit von Elementen überprüfen, bevor Sie mit ihnen interagieren. Wie bereits erwähnt, is_displayed() Methode bestätigt, ob ein Element für Benutzer sichtbar ist. So können Sie diese Sicherheitsmaßnahme in Ihrem Selenium-Skript implementieren:
from selenium import webdriver
# Set your WebDriver options
chrome_options = webdriver.ChromeOptions()
# Initialize the WebDriver
driver = webdriver.Chrome(options=chrome_options)
# Navigate to a sample website
driver.get("https://example.com")
# Locate the hidden button element
button_element = driver.find_element_by_id("fakeButton")
# Check if the element is displayed
if button_element.is_displayed():
# Element is visible; proceed with interaction
button_element.click()
else:
# Element is likely a honeypot, skip interaction
print("Detected a honeypot element, skipping interaction")
# Close the WebDriver session
driver.quit()
Folgendes sollten Sie bei der Identifizierung und Vermeidung von Honeypots beachten:
- Verwenden Sie immer
is_displayed()um zu prüfen, ob ein Element sichtbar ist, bevor mit ihm interagiert wird, um zwischen echten UI-Elementen und versteckten Fallen wie Honeypots zu unterscheiden - Stellen Sie bei der Automatisierung von Interaktionen (wie Klicks oder Formulareinreichungen) sicher, dass Ihr Skript versehentliche Interaktionen mit versteckten oder nicht sichtbaren Elementen vermeidet.
- Halten Sie sich beim Scraping von Daten an die Website-Regeln und rechtlichen Richtlinien, um ethisch zu handeln und zu vermeiden, dass Sie durch die Sicherheitsmaßnahmen der Website aufgefallen sind.
Durch die Integration dieser Vorgehensweisen in Ihre Selenium-Skripte verbessern Sie deren Zuverlässigkeit und ethische Konformität, schützen Ihre Automatisierungsbemühungen und respektieren gleichzeitig die beabsichtigte Verwendung der Webressourcen.
Schritt 8: Warten auf das Laden der Elemente
Dynamische Websites laden Inhalte häufig asynchron, was bedeutet, dass Elemente auf der Seite erst nach dem ersten Laden der Seite erscheinen können.
Um Fehler in Ihrem Web Scraping-Prozess zu vermeiden, ist es wichtig, zu warten, bis diese Elemente erscheinen, bevor Sie mit ihnen interagieren. Seleniums WebDriverWait Und expected_conditions Erlauben Sie uns, zu warten, bis bestimmte Bedingungen erfüllt sind, bevor wir fortfahren.
In diesem Beispiel zeige ich Ihnen, wie Sie warten, bis die Suchleiste auf der Startseite von Amazon geladen ist, eine Suche durchführen und dann die ASINs von Amazon-Produkten in den Suchergebnissen extrahieren.
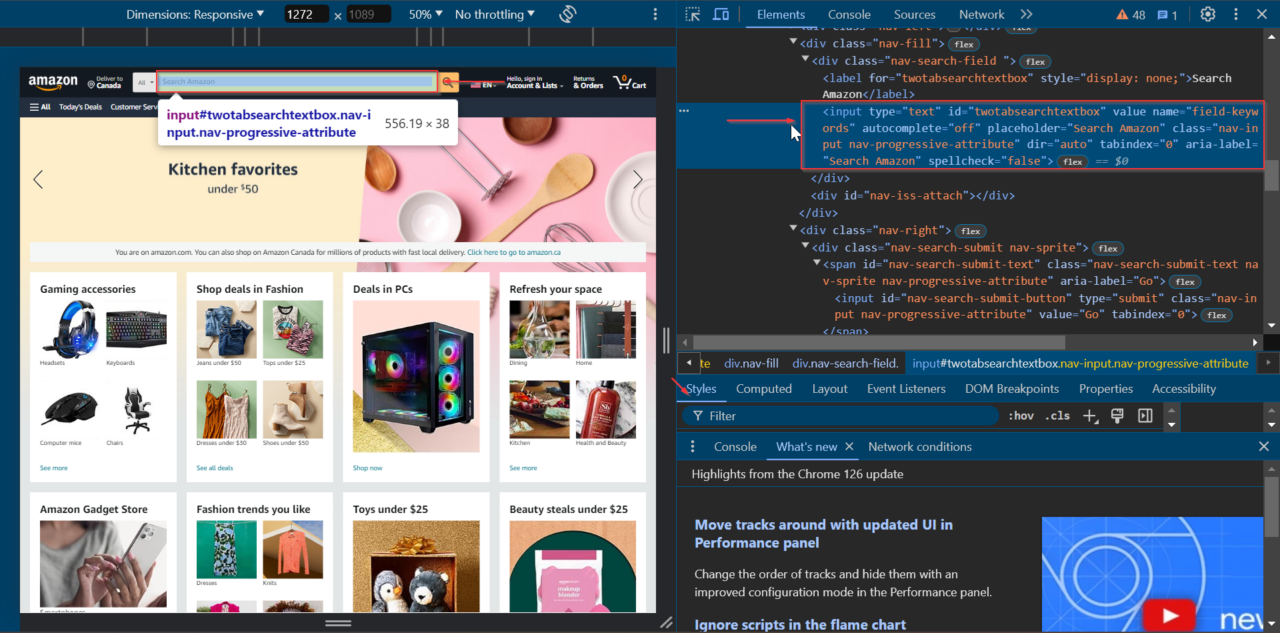
Zunächst suchen wir das Suchleistenelement auf der Startseite. Navigieren Sie zu Amazon, klicken Sie mit der rechten Maustaste auf die Suchleiste und wählen Sie „Untersuchen“, um die Entwicklertools zu öffnen.
Wir können sehen, dass das Suchleistenelement die ID hat von twotabsearchtextbox.
Beginnen wir mit der Einrichtung unseres Selenium WebDriver und der Navigation zur Homepage von Amazon.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# Set up the web driver
chrome_options = webdriver.ChromeOptions()
# Uncomment the line below to run Chrome in headless mode
# chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
# Open Amazon's homepage
driver.get("https://amazon.com/")
Als nächstes verwenden Sie WebDriverWait warten, bis das Suchleistenelement vorhanden ist, bevor mit ihm interagiert wird. Dadurch wird sichergestellt, dass das Element vollständig geladen und zur Interaktion bereit ist.
# Wait for the search bar to be present
search_bar = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "twotabsearchtextbox"))
)
Geben Sie anschließend Ihren Suchbegriff in die Suchleiste ein. Verwenden Sie dazu das send_keys() und senden Sie das Formular mit dem submit() Methode. In diesem Beispiel suchen wir nach headphones.
# Perform a search for "headphones"
search_bar.send_keys("headphones")
# Submit the search form (press Enter)
search_bar.submit()
Planen Sie eine kurze Wartezeit ein, indem Sie time.sleep() Methode, um sicherzustellen, dass die Suchergebnisseite genügend Zeit zum Laden hat.
# Wait for the search results to load
time.sleep(10)
Nachdem die Suchergebnisse geladen wurden, extrahieren wir die ASINs der Produkte in den Suchergebnissen. Wir verwenden BeautifulSoup, um die Seitenquelle zu analysieren und die Daten zu extrahieren.
from bs4 import BeautifulSoup
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
products = ()
# Extract product ASINs
productsHTML = soup.select('div(data-asin)')
for product in productsHTML:
if product.attrs.get('data-asin'):
products.append(product.attrs('data-asin'))
print(products)
Schließen Sie abschließend den Browser und beenden Sie die WebDriver-Sitzung.
# Quit the WebDriver
driver.quit()
Alles zusammen sieht der vollständige Code folgendermaßen aus:
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Set up the web driver
chrome_options = webdriver.ChromeOptions()
# Uncomment the line below to run Chrome in headless mode
# chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
# Open Amazon's homepage
driver.get("https://amazon.com/")
# Wait for the search bar to be present
search_bar = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "twotabsearchtextbox"))
)
# Perform a search for "headphones"
search_bar.send_keys("headphones")
# Submit the search form (press Enter)
search_bar.submit()
# Wait for the search results to load
time.sleep(10)
# Extract product ASINs
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
products = ()
productsHTML = soup.select('div(data-asin)')
for product in productsHTML:
if product.attrs.get('data-asin'):
products.append(product.attrs('data-asin'))
print(products)
# Quit the WebDriver
driver.quit()
Jetzt können Sie effektiv nutzen WebDriverWait um dynamische Elemente zu verarbeiten und sicherzustellen, dass sie geladen sind, bevor mit ihnen interagiert wird. Dieser Ansatz macht Ihre Web Scraping-Skripte zuverlässiger und effektiver.
