
Screen Scraping sollte einfach sein. Oftmals ist es das jedoch nicht. Wenn Sie jemals eine Datenextraktionssoftware verwendet und dann eine Stunde damit verbracht haben, XPaths und RegEx zu lernen/konfigurieren, wissen Sie, wie lästig Web Scraping sein kann.
Selbst wenn Sie es schaffen, die Daten abzurufen, dauert es viel länger, sie zu strukturieren, als den Screen Scraper zum Laufen zu bringen.
Es sind die Ad-hoc-Kommunikation und die von Natur aus nur halbstrukturierten Informationen im Web sowie die damit verbundenen Gesetzmäßigkeiten, die Web Scraping, sagen wir mal, immer noch zu einem „weniger angenehmen Erlebnis“ machen.
Statistiken zum Screen Scraping
Laut einer Stichprobe von 20.000 neue Projekte erstellt in Grepsr, so viele wie 45 % wurden nicht erfolgreich abgeschlossen.
Das Problem bestand nicht darin, dass die Leute das Produkt von Grepsr oder seine Funktionsweise nicht verstanden. Man wollte einfach erst einmal an die Daten kommen und dann darüber nachdenken, wie man sie strukturiert oder nutzbar macht. Dies führte zu Verzögerungen, erhöhten Kosten, Fehlern bei der Datenmigration und anderen Problemen.
Was wäre, wenn wir das Problem umkehrenund fragen Sie lieber: Was zeichneten die 55 % Projekte aus, die erfolgreich abgeschlossen wurden, und welchen Prozess verfolgten sie?
Inzwischen können Sie wahrscheinlich erraten, worauf wir hinaus wollen.
Projektumfang. Von den 55 % der abgeschlossenen Projekte hatten fast alle klar definierte Anforderungen – sowohl Inputs als auch Outputs.
Der Vorteil einer gründlichen Planung des Projektumfangs im Vorfeld besteht darin, dass das Endergebnis oft viel besser ist. Denn die Erwartungen – sowohl an Sie als auch an den Dienstleister – werden klar und frühzeitig geklärt, bevor die Arbeit erledigt wird.
Typischerweise handelt es sich um ein Textdokument, oft auch als „ Projektbeschreibungist einer der Kernbestandteile eines erfolgreichen Projekts. Von Anfang an eines zu haben, ist wahrscheinlich das Wichtigste, was Sie tun können, um sicherzustellen, dass Ihr Web-Scraping-Projekt startet und reibungslos läuft.
Schlüsselfrage
Kommen wir vor diesem Hintergrund zum Kern dieses Stücks.
Hier sind vier wichtige Fragen, die Sie sich bei der Planung Ihres nächsten Web-Scraping-Projekts stellen sollten:
- Was ist der geschäftliche Anwendungsfall hinter dem Projekt? Sie haben klar definierte Anforderungen?
- Haben Sie wichtige Datenquellen und die erforderlichen Zieldatenfelder identifiziert?
- Handelt es sich um einen kontinuierlichen Prozess oder um einen einmaligen Vorgang? Wer wird die Datenverschiebung durchführen und wie? Kann es automatisiert werden?
- Gibt es Anforderungen für die Bereinigung von Daten, die Ausführung von Regeln für die Quelldaten oder für die Daten, sobald sie in das Zielsystem geladen wurden?
Schauen wir uns jeden einzelnen im Detail an.
Was ist der geschäftliche Anwendungsfall hinter dem Projekt? Sie haben klar definierte Anforderungen?
Wir haben gesehen, dass Unternehmen die größten Vorteile von Webdatenprojekten erkennen, wenn sie mit geschäftlichen Herausforderungen und Zielen beginnen und diese dann schnell auf klar definierte Anforderungen eingrenzen.
Bei Grepsr erstellen wir diese Art von Geschäftsanwendungsfällen:
- Schnellerer Weg zum ROI sowohl mit Technologie als auch mit Dienstleistungen
- Fähigkeit, den Wert gegenüber selbst entwickelten Systemen nachzuweisen
- Skalierbarkeit auf mehr Datenquellen und Anwendungsfälle
Das Ziel mag klar sein, aber woher wissen Sie, ob Sie es erreicht haben? Es ist wichtig, den Erfolg Ihres Webdatenprojekts zu definieren, bevor Sie fortfahren.
Hier kommt die klare Definition der Anforderungen ins Spiel.
Stellen Sie sich vor, es ginge nicht nur darum, neue Daten aus Datenquellen zu erhalten. Aber die Daten mussten bestimmte Kriterien erfüllen – zum Beispiel, ob sie bereits in Ihrem System vorhanden sind oder nicht, die erforderlichen Felder aggregieren und schließlich die Daten so organisieren, dass sie nahtlos in Ihr System gelangen.
Einer unserer Kunden hatte ähnliche Anforderungen. Sie hatten schon früh erkannt, dass sie einen Datenextraktionsanbieter brauchten, der jeden Schritt des Prozesses von der Erfassung neuer Daten bis zum Eingang in ihr System (und alles dazwischen) automatisieren konnte.
Aus Crawling-Perspektive sah es so aus, als würden viele Web-Scraping-Anbieter einen ähnlichen Service zum Crawlen einer Website anbieten, und man hatte nicht unbedingt das Gefühl, dass ein bestimmter Anbieter etwas tun konnte, was andere nicht konnten.
John MacDonald
Da die Anforderungen klar definiert waren, erkannte unser Kunde, dass er eine Out-of-the-Box-Funktionalität benötigen würde, die nicht nur die auf dem Markt angebotenen Funktionen übersteigt.
Mehr zu ihrer Geschichte können Sie hier lesen.
Haben Sie wichtige Datenquellen und erforderliche Zieldatenfelder identifiziert?
Die erste Phase eines Web-Datenextraktionsprojekts besteht darin Identifizieren und erkunden Sie die Quellsysteme. Der am besten geeignete Weg zur Identifizierung besteht darin, Daten basierend auf den Zieldatenfeldern zu gruppieren.
Für ein Screen-Scraping-Projekt zur Lead-Generierung ist Ihr CRM das Zielsystem. Das Gruppieren von Daten nach Unternehmen, Kontakten, Rollen und anderen wichtigen Informationen, die in Ihr CRM importiert werden können, sind Ihre Zieldatenfelder.
In dieser Phase ist es wichtig zu ermitteln, welche Daten erforderlich sind und wo sie sich befinden sowie welche Daten redundant und nicht erforderlich sind.
Umgekehrt wird eine Lücke identifiziert, wenn die zunächst identifizierten Quellen nicht alle für die Zieldatenfelder erforderlichen Daten enthalten. In diesem Fall müssen Sie möglicherweise Daten aus mehreren Quellen konsolidieren, um einen Datensatz mit dem richtigen Datensatz zu erstellen, der die Anforderungen des Zielsystems erfüllt.
Benutzen mehrere Datenquellen Ermöglicht das Hinzufügen eines weiteren Elements von Datenvalidierung und ein gewisses Maß an Vertrauen in Ihre Daten.
Am Ende dieser Phase haben Sie Suchbegriffe, spezifische URLs und Seiten innerhalb dieser Quellsysteme identifiziert und diese dokumentiert. Außerdem haben Sie etwaige Lücken in den Daten identifiziert und, wenn möglich, zusätzliche Quellen zum Ausgleich eingefügt.
Im Idealfall haben Sie die Daten in Kategorien unterteilt, die Ihnen die Bearbeitung überschaubarer und möglicher paralleler Aufgaben ermöglichen.
Bedenken Sie dabei Folgendes: Möglicherweise brauchen Sie es nicht alles.
Oftmals besteht der erste Instinkt darin, riesige Datenmengen in hoher Häufigkeit zu sammeln, während ein gut konstruierter Stichprobendatensatz möglicherweise alles ist, was Sie benötigen, um umsetzbare Erkenntnisse zu gewinnen.
Handelt es sich um einen kontinuierlichen Prozess oder um einen einmaligen Vorgang? Wer wird die Datenverschiebung durchführen und wie? Kann es automatisiert werden?
Die Wahl zwischen kontinuierlichem Screen-Scraping oder einmaligem Daten-Scraping hängt vom Anwendungsfall ab. Ein einmaliger Kratzer könnte beispielsweise für Forschungs- oder akademische Zwecke dienen – Daten abrufen, visualisieren oder Berichte erstellen, fertig!
Andererseits könnte der Anwendungsfall für einen fortlaufenden Scrape darin bestehen, Teile von Geschäftsprozess-Workflows oder Apps zu automatisieren und voranzutreiben. Denken Sie an Preisüberwachungsprojekte, bei denen es wichtig ist, in regelmäßigen Abständen Live-Daten zur Analyse und zum Vergleich zu erhalten.
Idealerweise ist eine Demo oder ein Rundgang durch die Plattform Ihres Dienstanbieters ein guter Anfang. Worauf Sie achten sollten, ist ihre Fähigkeit, laufende Crawls zu automatisieren Und Optimieren Sie den Datenerfassungsprozess.
Bei Grepsr bieten wir a Planungsfunktion Dadurch können Sie Ihre Crawls im Voraus in die Warteschlange stellen, so wie Sie laufende Besprechungen in Ihrem Google-Kalender planen würden.
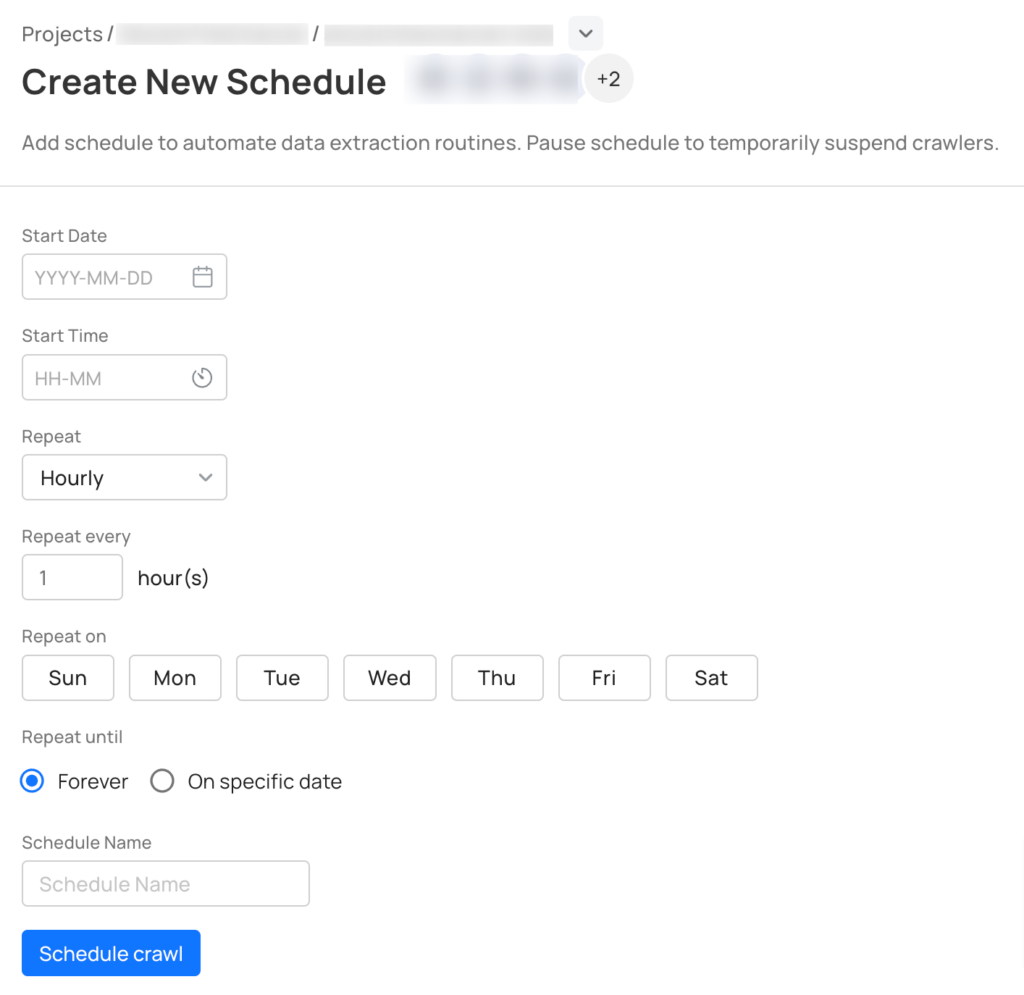
Und sobald die vollständigen Daten abgerufen sind, sendet unser System eine Benachrichtigung zum Herunterladen der Dateien. Alternativ können Sie die Daten mit unserem leistungsstarken Tool ganz einfach nahezu in Echtzeit in Ihr System übertragen APIs. Darüber hinaus können Sie unsere vorgefertigten Datenkonnektoren mit Ihren alltäglichen Geschäftstools nutzen.
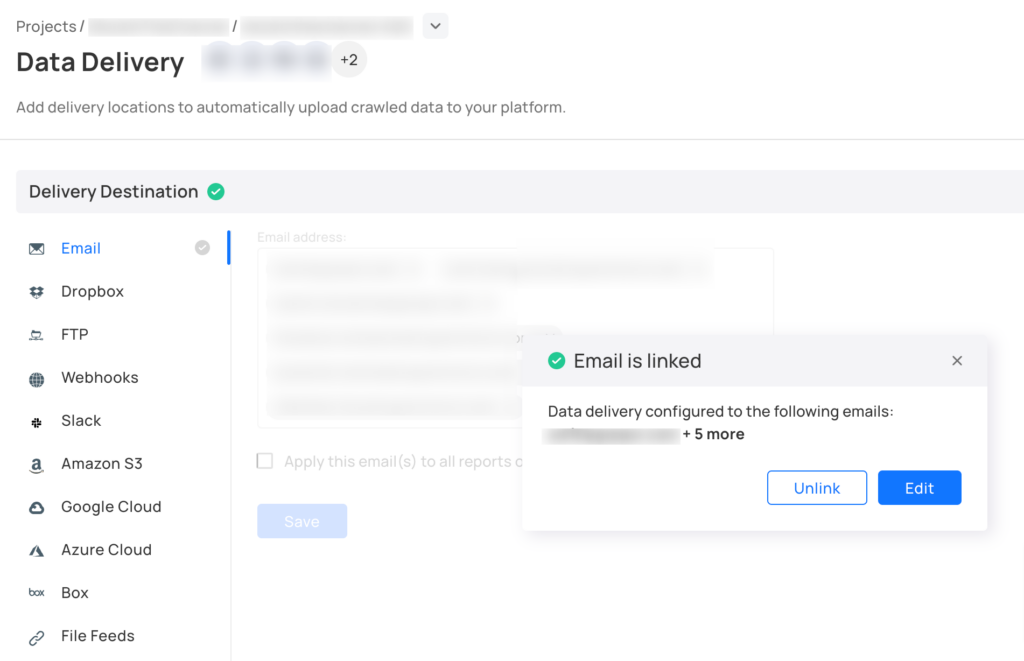
Gibt es Anforderungen für die Bereinigung von Daten, die Ausführung von Regeln für die Quelldaten oder für die Daten, sobald sie in das Ziel geladen wurden?
Die meisten Screen-Scraping-Projekte scheitern oder verzögern sich, weil die Datenstruktur oder das Ausgabeformat nachträglich berücksichtigt wurde. Zugegeben, denn wir wollen zunächst die Daten in die Hand bekommen und dann darüber nachdenken, sie nutzbar zu machen.
Wir haben vor ein paar Monaten ein Projekt durchgeführt, bei dem der Kunde vergessen hat zu erwähnen, dass die zurückgegebenen „Adressen“ der USPS-Adressstandardisierung entsprechen sollten, andernfalls würde sein System einfach keine Daten importieren. Schließlich mussten wir eine USPS-Adressverifizierungs-API verwenden, was zu Änderungen im Projektbudget und daraus resultierenden Verzögerungen führte.
In dieser Phase ist es für Sie und Ihr Team unerlässlich, Fragen zu stellen wie: Wo landen die Daten? In einer Tabellenkalkulation, einer Datenbank oder einer Analyseanwendung? Ist eine Datenbereinigung erforderlich?
Versuchen Sie, ein Datenschema im Voraus zu sperren. Konzentrieren Sie sich nicht nur darauf, an die Daten zu gelangen, ohne über die Struktur und das Format nachzudenken, die für die Datenintegrität und -aufnahme vorhanden sein müssen.
Abschluss
Wenn Sie zum ersten Mal mit dem Screen Scraping beginnen, müssen Sie es oft eilig haben, Daten in das System zu übertragen, damit Sie sie verwenden können. Der Eifer, die Daten zu nutzen, ist groß, aber ich hoffe, dieser Beitrag hat Ihnen genügend Gründe gegeben, sich einen Moment Zeit zu nehmen, um alle notwendigen Faktoren zu berücksichtigen und zu bedenken, wie wichtig es ist, den Umfang Ihres Scraping-Projekts frühzeitig festzulegen.
