
Mit über 1,5 Milliarden aktiven Angeboten zählt eBay zu den weltweit größten E-Commerce-Plattformen. Das Auslesen öffentlich verfügbarer Daten von eBay bietet viele Vorteile, wie z. B. die Überwachung von Preisen und Produkttrends.
In diesem ausführlichen Blog erfahren Sie, wie Sie eBay mit Python scrapen, welche Herausforderungen beim Scraping von eBay auftreten und wie Sie die Scrape-It.Cloud-API verwenden, um Daten von jeder Website mit einem einfachen API-Aufruf zu extrahieren, ohne dass ein Proxy erforderlich ist .
Einführung in eBay Data Scraping
eBay ist eine der beliebtesten Optionen für die E-Commerce-Datenextraktion, da es umfangreiche Informationen für Analysen und Entscheidungsfindung liefert. Das Geschäftsmodell von eBay unterscheidet sich von einer Standard-Einzelhandelsplattform (wie Amazon) durch die Auktionsfunktion, bei der Verkäufer Produkte zu niedrigen Preisen anbieten und Kunden bieten, was zu dynamischen Preisänderungen führt.
Verkäufer können wertvolle Daten von eBay extrahieren, um ihre Angebote zu verbessern und sich auf verschiedene Weise einen Wettbewerbsvorteil zu verschaffen, wie zum Beispiel:
- Preisüberwachung: Im E-Commerce schwanken die Preise ständig. Daher ist es wichtig, auf die Daten der Wettbewerber bei eBay zuzugreifen, um möglichst wettbewerbsfähige Preise anbieten zu können. Das Scrapen dieser Daten kann unglaublich wertvoll sein. Es kann die aktuelle Preisspanne für Ihre Zielprodukte anzeigen, sodass Sie fundierte Entscheidungen über Ihre Preisgestaltung treffen können.
- Marktforschung: E-Commerce-Daten bieten wertvolle Einblicke in Markttrends, Verbraucherpräferenzen und Kaufmuster. Durch die Analyse des Einkaufsverhaltens Ihrer Kunden können Sie deren zukünftige Einkäufe besser vorhersagen und allgemeinere Markttrends erkennen. Darüber hinaus kann die Verfolgung der Kundenstandorte zeigen, wo Ihre Produkte gut funktionieren.
- Wettbewerbsanalyse: Durch das Sammeln von Informationen über die Produktpreise, Rabatte und Werbeaktionen Ihrer Mitbewerber können Sie datengesteuerte Entscheidungen über Ihre Produktangebote treffen. Erwägen Sie, Ihre Preise zu senken, um Kunden oder Bieter anzulocken, wenn viele ähnliche Produkte verfügbar sind.
- Stimmungsanalyse: Rezensionen und Bewertungen bieten wertvolle Einblicke in die Kundenzufriedenheit und das Produktfeedback. Durch das Scrapen können Sie die Zufriedenheit Ihrer Kunden verstehen und Möglichkeiten zur Verbesserung Ihres Produkts oder Ihrer Dienstleistung erkennen.
Aufbau einer eBay-Seite
Die Website von eBay umfasst sowohl Produkt- als auch Suchergebnisseiten. Eine Standard-Ebay-Produktseite, wie z. B. die unten gezeigte Apple MacBook-Seite, enthält nützliche Informationen, die gescrapt werden können. Zu diesen Informationen gehören Produkttitel, Beschreibung, Bild, Bewertung, Preis, Verfügbarkeitsstatus, Kundenrezensionen, Versandkosten und Lieferdatum.
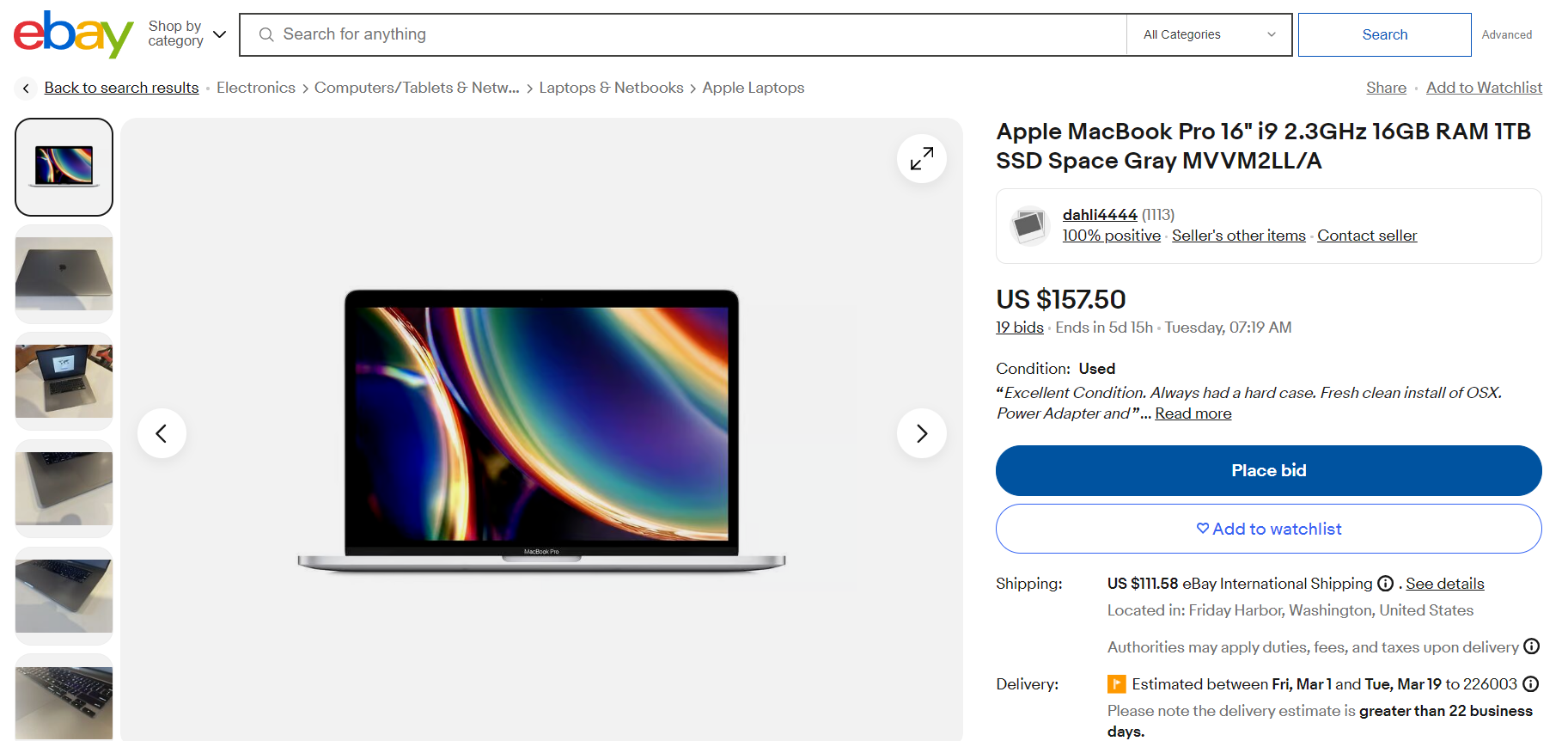
Wenn Sie in der Suchleiste nach einem Schlüsselwort wie „MacBook“ suchen, werden Sie zu einer Suchergebnisseite wie der folgenden weitergeleitet. Sie können alle auf dieser Seite aufgeführten Produkte extrahieren, einschließlich ihrer Titel, Produktbilder, Bewertungen, Rezensionen und mehr.
Hier können Sie Tausende von Produkten sehen, die extrahiert werden können und so Zugriff auf eine Fülle von Informationen bieten.
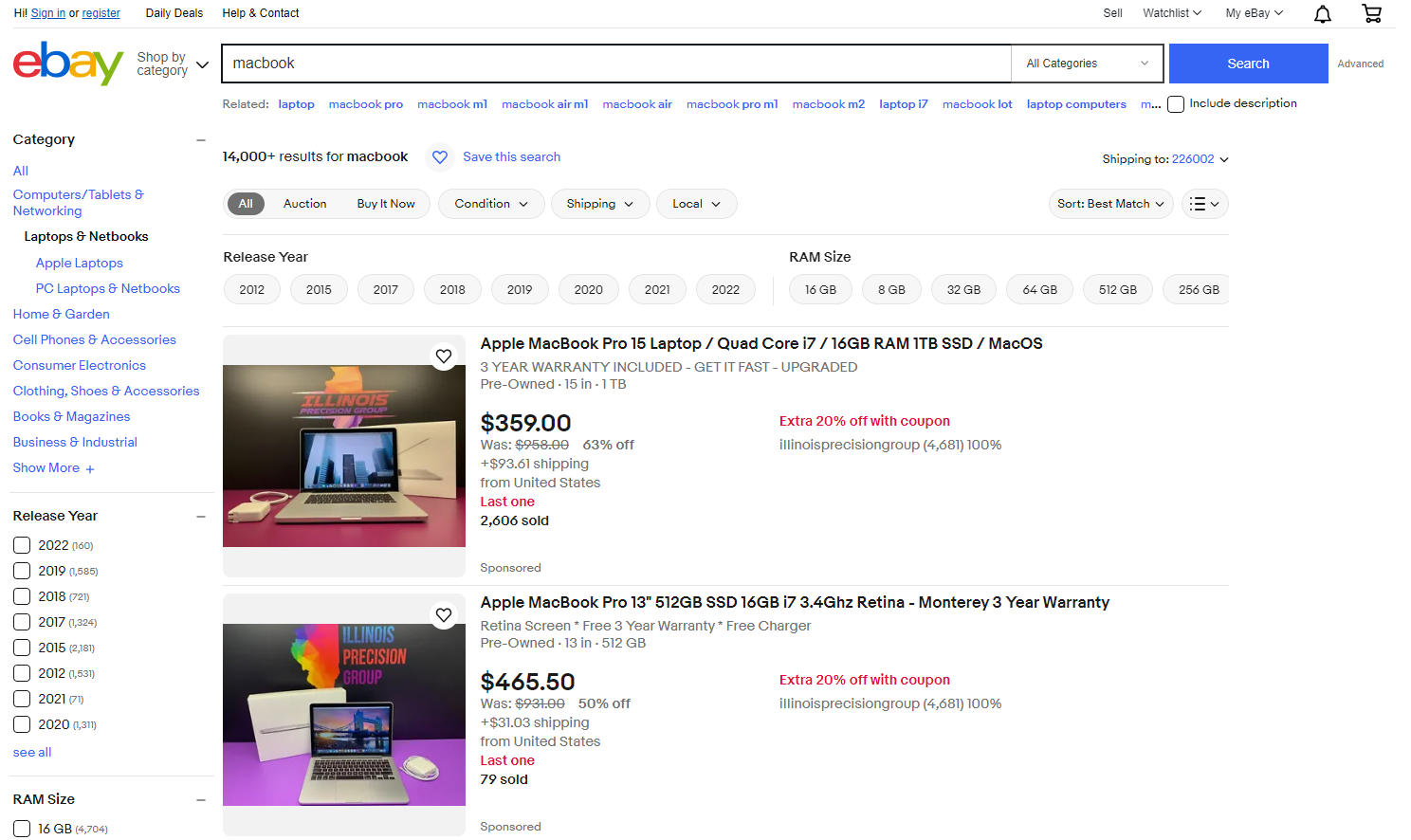
Nachdem Sie nun die Bedeutung der Daten verstanden haben, die wir von eBay erhalten können, tauchen wir in eine Schritt-für-Schritt-Anleitung zum Extrahieren spezifischer Daten aus eBay mithilfe von Python ein.
Einrichten Ihrer Python-Umgebung für Scraping
Um Ihre Python-Umgebung für Web Scraping einzurichten, müssen Sie einige Systemanforderungen erfüllen und die erforderlichen Bibliotheken installieren.
Voraussetzungen
Stellen Sie vor Beginn sicher, dass Sie die folgenden Anforderungen erfüllen:
- Python installiert: Laden Sie die neueste Version von der offiziellen Python-Website herunter. Für diesen Blog verwenden wir Python 3.9.12.
- Code-Editor: Wählen Sie einen Code-Editor, z. B. Visual Studio Code, PyCharm oder Jupyter Notebook.
Erstellen Sie als Nächstes ein Python-Projekt namens „ebay-scraper“ mit den folgenden Befehlen:
mkdir ebay-scraper
cd ebay-scraperÖffnen Sie dieses Projekt in Ihrem bevorzugten Code-Editor und erstellen Sie eine neue Python-Datei (scraper.py).
Installieren Sie die erforderlichen Bibliotheken
Um Web Scraping mit Python durchzuführen, müssen Sie einige wichtige Bibliotheken installieren: Requests, BeautifulSoup und Pandas.
- Pandas für die Erstellung von DataFrames aus den extrahierten Daten und das effiziente Schreiben des DataFrames in eine CSV-Datei. Es unterstützt offiziell Python 3.9, 3.10, 3.11 und 3.12.
- Anfragen senden HTTP-Anfragen und rufen HTML-Inhalte von Webseiten ab. Es unterstützt offiziell Python 3.7+.
- BeautifulSoup extrahiert Daten aus dem rohen HTML-Inhalt mithilfe von Tags, Attributen, Klassen und CSS-Selektoren.
pip install beautifulsoup4 requests pandasScraping der eBay-Produktseite
Beim Scraping einer Seite geht es darum, deren Struktur zu verstehen, den rohen HTML-Inhalt herunterzuladen, den HTML-Inhalt zu analysieren, um Produktdetails zu extrahieren, und die Daten dann zur weiteren Analyse zu speichern.
Analyse der eBay-Produktseite
Eine Produktseite enthält verschiedene Datenelemente, die wir extrahieren können. Wir werden sieben Schlüsselattribute von der Seite entfernen, darunter:
- Bilder des Produkts
- Produktname
- Preis
- Original Preis
- Rabatt
- Bewertung des Verkäufer-Feedbacks
- Versandkosten
Bei eBay folgt die URL der Produktseite dem untenstehenden Format. Dies ist eine dynamische URL, die sich basierend auf der Artikel-ID ändert, die eine eindeutige Kennung für jeden Artikel darstellt.
<https://www.ebay.com/itm/><ITM_ID>Lassen Sie uns die Seite https://www.ebay.com/itm/404316395828 durchsuchen. Die Artikel-ID lautet 404316395828.
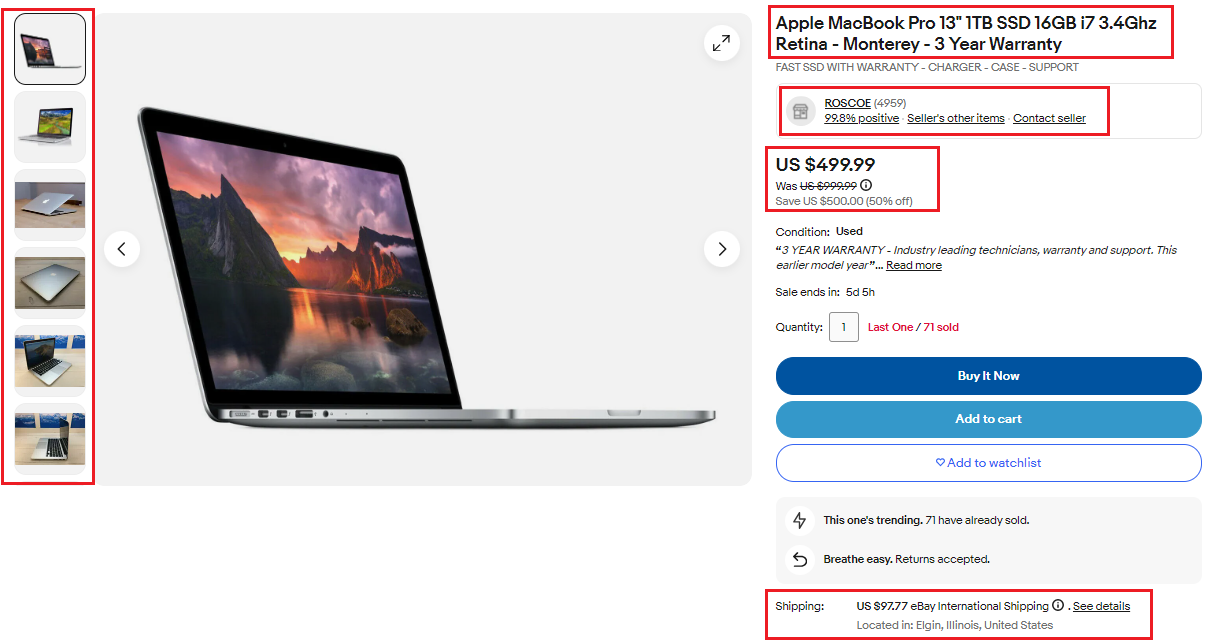
Abrufen der HTML-Seite
Um den HTML-Inhalt einer eBay-Produktseite zu erhalten, identifizieren Sie zunächst deren eindeutige ID-Nummer. Dann verwenden Sie die requests.get() Funktion und liefert die ID als Argument. Diese Funktion sendet eine HTTP-GET-Anfrage an eBay und fordert die spezifische Produktseite an.
Bei Erfolg sendet der Server eine Antwort mit dem gesamten HTML-Inhalt der Seite zurück, der in einer Variablen gespeichert wird, damit Sie darauf zugreifen können. Sollten bei diesem Vorgang jedoch Fehler auftreten, etwa eine ungültige ID oder Netzwerkprobleme, wird die raise_for_status() Die Funktion löst eine Ausnahme aus, um Sie zu warnen.
url = f"<https://www.ebay.com/itm/{item_id}>"
response = requests.get(url)
response.raise_for_status()Parsen der HTML-Seite
Erstellen Sie ein BeautifulSoup-Objekt, indem Sie Folgendes übergeben response.text und den Parsernamen „html.parser“ zum BeautifulSoup() Konstrukteur. Dieser Parsing-Prozess zerlegt den HTML-Code in seine Bestandteile, einschließlich Tags und Attribute, und erstellt eine baumartige Struktur, die als Document Object Model (DOM) bekannt ist.
Sobald das DOM eingerichtet ist, können Sie verschiedene Methoden wie find(), find_all(), select_one() und select() verwenden, um Elemente selektiv zu extrahieren. find() Und find_all() werden zum Navigieren im Analysebaum verwendet select_one() Und select() werden zum Suchen von Elementen mithilfe von CSS-Selektoren verwendet.
soup = BeautifulSoup(response.text, "html.parser")Wir extrahieren sieben Schlüsselattribute aus dem Produkt: Bilder, Titel, aktueller Preis, Originalpreis, Rabatt, Verkäuferbewertung und Versandkosten.
Der Titel wird im gespeichert h1 Tag mit der Klasse x-item-title__mainTitle. Mit diesem h1 Tag, da ist ein span Tag mit zwei Klassennamen. Wir werden das verwenden .ux-textspans--BOLD Klassenname, um den Titeltext zu extrahieren. Daher ist der letzte Selektor zum Extrahieren des Titels .x-item-title__mainTitle .ux-textspans--BOLD.
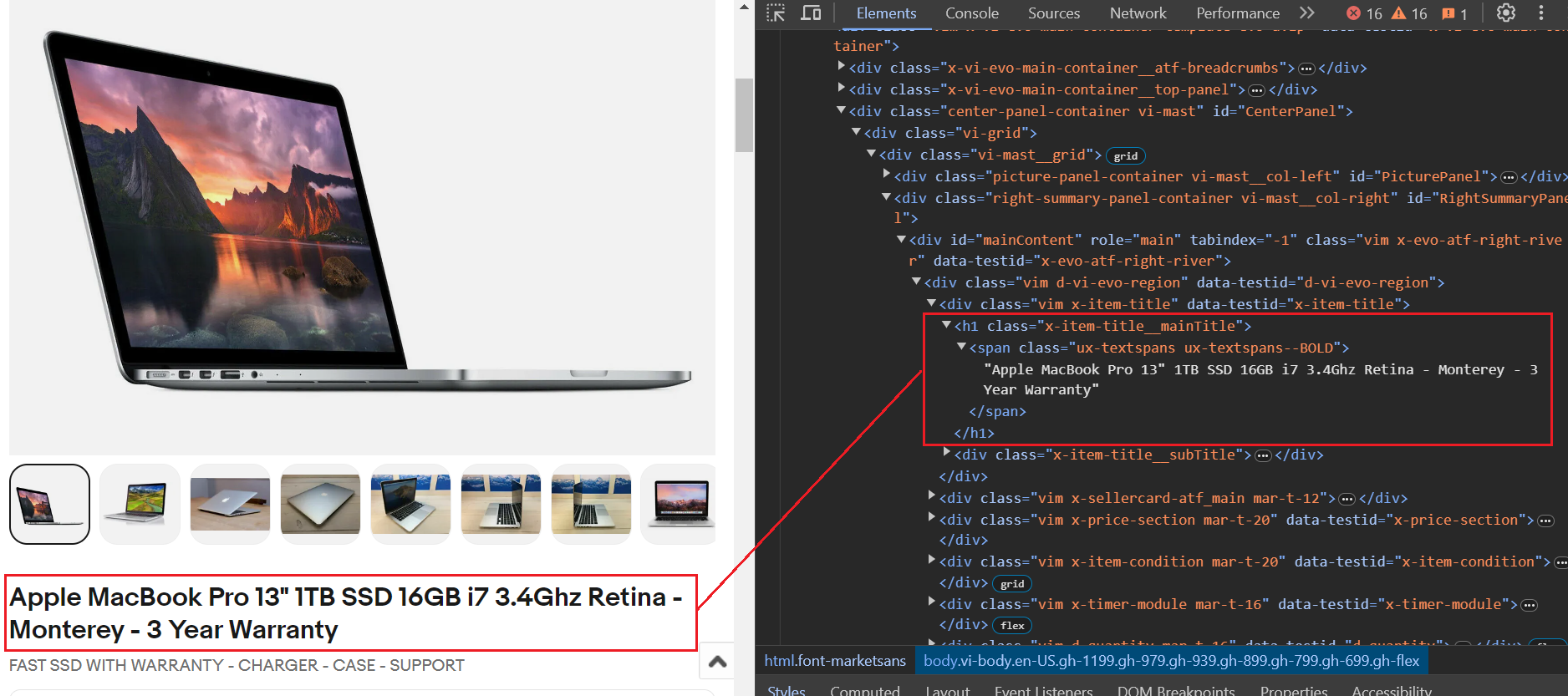
Hier ist ein Beispielcode-Snippet. Wir benutzen das select_one Methode, die das erste Element zurückgibt, das mit dem angegebenen CSS-Selektor übereinstimmt. Wir extrahieren zunächst den Titel, prüfen dann, ob er leer ist, und speichern ihn schließlich im item_data Wörterbuch, in dem alle Schlüsselattribute gespeichert werden.
item_title_element = soup.select_one(".x-item-title__mainTitle .ux-textspans--BOLD")
item_title = item_title_element.text if item_title_element else "Not available"
item_data("Title") = item_titleDer Preis liegt innerhalb von a div Tag mit dem Klassennamen x-price-primary. Darin drin div Tag, a span Tag mit dem Klassennamen ux-textspans enthält den Preis. Um dieses Element mithilfe von CSS genau anzusprechen, wäre der richtige Selektor .x-price-primary .ux-textspans.
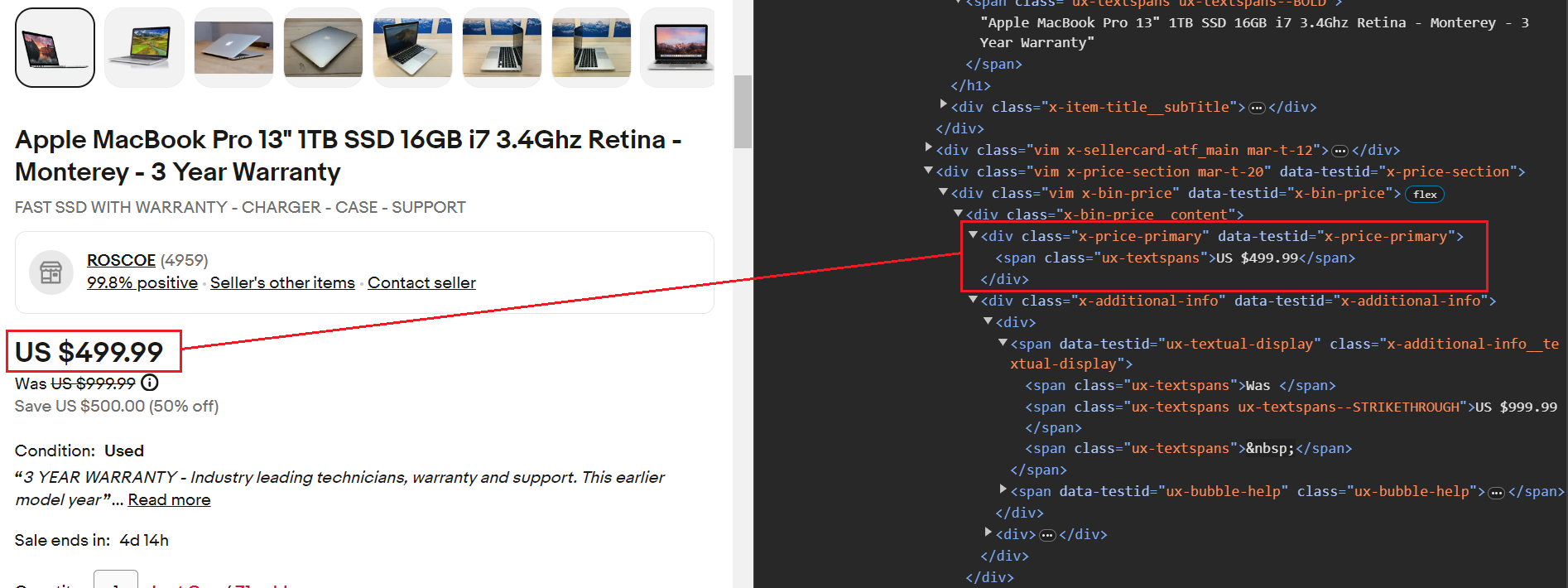
Hier ist der Codeausschnitt. Die Scraping-Vorgänge sind die gleichen, die wir im Titel gesehen haben.
current_price_element = soup.select_one(".x-price-primary .ux-textspans")
current_price = current_price_element.text if current_price_element else "Not available"
item_data("Current Price") = current_priceDer durchgestrichene Wert gibt den tatsächlichen Preis an. Dieser Wert kann leicht mithilfe von extrahiert werden span Tag-Klasse ux-textspans--STRIKETHROUGH.
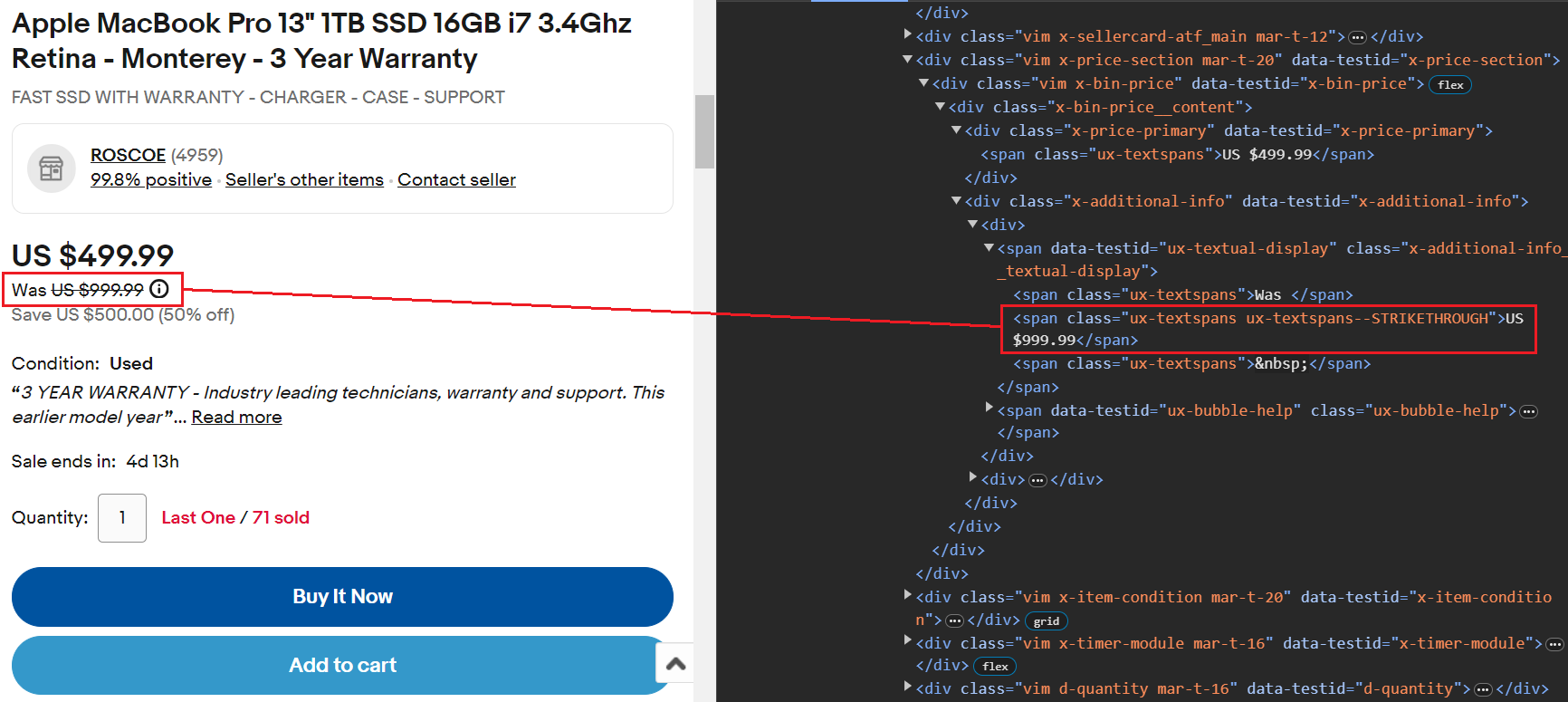
Hier ist der Codeausschnitt:
original_price_element = soup.select_one(".ux-textspans--STRIKETHROUGH")
original_price = (
original_price_element.text if original_price_element else "Not available")
item_data("Original Price") = original_priceDer Rabatt wird innerhalb von a gespeichert span Tag mit der Klasse ux-textspans--EMPHASIS. Das span Das Tag ist in einem übergeordneten Element verschachtelt, das die Klasse enthält x-additional-info__textual-display. Daher wäre der geeignete Selektor für die Ausrichtung auf dieses Element .x-additional-info__textual-display .ux-textspans--EMPHASIS.
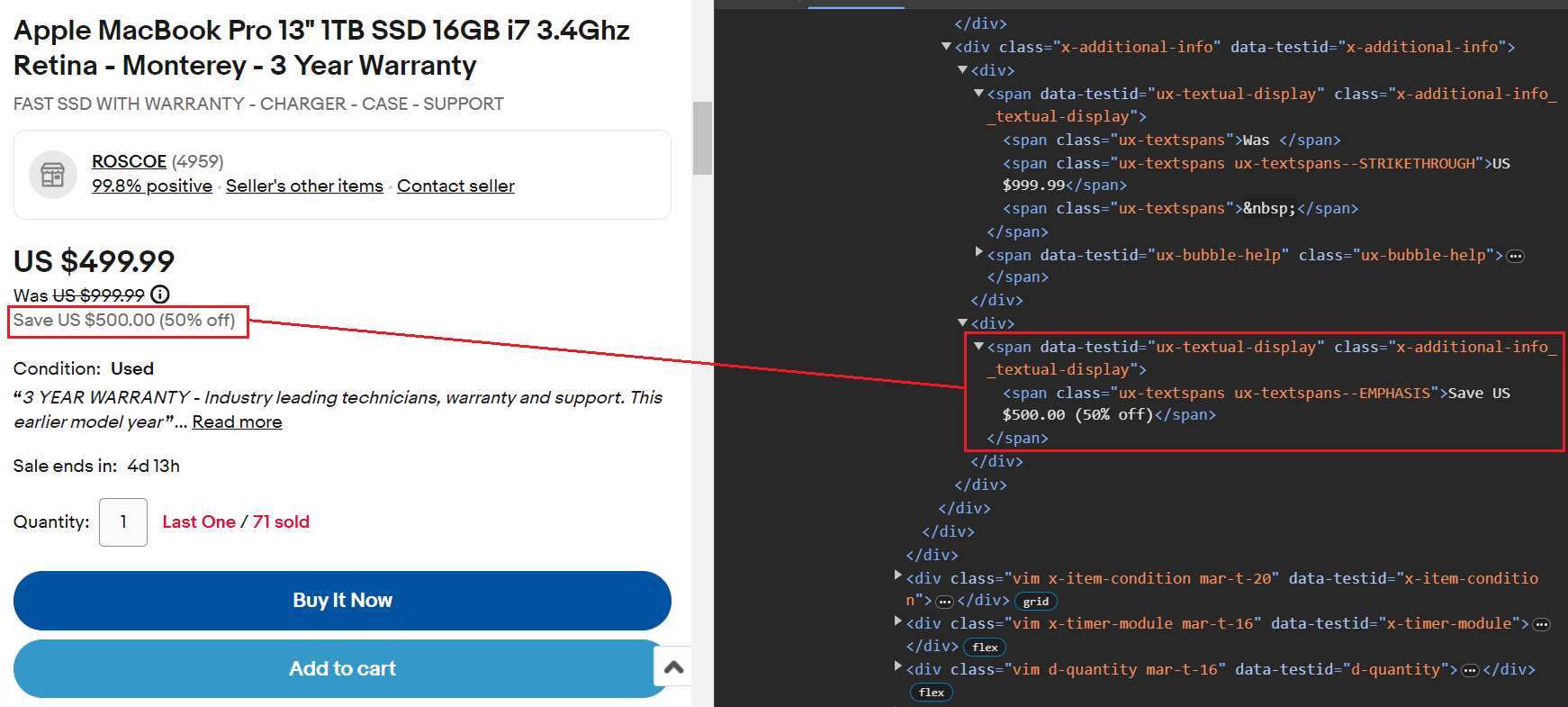
Hier ist der Codeausschnitt:
savings_element = soup.select_one(
".x-additional-info__textual-display .ux-textspans--EMPHASIS")
savings = savings_element.text if savings_element else "Not available"
item_data("Savings") = savingsDer Versandpreis liegt innerhalb von a span Tag mit der Klasse ux-textspans--BOLD. Insbesondere dies span Tag ist in verschiedenen verschachtelt div Tags, aber wir konzentrieren uns auf das übergeordnete Element div Tag, der die Klasse hat ux-labels-values--shippingwie dies div Tag scheint einen eindeutigen Klassennamen zu haben. Der Schabevorgang umfasst die folgenden zwei Schritte:
- Verwenden
soup.find('div', class_='ux-labels-values--shipping')um das zu findendivTag mit dem angegebenen Klassennamen. - Anwenden
.find('span', class_='ux-textspans--BOLD').textum den Textinhalt des ersten Treffers zu finden und zu extrahierenspanElement mit der Klasseux-textspans--BOLDinnerhalb des identifiziertendivEtikett.
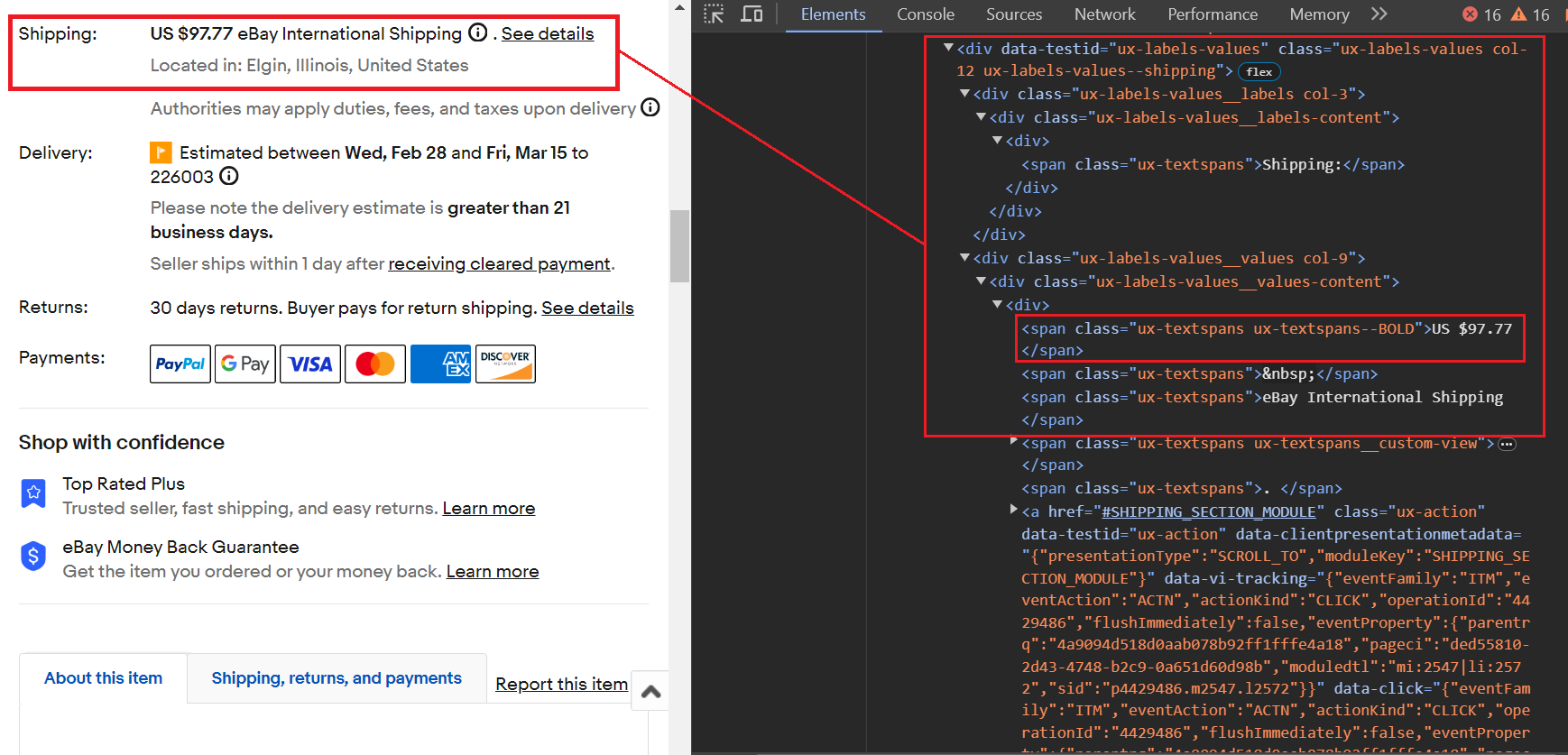
Hier ist der Codeausschnitt:
shipping_parent_element = soup.find("div", class_="ux-labels-values--shipping")
shipping_info = (
"Free Shipping"
if not shipping_parent_element
else shipping_parent_element.find("span", class_="ux-textspans--BOLD").text
)
item_data("Shipping Price") = shipping_infoDie Bewertung des Verkäufer-Feedbacks befindet sich innerhalb der <a> Tag, das in einem verschachtelt ist <li> Tag mit dem data-testid Attribut auf gesetzt x-sellercard-atf__data-item. Das <li> Das Tag wiederum ist in einem enthalten <ul> Tag, der die Klasse hat .x-sellercard-atf__data-item-wrapper.
Somit ist der Selektor, der auf dieses Element abzielt .x-sellercard-atf__data-item-wrapper li(data-testid="x-sellercard-atf__data-item") a.
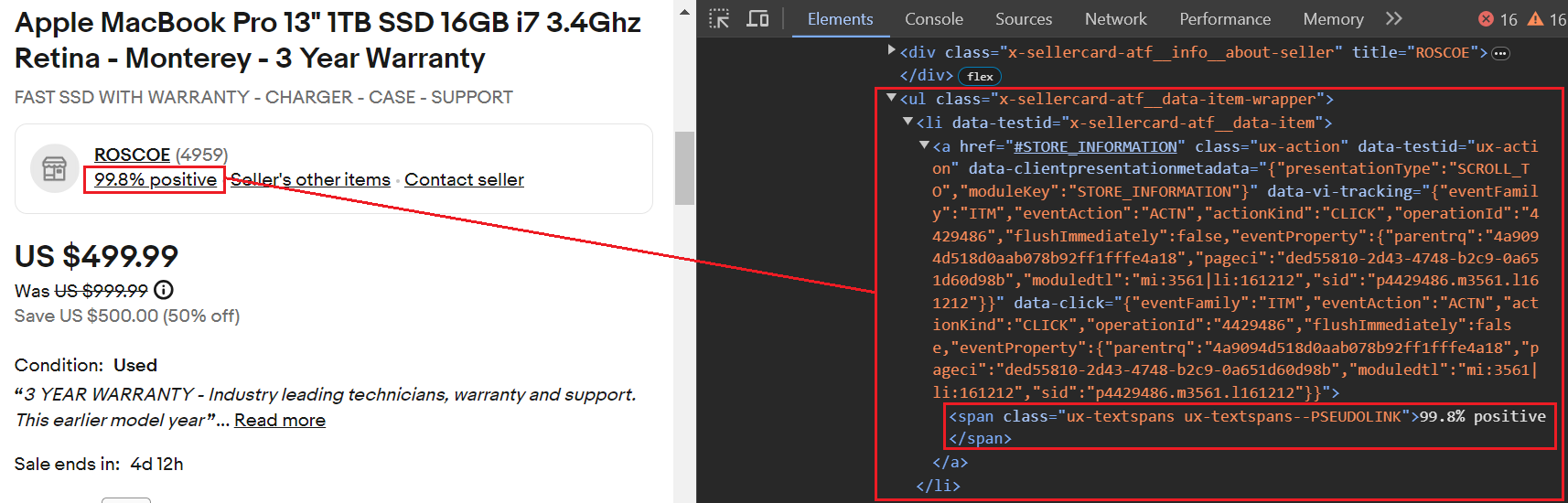
Hier ist der Codeausschnitt:
seller_feedback_element = soup.select_one(
'.x-sellercard-atf__data-item-wrapper li(data-testid="x-sellercard-atf__data-item") a'
)
seller_feedback = (
seller_feedback_element.text if seller_feedback_element else "Not available"
)
item_data("Seller Feedback") = seller_feedbackAlle Bilder befinden sich innerhalb einzelner button Tags, die den gemeinsamen Klassennamen teilen ux-image-grid-item. Der übergeordnete Container für diese button Tags ist ein div Tag mit der Klasse ux-image-grid-container.
Um auf die Bilder zuzugreifen, gehen Sie folgendermaßen vor:
- Suchen Sie das div-Tag mithilfe von
findMethode. - Wende an
selectMethode mit dem CSS-Selektor.ux-image-grid-item imgum eine Liste aller passenden Bildelemente abzurufen.
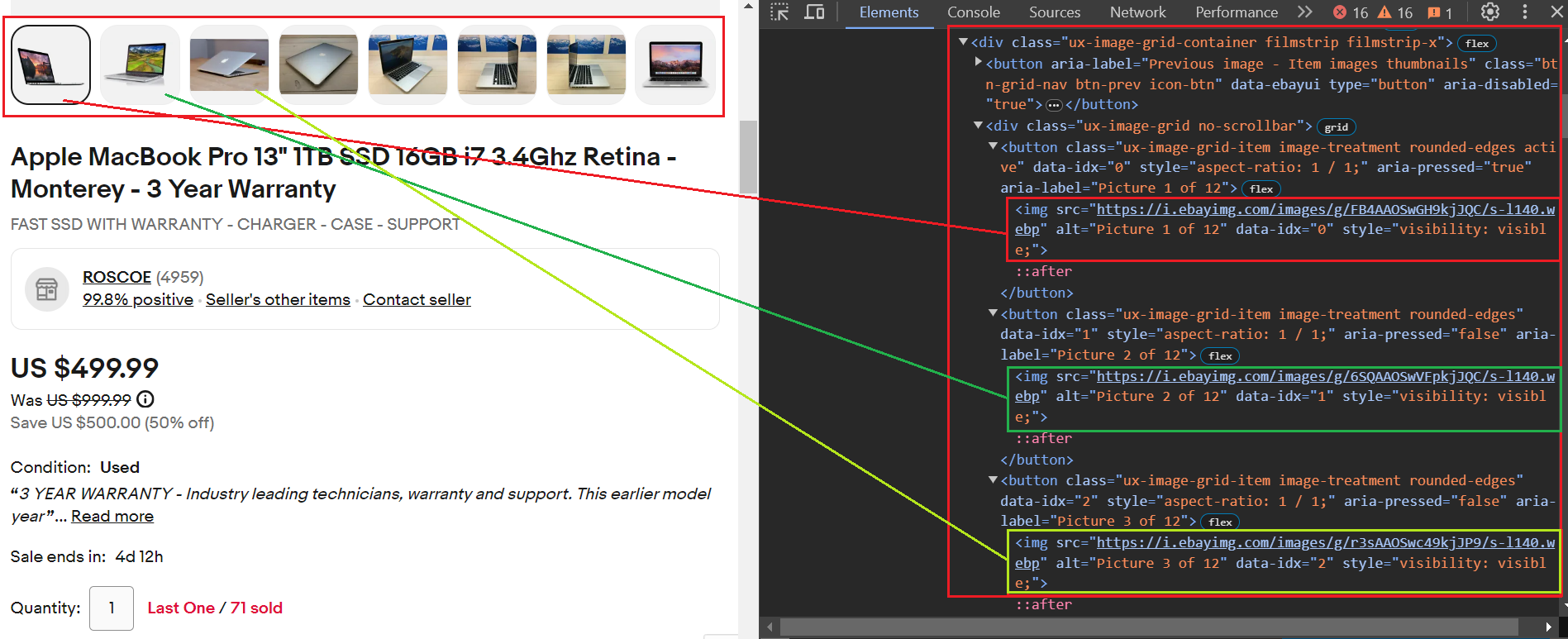
Hier ist der Codeausschnitt. Nach dem Extrahieren aller <img> Tags, wir prüfen, ob die src Das Attribut ist in diesen Tags vorhanden. Dies liegt daran, dass die src Das Attribut gibt die URL des Bildes an.
image_grid_container = soup.find("div", class_="ux-image-grid-container")
image_links = ()
if image_grid_container:
img_elements = image_grid_container.select(".ux-image-grid-item img")
image_links = (img("src") for img in img_elements if "src" in img.attrs)
item_data("Images") = image_linksDaten nach JSON exportieren
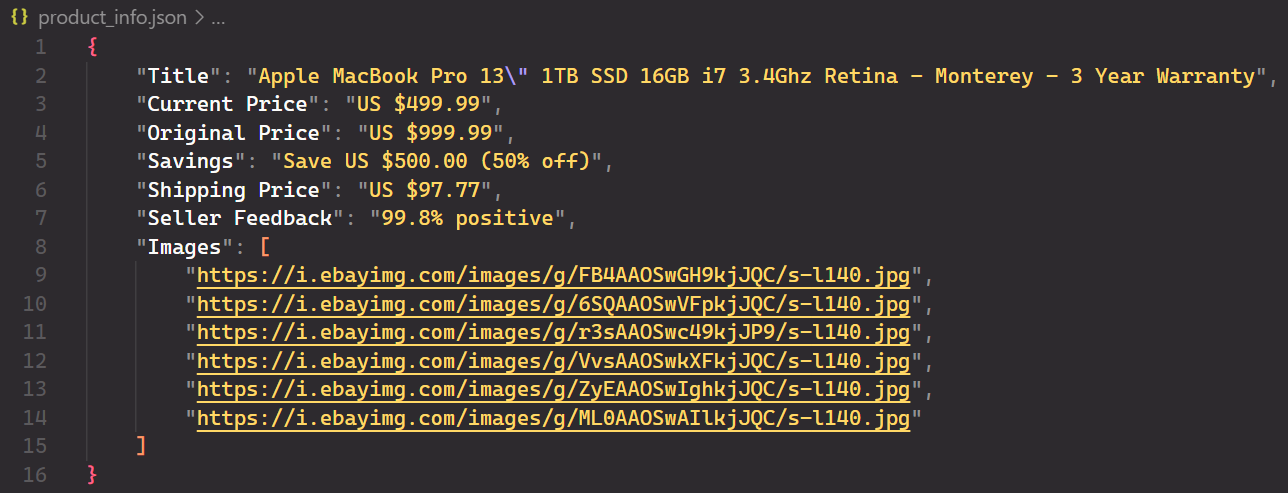
Sie haben alle Daten erfolgreich extrahiert und gespeichert item_data Wörterbuch. Um die Daten in einer JSON-Datei zu speichern, importieren Sie die json Modul und verwenden Sie das dump Methode.
with open(filename, "w") as file:
json.dump(item_data, file, indent=4)Hier ist die JSON-Datei:
Vollständiger Code
Nachfolgend finden Sie den vollständigen Code für die Produktdatenextraktion. Sie benötigen lediglich die Artikel-ID.
import requests
from bs4 import BeautifulSoup
import json
def fetch_ebay_item_info(item_id):
url = f"<https://www.ebay.com/itm/{item_id}>"
try:
response = requests.get(url)
response.raise_for_status() # Raise an exception for bad requests
except requests.exceptions.RequestException as e:
print(f"Error: Unable to fetch data from eBay ({e})")
return None
soup = BeautifulSoup(response.text, "html.parser")
item_data = {}
try:
current_price_element = soup.select_one(
".x-price-primary .ux-textspans")
current_price = (
current_price_element.text if current_price_element else "Not available"
)
original_price_element = soup.select_one(
".ux-textspans--STRIKETHROUGH")
original_price = (
original_price_element.text if original_price_element else "Not available"
)
savings_element = soup.select_one(
".x-additional-info__textual-display .ux-textspans--EMPHASIS"
)
savings = savings_element.text if savings_element else "Not available"
shipping_parent_element = soup.find(
"div", class_="ux-labels-values--shipping")
shipping_info = (
"Free Shipping"
if not shipping_parent_element
else shipping_parent_element.find("span", class_="ux-textspans--BOLD").text
)
seller_feedback_element = soup.select_one(
'.x-sellercard-atf__data-item-wrapper li(data-testid="x-sellercard-atf__data-item") a'
)
seller_feedback = (
seller_feedback_element.text if seller_feedback_element else "Not available"
)
item_title_element = soup.select_one(
".x-item-title__mainTitle .ux-textspans--BOLD"
)
item_title = item_title_element.text if item_title_element else "Not available"
image_grid_container = soup.find(
"div", class_="ux-image-grid-container")
image_links = ()
if image_grid_container:
img_elements = image_grid_container.select(
".ux-image-grid-item img")
image_links = (img("src")
for img in img_elements if "src" in img.attrs)
item_data("Title") = item_title
item_data("Current Price") = current_price
item_data("Original Price") = original_price
item_data("Savings") = savings
item_data("Shipping Price") = shipping_info
item_data("Seller Feedback") = seller_feedback
item_data("Images") = image_links
return item_data
except Exception as e:
print(f"Error: Unable to parse eBay data ({e})")
return None
def save_to_json(item_data, filename="product_info.json"):
if item_data:
with open(filename, "w") as file:
json.dump(item_data, file, indent=4)
print(f"Success: eBay item information saved to {filename}")
def main():
item_id = input("Enter the eBay item ID: ")
item_info = fetch_ebay_item_info(item_id)
if item_info:
save_to_json(item_info)
if __name__ == "__main__":
main()Scraping der eBay-Suche
Wenn Sie nach einem Schlüsselwort suchen, leitet eBay Sie automatisch zu einer bestimmten URL weiter, die Ihre Suchergebnisse enthält. Wenn Sie beispielsweise nach „kubernetes-Cluster“ suchen, gelangen Sie zu einer URL ähnlich wie https://www.ebay.com/sch/i.html?_nkw=kubernetes+cluster&_sacat=0.
Diese URL verwendet mehrere Parameter, um Ihre Suchanfrage zu definieren. Hier sind einige davon:
_nkw: Das Suchwort selbst._sacat: Alle von Ihnen angewendeten Kategorieeinschränkungen._sop: Der ausgewählte Sortiertyp, z. B. „Beste Übereinstimmung“ oder „Neu gelistet“._pgn: Die aktuelle Seitenzahl der Suchergebnisse._ipg: Die Anzahl der pro Seite angezeigten Einträge (Standard: 60).
Sie erhalten mehrere Ergebnisse zum Suchbegriff. Um die Daten erfolgreich zu extrahieren, müssen Sie alle Einträge auf der Seite durchgehen und die Paginierung vornehmen, bis Sie die letzte Seite erreichen.
eBay-Angebote
Wie Sie im Bild unten sehen können, haben wir nach dem Schlüsselwort gesucht und eine Ergebnisliste erhalten. Jedes Ergebnis ist in einer separaten Datei enthalten li Etikett. Um die gewünschten Informationen zu extrahieren, müssen wir alle diese durchlaufen li Tags und extrahieren Sie sorgfältig spezifische Daten. Wir extrahieren den Titel, den Preis, die Versandkosten des Verkäufers, die Produkt-URL und das Listendatum.
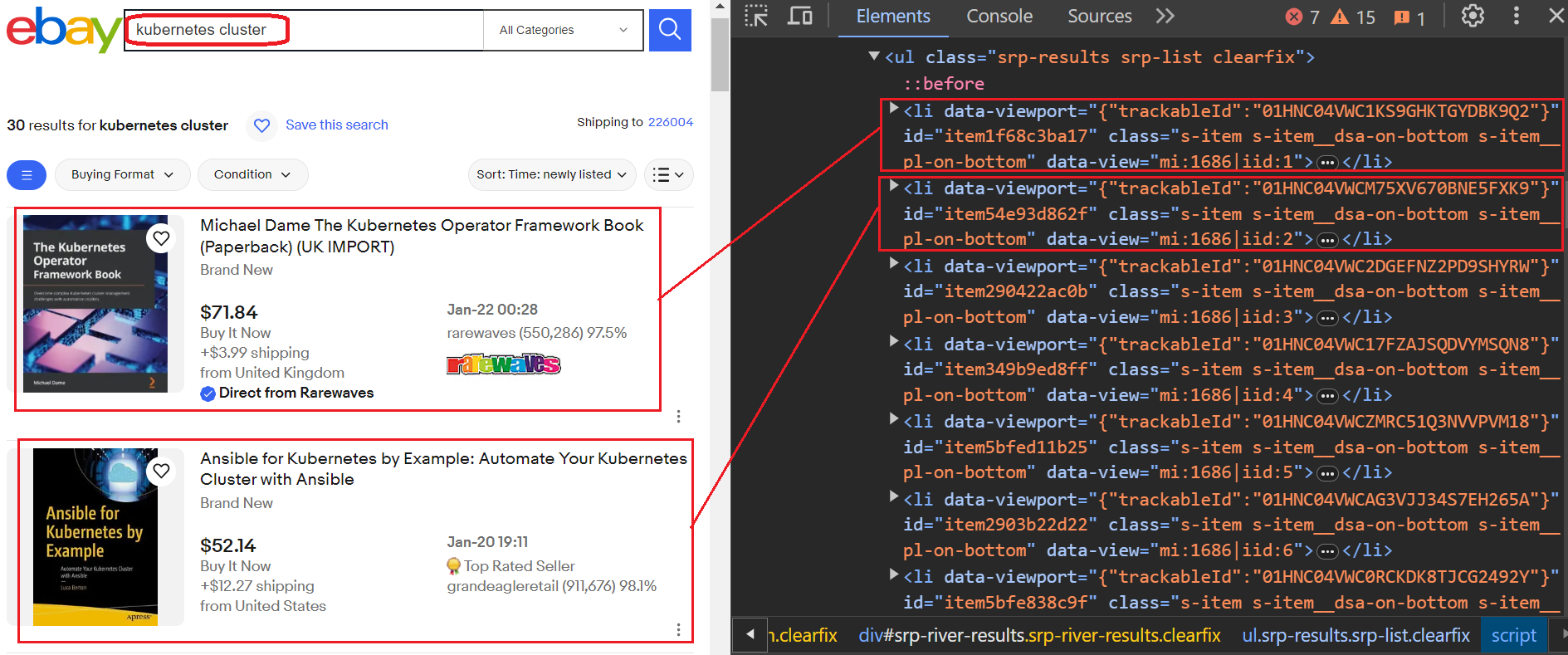
Sehen wir uns an, wie wir Produktdaten aus dieser Liste entfernen können. Konkret ist jedes Produkt in einer Verpackung verpackt li Tag mit der Klasse s-item. Wir können das nutzen find_all Funktion, um alle diese Elemente zu lokalisieren. Diese Funktion findet alle passenden Elemente im Analysebaum und gibt eine Liste zurück. Anschließend können Sie die Liste durchlaufen und jedes Element einzeln an übergeben extract_product_details Funktion zum Extrahieren seiner Informationen.
for item in soup.find_all("li", class_="s-item"):
extract_product_details(item)Jetzt können Sie alle Datenpunkte extrahieren, indem Sie das Tag mit dem Klassennamen übergeben. Der Titel befindet sich im div Tag, der Klasse hat s-item__title. Ebenso liegt der Preis innerhalb der span Tag mit Klasse s-item__priceund die Versandkosten liegen innerhalb der span Tag mit Klasse s-item__logisticsCost.
def extract_product_details(item):
title = item.find("div", class_="s-item__title")
price = item.find("span", class_="s-item__price")
seller = item.find("span", class_="s-item__seller-info-text")
shipping = item.find("span", class_="s-item__logisticsCost")
url = item.find("a", class_="s-item__link")
list_date = item.find("span", class_="s-item__listingDate")Umgang mit Paginierung
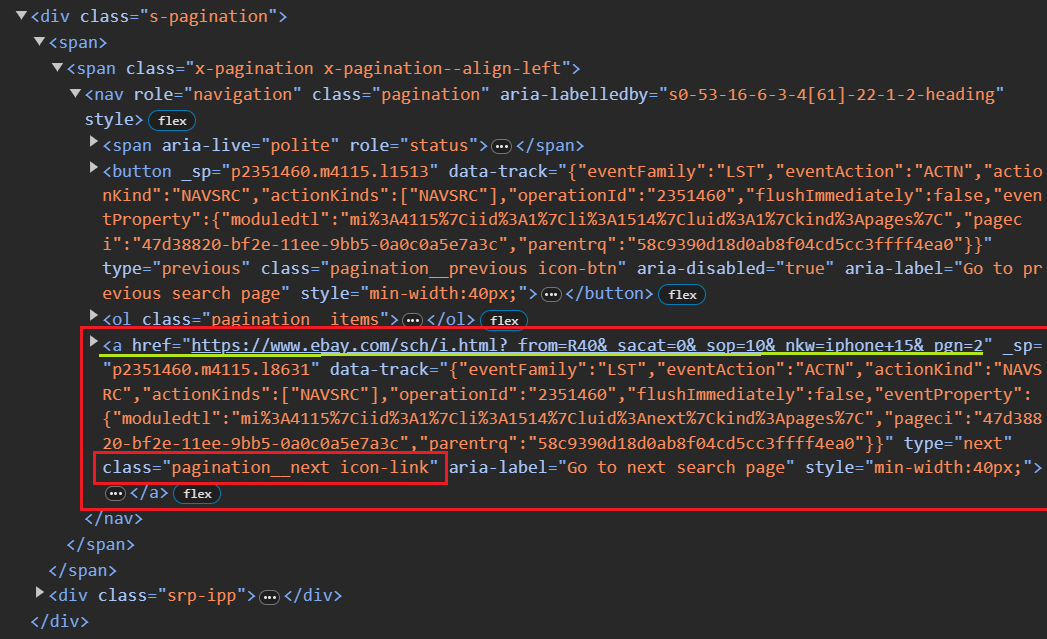
Für eine einzelne Seite wäre das Scrapen unkompliziert. Allerdings verwendet eBay ein nummeriertes Paginierungssystem (fortlaufende Seitenzahlen in der URL). Sie können leicht beobachten, wie sich die URL ändert, indem Sie auf „Weiter“ klicken: die _pgn Der Parameter wird einfach um eins erhöht.

Um die Paginierung zu handhaben, können wir eine While-Schleife implementieren, die so lange fortgesetzt wird, bis keine nächste Seite mehr verfügbar ist. Nach dem Scrapen jeder Seite müssen Sie die URL der nächsten Seite extrahieren. Unten finden Sie einen groben Codeausschnitt:
def extract_next_url(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
next_page_button = soup.select_one("a.pagination__next")
next_page_url = next_page_button("href") if next_page_button else None
while current_url:
products_on_page, next_page_url = extract_next_url(current_url)
current_url = next_page_urlDas obige Code-Snippet verwendet CSS-Selektoren, um das erste Ankerelement mit der Klasse zu finden pagination__next, was normalerweise die Schaltfläche „Nächste Seite“ darstellt. Wenn eine solche Schaltfläche gefunden wird, wird der Wert extrahiert href Attribut.
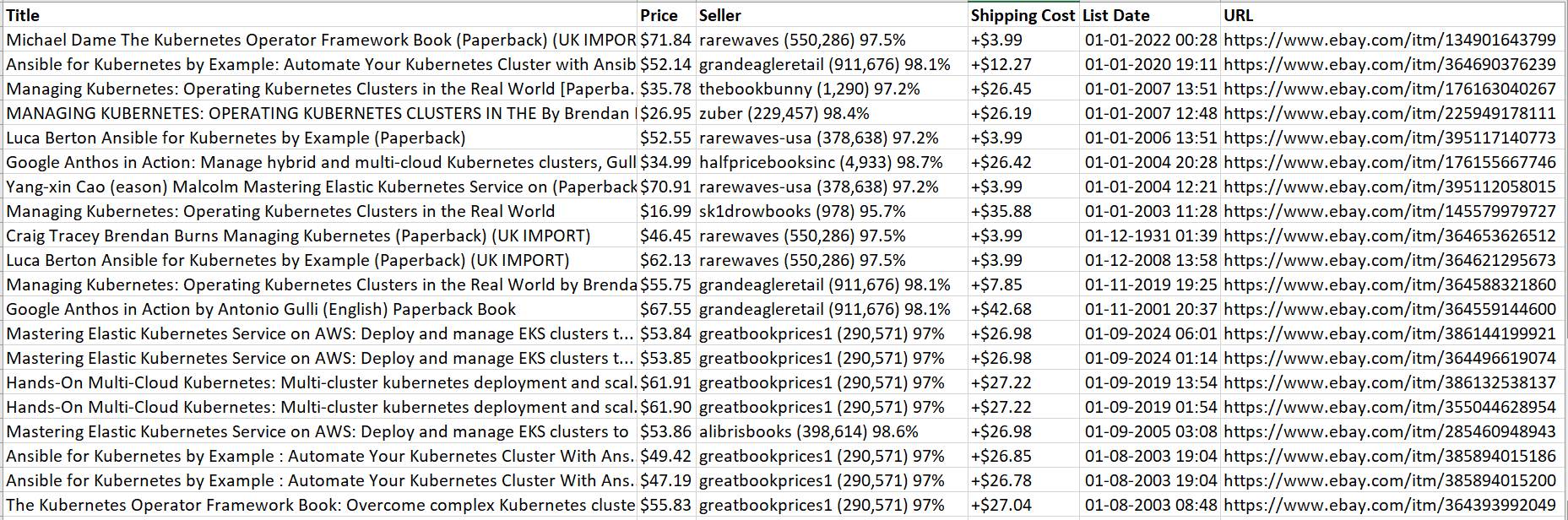
Wir haben es geschafft! Alles wird in einer CSV-Datei gespeichert.
Vollständiger Code
Das Skript ermöglicht es dem Benutzer im Wesentlichen, eine Suchabfrage und Sortierpräferenz einzugeben (z. B. „beste Übereinstimmung“, „bald_ende“ oder „neu_gelistet“), eBay-Suchergebnisse zu durchsuchen, Produktdetails zu extrahieren und sie in einer CSV-Datei zu speichern.
import requests
from bs4 import BeautifulSoup
import pandas as pd
from urllib.parse import urlencode
def extract_product_details(item):
title = item.find("div", class_="s-item__title")
price = item.find("span", class_="s-item__price")
seller = item.find("span", class_="s-item__seller-info-text")
shipping = item.find("span", class_="s-item__logisticsCost")
url = item.find("a", class_="s-item__link")
list_date = item.find("span", class_="s-item__listingDate")
return {
"Title": title.text.strip() if title else "Not available",
"Price": price.text.strip() if price else "Not available",
"Seller": seller.text.strip() if seller else "Not available",
"Shipping Cost": (
shipping.text.strip().replace("shipping", "").strip()
if shipping
else "Not available"
),
"List Date": (
list_date.text.strip() if list_date else "Date not found"
),
"URL": url("href").split("?")(0) if url else "Not available",
}
def extract_page_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
products = (
extract_product_details(item) for item in soup.find_all("li", class_="s-item")
)
next_page_button = soup.select_one("a.pagination__next")
next_page_url = next_page_button("href") if next_page_button else None
return products, next_page_url
def write_to_csv(products, filename="product_info.csv"):
df = pd.DataFrame(products)
mode = "w" if not pd.io.common.file_exists(filename) else "a"
df.to_csv(filename, index=False, header=(mode == "w"), mode=mode)
print(f"Data has been written to {filename}")
def make_request(query, sort, items_per_page=60):
base_url = "<https://www.ebay.com/sch/i.html?">
query_params = {
"_nkw": query,
"_ipg": items_per_page,
"_sop": SORTING_MAP(sort),
}
return base_url + urlencode(query_params)
def scrape_ebay(search_query, sort):
current_url = make_request(search_query, sort, 240)
total_products = ()
while current_url:
products_on_page, next_page_url = extract_page_data(current_url)
total_products.extend(products_on_page)
current_url = next_page_url
total_products = (
product for product in total_products if "Shop on eBay" not in product("Title")
)
write_to_csv(total_products)
SORTING_MAP = {
"best_match": 12,
"ending_soonest": 1,
"newly_listed": 10,
}
user_search_query = input("Enter eBay search query: ")
sort = input("Choose one ('best_match', 'ending_soonest', 'newly_listed'): ")
scrape_ebay(user_search_query, sort)Herausforderungen beim Scraping von eBay
Um das eBay-Crawling effizienter und effektiver zu gestalten, sollten Sie auch bedenken, dass eBay Bots erkennen, IP-Adressen blockieren und letztendlich den Datenfluss stören kann. Daher müssen Sie bei der Ausweitung des eBay-Crawlings auf die folgenden Herausforderungen vorbereitet sein:
- CAPTCHAs: Erschweren die reibungslose Datenextraktion erheblich.
- IP-Blockierung: eBay blockiert aktiv verdächtige IP-Adressen.
- Sitzungszeitüberschreitungen: Kontinuierliches Scraping erfordert die Aufrechterhaltung aktiver Sitzungen, um Datenlücken zu vermeiden.
- Paginierung: Eine effiziente Navigation durch paginierte Inhalte kann die Scraping-Geschwindigkeit erheblich verbessern.
- Rechtliche und ethische Überlegungen: Es ist wichtig, die Nutzungsbedingungen und die Privatsphäre der Nutzer von eBay zu respektieren.
Scraping von eBay mit der Scrape-It.Cloud API
Sehen wir uns an, wie einfach die Web-Scraping-API mit nur einem einfachen API-Aufruf Produktinformationen von E-Commerce-Websites extrahieren kann, ohne dass ein Proxy erforderlich ist.
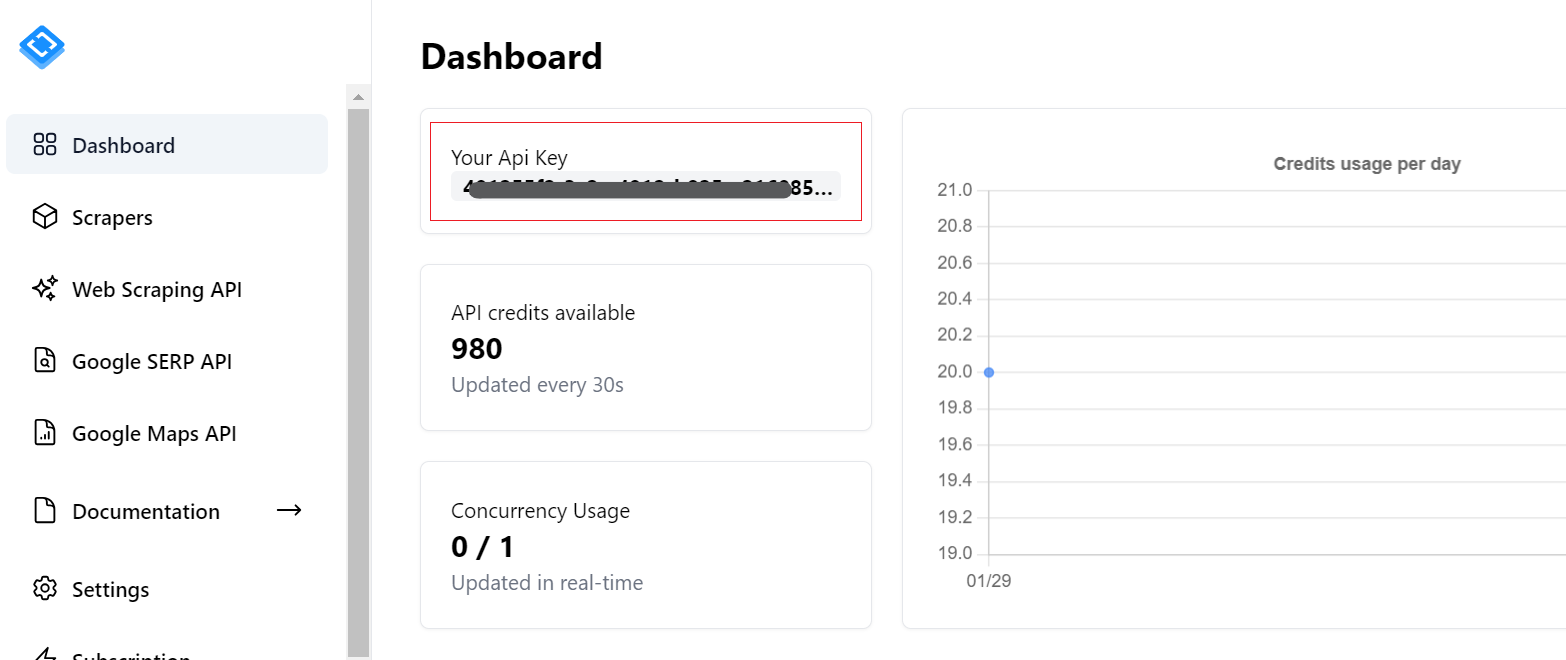
Um zu beginnen, benötigen Sie einen API-Schlüssel. Sie finden es in Ihrem Konto, nachdem Sie sich bei Scrape-It.Cloud angemeldet haben. Darüber hinaus erhalten Sie 1.000 Gratis-Credits, wenn Sie sich zum Testen unserer Funktionen registrieren.
Vorteile der Verwendung von Scrape-It.Cloud für eBay Scraping
eBay hat, wie die meisten Online-Plattformen, eine negative Einstellung zum Bot-Scraping. Das Scrapen großer Datenmengen in kurzer Zeit kann zu einem erhöhten Website-Verkehr führen, der sich auf Leistung und Verfügbarkeit auswirken kann. Dies kann die Reaktionszeiten anderer Benutzer verlangsamen und dazu führen, dass potenzielle Käufer verloren gehen. Obwohl nicht alle Scraper der Website bei der Datenerfassung schaden, kann eBay Maßnahmen ergreifen, um solche Bots einzuschränken, wenn sie entdeckt werden.
Um Bots einzudämmen, nutzt eBay Maßnahmen wie CAPTCHA und die Blockierung verdächtiger IP-Adressen. Diese Maßnahmen können das Schaben deutlich erschweren, sind aber umgehbar. Sie können beispielsweise CAPTCHA-Lösungsdienste in Ihre Anwendung implementieren und Proxys verwenden, um die Blockierung Ihrer echten IP-Adresse zu vermeiden. Dazu müssen Sie jedoch entweder kostenlose Proxys finden, die unzuverlässig sind, oder teure Proxys kaufen und diese für die Rotation konfigurieren.
Um alle diese Probleme auf einmal zu lösen, anstatt sie einzeln zu umgehen, was kostspielig sein kann, können Sie einen Mittelsmann-Dienst nutzen, der Daten für Sie sammelt und Ihnen die Daten fertig zur Verfügung stellt. Bei diesen Zwischenhändlern handelt es sich um Web-Scraping-APIs. In diesem Beispiel sehen wir uns an, wie wir unseren Code mithilfe der Web-Scraping-API Scrape-It.Cloud verbessern können, die verschiedene Mechanismen zur Vermeidung von Anti-Scraping-Techniken verwendet, darunter Blockierungsvermeidung, CAPTCHA-Lösung, JavaScript-Rendering, Proxy-Nutzung und mehr.
Implementieren der Scrape-It.Cloud-API in Ihrem Projekt
Mit Scrape-It.Cloud können Benutzer gezielte Daten direkt im JSON-Format abrufen, was den Datenextraktionsprozess vereinfacht und die Notwendigkeit einer HTML-Analyse überflüssig macht. Hier sind die Schritte zur Implementierung der Scrape-It.Cloud-API in Ihrem Projekt:
- Geben Sie die Scrape-It.Cloud-API-URL an.
- Definieren Sie die Nutzlast: Diese enthält die Anfragedaten im JSON-Format. Es enthält:
- Ziel-URL: Die Website-Adresse, die Sie scannen möchten.
- Extraktionsregeln: Diese legen fest, wie bestimmte Elemente mithilfe von CSS-Selektoren extrahiert werden. Zum Beispiel,
{"Title": ".product-title-css-selector"}Extrahiert das Titelelement mit der angegebenen CSS-Selektorklasse. Sie können Regeln für verschiedene Datenpunkte wie Preis, Verkäufer, Versandkosten usw. definieren. - Header: Dazu gehören Informationen wie Ihr API-Schlüssel zur Authentifizierung.
- Senden Sie eine POST-Anfrage mit der API-URL, den Headern und der Nutzlast.
- JSON-Antwort speichern: Die Antwort enthält alle Datenpunkte, die Sie in Ihren Extraktionsregeln definiert haben.
Ist Ihnen bei diesem Ansatz etwas anderes aufgefallen? Ja! Sie müssen den HTML-Code nicht selbst analysieren. Wählen Sie einfach einen Namen für den Datenpunkt und stellen Sie den entsprechenden CSS-Selektor für die Daten bereit, die Sie extrahieren möchten. Scrape-It.Cloud übernimmt das Parsing und gibt die Daten direkt im JSON-Format zurück.
Hier ist ein einfaches Beispiel für die Integration der Scrape-It.Cloud-API in Ihr Projekt:
def extract_page_data(url):
api_url = "<https://api.scrape-it.cloud/scrape>"
payload = json.dumps(
{
"url": url,
"js_rendering": True,
"extract_rules": {
"Title": "div.s-item__title",
"Price": "span.s-item__price",
"Seller": "s-item__seller-info-text",
"Shipping cost": "span.s-item__logisticsCost",
"List Date": "span.s-item__listingDate",
"URL": "a.s-item__link @href",
"next": "a.pagination__next @href",
},
"proxy_type": "datacenter",
"proxy_country": "US",
}
)
headers = {
# Put Scrape-it.cloud API key here
"x-api-key": "YOUR_API_KEY",
"Content-Type": "application/json",
}
full_response = requests.request("POST", api_url, headers=headers, data=payload)
data = json.loads(full_response.text)
title_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Title", ()), columns=("Title")
)
price_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Price", ()), columns=("Price")
)Hier ist der vollständige Code für die Implementierung der Scrape-It.Cloud-API in Ihrem Projekt.
import requests
import pandas as pd
from urllib.parse import urlencode
import json
def extract_page_data(url):
api_url = "<https://api.scrape-it.cloud/scrape>"
payload = json.dumps(
{
"url": url,
"js_rendering": True,
"extract_rules": {
"Title": "div.s-item__title",
"Price": "span.s-item__price",
"Seller": "s-item__seller-info-text",
"Shipping cost": "span.s-item__logisticsCost",
"List Date": "span.s-item__listingDate",
"URL": "a.s-item__link @href",
"next": "a.pagination__next @href",
},
"proxy_type": "datacenter",
"proxy_country": "US",
}
)
headers = {
# Put Scrape-it.cloud API key here
"x-api-key": "YOUR_API_KEY",
"Content-Type": "application/json",
}
full_response = requests.request(
"POST", api_url, headers=headers, data=payload)
data = json.loads(full_response.text)
title_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Title", ()), columns=("Title")
)
price_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Price", ()), columns=("Price")
)
seller_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Seller", ()), columns=("Seller")
)
shipping_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Shipping cost", ()),
columns=("Shipping cost"),
)
list_date_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("List Date", ()),
columns=("List Date"),
)
url_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("URL", ()), columns=("URL")
)
products = pd.concat(
(title_df, price_df, seller_df, shipping_df, list_date_df, url_df), axis=1
)
products("URL_split") = products("URL").apply(lambda x: x.split("?")(0))
products = products.drop(columns=("URL"))
next_page_url = data("scrapingResult")("extractedData").get("next")
next_page_url = next_page_url(0) if next_page_url else None
return products, next_page_url
def make_request(query, sort, items_per_page=60):
base_url = "<https://www.ebay.com/sch/i.html?">
query_params = {
"_nkw": query,
"_ipg": items_per_page,
"_sop": SORTING_MAP(sort),
}
return base_url + urlencode(query_params)
def write_to_csv(products, filename="product_info.csv"):
mode = "w" if not pd.io.common.file_exists(filename) else "a"
products.to_csv(filename, index=False, header=(mode == "w"), mode=mode)
print(f"Data has been written to {filename}")
def scrape_ebay(search_query, sort):
current_url = make_request(search_query, sort, 240)
total_products = pd.DataFrame()
while current_url:
products_on_page, next_page_url = extract_page_data(current_url)
if total_products.empty:
total_products = pd.DataFrame(products_on_page)
else:
total_products = pd.concat(
(total_products, products_on_page), ignore_index=True
)
write_to_csv(total_products)
current_url = next_page_url
SORTING_MAP = {
"best_match": 12,
"ending_soonest": 1,
"newly_listed": 10,
}
user_search_query = input("Enter eBay search query: ")
sort = input("Choose one ('best_match', 'ending_soonest', 'newly_listed'): ")
scrape_ebay(user_search_query, sort)Abschluss
Dieses Tutorial führte Sie durch das Scrapen von Datenelementen aus eBay. Wir haben die Anforderungsbibliothek verwendet, um Roh-HTML herunterzuladen und es dann mit BS4 zu analysieren. Wir haben die gewünschten Daten mithilfe integrierter Methoden aus dem strukturierten HTML-Baum extrahiert und in einer CSV-Datei gespeichert. Um eine Blockierung zu vermeiden, haben wir schließlich die Scrape-It.Cloud-API verwendet, die jeden Web-Scraper intelligent konfiguriert, um eine Blockierung zu verhindern.
