
Was ist ein Proxy-Pool?
Ein Proxy-Pool ist die Bezeichnung für eine große Menge an IP-Adressen, die ein Proxy-Anbieter gleichzeitig zur Verfügung stellt. Statt einer einzelnen festen Proxy-IP verwendet man hier einen dynamischen Zugang, über den bei jeder Verbindung automatisch eine andere IP aus dem Pool zugewiesen wird.
Der Begriff „Proxy-Pool“ wird fast ausschließlich im Zusammenhang mit rotierenden Proxys verwendet – also Systemen, bei denen sich die IP-Adresse regelmäßig ändert. Das Ziel: eine große Zahl an Anfragen über viele verschiedene IPs zu verteilen, um Sperren, Captchas oder Ratenbegrenzungen zu vermeiden.
Je nach Anbieter kann ein Proxy-Pool aus IPs von Rechenzentren, Haushalten, Mobilfunknetzen oder Internetanbietern bestehen. Größe, Zusammensetzung und Qualität dieses Pools haben großen Einfluss auf die Leistungsfähigkeit des Systems.
Wie funktioniert ein Proxy-Pool technisch?
Technisch gesehen basiert ein Proxy-Pool auf einem sogenannten Backconnect-System. Der Nutzer verbindet sich nicht direkt mit einer bestimmten IP-Adresse, sondern mit einem festen Zugangspunkt – meist ein Hostname mit Port (z. B. de.proxyanbieter.com:10000). Dieser fungiert als Gateway zur gesamten Pool-Infrastruktur.
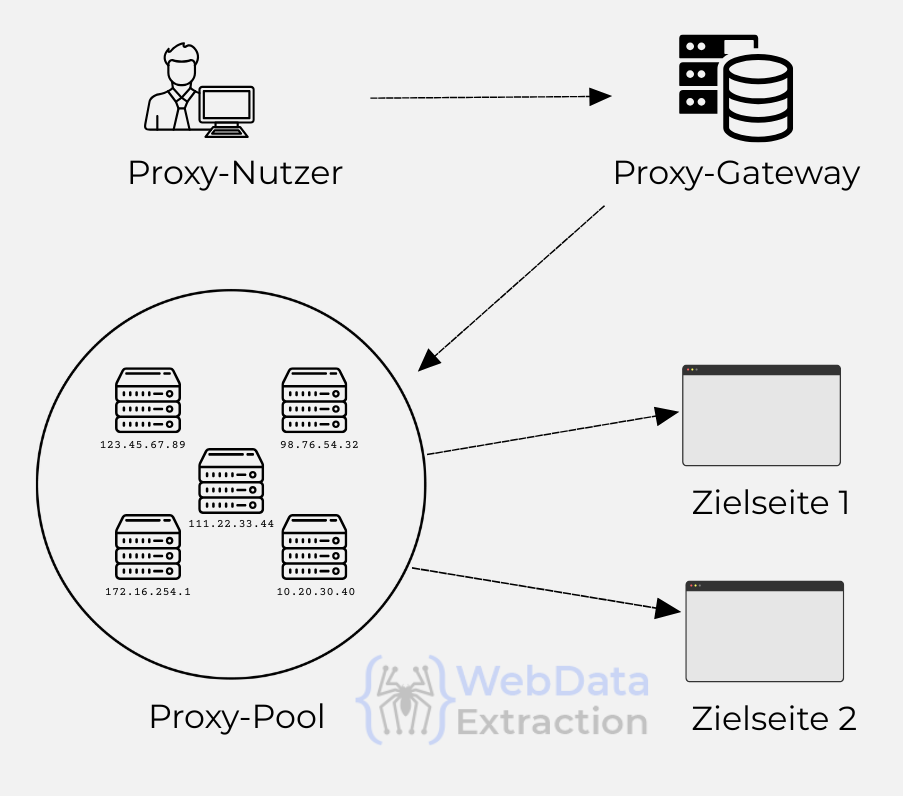
Im Hintergrund übernimmt der Anbieter die Auswahl und Weiterleitung des Traffics über einen von vielen Proxy-Servern, die jeweils eine eigene IP-Adresse besitzen. Die Zuordnung der IP erfolgt dynamisch – entweder automatisch oder nach bestimmten Parametern.
Gängige IP-Rotationsmethoden:
-
Per-Request-Rotation: Bei jeder Verbindung wird eine neue IP zugewiesen. Ideal für aggressives Scraping oder verteilte Zugriffe.
-
Zeitgesteuerte Rotation: Eine IP bleibt für eine bestimmte Dauer (z. B. 5–10 Minuten) aktiv, bevor sie gewechselt wird.
-
Sticky Sessions: Durch Nutzung einer Session-ID (z. B. im Benutzernamen) kann die IP über mehrere Requests hinweg gehalten werden.
-
Portbasierte Steuerung: Unterschiedliche Ports stehen für unterschiedliche Rotationsarten. Beispiel: Port
10000= Rotation, Port10001= Sticky. -
Round-Robin oder Zufallsprinzip: IPs werden zyklisch oder zufällig verteilt, oft unter Ausschluss kürzlich verwendeter IPs.
Steuerung über Zugangsdaten:
Viele Anbieter codieren Steuerungsparameter direkt in den Benutzernamen:
-
kunde123-country-us-session-abc123→ US-IP + Sticky Session -
kunde123-session-random→ Zufallsrotation bei jedem Zugriff -
kunde123-const→ Session soll bei IP-Ausfall nicht wechseln (optional)
Die Authentifizierung erfolgt je nach Anbieter:
-
HTTP Basic Auth mit Benutzername/Passwort
-
oder IP-Whitelist (z. B. bei dedizierten Proxys)
Beispiel für Proxy-Formate:
-
HTTP-Proxys:
http://user:[email protected]:10000 -
SOCKS5-Proxys:
socks5://user:[email protected]:1080
Erweiterte Funktionen bei Enterprise-Anbietern:
-
Failover-Mechanismen bei blockierten IPs
-
IP-Pinning für konstante Sessions trotz Rotation
-
Geo- und ASN-Targeting über Benutzernamen oder API
-
API-Zugriff zur Verwaltung von Session-IDs, Limits oder Filterregeln
Der Proxy-Gateway fungiert dabei als intelligenter Dispatcher: Die gesamte Komplexität des IP-Wechsels, der Auswahl, Filterung und Fehlerbehandlung läuft im Hintergrund auf Anbieter-Seite.
Welche Arten von Proxy-Pools gibt es?
Ein Proxy-Pool ist nicht gleich Proxy-Pool. Je nachdem, aus welchen Quellen die IP-Adressen stammen und wie der Zugriff organisiert ist, unterscheiden sich Struktur, Steuerungsmöglichkeiten und Stabilität erheblich. Hier eine realistische Beschreibung der gängigsten Pool-Typen:
1. Datacenter-Pools
Ein Datacenter-Pool besteht aus Tausenden oder sogar Zehntausenden IPs, die über virtuelle Maschinen (VPS) in Rechenzentren weltweit betrieben werden. Diese Server sind meist gleichmäßig konfiguriert, laufen rund um die Uhr und liefern eine konstant hohe Verbindungsgeschwindigkeit. Der Nutzer verbindet sich über einen Gateway – eine feste IP oder Domain mit Port – und erhält von dort eine zufällige IP aus dem Pool zugewiesen.
Bei einigen Anbietern lässt sich der Zielserver über Parameter beeinflussen. Beispielsweise kann man angeben:
-
In welchem Land sich die IP befinden soll
-
Welches Protokoll (HTTP/SOCKS5) benötigt wird
-
Wie lang eine IP gehalten werden soll (Sticky-Session-Steuerung)
Die Unterschiede zwischen den IPs sind minimal – alle sind technisch stark, aber sie haben auch einen Nachteil: Viele Websites erkennen diese IPs als künstlich (Hostingumgebung), was zu Sperren führen kann. Besonders bei Login-Seiten, Bezahlfunktionen oder verhaltenssensitiven Systemen sind sie oft unbrauchbar.
2. ISP-Pools
ISP-Proxys werden von Anbietern angeboten, die Verträge mit echten Internetprovidern abgeschlossen haben – z. B. Telekom, Vodafone, Orange oder Comcast. Die IPs stammen offiziell von diesen ISPs, werden aber auf Servern im Rechenzentrum gehostet. Das bedeutet: physisch laufen die Verbindungen über Hosting-Server, aber in der Außendarstellung wirken sie wie ein Heimanschluss.
Für den Nutzer ist das ein Vorteil: Er kann beim Verbindungsaufbau nicht nur die Region wählen, sondern oft auch den gewünschten ISP selbst. Beispiel: Ein User möchte nur IPs, die von deutschen Anbietern wie Telekom oder Vodafone stammen – diese kann er gezielt auswählen.
Der Zugriff erfolgt wieder über einen zentralen Gateway mit Benutzername und Passwort. Durch zusätzliche Session-Parameter lassen sich IPs über mehrere Minuten halten. Die Stabilität ist hoch, allerdings besteht ein gewisses Risiko, dass der IP-Anbieter (z. B. ISP) selbst nach einiger Zeit die IP austauscht – ohne Zutun des Proxy-Providers.
Use Case: Wenn du ein System aufbauen willst, das ausschließlich so aussieht, als ob es z. B. aus Deutschland über Vodafone oder O2 arbeitet – ohne dass der Hostname oder das Verhalten der IP diesen Eindruck zerstört –, ist ein ISP-Pool die passende Wahl.
3. Residential-Pools
Richtig komplex wird es bei Residential-Pools. Diese bestehen aus IPs, die über echte Haushaltsanschlüsse laufen – oft durch Geräte, auf denen VPNs, Apps mit integrierten SDKs oder Browser-Plugins installiert sind. Die IPs stammen dabei aus hunderten verschiedenen Ländern, Providern, Anschlussarten und sogar Verbindungstypen (Glasfaser, DSL, Mobilfunk).
Der Pool ist also eine globale Mischung, die sich ständig verändert. Die IP, die du heute bekommst, ist morgen vielleicht nicht mehr verfügbar. Und jede IP hat eigene Eigenschaften: Geschwindigkeit, Ping, Stabilität, Blacklist-Status.
Was Residential-Pools besonders macht, ist die Filterung. Gute Anbieter erlauben Targeting nach:
-
Land, Region, Stadt
-
ISP
-
Gerätetyp oder Verbindungstyp
-
ASN (z. B. nur Haushalte mit Vodafone in Berlin)
Allerdings: Die in Werbetexten genannten „10 Millionen IPs“ sind irreführend. Die Zahl bezieht sich häufig auf historische Gesamtwerte (z. B. IPs, die einmal im letzten Monat online waren). Was tatsächlich jetzt gerade verfügbar ist, kann man nur durch aktives Testen herausfinden – viele Anbieter bieten keine echten Zahlen oder Listen an.
Nachteile: Du weißt nie genau, wie lange eine IP verfügbar bleibt. Die Verbindung kann instabil oder langsam sein. Und: Es gibt keine Garantie, dass du beim nächsten Request überhaupt eine IP mit deinen gewünschten Eigenschaften bekommst.
4. Mobile-Pools
Im Mobilbereich gibt es zwei ganz unterschiedliche Klassen von Anbietern:
Variante A – Eigene Modem-Infrastruktur
Der Anbieter betreibt selbst 3G/4G/5G-Modems (z. B. Huawei-Sticks oder LTE-Router), in die echte SIM-Karten verschiedener Netzbetreiber eingelegt sind. Diese Systeme stehen in Racks und sind softwareseitig steuerbar: Der Nutzer kann per API eine IP wechseln, ein Session-Timeout setzen oder sogar gezielt den Wechsel unterdrücken, solange dieselbe IP erhalten bleiben soll.
Ein solcher Pool besteht zwar oft nur aus einigen hundert bis tausend IPs, ist aber technisch vollständig unter Kontrolle. Ideale Wahl für Projekte mit wenig Toleranz gegenüber Fehlern und hoher Sichtbarkeit (z. B. Google Ads, TikTok, Ticketplattformen).
Variante B – Mobil-IPs aus dem Residential-Pool
Hierbei zieht der Anbieter einfach IPs heraus, die im Residential-Netz als „mobil“ erkannt wurden – also beispielsweise von einem Smartphone mit LTE-Anschluss, das per VPN oder SDK ins System eingebunden wurde. Diese IPs sind weniger stabil, können jederzeit verschwinden und bieten oft keine Möglichkeit zur Steuerung.
Solche Pools sind billiger und sehen auf dem Papier ebenfalls nach „Mobile“ aus – aber in der Praxis ist die Steuerung eingeschränkt oder gar nicht vorhanden.
Fazit
Proxy-Pools sind das Rückgrat moderner Proxy-Infrastruktur. Statt mit festen Einzel-IPs zu arbeiten, erhalten Nutzer Zugriff auf dynamisch verwaltete IP-Bereiche – gesteuert über zentrale Gateways. Je nach Typ (Datacenter, Residential, Mobile oder ISP) unterscheiden sich Struktur, Verhalten, Steuerungsmöglichkeiten und Kosten erheblich. Wer die Funktionsweise eines Pools versteht und gezielt filtert (z. B. nach Geo, Provider oder Sessiondauer), kann mit hoher Effizienz arbeiten und Sperren gezielt umgehen. Entscheidend ist dabei: Nicht nur der IP-Typ zählt, sondern auch die technische Umsetzung durch den Anbieter.
Ein wichtiger Hinweis zum Schluss: Verlasse dich nicht blind auf die Zahlen und Versprechen auf der Website eines Anbieters. Begriffe wie „10 Millionen IPs“ sind oft Marketingwerte ohne Aussagekraft für dein konkretes Setup. Teste den Zugang immer vor dem Kauf – selbst wenn keine Testoption angegeben ist. Viele Anbieter stellen auf Anfrage über das Kontaktformular oder den Support dennoch einen Probezugang zur Verfügung.
